

Kuberneties Service
становится важным и мощным инструментом как для создания и управления Data Fabric (о котором дальше), так и для конкуренции на поле HCI систем. Ранее NetApp HCI был достаточно простым решением, работающим только с VMware, как, собственно, начинал и Nutanix. Теперь же когда появился NKS, NetApp HCI составит намного более жесткую конкуренцию Nutanix в плане Next Generation DataCenter & Next generation applications на базе контейнеров, но при этом самое интересное оставляя нишу, в которой гипервизор Nutanix, теоретически может запускаться на NetApp HCI. NetApp Kubernetes Service Demo.
HCI
Одним из первых и заслуженным HCI, который знаком многим, является Nutanix. Несмотря на то, что Nutanix очень интересный продукт, он не лишен недостатков. Самое интересное в Nutanix, на мой взгляд, внутренняя экосистема, а не архитектура хранилища. Если говорить касательно недостатков, стоит отметить, что маркетинг мог замылить некоторым инженерам глаза передавая не верный посыл, что все данные всегда находятся локально и это хорошо. В то время как у конкурентов, намекая на NetApp HCI, к данным нужно обращаться по сети, что «долго» и вообще это «не настоящий HCI», при этом не давая определения, что же является настоящим HCI, хотя его и не может быть в принципе как, например и у «Облака», которому тоже никто не берется дать определение. Потому что оно выдумано людьми для маркетинговых целей, чтобы в будущем можно было дополнять и изменять содержание этого понятия, а не для сугубо технических целей, в которых изначально у объекта всегда есть неизменное определение.
Изначально проще было войти на рынок HCI именно с архитектурой доступной массам, которую легче можно потребить, а именно просто использовать комодити сервера с набитыми дисками.
Но это далеко не значит, что это и есть определяющие свойства HCI и единый наилучший вариант HCI. Постановка задачи на самом деле породила проблему или как я уже сказал нюанс: когда вы используете storage в share-nothing архитектуре, к которой относятся Nutanix HCI на базе комодити оборудования, вам необходимо обеспечить доступность и защиту данных, для этого необходимо все записи как минимум копировать с одного сервера на другой. И когда виртуальная машина генерирует новую запись на локальный диск, всё бы было хорошо, если бы не нужно было эту запись синхронно продублировать и передать еще на второй сервер и дождаться ответа, что она находится в целости и сохранности. Другими словами, в Nutanix, да и в принципе любой share-nothing архитектуре, скорость записей плюс минус в лучшем случае равносильна тому, что эти записи были бы сразу переданы по сети на shared storage.
Главными базовыми конструктивными лозунгами HCI всегда были простота начальной установки и настройки, возможность начать из минимальной, простой и не дорогой конфигурации и расшириться до нужного размера, простота расширения/сжатия, простота управления из единой консоли, автоматизация, всё это так или иначе связано с, простотой, cloud-like experience, гибкостью и гранулярностью потребления ресурсов. А вот является ли система хранения в архитектуре HCI отдельно выделенной коробочкой или частью сервера, на самом деле архитектурно не играет большой роли для достижения этой простоты.
Резюмируя это можно сказать, что маркетинг удивительным образом ввёл в заблуждение многих инженеров, о том, что локальные диски — это всегда лучше, что не является действительностью, потому что с технической точки зрения, в отличии от маркетинга, не всё так просто. Сделав неверный вывод о том, что есть HCI архитектуры, в которых используются только локальные диски, можно сделать следующий не верный вывод, что системы хранения, подключённые по сети, будут всегда работать медленнее. Но принципы защиты информации, логика и физика в этом мире устроены таким образом что этого достичь невозможно, и от коммуникации по сети между дисковыми подсистемами в HCI инфраструктуре никуда не деться, по этому принципиальной разницы в том, будут ли диски локально вместе с компьютинг нодами или в отдельной storage ноде подключённой по сети нет. Скорее наоборот, выделенные storage ноды позволяют добиться меньших зависимостей компонент HCI друг от друга, к примеру если вы уменьшаете количество нод в HCI кластере на базе того же Nutanix или vSAN, вы автоматически уменьшает пространство в кластере. И наоборот: добавляя компьютинг ноды вы обязаны добавить и диски в этот сервер. В то время как в архитектуре NetApp HCI эти компоненты не связаны друг с другом. Плата за такую инфраструктуру отнюдь не в скорости работы дисковой подсистемы, а в том, что для старта необходимо иметь минимум 2 storage ноды и минимум 2 компьютинг ноды, итого 4 ноды. 4 ноды NetApp HCI могут быть упакованы в 2U используя половинчатые лезвия.


NetApp HCI
С покупкой SolidFire в линейке продуктов NetApp появилась HCI (у данного продукта нет собственного названия, по этому его называют просто HCI) система. Основным её отличием от “классических” HCI систем являются отдельный storage ноды, подключённые по сети. Сама же система SolidFire, которая является “стораджовой” прослойкой для HCI радикально отличается от All-Flash систем AFF, которые развилась из линейки FAS, которая в свою очередь уже около 26 лет находится на рынке. Познакомившись с ним поближе (что можете сделать и вы), становится понятно, что это продукт совсем другой идеологии, нацеленный на другой сегмент потребителей (облачных провайдеров) и идеально вписывающийся именно под их задачи, как с точки зрения производительности, отказоустойчивости, так и с точки зрения интеграции в единую экосистему биллинга.
Отжигаем на все 200 Тестирование NetApp SolidFire Артур Аликулов, Евгений Елизаров. NetApp Directions 2018.
Компания NetApp движется в облака
и давно уже перестала быть просто производителем систем хранения данных. Теперь это скорее уже облачная, дата менеджмент компания, по крайней мере они упорно движутся в этом направлении. Огромное количество тех или иных внедрений продуктов компании NetApp говорит именно об этом — SaaS backup for O365, SaaS backup for Salesforce (и планы для Google Apps, Slack & ServiceNow). ONTAP Select стал очень важным решением, самостоятельным, а не как раньше маленькой примочкой для репликации на «полноценный» FAS. NDAS всё глубже объединяет раньше, казалось бы, необъединимое – системы хранения данных и облако предоставляя резервное копирование, google-like поиск по каталогу файлов и графический интерфейс управления как услугу. FabricPool пошел ещё глубже и объединил SSD и облако, что казалось раньше не вероятным или даже сумасшедшим.
Тот только факт, что NetApp за довольно-таки короткий срок оказался в четырёх этих самых больших в мире облачных провайдерах говорит о серьёзности их намерений. Мало того NFS сервис в Azure построен исключительно на NetApp AFF системах.
Azure NetApp Files Demo.
