
var length = array.Length;
for (int i = 0; i < length; i++) {
//do smth
}Пишут они это в надежде ускорить цикл, думая что создавая локальную переменную избавляют CLR от необходимости вызывать каждый раз геттер для Array.Length. Я решил раз и навсегда для себя понять стоит так делать или можно сэкономить своё время и написать без временной переменной.
Для начала рассмотрим два метода на C#:
public int WithoutVariable() {
int sum = 0;
for (int i = 0; i < array.Length; i++) {
sum += array[i];
}
return sum;
}
public int WithVariable() {
int sum = 0;
int length = array.Length;
for (int i = 0; i < length; i++) {
sum += array[i];
}
return sum;
}И давайте посмотрим на код, который получается после JIT компиляции в релизе на .NET Framework 4.7.2 под LegacyJIT-x86:
| WithoutVariable() ;int sum = 0; xor edi, edi ;int i = 0; xor esi, esi ;int[] localRefToArray = this.array; mov edx, dword ptr [ecx+4] ;int arrayLength = localRefToArray.Length; mov ecx, dword ptr [edx+4] ;if (arrayLength == 0) return sum; test ecx, ecx jle exit ;int arrayLength2 = localRefToArray.Length; mov eax, dword ptr [edx+4] ;if (i >= arrayLength2) ; throw new IndexOutOfRangeException(); loop: cmp esi, eax jae 056e2d31 ;sum += localRefToArray[i]; add edi, dword ptr [edx+esi*4+8] ;i++; inc esi ;if (i < arrayLength) goto loop cmp ecx, esi jg loop ;return sum; exit: mov eax, edi |
WithVariable() ;int sum = 0; xor esi, esi ;int[] localRefToArray = this.array; mov edx, dword ptr [ecx+4] ;int arrayLength = localRefToArray.Length; mov edi, dword ptr [edx+4] ;int i = 0; xor eax, eax ;if (arrayLength == 0) return sum; test edi, edi jle exit ;int arrayLength2 = localRefToArray.Length; mov ecx, dword ptr [edx+4] ;if (i >= arrayLength2) ; throw new IndexOutOfRangeException(); loop: cmp eax, ecx jae 05902d31 ;sum += localRefToArray[i]; add esi, dword ptr [edx+eax*4+8] ;i++; inc eax ;if (i < arrayLength) goto loop cmp eax, edi jl loop ;return sum; exit: mov eax, esi |

Несложно заметить, что количество ассемблерных инструкций абсолютно одинаково — 15 штук. Причём логика этих инструкций тоже практически полностью совпадает. Есть только небольшое различие в порядке инициализации переменных и сравнении стоит ли продолжать цикл. Можно заметить, что в обоих случаях длина массива заносится в регистры два раза перед циклом:
- чтобы проверить на 0 (arrayLength);
- и во временную переменную для проверки в условии цикла (arrayLength2);
Получается, что оба вышеприведённых метода компилируются в один и тот же код, но первый пишется быстрее и явный выигрыш в скорости выполнения отсутствует.
Приведённый выше ассемблерный код навёл меня на некоторые мысли и я решил проверить ещё пару методов:
public int WithoutVariable() {
int sum = 0;
for(int i = 0; i < array.Length; i++) {
sum += array[i] + array.Length;
}
return sum;
}
public int WithVariable() {
int sum = 0;
int length = array.Length;
for(int i = 0; i < length; i++) {
sum += array[i] + length;
}
return sum;
}Теперь суммируется текущий элемент и длина массива, только в первом случае длина массива каждый раз запрашивается, а во втором сохраняется один раз в локальную переменную. Посмотрим на ассемблерный код этих методов:
| WithoutVariable() int sum = 0; xor edi, edi int i = 0; xor esi, esi int[] localRefToArray = this.array; mov edx, dword ptr [ecx+4] int arrayLength = localRefToArray.Length; mov ebx, dword ptr [edx+4] if (arrayLength == 0) return sum; test ebx, ebx jle exit int arrayLength2 = localRefToArray.Length; mov ecx, dword ptr [edx+4] if (i >= arrayLength2) throw new IndexOutOfRangeException(); loop: cmp esi, ecx jae 05562d39 int t = array[i]; mov eax, dword ptr [edx+esi*4+8] t += sum; add eax, edi t+= arrayLength; add eax, ebx sum = t; mov edi, eax i++; inc esi if (i < arrayLength) goto loop cmp ebx, esi jg loop return sum; exit: mov eax, edi |
WithVariable() int sum = 0; xor esi, esi int[] localRefToArray = this.array; mov edx, dword ptr [ecx+4] int arrayLength = localRefToArray.Length; mov ebx, dword ptr [edx+4] int i = 0; xor ecx, ecx if (arrayLength == 0) (return sum;) test ebx, ebx jle exit int arrayLength2 = localRefToArray.Length; mov edi, dword ptr [edx+4] if (i >= arrayLength2) throw new IndexOutOfRangeException(); loop: cmp ecx, edi jae 04b12d39 int t = array[i]; mov eax, dword ptr [edx+ecx*4+8] t += sum; add eax, esi t+= arrayLength; add eax, ebx sum = t; mov esi, eax i++; inc ecx if (i < arrayLength) goto loop cmp ecx, ebx jl loop return sum; exit: mov eax, esi |

Количество инструкций у этих двух методов и сами инструкции почти абсолютно одинаковые, опять различие есть только в порядке инициализации переменных и проверке на продолжение цикла. Причём можно заметить, что в расчёте sum учитывается только тот array.Length, который был взят самым первым. Очевидно что вот это:
int arrayLength2 = localRefToArray.Length;во всех четырёх методах — заинлайниная проверка на выход за пределы массива и она выполняется для каждого элемента массива.
mov edi, dword ptr [edx+4]
if (i >=arrayLength2) throw new IndexOutOfRangeException();
cmp ecx, edi
jae 04b12d39
Можно сделать уже первый вывод о том, что заводить дополнительную переменную чтобы пытаться ускорить выполнение цикла это пустая трата времени, т.к. компилятор всё сделает за нас. Заводить переменную с длиной цикла имеет смысл только чтобы увеличить читабельность кода.
