
Однажды в интервью один всем известный российский музыкант сказал: “Мы работаем над тем, чтобы лежать и плевать в потолок”. Не могу не согласиться с этим утверждением, ведь то, что именно лень является движущей силой в развитии технологий, спору никакого быть не может. И действительно, только за последнее столетие мы перешли от паровых машин к цифровой индустриализации, и теперь искусственный интеллект, о котором писали фантасты и футурологи прошлого столетия, с каждым днём становится всё большей реальностью нашего мира. Компьютерные игры, мобильные устройства, умные часы и многое другое в своей основе используют алгоритмы, связанные с механизмами машинного обучения.
В настоящее время, благодаря росту вычислительных способностей графических процессоров и появившемуся большому объёму данных, популярность получили нейронные сети, с использованием которых решают задачи классификации и регрессии, обучая их на подготовленных данных. О том как обучать нейронные сети и какие фреймворки для этого использовать — уже написано немало статей. Но существует более ранняя задача, которую так же необходимо решить и это задача формирования массива данных — датасета, для дальнейшего обучения нейронной сети. Об этом и пойдет речь в данной статье.
Не так давно возникла необходимость построения акустического классификатора автомобильных шумов способного выделять из общего аудиопотока данных: разбитое стекло, открытие дверей и работу двигателя автомобиля в различных режимах. Разработка классификатора не представляла сложности, но где взять датасет, чтобы он удовлетворял всем требованиям?
На помощь пришёл Google (не в обиду Яндексу — о его плюсах я скажу чуть позже), с использованием которого получилось выделить несколько основных кластеров, содержащих необходимые данные. Заранее хочу отметить, что источники, указанные в данной статье включают в себя большой объём акустической информации, с различными классами, позволяющим сформировать датасет под разные задачи. Теперь перейдём к обзору этих источников.
Freesound.org

Вероятнее всего Freesound.org предоставляет самый большой объём акустических данных, являясь совместным хранилищем лицензионных музыкальных образцов, который на данный момент насчитывает более чем 230.000 экземпляров звуковых эффектов. Каждый звуковой образец может распространяться под разной лицензией, поэтому предварительно лучше ознакомиться с лицензионным соглашением. Для примера, лицензия zero(cc0) имеет статус “Без авторских прав”, и позволяет осуществлять копирование, изменение и распространение, включая коммерческое использование, и позволяет использовать данные абсолютно легально.
Для удобства нахождения элементов акустической информации в множестве freesound.org, разработчики предусмотрели API предназначенный для анализа, поиска и скачивания данных из репозиториев. Для работы с ним необходимо получить доступ, для этого вам необходимо перейти на форму и заполнить все необходимые поля, после чего пройдёт генерация индивидуального ключа.

Разработчики freesound.org предоставляю API под различные языки программирования, тем самым позволяя решать разными инструментами одну и ту же задачу. Список поддерживаемых языков и ссылки доступа к ним на GitHub указаны ниже.
Для достижения цели использовался python, так как этот прекрасный язык программирования с динамической типизацией получил свою популярность благодаря своей простоте в использовании, полностью перечёркивая миф о сложности разработки программного обеспечения. Модуль для работы с freesound.org для python можно клонировать из хранилища github.com.
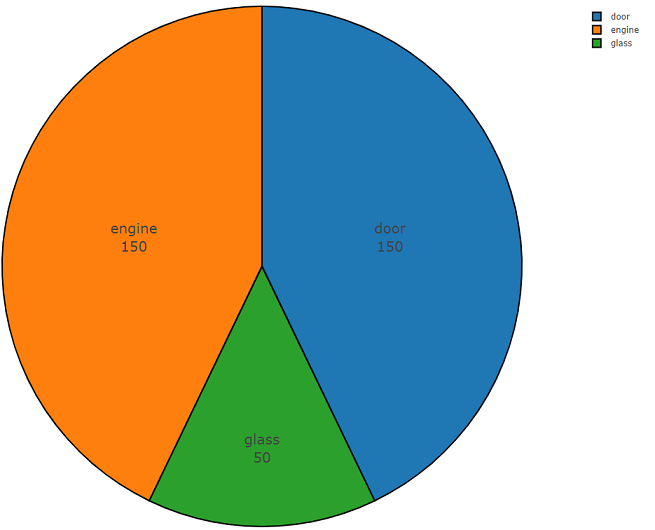
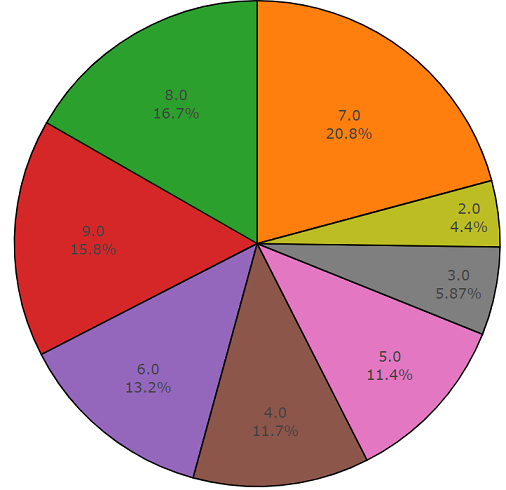
Ниже расположен программный код, состоящий из двух частей и демонстрирующий всю простоту использования данного API. Первая часть программного кода выполняет задачу анализа данных, результатом которого является плотность распределения данных по каждому запрашиваемому классу, а вторая часть осуществляет выгрузку данных из репозиториев freesound.org для подобранных классов. Плотность распределения при поиске акустической информации, с ключевыми словами glass, engine, door представлена ниже на круговой диаграмме в качестве примера.