В Azure, AWS и Google доступны системы хранения NetApp AFF как сервис, их поддержкой, обновлением и обслуживанием занимается NetApp, а пользователи облака могут потреблять пространство AFF систем и функционал снепшотирования, клонирования, QoS, как услугу. NetApp Cloud Volumes Service for AWS Demo.
В IBM Cloud используется ONTAP Select, который имеет точно такой же функционал, как и AFF системы, но используется в виде ПО который может быть установлен на комодити сервера. Active IQ это веб-портал который отображает информацию по программному обеспечению и оборудованию NetApp и даёт рекомендации по упреждению проблем и обновлению при помощи AI алгоритмов запущенных на собранной телеметрии с устройств и сервисов NetApp. NetApp Active IQ Demo.
Data Fabric
В целом, стратегия Data Fabric, которой сейчас придерживается компания NetApp как раз призвана совместить эти, совершенно разные среды: публичные и частные облака, и все продукты NetApp. Ведь мало просто запустить какой-то продукт в облаке, нужно что бы он логично и гармонично вписывался в сервисы облачных провайдеров. И на сегодняшний день NetApp это удаётся более чем успешно. Data Fabric из маркетинговой идеи плавно приобретает вполне осязаемые черты в виде отдельно взятых технологий и продуктов: FabricPool тиринг между SSD & S3, SnapMirror между ONTAP & SolidFier/HCI, SnapCenter для ONTAP & SolidFier (который еще не реализован), NDAS сервис резервного копирования данных их СХД в облако, MAX Data ПО для software defined memory, это всё продукты или фичи NetApp которые воплощают это видение Data Fabric. ONTAP Select теперь может работать на Nutanix, доставляя богатый файловый функционал в их экосистему.
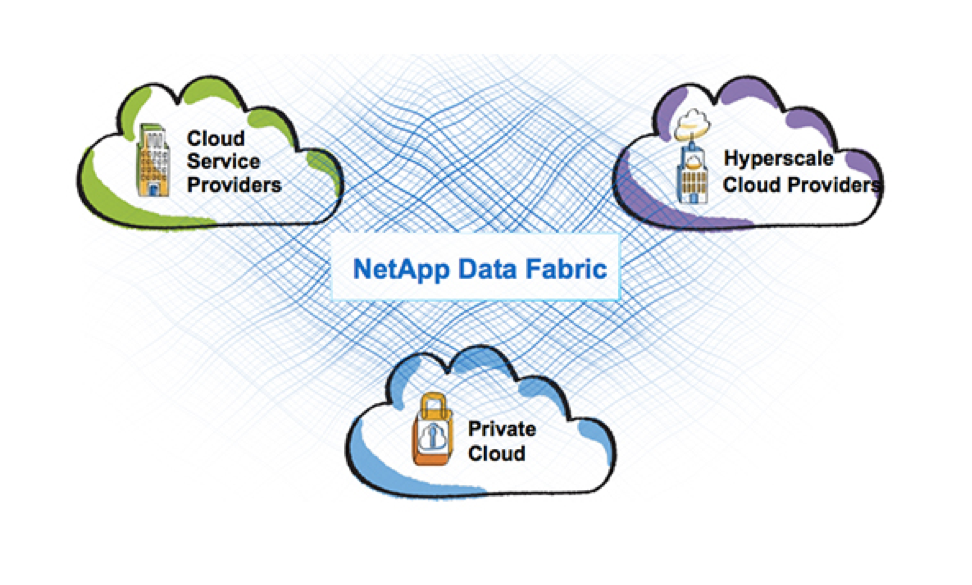
Data Fabric это от части видение процесса слияния либо интеграции всех продуктов NetApp и даже облаков, и я даже вижу не просто маркетинговое, а вполне даже физическое слияние отдельно взятых продуктов.
Мало того, я хочу сделать предсказание. Я уже несколько лет играю в эту игру на счёт предсказаний с некоторыми своими коллегами и пока что я всегда был очень близок либо угадывал ход мыслей в этой компании, посмотрим, как мне повезёт в этот раз. Хочу подчеркнуть, что это лично моё мнение, основанное на кусочках информации, полученные за все 7 лет моего опыта с NetApp и интуиции, никто из NetApp мне этого не говорил, поэтому это может быть исключительно плодом моей фантазии:
- AFF станет частью HCI
- Станет возможно мигрировать LUN в онлайне между AFF/HCI
NetApp заканчивает быть вендором СХД
может это слишком громкое название заголовка, но NetApp переходит в фазу, где компания становится data management, software defined, cloud-native оператором и по старинке по-прежнему продолжает выпускать СХД. СХД никуда не делись и не видно края тому, что это может произойти в ближайшее время, но смещается упор на облачность и на сами данные.
Данный текст написан в тесной коллаборации с Дмитрием bbk, если вы хотите знать больше о технологиях NetApp — не поленитесь поставить ему +, и новые статьи не заставят себя ждать.
Если вас интересуют новости из мира NetApp, добро пожаловать в telegram-канал StorageTalks, но а если вы ищете активное русскоязычное storage-комьюнити, приходите в telegram-чат StorageDiscussions.
Комментарии (75)

shapa
08.11.2018 13:08+1Во-первых, всем спасибо за заряд хорошего настроения этим утром.
Упоминания Nutanix с первых же слов — безусловно приятно и правильно, правильно ориентироваться на безусловного лидера рынка.
Коллегам советую-таки изучить сначала архитектуру Nutanix, затем писать статьи.
К сожалению в статье очень много маркетинга, что в целом понятно — надо выдать «недо-HCI» архитектуру (для которой уже появилась юмористическая абрревиатура FHCI — Fake Hyper Convergent Infractucture) за реальную гиперконвергенцию.
Можно даже на русском — например www.nutanixbible.ru
В целом — масса недостоверных фактов, удобных умолчаний и прочих натягиваний ужа на ежа («в которой гипервизор Nutanix, теоретически может запускаться на NetApp HCI»).
Причем тут Кубернетис / микросервисы и гипервизор Nutanix — это видно пожалуй лишь авторам статьи.
Например — «скорость записей плюс минус в лучшем случае равносильна тому» — не в лучшем, а в худшем, ибо в целом практически всегда будет быстрее (см. ниже).
По поводу пути записи / задержек (I/O latency) — есть масса нюансов, о которых в статье почему-то не упомянуто.
1) Задержки FC SAN фабрики (смотрим задержки типовых SAN коммутаторов) — существенно выше чем хорошие сетевые коммутаторы (которые имеют задержки близкие к Infiniband). А фабрику вы обязательно будете строить в случае достаточно большого кластера.
