
Если да — то вы уже представляете, что вам придётся написать что-то вроде такого, только хуже
SELECT hour(datetime), somename, count(*), sum(somemetric)
from table
where datetime > :monthAgo
group by 1, 2
order by 1 desc, 2Время от времени самые разнообразные подобные запросы начинают появляться, и если один раз стерпишь и поможешь — увы, обращения будут поступать и в будущем.
А плохи такие запросы тем, что хорошо отнимают ресурсы системы на время выполнения, да и данных может быть так много, что даже реплику для таких запросов будет жаль (и своего времени).
А что если я скажу, что прямо в PostgreSQL можно создать вьюху, которая на лету будет учитывать только новые поступающие данные в прямо подобном запросе, как выше?
Так вот — это умеет делать расширение PipelineDB

Ранее PipelineDB был отдельным проектом, но теперь доступен как расширение для PG 10.1 и выше.
И хотя предоставляемые возможности уже давно существуют в иных продуктах, специально созданных для сбора метрик в режиме реального времени — у PipelineDB есть существенный плюс: меньший порог вхождения для разработчиков, которые уже умеют SQL).
Возможно для кого-то это несущественно. Лично я не ленюсь пробовать всё, что кажется подходящим для решения той или иной задачи, но и не двину тут же юзать одно новое решение на все случаи. Потому в этой заметке я не призываю тут же бросать всё и устанавливать PipelineDB, это лишь обзор основного функционала, т.к. штука мне показалась любопытной.
И так, в целом документация у них хорошая, но я хочу поделиться опытом, как это дело попробовать на практике и вывести результаты в Grafana.
Чтобы не захламлять локальную машину всё разворачиваю в докере.
Используемые образы:
postgres:latest, grafana/grafanaУстановка PipelineDB на Postgres
На машине с postgres выполнить последовательно:
apt updateapt install curlcurl -s http://download.pipelinedb.com/apt.sh | bashapt install pipelinedb-postgresql-11cd /var/lib/postgresql/data- Открыть в любом редакторе файл
postgresql.conf - Найти ключ
shared_preload_libraries, расскоментить и установить значениеpipelinedb - Ключ
max_worker_processesустановить в значение 128 (рекомендация доки) - Ребутнуть сервер
Создание потока и вьюх в PipelineDB
- Бд в которой будем работать:
CREATE DATABASE testpipe; - Создание расширения:
CREATE EXTENSION pipelinedb; - Теперь самое интересное — создание стрима. Именно в него необходимо добавлять данные для дальнейшей обработки:
CREATE FOREIGN TABLE flow_stream ( dtmsk timestamp without time zone, action text, duration smallint ) SERVER pipelinedb;
По сути очень похоже на создание обыкновенной таблицы, только получить данные из этого стрима простымselectнельзя — нужна вьюха - собственно как её создать:
CREATE VIEW viewflow WITH (ttl = '3 month', ttl_column = 'm') AS select minute(dtmsk) m, action, count(*), avg(duration)::smallint, min(duration), max(duration) from flow_stream group by 1, 2;
Называются они Continuous Views и по дефолту materialize, т.е. с сохранением состояния.
В выраженииWITHпередаются дополнительные параметры.
В моём случаеttl = '3 month'говорит о том, что хранить нужно данные только за последние 3 месяца, а брать дату/время из колонкиM. Фоновый процессreaperищет устаревшие данные и удаляет их.
