

Что мы делаем
Возьмём две группы слов:
- бег, съёмка, черчение, поход, ходьба;
- бегун, фотограф, инженер, турист, атлет.
Для человека не составляет труда определить, что в первой группе представлены существительные, называющие действия или события; во второй — называющие людей. Наша цель — научить решать такого рода задачи машину.
Для этого необходимо:
- Выяснить, какие естественные классы существуют в языке.
- Разметить достаточное количество слов на предмет принадлежности к классам из п.1.
- Создать алгоритм, обучающийся на разметке из п.2 и воспроизводящий классификацию на незнакомых словах.
w1 | w2 | cosine_sim |
| | |
бег | бег | 1.0000 |
бег | бегун | 0.6618 |
бег | ходьба | 0.5410 |
бег | атлет | 0.3389 |
бег | поход | 0.1531 |
бег | съёмка | 0.1342 |
бег | черчение | 0.1067 |
бег | турист | 0.0681 |
бег | инженер | 0.0458 |
бег | фотограф | 0.0373 |
| | |
съёмка | съёмка | 1.0000 |
съёмка | фотограф | 0.5782 |
съёмка | турист | 0.2525 |
съёмка | черчение | 0.2116 |
съёмка | поход | 0.1644 |
съёмка | инженер | 0.1579 |
съёмка | бег | 0.1342 |
съёмка | бегун | 0.1275 |
съёмка | ходьба | 0.1100 |
съёмка | атлет | 0.0975 |
| | |
черчение | черчение | 1.0000 |
черчение | инженер | 0.3575 |
черчение | съёмка | 0.2116 |
черчение | фотограф | 0.1587 |
черчение | ходьба | 0.1207 |
черчение | бег | 0.1067 |
черчение | атлет | 0.0889 |
черчение | поход | 0.0794 |
черчение | бегун | 0.0705 |
черчение | турист | 0.0430 |
| | |
поход | поход | 1.0000 |
поход | турист | 0.1896 |
поход | ходьба | 0.1753 |
поход | съёмка | 0.1644 |
поход | бегун | 0.1548 |
поход | бег | 0.1531 |
поход | атлет | 0.0889 |
поход | черчение | 0.0794 |
поход | инженер | 0.0568 |
поход | фотограф | -0.0013 |
| | |
ходьба | ходьба | 1.0000 |
ходьба | бег | 0.5410 |
ходьба | бегун | 0.3442 |
ходьба | атлет | 0.2469 |
ходьба | поход | 0.1753 |
ходьба | турист | 0.1650 |
ходьба | черчение | 0.1207 |
ходьба | съёмка | 0.1100 |
ходьба | инженер | 0.0673 |
ходьба | фотограф | 0.0642 |
| | |
бегун | бегун | 1.0000 |
бегун | бег | 0.6618 |
бегун | атлет | 0.4909 |
бегун | ходьба | 0.3442 |
бегун | поход | 0.1548 |
бегун | турист | 0.1427 |
бегун | инженер | 0.1422 |
бегун | съёмка | 0.1275 |
бегун | фотограф | 0.1209 |
бегун | черчение | 0.0705 |
| | |
фотограф | фотограф | 1.0000 |
фотограф | съёмка | 0.5782 |
фотограф | турист | 0.3687 |
фотограф | инженер | 0.2334 |
фотограф | атлет | 0.1911 |
фотограф | черчение | 0.1587 |
фотограф | бегун | 0.1209 |
фотограф | ходьба | 0.0642 |
фотограф | бег | 0.0373 |
фотограф | поход | -0.0013 |
| | |
инженер | инженер | 1.0000 |
инженер | черчение | 0.3575 |
инженер | фотограф | 0.2334 |
инженер | съёмка | 0.1579 |
инженер | турист | 0.1503 |
инженер | атлет | 0.1447 |
инженер | бегун | 0.1422 |
инженер | ходьба | 0.0673 |
инженер | поход | 0.0568 |
инженер | бег | 0.0458 |
| | |
турист | турист | 1.0000 |
турист | фотограф | 0.3687 |
турист | съёмка | 0.2525 |
турист | поход | 0.1896 |
турист | ходьба | 0.1650 |
турист | инженер | 0.1503 |
турист | атлет | 0.1495 |
турист | бегун | 0.1427 |
турист | бег | 0.0681 |
турист | черчение | 0.0430 |
| | |
атлет | атлет | 1.0000 |
атлет | бегун | 0.4909 |
атлет | бег | 0.3389 |
атлет | ходьба | 0.2469 |
атлет | фотограф | 0.1911 |
атлет | турист | 0.1495 |
атлет | инженер | 0.1447 |
атлет | съёмка | 0.0975 |
атлет | поход | 0.0889 |
атлет | черчение | 0.0889 | слово | семантический тег |
| |
бег | ABSTRACT:ACTION |
съёмка | ABSTRACT:ACTION |
черчение | ABSTRACT:ACTION |
поход | ABSTRACT:ACTION |
ходьба | ABSTRACT:ACTION |
бегун | HUMAN |
фотограф | HUMAN |
инженер | HUMAN |
турист | HUMAN |
атлет | HUMAN |Что сделано и где скачать
Результатом работы, опубликованном в репозитории на ГХ и доступным для скачивания, является описание иерархии классов и разметка (ручная и автоматическая) существительных по этим классам.