Совершенно другая ситуация с ForEach. Возьмём три метода:
public int ForEachWithoutLength() {
int sum = 0;
foreach (int i in array) {
sum += i;
}
return sum;
}
public int ForEachWithLengthWithoutLocalVariable() {
int sum = 0;
foreach (int i in array) {
sum += i + array.Length;
}
return sum;
}
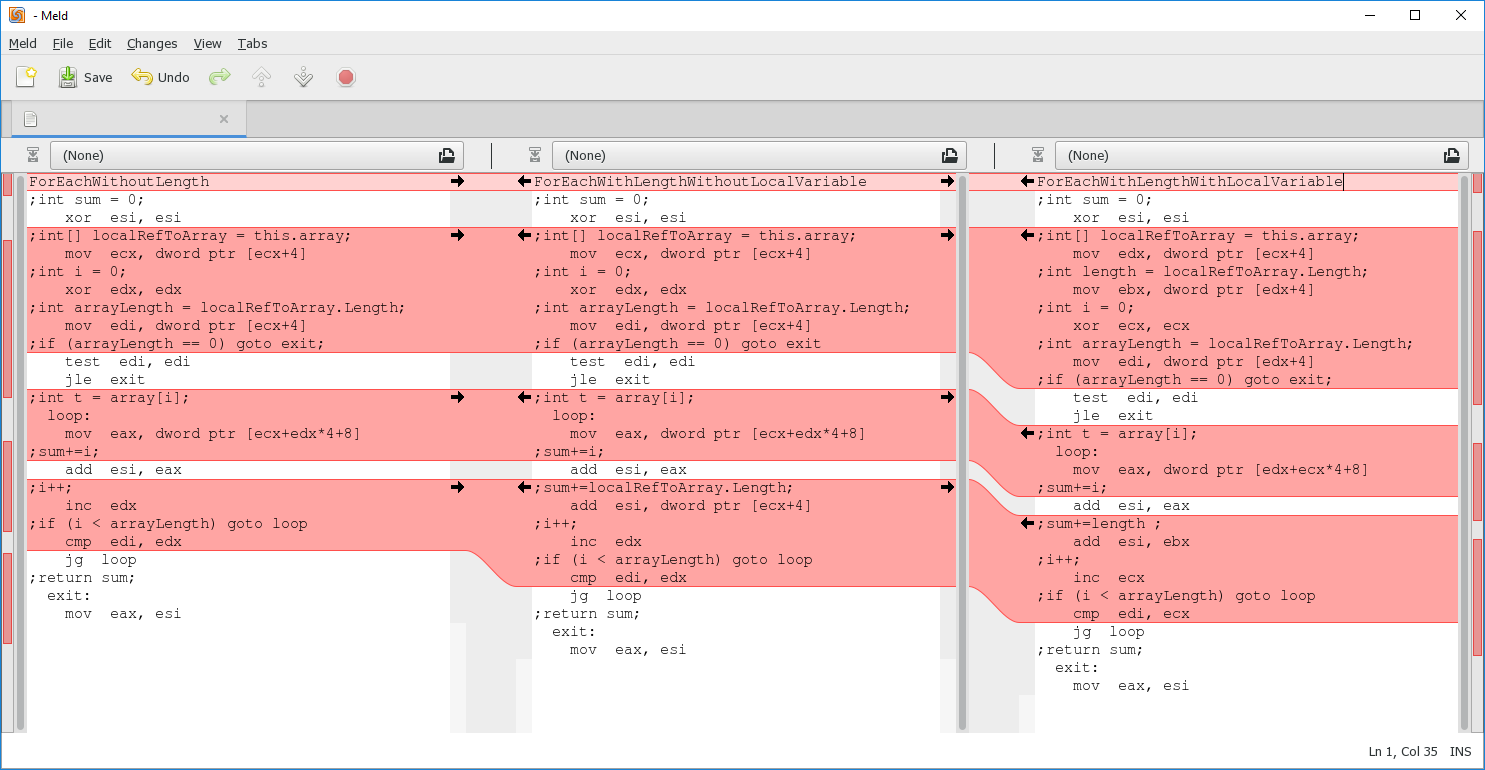
public int ForEachWithLengthWithLocalVariable() {
int sum = 0;
int length = array.Length;
foreach (int i in array) {
sum += i + length;
}
return sum;
}И посмотрим на их код после JIT:
xor esi, esi
;int[] localRefToArray = this.array;
mov ecx, dword ptr [ecx+4]
;int i = 0;
xor edx, edx
;int arrayLength = localRefToArray.Length;
mov edi, dword ptr [ecx+4]
;if (arrayLength == 0) goto exit;
test edi, edi
jle exit
;int t = array[i];
loop:
mov eax, dword ptr [ecx+edx*4+8]
;sum+=i;
add esi, eax
;i++;
inc edx
;if (i < arrayLength) goto loop
cmp edi, edx
jg loop
;return sum;
exit:
mov eax, esi
xor esi, esi
;int[] localRefToArray = this.array;
mov ecx, dword ptr [ecx+4]
;int i = 0;
xor edx, edx
;int arrayLength = localRefToArray.Length;
mov edi, dword ptr [ecx+4]
;if (arrayLength == 0) goto exit
test edi, edi
jle exit
;int t = array[i];
loop:
mov eax, dword ptr [ecx+edx*4+8]
;sum+=i;
add esi, eax
;sum+=localRefToArray.Length;
add esi, dword ptr [ecx+4]
;i++;
inc edx
;if (i < arrayLength) goto loop
cmp edi, edx
jg loop
;return sum;
exit:
mov eax, esi
xor esi, esi
;int[] localRefToArray = this.array;
mov edx, dword ptr [ecx+4]
;int length = localRefToArray.Length;
mov ebx, dword ptr [edx+4]
;int i = 0;
xor ecx, ecx
;int arrayLength = localRefToArray.Length;
mov edi, dword ptr [edx+4]
;if (arrayLength == 0) goto exit;
test edi, edi
jle exit
;int t = array[i];
loop:
mov eax, dword ptr [edx+ecx*4+8]
;sum+=i;
add esi, eax
;sum+=length ;
add esi, ebx
;i++;
inc ecx
;if (i < arrayLength) goto loop
cmp edi, ecx
jg loop
;return sum;
exit:
mov eax, esi
Первое что бросается в глаза это то, что получилось меньше ассемблерных инструкций, по сравнению с циклом for (например для простого суммирования элементов вышло в foreach 12 инструкций, в for 15).

В самом деле, если написать бенчмарк for vs foreach на 1 000 000 элементов массива, то получится такая картина для
sum+=array[i];| Method | ItemsCount | Mean | Error | StdDev | Median | Ratio | RatioSD |
| ForEach | 1000000 | 1.401 ms | 0.2691 ms | 0.7935 ms | 1.694 ms | 1.00 | 0.00 |
| For | 1000000 | 1.586 ms | 0.3204 ms | 0.9447 ms | 1.740 ms | 1.23 | 0.65 |
sum+=array[i] + array.Length;| Method | ItemsCount | Mean | Error | StdDev | Median | Ratio | RatioSD |
| ForEach | 1000000 | 1.703 ms | 0.3010 ms | 0.8874 ms | 1.726 ms | 1.00 | 0.00 |
| For | 1000000 | 1.715 ms | 0.2859 ms | 0.8430 ms | 1.956 ms | 1.13 | 0.56 |
Посмотрим на ForEachWithoutLength. В нём длина массива запрашивается только один раз и не происходит никаких проверок на выход элементов за пределы массива. Так происходит потому что цикл ForEach во-первых запрещает изменение коллекции внутри цикла, а во-вторых точно не будет выходить за пределы коллекции. Из-за этого JIT может себе позволить вообще убрать проверки на выход за пределы массива.
Теперь посмотрим внимательно на метод ForEachWithLengthWithoutLocalVariable. В его коде есть только один странный момент в том, что sum+=length происходит не с сохранённой ранее локальной переменной arrayLength, а с новой, которую программа спрашивает каждый раз из памяти. Получается, что обращений к памяти за длиной массива будет N + 1, где N — длина массива.
Осталось рассмотреть метод ForEachWithLengthWithLocalVariable. Его код ничем не отличается от ForEachWithLengthWithoutLocalVariable, кроме работы с длинной массива. Компилятор опять сгенерировал локальную переменную arrayLength, с помощью которой проверяет что массив не пустой, но при этом компилятор честно сохранил нашу явную локальную переменную length и сложение в теле цикла происходит уже с ней. Получается, что этот метод всего дважды обращается к памяти для определения длины массива. Эту разницу в количестве обращений к памяти в реальных приложениях очень сложно заметить.
Ассемблерный код рассмотренных методов получился такой простой потому что сами методы простые. Будь в методе больше параметров, там была бы уже работа со стеком, переменные хранились бы не только в регистрах и возможно было бы больше проверок, но основная логика осталась бы такая же: введение локальной переменной с длиной массива может иметь смысл только для повышения читабельности кода. Кроме того, оказалось, что Foreach по массиву часто выполняется быстрее чем For.
Комментарии (160)

Greendq
23.12.2018 16:44+2Хмм, на заре дотнета foreach был намного тормознутее простого for-а. Интересный прогресс :)
T-D-K Автор
23.12.2018 16:50+3И сейчас есть разница в производительности.
Если написать:
void SomeMethod(int[] array) { foreach(var i in array) { } }
то JIT это развернёт в обычный цикл со счётчиком, а если сделать:
void SomeMethod(IEnumerable<int> array) { foreach(var i in array) { } }
то тут уже будут все «прелести» foreach — получение енумератора, MoveNext и т.д. И вот этот код уже будет тормозить даже если передать туда массив интов.
ialexander
23.12.2018 18:11Думаю, во втором случае речь должна идти о «прелестях» не foreach, а IEnumerabe/IEnumerator.
Выходит, что foreach научился оптимизировать циклы, используя дополнительную функциональность, к примеру, IList.
И получается, что с точки зрения производительности, выгоднее не генерализировать код, передавая минимально допустимый интерфейс вроде IEnumerable, а передавать ILIst, давая возможность компилятору оптимизировать код.T-D-K Автор
23.12.2018 18:14Можно написать много кастований к разным интерфейсам и в зависимости от успеха вызывать уже метод, оптимизированный пот конкретную коллекцию.
Примерно также сделали вот здесь: github.com/dotnet/corefx/blob/master/src/System.Linq/src/System/Linq/Count.cs
Но мне кажется, что если приходится в реальном проекте делать такую оптимизацию, то скорее всего что-то сильно раньше пошло не так.a-tk
23.12.2018 18:51Все эти касты тоже далеко не дешёвые. Если коллекция короткая, то накладные расходы на касты будут приносить больше вреда чем пользы.
