
Почему некоторыми API удобнее пользоваться, чем другими? Что мы как фронтендеры можем сделать на своей стороне, чтобы работать с API приемлемого качества? Сегодня я расскажу читателям Хабра как о технических вариантах, так и об организационных мерах, которые помогут фронтендерам и бэкендерам найти общий язык и наладить эффективную работу.

Этой осенью Яндекс.Маркету исполняется 18 лет. Все это время развивается партнерский интерфейс Маркета. Если кратко, то это админка, с помощью которой магазины могут загружать каталоги, работать с ассортиментом, следить за статистикой, отвечать на отзывы и т.д. Специфика проекта такова, что приходится очень много взаимодействовать с различными бэкендами. При этом данные не всегда можно получить в одном месте, из одного конкретного бэкенда.
Симптомы проблемы
Итак, представьте, появилась какая-то задача. Менеджер идет с задачей к дизайнерам — они рисуют макет. Потом он идет к бэкендерам — они делают какие-то ручки и на внутренней вики пишут список параметров и формат ответа.
Потом менеджер идет к фронтендеру со словами «я тебе API принес» и предлагает все по-быстрому заскриптовать, т. к., по его мнению, почти вся работа уже сделана.
Вы смотрите на документацию и видите это:
№ | Имя параметра
----------------------
53 | feed_shoffed_id
54 | fesh
55 | filter-currency
56 | showVendorsНе замечаете ничего странного? Camel, Snake и Kebab Case в рамках одной ручки. Я уже не говорю про параметр fesh. Что вообще такое fesh? Такого слова даже не существует. Попробуйте догадаться до того, как раскроете спойлер.
Fesh — это фильтр по ID магазина. Можно передать несколько айдишников через запятую. Перед ID может идти знак минус, что означает, что надо исключить этот магазин из результатов.
При этом из JavaSctipt'а, понятное дело, я не могу получить доступ к свойствам такого объекта через точечную нотацию. Не говоря уже о том, что если у вас больше 50 параметров у одного плейса, то, очевидно, вы в своей жизни повернули куда-то не туда.
Вариантов неудобного API очень много. Классический пример — API осуществляет поиск и возвращает результаты:
result: [
{id: 1, name: 'IPhone 8'},
{id: 2, name: 'IPhone 8 Plus'},
{id: 3, name: 'IPhone X'},
]
result: {id: 1, name: 'IPhone 8'}
result: nullЕсли товары найдены — получаем массив. Если найден один товар, то получаем объект с этим товаром. Если ничего не найдено, то в лучшем случае получаем null. В худшем случае бэкенд отвечает 404 или вообще 400 (Bad Request).
Бывают ситуации проще. Например, вам нужно получить список магазинов в одном бэкенде, а параметры магазина — в другом. В каких-то ручках данных не хватает, в каких-то данных слишком много. Фильтровать все это на клиенте или делать множественные аякс-запросы — плохая идея.
Итак, какие могут быть пути решения этой проблемы? Что мы как фронтендеры можем сделать на своей стороне, чтобы работать с API приемлемого качества?
Бэкенд для фронтенда
Мы в партнерском интерфейсе используем на клиенте React/Redux. Под клиентом лежит Node.js, который делает много вспомогательных вещей, например прокидывает на страницу InitialState для Редакса. Если у вас сервер-сайд рендеринг, не важно с каким клиентским фреймворком, скорее всего, он рендерится нодой. А что, если пойти на шаг дальше и не обращаться с клиента напрямую в бэкенд, а сделать свое проксирующее API на ноде, максимально заточенное под клиентские нужды?
Эту технику принято называть BFF (Backend For Frontend). Впервые этот термин ввел SoundCloud в 2015 году, и схематично идею можно изобразить в таком виде:
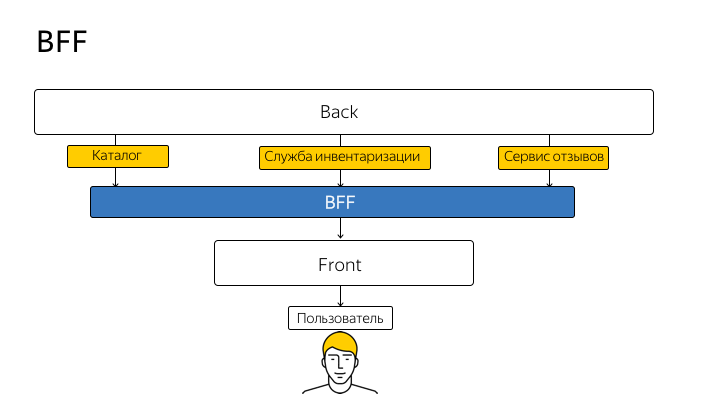
Таким образом, вы перестаете с клиентского кода ходить напрямую в API. Каждую ручку, каждый метод реального API вы дублируете на ноде и с клиента ходите исключительно на ноду. А нода уже проксирует запрос в реальное API и возвращает вам ответ.
