
В одной из предыдущих статей я рассказывал о том, как можно построить исполнитель программ для виртуальной стековой машины, используя подходы функционального и языково-ориентированного программирования. Математическая структура языка подсказала базовую структуру для реализации его транслятора, основанную на концепции полугрупп и моноидов. Этот подход позволил построить красивую и расширяемую реализацию и сорвать аплодисмент, но первый же вопрос из зала заставил меня слезть с трибуны и снова залезть в Emacs.

Я провёл простое тестирование и убедился в том, что на простых задачах, использующих только стек, виртуальная машина работает шустро, а при использовании "памяти" — массива со случайным доступом — начинаются большие проблемы. О том, как удалось их решить, не меняя базовых принципов архитектуры программы и достичь тысячекратного ускорения работы программы, и пойдёт речь в предлагаемой вашему вниманию статье.
Haskell — язык своеобразный и с особенной нишей. Основной целью его создания и развития была необходимость в lingua franca для выражения и тестирования идей функционального программирования. Этим оправданы его самые яркие особенности: ленивость, предельная чистота, акцент на типы и манипуляции с ними. Он разрабатывался не для повседневной разработки, не для промышленного программирования, не для широкого использования. То, что он, действительно, используется для создания масштабных проектов в сетевой индустрии и в обработке данных — это добрая воля разработчиков, proof of concept, если угодно. Но до сих пор, самым главным, широко используемым и потрясающим своими возможностями продуктом, написанным на Haskell является… компилятор ghc. И это совершенно оправданно с точки зрения его предназначения — быть инструментом для исследований в области computer science. Принцип, провозглашённый Саймоном Пейтоном-Джонсоном: "Избегать успеха любой ценой", необходим языку для того, чтобы оставаться таким инструментом. Haskell подобен стерильной камере в лаборатории какого-либо научного центра, разрабатывающего полупроводниковые технологии или наноматериалы. В ней жутко неудобно работать, и для повседневной практики она слишком уж ограничивает свободу действий, но без этих неудобств, без безкомпромиссного следования ограничениям не удастся наблюдать и изучать тонкие эффекты, которые потом превратятся в основу промышленных разработок. При этом, в промышленности стерильность уже будет нужна лишь в самом необходимом объёме, а результаты этих экспериментов появятся в наших карманах в виде гаджетов. Мы изучаем звёзды и галактики не потому что рассчитываем получить от них прямую пользу, а потому что в масштабах этих непрактичных объектов квантовые и релятивистские эффекты становятся наблюдаемы и изучаемы, настолько, что потом мы можем использовать это знание для разработки чего-то очень утилитарного. Так и Haskell с его "неправильными" строками, непрактичной ленивостью вычислений, жёсткостью некоторых алгоритмов вывода типов, с чрезвычайно крутой кривой входа, наконец, не позволяет с лёгкостью создать шустрое приложение на коленке или операционную систему. Однако, из этой лаборатории вышли в практический мир линзы, монады, комбинаторный парсинг, широкое использование моноидов, методы автоматического доказательства теорем, декларативные функциональные менеджеры пакетов, на подходе линейные и зависимые типы. Это находит применение в менее стерильных условиях в языках Python, Scala, Kotlin, F#, Rust и многих других. Но ни одном из этих чудесных языков я не стал бы использовать для преподавания принципов функционального программирования: я отвёл бы ученика в лабораторию, показал на ярких и чистых примерах как это работает, а потом уже можно "на заводе" увидеть эти принципы в действии в виде большого и непонятного, но очень быстрого станка. Избегание успеха любой ценой — это защита от попыток засунуть в электронный микроскоп кофеварку, с целью его популяризации. И в соревнованиях какой язык круче, Haskell всегда будет вне обычных номинаций.
