
Чем больше разработчик работает над приложением в команде и чем лучше знает его код, тем чаще он занимается вычиткой творчества своих товарищей. Сегодня я покажу, что может быть выловлено за одну неделю в коде, написанном весьма неплохими разработчиками. Под катом собрание ярких артефактов нашего творчества (и немного моих размышлений).
Компараторы
Есть код:
@Getter
class Dto {
private Long id;
}
// another class
List<Long> readSortedIds(List<Dto> list) {
List<Long> ids = list.stream().map(Dto::getId).collect(Collectors.toList());
ids.sort(new Comparator<Long>() {
public int compare(Long o1, Long o2) {
if (o1 < o2) return -1;
if (o1 > o2) return 1;
return 0;
}
});
return ids;
}Кто-то отметит, что сортировать можно напрямую стрим, я же хочу обратить ваше внимание на компаратор. В документации к методу Comparator::compare английским по белому написано:
Compares its two arguments for order. Returns a negative integer, zero, or a positive integer as the first argument is less than, equal to, or greater than the second.
Именно это поведение и реализовано в нашем коде. Что же не так? Дело в том, что создатели явы весьма дальновидно предположили, что подобный компаратор понадобится многим и сделали его за нас. Нам же остаётся им воспользоваться упростив наш код:
List<Long> readSortedIds(List<Dto> list) {
List<Long> ids = list.stream().map(Dto::getId).collect(Collectors.toList());