Это касается не только примитивных get-запросов, а вообще всех запросов, в том числе с multipart/form-data. Например, магазин через форму на сайте загружает .xls-файл со своим каталогом. Так вот, в этой реализации каталог загружается не напрямую в API, а в вашу нодовскую ручку, которая проксирует stream в настоящий бэкенд.
Помните тот пример с result-ом, когда бэкенд возвращал null, массив или объект? Теперь мы можем привести его к нормальному виду — чему-нибудь вроде такого:
function getItems (response) {
if (isNull(response)) return []
if (isObject(response)) return [response]
return response
}Этот код выглядит ужасно. Потому что он ужасен. Но нам все равно нужно это сделать. У нас выбор: делать это на сервере или на клиенте. Я выбираю сервер.
Также мы можем мапить все эти кебаб- и снейк-кейсы в удобный нам стиль и тут же проставлять значение по умолчанию в случае необходимости.
query: {
'feed_shoffer_id': 'feedShofferId',
'pi-from': 'piFrom',
'show-urls': ({showUrls = 'offercard'}) => showUrls,
}Какие еще плюсы мы получаем?
- Фильтрация. Клиент получает только то, что ему нужно, ни больше ни меньше.
- Агрегация. Не нужно тратить клиентскую сеть и батарею, чтобы делать множественные аякс-запросы. Заметный выигрыш по скорости за счет того, что открытие соединения — это дорогая операция.
- Кэширование. Ваш повторный агрегированный вызов не будет лишний раз никого дергать, а просто вернет 304 Not Modified.
- Сокрытие данных. Например, у вас могут быть токены, которые нужны между бэкендами и не должны попадать на клиент. У клиента может не быть прав даже знать о существовании этих токенов, не говоря уже об их содержимом.
- Микросервисы. Если у вас на бэке монолит, то BFF — это первый шаг к микросервисам.
Теперь о минусах.
- Повышение сложности. Любая абстракция — это еще один слой, который необходимо кодить, деплоить, поддерживать. Еще одна движущаяся часть механизма, которая может сбоить.
- Дублирование ручек. Например, несколько ендпойнтов могут выполнять один и тот же тип агрегаций.
- BFF — это пограничный слой, который должен поддерживать общую маршрутизацию, ограничения прав пользователей, ведение журнала запросов и т. д.
Чтобы нивелировать эти минусы, достаточно придерживаться простых правил. Первое — разделять интерфейсную и бизнес-логику. Ваш BFF не должен менять бизнес-логику основного API. Второе — ваша прослойка должна преобразовывать данные только в случае крайней необходимости. Мы говорим не о самодостаточном всеохватывающем API, а только о проксе, которая заполняет пробел, исправляя недостатки бэкенда.
GraphQL
Похожие проблемы решает GraphQL. С GraphQL вместо множества «глупых» endpoint у вас одна умная ручка, которая умеет работать со сложными запросами и формировать данные в том виде, в котором их запрашивает клиент.
При этом GraphQL может работать поверх REST, т. е. источником данных служит не база, а рестовое API. За счет декларативности GraphQL, за счет того, что все это дружит с Реактом и Редаксом, ваш клиент становится проще.
На самом деле, GraphQL мне видится реализацией BFF со своим протоколом и строгим языком запросов.
Это отличное решение, но у него есть несколько недостатков, в частности, с типизацией, с разграничением прав, и в целом это относительно свежий подход. Поэтому мы на него пока не перешли, но в перспективе это кажется мне самым оптимальным способом создания API.
Best Friends Forever
Ни одно техническое решение не будет правильно работать без организационных изменений. Вам все равно нужна документация, гарантии того, что формат ответа внезапно не изменится и т. д.