Однако, человек слаб, и во мне тоже живёт демон, который подзуживает сравнивать, оценивать и защищать "мой любимый язык" перед другими. Так, написав изящную реализацию стековой машины, основанную на моноидальной композиции, с единственной целью — увидеть, работает ли эта моя идея, я тут же огорчился, обнаружив, что реализация работает блестяще, но жутко неэффективно! Как будто я, и правда, собираюсь использовать её для серьёзных задач, либо продавать свою стековую машину на том же рынке, где предлагают виртуальные машины Python или Java. Но, чёрт побери, в статье про поросёнка с которой начался весь этот разговор приводятся такие вкусные цифры: сотни миллисекунд у поросёнка, секунды у Python… а мой прекрасный моноид с этой же задачей не справляется и за час! Я должен добиться успеха! Мой микроскоп будет варить эспрессо не хуже кофемашины в коридоре института! Хрустальный дворец можно разогнать и запустить в космос!
Но чем ты готов поступиться, — спрашивает меня ангел-математик? Чистотой и прозрачностью архитектуры дворца? Гибкостью и расширяемостью, которую предоставляют гомоморфизмы из программ в другие решения? Демон и ангел оба упрямы, и мудрый даос, которого я тоже пускаю к себе пожить, предложил пойти по пути, устраивающему обоих, и идти по нему так долго, как получится. Однако не с целью выявить победителя, а чтобы познать сам путь, выяснить как далеко он ведёт, и получить новый опыт. И так я познал суетные печаль и радость оптимизации.
Перед тем как начать, добавим ещё что сравнения языков по эффективности бессмысленны. Сравнивать надо трансляторы (интерпретаторы или компиляторы), либо производительность программиста, пользующегося языком. В конце концов утверждение, что программы на C самые быстрые легко опровергнуть, написав полноценный интерпретатор C на BASIC, например. Итак, мы сравниваем не Haskell и javascript, а производительность программ, выполняемых транслятором, скомпилированным ghc и программ, выполняемых, скажем, в каком-то конкретном браузере. Вся свинская терминология взялась из вдохновляющей статьи о стековых машинах. Весь код на Haskell, сопровождающий статью можно изучить в репозитории.
Выходим из зоны комфорта
Исходной позицией будет реализация моноидальной стековой машины в виде EDSL — маленького простого языка, который позволяет комбинируя два десятка примитивов, воздавать программы для виртуальной стековой машины. Коль скоро он попал во вторую статью, дадим ему имя monopig. Его основой служит то обстоятельство, что языки для стековых машин образуют моноид с операцией конкатенации и пустой операцией в качестве единицы. Соответственно, и он сам построен в форме моноида трансформации состояния машины. Состояние включает в себя стек, память в виде вектора (структуры, обеспечивающей случайный доступ к элементам), флаг аварийной остановки и моноидальный аккумулятор для накопления отладочной информации. Вся эта структура передаётся по цепочке эндоморфизмов от операции к операции, осуществляя вычислительный процесс. Из структуры, которую образуют программы была построена изоморфная структура кодов программ, а из неё гомоморфизмы в другие полезные структуры, представляющие требования к программе по числу аргументов и памяти. Завершающим этапом строительства было создание моноидов трансформации в категории Клейсли, которые позволяют погрузить вычисления в произвольную монаду. Так у машины появились возможности ввод-вывода и неоднозначных вычислений. С этой реализации и начнём. Её код можно посмотреть здесь.
Мы будем испытывать эффективность программы на наивной реализации решета Эратосфена, которая заполняет память (массив) нулями и единицами, обозначая простые числа нулём. Процедурный код алгоритма приведём на языке javascript:
var memSize = 65536;
var arr = [];
for (var i = 0; i < memSize; i++)
arr.push(0);
function sieve()
{
var n = 2;
while (n*n < memSize)
{
if (!arr[n])
{
var k = n;
while (k < memSize)
{
k+=n;
arr[k] = 1;
}
}
n++;
}
}Алгоритм сразу немного оптимизирован. Тут исключено дурное шагание по уже заполненным ячейкам памяти. Мой ангел-математик не согласился на действительно наивную версию из примера в проекте PorosenokVM, поскольку эта оптимизация стоит всего пяти инструкций стекового языка. Вот как алгоритм переводится на monopig:
sieve = push 2 <>
while (dup <> dup <> mul <> push memSize <> lt)
(dup <> get <> branch mempty fill <> inc) <>
pop
fill = dup <> dup <> add <>
while (dup <> push memSize <> lt)
(dup <> push 1 <> swap <> put <> exch <> add) <>
popА вот как можно записать эквивалентную реализацию этого алгоритма на идиоматичном Haskell, с использованием тех же типов, что и в monopig:
sieve' :: Int -> Vector Int -> Vector Int
sieve' k m
| k*k < memSize =
sieve' (k+1) $ if m ! k == 0 then fill' k (2*k) m else m
| otherwise = m
fill' :: Int -> Int -> Vector Int -> Vector Int
fill' k n m
| n < memSize = fill' k (n+k) $ m // [(n,1)]
| otherwise = mЗдесь используется тип Data.Vector и инструменты для работы с ним, не слишком обычные для повседневной работы в Haskell. Выражение m ! k возвращает k-тый элемент вектора m, а m // [(n,1)] — устанавливает элементу с номером n значение 1. Пишу это здесь, потому что мне пришлось лезть за ними в справку, притом, что я работаю в Haskell едва ли не каждый день. Дело в том, что структуры с произвольным доступом в функциональной реализации неэффективны и по этой причине нелюбимы.