Пример кода для анализа данных freesound.org
import plotly
import plotly.graph_objs as go
import freesound
import os
import termcolor
#Построение гистограммы в соответствии с данными
def histogram(data, filename = "tmp_histogram.html"):
data = [
go.Histogram(
histfunc="count",
x=data,
name="count",textfont=dict(size=15)
),
]
plotly.offline.plot({
"data": data,
"layout": go.Layout(title="Histogram")
}, auto_open=True, filename=filename)
pass
# Анализ запрашиваемых данных из пространства freesound.org
def freesound_analysis(search_tokens, output, lim_page_count = 1, key = None):
lim_page_count = int(lim_page_count)
try:
client = freesound.FreesoundClient()
client.set_token(key,"token")
print(termcolor.colored("Authorisation successful ", "green"))
except:
print(termcolor.colored("Authorisation failed ", "red"))
classes = list()
for token in search_tokens:
try:
results = client.text_search(query=token,fields="id,name,previews")
output_catalog = os.path.normpath(output)
if not os.path.exists(output_catalog):
os.makedirs(output_catalog)
page_count = int(0)
while True:
for sound in results:
try:
classes.append(token)
info = "Data has been getter: " + str(sound.name)
print(termcolor.colored(info, "green"))
except:
info = "Data has not been getter: " + str(sound.name)
print(termcolor.colored(info, "red"))
page_count += 1
if (not results.next) or (lim_page_count == page_count):
page_count = 0
break
results = results.next_page()
except:
print(termcolor.colored(" Search is failed ", "red"))
histogram(classes)
pass
Пример кода для скачивания данных freesound.org
#Скачивание запрашиваемых данных
def freesound_download(search_tokens, output, lim_page_count = 1, key = None):
lim_page_count = int(lim_page_count)
#Попытка подключения клиента. Необходимо указать полученный ключ
try:
client = freesound.FreesoundClient()
client.set_token(key,"token")
print(termcolor.colored("Authorisation successful ", "green"))
except:
print(termcolor.colored("Authorisation failed ", "red"))
for token in search_tokens:
try:
results = client.text_search(query=token,fields="id,name,previews")
output_catalog = os.path.normpath(output + "\\" + str(token))
if not os.path.exists(output_catalog):
os.makedirs(output_catalog)
page_count = int(0)
while True:
for sound in results:
try:
sound.retrieve_preview(output_catalog)
info = "Saved file: " + str(output_catalog) + str(sound.name)
print(termcolor.colored(info, "green"))
except:
info = str("Sound can`t be saved to " + str(output_catalog) + str(sound.name) )
print(termcolor.colored(info, "red"))
page_count += 1
if not results.next or lim_page_count == page_count:
page_count = 0
break
results = results.next_page()
except:
print(termcolor.colored(" Search is failed ", "red"))
Особенностью freesound является то, что анализ звуковых данных можно проводить без скачивания аудиофайла, позволяя получать MFCC, spectral energy, spectral centroid и другие коэффициенты. Подробнее о lowlevel информации можно прочесть в документации freesound.ord.
С использованием API freesound.org, время затраченное на выборку и выгрузку данных сводится к минимуму, позволяя экономить рабочие часы на изучение других источников информации, так как для высокой точности акустического классификатора необходим объёмный датасет с большой вариативностью, представляющей данные с различными гармониками на один и тот же класс событий.
YouTube-8M и AudioSet

Думаю что youtube особо не требуется в представлении, но всё же википедия говорит нам что youtube — это видехостинговый сайт, предоставляющий пользователям услуги показа видео, забывая сказать о том, что youtube — это огромная база данных, и этот источник просто необходимо использовать в машинном обучении, а Google Inc предоставляет нам проект под названием YouTube-8M Dataset.
YouTube-8M Dataset — это набор данных включающий в себя более миллиона видеофайлов с YouTube в высоком качестве, если давать более точную информацию, то на май 2018 года насчитывалось 6.1M видео с 3862-мя классами. Данный датасет распространяется под лицензией Creative Commons Attribution 4.0 International (CC BY 4.0). Такая лицензия позволяет вам копировать и распространять материал на любом носителе и формате.
Вы наверное задаётесь вопросом: причём тут видеоданные, когда для задачи необходима акустическая информация, и будете очень даже правы. Дело в том, что Google предоставляет не только видеоконтент, но и отдельно выделил подпроект с аудиоданными под названием AudioSet.