Для тех, кто не в курсе — функцияminuteвозвращает дату/время без секунд. Таким образом все события, произошедшие в одну минуту будут иметь одно и то же время в результате агрегации. - Такая вьюха — практически таблица, потому индекс по дате для выборки будет полезным, если данных будет храниться много
create index on viewflow (m desc, action);
Использование PipelineDB
Помни: вставлять данные в стрим, а читать — из подписавшихся на него вьюх
insert into flow_stream VALUES (now(), 'act1', 21);
insert into flow_stream VALUES (now(), 'act2', 33);
select * from viewflow order by m desc, action limit 4;
select now()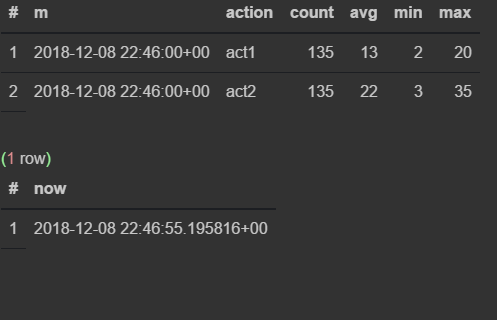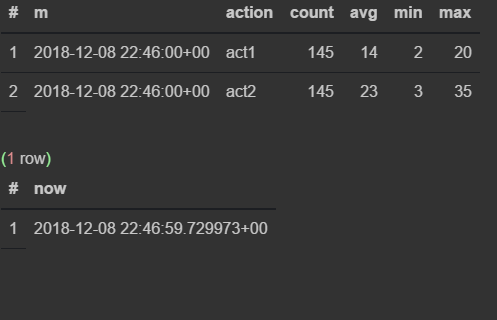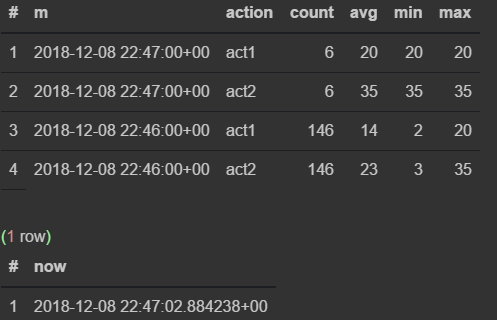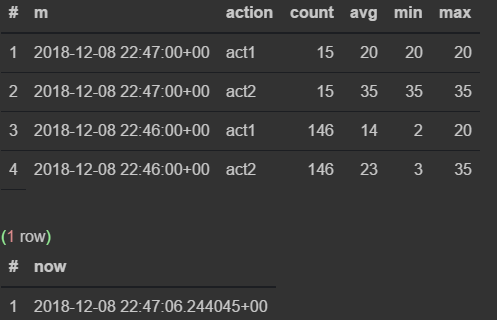
Как только наступает 47-я — предыдущая прекращает обновляться и начинает тикать текущая минута.
Если обратить внимание на план запроса, то можно увидеть оригинальную таблицу с данными
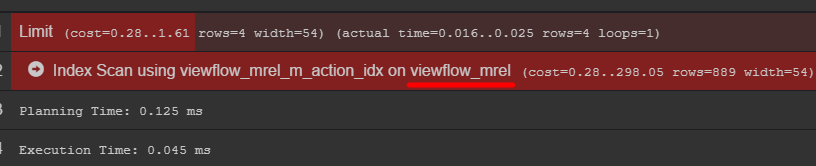
Рекомендую сходить в неё и узнать, как на самом деле хранятся ваши данные
using Npgsql;
using System;
using System.Threading;
namespace PipelineDbLogGenerator
{
class Program
{
private static Random _rnd = new Random();
private static string[] _actions = new string[] { "foo", "bar", "yep", "goal", "ano" };
static void Main(string[] args)
{
var connString = "Host=localhost;port=5432;Username=postgres;Database=testpipe";
using (var conn = new NpgsqlConnection(connString))
{
conn.Open();
while (true)
{
var dt = DateTime.UtcNow;
using (var cmd = new NpgsqlCommand())
{
var act = GetAction();
cmd.Connection = conn;