По условиям соревнования, заданным в статье про поросёнка, алгоритм прогоняется 100 раз. А чтобы отвязаться от конкретного компьютера, давайте сравнивать скорости выполнения этих трёх программ, отнеся их к производительности программы на javascript, прогонявшейся в Chrome.
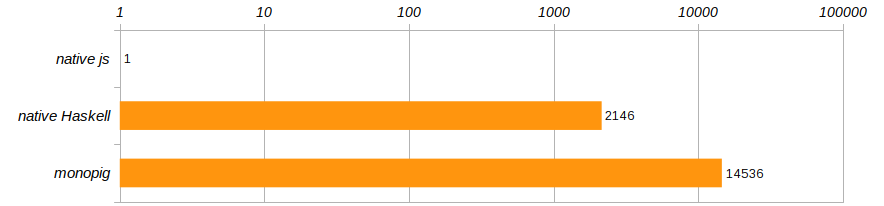
Ужас-ужас!!! Мало того, что monopig тормозит безбожно, так ещё и нативная версия не многим лучше! Haskell, конечно, крут, но не настолько же, чтобы уступать программе, выполняемой в браузере?! Как учат нас коучи — так дальше жить нельзя, пора выходить из зоны комфорта, которую нам предоставляет Haskell!
Преодолеваем лень
Давайте разбираться. Для этого скомпилируем программу на monopig с флагом -rtsopts для ведения учёта статистики времени выполнения и посмотрим что нам стоит прогнать решето Эратосфена один раз:
$ ghc -O -rtsopts ./Monopig4.hs
[1 of 1] Compiling Main ( Monopig4.hs, Monopig4.o )
Linking Monopig4 ...
$ ./Monopig4 -RTS -sstderr
"Ok"
68,243,040,608 bytes allocated in the heap
6,471,530,040 bytes copied during GC
2,950,952 bytes maximum residency (30667 sample(s))
42,264 bytes maximum slop
15 MB total memory in use (7 MB lost due to fragmentation)
Tot time (elapsed) Avg pause Max pause
Gen 0 99408 colls, 0 par 2.758s 2.718s 0.0000s 0.0015s
Gen 1 30667 colls, 0 par 57.654s 57.777s 0.0019s 0.0133s
INIT time 0.000s ( 0.000s elapsed)
MUT time 29.008s ( 29.111s elapsed)
GC time 60.411s ( 60.495s elapsed) <-- утечка времени здесь!
EXIT time 0.000s ( 0.000s elapsed)
Total time 89.423s ( 89.607s elapsed)
%GC time 67.6% (67.5% elapsed)
Alloc rate 2,352,591,525 bytes per MUT second
Productivity 32.4% of total user, 32.4% of total elapsedПоследняя строчка говорит нам, что программа занималась продуктивными вычислениями лишь треть времени. Всё остальное время по памяти бегал сборщик мусора и убирался за ленивыми вычислениями. Сколько раз нам повторяли в детстве, что лениться нехорошо! Здесь главная особенность Haskell оказала нам дурную услугу, пытаясь создать несколько миллиардов отложенных трансформаций вектора и стека.