ids.sort(Comparator.naturalOrder());
return ids;
}Точно так же этот код
List<Dto> sortDtosById(List<Dto> list) {
list.sort(new Comparator<Dto>() {
public int compare(Dto o1, Dto o2) {
if (o1.getId() < o2.getId()) return -1;
if (o1.getId() > o2.getId()) return 1;
return 0;
}
});
return list;
}лёгким движением руки превращается в такой
List<Dto> sortDtosById(List<Dto> list) {
list.sort(Comparator.comparing(Dto::getId));
return list;
}Кстати, в новой версии "Идеи" можно будет делать вот так:
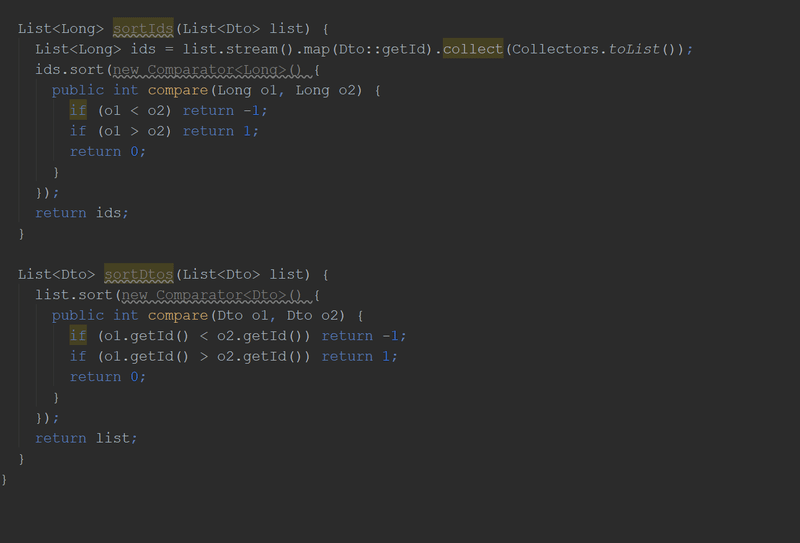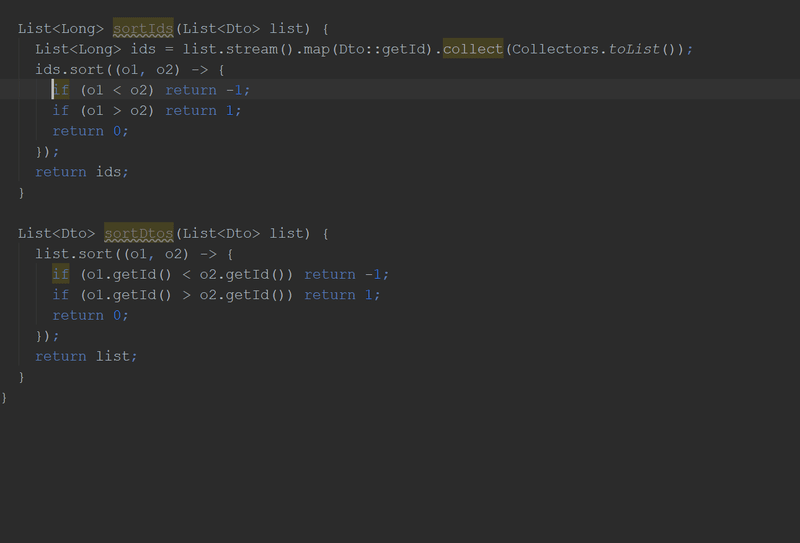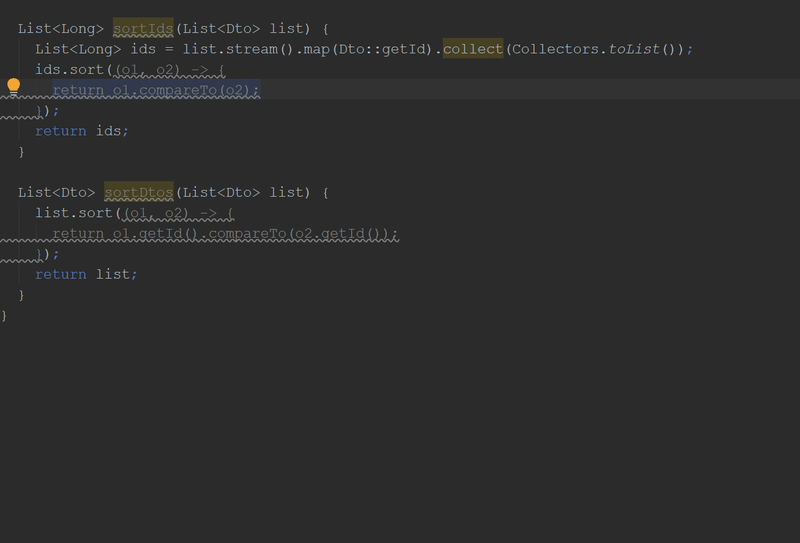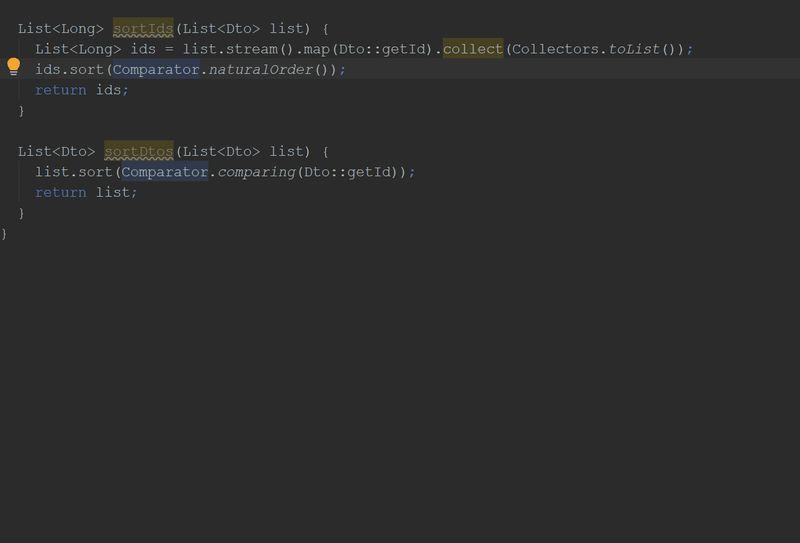
Злоупотребление Optional-ами
Наверное, каждый из нас видел что-то вроде этого:
List<UserEntity> getUsersForGroup(Long groupId) {
Optional<Long> optional = Optional.ofNullable(groupId);
if (optional.isPresent()) {
return userRepository.findUsersByGroup(optional.get());
}
return Collections.emptyList();
}Часто Optional используют для проверки наличия/отсутствия значения, хотя создан он был не для этого. Завязывайте со злоупотреблением и пишите проще:
List<UserEntity> getUsersForGroup(Long groupId) {
if (groupId == null) {
return Collections.emptyList();
}
return userRepository.findUsersByGroup(groupId);
}Помните, что Optional — это не про аргумент метода или поле, а про возвращаемое значение. Именно поэтому он спроектирован без поддержки сериализации.
