

С корпоративной базой знаний для разработчиков обычно есть проблема — она либо превращается в пустоту, потому что нет мотивации ее наполнять или ответственного человека, либо — в заполненный вещами балкон из советской квартиры, все вносят свой вклад, но пишут хаотично, информация быстро устаревает, и ее не всегда успевают обновлять.
Как этого избежать, ну или хотя бы снизить возможные издержки? Как сделать вашу корпоративную базу теплой и ламповой? Попробую ответить.
Документация в стиле «коллаб»
Есть такой подход, collaborative documentation, изначально он появился в сфере медицины, когда принятие решение о постановке диагноза принимается коллегиально пациентом и несколькими врачами.
Яркий пример в сфере IT — это Google Docs, Wiki, Github, любая система, где есть внутренние конвенции и возможность совместной работы над проектом.
Идея в том, чтобы как можно раньше включить в работу над документацией разработчиков, экспертов, критиков, вместе выявлять пробелы.
Зачем это вообще нужно?

Во-первых, снизить bus factor — это узкие места в корпоративных знаниях, где количество обладателей знания стремится к единице. Нужно перемещать такие знаний из головы разработчика, из whiteboards, тикетов, разговоров на кухне в единое пространство, чтобы все могли с ними работать и вносить вклад.
Во-вторых, для упрощения вхождения новичков в проекты, что особенно важно для распределенных команд и команд с некоторым количеством аутсорс-разработчиков, а также для тех компаний, у кого очень специфичная сфера бизнеса, и шанс найти готового специалиста равен нулю.
В-третьих, для формирования доброкачественной корпоративной культуры, прозрачности «не на словах». Разработчик в такой среде четко понимает точки профессионального роста, какие еще технологии он может опробовать в компании, чему научиться.
Что делать-то?
Документацию в рамках корпоративной базы знаний может писать любой участник команды, нужно упростить для них эту возможность, тогда они будут чувствовать себя владельцами результата — причастными.
Однако, обязательно нужен человек, который возьмет на себя функции архитектора информации — задаст единые правила, структуру, логику, стиль, будет правильно размещать документы в пространствах.
Откройте возможность редактирования и создания документов участникам команды, предварительно договорившись о правилах игры. Автоматизируйте эти правила по максимуму — не полагайтесь на команду, создайте шаблоны, помечайте контент тегами автоматически, настройте выгрузку из репозитория в базу знаний (об этом хочу сделать отдельную статью, кстати).

Важно, чтобы разработчики видели, что в корпоративную Wiki документы не уходят умирать. Важный принцип: definition of done внутреннего документа, это момент, когда в него внесли правки или комментарии, то есть собственно, момент коллаборации. В этом его ценность, на него хотят тратить время. Не дополняют — значит, плохо налажен процесс доставки, внедрения поиска, или инструмент неудобен.

Потенциальные проблемы такого подхода — это накапливание правок и комментариев как снежного кома, за ним сложно уследить, часто создаются дублирующие документы.
Чтобы этого не случилось, можно и нужно: А. Задать команде вектор, набор правил и усложнить процесс не следования им (пример, мы в Confluence спрятали кнопку «Создать» и сделать обязательным выбор шаблона). Б. С умом разграничивать права и настроить процессы правок удобно для того, кто отвечает за архитектуру информации.
И тогда наступит идеальный мир
Разработчики не перестанут задавать друг другу вопросы, в том числе глупые и повторяющиеся . Они не научатся находить все ответы в базе знаний самостоятельно. У нас есть внутренний юмор, когда из-за ограничений поискового индекса Confluence разработчики не могут что-то найти, они просят меня, как архитектора информации. Мы называем это Sveta-based search.
Несмотря на эти ограничения, сама структура базы знаний, единое именование страниц, применение лейблов, будут стимулировать их искать и создавать знания, чтобы например не отвечать на постоянно повторяющиеся вопросы.
Еще один лайфхак, который мы применили — всегда включать в документы бизнес-контекст, даже если это описание библиотеки или класса или чек-лист по задаче, важно понимать, что это значит для клиента.
А теперь к практике
Далее будет часть про «Как», какие внутренние возможности Confluence (да, у нас используется стек Atlassian) можно использовать, чтобы реализовать эти принципы.
Шаблоны
Мы создали готовые шаблоны для разных видов документов, которые чаще всего пишем — техническая спецификация, how-to, чек-лист. Их можно настроить в панели админа пространства. Шаблоны нужны, чтобы, создавая документ, разработчик не видел перед собой пустую страницу, в нем уже есть инструкции, что написать в том или ином разделе. Если вы хотите, чтобы документы определенного вида попадали в один раздел и по ним отображалась метаинформация (это удобно, например, для описания компонентов сложного продукта или набора микросервисов по одной схеме), то создайте blueprint, это как шаблон на максималках.
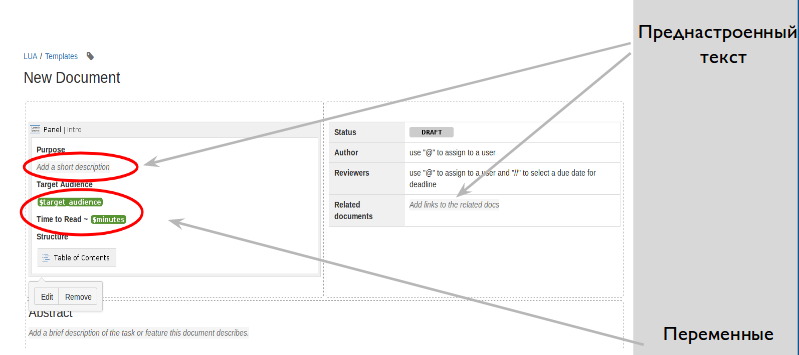
В них мы настроили разметку страницы, заголовки, где останется только заменить несколько слов, шапку со статусом, изображения, таблицы, блоки кода, и даже переменные.
Переменные — это преднастроенные элементы контента, которым дальнейший редактор документа должен придать значение, например, ввести текст или выбрать из списка.
Также к шаблону можно заранее, если это узкий вид документа добавить теги, можно упомянуть пользователей как ревьюеров, например, если есть четкий поименный workflow по утверждению, Jira macro, и прикрепить тикет из Jira. Наш опыт показывает, что можно покрыть шаблонами до 80 процентов задач.
Разметка страницы
Еще один важный элемент — это создание понятной и красивой страницы приземления в командном пространстве. Для этого мы используем разметку страницы (page layout) и макросы Панель, Колонка и Секция.
Ниже показываю пример одного из наших пространств команд разработки.