Ангел-математик в этом месте воздымает палец и радостно рассказывает о том, что ещё со времён Алонзо Чёрча, существует теорема, утверждающая, что стратегия вычислений не влияет на их результат, а значит, мы вольны в её выборе из соображений эффективности. Поменять вычисления на строгие совсем несложно — ставим знак ! в объявлении типа стека и памяти и тем самым делаем эти поля строгими.
data VM a = VM { stack :: !Stack
, status :: Maybe String
, memory :: !Memory
, journal :: !a }Ничего больше менять не будем и сразу проверим результат:
$ ./Monopig41 +RTS -sstderr
"Ok"
68,244,819,008 bytes allocated in the heap
7,386,896 bytes copied during GC
528,088 bytes maximum residency (2 sample(s))
25,248 bytes maximum slop
16 MB total memory in use (14 MB lost due to fragmentation)
Tot time (elapsed) Avg pause Max pause
Gen 0 129923 colls, 0 par 0.666s 0.654s 0.0000s 0.0001s
Gen 1 2 colls, 0 par 0.001s 0.001s 0.0006s 0.0007s
INIT time 0.000s ( 0.000s elapsed)
MUT time 13.029s ( 13.048s elapsed)
GC time 0.667s ( 0.655s elapsed)
EXIT time 0.001s ( 0.001s elapsed)
Total time 13.700s ( 13.704s elapsed)
%GC time 4.9% (4.8% elapsed)
Alloc rate 5,238,049,412 bytes per MUT second
Productivity 95.1% of total user, 95.1% of total elapsedПродуктивность существенно выросла. Общие затраты памяти всё равно остались внушительными из-за неизменяемости данных, но главное, теперь, когда мы ограничили ленивость данных, у сборщика мусора появилась возможность лениться, на его долю осталось лишь 5% всей работы. Заносим новую запись в рейтинг.

Ну, что же, строгие вычисления приблизили нас по скорости к работе нативного кода Haskell, который позорно тормозит безо всякой виртуальной машины. Это значит, что накладные расходы на использование неизменяемого вектора существенно превосходят расходы на содержание стековой машины. И это значит, что пора распрощаться с неизменяемостью памяти.
Впускаем изменения в жизнь
Тип Data.Vector хорош, но используя его, мы тратим кучу времени на копирование, во имя сохранения чистоты вычислительного процесса. Заменив его на тип Data.Vector.Unpacked мы, хотя бы экономим на упаковке структуры, но это принципиально не меняет картину. Правильным решением было бы вывести память из состояния машины и обеспечить доступ к внешнему вектору, воспользовавшись категорией Клейсли. При этом наряду с чистыми векторами, можно использовать так называемые изменяемые (мутабельные) векторы Data.Vector.Mutable.
Подключим соответствующие модули и подумаем, как нам иметь дело с изменяемыми данными в чистой функциональной программе.
import Control.Monad.Primitive
import qualified Data.Vector.Unboxed as V
import qualified Data.Vector.Unboxed.Mutable as MЭти грязные типы, как полагается, изолируются от чистой публики. Они содержатся в монадах класса PrimMonad (к ним относятся ST или IO), куда чистые программы аккуратно просовывают им инструкции к действиям, написанные кристальным функциональным языком на драгоценном пергаменте. Таким образом, поведение этих нечистых животных определяется строго правоверными сценариями и не представляет опасности. Не все программы для нашей машины используют память, так что обрекать на погружение в монаду IO всю архитектуру нет необходимости. Наряду с чистым подмножеством языка monopig мы создадим четыре инструкции, обеспечивающие обращение к памяти и только они будут иметь доступ к опасной территории.
Тип чистой машины становится короче:
data VM a = VM { stack :: !Stack
, status :: Maybe String
, journal :: !a }Конструкторы программ и сами программы этого изменения почти не заметят, но поменяются их типы. Кроме того, имеет смысл определить несколько типов-синонимов для упрощения сигнатур.
type Memory m = M.MVector (PrimState m) Int
type Logger m a = Memory m -> Code -> VM a -> m (VM a)
type Program' m a = Logger m a -> Memory m -> Program m aУ конструкторов появится ещё один аргумент, представляющий доступ к памяти. Существенно поменяются исполнители, особенно, ведущие журнал вычислений, ведь теперь им нужно испрашивать у изменяемого вектора его состояние. Полный код можно увидеть и изучить в репозитории, а здесь я приведу самое интересное: реализацию базовых компонент для работы с памятью, чтобы показать как это делается.