void-методы, меняющие состояние аргумента
Представьте такой метод:
@Component
@RequiredArgsConstructor
public class ContractUpdater {
private final ContractRepository repository;
@Transactional
public void updateContractById(Long contractId, Dto contractDto) {
Contract contract = repository.findOne(contractId);
contract.setValue(contractDto.getValue());
repository.save(contract);
}
}Наверняка вы много раз видели и писали что-то подобное. Здесь мне не нравится, что метод меняет состояние сущности, но не возвращает её. Как ведут себя подобный методы фреймворков? Например, org.springframework.data.jpa.repository.JpaRepository::saveи javax.persistence.EntityManager::merge возвращают значение. Предположим, после обновления контракта нам нужно получить его за пределами метода update. Получается что-то вроде этого:
@Transactional
public void anotherMethod(Long contractId, Dto contractDto) {
updateService.updateContractById(contractId, contractDto);
Contract contract = repositoroty.findOne(contractId);
doSmth(contract);
}Да, мы могли бы передавать сущность напрямую в метод UpdateService::updateContract, изменив его сигнатуру, но лучше сделать вот так:
@Component
@RequiredArgsConstructor
public class ContractUpdater {
private final ContractRepository repository;
@Transactional
public Contract updateContractById(Long contractId, Dto contractDto) {
Contract contract = repository.findOne(contractId);
contract.setValue(contractDto.getValue());
return repository.save(contract);
}
}
//использование
@Transactional
public void anotherMethod(Long contractId, Dto contractDto) {
Contract contract = updateService.updateContractById(contractId, contractDto);
doSmth(contract);
}С одной стороны, это помогает упростить код, с другой — помогает при тестировании. Вообще тестирование void методов на редкость муторная задача, что я покажу, используя этот же пример:
@RunWith(MockitoJUnitRunner.class)
public class ContractUpdaterTest {
@Mock
private ContractRepository repository;
@InjectMocks
private ContractUpdater updater;
@Test
public void updateContractById() {
Dto dto = new Dto();
dto.setValue("что-то там");
Long contractId = 1L;
when(repository.findOne(contractId)).thenReturn(new Contract());
updater.updateContractById(contractId, contractDto); //void
//как проверить, что в контракт вписали значение из dto? - Примерно так:
ArgumentCaptor<Contract> captor = ArgumentCaptor.forClass(Contract.class);
verify(repository).save(captor.capture());
Contract updated = captor.getValue();
assertEquals(dto.getValue(), updated.getValue());
}
}А ведь всё можно сделать проще, если метод возвращает значение:
@RunWith(MockitoJUnitRunner.class)
public class ContractUpdaterTest {
@Mock
private ContractRepository repository;
@InjectMocks
private ContractUpdater updater;
@Test
public void updateContractById() {
Dto dto = new Dto();
dto.setValue("что-то там");
Long contractId = 1L;
when(repository.findOne(contractId)).thenReturn(new Contract());
Contract updated = updater.updateContractById(contractId, contractDto);
assertEquals(dto.getValue(), updated.getValue());
}
}Одним махом проверяется не только вызов ContractRepository::save, но и правильность сохранённого значения.