Для знакомства с датасетом можно воспользоваться интерактивным навигатором (ссылка в репозитории). Также существует упрощённая версию набора, в котором мы убрали всю иерархию и каждому слову присвоили один единственный крупный семантический тег: «люди», «животные», «места», «вещи», «действия» и т.д.
Ссылка на Гитхаб: открытая семантика русского языка (датасет).
О классах слов
В задачах классификации сами классы зачастую продиктованы решаемой проблемой и работа инженера данных сводится к поиску удачного набора признаков, поверх которого можно построить работающую модель.
В нашей задаче классы слов, строго говоря, заранее неизвестны. Здесь на помощь приходит большой пласт исследований по семантике, проделанных отечественными и зарубежными учёными-лингвистами, знакомство с существующими семантическими словарями и WordNet'ами.
Это хорошее подспорье, но всё же окончательное решение формируется уже внутри нашего собственного исследования. Дело здесь вот в чём. Многие семантические ресурсы начали создаваться в докомпьютерную эпоху (по крайней мере в современном понимании компьютера) и выбор классов во многом диктовался языковой интуицией их создателей. В конце предыдущего столетия WordNet'ы нашли активное применение в задачах автоматического анализа текстов и многие вновь созданные ресурсы были заточены под конкретные практические применения.
Результатом стало то, что данные языковые ресурсы одновременно содержат как лингвистические, так и внеязыковые, энциклопедические сведения об единицах языка. Логично предположить, что построить модель, которая бы проверяла внеязыковые сведения, опираясь только на статистический анализ текстов невозможно, ведь в источнике данных просто не содержится необходимых сведений.
Исходя из этого предположения мы ищем только естественные классы, которые могут быть обнаружены и автоматически проверены, опираясь на чисто лингвистическую модель. При этом архитектура системы допускает добавление сколь угодно большого количества дополнительных слоёв информации о языковых единицах, которые могут быть полезны в рамках практических применений.
Продемонстрируем вышесказанное на конкретном примере, разобрав слово «холодильник». Из лингвистической модели мы можем узнать, что «холодильник» это материальный объект, конструкция, является вместилищем типа «коробка или сумка», т.е. не предназначенном для хранения жидкостей или сыпучих тел без дополнительной ёмкости. При этом из этой модели не ясно, что «холодильник» является товаром, причём товаром длительного пользования, а также неясно, что это артефакт, т.е. объект, произведённый человеком. Это и есть внеязыковая информация, которая должна поставляться отдельно.

Зачем всё это нужно
Как бы то ни было, человек в процессе обучения и познания действительности нанизывает дополнительные сведения об окружающих его объектах и явлениях на естественный каркас, усвоенный им в детстве. При этом некоторые концепты являются универсальными, независящими от предметной области, и могут успешно переиспользоваться.
Скажем «продавец» — это человек + функциональная роль. В некоторых случаях случаях продавцом может выступать группа людей или организация, но при этом всегда сохраняется субъектность: в противном случае будет невозможно выполнение целевого действия. Слова «обмен» или «обучение» называют действия, т.е. у них есть участники, длительность и результат. Точное содержание данных действий может значительно варьироваться в зависимости от ситуации и предметной области, но определённые аспекты будут представлять собой инвариант. Это и есть языковой каркас на который наслаивается переменное внеязыковое знание.
Наша цель найти и исследовать максимум доступной интралингвистической информации и построить на её основе объяснительную модель языка. Это позволит усовершенствовать существующие алгоритмы автоматической обработки текста, в т.ч. таких сложных, как разрешение лексической неоднозначности, разрешение анафоры, сложные случаи морфологической разметки. В процессе мы обязательно где-то будем упираться в необходимость привлечения внеязыковых знаний, но по крайней мере мы будем знать, где проходит та самая граница, когда внутренних знаний о языке уже недостаточно.
Классификация и обучение, набор признаков
Пока что мы работаем только с существительными, поэтому ниже, говоря «слово», будем подразумевать знаки, относящиеся только к этой части речи. Поскольку мы решили использовать только интралингвистическую информацию, то работать будем с текстами, снабжёнными морфологической разметкой.
В качестве признаков возьмём все возможные микроконтексты в которых встречается данное слово. Для существительных это будут:
- ПРИЛ + X (красивые X: глаза)
- ГЛАГ + X (вдеть X: нитку)
- ГЛАГ + ПРЕДЛ + X (войти в X: дверь)
- X + СУЩ_РОД (X: край стола)
- СУЩ + X_РОД (рукоять X: сабли)
- X_СУБЪЕКТ + ГЛ (X: сюжет развивается)
Типов микроконтекстов существует больше, но вышеперечисленные являются наиболее частотными и уже дают неплохой результат при обучении.