AudioSet — предоставляет набор данных полученный из роликов YouTube, где множество данных представлено в иерархию классов, с использованием файла онтологии, его графическое представление расположено ниже.
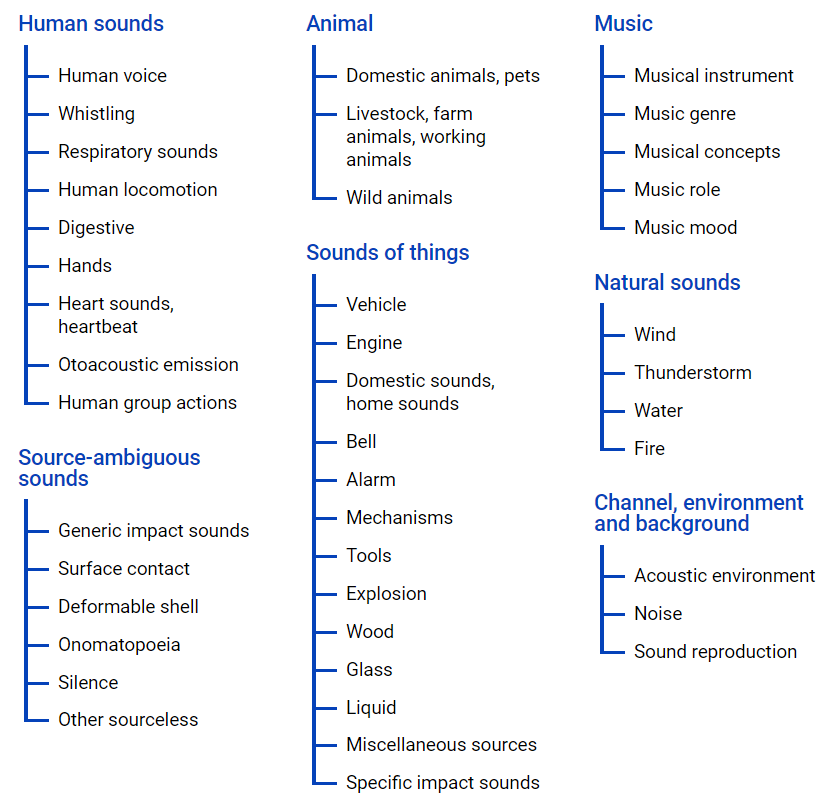
Данный файл позволяет получить представление о вложенности классов, а также получить доступ к youtube роликам. Для выгрузки данных из интернет пространства можно использовать python модуль — youtube-dl, который позволяет скачивать аудио или видеоконтент в зависимости от необходимой задачи.
AudioSet представляет кластер разделённый на три множества: тестовый, тренировочный(сбалансированный) и тренировочный( несбалансированный ) датасет.
Давайте рассмотрим данный кластер и проанализируем каждое такое из множеств отдельно, чтобы иметь представление о содержащихся классов.
Тренировочный (сбалансированный)
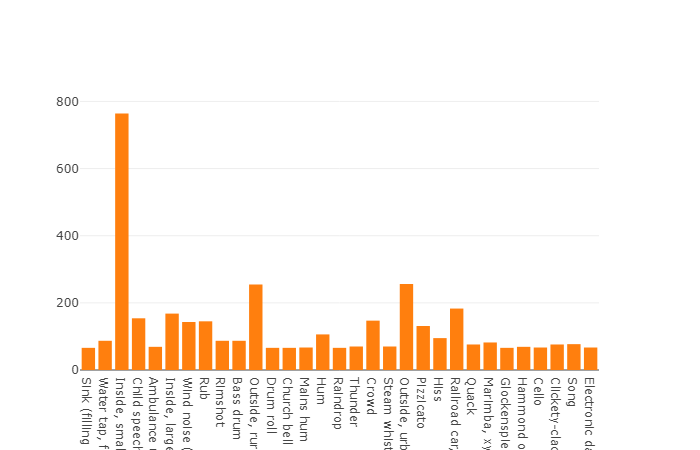
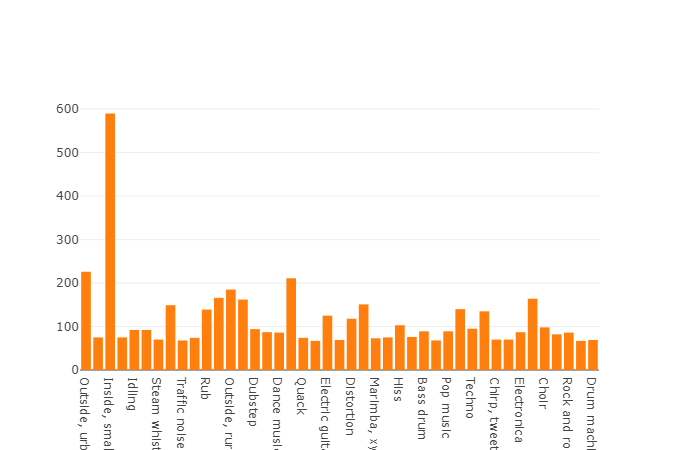
Согласно документации данный датасет состоит из 22,176 сегментов полученных из различных видеороликов отобранных по ключевым словам, предоставляя каждого класса не менее 59 экземпляров. Если посмотреть на плотность распределения корневых классов в иерархии множества, то мы увидим что самую большую группу аудио файлов представляет класс Music.