cmd.CommandText = "INSERT INTO flow_stream VALUES (@dtmsk, @action, @duration)";
cmd.Parameters.AddWithValue("dtmsk", dt);
cmd.Parameters.AddWithValue("action", act);
cmd.Parameters.AddWithValue("duration", GetDuration(act));
var res = cmd.ExecuteNonQuery();
Console.WriteLine($"{res} {dt}");
}
Thread.Sleep(_rnd.Next(50, 230));
}
}
}
private static int GetDuration(string act)
{
var c = 0;
for (int i = 0; i < act.Length; i++)
{
c += act[i];
}
return _rnd.Next(c);
}
private static string GetAction()
{
return _actions[_rnd.Next(_actions.Length)];
}
}
}Вывод в Grafana
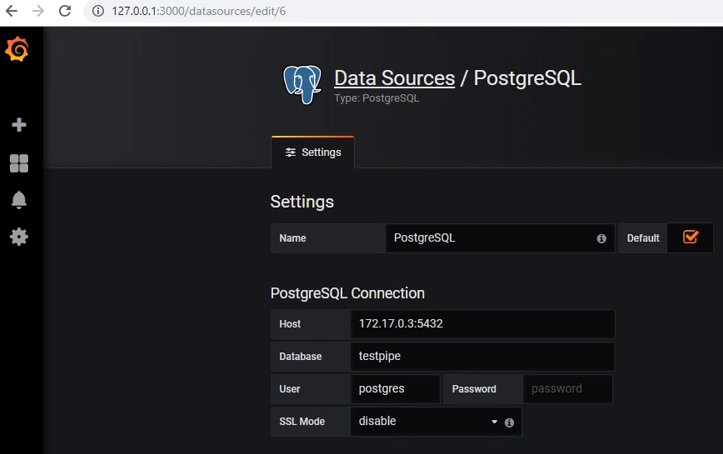
Для получения данных из postgres нужно добавить соответствующий источник данных:
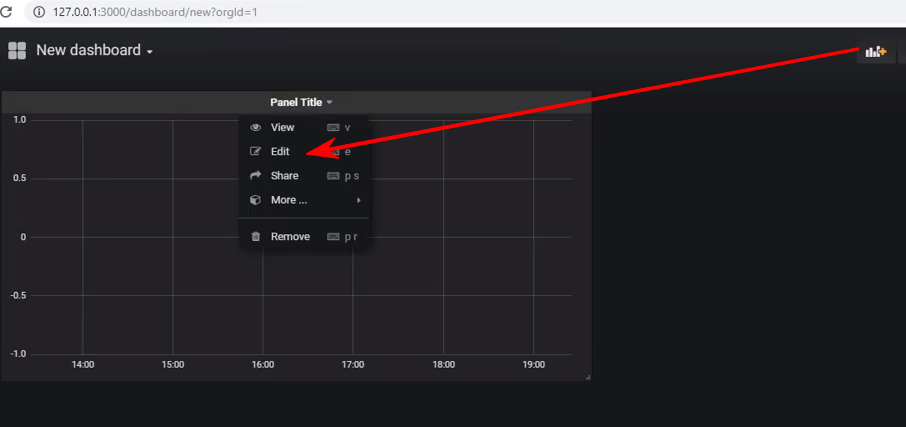
Создать новую дашборду и добавить на неё панель типа Graph, а после нужно перейти в редактирование панели:
Далее — выбрать источник данных, переключиться в режим написания sql-запроса и ввести такое:
select
m as time, -- Grafana требует колонку time
count, action
from viewflow
where $__timeFilter(m) -- макрос графаны, принимает на вход имя колонки, на выходе col between :startdate and :enddate
order by m desc, action;И тут же получается нормальный график, конечно, если вы запустили генератор событий
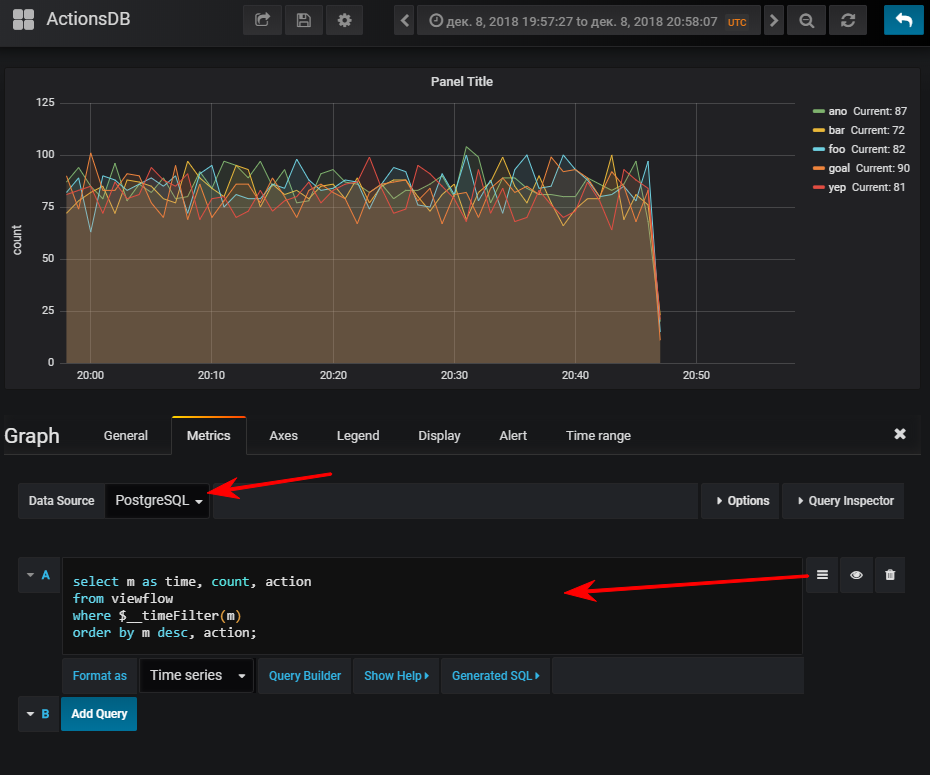
FYI: наличие индекса может оказаться очень важным. Хотя его использование зависит от объёма получившейся таблицы. Если вы планируете хранить небольшое количество строк за небольшое количество времени, то очень легко может оказаться, что seq scan будет дешевле, а индекс лишь добавит доп. нагрузку при обновлении значений
На один стрим может быть подписано несколько вьюх.