Велосипедостроение
Прикола ради, откройте свой проект и поищите вот это:
lastIndexOf('.')С большой вероятностью всё выражение выглядит примерно так:
String fileExtension = fileName.subString(fileName.lastIndexOf('.'));Вот о чём ни один статический анализатор не может предупредить, так это о вновь изобретённом велосипеде. Господа, если вы решаете некую задачу, связанную с именем/расширением файла или путём к нему, ровно как и с чтением/записью/копирование, то в 9 случаях из 10 задача уже решена до вас. Поэтому завязывайте с велосипедостроением и берите готовые (и проверенные) решения:
import org.apache.commons.io.FilenameUtils;
//...
String fileExtension = FilenameUtils.getExtension(fileName);В этом случае вы сберегает время, которое было бы потрачено на проверку годности велосипеда, а также получаете более продвинутый функционал (см. документацию FilenameUtils::getExtension).
Или вот такой код, копирующий содержимое одного файла в другой:
try {
FileChannel sc = new FileInputStream(src).getChannel();
FileChannel dc = new FileOutputStream(new File(targetName)).getChannel();
sc.transferTo(0, sc.size(), dc);
dc.close();
sc.close();
} catch (IOException ex) {
log.error("ой", ex);
}Какие обстоятельства могут нам помешать? Тысячи их:
- точка назначения может оказаться папкой, а вовсе не файлом
- источник может оказаться папкой
- источник и точка назначения могут оказаться одним и тем же файлом
- точку назначения невозможно создать
- и т. д. и т. п.
Печаль в том, что пользуясь самописью об этом всём мы узнаем уже в ходе копирования.
Если же сделаем по уму
import org.apache.commons.io.FileUtils;
try {
FileUtils.copyFile(src, new File(targetName));
} catch (IOException ex) {
log.error("ой", ex);
}то часть проверок будет выполнена ещё до начала копирования, а возможное исключение будет более информативным (см. исходники FileUtils::copyFile).
Пренебрежение @Nullable/@NotNull
Предположим, у нас есть сущность:
@Entity
@Getter
public class UserEntity {
@Id
private Long id;
@Column
private String email;
@Column
private String petName;
}В нашем случае колонка email в таблице описана как not null, в отличие от petName. Т. е. мы можем пометить поля соответствующими аннотациями:
import javax.annotation.Nullable;
import javax.annotation.NotNull;
//...
@Column
@NotNull
private String email;
@Column
@Nullable
private String petName;На первый взгляд, это выглядит как подсказка разработчику, и это действительно так. Вместе с тем эти аннотации — куда более могущественное средство, чем обычная метка.
Например, их понимают среды разработки, и если после добавления аннотаций мы попробуем сделать вот так:
boolean checkIfPetBelongsToUser(UserEnity user, String lostPetName) {
return user.getPetName().equals(lostPetName);
}то "Идея" предупредит нас об опасности таким сообщением:
Method invocation 'equals' may produce 'NullPointerException'
В коде
boolean hasEmail(UserEnity user) {
boolean hasEmail = user.getEmail() == null;
return hasEmail;
}будет другое предупреждение:
Condition 'user.getEmail() == null' is always 'false'
Это помогает встроенному цензору находить возможные ошибки и помогает нам лучше понимать исполнение кода. С той же целью аннотации полезно расставлять над методами, возвращающими значение, и их аргументами.
Если мои доводы кажутся неубедительными, то смотрите исходники любого серьёзного проекта, того же "Спринга" — они увешаны аннотациями как новогодняя ёлка. И это не блажь, а суровая необходимость.
Единственный недостаток, как мне кажется, — необходимость постоянно поддерживать аннотации в современном состоянии. Хотя, если разобраться, — это скорее благо, ведь возвращаясь раз за разом к коду мы понимаем его всё лучше.