Достаточно посмотреть нано секунды задержек типовых SAN коммутаторов и сравнить со скажем Mellanox или Arista Networks.
Именно поэтому ни одна из действительно крупных компаний (уровень Google, Facebook и прочие) не использует СХД или «псевдо-HCI», но создали для себя (внутреннее использование) реальный HCI.
Собственно, те-же инженеры и создавали Nutanix DFS — это публичная и широко известная история.
Кстати, интересный момент — на СХД NetApp сидел Yahoo, который в итоге проиграл технологическую войну Гуглу. Пока одни пытались использовать традиционные технологии, другии занимались инновациями.
Хорошая статья например тут:
techcrunch.com/2016/05/22/why-google-beat-yahoo-in-the-war-for-the-internet
2) В случае операций чтения, данные читаются с локальных SSD / NVMe дисков на максимальной скорости (локализация ввода-вывода), что технически невозможно для псевдо-HCI систем уровня Netapp. Можно применять костыли (ставить локально SSD в сервера для кэширования), но это именно что костыли с массой недостатков.
3) В лучшем случае, в идеальных условиях (100% запись, отсутствие SAN фабрики / прямое включение FC портов), традиционные СХД (включая Netapp и их псевдо-HCI), лишь приблизятся по скорости работы к грамотно спроективрованным настоящим HCI.
Учитывая что в реальной жизни в большинстве случаев если чтение даже превалирует над записью, то как минимум составляет существенную часть нагрузки. Это в итоге создает существенный реальный отрыв по производительности того-же Нутаникс — как мы уже показывали, легко можем выдать 1 million IOPS в одну виртуальную машину c ультра-низкими задержками.
longwhiteclouds.com/2017/11/14/1-million-iops-in-1-vm-world-first-for-hci-with-nutanix
4) Подтверждение записи от 2-х cетевых узлов в кластере идет одновременно, никто не ждет «сначала один потом другой».
5) Говорить про Netapp / Soliчdfire как нормальное решение в 2018 году — откровенно удивило.
Для наводки — максимальный размер LUN дл Netapp FHCI — 16TB. На дворе — 2019 год.
Говорить о том что в Nutanix нет LUN как таковых, а storage pool / container может быть петабайты — думаю смысла нет.Smasher
08.11.2018 13:57+1Достойный комментарий, жаль, что половину его можно было не писать, если для сначала разобраться, что SolidFire работает по iSCSI и FC там вообще никаким боком не участвует.
shapa
08.11.2018 16:08+1FC вообще-то про традиционные решения, клиенты регулярно радуются байкам инженеров Netapp про то что FC SAN это быстро.
С iSCSI-же обычным все еще хуже — начиная с того что это не мультипоточный протокол (не путать с multipath).
По определению это не может эффективным быть в 2019 году, особенно на высоких скоростях (25/40/50/100 гигабит) — поэтому изобретаются костыли уровня NFS4.1 (pNFS) (который кстати netapp поддерживает для традиционных СХД) или весьма грамотно спроектированный MS SMB3.
Для Нутаникс это не проблема — отдельный iSCSI поток на каждый виртуальный диск (vdisk) внутри хоста (множественные подключения к Stargate на CVM), фактически архитектурно iSCSI превращен в мультипоточный протокол, без изменения самого протокола.
Если работает на узле скажем 100 VM с 2-я дисками, то будет 200 потоков iSCSI в пределах хоста.
Интер-коммуникации CVM тоже мультипоточные. При том что поддерживается и SMB3 и NFS (для других гипервизоров).
Для Solidfire — все очень грустно, ввиду того что архитектурно это не HCI и реально сервера просто работают с внешними all flash СХД.
Как вишенка на торт — Нутаникс может на каждый узел ставить 4x40G адаптера Мелланокс, Solidfire — максимум 2 адаптера по 25G.
С учетом отсутствия Data Locality на Netapp FHCI — нагрузка на сеть совсем грустной становится — 12xSSD дисков забивают 50 гигабит «влет».Smasher
08.11.2018 16:24Можно подробнее про не мультипоточность iSCSI? Особенно в свете того, что можно создавать множество сессий к одним и тем же ресурсам.
А почему выше было про миллионы IOPS, а теперь мы пришли к поточной нагрузке?
Вообще меряться скоростью портов достаточно странное занятие, только в очень редких и весьма специфических случаях узким местом становится ширина канала. В случае со случайными нагрузками мелкими и средними блоками это вообще неважно.
Я правильно понял, что для репликации записи на второую ноду в Nutanix используется iSCSI?
Scif_yar
10.11.2018 09:05только в очень редких и весьма специфических случаях узким местом становится ширина канала.
нуну. К примеру у нас обычный 10G. Который, округленно, может давать гигабайт/секунду — то есть то, что выдает 6 штук (всего 6) SATA дисков 7200 на чтение. И вот такое специфическое у меня каждые выходные, угадайте что происходит в это время. И да, на запись с другой стороны стоит R60, из 7200 дисков.
bbk
08.11.2018 18:04Например — «скорость записей плюс минус в лучшем случае равносильна тому» — не в лучшем, а в худшем
Нет, таки в лучшем уважаемый коллега. Почему? Всё просто: replication factor 3. Нужно реплику не на один, а на два внешних сервера слать, да, они шлются параллельно, но разные сервера по-разному нагружены, мало того, что там «сторедж функция», так там ещё и компьютинг крутится, поэтому один из этих серверов может быть более занят чем другой. Плюс получается по сети в два раза больше внутреннего трафика бегает и вместо 2 нод так у вас еще и третья задействована. Это всё дополнительные накладные расходы. Именно поэтому применено выражение «в лучшем случае».
А вот в случае replication factor 2, то будет ровно тоже самое, как если бы система была подключена по сети откинуть влияние нагрузки серверов задачами от виртуальных машин. Эти нюансы вылазят именно из-за shared-nothing архитектуры и никуда от них ни деться. Это ни плохо и ни хорошо, они просто есть и про это нужно знать.
И вообще я Nutanix обидеть не хотел, заслуженная и уважаемая HCI архитектура. Но нужно расставить всё по своим местам, потому что даже при наличии «Библии Nutanix», всё равно некоторые инженеры думают, что записи пишутся исключительно локально, чего архитектура себе позволить не может при всём желании, далее делая из этого не правильные умозаключения, что говорит о том, как обычно техническую документацию никто не читает, а просто «борются на словах» не верными, маркетинговыми идеями.
bbk
08.11.2018 18:35Касательно Гугла и FB и гиперскейлеров.