Допустим я хочу видеть сколько выполняются методы апи в разрезе по процентилям
CREATE VIEW viewflow_per WITH (ttl = '3 d', ttl_column = 'm') AS
select minute(dtmsk) m,
action,
percentile_cont(0.50) WITHIN GROUP (ORDER BY duration)::smallint p50,
percentile_cont(0.95) WITHIN GROUP (ORDER BY duration)::smallint p95,
percentile_cont(0.99) WITHIN GROUP (ORDER BY duration)::smallint p99
from flow_stream
group by 1, 2;
create index on viewflow_per (m desc);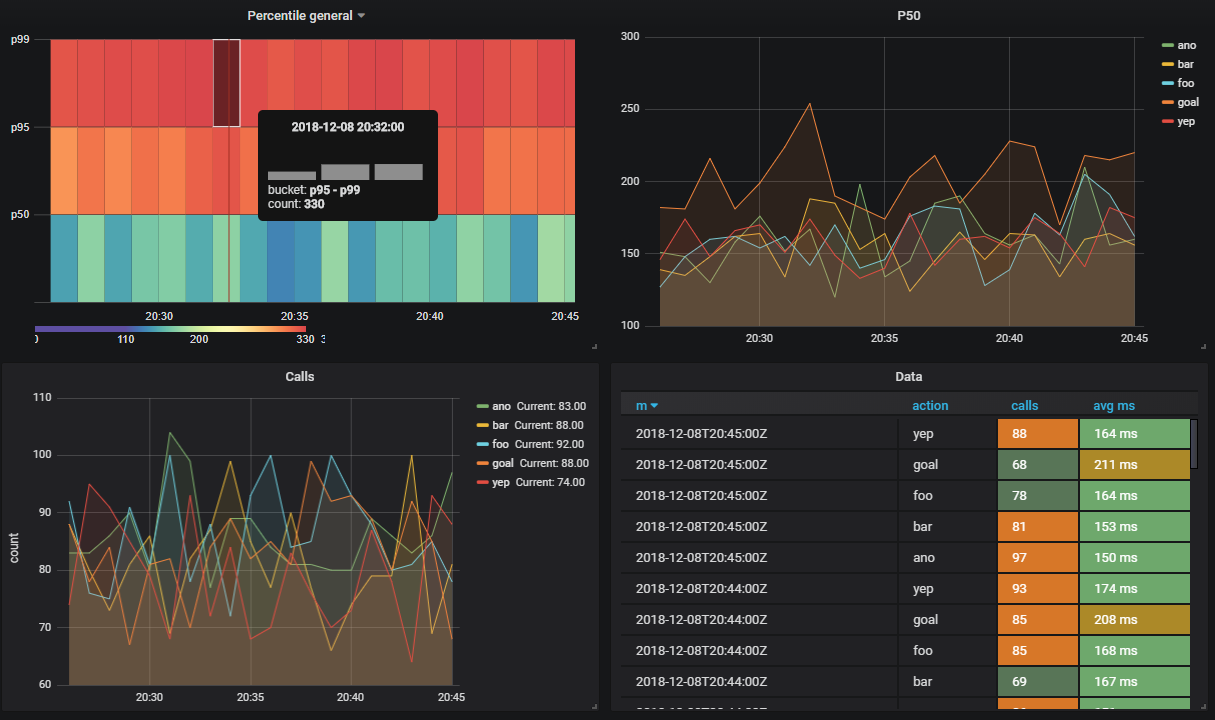
Итого
В целом штука рабочая, вела себя хорошо, без нареканий. Хотя под докером загрузка их демо базы в архиве (2.3 гб) оказалась малость долгим делом.
Хочу заметить — я не проводил нагрузочные тесты.
Официальная документация
Может быть интересным
- Поддержка загрузки данных из Apache Kafka в стримы
- Аналогично с Amazon Kinesis
- Можно создавать вьюхи только для трансформации данных (без хранения)
- PipelineDB Cluster — имеется комерческая версия. В ней можно распределять вьюхи по шардам. Подробнее в доке по кластерному решению
Комментарии (24)

Tantrido
10.12.2018 08:22Интересно: а это расширение может помочь, если данные будут в основном в JSONB поле?
SanSYS Автор
10.12.2018 08:59Типа того?
select minute(eventtime) as time, sum((data->>'value')::integer) as sum from table1
Не вижу проблем с таким вариантом, хотя не пробовал
Тут же суть в том, что расширение организует поточную обработку данных
т.е.: приходят данные, возможно накапливаются в каком-то буфере, в фоне выполняется запрос из вьюхи над новыми данными, далее — результат вставляется в результирующую таблицу, либо — дополяет старые данные