При этом нужно понимать, что все мы в одной лодке. Абстрактному заказчику, будь то менеджер или ваш руководитель, по большому счету без разницы — GraphQL у вас там или BFF. Ему важнее, чтобы задача была решена и на проде не всплывали ошибки. Для него нет особой разницы, по чьей вине возникла ошибка в проде — по вине фронта или бэка. Поэтому нужно договариваться с бэкендерами.
К тому же изъяны бэка, о которых я говорил в начале доклада, не всегда возникают из-за чьих-то злонамеренных действий. Вполне возможно, что и у параметра fesh есть какой-то смысл.

Обратите внимание на дату коммита. Получается совсем недавно fesh отметил свое семнадцатилетие.
Видите какие-то странные идентификаторы слева? Это SVN, просто потому что в 2001 году гита не было. Не гитхаба как сервиса, а именно гита как системы управления версиями. Он появился только в 2005 году.
Документация
Итак, все, что нам нужно — не ссориться с бэкендерами, а договориться. Это можно сделать только если мы найдем один единственный источник правды. Таким источником должна быть документация.
Самое главное здесь — написать документацию до того, как мы начнем работать над функциональностью. Как с брачным договором, лучше обо всем договориться на берегу.
Как это работает? Условно говоря, собираются трое: менеджер, фронтендер и бэкендер. Фронтедер хорошо разбирается в предметной области, поэтому его участие критически важно. Они собираются и начинают думать над API: по каким путям, какие ответы должны возвращаться, вплоть до названия и формата полей.
Swagger
Хороший вариант для документации API — формат Swagger, сейчас он называется OpenAPI. Лучше использовать Swagger в YAML-формате, т. к., в отличие от JSON, он лучше читается человеком, а для машины разницы нет.
В итоге все договоренности фиксируются в Swagger-формате и публикуются в общий репозиторий. Документация на продовый бэкенд должна лежать в мастере.
Мастер защищен от коммитов, код в него попадает только через пул реквесты, пушить в него нельзя. Представитель фронт-команды обязан проводить ревью пул реквеста, без его апрува код в мастер не едет. Это защищает вас от неожиданных изменений API без предварительного уведомления.
Итак, вы собрались, написали Swagger, таким образом фактически подписали контракт. С этого момента вы как фронтендер можете начинать свою работу, не дожидаясь создания реального API. Ведь в чем был смысл разделения на клиент и сервер, если мы не можем работать параллельно и клиентским разработчикам приходится ждать серверных разработчиков? Если у нас есть «контракт», то мы можем спокойно параллелить это дело.
Faker.js
Для этих целей отлично подходит Faker. Это библиотека для генерации огромного количества фейковых данных. Она умеет генерировать разные типы данных: даты, имена, адреса и т. д., все это хорошо локализуется, есть поддержка русского языка.
При этом фейкер дружит со свагером, и вы можете спокойно поднять моковый сервер, который на основе Swagger-схемы будет генерировать вам фейковые ответы по нужным путям.
Валидация
Swagger можно сконвертировать в json-схему, и с помощью таких инструментов как ajv вы можете прямо в рантайме, в своем BFF, валидировать ответы бэкендов и в случае расхождений репортить тестировщикам, самим бэкендерам и т. д.
Допустим, тестировщик находит на сайте какой-то баг, например при клике на кнопку ничего не происходит. Что делает тестировщик? Ставит тикет на фронтендера: «это ведь ваша кнопка, вот она не нажимается, чините».
Если между вами и бэком стоит валидатор, то тестировщик будет знать, что кнопка на самом деле нажимается, просто бэкенд присылает неправильный ответ. Неправильный — это такой ответ, который фронт не ожидает, т. е. не соответствующий «контракту». И тут уже надо или чинить бэк или менять контракт.
Выводы
- Принимаем активное участие в проектировании API. Проектируем API так, чтобы им было удобно пользоваться через 17 лет.
- Требуем Swagger-документацию. Нет документации — работа бэка не выполнена.
- Есть документация — публикуем ее в git, при этом любые изменения в интерфейсе API должны апрувиться представителем фронт-команды.
- Поднимаем фейковый сервер и начинаем работать над фронтом не дожидаясь реального API.
- Кладем ноду под фронтенд и валидируем все ответы. Плюс получаем возможность агрегировать, нормализовать и кэшировать данные.
См. также
> Как построить REST-like API в крупном проекте
> Backend In the Frontend
> Using GraphQL as BFF Pattern Implementation
Комментарии (36)

Druu
01.11.2018 12:47Симптомы проблемы
Это симптомы алкоголизма или наркомании у того, кто пишет такое апи. На лечение отправьте.