Все микроконтексты приводим к базовой форме и составляем из них набор признаков. Далее для каждого слова составляем вектор, i-ая координата которого будет коррелировать со встречаемостью заданного слова в i-ом микроконтексте.
микроконтекст | тип | встречаемость | значение |
| | | |
достать из | VBP_РОД | 3043 | 1.0000 |
тяжёлый | ADJ | 2426 | 0.9717 |
карман | NX_NG | 1438 | 0.9065 |
вытащить из | VBP_РОД | 1415 | 0.9045 |
полезть в | VBP_ВИН_НЕОД | 1300 | 0.8940 |
лямка | NX_NG | 1292 | 0.8932 |
свой | NX_NG | 1259 | 0.8900 |
небольшой | ADJ | 1230 | 0.8871 |
огромный | ADJ | 1116 | 0.8749 |
большой | ADJ | 903 | 0.8485 |
набитый | ADJ | 849 | 0.8408 |
содержимое | NX_NG | 814 | 0.8356 |
походный | ADJ | 795 | 0.8326 |
пустой | ADJ | 794 | 0.8325 |
порыться в | VBP_ПРЕД | 728 | 0.8217 |
тяжеленный | ADJ | 587 | 0.7948 |
школьный | ADJ | 587 | 0.7948 |
положить в | VBP_ВИН_НЕОД | 567 | 0.7905 |
рыться в | VBP_ПРЕД | 549 | 0.7865 |
сунуть в | VBP_ВИН_НЕОД | 538 | 0.7840 |
лежать в | VBP_ПРЕД | 495 | 0.7736 |
вынуть из | VBP_РОД | 484 | 0.7708 |
день | NX_NG | 476 | 0.7687 |
старый | ADJ | 463 | 0.7652 |
тяжесть | NX_NG | 459 | 0.7642 |Целевое значение, иерархия семантических срезов
Язык располагает естественными механизмами переиспользования слов из-за чего возникает такое явление как многозначность. При этом иногда переиспользуются не просто отдельные слова, а делается метафорический перенос целых концептов. Особенно хорошо это заметно при переходе от вещественных понятий к абстрактным.
Этот факт диктует необходимость иерархической классификации, при котором семантические срезы выстроены в древовидную структуру и разбиение происходит в каждом внутреннем узле. Это позволяет намного эффективнее справляться с многозначностью в микроконтекстах.
Другая вездесущая онтологическая метафора — это метафора контейнера, или вместилища (container), предполагающая проведение границ в континууме нашего опыта и осмысление его через пространственные категории. По мнению авторов, способ восприятия окружающего мира человеком определяется его опытом обращения с дискретными материальными объектами и в частности его восприятием себя, своего тела. Человек — существо, отграниченное от остального мира кожей. Он — вместилище (container), и потому ему свойственно воспринимать прочие сущности как вместилища с внутренней частью и наружной поверхностью.
Скребцова Т. Г. Когнитивная лингвистика: классические теории, новые
подходы
Построенная нами модель действует в едином пространстве признаков и позволяет обучаться на вещественных примерах, а предсказания делать в области абстрактного. Это позволяет делать описанный выше перенос. Так, например, следующие слова представляют собой абстрактные контейнеры, что вполне согласуется с интуитивным представлением:

Ещё одним интересным примером может служить перенос концепции «жидкости» в сферу нематериального:
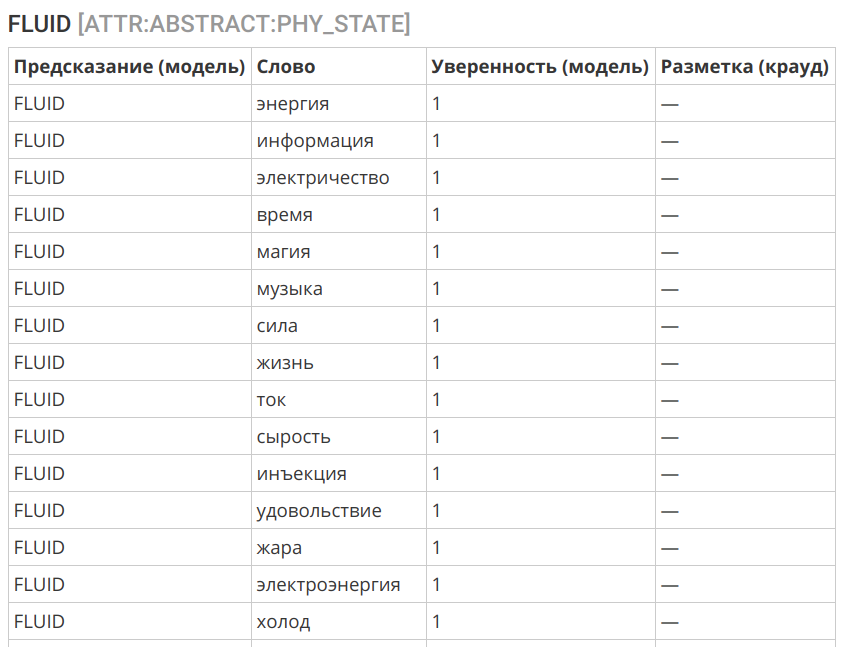
Выбор алгоритма
В качестве алгоритма мы использовали логистическую регрессию. Обусловлено это несколькими факторами:
- Исходная разметка так или иначе содержит определённое количество ошибок и шума.