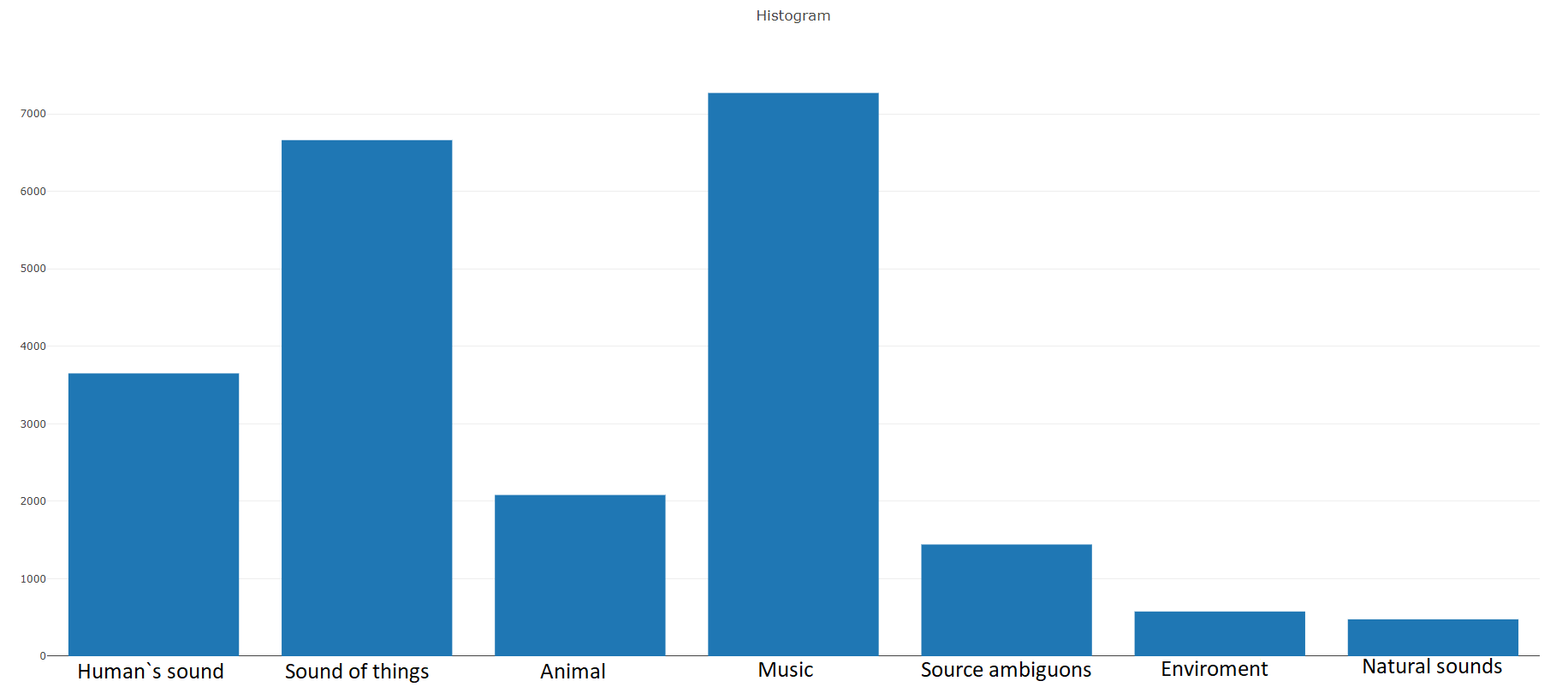
Организованные классы декомпозируются в подмножества классов, позволяя получать при использовании более детальную информацию. Данное сбалансированное тренировочное множество имеет плотность распределения на которой видно, что сбалансированность присутствует, но также отдельные классы сильно выделяются из общего вида.
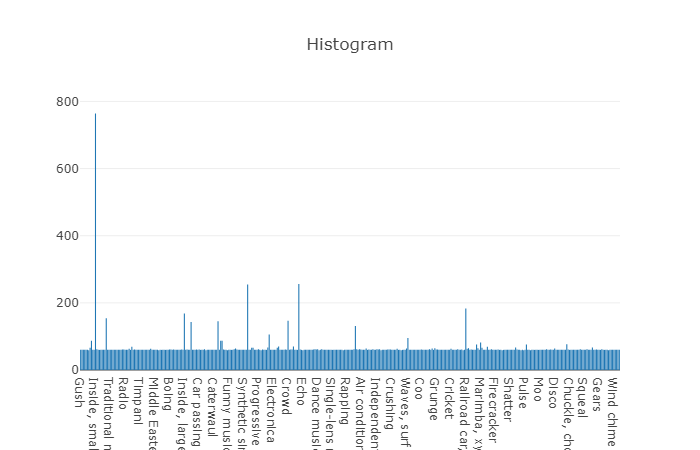
Распределение классов, количество элементов которых превышает среднее значение
Средняя длительность каждого из аудиофайлов равняется 10-ти секундам, более детальную информация представляет дисковая диаграмма, на которой видно, что длительность части файлов отличается от основного множества. Данная диаграмма так же представлена.