Итак, какие могут быть пути решения этой проблемы? Что мы как фронтендеры можем сделать на своей стороне, чтобы работать с API приемлемого качества?
шаг 1: требование от человека, который "апи принес", предоставлять следующий раз нормальное апи
шаг 2: если шаг 1 не оказался успешным — обращение к начальству с требованием разобраться
шаг 3: если шаг 2 не оказался успешным, увольняться нафиг
eugef
01.11.2018 13:15Спасибо за интересную статью. Мы тоже используем BFF, поэтому интересно узнать ваше мнение.
— Как вы тестируете соответствие ответа бэкенд АПИ и его Swagger документации? Каки-либо контракт-тесты используете?
— Как часто валидация ответа по JSON-схеме помогало находит ошибки на проде?
— Валидация синхронная, не было у вас проблем с блокированием event-loop при валидации большого ответа?ngOo Автор
01.11.2018 21:57+1– После каждого релиза бэкендеров мы гоняем тесты на соответствие ответов API и Swagger-документации. Данные для формирования запросов берем из самого свагера, обычно это поле x-example.
– Валидация ответов в продакшене очень редко находит баги, т.к. есть несколько ступеней защиты.
Во-первых, после каждого релиза бэкенда надо снапшотить Swagger-схему и проверять, что новая схема является надмножеством старой (дорелизной) схемы. Таким образом мы можем удостовериться, что релиз бэкенда не имеет ломающих изменений, а если имеет, то мы к ним готовы.
Во-вторых, из Swagger’а можно генерировать Flow-типы и смотреть не ругается ли Flow на ваш код.
– Мы утешаем себя тем, что ajv очень быстрый, плюс у нас куча инстансов ноды, балансер и все такое.
Но если это становится проблемой, то можно отключить (полностью или частично) валидацию в проде, оставить только в престейбле.
bayarsaikhan
01.11.2018 17:33+3Спасибо, полезная статья. За линк на валидатор схем — отдельное спасибо, ибо это больной вопрос.

ODware
01.11.2018 19:40При этом фейкер дружит со свагером, и вы можете спокойно поднять моковый сервер, который на основе Swagger-схемы будет генерировать вам фейковые ответы по нужным путям.
улыбнуло предложение :)
springimport
01.11.2018 20:10У вас была задача на добавление/обновление множества элементов? Расскажите как ее решили.
Moxa
01.11.2018 20:53+2год назад начали писать новый проект, решили сделать api на основе вебсокетов, два типа запросов: по айдишнику или коллецией. Получилось очень удобно, фронтенд грузит все, показывает как ему удобно, не нужно на каждую хотелку менять апи, за год только dto потолстели чуток. Я прям народоваться не могу такому подходу
MZintchenko
01.11.2018 21:17В целом при разработке api мы пляшем от нужд фронта, что в общем-то логично, так что описанные проблемы для нас не так актуальны.
Мы используем swagger-codegen для гарантии того, что бэкенд формирует правильный ответ. К сожалению, в openapi 2.0 есть целый класс вещей, которые невозможно реализовать, а фронтенд их очень хочет, так что многие вещи приходится делать нелегально. Например, сущность или массив в query параметре.
Кое-что было поправлено в openapi 3.0, но с ним своя беда. Во-первых, отвратительная поддержка тулзами. Тот же openapi-codegen хотя формально и поддерживает новую спеку, ужасно забагован и для продакшена пока не годится. Во-вторых, openapi 3.0 по формату очень не похож на openapi 2.0. Это может и не страшно для маленьких api, но у нас есть спеки по ~12 тысяч строк, которые грамотно отконвертить тоже будет непросто.
Так что у нас в основном проблема именно с фронтом — было бы приятно, если бы фронт не мог отправить неправильный запрос. Нет ли у кого опыта привязывания валидатора запросов на фронте? Пусть не для прода, это как раз интереснее в момент изолированной разработки фронта.ngOo Автор
01.11.2018 21:21Наш BFF валидирует не только ответы с бэка, но и все запросы с фронта. Если запрос невалидный, то BFF не пустит его на «настоящий» бэкенд, а вернет 400.
funca
01.11.2018 23:11Какие библиотеки и фреймворки вы порекомендуете использовать для реализации подхода и что придется кодить самим?