Невнимательность
В этом коде нет ошибок, но есть излишество:
Collection<Dto> dtos = getDtos();
Stream.of(1,2,3,4,5)
.filter(id -> {
List<Integer> ids = dtos.stream().map(Dto::getId).collect(toList());
return ids.contains(id);
})
.collect(toList());Непонятно, зачем создавать новый список ключей, по которому выполняется поиск, если он не меняется при проходе по стриму. Хорошо, что элементов всего 5, а если их будет 100500? А если метод getDtos вернёт 100500 объектов (в списке!), то какая производительность будет у этого кода? Никакая, поэтому лучше вот так:
Collection<Dto> dtos = getDtos();
Set<Integer> ids = dtos.stream().map(Dto::getId).collect(toSet());
Stream.of(1,2,3,4,5)
.filter(ids::contains)
.collect(toList());Также и здесь:
static <T, Q extends Query> void setParams(
Map<String, Collection<T>> paramMap,
Set<String> notReplacedParams,
Q query) {
notReplacedParams.stream()
.filter(param -> paramMap.keySet().contains(param))
.forEach(param -> query.setParameter(param, paramMap.get(param)));
}Очевидно, что значение, возвращаемое выражение inParameterMap.keySet() неизменно, поэтому его можно вынести в переменную:
static <T, Q extends Query> void setParams(
Map<String, Collection<T>> paramMap,
Set<String> notReplacedParams,
Q query) {
Set<String> params = paramMap.keySet();
notReplacedParams.stream()
.filter(params::contains)
.forEach(param -> query.setParameter(param, paramMap.get(param)));
}Кстати, такие участки можно вычислить используя проверку 'Object allocation in a loop'.
Когда статический анализ бессилен
Восьмая ява давно отгремела, но все мы любим стримы. Некоторые из нас любят их так сильно, что используют повсюду:
public Optional<EmailAdresses> getUserEmails() {
Stream<UserEntity> users = getUsers().stream();
if (users.count() == 0) {
return Optional.empty();
}
return users.findAny();
}Стрим, как известно, свеж до вызова на нём завершения, поэтому повторное обращение к переменной users в нашем коде приведёт к IllegalStateException.
Статические анализаторы пока не умеют сообщать о таких ошибках, поэтому ответственность за их своевременное вылавливание ложится на ревьюера.
Мне кажется, что использование переменных типа Stream, равно как их передача в качестве аргументов и возврат из методов, похоже на хождение по минному полю. Может повезти, а может и нет. Отсюда простое правило: любое появление Stream<T> в коде должно проверяться (а по-хорошему сразу же выпиливаться).
Простые типы
Многие уверены, что boolean, int и т. п. — это только про производительность. Отчасти это так, но кроме того простой тип not null по умолчанию. Если целочисленное поле сущности ссылается на колонку, которая объявлена в таблице как not null, то имеет смысл использовать int, а не Integer. Это своего рода комбо — и потребление памяти ниже, и код упрощается ввиду ненужности проверок на null.
На этом всё. Помните, что всё вышеперечисленное не является истиной в последней инстанции, думайте своей головой и осмысленно подходите к применению любых советов.
Комментарии (22)

ris58h
24.10.2018 14:06+1Collection<Dto> dtos = getDtos(); Set<Integer> ids = dtos.stream().map(Dto::getId).collect(toSet()); Stream.of(1,2,3,4,5) .filter(ids::contains) .collect(toList());
Я, может, чего не понял, но, вроде, задача — получить те id, что есть в списке (1,2,3,4,5). Зачем тогда собирать в Set id-шники из DTO (их же может быть 100500), когда можно взять Set.of(1,2,3,4,5) и бежать по списку DTO?