У этих компаний другая постановка задачи, которая выливается в то, как у них построена внутренняя архитектура под эту задачу и как результат что они для этой задачи используют. И это отнюдь не связано с тем, что shared-nothing архитектура априори лучше и быстрее. Объясню. У этих компаний контент распределяется по их кластерным файловым системам или БД с задержкой, это называется eventual consistency, которую на практике им невозможно достичь. На пальцах: из-за eventual consistency разным пользователям в разных регионах, в поиске гугла/ФБ могут «не доползать» некоторые новые статьи. Но какая разница для пользователя, если он недополучит пару новых статей и вместо них будут другие тоже релевантные для поиска, но просто немного более старые статьи, если у него результат поиска и так состоит из релевантных 10 страниц, на каждой по 10 ссылок. Пользователь просто не заменит этой разницы или она будет не существенна и для бизнеса ФБ/Гугл это приемлемо и не критично.
Благодаря принципу eventual consistency, они могут не покупать промышленные системы хранения под описанные выше задачи, а использовать свою кластерную ФС/БД вместо этого, потому что им это может позволить сама постановка задачи. И не забывайте про армию программистов, которые постоянно допиливают эти алгоритмы.
При том в инфраструктуре с приложениями, к примеру виртуальными машинами, вы не можете себе позволить eventual consistency, это просто не из того мира функционал. Если у вас умирает один сервер с кучей виртуалок, а на второй сервер ещё не успели докатиться самые последние данные, у вас будет куча повреждённых виртуалок. Другими словами вам необходимо синхронно реплицировать данные и ярким примером тому является Nutanix.
А теперь давайте про гиперскейлеров. Оборудование (или софт) NetApp есть в таких гиперскейлерах как Azure, Amazon AWS, Google Cloud, Rackspace, IBM Cloud (и на этом список не заканчивается на самом деле) и доступно как сервис для конечных потребителей. Почему? Да потому что есть много задач в которых shared storage показывает необходим, имеет много функционала и показывает себя с очень хорошей стороны. Иначе бы NetApp не появился у них в ЦОДах.shapa
08.11.2018 18:57«Объясню. У этих компаний контент распределяется по их кластерным файловым системам или БД с задержкой, это называется eventual consistency, которую на практике им невозможно достичь. „
Cадитесь, два балла. Перефразируя — “слышали звон, да не знаем где он».
Т.е. CAP теорема слышали, как работает на практике — не в курсе.
Коллеги из EMC и то грамотнее пишут «battle cards» — приложил скриншотик just for fun. Они на удивление оказались совершенно недалеки от правды.
Так вот — NoSQL, на которых работают Гуглы и Фейсбуки — совершенно спокойно может работать в CAp режиме когда требуется.
Та-же Cassandra (существенно доработанный движок в Нутаникс) по умолчанию действительно работает в cAP режиме (eventually consistenent), но Нутаникс-таки переделал в «always consistent» режим.
И кстати не только Нутаникс — у всех «крупняков» (кроме собственно несчастного Yahoo с Netapp) есть собственные NoSQL движки, работающие в том режиме который им нужен.
Но да, сделать самим такое, без остутствия опыта разработки в «гуглах и фейсбуках», практически невозможно.
Поэтому, если посмотреть внимательно вот сюда — единственный инфраструктурный вендор на NoSQL / Cassandra — это Нутаникс (кроме Cisco Webex, но это онлайн проект).
en.wikipedia.org/wiki/Apache_Cassandra
Да, ни у NetApp ни у других вендоров нет такого уровня разработчиков чтобы сделать правильный NoSQL движок, поэтому все работает по старинке.
p.s. Если кому-то интересно как решили проблему партиционирования при переводе движка в CAp — то «умный в гору не пойдет», смотрим Paxos Computer Science
https://en.wikipedia.org/wiki/Paxos_(computer_science)
Делаем 5 копий метаданных, если отказы нескольких колец Кассандры — это не проблема, легко и быстро восстанавливаются корректные данные.

bbk
08.11.2018 19:05Если вкльюить режим консистентности «когда нужно», получается просадка в производительности в 5 раз ;)
shapa
08.11.2018 21:35В Нутаникс режим консистентности включен _всегда_. Его невозможно выключить. При максимально высокой производительности.
Ввиду Apache License — изменения сделанные в Кассандре отдавать обратно никто не обязан, иначе бы уже развелось клонов ;)bbk
08.11.2018 22:53О боже. У вас какой-то режим защиты нутаникса включился неадекватный.
Никто и не говорил про ваш нутаникс. Понятное дело что в Нутаниксе он включён всегда, иначе быть не может.
совершенно спокойно может работать в CAp режиме когда требуется.
Я говорю без привязки к Nutanix, если в NoSQL BD такой как MongoDB (подозреваю что в Касандре будет аналогичная картина) включить режим консистентности, то там просядет производительность в 5 раз по сравнению с той же самой БД, только с eventual consistency. Так что всегда когда у вас есть выбор что-то включать «если требуется», это значит что вы что-то взамен потеряете, в данном случае потеряете перфоменс БД.shapa
08.11.2018 23:06Вы уж сэр определитесь. Внезапно — вдруг как бы закинутое про «в 5 раз медленнее» — уже Нутаникса и не касается (хорошо что хотя бы это открыто признали).
В целом такое поведение называется «накинуть и попытаться отскочить».
«Так что всегда когда у вас есть выбор что-то включать «если требуется», это значит что вы что-то взамен потеряете, в данном случае потеряете перфоменс БД.»
Пардон — но это откровенная ерунда.
В контексте обсуждения (речь про HCI, FHCI и гиперскейлы) — вообще бессмыслица, ибо упомянутые «гиперскейлы» и Нутаникс обладают движками NoSQL с максимально высокой производительностью, надежностью и консистентностью данных на уровне наносекунд.
Современные динозавры рынка не только не обладают подобными технологиями, но и неспособны их создать.bbk
08.11.2018 23:22Да я опредилился. И повторяю вам еще раз, вы сами начали разговор за консистентность в базах данных и про то что его «можно включить если нужно», я его и продолжил. И этот трэд он был конкретно в тему про гиперскейлеров которые юзают файловые системы и баз данных с cогласованностью в конечном счёте (когда нибудь, может быть) и не юзают стореджи.
Я вам здесь и говорю не за ваш нутаникс, а за эти вот NoSQL базы данных. А вы всё со своим режимом защиты нутаникса, на свой счёт принимаете. Читайте внимательнее и отключите свой режим защиты нутаникса.
Это не ерунда, а правда жизни. Когда Вы включаете консистентность в моднго ДБ палает перфоменс в 5 раз. Когда отключаете, выростает. Это плата за консистентность и я говорю что эта плата она всегда есть. Я сейчас про БД, не про ваш нутаникс, если что.shapa
08.11.2018 23:30«а за эти вот NoSQL базы данных» — для начала, я крайне сомневаюсь что вы адекватно способны рассуждать про «эти вот NoSQL».
