
Новый год — время подводить итоги. И если вы ведёте блог на хабре, или вам интересно посмотреть статистику по чьему-нибудь чужому блогу — то вам может пригодиться моя опенсорсная утилитка.

CSV-файл с базовой информацией о всех статьях:
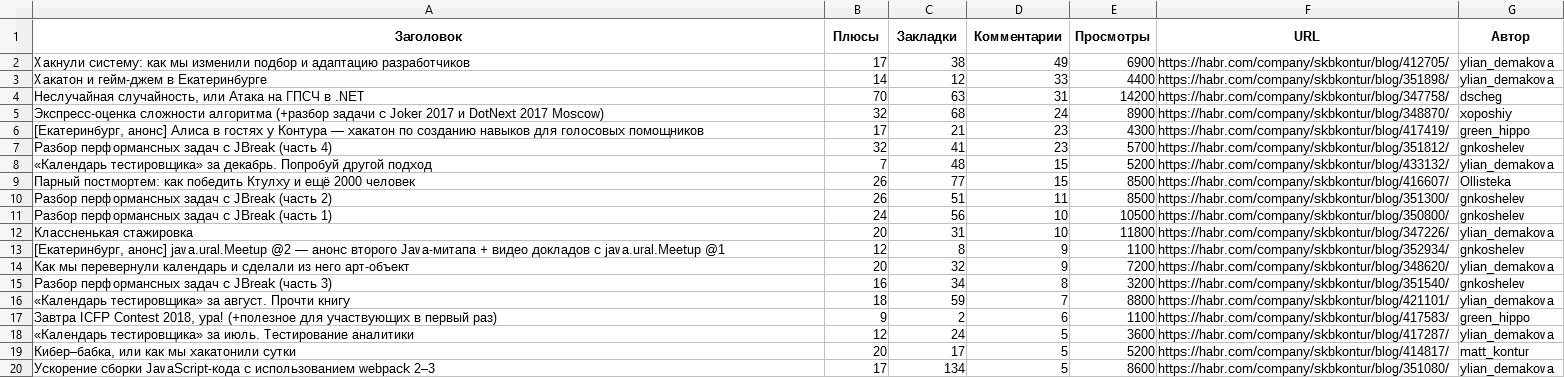
(более крупная версия скриншота доступна по клику)
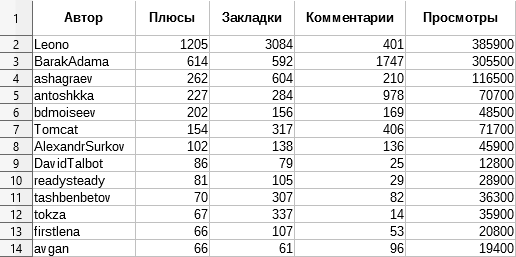
CSV-файл c информацией, какой автор в блоге несёт ответственность за какое число просмотров/комментариев/плюсов/добавлений в закладки.
CSV-файл с аналогичной информацией, но сгруппированной по хабам.

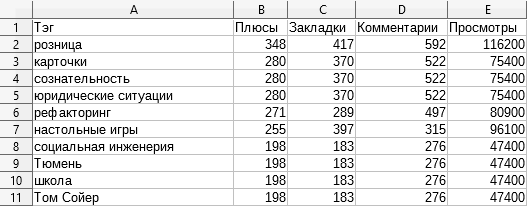
CSV-файл с аналогичной информацией, но сгруппированной по тегам. Для скачивания тегов приходится грузить не только список статей, но и каждую статью в отдельности, так что если вам оно не надо — то флаг -skipTags нехило ускорить процесс скачивания данных.
Ну и в качестве бонуса — JSON-файл с этой же информацией.

Исходники лежат на GitHub, написана утилита на Java 10, и. Уже собранный JAR, инструкция по использованию и примеры – там же, в разделе релизов.
Поскольку Хабрахабр API — миф*, то утилитка просто и уныло разбирает HTML через jsoup. Натравливать утилитку можно как на личные, так и на корпоративные блоги — ей всё едино.
Для корпоративных блогов — передаём программе ссылку на сам блог, например
Для личных блогов нужно указывать страничку с постами, например:
Более подробная справка встроена в приложение, плюс есть readme файл в репозитории.
* может и нет, но я такой информации найти не смог
Не вопрос — баги или пожелания оставляйте в гитхабовские issues, предложения и доработки — туда же в виде pull-request’ов. Ну или прямо здесь в комментариях!
Какую статистику выдаёт?
CSV-файл с базовой информацией о всех статьях:
- название
- рейтинг статьи
- число добавлений в закладки
- число просмотров
- число комментариев
- автор
- ссылка на статью
(более крупная версия скриншота доступна по клику)
CSV-файл c информацией, какой автор в блоге несёт ответственность за какое число просмотров/комментариев/плюсов/добавлений в закладки.
CSV-файл с аналогичной информацией, но сгруппированной по хабам.
CSV-файл с аналогичной информацией, но сгруппированной по тегам. Для скачивания тегов приходится грузить не только список статей, но и каждую статью в отдельности, так что если вам оно не надо — то флаг -skipTags нехило ускорить процесс скачивания данных.
Ну и в качестве бонуса — JSON-файл с этой же информацией.
Где взять?
Исходники лежат на GitHub, написана утилита на Java 10, и. Уже собранный JAR, инструкция по использованию и примеры – там же, в разделе релизов.
Как работает и как использовать?
Поскольку Хабрахабр API — миф*, то утилитка просто и уныло разбирает HTML через jsoup. Натравливать утилитку можно как на личные, так и на корпоративные блоги — ей всё едино.
Для корпоративных блогов — передаём программе ссылку на сам блог, например
https://habr.com/company/JetBrains/Для личных блогов нужно указывать страничку с постами, например:
https://habr.com/users/milfgard/posts/Более подробная справка встроена в приложение, плюс есть readme файл в репозитории.
* может и нет, но я такой информации найти не смог
Я нашёл баг / хочу ещё фичу
Не вопрос — баги или пожелания оставляйте в гитхабовские issues, предложения и доработки — туда же в виде pull-request’ов. Ну или прямо здесь в комментариях!
qwert_ukg
A u habra razve net open api?
Newbilius Автор
Я не нашёл. Если есть — поделитесь ссылкой, учту и с удовольствием использую.
Boomburum
Общедоступного нет, но сам API есть — даём доступ в некоторых случаях :) Сейчас напишу вам.