geti :: PrimMonad m => Int -> Program' m a
geti i = programM (GETI i) $
\mem -> \s -> if (0 <= i && i < memSize)
then \vm -> do x <- M.unsafeRead mem i
setStack (x:s) vm
else err "index out of range"
puti :: PrimMonad m => Int -> Program' m a
puti i = programM (PUTI i) $
\mem -> \case (x:s) -> if (0 <= i && i < memSize)
then \vm -> do M.unsafeWrite mem i x
setStack s vm
else err "index out of range"
_ -> err "expected an element"
get :: PrimMonad m => Program' m a
get = programM (GET) $
\m -> \case (i:s) -> \vm -> do x <- M.read m i
setStack (x:s) vm
_ -> err "expected an element"
put :: PrimMonad m => Program' m a
put = programM (PUT) $
\m -> \case (i:x:s) -> \vm -> M.write m i x >> setStack s vm
_ -> err "expected two elemets"Демон-оптимизатор предложил сразу ещё немного сэкономить на проверке допустимых значений индекса в памяти, ведь для команд puti и geti индексы известны на этапе создания программы и неверные значения можно отсеять заранее. Динамически определяемые индексы для команд put и get не гарантируют безопасности и ангел-математик не разрешил в них проводить опасные обращения.
Вся эта возня с выведением памяти в отдельный аргумент кажется сложной. Но она очень чётко показывает изменяемым данным их место — они должны быть снаружи. Напоминаю, что мы пытаемся провести в стерильную лабораторию разносчика пиццы с пиццей. Чистые функции знают что с ними делать, но эти объекты никогда не станут гражданами первого класса, и готовить пиццу прямо в лаборатории не стоит.
Давайте проверим что мы купили этими изменениями:
$ ./Monopig5 +RTS -sstderr
"Ok"
9,169,192,928 bytes allocated in the heap
2,006,680 bytes copied during GC
529,608 bytes maximum residency (2 sample(s))
25,248 bytes maximum slop
2 MB total memory in use (0 MB lost due to fragmentation)
Tot time (elapsed) Avg pause Max pause
Gen 0 17693 colls, 0 par 0.094s 0.093s 0.0000s 0.0001s
Gen 1 2 colls, 0 par 0.000s 0.000s 0.0002s 0.0003s
INIT time 0.000s ( 0.000s elapsed)
MUT time 7.228s ( 7.232s elapsed)
GC time 0.094s ( 0.093s elapsed)
EXIT time 0.000s ( 0.000s elapsed)
Total time 7.325s ( 7.326s elapsed)
%GC time 1.3% (1.3% elapsed)
Alloc rate 1,268,570,828 bytes per MUT second
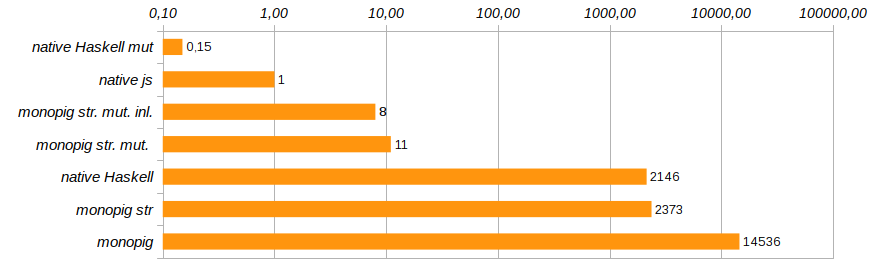
Productivity 98.7% of total user, 98.7% of total elapsedВот это уже прогресс! В восемь раз сократилось использование памяти, в 180 раз увеличилась скорость выполнения программы, а сборщик мусора остался почти совсем без работы.