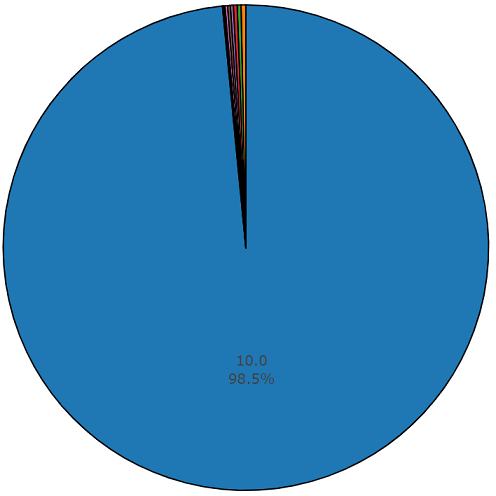
Диаграмма длительности полутора процентов, отличных от среднего значения, из сбалансированного множества audioset
Тренировочный (несбалансированный)
Преимуществом данного датасета является его размер. Только представьте, что согласно документации это множество включает в себя 2,042,985 сегментов и в сравнении со сбалансированных датасетом представляет большую вариативность, но и энтропия данного множества гораздо выше.
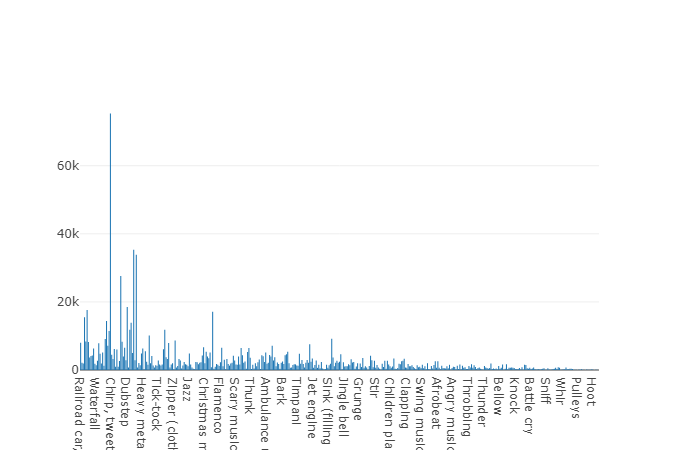
В данном множестве средняя длительность каждого из аудиофайлов также равняется 10-ти секундам, дисковая диаграмма для данного датасета представлена ниже.
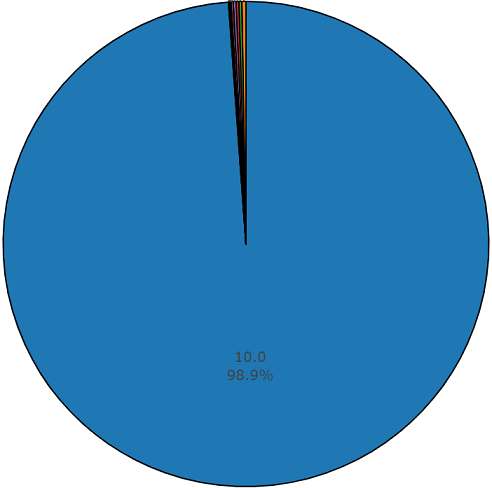
Диаграмма длительности, отличных от среднего значения, из несбалансированного множества audioset
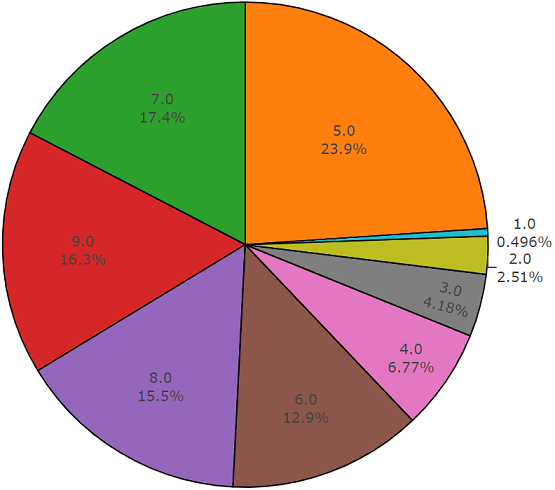
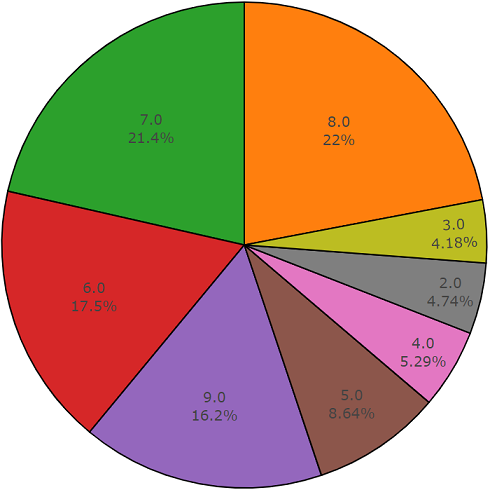
Тестовое множество
Данное множество очень похоже на сбалансированное множество с преимуществом того, что элементы этих множеств не пересекаются. Их распределение представлено ниже.