bystr1k
24.10.2018 14:54+1Мне кажется, автор имел в виду про то, что надо выносить инварианты из циклов. Это просто как показательный пример
PqDn
24.10.2018 14:58Имелось ввиду, что можно написать эффективней, например так
Set<Integer> search = Set.of(1,2,3,4,5); dtos.stream() .map(Dto::getId) .filter(search::contains) .distinct() .collect(toList())
valery1707
24.10.2018 15:08А вот ваш исходный
List<UserEntity> getUsersForGroup(Long groupId) { Optional<Long> optional = Optional.ofNullable(groupId); if (optional.isPresent()) { return userRepository.findUsersByGroup(optional.get()); } return Collections.emptyList(); }
я бы преобразовал в
List<UserEntity> getUsersForGroup(Long groupId) { return Optional .ofNullable(groupId) .map(userRepository::findUsersByGroup) .orElseGet(Collections::emptyList); }
вместо вашего варианта:
List<UserEntity> getUsersForGroup(Long groupId) { if (groupId == null) { return Collections.emptyList(); } return userRepository.findUsersByGroup(groupId); }tsypanov Автор
24.10.2018 15:18Тоже вариант, только в этом случае
orElseGetне даёт преимущества передorElse, т. к.Collections.emptyList()возвращает кэшированный список.valery1707
24.10.2018 15:28В случае с
orElseметодCollections.emptyList()будет вызван в любом случае был ли у насnullна входе или нет, а в случае сorElseGetв него будет переданmethod referenceкоторый будет вызван только при необходимости.
Это алгоритмическая разница. Есть ли разница в производительности — я не измерял, и возможноorElse(Collections.emptyList())будет даже эффективнееorElseGet(Collections::emptyList).
Но тут вопрос в том как будет в дальнейшем использоваться результат выполненияgetUsersForGroup— ведь коллекцию, полученную изCollections.emptyList(), нельзя модифицировать. А если нам нужна такая возможность, тоorElseGe(Collections::emptyList)можно заменить наorElseGet(ArrayList::new)и тут уже будет явный профит, по сравнению сorElse(new ArrayList())tsypanov Автор
24.10.2018 16:11По поводу дальнейшего использования, я тут посмотрел внутрь
org.springframework.data.jpa.repository.support.SimpleJpaRepository, там есть такой метод
public List<T> findAll(Iterable<ID> ids) { if (ids == null || !ids.iterator().hasNext()) { return Collections.emptyList(); } if (entityInformation.hasCompositeId()) { List<T> results = new ArrayList<T>(); for (ID id : ids) { results.add(findOne(id)); } return results; } ByIdsSpecification<T> specification = new ByIdsSpecification<T>(entityInformation); TypedQuery<T> query = getQuery(specification, (Sort) null); return query.setParameter(specification.parameter, ids).getResultList(); }
В текущем виде возможны два случая, когда возвращается пустой список: 1) на вход пришла пустая коллекция ключей и 2) запрос вернул пустую выборку.
Так вот в первом случае возвращается неизменяемый список, а во втором —
ArrayList.valery1707
24.10.2018 17:14Если точнее, то реализация
SimpleJpaRepository#findAll(java.lang.Iterable<ID>)возвращает разные типы коллекций, в зависимости от значения аргумента и структуры сущности:
null:java.util.Collections.EmptyList- пустая коллекция:
java.util.Collections.EmptyList - сущность имеет композитный ключ:
java.util.ArrayListиз всех результатовSimpleJpaRepository#findOne(ID) - сущность с некомпозитным ключом: то что вернёт ниже лежащий уровень, в случае с
Hibernateэто:
java.util.Collections.EmptyList: не совсем ясно когда это возможно, но вorg.hibernate.internal.SessionImpl#list(java.lang.String, org.hibernate.engine.spi.QueryParameters)есть такой флоу — не уверен на сколько он реалистиченjava.util.ArrayList: если дело дошло до выполнения запроса
Это можно представить в виде двух ответов на вопрос
нужно ли реально выполнять запрос на БД:
нет:java.util.Collections.EmptyListи хватит с васда:java.util.ArrayList
и опять же — никакой магии.
valery1707
24.10.2018 15:13А вот тут
try { FileChannel sc = new FileInputStream(src).getChannel(); FileChannel dc = new FileOutputStream(new File(targetName)).getChannel(); sc.transferTo(0, sc.size(), dc); dc.close(); sc.close(); } catch (IOException ex) { log.error("ой", ex); }
, кроме всего уже описанного, можно не закрыть один и даже оба канала, что чревато всякими бяками.