И чисто теоретически не сильно важно, какого типа данные гоняются от потока до вьюхи, потому что вы сами же с ними и работаете весьма прозрачным образом
Например если у вас в jsonb хранится массив объектов и хотите именно его обрабатывать «в потоке», то можно сделать трансформацию разложив массив на строки и… работать как с обычной таблицейTantrido
10.12.2018 09:03А можно JSONB разложить в представление (view)?
Envek
10.12.2018 17:10Один JSON-объект можно разложить в запись с помощью
jsonb_to_record, а массив — с помощьюjsonb_to_recordset. См. официальную документацию и мой пример.
SanSYS Автор
10.12.2018 18:03Как подсказали выше, вот так
select * from jsonb_to_recordset( '[{"a":1,"b":"foo"},{"a":"2","c":"bar", "v":"2018-04-01"}]'::jsonb ) as x(a int, b text, v date, not_exists time);Tantrido
11.12.2018 00:48Это простенький JSON, а если сложный иерархический, но структура более менее постоянна.
Envek
12.12.2018 19:12+1Можно вытаскивать нужный кусок JSONB и скармливать его это же функции, на ходу подправляя, если требуется.
Вот, например, если у нас есть таблицаlistings, у которой есть jsonb-полеraw, где-то в недрах которого лежит нужный нам массив (а иногда не массив):
SELECT id, v."SKU" FROM listings, jsonb_to_recordset( CASE jsonb_typeof(raw->'Variations'->'Variation') WHEN 'array' THEN raw->'Variations'->'Variation' ELSE jsonb_build_array(raw->'Variations'->'Variation') END ) AS v("SKU" varchar) WHERE raw IS NOT NULL AND raw->'Variations'->'Variation' IS NOT NULL
UncleAndy
10.12.2018 11:10Т.е. эта система потокобезопасная и лишена дедлоков при наличии вставок через несколько подключений к БД?