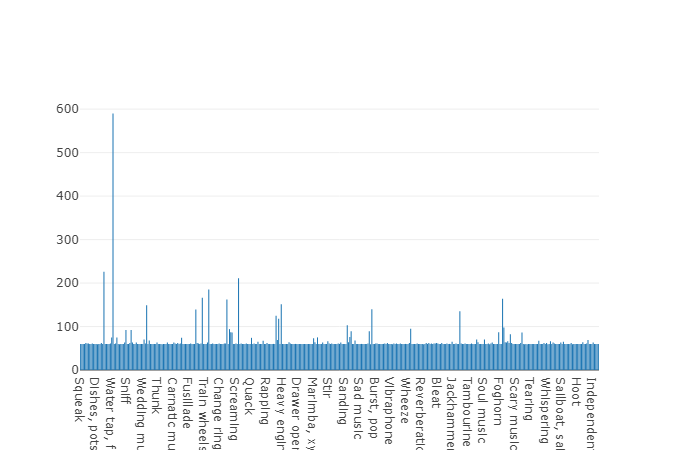
Распределение классов, количество элементов которых превышает среднее значение
Средняя длительность одного сегмента из данного датасета также равна 10-ти секундам
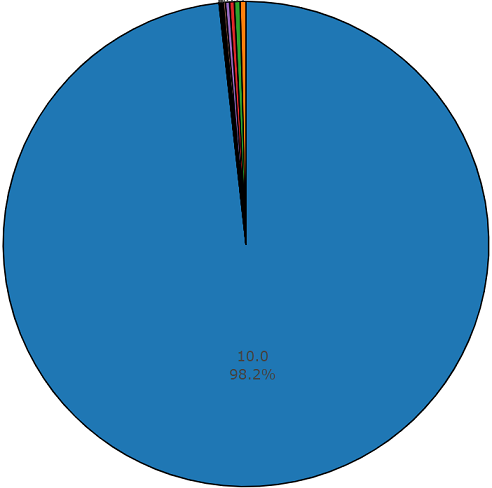
а оставшееся часть имеет длительность представленную на дисковой диаграмме
Пример программного кода для анализа и скачивания акустических данных в соответствии с выбранным датасетом:
import plotly
import plotly.graph_objs as go
from collections import Counter
import numpy as np
import os
import termcolor
import csv
import json
import youtube_dl
import subprocess
#Построение гистограммы в соответствии с данными
def histogram(data,hist_mean= True, filename = "tmp_histogram.html"):
if hist_mean == True:
cdata = Counter(data)
mean_number_classes = np.asarray([cdata[x] for x in cdata]).mean()
ldata = list()
for name in cdata:
if cdata[name] > mean_number_classes:
ldata += list(Counter({name:cdata[name]}).elements())
trace_mean_data = go.Histogram(histfunc="count", x=ldata, name="count" )
trace_data = go.Histogram(histfunc="count", x=data, name="count", text="" )
trace = [ trace_data, trace_mean_data]
plotly.offline.plot({
"data": trace,
"layout": go.Layout(title="stack")
}, auto_open=True, filename=filename)
pass
#Построение круговой диаграммы в соответствии с данными
def pie_chart(labels, values = None, filename = "tmp_pie_chart.html", textinfo = 'label+value'):
if labels == None:
raise Exception("Can not create pie chart, because labels is None")
if values == None:
data = Counter(labels)
labels = list()
values = list()
for name in data:
labels.append(name)
values.append(data[name])
trace = go.Pie(labels=labels, values=values,textfont=dict(size=20),hoverinfo='label+percent', textinfo=textinfo,
marker=dict(line=dict(color='#000000', width=2))
)
plotly.offline.plot([trace], filename='basic_pie_chart')
pass
#Анализ данных в соответствии с файлом онтологии и выбранного датасета
def audioset_analysis(audioset_file, inputOntology):
if not os.path.exists(inputOntology) or not os.path.exists(audioset_file):
raise Exception("Can not found file")
with open(audioset_file, 'r') as fe:
csv_data = csv.reader(fe)
sx = list()
with open(inputOntology) as f:
data = json.load(f)
duration_hist = list()
for row in csv_data:
if row[0][0] == '#':
continue
classes = row[3:]
try:
color = "green"
tmp_duration = str(float(row[2]) - float(row[1]))
info = str("id: ") + str(row[0]) + str(" duration: ") + tmp_duration
duration_hist.append(tmp_duration)
for cl in classes:
for dt in data:
cl = str(cl).strip().replace('"',"")
if cl == dt['id'] and len(dt['child_ids']) == 0:
sx.append(dt['name'])
info += str(" ")+str(dt['name']) + str(",")
except:
color = "red"
info = "File has been pass: " + str(row[0])
continue
print(termcolor.colored(info, color))