И, в случае отсутствия библиотечных функций, для таких вещей, как минимум, необходимо использоватьtry-with-resources. Благо он появился уже очень давно.
valery1707
24.10.2018 15:16А вот тут
static <T, Q extends Query> void setParams( Map<String, Collection<T>> paramMap, Set<String> notReplacedParams, Q query) { Set<String> params = paramMap.keySet(); notReplacedParams.stream() .filter(params::contains) .forEach(param -> query.setParameter(param, paramMap.get(param))); }
нет необходимости в отдельной переменной, так как вместо
params::containsможно сделать сразуparamMap.keySet()::contains.
P.S.
А ещё этот тот самыйvoid-метод меняющий состояние аргумента.
dskozin
Вот вопрос, а что возвращает
когда ни одного пользователя не найдено?
peresada
какой-то странный вопрос… Очевидно, если в группе нет пользователей, то возвращает нулл\пустой список
tsypanov Автор
В Spring Data запросы вида
возвращают пустой список (
ArrayList) для пустой выборки.valery1707
Так делает, на сколько я помню, не сам Spring Data, но и вообще любой ORM-маппинг, да и вообще чистый JDBC.
tsypanov Автор
Про чистый JDBC не скажу, а Hibernate возвращает пустой список (ЕМНИП, пустой
ArrayList).valery1707
Да, я как раз про это: все возвращают пустую коллекцию если запрос вернул 0 записей.
В том смысле что ответ на исходный вопрос
пустая коллекция, но не потому что так делает Spring Data, а потому что так делают все и всегда и нет причин по которым кто-то будет отдавать что-то другое кроме пустой коллекции.Возможно dskozin предположил что
UserRepository#findUsersByGroupможет возвращатьnullпо аналогии с методами возвращающими одиночный объект. Но тут как раз все нормально: если мы не можем найти объект, то представлением пустого результата будет как разnullза неимением лучшего варианта. А для коллекций пустой result set запроса это пустая коллекция.Если перевести все запросы возвращающие одиночный объект на
Optional<T>то там тоже можно избавиться отnull.Вот это как раз умеет Spring Data.
dskozin
Да. Как раз это я и имел ввиду, предполагая что ответ возможно необходимо обработать. И вообще как-то не совсем синхронное ощущение от этого метода, поскольку есть и прямой возврат пустой коллекции и возврат чего-то, что возвращает репозиторий, а его возврат в свою очередь зависит от магии и т.п. Т.е. получается, что если меняется тип возвращаемого значения, то его нужно менять в двух местах…
tsypanov Автор
По поводу двойственного ощущения я ниже оставил комментарий про `SimpleJpaRepository::findAll`.
valery1707
Вы сейчас о чём?
Во всех вариантах метода
getUsersForGroupтип (UserEntity) упоминается 1 раз — в джеренике на возвращаемом листе. Ну и ещё раз он, естественно присутствует в дженерике листа уUserRepository#findUsersByGroup.Да, это два места. Но если мы меняем название класса сущности то, естественно, в обоих местах его и нужно будет сменить.
И я не понимаю как вопрос
а что возвращает getUsersForGroup(Long) когда ни одного пользователя не найдено?превратился весли меняется тип возвращаемого значения, то его нужно менять в двух местах?Где там магия?
nullкакпользователи без группы)null: пустая коллекция, так как мы сразу и заранее знаем что нет таких пользователейnull: запрос в БД, который всегда возвращает коллекциюВ результате метод всегда возвращает коллекцию и никогда
null.По факту на метод можно (и нужно, раз уж они упоминаются в статье) добавить аннотацию
@Nonnull.Опять же на счёт магии запроса к БД: нет там магии.
Мы выполняем запрос в БД вида (упрощённо)
SELECT * FROM user WHERE group_id = ?и этот запрос, при любом значении параметра, любоая БД обработает одинаково и без магии — вернёт коллекцию строк подходящих под наше условие. И да, в некоторых случаях эта коллекция может быть пустой и это нормально.