SanSYS Автор
10.12.2018 18:21Не знаю
Уверен, что при простом использовании стримов и вьюх — всё будет ок
Но если использовать вызовы различных кастомных методов, то внутри можно написать любуую логику и да — монжо словить классический дедлок, всё как всегда
У них в репе issues имеют метку deadlock, но они скорее не к экстеншену для postgres
SergeyGershkovich
10.12.2018 11:58А где в статье связь между запросом
SELECT hour(datetime), somename, count(*), sum(somemetric) from table where datetime > :monthAgo group by 1, 2 order by 1 desc, 2
и стримомCREATE FOREIGN TABLE flow_stream ( dtmsk timestamp without time zone, action text, duration smallint ) SERVER pipelinedb;
Я так понимаю, в «table» нужно триггер или правило добавлять, чтобы заливать данные в «flow_stream»?VJean
10.12.2018 12:17PipelineDB можно рассматривать как таблицы с интегрированными триггерами.
SergeyGershkovich
10.12.2018 13:00Мне очень понравился первый абзац:
Вас когда-либо просили посчитать количество чего-то на основании данных в бд за последний месяц, сгруппировав результат по каким-то...
Что если у меня уже есть Postgres DB со своими таблицами, к которым требуется писать множество агрегатных запросов. Я так понимаю, чтобы использовать PipelineDB, я должен переместить таблицы в PipelineDB или написать некие правила для отправки данных из своих таблиц в PipelineDB? — этих правил в статье я не увидел.VJean
10.12.2018 15:48+1Достаточно детальный пример с примечаниями: Streaming Databases & PipelineDB: Likes Use Case
В статье много чего не описано по сравнению с официальной документацией, в том числе и про докер, т.к. готовый образ уже собран.SergeyGershkovich
10.12.2018 19:37Почитал документацию, для себя определил PipelineDB, как механизм агрегирующих счетчиков в режиме реального времени. Счетчик от потока отключил, агрегированные данные потерял.
Идея интересная, но не для случая уже хранимых данных. Удобно для данных, которые только планируется сохранять, с учетом, что счетчики должны быть включены заранее.
le1ic
10.12.2018 14:06Вечный tradeoff — тормозить чтение, или тормозить запись. Аггрегация, как я понимаю, синхронная, классическая?
Tatikoma
10.12.2018 14:19curl -s http://download.pipelinedb.com/apt.sh | bash
Очень сильно удивился увидев такую конструкцию. Открыл документацию pipelinedb и увидел там ровно такую же строчку. Выглядит очень грустно.Pinkerton42
10.12.2018 16:27Угу. В нем безапеляционно мелькают строки «apt-get install -y ...» без всяких вопросов. За такое обычно по рукам бьют.
Tatikoma
10.12.2018 17:20Это проблемы разного уровня, если я ничего не путаю.
apt-get install -y в худшем случае сломает вам систему, если у вас нет косячных репозиториев.
curl -s http | bash — в худшем случае установит вирус, который спросит права на рута и вы ему их сами предоставитеPinkerton42
10.12.2018 18:45Неважно какого уровня: это — проблема. И считаю, что да, за такое надо бить по рукам.
neenik
10.12.2018 14:58Поздно postgresql, поздно. OLAP+SQL=ClickHouse.
У нас у самих до сир пор осталось пяток самописных агрегаций в постгресе. Характеристика одним словом — неудобно.
DrAndyHunter
Спасибо за статью, буквально в пятницу узнал об этом расширении для pg. Подскажите, а для 9.6 postgresql версии как быть? Расширения нет под 9.6?
SanSYS Автор
Кажется расширения под 9.6 нет, но я не сильно искал
Как быть — заюзать уже пг 10 )Даже 11-й зарелизился
Ну или если решили, что нужно использовать PipelineDB, а хотите продолжать сидеть на 9.6, то всегда можно поднять ещё один свежий Postgres и там развлекаться