Жаль в C# нету перегрузок методов по constraint-ам на generic-параметры…BlackOne
24.12.2018 01:52Наиболее правильным вариантом тут будет использовать generic типы с необходимыми вам constraint-ами. В этом случае runtime проводит дополнительные оптимизaции используя информацию о типе (например переданные тип может быть struct … или же sealed … или идин из немногих типов от которых наследование возможно, но наследников фактически нет (на счет этой оптимизации не уверен)). Такой код будет значительно быстрее, но к сожалению «duck typing» к-рый используется в foreach конструкциях не будет задействован (а ведь именно он даёт такой прирост производительности в сравнении с for циклами)
a-tk
24.12.2018 13:11Так я ж о чём и говорю…
Но нельзя сделать перегрузки вида
void Smth<T, X>(this T obj) where T : IList<X>; void Smth<T, X>(this T obj) where T : IEnumerable<X>;
Generic-методы дают максимальный выигрыш в скорости только тогда, когда не происходит приведений типов. Получение интерфейсной ссылки и вызов методов через неё обходится дороже чем прямой вызов метода, даже через generic с constraint-ом.
Кроме того, код с кастом выполняется в runtime и способен обнаруживать совместимые конкретизации типов, когда объект передан обобщённо в виде интерфейсной ссылки или приведением к базовому типу.
PS: На хабре отвалилась подсветка C# из списка языков?
ICELedyanoj
23.12.2018 23:14+2Зачем IList? Передача изменяемых списков в качестве аргументов — попахивает.
Я в последнее время всё, где можно — на IReadonlyCollection переделываю. List, Array и некоторые другие списки её умеют из коробки, соответственно переделываем только сигнатуру, а вызовы можно оставить как есть.
Исключение делается только в одном случае — если состав коллекции действительно IEnumerable, например это результат асинхронного выполнения запроса к базе или результат рекурсивной загрузки дерева файлов с диска, когда мы не можем получить весь результат одним куском и не знаем конечного размера массива элементов.
Во всех остальных случаях IReadonlyCollection — то, что доктор прописал.
Только одна претензия — слишком длинное название интерфейса, но здесь уж ничего не изменишь.
И главное — чистота кода. IReadonly сам собой подразумевает, что список передаётся в метод только для чтения, и не будет использоваться для неявного пополнения внутри метода.poxvuibr
24.12.2018 10:56Зачем IList? Передача изменяемых списков в качестве аргументов — попахивает.
Я в последнее время всё, где можно — на IReadonlyCollection переделываю.IReadonlyCollection даёт произвольный доступ к элементам? Если нет, то вот и причина передавать IList.
ICELedyanoj
24.12.2018 11:31IList? Например Array реализует IList, но бросает NotSupportedException при попытке вызвать методы, изменяющие коллекцию.
Если реализация метода, принимающая IList закрыта от вызывающей стороны интерфейсом, то вызывающая сторона не может быть уверена, что в такой метод можно передать Array — вдруг реализация начнёт менять коллекцию?
Если вам нужен доступ к элементам по индексу — используйте IReadonlyList, но, как по мне, это тоже попахивает какими-то костылями.
Просто вопрос — зачем? Если, например, методу нужен какой-то конкретный элемент массива, это означает, что метод слишком много знает об организации коллекции. Вместо этого метод может принимать нужный элемент, вместо коллекции.
В общем принимать коллекции с доступом по индексу — это должна быть какая-то очень специфическая необходимость.poxvuibr
24.12.2018 12:56IList? Например Array реализует IList, но бросает NotSupportedException при попытке вызвать методы, изменяющие коллекцию.
Это у меня из-за недостатка знаний про .net.
Если вам нужен доступ к элементам по индексу — используйте IReadonlyList, но, как по мне, это тоже попахивает какими-то костылями.
Ага, спасибо.
В общем принимать коллекции с доступом по индексу — это должна быть какая-то очень специфическая необходимость.
Есть ещё такое соображение, что в коллекцию можно передать что угодно, в том числе LinkedList. Возможно вы хотите запретить его использование на уровне API.
ICELedyanoj
24.12.2018 14:49LinkedList — сам по себе очень специфичный вид коллекции. Даже приведу цитату из хабракоммента из статьи по LinkedList:
Согласен, что очень специфичный и редко используемый контейнер.
Я же говорю об остальных 99 случаях из 100 — IReadOnlyCollection будет предпочтительнее — с ним интерфейсы становятся чище и понятнее.poxvuibr
24.12.2018 15:14Я же говорю об остальных 99 случаях из 100 — IReadOnlyCollection будет предпочтительнее — с ним интерфейсы становятся чище и понятнее.
Если LinkedList используется редко, то в 99 случаях из 100 можно рассчитывать, что его в метод не передадут. Следовательно в этих 99 случаях из 100 можно сделать явное ограничение в виде IReadOnlyList.
IReadOnlyCollection — явно указывает, что можно передать спокойно передавать LinkedList и так и надо. В 99 случаях из 100 так не надо, поэтому я считаю, что лучше это выразить явно.
ICELedyanoj
24.12.2018 17:07+1IReadOnlyCollection — явно указывает, что можно передать спокойно передавать LinkedList и так и надо. В 99 случаях из 100 так не надо, поэтому я считаю, что лучше это выразить явно.
А что в этом плохого? Вызывающая сторона будет обращаться с LinkedList так же, как и с любой другой коллекцией. Зачем вызывающей стороне IReadOnlyList, который отличается от IReadonlyCollection исключительно геттером по индексу элемента?
Наоборот — ожидая IReadonlyList метод указывает вызывающей стороне, что он собирается вызывать Collection[index], иначе он ожидал бы базовый интерфейс IReadonlyCollection.
Если методу нужна исключительно энумерация входящих в коллекцию элементов — то LinkedList ничем не хуже любой другой коллекции, и ограничение не имеет смысла.poxvuibr
24.12.2018 17:42Зачем вызывающей стороне IReadOnlyList, который отличается от IReadonlyCollection исключительно геттером по индексу элемента?
Чтобы нам не передали LinkedList.
Наоборот — ожидая IReadonlyList метод указывает вызывающей стороне, что он собирается вызывать Collection[index], иначе он ожидал бы базовый интерфейс IReadonlyCollection.
Да, тут вы совершенно правы. Если бы был какой-то интерфейс, маркирующий наличие массива под капотом у коллекции, я бы предложил использовать его.
Если методу нужна исключительно энумерация входящих в коллекцию элементов — то LinkedList ничем не хуже любой другой коллекции
LinkedList жрёт память, убивает перформанс, не даёт элементам коллекции ложиться в кеш и так далее.
a-tk
24.12.2018 22:07+1Как и любой контейнер, двусвязный список предназначен для решения специализированных задач.
У него быстрая вставка и удаление по итератору.
Например, он лучше других будет подходить как контейнер для MRU List и ряда других задач.poxvuibr
25.12.2018 01:29-1Как и любой контейнер, двусвязный список предназначен для решения специализированных задач.
Вот когда появляются такие задачи и надо использовать LinkedList.
У него быстрая вставка и удаление по итератору.
И, соотвественно, LinkedList нужен когда есть необходимость итерировать по коллекции в обоих направлениях, при этом постоянно удаляя произвольные элементы и добавляя их. И при это порядок этих элементов в коллекции должен быть важен. Комбинация таких условий встречается редко, если вообще встречается.
Например, он лучше других будет подходить как контейнер для MRU List
И что делает LinkedList лучше других подходящим на роль MRU List? Чем он лучше ArrayList? Почему там нельзя использовать банальный массив фиксированного размера?
mayorovp
25.12.2018 06:32И что делает LinkedList лучше других подходящим на роль MRU List? Чем он лучше ArrayList? Почему там нельзя использовать банальный массив фиксированного размера?
Потому что в массиве фиксированного размера операция "взять произвольный элемент и переставить в начало" выполняется за ?(N)
poxvuibr
25.12.2018 11:26Потому что в массиве фиксированного размера операция "взять произвольный элемент и переставить в начало" выполняется за ?(N)
Для того, чтобы переставить в начало произвольный элемент в двусвязном списке нужно:
- Вписать в prev первого элемента ссылку наш элемент
- Вписать в prev нашего элемента null
- Вписать в next нашего элемента ссылку на бывший первый элемент
- Вписать в next предущего элемента ссылку на следующий элемент
- Вписать в prev следующего элемента ссылку на предыдущий элемент
Итого 5 действий. То есть, пока у нас в листе 5 элементов и менее, то массив лучше двусвязного списка, тут даже обсуждать нечего.