histogram(sx, filename="audioset_class")
pie_chart(duration_hist, textinfo="percent + label", filename="audioset_duration")
#Скачивание файла из youtube
def youtube_download(filepath, ytid):
ydl_opts = {
'format': 'bestaudio/best',
'outtmpl': os.path.normpath(filepath),
'postprocessors': [{
'key': 'FFmpegExtractAudio',
'preferredcodec': 'wav',
'preferredquality': '192',
}],
}
with youtube_dl.YoutubeDL(ydl_opts) as ydl:
ydl.download(['https://www.youtube.com/watch?v={}'.format(ytid)])
pass
#Обрезание файла с использованием ffmpeg
def cutOfPartFile(filename,outputFile, start, end, frequency = 44100):
duration = float(end) - float(start)
command = 'ffmpeg -i '
command += str(filename)+" "
command += " -ar " + str(frequency)
command += " -ss " + str(start)
command += " -t " + str(duration) + " "
command += str(outputFile)
subprocess.call(command,shell=True)
pass
#Преобразование выгруженных файлов из yotube к виду в соответствии с файлом датасета
def audioset_converter(incatalog,outcatalog, token = "*.wav", frequency = 44100):
find_template = os.path.join(incatalog,token)
files = glob(find_template);
for file in files:
_,name = os.path.split(file)
name = os.path.splitext(name)[0]
duration = str(name).split("_")[1:3]
filename = name.split("_")[0] +"."+ token.split(".")[1];
outfile = os.path.join(outcatalog,filename)
cutOfPartFile(file,outfile,start=duration[0],end=duration[1])
#Скачивание соответствующего датасета из audioset
def audioset_download(audioset_file, outputDataset, frequency = 44100):
t,h = os.path.split(audioset_file)
h = h.split(".")
outputDataset_full = os.path.join(outputDataset,str(h[0])+"_full")
outputDataset = os.path.join(outputDataset,str(h[0]))
if not os.path.exists(outputDataset):
os.makedirs(outputDataset)
if not os.path.exists(outputDataset_full):
os.makedirs(outputDataset_full)
with open(audioset_file, 'r') as fe:
csv_data = csv.reader(fe)
duration_hist = list()
for row in csv_data:
if row[0][0] == '#':
continue
try:
color = "green"
tmp_duration = str(float(row[2]) - float(row[1]))
info = str("id: ") + str(row[0]) + str(" duration: ") + tmp_duration
duration_hist.append(tmp_duration)
save_full_file = str(outputDataset_full) + str("//")+ str(row[0]).lstrip()+str("_") +str(row[1]).lstrip() + str("_").lstrip() + str(row[2]).lstrip() + str('.%(ext)s')
youtube_download(save_full_file,row[0])
except:
color = "red"
info = "File has been pass: " + str(row[0])
continue
print(termcolor.colored(info, color))
audioset_converter(outputDataset_full,outputDataset, frequency = frequency)
Для получения более детальной информации по анализу данных audioset, или выгрузки этих данных из пространства yotube в соответствии с файлом онтологии и выбранным множеством audioset, программный код располагается в свободном доступе репозитория GitHub.