Далее — у нас здесь не разговор «обо всем на планете», но про HCI и FHCI.
Ваша заявка про «в 5 раз медленнее» не имеет никакого отношения к теме статьи, и в лучшем случае просто является попыткой наброса и ухода от темы.bbk
08.11.2018 23:54Тю, так вы же сами эту тему поднялии. Ну ладно, нет так нет.
Ой, как мне нравится как вы в каждом своём посте методично не забываете писать про Fake HCI. Жалко в Хабре хэштегов нет в комментариях…
А можно вас попросить в каждом своём комментарии к этой статье ставить хэштег #FHCI, мне так веселее будет?
bbk
08.11.2018 19:13Ну так NetApp не на том уровне бизнес ведёт, чтобы глубоко лезть в разработку Casandra.
Собственно вот вы сами и пришли к тому, что я сказал, что Nutanix интерестен своей внутренней экосистемой, а не устройством стореджа.shapa
08.11.2018 21:39Устройство «стоража» в данном случае — ключевой момент, ибо позволяет при сохранении ультра-высокой надежности — практически безлимитно масштабироваться — как по скорости так и емкости.
Cобственно, NDFS (Nutanix DFS) и «Кассандра» (она же Medusa) — это DNA Нутаникс, на который все остальные «фича» навешаны — включая SDN (чем и близко не пахнет в NetApp FHCI), стек виртуализации AHV, Karbon (Kubernetes), Buckets (Object Storage / S3) и многое другое — они все хранят данные в _всегда консистентной_ NoSQL базе данных (доработанная Кассандра).
По сути коллеги из NetApp и «любимых партнеров» откровенную глупость пишут про «гиперконвергентные» и «неконсистентные»
…
Да, согласен. NetApp — нишевая стораж компания, которая полезла по сути туда где не имеет практически никаких шансов закрепиться. Cкупка устаревших сторонних технологий (например Solidfire) этому точно не поможет.bbk
08.11.2018 23:05Необходимость реплицировать данные между нодами и есть лимит в данной архитектуре. По этому на практике лимит будет, точнее он есть.
А что такое устаревшая технология в данном случае и что есть новая технология? Новая это там где нужно в 3 раза больше накладных расходов по ёмкости и там где в два раза больше накладных расходов на cross-talsk между нодами кластера при записи? Или новая это где нужно занимать ресурсы по памяти и CPU двух дополнительных серверов, которые можно было бы использовать под виртуалки?
В то время как в древнем ONTAP все данные пишуться на ноду которая владеет этим вольюмом и только при аварии переключается и соответственно не жрёт ни рисурсов соседного контроллера ни дополнительных расходов на сеть?
И что значит не поможет, вы в будущем были, у вас машина времени? Давайте дождёмся этого будущего и посмотрим, а не будем выдавать желаемое за действительное. Я к примеру, свои два предсказания сделал потому что уже 7 лет этими устройствами занимаюсь и знаю как оно устроено и куда движется, и громких заявлений типа «нутаникс умрёт и ничто ему не поможет» не делаю.shapa
08.11.2018 23:27«Необходимость реплицировать данные между нодами и есть лимит в данной архитектуре. „
Т.е. Solidfire не защищает / реплицирует данные? Правда? :)
“Новая это там где нужно в 3 раза больше накладных расходов по ёмкости » — извините, глупость. Solidfire существенно проигрывает по эффективной емкости. Как начнут поддерживать EC-X хотя-бы — приходите обратно, поговорим.
«Или новая это где нужно занимать ресурсы по памяти и CPU двух дополнительных серверов, которые можно было бы использовать под виртуалки?»
Вы про solidfire? Где стартовая конфигурация — минимум 4 узла СХД (с выкинутыми процессорами — фактически только под СХД) и 2 сервера, итого 6 узлов?
…
Пардон, но еще раз непрозрачно намекаю — чтобы не нести странности, изучите для начала хотя-бы минимум технологический
bbk
08.11.2018 23:50Если мы говорим уже за SF, то там тоже, на подобии как в Nutanix есть репликация между нодами по сети. Ключевое слово тоже, так что не нужно тут пытаться опять песни петь про локальные диски и православные локальные записи. Вы как-то внезапно на SF переключились, хотя говорили мы про ONTAP & AFF и NoSQL, ну да ладно.
Да, в NetApp HCI/SF нужно по сути минимум две ноды SF и две ноды серверов, итого 4ре, а 10 версии прошивки нужно минимум 4 ноды SF. Я об этом честно пишу. Но опять таки уменьшаем/увеличиваем количество нод, что будет с нутаниксом? Потеряем пространство если нужно уменьшить компьютин, если нужно увеличить компьютинг — автоматом добавим пространство, нужно оно или нет, а добавить обязан. В архитектуре NetApp HCI компьютинг и пространство могут уменьшаться/расти независимо.
Ох уж этот режим защиты нутаникс. Всех порву. Все дураки. Один я дартаньян потому что читал биболию нутаникс.
EC-X это конечно классная штука. Сначала делаем replication factor 3, магко говоря охреневаем от оверхэдов как по пространству, так и по сети. А потом такие, «а давайте ка мы Eresure Coding по сети на продуктив натянем» (С)? Экономия! Только перфоменс гуляет лесом. Потому что это обратная строна медали EC. Когда у тебя есть опции, это говорит, что технология имеет недостатки, где выбор и принятие между несколькими обоими плохими решениями перелаживаются на плечи заказчика. Хотите безопасность — ставьте репликацию 3 (и охреневайте от оверхэдов), хотите сэкономитть, ставьте 2, хотите сильнее сэкономить, ставьте EC (и охреневайте от performance impact)! И каждый из этих вариантов со смоими проблемами.
Сделал себе проблему, а потом героически решил, точнее дал ложный выбор. А потом ещё сказать, а у вас в SF нет такой штуки как EC! Круто.
shapa
08.11.2018 19:01Про гиперскейлеров, которые дают клиентам (но не используют для своих задач) устаревшие СХД — ответ тоже очевиден, многие клиенты хотят то, к чему привыкли.
Мантра про «треубется shared storage» — крайне забавна. AWS например не предоставляет shared storage? Вы реально утверждаете что S3 например работает на NetApp? :)bbk
08.11.2018 19:08Ну при чём же здесь S3. Он преспокойно себе живет и работает на комодити оборудовании. Иногда работает, иногда не работает. Но опять таки постановка задачи у него «дешевое» и надёжное хранилище данных (про доступность этих данных умалчиваем). Которое кстати под задачи виртуальных машин и задачи баз данных использовать не возможно. Потому что протокол в основном заточен на то чтобы туда один раз записали и много раз читали. Или подождали пару часиков и прочитали ;)
shapa
08.11.2018 21:58Хорошо. Тяжело вздыхаем, идем длинным путем.