Используйте понятные названия страниц. Как вы возможно знаете, Confluence не поддерживает одинаковые наименования страниц в пределах одного пространства. Поддерживайте понятные названия страниц, например
Плохое название Python
Хорошее название Python Styleguide для команды внутренних сервисов
Лейблы
У Confluence есть некоторые ограничения поискового алгоритма, связанные с индексацией контента. А для корпоративной базы знаний именно находимость и связность — это самые актуальные вопросы. У нас в базе знаний есть целая статья, называется How to beat the Confluence Search, если хотите, я поделюсь ей в комментариях.

Для преодоления этих ограничений мы используем систему лейблов. По сути, это теги, которые помечают тематику контента, а зачем позволяют агрегировать контент определенной тематики в одном месте в виде своеобразного RSS Feed (макрос Content by Label). Так у нас настроены предметные указатели.
Если у вас уже сотни страниц в базе, то советую начать со следующих упражнений:
- Посмотрите список всех лейблов по следующему URL https://<my-host-name>/labels/listlabels-alphaview.action.
- Найти весь контент, не помеченный никакими лейблами в строке расширенного поиска: type:page NOT labelText:[a TO z] NOT labelText:[0 TO 9].
Что вы можете пойти и сделать прямо сейчас?
- Дайте разработчикам права на редактирование, но с умом.
- Подумайте над структурой командного пространства, сделайте удобную страницу приземления.
- Настройте шаблоны.
- Используйте лейблы.
- Пойдите и отредактируйте чей-нибудь документ или напишите комментарий, заставьте это документ работать.
Комментарии (5)

Chamellion
21.11.2018 12:19+1Любопытно прочитать еще одно мнение о внутренней базе знаний.
Я тоже занимаюсь базой знаний в компании. Не могли бы вы подробнее описать процесс выгрузки в базу знаний? У вас это что-то внешнее для клиентов?
Одно замечание — у вас немного верстка поехала. Где-то пропало двоеточие, где-то есть знаки препинания в списках разнятся. Неплохо было бы поправить)
nerazzgadannaya Автор
21.11.2018 12:37поправлю, спасибо огромное! нет, база внутренняя, хочу написать отдельно про автоматизацию выгрузки из репозиториев, если коротко, то сделано на базе Sphinx с поддержкой сорса в MD и RST
Coob
21.11.2018 16:16Поддерживаю, мне тоже было бы интересно почитать про автоматизацию выгрузки, буду ждать стати.
Сам, кстати, создал/поддерживаю базу знаний на Mediawiki. У нее есть свои ограничения, но категоризация там гораздо более естественным образом устроена, кмк, чем теги Confluence.
nerazzgadannaya Автор
Делюсь статьей про How to beat the Confluence Search? docs.google.com/document/d/1Sx0sPdqNlCAstXq82aJIjtNU3jBZDvqwEH_IewmXcVQ/edit?usp=sharing