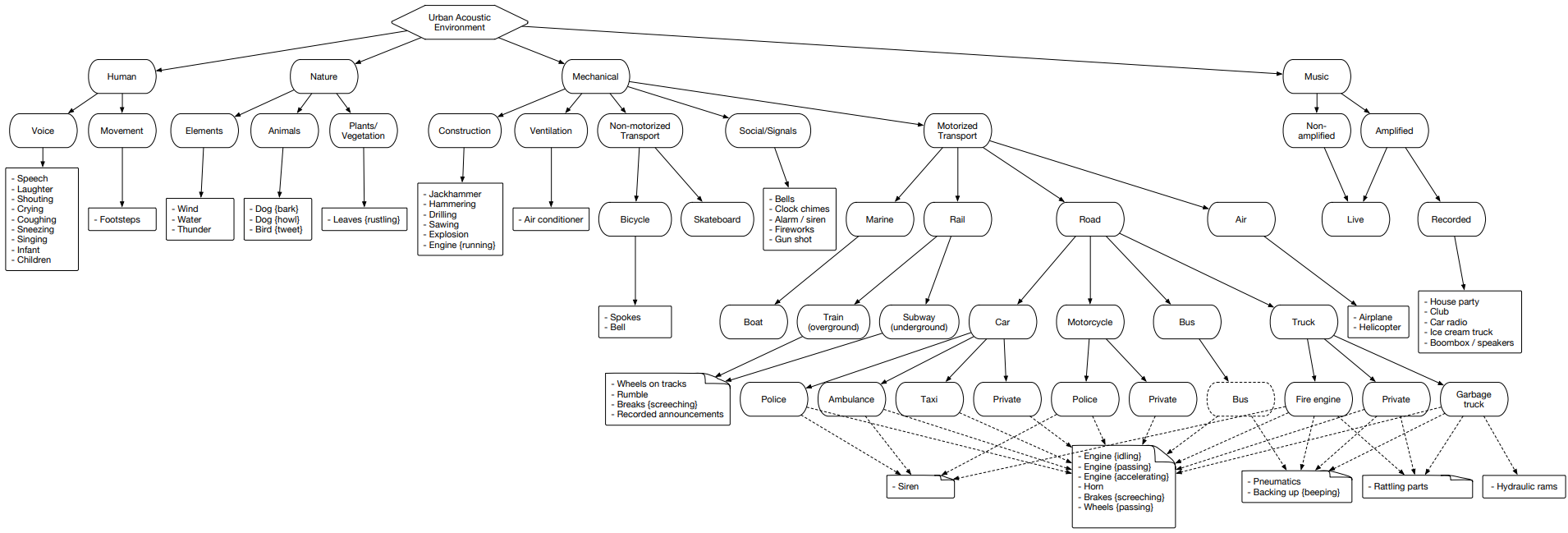
urbansound
Urbansound — это один из самых больших датасетов, с размеченными звуковыми событиями, классы которого принадлежат к городской окружающей среде. Данное множество получило название таксономическое(категориальное), т.е. каждый класс разделяется на принадлежащие ему подклассы. Такое множество можно представить в виде дерева.
Чтобы выгрузить данные urbansound для последующего использования достаточно просто перейти к ним на страницу и нажать скачать.
Так как в задаче нет необходимости использовать все подклассы, а нужен только единственный класс связанный с автомобилем, то предварительно необходимо осуществить фильтрацию необходимых классов, с использованием meta файла, расположенного в корне каталога получаемого при разархивировании скачанного файла.
После выгрузки всех необходимых данных из перечисленных источников, получилось сформировать датасет содержащий более 15000 файлов. Такой объём данных позволяет перейти к задаче обучения акустического классификатора, но остаётся не решённый вопрос касаемый “чистоты” данных, т.е. тренировочное множество включает в себя данные не относящихся к необходимым классам решаемой задачи. К примеру при прослушивании файлов из класса “разбитие стекла”, можно найти разговоры людей о том что, “как же не хорошо бить стёкла”. Следовательно перед нами возникает задача фильтрации данных и в роли инструмента решения такого рода задачи отлично подходит инструмент, ядро которого разработано белорусскими ребятами и получившее странное название “Яндекс.Толока”.
Яндекс.Толока

Яндекс.Толока — это краудфандинговый проект, созданный в 2014 году для разметки или сбора большого объёма данных для дальнейшего использования в машинном обучении. Фактически данный инструмент позволяет собирать, размечать и фильтровать данные с использованием человеческого ресурса. Да, данный проект не только позволяет решать задачи, но и позволяет другим людям заработать. Финансовое обременение в данном случае ложится на ваши плечи, но за счёт того, что со стороны исполнителей выступает более 10000 толокеров результаты работы будут получены уже в ближайшее время. Хорошее описание работы данного инструмента можно прочесть в блоге компании Яндекс.
Вообще использование толоки не представляет особой сложности, так как для публикации задания всего лишь необходима регистрация на сайте, минимальная сумма в 10 долларов США, и правильно оформленное задание. Как корректно формировать задание можно посмотреть документацию Яндекс.Толока или есть не плохая статья на Хабре. От себя к данной статье хочу добавить, что даже если шаблон подходящий под требование вашей задачи отсутствует, то его разработка займет не более нескольких часов работы, с перерывом на кофе и сигарету, а результаты исполнителей можно получить к концу рабочего дня.
Заключение
В машинном обучении при решении задачи классификации или регрессии, одной из первичных задач является разработка достоверного набора данных — датасета. В данной статье были рассмотрены источники информации с большим объёмом акустических данных позволяющих сформировать и сбалансировать необходимый набор данных под конкретную задачу. Представленный программный код позволяет упростить операцию выгрузки данных до минимума, позволяя сократить время на получение данных, его остаток потратить на разработку классификатора.
Что касается моей задачи, то после сбора данных, из всех представленных в данной статье источников и последующей фильтрации данных, удалось сформировать необходимый датасет для обучения акустического классификатора, в основе которого находится нейронная сеть. Надеюсь что данная статья позволит вам и вашей команде сэкономить время и потратить его на развитие новых технологий.
P.S. Программный модуль разработанный на языке python, для анализа и выгрузки акустических данных по каждому из представленных источников вы можете найти в хранилище github