Пойдем от обратного, как в анекдоте про Аленушку, чудовище заморское для утех и аленький цветочек.
Перечислите (например) сервисы AWS, которые предоставляют shared storage на NetApp.
Кстати, если долго говорить «сахар» — слаще не станет.
Первый же тотальный провал Yahoo при переходе Мариссы Мейер из Гугла — тотальная пролежка файлеров NetApp, с массой репутационных и финансовых потерь.
Собственно, как IMHO правильно пишут на tech crunch (ссылку давал выше) — одна из причин смерти Yahoo — устаревшие технологии NetApp / отсутствие инноваций.
«Building fast and building to last
At the beginning of the new millennium, Google and Yahoo started down very different paths to attain the enormous scale that the growing size and demands of the Internet economy (search, email, maps, etc.) required. For Yahoo, the solution came in the form of NetApp filers, which allowed the company to add server space at a dizzying rate. Almost every service that Yahoo offered ultimately ran on NetApp’s purpose-built storage appliances, which were quick to set up and easy to use, giving Yahoo a fast track to meet market demand (and soon made the company NetApp’s largest customer).
But in nearby Mountain View, Google began work on engineering its own software-defined infrastructure, ultimately known as the Google File System
…
Instead of using the latest storage appliances as a foundation, the Google File System used commodity servers to support a flexible and resilient architecture that could solve scalability and resiliency issues once and for all, „bbk
08.11.2018 23:16Ох уж этот NetApp со своими устаревшими технологиями!
Ох уж эти AWS, Azure, Google Cloud, IBM Cloud, Rackspace (и скоро ждите еще одного крупного играка), все хотят напродавать своим заказчикам этот поганый и устаревший NetApp своим заказчикам, а сами то посмотрите, сами то его не используют!
Всё строют и строют свои датацентры, расширяют покрытие со своими сутаревшими технологиями.
Это никак иначе как глобальный сговор буржуев против православного нутаникса!
Предлагаю выключить режим всезнайки,- плохо получается.shapa
08.11.2018 23:19Понятно, кого-то понесло.
Технически / по делу есть что-то?
Да, про «Backups for NetApp Cloud Volumes Service for AWS» — как я понимаю, вы совершенно не понимаете о чем пишете.
Backups for NetApp Cloud Volumes Service for AWS — это AWS разрешила поверх своего HCI запускать ПО NetApp для тех клиентов кому это нужно.
Попытка выдать это как AWS использует NetApp для расширения — прекрасна в своей неразумности.
«he NetApp Cloud Backup Service is an add-on feature for Cloud Volumes Service that delivers fully managed backup and restore capabilities for Cloud Volumes Service»
add-on требуется перевод? ;)bbk
08.11.2018 23:26Я вам технически уже выложил выше. И про репликацию по сети и про в 3 раза больше ёмкости и про архитектурные ограничения.
И читайте внимательнее там есть запятая и слово «and» в заголовке.
Чтобы вы били в курсе, NetApp Cloud Volumes Service for AWS построены на «устаревших» NetApp AFF, в октябре добавили 8 новых регионов.shapa
08.11.2018 23:36«Я вам технически уже выложил выше.»
К сожалению, все ваши выкладки — в лучшем случае просто означают полное непонимание архитектуры. В худшем — осознанная попытка ввести в заблуждение. Solidfire кардинально проигрывает Nutanix с точки зрения эффективности использования пространства, ввиду того что не поддерживает EC-X и максимальный размер LUN всего 16TB.
«NetApp Cloud Volumes Service for AWS » — это прекрасно.
Внезапно, «NetApp Cloud Volumes» построены на NetApp.
Я бы реально удивился если бы они были построены на HPE 3par :)
Повторяю, цитата NetApp:
«NetApp Cloud Backup Service is an add-on feature for Cloud Volumes Service that delivers fully managed backup and restore capabilities for Cloud Volumes Service»
У AWS есть Cloud Volumes Service. Которые построены на технологиях AWS и там и близко не пахнет NetApp. Нетапу разрешили выпустить Add-On для Cloud Volumes Services, поэтому он и называется NetApp Cloud Volumes Service.
Это как примерно VMware начнет рассказывать что (им разрешили запускать ESXi на bare-metal instance i3 AWS) что AWS перешел на ESXi.bbk
08.11.2018 23:56Ой, так напишите статью на хабре про архитектуру и как в вашем нутаниксе операции записи на соседние ноды телепортируются без использования сети. И как они не занимают в 3 раза больше ёмкости с фактором репликации 3.
bbk
09.11.2018 00:02Я плачу. Просто плачу катаясь под столом. Вы ж вроде в Англии живёте. Читать на ангицком должны уметь. А ещё меня учить хотели.
Всё уже, прочитали, поняли, о чём в той статье говорилось? Что там про Cloud Volumes Service (Читай NetApp AFF), что это не исключительно речь про бэкапы, они как бы тоже (also) есть. И что в 8 новых регионах этот сервис с «устаревшими технологиями» NetApp AFF открыли. не с нутаниксом почему-то…
Ах да. Буржуи. Заговор… и не забываем добавить, то что NetApp ничего не спасёт.
Hardened
08.11.2018 23:06Навеяно одним из основныз посылов статьи. Было бы интересно получить от обоих уважаемых вендоров перечень фич, которые с их точки зрения интересны сервис-провайдерам под раздачу виртуалок. Сегмент на который целится SP — B2E.
Smasher
09.11.2018 11:51NetApp HCI:
Возможность независимого масштабирования compute и storage составляющих.
Автоматизация и интеграция с чем угодно — API, Trident (volume плагин для k8s и docker), OpenStack драйвер и т.д.
QoS — min, max, burst. Любые тома всегда создаются с QoS политикой.
Гарантированная эфективность 4:1 для Private Cloud, IaaS. Не учитываются клоны, снепшоты и т.д. Если эффективность оказывается меньше, вендор отружает дополнительное железо.navion
09.11.2018 11:55Это же всё фичи SF, в каком месте там HCI?