В рейтинге появилось решение monopig st. mut., которое медленнее нативного решения на js в десять раз, но кроме него и нативное решение на Haskell, использующее изменяемые векторы. Вот его код:
fill' :: Int -> Int -> Memory IO -> IO (Memory IO)
fill' k n m
| n > memSize-k = return m
| otherwise = M.unsafeWrite m n 1 >> fill' k (n+k) m
sieve' :: Int -> Memory IO -> IO (Memory IO)
sieve' k m
| k*k < memSize =
do x <- M.unsafeRead m k
if x == 0
then fill' k (2*k) m >>= sieve' (k+1)
else sieve' (k+1) m
| otherwise = return mЗапускается он следующим образом
main = do m <- M.replicate memSize 0
stimes 100 (sieve' 2 m >> return ())
print "Ok" И теперь Haskell наконец показывает, что он не игрушечный язык. Просто нужно его с умом использовать. Кстати, в приведённом коде используется то, что тип IO () образует полугруппу с операцией последовательного выполнения программ (>>), и с помощью stimes мы повторили 100 раз вычисления тестовой задачи.
Теперь понятно, отчего происходит такая нелюбовь к функциональным массивам и почему никто не помнит, как с ними работать: как только Haskell-программисту становятся всерьёз нужны структуры с произвольным доступом, он переориентируется на изменяемые данные и работает в монадах ST или IO.
Выведение в особую зону части команд ставит под вопрос законность изоморфизма кодпрограмма. Ведь мы не можем одновременно превращать код и в чистые программы и в монадические, это не разрешает делать система типов. Однако классы типов достаточно гибки для того, чтобы этот изоморфизм существовал. Гомоморфизм кодпрограмма теперь разбивается на несколько гомоморфизмов для разных подмножеств языка. Как именно это сделано, можно увидеть в полном [коде]() программы.
Не останавливайся на достигнутом
Ещё немного изменить продуктивность программы поможет исключение лишних вызовов функций и встраивание их кода непосредственно с помощью прагмы {-# INLINE #-}. Этот способ непригоден для рекурсивных функций, но отлично подходит для базовых компонентов и функций-сеттеров. Он уменьшает время выполнения тестовой программы ещё на 25% (см. Monopig51.hs).
Следующим разумным шагом будет избавление от инструментов логирования тогда, когда необходимости в них нет. На этапе формирования эндоморфизма, представляющего программу, мы используем внешний аргумент, который определяем при запуске. Умные конструкторы program и programM можно предупредить о том, что аргумента-логгера может не быть. В этом случае код преобразователя не содержит ничего лишнего: только функционал и проверку статуса машины.
program code f = programM code (const f)
programM code f (Just logger) mem = Program . ([code],) . ActionM $
\vm -> case status vm of
Nothing -> logger mem code =<< f mem (stack vm) vm
_ -> return vm
programM code f _ mem = Program . ([code],) . ActionM $
\vm -> case status vm of
Nothing -> f mem (stack vm) vm
_ -> return vmТеперь функции-исполнители должны явно указывать наличие или отсутствие логгирования не при помощи заглушки none, а пользуясь типом Maybe (Logger m a). Почему это должно сработать, ведь о том есть логгирование или нет, компоненты программ узнают "в последний момент", перед самым выполнением? Разве не будет ненужный код вшит на этапе формирования композиции программ? Haskell — ленивый язык и тут это играет нам на руку. Именно перед выполнением и формируется окончательный код, оптимизированный под конкретную задачу. Эта оптимизация сократила время выполнения программы ещё на 40% (см. Monopig52.hs).
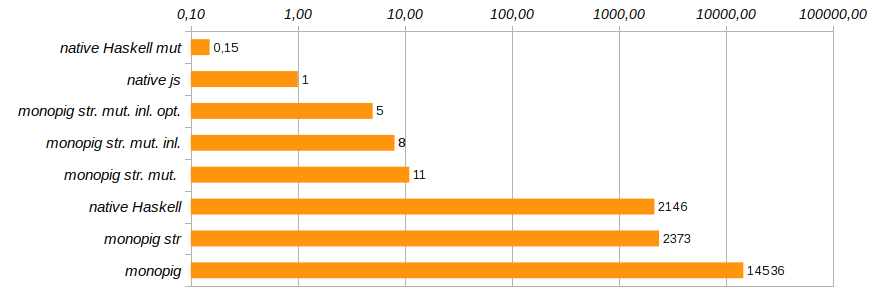
На этом мы завершим работу над ускорением моноидального поросёнка. Он уже достаточно шустро носится, чтобы и ангел и демон могли успокоиться. Это, конечно, не C, у нас всё ещё используется чистый список в качестве стека, но замена его на массив приведёт к основательному перелопачиванию кода, и отказу от использования элегантных шаблонов в определениях базовых команд. Мне же хотелось обойтись минимальными изменениями и, в основном, на уровне типов.