Но сдвиг в массиве это не просто N операций, это N операций, операнды которых хорошо легли в кеш, а значит они сильно быстрее, чем операции с Linked List.
Кроме того, сдвиг в массиве оптимизируется на низком уровне, а значит — он ещё быстрее.
Поэтому количество элементов, при котором массив — лучший инструмент для решения нашей задачи существенно больше пяти.
MRU List это такая штука, которая ограничена в размерах каким-то небольшим числом и поэтому массив тут подойдёт лучше, чем LinkedList, если речь только о времени, затрачиваемом на то, чтобы переместить в начало произвольный элемент.
mayorovp
25.12.2018 11:47Э… а почему вы считаете что MRU List должен быть ограничен каким-то небольшим числом?
poxvuibr
25.12.2018 12:05Э… а почему вы считаете что MRU List должен быть ограничен каким-то небольшим числом?
Потому что он нужен для того, чтобы вернуться к файлу или проекту или ещё какой-то сущности с которой вы либо недавно работали, либо работатете постоянно. Хранить там больше какого-то небольшого количества элементов не имеет смысла, если надо найти что-то что вы использовали давно — если другие инструменты.
a-tk
25.12.2018 15:49Обновление ссылки — это обновление одного машинного слова в памяти.
Перемещение элемента целиком — зависит от размера элемента, но редко бывает элемент размером в 1 машинное слово. Альтернатива — сами элементы хранятся в одном контейнере, а индексы для доступа — в другом. Но такие структуры не кэш-френдли. Ну и напоследок: большие структуры, да ещё хранящие ссылки, например, на строки — тоже не слишком кэш-френдли.poxvuibr
25.12.2018 18:07Вы точно в ответ на мой комментарий это написали? Если да, то я не понял, что вы хотели сказать.
mayorovp
25.12.2018 06:30+1А что страшного случится если вам передадут LinkedList? Почему бы не предположить что тот, кто создает LinkedList и передает его нам, знает что делает?
ICELedyanoj
25.12.2018 07:13Это какое-то новое слово в архитектуре интерфейсов — специально ограничивать API, чтобы запретить использование ненавистного типа.
Представим себе ситуацию. Мы пишем API, в котором нужен метод вычисления какой-нибудь математической функции из входящей коллекции Int. Единственным условием для успешности вычисления этой функции является конечность коллекции.
Вы действительно предлагаете запретить использование всех базовых коллекций, не реализующих IReadonlyList, только для того, чтобы не убить перформанс?
Чей перформанс? Перформансом LinkedList должен озаботиться в первую очередь тот, кто нам его передаёт. Если пользователя API устраивает перформанс LinkedList, и ему нужна именно такая коллекция? Или даже она досталась ему по наследству из другого API. Что же ему теперь — перед каждым вызовом нашего метода API вызывать .ToArray() на своём списке?
Кроме того, запрещая использование IReadonlyCollection, помимо LinkedList вы теряете и другие базовые коллекции — например Stack или Queue. Да даже Dictionary.
Попахивает каким-то рассизмом по отношению к типам.a-tk
25.12.2018 15:51Интерфейсы вообще-то по-хорошему нужны для того, чтобы заявлять, какой функционал от коллекции нужен алгоритму, который Вы реализуете.
Если коллекция (любая) его удовлетворяет — окей, пользователь вашего API лучше знает, что ему надо на самом деле.
dmitry_dvm
23.12.2018 21:11+1Тормознутость какого порядка? Микросекунды на миллион итераций или хуже?
Сам не особо парюсь такими оптимизация и использую везде IEnunerable<> и List<>, потому что любой запрос к соседнему микросервису отработает в сотни и тысячи раз дольше.T-D-K Автор
23.12.2018 21:37+3Такими оптимизациями и не стоит заниматься, пока именно в них не упирается производительность.
Но для интереса я накидал бенчмарк. Вот сорец: gist.github.com/tdkkdt/181e3f1e2ee6bb1ce1662bfae1241545
Вот результаты:
gist.github.com/tdkkdt/c3250b9c4d25f13a486cb435870bd7aa
foreach на IEnumerable в среднем в 10 раз медленнее чем foreach на массиве.
DrPass
23.12.2018 17:50Я решил раз и навсегда для себя понять стоит так делать или можно сэкономить своё время и написать без временной переменной.
Можно было и не тратить время на проверку. То, что условие цикла for вычисляется один раз перед входом в цикл, написано в документации на C#. Собственно, точно так же этот цикл ведет себя и в других языках.T-D-K Автор
23.12.2018 18:08А можно ссылку на документацию? Интересно почитать подробнее.
условие цикла for вычисляется один раз перед входом в цикл
Странно сформулировано. Условие выхода из цикла в общем случае точно вычисляется на каждой итерации.VezhLos
23.12.2018 18:23Вот здесь
VezhLos
23.12.2018 18:28Видимо, за счет оптимизаций проверка может выполняться в упрощенном варианте, без вычисления правой части условия, если код внутри цикла не изменяет эту правую часть
DrPass
23.12.2018 20:01Да, прошу прощения, глупость сморозил. Естественно, на каждой. Я чего-то про инициализацию думал.
1andy
23.12.2018 18:13Насмешили.
«Условие», а точнее булевое выражение в for вычисляется каждый раз (если оно есть).
Oxoron
23.12.2018 18:53Ок, поставим эксперимент
Заголовок спойлераpublic class LimitWithCounter { private static readonly Random Rnd = new Random(); public int CurrentLimit = 2; public int Limit() { CurrentLimit = Rnd.Next(15) + 5 ; Console.Write(CurrentLimit); return CurrentLimit; } } ... static void Main(string[] args) { var limit = new LimitWithCounter(); limit.Limit(); Console.WriteLine($"Limit {limit.CurrentLimit}"); limit.Limit(); Console.WriteLine($"Limit {limit.CurrentLimit}"); limit.Limit(); Console.WriteLine($"Limit {limit.CurrentLimit}"); Console.WriteLine(); for(int i = 0; i < limit.Limit(); i++) { Console.WriteLine($"\tStep: {i}"); } Console.WriteLine(); Console.ReadLine(); return; }ICELedyanoj
24.12.2018 08:11Вы невнимательно прочли статью. Автор даже результаты Jit-компиляции анализировал.
Очевидно, что компилятор достаточно умный, чтобы отличить свойство Length стандартного Array от метода самописного класса. В первом случае Length измениться не может, и компилятор генерирует код, кеширующий длину массива перед циклом. Во втором случае генерируется код, вызывающий метод на каждом цикле.Oxoron
24.12.2018 13:49То, что условие цикла for вычисляется один раз перед входом в цикл, написано в документации на C#.
Я комментировал не сам пост, а комментарий к нему.
Очевидно, что компилятор достаточно умный, чтобы ...
А вот это потенциальный отстрел ноги. Нужно работать в очень профессиональной команде, чтобы спокойно применять трюки с компиляторами.
чтобы отличить свойство Length стандартного Array от метода самописного класса. В первом случае Length измениться не может, и компилятор генерирует код, кеширующий длину массива перед циклом.
Просто чтобы продемонстрировать опасность слов «очевино» и «компилятор может» в одном предложении.
Чуток кодаvar arr5 = new int[5]; var arr10 = new int[10]; var loopArr = arr5; for(int i =0; i<loopArr.Length; i++) { loopArr = arr10; Console.WriteLine($"\tStep: {i}"); } Console.WriteLine(); Console.ReadLine(); return;
Собственно, у меня выводится Step: 0… Step: 9. Всего 10 значений, хоть я и использовал переменную типа Array, изначально указывающую на массив из 5 элементов. Вывод: длина массива как минимум, в некоторых случаях, не кешируется при использовании в цикле for.
bro-dev0
24.12.2018 00:50В js кэширование длины массива точно дает выигрыш, по крайней мере в V8, где-то 5-50% может дать.
Drag13
24.12.2018 10:33Зависит от того что за массив.
Вот последние замеры на Chrome
Не кешированый: 3,638
Кешированый: 3,628
Разница в пределах погрешности.