Spiceman
01.11.2018 23:41-1Какие-то очевидные вещи описаны. Начал делать веб-приложение с нуля год назад. Серверная часть уже существовала лет 15. Сделал прокси как раз для этих очевидных вещей типа агрегации запросов и т.д. Прокси на .net. Свагером генерю сразу клиента на тайпскрипте. Детский сад.
l27_0_0_1
02.11.2018 01:15Только в яндексе могут написать статью, используя специфичный сленг («ручки») и вместо того чтобы инлайн пояснить — сделать ссылку на стековерфлоу где поясняют что это специфичный яндексовый сленг и что он означает.
FreeBa
02.11.2018 02:18+1Имхо, Яндекс это такая компания, которая может только в крайности. Либо примитивы из костылей и велосипедов, либо махровый оверинжиринг (приготовление кофе и отправка космонавтов на луну прилагаются). Этим многие страдают, тот же фб, например. Но как то странно, что крупная компания не может делать сбалансированные, универсальные решения (да-да, работать с яндексом вне инструментария обозначенного в доках — лютейший ад, этот факт упорно не проникает в головы маркетологов).
bevalorous
02.11.2018 10:20+1Из-за чего вообще возникла насущная потребность в BFF? Команда, пишущая бэк, полностью оторвана от команды, пишущей фронт? Почему бэкэнд сразу не пишется так, чтобы фронтэндерам не было больно при интеграции? Где элементарные правила, которых должны придерживаться разработчики бэка и которыми можно сильно ударить по пальцам бэкэндера, который:
- извращается с регистром полей в ответе (можно не любить конкретно underscored_case, например, но правила есть правила, единообразие важнее творческого самовыражения и личного мнения! в конце концов, командная работа же!);
- извращается с форматом возвращаемого результата (массив, объект или null как результат ответа на один и тот же запрос, который возвращает список — серьезно? как такого на работу взяли?);
- не пишет документацию по своим API (как минимум: имя, тип, текстовое описание каждого параметра запроса и поля в ответе + пример реального запроса и реального ответа на такой запрос).
То есть бэкэндеры у вас пишут как Б-г на душу положит, а фронтэндерам, чтобы как-то интегрировать в клиентскую часть это «творчество», приходится писать целую обертку (BFF), которая более или менее скрывает за собой всю убогость, несогласованность и противоречивость бэка? Я правильно понял?polar11beer
02.11.2018 13:00+1Команда, пишущая бэк, полностью оторвана от команды, пишущей фронт? Почему бэкэнд сразу не пишется так, чтобы фронтэндерам не было больно при интеграции?
1. BFF позволяет при необходимости менять бэк, не трогая при этом фронт. Бывает удобнее и надёжнее, чем на каждый чих просить фронтендеров делать соответствующие изменения.
2. Если у компании несколько проектов, то новые проекты могут использовать существующие сервисы на бэке, и шарить их с другими проектами. Тут уже так просто бэком не покомандуешь.Druu
02.11.2018 13:12+2То, что вы описали — это вполне разумные причины использования BFF, но в статье же предлагается использовать BFF для того чтобы вот такие какашки:
53 | feed_shoffed_id
54 | fesh
55 | filter-currency
56 | showVendorsПревращать во что-то вменяемое. Вы тоже считаете, что для исполнения в команде бекенда базовых правил культуры и вежливости надо применять BFF, а не административные методы?
Это примерно как если некий человек постоянно матерится на митингах, рассказывает как мам коллег на свидание водил и т.п. вещи, а в качестве решения — давайте приобретем такой девайс, который при произнесении данным человеком определенных ключевых фраз будет пищалку включать, чтоб не слышно было.
polar11beer
02.11.2018 14:26но в статье же предлагается использовать BFF для того чтобы вот такие какашки: Превращать во что-то вменяемое.
С такого ракурса использование BFF действительно выглядит избыточно. Либо как жест отчаяния, когда достучаться не получается, а делать надо.
funca
02.11.2018 22:34В высоконагруженных системах часто выгоднее отдать данные быстро и компактно, нежели медленно и удобно для конкретного приложения. Поэтому бекенды вольны в выборе формата. А фронтенд подстраивается и собирает как ему нужно.
Второй момент в том, что требования к фронтендам меняются значительно чаще, их проще масшабировать и стоимость ошибки ниже. Поэтому трогать бэкенды лучше в последнюю очередь.Druu
03.11.2018 08:11+1В высоконагруженных системах часто выгоднее отдать данные быстро и компактно, нежели медленно и удобно для конкретного приложения.