Некоторые проблемы остаются при ведении журнала. Простой подсчёт числа шагов или использования стека работают неплохо (мы сделали поле журнала строгим), но их объединение в пару уже начинает кушать память, приходится возиться с пинками с помощью seq, что уже изрядно раздражает. Но, скажите, кто будет логировать 14 миллиардов шагов, если отладить задачу можно на первых сотнях? Так что тратить своё время на ускорение ради ускорения я уже не буду.
Осталось лишь добавить, что в статье про поросёнка, в качестве одного из методов оптимизации вычислений, приводится трассировка: выделение линейных участков кода, трасс, внутри которых вычисления можно производить минуя главный цикл диспетчеризации команд (блок switch). В нашем случае, моноидальная композиция компонентов программы создаёт такие трассы либо во время формирования программы из компонентов EDSL, либо при работе гомоморфизма fromCode. Этот способ оптимизации достаётся нам бесплатно, так сказать, по построению.
В экосистеме Haskell существует много изящных и быстрых решений, таких как потоки Conduits или Pipes, есть отличные замены типу String и шустрые создатели XML, такие как blaze-html, а парсер attoparsec — это эталон комбинаторного анализа для LL(?)-грамматик. Всё это нужно для нормальной работы. Но ещё нужнее — исследования, приводящие к этим решениям. Haskell был и остаётся исследовательским инструментом, удовлетворяющим специфическим требованиям, не нужным широкой публике. Я видел на Камчатке, как асы на вертолёте Ми-4 закрывали на спор коробок спичек, надавливая на него колесом шасси, вися в воздухе. Это можно сделать, и это классно, но не нужно.
Но, всё-таки, это классно!!
Комментарии (25)

samsergey Автор
26.11.2018 03:16+1Полумёртвый? Вы серьёзно? Язык жив, пока выходят новые версии трансляторов и библиотек, пока есть ниша, в которой он играет главную роль и пока есть сообщество, им пользующееся. Спешу вас обрадовать, с этим у Haskell всё хорошо.
- Загляните на сайт Haskell Weekly где каждую неделю приводятся по два десятка новых (лучших) статей с разных ресурсов, по тридцать конференций во всём мире — еженедельно!
- Новая версия ghc вышла только в ноябре.
- Основной репозиторий Hackage стабильно пополняется.
- Существует вполне отчётливое видение развития языка.
- Два года назад вышла блестящая книга Haskell programming from the first principles, поднимающая преподавание ФП на новый уровень.
- Reddit-сообщество включает в себя более 30 тыс. участников и растёт, производная не велика, но положительна.
- Существует активное русскоязычное сообщество.
- Наконец, подавляющее большинство научных статей в области ФП и теории типов формулируются с помощью Haskell.
Со своей ролью языка исследований в этой области он справляется блестяще! А вот Prolog, увы, действительно, полужив-полумёртв, хотя буду рад ошибиться.
oleg-x2001
26.11.2018 11:36+2Ну нельзя же принимать так близко к сердцу такие очевидно нелепые высказывания (про «полумертвый Хаскель»). Тот кто это написал или тролль, или просто очень недалекий человек, обиженный на то что не смог осилить.
samsergey Автор
26.11.2018 11:45+1Зато какой прекрасный повод сделать современный дайджест в этой области! Тема на статью не тянет, а обратить внимание хочется. Понятно, что каждый варится в своей отрасли и отслеживает свои новости. Я, правда, был бы рад узнать, что творится в мире логического программирования в подобной сводке.
valdemartorch
26.11.2018 11:47видение развития языка
Мало кому это интересно.JC_IIB
26.11.2018 11:59Мало кому это интересно.