А вот на EDGE
Не кешированый: 64,482
Кешированый: 67,909
Разница в 6%
Это если речь про обычный массив с тестом аналогичным авторскому.bro-dev0
24.12.2018 20:09Как вы мерили, я просто открыл готовый тест jsben.ch/qTUpg ну и раньше эта тема уже обсасывалась на хабре с теми же результатами.
Drag13
25.12.2018 00:03jsperf.com/length-to-const
Там есть полезная нагрузка в виде суммы, так что может она нивелирует. Надо смотреть во что оно скомпилируется.
a-tk
23.12.2018 18:49На C++ есть был такой вот паттерн написания циклов до того, как появились нормальный range for:
for ( Container::const_iterator it = container.begin(), end = container.end(); it != end; ++it) { // do something }
Ваши разработчики случаем раньше на С++ не писали?robert_ayrapetyan
23.12.2018 19:58А это реально быстрее it != container.end()?
a-tk
23.12.2018 21:43Зависит от контейнера. Где-то выигрыш будет, где-то нет. Но проигрыша точно не будет нигде.
dmitryb-dev
23.12.2018 19:34+1Вообще не понимаю такой экономии «на спичках» (и речь не только о вышеописанном случае). Всегда в голове проносится вопрос: «А что, остальной ваш код настолько идеален и оптимизирован, что вот осталось только вот тут сэкономить на вызове гетера?».
На мой взгляд любая оптимизация, которая ухудшает читабельность кода, должна быть чем-то аргументирована, если не замерами и профайлерами, то хотя бы мыслью «мне кажется эта функция будет вызваться очень часто, надо бы написать ее чуть поаккуратнее». А не «оптимизирую, потому что могу».aensidhe
24.12.2018 09:45Да, иногда наш остальной код оптимизирован. А иногда метод, в котором вы оптимизируете, вызывается миллионы или миллиарды раз в час. Ну и там получается нормально.
WRONGWAY4YOU
23.12.2018 22:59Да, конечно, в указанных в статье случаях компилятор это делает за вас. Но, однако, бывают и более нетривиальные случаи. Правда?
Должен ли компилятор делать такие оптимизации в данной функции, например?
void whatever(char* s, char* a) { int k = 0; for (int i = 0; i < strlen(s); ++i) { for (int j = 0; j < strlen(s); ++j) { if (s[i] == s[j]) { a[k++] = s[i]; // Modifying "a" } } } }
А вот нет: указатель
aможет ссылаться на регион в памяти, принадлежащейs. В процессе исполнения этого цикла мы модифицируемa, и, следовательно, можем изменить расположение'\0\'вs, которое, в свою очередь, может поменять результат исполнения выраженияstrlen(s), из-за чего компилятор, конечно, оптимизировать этот код не будет.
Не нужно постоянно полагаться на компилятор, т.к.
Compiler is a tool, not a magic stick.
T-D-K Автор
23.12.2018 23:00+1У нас в .net всё проще. :) есть конечно fixed, unsafe и прочий unmanaged, но это очень не приветствуется.
aensidhe
24.12.2018 10:07Это не так.
Во-первых, это приветствуется прятать во всякие методы и классы отдельные.
Во-вторых, есть ref/Span, которые полностью безопасны.mayorovp
24.12.2018 10:10Вот именно, они безопасны, и там нет никаких strlen. Длина всегда хранится отдельно и не может внезапно измениться.
a-tk
24.12.2018 13:17Зависит. Длина контейнера меняться в некоторых случаях может, и корректно по ним итерироваться тоже надо уметь.
В .NET большинство коллекций отслеживают свою версию и итератор проверяет, не поменялась ли версия контейнера по сравнению с той, на которой началось итерирование, но это, строго говоря, не обязательно.
a-tk
24.12.2018 13:16Смотря у кого не приветствуется и смотря где.
Не приветствоваться должны некорректные обобщения.
kuber
23.12.2018 23:04+1Раз уж мы решили обсудить данный момент, то надо ещё посмотреть на скорость компиляции одного и другого фрагмента. И окончательно поставить точку.
easyman
23.12.2018 23:59+1И тут выясняется, что не хватает сравнения с новым типом Index из C# 8 :)
https://blogs.msdn.microsoft.com/dotnet/2018/11/12/building-c-8-0/T-D-K Автор
24.12.2018 00:04А ещё можно сравнить в RyuJit, LegacyJit x64, Mono и т.д. Увы, этот вопрос возник у меня только для рабочих проектов, потому я и проверял только то, что доступно на работе. Новый .net даёт всё больше возможностей. Сейчас изучаю SIMD в .netcore 3.0 (готовлю статью) и вот там уже можно разгуляться во всю. Правда в домашних условиях применять это некуда.
iga2iga
24.12.2018 00:52Геттер у Array.Length? Серьезно? Ну по дизасму же видно, что нет там никакого геттера, это обычная переменная, хранящая длину массива, точно такая же как и у строк и у кучи всего остального и не только в C#…
tsul
24.12.2018 01:12Конечно серьёзно. Это же property. Скомпилируйте в Debug, будет честный вызов геттера.
iga2iga
24.12.2018 20:23Ну так и надо было это отобразить в статье, т.е. показать дизасм дебаг версии. Потому что даже в моём мире Delphi, даже в дебаг версии без оптимизаций, даже при явном указании «якобы функции» len := length(array) нет никаких call в дизасме, регистр напрямую читает длину массива из памяти. Было бы очень странно и как-то даже глупо, если бы в C# было бы по другому. Ну а с геттером — это вообще рукалицо. В смысле прям с геттером, который вызывает целую функцию (уж не спец в C#), а не просто возвращает длину массива.
ICELedyanoj
24.12.2018 21:58Это как раз аргумент не в пользу компилятора Delphi.
Дебаг-версия она как раз для того и существует, чтобы иметь возможность пройти в пошаговом режиме через каждую строчку кода, иначе в чём смысл Debug?mayorovp
24.12.2018 22:06А в чем смысл «гулять» внутри кода стандартной библиотеки?
a-tk
24.12.2018 22:09+2Не боги горшки обжигают. Стандартную библиотеку пишут люди (C++ STL не в счёт), им тоже надо иметь возможность отладки своего творения.
mayorovp
25.12.2018 06:20Хорошо, уточню вопрос: в чем смысл разработчику прикладной программы «гулять» внутри кода стандартной библиотеки?
a-tk
25.12.2018 15:54А зачем Вы туда полезли? Ну, не лично Вы, а любой пользователь. Какая разница, что там написано, есть ли промежуточные переменные или что-то ещё, если библиотека достаточно быстрая качественная?
mayorovp
25.12.2018 16:08Так я именно об этом и говорю! Незачем мне туда лезть. А значит, отладчик в пошаговом режиме и не должен заходить внутрь, это совершенно корректное поведение.
iga2iga
24.12.2018 22:55В смысле не в пользу компилятора Delphi?! Тут и компилятор-то не при делах… Это ж как бы логично, что если имеем некий массив, уж без разницы как он реализован, на уровне компилятора (языка), на уровне рукописного класса или класса стандартной библиотеки, то там должна быть (даже обязана быть) переменная 1 штука, которая всегда хранит текущую длину этого массива. При увеличении количества элементов массива на N, увеличиваем переменную длины массива на N. То же самое при уменьшении. Зачем это проходить отладчиком? Строки обязаны быть реализованы точно таким же образом. Я, собственно, именно по этому и был удивлен геттеру получения длины массива, когда вот просто возьми и прочитай эту самую переменную из памяти в регистр. Её адрес или смещение и всё прочее заранее известны компилятору.
a-tk
24.12.2018 23:56+1В С++ ни в старом варианте — [], ни в новом array<T, N> не хранится переменная с длиной. В первом случае это просто указатель, во втором — constexpr-метод.
iga2iga
25.12.2018 04:10Она явно не хранится, она создается, когда есть ключевое слово array или string (Delphi). Для плюсов, да, там все прям квадратно и перпендикулярно: sizeof(array)/sizeof(array[0]), хотя вот в векторе скорее всего как в дельфи. Впрочем оставим неизлечимо больного в покое (это я про с++)… Ну а уж в C#-то должно же быть как в дельфи хотя бы… разве нет?
На счет «скрытых» элементов массива не скажу, а вот строки дельфи, например, содержат такие элементы как CodePage, ElemSize, RefCount, ну и наш length. У массивов всё точно так же, за минусом CodePage. Они хранятся по отрицательному смещению от первого элемента строки/массива.