- Признаки могут быть несбалансированными и также содержать ошибки — многозначность и метафорическое (переносное) использование слова.
- Предварительный анализ подсказывает, что адекватно выбранная граница раздела должна фиксироваться достаточно простым алгоритмом.
- Важна хорошая интерпретируемость алгоритма.
Алгоритм продемонстрировал вполне неплохую точность:
== ENTITY ==
slice | label | count | correctCount | accuracy |
| | | | |
ENTITY | PHYSICAL | 12249 | 11777 | 0.9615 |
ENTITY | ABSTRACT | 9854 | 9298 | 0.9436 |
| | | | |
| | | | 0.9535 |
== PHYSICAL:ROLE ==
slice | label | count | correctCount | accuracy |
| | | | |
PHYSICAL:ROLE | ORGANIC | 7001 | 6525 | 0.9320 |
PHYSICAL:ROLE | INORGANIC | 3805 | 3496 | 0.9188 |
| | | | |
| | | | 0.9274 |
== PHYSICAL:ORGANIC:ROLE ==
slice | label | count | correctCount | accuracy |
| | | | |
PHYSICAL:ORGANIC:ROLE | HUMAN | 4879 | 4759 | 0.9754 |
PHYSICAL:ORGANIC:ROLE | ANIMAL | 675 | 629 | 0.9319 |
PHYSICAL:ORGANIC:ROLE | FOOD | 488 | 411 | 0.8422 |
PHYSICAL:ORGANIC:ROLE | ANATOMY | 190 | 154 | 0.8105 |
PHYSICAL:ORGANIC:ROLE | PLANT | 285 | 221 | 0.7754 |
| | | | |
| | | | 0.9474 |
== PHYSICAL:INORGANIC:ROLE ==
slice | label | count | correctCount | accuracy |
| | | | |
PHYSICAL:INORGANIC:ROLE | CONSTRUCTION | 1045 | 933 | 0.8928 |
PHYSICAL:INORGANIC:ROLE | THING | 2385 | 2123 | 0.8901 |
PHYSICAL:INORGANIC:ROLE | SUBSTANCE | 399 | 336 | 0.8421 |
| | | | |
| | | | 0.8859 |
== PHYSICAL:CONSTRUCTION:ROLE ==
slice | label | count | correctCount | accuracy |
| | | | |
PHYSICAL:CONSTRUCTION:ROLE | TRANSPORT | 188 | 178 | 0.9468 |
PHYSICAL:CONSTRUCTION:ROLE | APARTMENT | 270 | 241 | 0.8926 |
PHYSICAL:CONSTRUCTION:ROLE | TERRAIN | 285 | 253 | 0.8877 |
| | | | |
| | | | 0.9044 |
== PHYSICAL:THING:ROLE ==
slice | label | count | correctCount | accuracy |
| | | | |
PHYSICAL:THING:ROLE | WEARABLE | 386 | 357 | 0.9249 |
PHYSICAL:THING:ROLE | TOOLS | 792 | 701 | 0.8851 |
PHYSICAL:THING:ROLE | DISHES | 199 | 174 | 0.8744 |
PHYSICAL:THING:ROLE | MUSIC_INSTRUMENTS | 63 | 51 | 0.8095 |
PHYSICAL:THING:ROLE | WEAPONS | 107 | 69 | 0.6449 |
| | | | |
| | | | 0.8739 |
== PHYSICAL:TOOLS:ROLE ==
slice | label | count | correctCount | accuracy |
| | | | |
PHYSICAL:TOOLS:ROLE | PHY_INTERACTION | 213 | 190 | 0.8920 |
PHYSICAL:TOOLS:ROLE | INFORMATION | 101 | 71 | 0.7030 |
PHYSICAL:TOOLS:ROLE | EM_ENERGY | 72 | 49 | 0.6806 |
| | | | |
| | | | 0.8031 |
== ATTR:INORGANIC:WEARABLE ==
slice | label | count | correctCount | accuracy |
| | | | |
ATTR:INORGANIC:WEARABLE | NON_WEARABLE | 538 | 526 | 0.9777 |
ATTR:INORGANIC:WEARABLE | WEARABLE | 282 | 269 | 0.9539 |
| | | | |
| | | | 0.9695 |
== ATTR:PHYSICAL:CONTAINER ==
slice | label | count | correctCount | accuracy |
| | | | |
ATTR:PHYSICAL:CONTAINER | CONTAINER | 636 | 627 | 0.9858 |
ATTR:PHYSICAL:CONTAINER | NOT_A_CONTAINER | 1225 | 1116 | 0.9110 |
| | | | |
| | | | 0.9366 |
== ATTR:PHYSICAL:CONTAINER:TYPE ==
slice | label | count | correctCount | accuracy |
| | | | |
ATTR:PHYSICAL:CONTAINER:TYPE | CONFINED_SPACE | 291 | 287 | 0.9863 |
ATTR:PHYSICAL:CONTAINER:TYPE | CONTAINER | 140 | 131 | 0.9357 |
ATTR:PHYSICAL:CONTAINER:TYPE | OPEN_AIR | 72 | 64 | 0.8889 |