Без подколок, мне действительно интересно какие преимущества даёт NetApp HCI перед своими серверами + SolidFire + лицензии на vSphere. Кроме визарда длядебиловпервичной настройки и поддержки из одного корыта.Smasher
09.11.2018 12:38А какие преимущества даёт любоё HCI решение в сравнении с своими серверами+СХД+гипервизор?
catsfamily
09.11.2018 13:09+1навскидку —
Масштабируемость
управляемость из одной точки + api
Саппорт в «одном окне» (это как правило уже)
отказоустойчивость выше
Накладные расходы меньше (No SAN, 1/10/25/40G Ethernet only)
чаще всего — дешевле классического аналога (за комплект).Smasher
09.11.2018 13:35чаще всего — дешевле классического аналога (за комплект)
Это спорно :) На чем же тогда вендор HCI зарабатывает?
отказоустойчивость выше
За счёт чего?
Масштабируемость у NetApp HCI до 40 storage нод и до 64 compute.
Можно без проблем убирать ноды из существуещего кластера и, например, собирать из них другой кластер на удаленной площадке.
Про API уже писал, всё управление из vCenter происходит. Поддержка на всё от NetApp. В том числе на коммутаторы и VMware.navion
09.11.2018 13:59То есть это реинкарнация FlexPod с масштабируемым сториджем?
А какие преимущества даёт любоё HCI решение в сравнении с своими серверами+СХД+гипервизор?
Любое HCI не интересно, вопрос был конкретно про value от покупки NetApp HCI.Smasher
09.11.2018 14:15Выгоду от покупки NetApp HCI я уже описал, да по большой части это те преимущества, которые получены благодаря SolidFire. Для этого их и покупали.
То что SolidFire доступен как отдельный продукт говорит о том, что вендор видит в нем востребованность и понимает как на нём зарабатывать в отрыве от HCI.
catsfamily
09.11.2018 16:27Это спорно :) На чем же тогда вендор HCI зарабатывает
Так себест тоже ниже получается, основная цена у HCI — в софте же…bbk
09.11.2018 18:38Основная цена HCI в простоте. А как оно реализовано, через софт или через железные коробочки, какая разница, всё-равно в итоге у вас эти железные коробочки в ЦОДе, что так что так.
KorP Автор
09.11.2018 13:38отказоустойчивость выше
На основе чего сделан данный вывод? Я не тролю, просто интересно мнение.
Накладные расходы меньше (No SAN, 1/10/25/40G Ethernet only)
Чем плох SAN? Тесты NVMEoF видели?catsfamily
09.11.2018 13:53Меньше сущностей — от того и выше.
И да, SAN сам по себе ничем не плох. Как вобщем и Nokia 3310 :)
работает справно, что положено делает.
Технологически устаревает? Ну это закон природы, все устаревает :)
NVMeoF? Это прекрасно :) по мне — костыль для SAN, да.KorP Автор
09.11.2018 14:00Меньше сущностей
Сущностей то как раз не меньше. Оборудования — да.
по мне — костыль для SAN, да.
чем?catsfamily
09.11.2018 14:27Давайте считать.
Классика.
Серверы. (в них Адаптеры SAN и LAN)
SAN (Коммутаторы, провода и проч)
LAN (--"--)
СХД
HCI
Серверы (c LAN)
LAN (Коммутаторы, провода и тд)
Итого сущностей столько же, верно?
А про «чем костыль»… Это как разгон процессора на водяном или крио охлаждении (метафора). Работать будет, но это уже «дожим» возможностей.KorP Автор
09.11.2018 14:30HCI
Серверы (c LAN)
Не понял — зачем отдельно серверы, если мы про HCI?
«дожим» возможностей
Пока, судя по тестам NetApp + Brocade — дожимом там и не пахнет, учитывая более скромные показатели аналогов на Ethernet, которые ещё до конца и не готовы.catsfamily
09.11.2018 16:25В общем случае HCI состоит из серверов с дисками (ну и сеть, конечно), поэтому они и выделены как сущность. Потом уже ее в кластерный сторадж софтом объединяем, все так?
bbk
09.11.2018 18:54Ну так давайте посчитаем.
Если всё делаем с фактором репликации 3, нужно в 3 раза больше стореджа, в 3 раза больше дисков, в 3 раза больше серверов в которые можно вставить эти диски. в 3 раза больше лицензий на эти сервера и не важно нужно ли вам столько компьютинга.
Кабели, NIC/HBA в серверах и свичи, как ни крути всё-равно будут и у True HCI они никуда не делись. Единственное что нужно будет в 3 раза больше этих вот NIC, в 3 раза больше портов на свиче, где будет гоняться в 2 раза больше сетевого трафика и тех же самых кабелей в 3 раза больше.
Ситуацию немного может улучшить фактор репликации 2, тогда вам всего нужно в 2 раза больше, а не в 3 (Мама мия!). Но при этом немного ухудшить защищённость данных.
Касательно скорости, то «Записи не подтверждаются до тех пор, пока по сети удалённые ноды не подтвердят получения этих данных, что равносильно скорости работы с shared storage по сети».
Есть еще вариант сделать EC, и существенно сократить накладные расходы на железо и пространство, став по эффективности почти таким как shared storage, порядка 35%. Но при этом просев в производительности, потому что EC это по-сути сетевой RAID.
Hardened
09.11.2018 20:171) Нет уникальности. 3PAR тоже отдельно масштабируется от серверов.
2) Спорно. На российском B2E засилье предложений от SP на VMware. Управление через конечно API пишут в тендерах, но на практике выдают разве что в рамках dedicated private cloud. Чтобы не дай бог платформу с другими клиентами вместе с собой никто не положил.
3) Можно подробней? На практике QoS на LUN не очень работает, так как на нем обычно несколько дисков VM создаётся уже самим клиентом. QoS на диск? VVOLs?
4) Готовы сделать commitement на эффективность вместе с commitement по QoS? Разделить ответственность провайдера при трансляции back to back SLA в End User? У вендора с большим опытом в cloud есть представление, как это вообще может быть устроено? При том, что у провайдера жизнь на инфраструктуре достаточно динамичная — под одни включения нужен выше QoS возможно в ущерб эффективности, под другие наоборот. И это ещё во времени меняетсяSmasher
09.11.2018 22:341) С каких пор 3Par стал HCI-решением?
3) QoS на LUN, на vvol. Что под диском понимается? Есть интеграция с SIOC.
4) Тут я за вендора отвечать не могу. По эффективности подписывается документ со всеми условиями. Есть 180 дней с момента отгрузки оборудования, чтобы выяснить достигается ли арантированная эффективность. Если не достигается, то клиент обращается к вендору. Для начала выделяют инженера для проверки, что все настроенно в соответствии с best practices, если это не помогает, то вендор отгружает ноды/диски.
При том, что у провайдера жизнь на инфраструктуре достаточно динамичная — под одни включения нужен выше QoS возможно в ущерб эффективности, под другие наоборот. И это ещё во времени меняется
Про это можно подробнее?