зы Мне кажется я сейчас ещё чуточку больше полюбил Delphi :)
mayorovp
25.12.2018 06:27Вы забываете, что в C# компиляция идет не сразу в машинный код, а сначала в байт-код. А потому для определения длины массива есть лишь два варианта — или придумывать отдельную команду IL именно для этой цели, или просто вызвать метод из стандартной библиотеки. Создатели .NET решили пойти по второму пути для упрощения спецификации.
А вот JIT уже никто не мешает вызов известного ему метода
get_Length()заменить простое на чтение переменной из памяти.
T-D-K Автор
24.12.2018 01:19Я не специалист по исходникам .NET. Но копание в .netcore 3.0 показало, что при вызове Array.Length выполняется вот этот «код»:
FCIMPL2(INT32, ArrayNative::GetLength, ArrayBase* array, unsigned int dimension) { FCALL_CONTRACT; VALIDATEOBJECT(array); if (array==NULL) FCThrow(kNullReferenceException); if (dimension != 0) { // Check the dimension is within our rank unsigned int rank = array->GetRank(); if (dimension >= rank) FCThrow(kIndexOutOfRangeException); } return array->GetBoundsPtr()[dimension]; } FCIMPLENDpanteleymonov
24.12.2018 01:53unsigned int rank = array->GetRank();
if (dimension >= rank)
Забавно, тут тоже можно было бы спросить зачем выносить в отдельную переменную.a-tk
24.12.2018 13:19Эта переменная всё равно осядет в регистр в релизном коде и будет вести себя точно так же, как если бы её не было, потому что используется ровно 1 раз. Зато отлаживать такой код гораздо удобнее если что-то пойдёт не так.
panteleymonov
24.12.2018 16:06Спасибо кеп. Чуть ниже я именно об этом написал, если игнорировать саму статью и множество подобных комментариев под ней.
panteleymonov
24.12.2018 01:43Если покопаться в памяти и вспомнить почему выносят «var length», то это не только какая то мнимая оптимизация. Что то вроде правила хорошего тона «ходить с завязанными шнурками» вместо «сунул и пошел». Как приводился пример выше, со вложенными циклами, такой подход «защищает» от проблемы лишнего вызова. То есть когда у многих задач одно решение, то оно превращается в привычку и получается что вроде как ляпается повсюду. А с другой стороны еще и помогает избавиться от длинных строк кода, если есть такие предпочтения. Предпосылок конечно больше у тех кто работал с С++ и С еще с 90-x. Но на таком простом коде это не наглядно даже для старых компиляторов. И логика в некоторых случаях могла меняться по причине большого объема кода, вплоть до запарывания стека самим компилятором.
В общем если есть много времени на то чтобы лишний раз просмотреть как это откомпилировалось то заморачиваться стоит. Но куда проще добавить этот самый «var length» аналог и не нарушать феншуй гармонию кода.
shibaev
24.12.2018 06:56Есть еще один аргумент в пользу использования Array.Length напрямую, без доп. переменных. С включенными оптимизациями JIT компиляторы умеют избавляться от array bounds check при доступе к элементам массива внутри цикла. С доп. переменной такие оптимизации могут не работать:
blogs.msdn.microsoft.com/clrcodegeneration/2009/08/13/array-bounds-check-elimination-in-the-clr
stackoverflow.com/questions/16713076/array-bounds-check-efficiency-in-net-4-and-above
В ваших примерах bounds check присутствуют:
cmp esi, eax
jae 056e2d31
Возможно, это ограничение LegacyJIT x86. Либо код запускался без оптимизаций. RyuJIT x64 должен быть умнее (https://stackoverflow.com/a/17138483/136138).ideatum
24.12.2018 09:27Вы удивитесь, но проверка границ массива практически не влияет на производительность. Современные процессоры умеют делать это очень эффективно, так что время доступа к элементу массива с проверкой границ увеличивается всего на (0.881 ± 0.009) %
Более подробно здесьpanteleymonov
24.12.2018 11:47Первый раз слышу чтобы процессор сам проверял границы массива. Вообще непонятно для чего эти проверки, возможно в режиме дебаг и прокатит, но в рабочем коде для чего? Особенно что цикл в этих самых границах.
shibaev
24.12.2018 14:14Не удивлюсь, т.к. про это написано по ссылке со StackOverflow, которую я привел в своем сообщении (https://stackoverflow.com/a/16719474/136138)
На практике на моем i7-4200HQ разница существенна для RyuJIT x64. Я взял benchmark gist.github.com/aensidhe/0d412e142eb29fd21eea01b5f6462d41 и сравнил For() и ForReverse(). В первом случае RyuJIT убирает bounds check, во втором — оставляет. И у меня на машине получаются такие результаты:
BenchmarkDotNet=v0.11.3, OS=Windows 10.0.17134.472 (1803/April2018Update/Redstone4) Intel Core i7-4720HQ CPU 2.60GHz (Haswell), 1 CPU, 8 logical and 4 physical cores Frequency=2533210 Hz, Resolution=394.7561 ns, Timer=TSC [Host] : .NET Framework 4.7.2 (CLR 4.0.30319.42000), 32bit LegacyJIT-v4.7.3260.0 Clr LegacyJit : .NET Framework 4.7.2 (CLR 4.0.30319.42000), 64bit LegacyJIT/clrjit-v4.7.3260.0;compatjit-v4.7.3260.0 Clr RyuJit : .NET Framework 4.7.2 (CLR 4.0.30319.42000), 64bit RyuJIT-v4.7.3260.0 Platform=X64 Runtime=Clr Method | Job | Jit | Mean | Error | StdDev | ----------- |-------------- |---------- |---------:|---------:|---------:| For | Clr LegacyJit | LegacyJit | 724.0 ns | 1.945 ns | 1.819 ns | ForReverse | Clr LegacyJit | LegacyJit | 725.5 ns | 9.341 ns | 7.800 ns | For | Clr RyuJit | RyuJit | 583.3 ns | 2.706 ns | 2.259 ns | ForReverse | Clr RyuJit | RyuJit | 732.2 ns | 2.568 ns | 2.402 ns |aensidhe
24.12.2018 15:50Это странно. Запустите ещё пару раз. В релизе. Из командной строки. И не используйте при этом компьютер.
fukkit
24.12.2018 08:05+1Явная оптимизация лучше неявной.
Если ничего более важного в голове хранить не нужно, можно хранить и детали внутреннего устройства компилятора, конечно.RegisterWindowClassExA
24.12.2018 08:54Плюсую. Эта статья скорее о том, что неявная оптимизация может сильно подгадить. И вообще не понятно, для каких нубов нужна такая «неявная оптимизация». Я не пишу на C#, но например, если в теле цикла меняется размер массива, или если массив может меняться из другого потока, то «оптимизированная» компилятором функция может вести себя не так, как ожидает программист. Т.к. в условии цикла, по сути, будет проверяться не текущий размер массива, а размер массива на момент входа в цикл. Хорошо, если массив уменьшается, тогда, возможно, Вы получите исключение типа «выход за пределы массива», и будете долго врубаться, в чем собственно дело. А если массив увеличивается, а Ваш цикл (поток?) проходит не по всем его элементам, а только по части, ошибки будут очень неявными, и искать их будет на порядок труднее…
Ogra
24.12.2018 09:18+1Компилятор не будет оптимизировать, если он не уверен, что размер не меняется. Если в теле цикла будет что-то вроде такого
for (int i=0; i<array.getLength(); i++) {
if (something) array.nonConstMethod();
}
то оптимизации не произойдет и обращение к array.length() будет происходить при каждой итерации.
Собственно, иногда и нужно сохранять размер контейнера в локальную переменную — когда компилятор не может быть уверенным, а программист может.RegisterWindowClassExA
24.12.2018 09:25Мне тоже подумалось про «если будет в теле цикла», но вот то, что Вы написали — это Ваше 100%-ное знание или просто идеализация компиляторов? А если будет поток? Тоже компилятор будет анализировать, используется ли функция в потоке, или меняется ли массив другими потоками? Теоретически это возможно, практически это тоже и возможно, и скорее всего так и есть, НО… Всё-таки я привык к тому, что «машина делает ровно то, что Вы написали, а не то, что Вы имели в виду»… Вот мой последний проект, например, работает нормально только при отключенной оптимизации. И вообще у нас так повелось, что если программа сбоит, попробуй отключить оптимизацию.
mayorovp
24.12.2018 10:00Это общий принцип любой оптимизации — не менять наблюдаемого поведения. Если проект работает только при отключенной оптимизации — значит, либо в коде где-то UB, либо в компиляторе баг. Второе возможно, но куда реже чем первое.