Ну, наверное, вы сможете подтвердить свои слова статистикой, если так уверенно утверждаете про мало кому? Цифрами там, ссылками, исследованиями, не?valdemartorch
26.11.2018 12:27Вас забанили в поисковых системах или вы не самостоятельный в силу возраста или физических особенностей?
VlK
26.11.2018 11:47Я очень люблю первые комментарии на Хабре под любой статьей. Немного напоминают комментарии на Ютубе в смысле доброжелательности и компетентности :-)
Пролог, кстати, в каком-то смысле живее всех живей. Как язык общего назначения он, конечно, не зашел, но совершенно точно сильно повлиял на многие другие языки.
VlK
26.11.2018 11:16+1очень рад, что сумел привлечь внимание к стековым машинам и теме своими статьями :-) Спасибо, я с удовольствием почитал обе ваши статьи.
Признаться, меня виртуальные машины в общем заинтересовали немного с другой стороны — как повод погрузиться в общение с физическими машинами, их регистрами, хитрыми наборами инструкций, внеочередным исполнением и т.д. Если Хаскелл — свобода мысли, то Си и виртуальные машины — свобода от высокоуровневых абстракций, за которыми не видно процессора и иже с ним.
В любом случае интересно, что к тем же вопросам можно подойти с совершенно другой стороны!samsergey Автор
26.11.2018 11:48Это всегда здорово: выйти на знакомую площадь новым путём — так по-настоящему узнаётся город. Я грущу, когда противопоставляют абстракции и нечто "реальное". В такой позиции не видно общей картины, а без этого не заглянуть глубже ни в абстракции, ни в реальность.
VlK
26.11.2018 11:52Почему же именно противоставляются? Абстракции полезны, очень нужны и без них — никуда. Те же парсеры на языках из семейства ML делаются не в пример удобней, чем на потомках Алгола.
Но, согласитесь, в Хаскелле трудно учесть число вычислительных блоков процессора при развертывании цикла!
amarao
26.11.2018 14:01У Си модель памяти отличается от модели памяти процессора. Хотя бы потому, что процессоры разные, а Си одинаковый. Попытка писать на Си для unreal mode, например, почти гарантировано обречена на провал.
VlK
26.11.2018 14:36Если вы про то, что у современных настольных x86-ых процессоров 5 видов памяти (винт, оперативная память, три слоя кеша), а Си из них видит только 2 (оперативная память и винт), то да, конечно, это в модели видно плохо.
Это и на ассемблере не особо заметно будет.
Режим процессора unreal я, признаться, с детства не встречал.amarao
26.11.2018 15:25Это специальный режим работы процессора, когда память не настроена. Задача кода — настроить память. Можно использовать только ппзу и кеш как стек (вроде бы, как стек — могу путаться). Ну и регистры.
Плюс такой же режим у процессора при входе в код обработки SMM.
Вообще, я не понимаю какой операцией в Си производится смена 16-битного режима (real) в 32-битный, например. Все указатели становятся тыквой — и язык этого не понимает.VlK
26.11.2018 15:32я понимаю, что это за режим :-)
Но требовать от любого языка (в случае) общего назначения поддержки специальных режимов работы каждого из существующих процессоров — странно. Подозреваю (т.е. точно знаю), что в популярных ОС те небольшие участки кода, где это реально требуется, пишутся на ассемблере.amarao
26.11.2018 15:37Разумеется, на ассемблере. Я просто возмутился тезисом, что «Си и виртуальные машины — свобода от высокоуровневых абстракций, за которыми не видно процессора и иже с ним.»
В Си тоже не видно.VlK
26.11.2018 15:40Тогда можно сказать, что процессор плохо видно даже из ассемблера, т.к. микрокод писать все равно низя :-) Си тут относительно немного слоев добавляет.
Думаю, вы поняли, о чем именно я говорил. :-)
mayorovp
26.11.2018 19:38Превращение указателей в тыкву как раз не беда, «лечится» барьером памяти и аккуратностью программиста. Смена модели памяти, да и в принципе существование сразу двух моделей памяти в одной программе куда серьезнее.
valdemartorch
Приятно видеть, что кто то еще пытается реанимировать полумертвый Хаскел.
VlK
Чувствую, вы не Хабре не задержитесь :-)