QoS по сути неотключаемая функциональность. Каждая нода имеет заявленную производительность с профилем 80/20 rr/rw 4k. В зависимости от модели ноды это 50К IOPS или 100K IOPS на ноду. Для любого создаваемого тома задаётся политика, в которой указывается минимально гарантированная производительность, максимальная и burst. Сумма минимальных QoS для всех томов не может превышать производительность всего кластера. Если нагрузка на томе не превышает максимальный QoS, то накапливаются кредиты. При превышении максимального значения QoS эти кредиты начинают тратиться.Hardened
10.11.2018 10:281) Провайдер не ограничивает себя HCI. Главное, чтобы решение по хранению было удобно для предоставления услуг множеству конечных пользователей и было экономически эффективным.
2) Если вы не знакомы, в портале самообслуживания VMware vCloud Director клиенты сами создают диски (vHDD) для своих виртуальных машин. Интеграция с SIOC и vVOL хорошо.
3) Приведите пример формулировки правила QoS. Пока не понятно что в нем участвует — полоса, IOPS, latency?
4) Не скажу как для Enterprise, но для провайдера схема не очень рабочая. Клиенты на массив будут приходить 1-2 года. За 180 дней будет загружен лишь небольшой dataset от общего объема. Для примера допустим на нем эффективность 2:1. Вендор расширит весь массив в два раза? Ну и условия непонятно какие подписывать — провайдер еще не знает какие клиенты и с какими данными придут через отдел продаж
gotch
Вот это действительно важный момент, про который маркетинг умалчивает.
navion
У них хотя бы есть «библия», где описано как работает Unified Cache.
А у Netapp вся техническая документация под NDA и маркетинг умалчивают значительно больше.
KorP Автор
Какой именно технической документации вам не хватает? Вроде уж чего-чего, а этого у нетапа завались
gotch
Да в половину статей как логиниться надо, иначе тайное знание не откроется.
KorP Автор
На заходите в StorageDiscussions, если к какому то документу у вас нет доступа — с вами без проблем там им поделятся.
navion
Подробные офисания фичей и характеристики железок с филдпортала.
Smasher
Куча документации с подробным описанием того как рабьотают технологии доступно в виде Technical Reports. К примеру TR-4476 про технологии эффективности. Характеристики оборудования доступны в hardware universe куда есть доступ у клиентов и партнёров.
KorP Автор
Приходите в StorageDiscussions, вам там или документацию подкинут или объяснят без маркетинга.
bbk
Коллеги, а на кой чёрт вам меркетинговые материалы NetApp?
Я уверен что к маркетинговым материалам Nutanix у вас тоже нет доступа.
Дотошные характеристики железок на HWU.netapp.com
navion
Где тут маркетинг? Я вижу подробное описание железок и характеристики, которых нет на HWU.
bbk
Боже, на кой чёрт вам этот документ? Что вам не хватает в характеристиках HWU?
Я вам еще раз говорю, что я просто уверен в том, что у нутаникса тоже есть такой же аналог fieldportal, к которому у вас тоже никто доступа нет.
Просто вы про fieldportal знаете.
navion
Хочу всё знать! Про Нутаникс не скажу, но у IBM и Cisco в партнёрке только батлкарды с прайсами.
А docs с hwu тогда что? Там даже этого нет, лишь картинки как менять FRU и включать фичи в админмоде.
bbk
Это конечно похвально.
bbk
Кстати хотел спросить, а зачем вам «всё знать» про вендора, которого вы упорно и всегда критикуете буквально в любой статье где речь заходит за NetApp, учитывая что он такой плохой?
Я так понимаю вы в интеграторе работаете и далеко не NetApp занимаетесь, правильно я понял?
У меня такое ощущение что «всё знать про NetApp» связано, особенно в маркетинговом плане, не просто с жаждой знаний.
navion
Не угадали, я заказчик и пишу гадости про всех, так как считаю критику лучшим фидбеком.
bbk
Тоже вариант
romxx
Виссарион Григорьевич Белинский едет по вечернему Петербургу на извозчике. Извозчик видит — барин незаносчив, из простых, пальтишко на нём худое, фуражечка, — в общем, можно поговорить. Спрашивает:
— Ты, барин, кем будешь?
— А я, братец, литературный критик.
— А это, к примеру, что ж такое?
— Ну вот писатель напишет книжку, а я ее ругаю…
Извозчик чешет бороду, кряхтит:
— Ишь, говна какая…
bbk
Таки да. Это маркетинг. Картинки, слайды, собранная и пережёванная информация. Это не техническая документация.
Техническая документация без слайдиков и не из 100 страниц картинок, а 300 страниц сухого технического текста который рассказывает всё как есть без предвзятости, прикрас и маркетинга здесь
docs.netapp.com/ontap-9
catsfamily
«Login to continue»
Вообще логиниться по каждому чиху очень мешает работе.
А политика «зайдите на такой то канал вам там все разжуют» — такое…
bbk
Вы куда-то не туда смотрите. Вот куча открытой и технической документации.
docs.netapp.com/ontap-9
Dantte
Smasher
https://docs.netapp.com/ontap-9/index.jsp
gotch
Да, к сожалению открытостью документации NetApp похвастать не может.
romxx
Не то что не «умалчивает», а пишет (о том, как производится запись на диски в Nutanix HCI)всюду, включая и на русском, ссылки ниже.
Но тут конечно есть некоторая манипуляция в форме передергивания. Потому что вот в той форме, как у Евгения конечно не пишет, потому что это неправда.
bbk
Рома, ну ты сам прекрастно видишь, что все бегают с этими лозунгами «локальные диски быстрее», как обычно оставив в стороне «технические детали». Просто пора уже придумывать новые лозунги, эти устарели ;)
PS. Эта фраза больше не Женина, а моя.
romxx
Слушайте, вы выдумываете проблему, а потом говорите, «ну, вот, проблема, видите»?
Если есть абстрактный «инженер», который не знает и не интересуется «техническими деталями», то проблема в этом «инженере», и в узости его понимания, а совсем не в Nutanix, при чем здесь мы-то?
Вы берете некоего абстрактного человека, который «бегает», а виноваты в этом мы?
Повторяю, в статье много от простого непонимания до передергивания, и это неприятно, потому что garbage-in garbage-out. Представьте статью про NetApp, в которой автор говорит: «Ну, так как всем известно, что LUN в NetApp это файловая эмуляция, а потому априори проигрывает нативному блочному доступу...» и дальше две страницы текста и выводов, основанных на этом заблуждении, это что? Это мусор с самого начала. Вот и тут та же история.