ATTR:PHYSICAL:CONTAINER:TYPE | BAG_OR_BOX | 43 | 31 | 0.7209 |
ATTR:PHYSICAL:CONTAINER:TYPE | CAVITY | 30 | 20 | 0.6667 |
| | | | |
| | | | 0.9253 |
== ATTR:PHYSICAL:PHY_STATE ==
slice | label | count | correctCount | accuracy |
| | | | |
ATTR:PHYSICAL:PHY_STATE | SOLID | 308 | 274 | 0.8896 |
ATTR:PHYSICAL:PHY_STATE | FLUID | 250 | 213 | 0.8520 |
ATTR:PHYSICAL:PHY_STATE | FABRIC | 72 | 51 | 0.7083 |
ATTR:PHYSICAL:PHY_STATE | PLASTIC | 78 | 42 | 0.5385 |
ATTR:PHYSICAL:PHY_STATE | SAND | 70 | 31 | 0.4429 |
| | | | |
| | | | 0.7853 |
== ATTR:PHYSICAL:PLACE ==
slice | label | count | correctCount | accuracy |
| | | | |
ATTR:PHYSICAL:PLACE | NOT_A_PLACE | 855 | 821 | 0.9602 |
ATTR:PHYSICAL:PLACE | PLACE | 954 | 914 | 0.9581 |
| | | | |
| | | | 0.9591 |
== ABSTRACT:ROLE ==
slice | label | count | correctCount | accuracy |
| | | | |
ABSTRACT:ROLE | ACTION | 1497 | 1330 | 0.8884 |
ABSTRACT:ROLE | HUMAN | 473 | 327 | 0.6913 |
ABSTRACT:ROLE | PHYSICS | 257 | 171 | 0.6654 |
ABSTRACT:ROLE | INFORMATION | 222 | 146 | 0.6577 |
ABSTRACT:ROLE | ABSTRACT | 70 | 15 | 0.2143 |
| | | | |
| | | | 0.7896 |Анализ ошибок
Возникающие при автоматической классификации ошибки обусловлены тремя основными факторами:
- Омонимия и полисемия: слова, имеющие одинаковое начертание, могут иметь разное значение (мука и мука, остановка как процесс и остановка как локация). Сюда же можно отнести метафорическое употребление слов и метонимию (например дверь будет классифицирована как замкнутое пространство — это ожидаемая особенность языка).
- Несбалансированность контекстов употребления слова. Некоторые органичные употребления могут отсутствовать в исходном корпусе, приводя к ошибкам при классификации.
- Неверно выбранная граница класса. Можно провести такие границы, которые невычислимы из контекстов и требуют привлечения внеязыковых знаний. Тут алгоритм будет бессилен.
На данном этапе мы обращаем внимание только на ошибки третьего типа и корректируем выбранную границу между классами. Ошибки первых двух типов в заданной конфигурации системы неустранимы, но при достаточном объёме размеченных данных они не представляют большой проблемы — это видно из точности разметки верхних проекций.
Что дальше
На данный момент датасет охватывает большинство существительных, существующих в русском языке и представленных в корпусе в достаточном разнообразии контекстов. Основной фокус был сделан на вещественных объектах — как наиболее понятных и проработанных в научных работах. Остаются задачи по уточнению существующей разметки с учётом данных, полученных от алгоритма, и работа с классами на нижних ярусах, где наблюдается падение точности предсказания, обусловленное размыванием границ между категориями.
Но это в своём роде рутинная работа, которая есть всегда. Качественно новой пласт исследований будет касаться возможности классификации того или иного слова в конкретном контексте или предложении, что позволит учесть явления омонимии и полисемии, включая метафору (переносные значения).
Также у нас сейчас в работе несколько сопутствующих проектов:
- словарь узнаваемости слов РЯ: вариация частотного словаря, где понятность и знакомость слова оценивается в результате краудсорсинговой разметки, а не высчитывается по корпусу текстов.