А если будет поток?
А многопоточный доступ к изменяемому массиву без синхронизации — это очень плохая идея. Так писать программы не следует.
RegisterWindowClassExA
24.12.2018 12:06Насчёт потоков и синхронизации — по большей части согласен. Но все равно слишком много «если». Все-таки правильно написал товарищ выше, что лучше писать явно оптимальный код, который и тебя будет держать в тонусе, и твоих последователей, нежели держать в голове нюансы работы компилятора.
RegisterWindowClassExA
24.12.2018 15:06-1Тем не менее, подумав еще раз, склоняюсь к тому, что явная оптимизация лучше. В общем случае, если Вы программируете на всем, что допускает возможность программирования, это сослужит Вам добрую службу.
Например, пишете Вы код, знаете хорошо повадки компилятора. Ок. Потом Вы решили сделать Ваше приложение кроссплатформенным, каков будет масштаб изменений? Явно оптимизированное приложение гораздо проще перенести, в другой ОС будет другой компилятор, который не будет столь же продвинутым, и сделает неэффективный код.
У Вас есть хорошая библиотека, которую Вам нужно перенести на другой ЯП для другого проекта. Опять же неизвестно, что там будет за компилятор, кто будет исполнять полученный код. Известно только одно — явно оптимизированный код с большей вероятностью будет выполняться более оптимально везде, где это может быть. Нормально делай — нормально будет.
И вот куда мне во всей этой куче ситуаций нужно впихнуть знание, что «компилятор С# в такой-то конкретной ситуации неявно догадывается о том, что я хочу сделать». ИМХО, на таком уровне хорошо бы и мне представлять, что именно я написал, и какие есть пути оптимизации.
На мой взгляд, явная оптимизация всё-таки показатель того, что человек понимает, что происходит за ширмой IDE, в которой он работает. И она учит этому пониманию и других, особенно если это прокомментировано в коде.mayorovp
24.12.2018 15:28У Вас есть хорошая библиотека, которую Вам нужно перенести на другой ЯП для другого проекта.
Поскольку я пишу на C#, то и переносить я буду ее с другого языка программирования на C#, и никак иначе. И я не вижу чем знание "повадок" компилятора мне в этом помешает...
А если я захочу перейти на другой ЯП (например, на Rust) — то я просто изучу основные "повадки" компилятора этого самого другого языка.
Ogra
24.12.2018 12:18вот то, что Вы написали — это Ваше 100%-ное знание или просто идеализация компиляторов?
На разумном уровне оптимизации, компиляторы делают только то, в чем уверены. Я не знаю, лезут ли компиляторы каждый раз в тело метода, или просто смотрят на модификаторы (вроде const), решая, когда переменную можно заоптимизировать, а когда нет. Я даже уверен, что для разных языков будет по разному.
Я, конечно, не идеализирую компиляторы, но в плане оптимизаций после этой статьи про предсказание ветвлений, не решаюсь высказываться в духе «Ассемблер быстрее, чем Си».
А если будет поток? Тоже компилятор будет анализировать, используется ли функция в потоке, или меняется ли массив другими потоками?
Тогда трындец. Ставьте volatile там, где у вас многопоточный доступ к переменной.
LMSn
24.12.2018 13:34Эта статья скорее о том, что неявная оптимизация может сильно подгадить.
Я не пишу на C#, но например, если в теле цикла меняется размер массива
Ага, «не читал, но осуждаю». В .NET все массивы без исключения фиксированной длины. Она не может измениться, можно только создать новый массив другого размера.RegisterWindowClassExA
24.12.2018 13:42Пффф, а я же думал: «Ну не пишешь ведь на C#, ну иди мимо, не пиши». Но нет, решил натянуть свою сову на чужой глобус :)
Спасибо, буду знать :)
ideatum
24.12.2018 09:38Зная структуру (memory layout) массива, можно посмотреть здесь, в общем понятно, что смысла сохранять длину массива в локальную переменную смысла не имеет и обращение к Length хорошо оптимизированно. imho на мой взгляд более интересным вопросом является, каким образом стоит обращаться со свойством коллекций Count.
aensidhe
24.12.2018 09:43Для подобных вещей есть давно BenchmarkDotNet. Вот, например, вариант кода и результаты.
Как можно увидеть — никакого влияния на производительность вынос Length не имеет.
alex_zzzz
24.12.2018 11:14Спасибо. Сегодня я узнал, что вынесение array.Length из условия цикла в отдельную переменную больше не приводит к замедлению. Проверка выхода за пределы массива оптимизируется в обоих случаях. Видать, компиляторы поумнели. Хотя, надо ещё Моно проверить, там это важно.
aensidhe
24.12.2018 11:33Выше бенчмарк, запустите его на моно.
alex_zzzz
25.12.2018 01:46Проверил. Убрал тест Aggregate, добавил несколько с указателями из любопытства. На NET Core не проверял, оно у меня не установлено. Добавил Моно и x86.
Если коротко: нехрен микрооптимизировать наугад, без тестов на целевой платформе, даже если думаешь, что знаешь.
- LegacyJit x64 отдал предпочтение методу с array.Length, вынесенному из условия цикла (540 нс против 770 нс). Но проверка на выход индекса за пределы массива есть в обоих случаях. Нихрена она не убрана.
- В других конфигурациях NET Framework-компиляторам пофиг, скорость одинаковая. Хотя RyuJit догадался убрать проверку в обоих случаях (они вообще идентичные с точностью до замены регистров). Оставил её только в варианте ForReverse. Поэтому без необходимости ходить по массиву в обратную сторону наверное не надо, хотя разница невелика (600 нс против 640 нс).
- Компилятор Mono x64 тоже выбрал вариант с вынесением array.Length из цикла (860 нс против 1040 нс). Так же и в Mono x86 (1800 нс против 1960 нс). Осталась там проверка на выход за пределы или нет, непонятно. Дизассемблер непривычный и без отображения меток. Вообще ХЗ что там происходит.
- Замена статического массива на экземплярный дала изменение только в одном пункте: немного ускорился For на Mono x64, но на общую картину это не повлияло.
- Моно генерирует какие-то бессмысленные портянки машинных инструкций, перетасовывая регистры взад-вперёд. Дизассемблер методов с развёрнутыми циклами сам разворачивается на несколько экранов. В результате чем сильнее цикл развёрнут, тем больше кода и всё медленнее. При том что для LegacyJit x64 это тест даёт лучший результат из всех возможных.
- Лучше таки использовать foreach и для скорости, и для наглядности, и писать быстрее, и негде ошибиться.
- Вариант с указателями тоже неплох (почему-то из трёх похожих лучше всего именно PtrA). Когда очень надо, все средства хороши.
aensidhe
25.12.2018 12:52Без тестов на .net core выводы делать так себе. Потому что .net framework переведён в maintenance мод и в .net core была куча оптимизаций (в рантайме, джите и BCL), не все из которых портированы обратно в полный фреймворк.
Спасибо за тесты.
erty
24.12.2018 11:24Я не специалист в C#, но в некоторых языках реализация foreach не гарантирует строго последовательного перебора набора. т.е. могут браться элементы вразнобой (как они там хранятся в памяти), а не строго подряд. В C# такого не наблюдается?
aensidhe
24.12.2018 11:36+1Это зависит от коллекции.
foreach (var x in collection) {}
Это всего лишь сахар для:
using (var e = collection.GetEnumerator()) { while (e.MoveNext()) {} }
Так что всё зависит от реализации MoveNext.
Если тип collection — массив и компилятору это точно известно, то там будет просто проход по индексу.
mayorovp
24.12.2018 11:41Если там элементы хранятся в памяти вразнобой — то откуда вообще возьмется быстрый доступ по индексу?
ICELedyanoj
24.12.2018 11:43За порядок элементов в IEnumerable отвечает реализация энумератора. Конечно, можно написать энумератор, использующий рандомайзер для выборки элементов, но, как правило, энумерация стабильна.
Нестабильной она может быть когда коллекция приходит извне — например это результат выборки из базы данных или файловой системы.