И как компактность связана с тем, что в одном месте feed_shoffed_id, а в другом — filter-currency?
Поэтому бекенды вольны в выборе формата.
Конечно же свободен! Только в данном случае никакого формата нет, есть куча говна, которое бекенд вывалил под дверью у фронтенда. И если я под своей дверью вижу кучу говна, то:
- я ожидаю услышать объяснения, четкие и понятные — кто и почему навалил
- я ожидаю услышать извинения
- я уж точно не ожидаю, что предполагается, будто я его стану убирать. Кто намусорил — тот пусть за собой и прибирает.
Если же человек профнепригоден и не способен выполнять работу бекендщика — пусть увольняется нафиг.
bevalorous
02.11.2018 14:15+2Если изменения бэка не ломают совместимость (интерфейсы API, структуры данных и смысл полей) — фронт менять не нужно. А если нужно, значит совместимость (контракт) ломается. Почему не использовать версионирование API для этого? Фактически это оно и есть, но реализовано оно в BFF. То есть это такой двусторонний мультиадаптер с дополнительными функциями (кэширование, валидация и т.п.), сильно зацепленный и на фронт, и на бэк.
polar11beer
02.11.2018 14:30Версионирование АПИ предполагает, что рано или поздно фронтенд всё-таки придётся дорабатывать под новую версию. Или что-то не улавливаю в Вашем ответе?
bevalorous
02.11.2018 16:17+1Не обязательно. Достаточно просто не отключать версию бэка, которая используется таким фронтом. От фронта требуется лишь сообщить, какая версия API ему нужна (или, если он не сообщает, автоматом выставить какую-то версию по умолчанию). Другое дело, что для маршрутизации на нужную версию бэка нужен какой-то промежуточный слой (сервер Nginx, например, или тот же BFF).
polar11beer
02.11.2018 17:14А, хорошо, теперь понял. Но тогда — не получаем ли мы сложности в виде двух (или, реже, нескольких) версий бэка (решающих одну задачу!), которые надо поддерживать, и которые скорее всего ходят в одну базу. То есть, теперь изменения в базе нужно делать с оглядкой на две версии бэка.
Druu
02.11.2018 20:49Ну иногда, вообще говоря, поддержка нескольких версий просто требуется и все. В таких случаях приходится с этим жить и ничего особо не сделаешь :)
RustaMechanic
02.11.2018 19:49+1Почему пользователь в самом низу на картинке BFF?!) Картинка аж давит)
Переверните пирамидку
fedorro
03.11.2018 09:27Уж не знаю где и спросить, попробую тут: Яндекс.Коннект вообще жив? Ничего не работает, поддержка не отвечает… Уже неделю не могу почту подключить, хотя операция простейшая. Во времена ПДД такого не было.
youROCK
Говорите про «без костылей», но первое же, о чем рассказываете — это о том, как написали прокси на ноде, чтобы не общаться напрямую с бэкендом. Теперь у вас становится в 2 раза больше апишек, к которым можно обращаться — «настоящий» апи для мобилок и прочего, и свой отдельный (и наверняка открытый наружу, в том числе для мобилок) апи, который «чуть-чуть отличается» и почти полностью дублирует функциональность «настоящего» апи, но делает все немного по-своему. Мне одному кажется, что это, мягко говоря, не лучшее решение?
u33er
А если бэкендов несколько? Подход хороший для определенного скоупа задач.
ngOo Автор
Апишек не становится в 2 раза больше. В 99% случаев это чистая прокся – один к одну с «настоящим» бэкендом. В редких случаях, когда batching’а недостаточно, приходится агрегировать несколько ручек. Но это не костыль, так работает REST.
И только в самом крайнем случае, когда нет других вариантов (например, это внешнее API, которое вы никак не контролируете) приходится немножко править ответ.
Zibx
А когда на это апи завяжется другое, которое тоже удумает проксировать запросы, и после этого что-то изменят в изначальном апи — отлетит всё расходящееся дерево проксей?
u33er
Почему отлетит? Все роуты документированные. Приведу на примере, есть сервис с Юзерами, и есть сервис с Постами. Что б каждый раз руками не писать http запрос на юзер сервис, или на пост сервис, делаем допустим миддлварку для Юзер префикса, которая просто редиректит запрос и хендлим респонс как хотим. Если мы моддифицируем наш респонс, то это тоже документируется. Эта прокся просто лаер между всеми микросервисами и фронтом