- открытый корпус по разрешению лексической неоднозначности: по мотивам соревнования RUSSE 2018 WSI&D Shared Task, проводимого в рамках конференции Диалог-2018, стала понятна полезность корпуса со снятой лексической неоднозначностью для апробации автоматических алгоритмов по дизамбигуации и кластеризации значений слов. Также данный корпус понадобится нам для перехода к описанному в предыдущем абзаце этапу работы над открытой семантикой.
Тональный словарь русского языка
Тональный словарь представляет собой слова и выражения РЯ, размеченные по тональности и силе выраженности эмоционально-оценочного заряда. Проще говоря, насколько то или иное слово является «плохим» или «хорошим».
В настоящий момент размечено 67.392 знака (из них 55.532 слов и 11.860 выражений).
Обратная связь и распространение датасета
Будем рады любой обратной связи в комментариях — от критики работы и выбранных нами подходов до ссылок на интересные исследования и статьи по теме.
Если у вас есть знакомые или коллеги, которым может быть интересен опубликованный датасет, перешлите им ссылку на статью или репозиторий, чтобы помочь в распространении открытых данных.
Ссылка на скачивание и лицензия
Датасет: открытая семантика русского языка
Датасет распространяется по лицензии CC BY-NC-SA 4.0.
Комментарии (23)

madrugado
25.12.2018 14:54большое вам спасибо за работу, но на мой взгляд NC в лицензии было сделано зря, есть множество компаний, которые бы хотели использовать этот датасет, но теперь не имеют возможности
snakers4
25.12.2018 15:55Про коммерческое использование.
Смотрели этот датасет. Он, конечно же, прекрасен и автор большой молодец (помню он как-то писал мне год назад, я шерил на канале их сбор народа на крауд), но вот одна беда — даже имея иерархию предметной области, использовать это в своем домене — ну почти нереально.
Разве что только датасет с эмоциями для каких-то «ручных» алгоритмов (без обучения).
Почему? Поясню на примере.
Вот есть слово ноготь. Это физический объект. Но вот в бизнесе это будет некий атом некой услуги. И как использовать это напрямую — непонятно =(kdenisk Автор
26.12.2018 10:45Здравствуйте, помню вас. Спасибо, что помогали шером и распространением информации!
Что касается применимости. Познание внутренней структуры языка — это путь. И он не обещает быть ни простым, ни коротким. Сейчас мы пытаемся переложить тот пласт лингвистических исследований (в первую очередь когнитивистов), которые были сделаны в последние 50 лет, на современные технологические рельсы.
Опять же, какими бы ни были коммерческие процессы — это всегда взаимодействие субъектов, объектов (assets) и процессов. Возможность их эффективно вычленять из потока текстовой информации, отделять общеязыковые, каркасные единицы от тематических, специализированных и строить модели поверх более высокоуровневых, чем слова или символы объектов — чем не задача.
Это на перспективу. Программа минимум сейчас — обогатить предельно грубую частеречную разметку инвариантной семантикой и посмотреть, насколько это поможет существующим алгоритмам. Только так, маленькими шажочками и кропотливой работой, придём к качественному результату. Волшебной пилюли здесь нет.snakers4
27.12.2018 05:23Ну что тут сказать.
В плане есть работа с чатами на разметки по типу SQUAD.
Если дойдем до этого, подадим разметку из PyMorphy и ваши теги отдельным каналом, заценим точность) Может тот факт, что холодильник это контейнер в квартире поможет. Но наверное, придется разметить и оставить только нужные теги.
Но это все, конечно же, все неточно и subject to популяции кроликов в Австралии =)snakers4
27.12.2018 08:01Опача
Нашел русский сквад
В общем заюзаем в своем простом бейслайне, проверим RNN против TCN и Trellis сеток, подадим ваши сущности каналом сетке
Будет весело
kdenisk Автор
26.12.2018 10:49+1Мы всецело заинтересованы в том, чтобы данные использовались максимально широко, а не пылились на ГХ. Но когда мы запускали проект были не вполне ясны его перспективы и потенциал для научных и коммерческих применений, поэтому выбрали наиболее строгий вариант лицензии — взять время на подумать, посмотреть что к чему и решить, решить куда хотим развиваться дальше.
Сейчас пришли к пониманию того, что лицензию через какое-то время можно будет сделать более свободной. При этом данные для коммерческих организаций можно получить уже сейчас: достаточно написать на kartaslov@mail.ru с описанием кейса или примерных целей использования и мы отправим своё согласие на использование.
trapwalker
25.12.2018 18:28Хабр ТОРТ! Статья — огонь!
Вопрос по поводу
- Омонимия и полисемия: слова, имеющие одинаковое начертание, могут иметь разное значение (мука и мука, остановка как процесс и остановка как локация). Сюда же можно отнести метафорическое употребление слов и метонимию (например дверь будет классифицирована как замкнутое пространство — это ожидаемая особенность языка).