GLeBaTi
24.12.2018 11:28Стоит упомянуть, что если использовать другое свойство:
for (int i = 0; i < myObj.MyProperty; i++)
То компилятор может не оптимизировать и вызов будет каждый раз.
blogs.msdn.microsoft.com/vancem/2008/08/19/to-inline-or-not-to-inline-that-is-the-question
Поэтому не вижу ничего страшного, что кто-то выделяет в локальную переменную. Явное лучше неявного.alex_zzzz
24.12.2018 11:40
Advice 2: When possible, use “a.Length” to bound a loop whose index variable is used to index into “a”.
Как минимум раньше эта «оптимизация» приводила к обратному эффекту. Вместо явного (i < a.Length) JIT видел сравнение индекса с какой-то левой переменной и на всякий случай вставлял в код проверку на выход за границы массива.
UncleJey
24.12.2018 12:31Статья не полная.
не вижу обратного перебора.
for (int i = array.Length - 1; i>=0; i--) { //do smth }T-D-K Автор
24.12.2018 15:43Цель моей статьи разве была определить самый быстрый способ итерации на массиве? Или разобрать все возможные варианты итерации? Я рассматривал один конкретный пример и делал выводы для одного конкретного примера. С моей точки зрения статья полная.
PsyHaSTe
24.12.2018 12:36Очень часто замечаю, что люди пишут вот так
Не знаю, ни разу не встречал. В 99% случаях люди пишут `var result = arr.Sum(x=>x.Something)`, и в оставшемся 1% случае foreach.
Про деоптимизацию из-за сохранения длины в локальную переменную писали уже прилично раз, но раз статья получила столько положительных отзывов, видимо это всё еще не всем ясно.
К слову, for/foreach должны давать одинаковую производительность для массивов. Для список результат иной, насколько я помню.aensidhe
24.12.2018 12:44Нет никакой деоптимизации.
PsyHaSTe
24.12.2018 13:57Ну как нет, могли пойти по быстрому пути, но нарушили эвристику компилятора.
Вообще, не знаю реального кода, который бы на это заявзывался. Такой код навреное только на заре карьеры пишут. Я когда джуном был, тоже в циклах где мог byte/short использовал, если позволяло максимальное значение циклов. И про себя думал «вот поэтому мне 4гб памяти и не хватает, во всех примеров программисты разбазаривают её, int пишут!».
Warg_nvkz
24.12.2018 14:07Это не имеет значения, потому что длина массива хранится в отдельной переменной в классе, а не вычисляется. Так писали на старых языках, вроде C, Pascal и Basic и их ближайших потомках, потому что там массив, это просто последовательность неизвестной длины.
Ну, и length писать короче, чем array.LengthPsyHaSTe
24.12.2018 14:45Не хранится, выше показывали плюсовый код, который вызывается при обращении к свойству.
mayorovp
24.12.2018 15:29В Pascal так писать не имеет ни малейшего смысла, поскольку там верхняя граница цикла for вычисляется строго один раз.

Brightori
25.12.2018 10:09Ммм, я слышал мнение что на каждой итерации фор, алоцируется память под Length, и если Length закэшировать, то типа будет быстрее и не будет засираться память.
mayorovp
25.12.2018 10:28Length — int, это value type. С каких пор в .net возврат value type стал требовать аллокаций памяти?
eshirshov
25.12.2018 13:24но ведь это примитивный пример. в общем случае как компилятор может гарантировать неизменность размера массива? вызов метода напрочь убьёт все гарантии.
теоретически разумеется.a-tk
25.12.2018 15:57Покажите реальный сценарий, приводящий к таким последствиям.
Теория понятна и даже местами её можно как-то логически подтвердить. Однако Ваше утверждение пахнет чрезмерным обобщением.eshirshov
25.12.2018 17:20я упустил что речь идёт об Array. подразумевал абстрактный контейнер со свойством Lenght. посылаю голову пеплом.
mayorovp
25.12.2018 16:10В .NET — запросто: длина массива неизменяема. Может поменяться только ссылка на сам массив, но если она находится в локальной переменной, то тоже не может поменяться сторонним кодом.
jevius
Сомнительная оптимизация, это как называть переменные одной буквой для экономии памяти.
И поправьте отображение кода
T-D-K Автор
Вводить лишнюю переменную всегда медленнее чем её не вводить. Мне часто объсняли, что сохраняя в локальную переменную длину массива, программист таким образом увеличивает скорость выполнения цикла. Я доказал, что это не так. Всё. За оптимизациями я не гнался.
Что не так с отображением кода? Можно подробнее? habrahabr не умеет в нативную подсветку ассемблера и пришлось экспериментировать с другими тулзами.
jevius
Скриншотом хоть. Как-то грязно сейчас
T-D-K Автор
Спрятал большие куски кода по кат. Код в таблицах нужен для визуального сравнения. Скриншоты из утилиты есть под катами после таблиц.
В целом вставлять код скриншотом это очень плохая практика, т.к. такой код нельзя скопировать и такой код не проиндексируется поисковиками.
jevius
В данном конкретном случае скорее всего никто не станет копировать те вставки. А гуглить код… Здесь тоже маловероятный сценарий
u-235
SiliconValleyHobo
Это не ssa, это loop invariant
navrocky
А если это не функция Length стандартного Array, а какая-нибудь кастомная функция, как компилятор такое соптимизирует не проверяли?
T-D-K Автор
В общем случае функция будет вычислять на каждой итерации цикла. SZ-массивы в .NET это очень нативная вещь и под неё сделано очень много оптимизаций. Для остального такие оптимизации в общем случае могут быть не сделаны. Подробности можно узнать только дизассемблировав код метода после JIT компиляции конкретным JIT.
Ради интереса. Вот код: pastebin.com/2fhb1fUZ, вот asm (LegacyJit x86): pastebin.com/8uSmwitv
Метод вызывается каждый раз, хотя возвращает каждый раз одного и тоже значение.
severgun
Тогда какой смысл не создавать переменную?
Быстрее код не станет, но и медленнее тоже. Скорость написания кода тоже сомнительный аргумент. Перерыв «на кофе» займет больше времени чем сэкономите.
Зато если всегда писать, то это будет делаться машинально и будет хоть какая то однородность в стиле.
poxvuibr
Чтобы не было лишней строчки в идиоматичном коде.
Обход массива — идиоматичный код, лучше, если он у всех выглядит одинаково.
Однородно должен быть написан как раз обход массива. А, если выделена отдельная переменая — значит можно сразу понять, что там какой-то не тривиальный код
LoadRunner
А если размер массива меняется внутри цикла от шага к шагу?
poxvuibr
Конечно, хочется сказать — не делайте так. Но на самом деле интересно, в каком случае это может понадобиться. Особенно учитывая, что менять размер массива внутри цикла и при это не ушатать производительность можно только удаляя элементы из конца. Ну или добавляя их туда.
LoadRunner
Например, при кодовой генерации интерфейса, когда надо удалить те контролы, которые проходят по условию.
Возможно, что-то изначально уже сделано неправильно, но я не программист и это хобби-проект.
poxvuibr
Если из листа надо только удалить элементы, то лучше просто вернуть новый лист, где удалённых элементов нет.
LoadRunner
Эм… А если работа напрямую со списком контролов, который предоставляет родительский контрол? А на дочерние контролы могут и события вешаться, и прочая шелуха WinForms.
poxvuibr
Там, наверное, удаление контрола делается вызовом отдельного метода родительского контрола?
Я бы прошёл по списку, получил контролы, которые нужно удалить и сделал ещё один цикл, в котором бы их удалил. Я стараюсь избегать кода, в котором модифицируется размер коллекции, по которой происходит итерация.
PsyHaSTe
var controlsToUpdate = Controls.Where(SomeCondition).ToArray()PsyHaSTe
Размер массива не может меняться. Это его ключевое свойство, в общем-то.
LmTinyToon
Строго говоря вы доказали это лишь для одной структуры данных. Я бы побоялся делать такие выводы на одном примере. А если работа идёт с какой-то коллекцией где логика подсчета длины не совсем константая по сложности? Слишком тонкая тема. Думаю серебряной пули тут нет. Разве что только для встроенных примитивных типов
kalininmr
ну одной не одной, но, вроде бы, начиная с какой то длины добавляется лишняя работа.
кстати подобное во многих языках, где есть рефлексия и кеш на короткие строки