- Несбалансированность контекстов употребления слова. Некоторые органичные употребления могут отсутствовать в исходном корпусе, приводя к ошибкам при классификации.
[..]
Ошибки первых двух типов в заданной конфигурации системы неустранимы
Не понятно почему эти ошибки по-вашему неустранимы.
Можно же изначально считать каждый семантический атом неоднозначно связанным с набором его лексических представлений. Тогда употребление омонимов в тексте будет вызывать смысловое ветвление, но у каждой такой веточки будет свой кумулятивный вес. Если среди взвешенных семантических веток есть ярко выраженный лидер, то его можно брать как основную гипотезу, иначе у нас просто несколько разновероятных смыслов. И с этим нужно работать.
Дополню. Вообще вся это онтологическая и семантическая кухня в натуральных языках, как мне кажется, здорово ложится на язык Пролог. Такое ощущение, что уже сейчас вашу БД можно сконвертировать в большую базу предикатов и атомов, а потом играться с ней выявляя интересные закономрености.kdenisk Автор
26.12.2018 11:02Они устранимы и мы будем с ними работать, просто сейчас стоит другая задача. Нет никакого смысла размечать отдельные слова или даже отдельные значения — как потом такую разметку увязать с конкретным контекстом? Наша задача разметить понятия, концепты словами, примерами, чтобы потом в каждом конкретном случае употребления сказать — оно подходит под этот концепт, маркируем таким-то тегом.
Согласно когнитивным теориям языка оно примерно так и устроено в нашей голове. Т.е. мы примерно понимаем границы явлений и можем с разной степенью уверенности говорить, что та или иная языковая единица подходит под конкретное из них. Но при этом попробуйте сформулировать, что такое «игра» или даже тот же «смысл» — это очень непросто, если вообще возможно. А главное, полученное описание будет совершенно непригодно в качестве инструмента классификации: всё равно проще на примерах показать.
Суть качественного скачка, которое сделало машинное обучение, именно в этом — не объяснять компьютеру в чём отличие кошек от собак, а показать 100 картинок тех и тех, а дальше он сам разберётся. Здесь та же идея, но с языковыми единицами.trapwalker
26.12.2018 12:27А никто и не предлагал маркировать изолированные слова. Суть та же, что с картинками. Вы показываете компьютеру размеченый корпус, а он находит в нём закономерности, по некотороым абстрактным шаблонам. Так вы дополнительно можете промаркировать корпус признаками Объекта, Предмета, Контейнера и более сложными. В случае с омонимами как раз вполне разрешимая задача предположить какое из понятий лучше подходит для этого места. И здесь речь не только о словах, но и о выражениях вроде «гореть на работе» или "[глоток] [свежего воздуха]".
kdenisk Автор
26.12.2018 14:01Всё верно: можно разметить корпус и дальше использовать подходы, работающие сейчас для предсказания частеречной и морфологической разметки. Другое дело, что синтаксис и морфология хорошо изучены и более-менее понятно, какими классами размечать. Но даже там есть масса сложных случаев, требующих вдумчивости и специальных знаний (можно попробовать сложные задания на opencorpora.org).
Чтобы провернуть такой трюк для семантики нужно найти достоверные классы — это мы и делаем. Другое соображение, что разметив достаточно большое количество слов можно будет попробовать обойтись без необходимости разметки корпуса. Вот, например, контраст физических ёмкостей против предметов:
микроконтекст | тип | значение | | | | отхлёбывать из | VBP_РОД | 0.9990 | отпивать из | VBP_РОД | 0.9989 | окунуть в | VBP_ВИН_НЕОД | 0.9986 | разлить в | VBP_РОД | 0.9984 | мадеры | XG_NG | 0.9981 | лака | XG_NG | 0.9978 | порционный | ADJ | 0.9978 | плюхнуться в | VBP_ВИН_НЕОД | 0.9978 | вариться в | VBP_ПРЕД | 0.9978 | плескаться в | VBP_ПРЕД | 0.9978 | плова | XG_NG | 0.9977 | налитой | ADJ | 0.9976 | макать в | VBP_ВИН_НЕОД | 0.9976 | политься в | VBP_ВИН_НЕОД | 0.9975 | долить в | VBP_ВИН_НЕОД | 0.9975 | кальвадоса | XG_NG | 0.9974 | выложить в | VBP_РОД | 0.9974 | умыться из | VBP_РОД | 0.9973 | чачи | XG_NG | 0.9973 | плевать в | VBP_ВИН_НЕОД | 0.9971 | термоса | XG_NG | 0.9971 | отлить в | VBP_ВИН_НЕОД | 0.9969 | чернил | XG_NG | 0.9969 | разложить в | VBP_РОД | 0.9968 | процедить в | VBP_ВИН_НЕОД | 0.9968 |
Вполне себе рабочий семантический TF-IDF.
kdenisk Автор
26.12.2018 11:03С Прологом всё не так просто. Язык, да и мышление в целом, подчиняются нечёткой логике и в словоупотреблении встречается много ситуаций семантического блендинга — смешения в слове нескольких смыслов в неизвестных заранее пропорциях. Причём разные контексты «подсвечивают» разные смыслы в одном слове.
Например: «убрать книгу в рюкзак» — это про свойство быть контейнером, «купить рюкзак» — про свойство быть товаром, «взвалить рюкзак на плечи» — одновременно про свойство быть надеваемым и быть достаточно громоздким, «усесться на рюкзак» — про свойство быть предметом, достаточно твёрдым, чтобы служить сидением. В общем пока такое разнообразие компьютеру скорее не зубам.trapwalker
26.12.2018 12:45Ну почему, как раз то, что вы перечислили вполне описывается отдельными правилами и не противоречит друг другу. В статье это, мне показалось, называется не свойствами, а «семантическими ролями», но не суть важно.
Все эти роли могут быть отдельными предикатами или атомами. В качестве атомов они могут быть аргументами предикатов-отношений — это ещё более высокий мета-уровень.
Но я вас кажется понял. В текстах часто встречается не просто смысловая неоднозначность, а двойные и тройные смыслы. Намёки, сарказм, каламбур, ирония… Но и это всё можно разметить. И даже с нечеткой логикой Пролог отлично справляется, если весовые коэффициенты добавить в качестве аргументов.
Хотя согласен, наверно для таких задач пора бы придумать что-то покруче пролога, что-то более заточенное на нечеткую логику, на многозначность и мультиконтекстность.
Да, эзопов язык машины понимать научатся не скоро, но, я надеюсь, они хотя бы научатся в ближайшем будущем сочинять двусмысленные тексты… Надо же что-то новенькое для капчи придумывать.kdenisk Автор
26.12.2018 14:17Намёки, сарказм, каламбур, ирония, юмор в целом и метафора — это даже не следующий этап, а где-то очень-очень нескоро. Впрочем у Шелодона Купера тоже с пониманием сарказма не очень, но при этом он вполне себе обладает интеллектом.
Первостепенная задача научить машину понимать прямые, характерные контексты и строить поверх них несложные логические цепочки. А там уже видно будет.
trapwalker
25.12.2018 18:39+1Вообще в контексте стремительно развивающегося направления всяких голосовых помощников и чат-ботов ваши разработки кажутся чутовищно актуальными. Потребность в них как никогда высока.
Теперь мне уже не кажутся недостижимо далёкими перспективы работы с языковой семантикой на полностью автоматическом уровне, как это, к примеру, красочно описал Юдковскй в своём "Тройном Контакте".kdenisk Автор
26.12.2018 11:07Да, это ли не мечта всех исследователей, работающих с языком! Спасибо за книгу, нужно будет прочитать.
trapwalker
26.12.2018 12:47+1Не побрезгуйте также «Гарри поттером и Методами рационального мышления» Юдковского. Думаю не пожалеете. Название странное, но книга стоит быть прочитанной и не раз.
azazlal
26.12.2018 14:21+1Хорошо, что кто-то этим занимается, правильно. Пока мы очень отстаем в сентимент анализе, его по сути нет для русского языка. Нельзя даже бота-модератора написать, даже на платном софте, для русского языка.
kdenisk Автор
26.12.2018 14:29Согласны. Ничто не мешает для русского языка создавать датасеты и технологии не уступающие тем, что есть для английского и основных европейских языков. В особенности с учётом того, насколько у нас сильная лингвистическая школа.
buriy
26.12.2018 19:26+11) Я не очень понимаю, почему вы называете это лишь «семантикой», так как, если я правильно понял, в основном у вас ловятся синтактико-семантические отношения, но слово «синтаксис» у вас ни разу за статью даже не упоминается. Да и вообще, именно «семантика» — это про энциклопедические знания, которые вы признаёте трудными для автоматического сбора, а вот «синтаксис» — он про сочетание слов друг с другом в рамках предложения, и это как раз то, что вы ловите! Далее, часть из этих классов уже даже помечена в морфо-синтаксических словарях, скажем, взятая вами для примера одушевлённость, нужная, чтобы отличать «бегуна» от «бега» — а одушевлённость нужно отмечать в морфологических словарях, потому что винительный падеж множественного числа образуется для них по-разному: вижу бегунов/атлетов vs нет бегунов/атлетов, вижу бега/черчения vs нет бегов/черчений.
2) Вы, наверное, удивитесь, но word2vec имеет встроенную кластеризацию, которая даже из коробки неплохо ловит подобные синтаксическо-семантические классы. Можно и дальше развивать данную идею.
Подскажу, как сделать, чтобы word2vec ещё лучше выделял подобные классы: нужно его тренировать на нелемматизированном корпусе, тогда синтаксические падежные отношения подберут большую часть ваших классов для существительных, но заодно выделят ещё и классы на глаголах, прилагательных, числительных, наречиях. Поэтому мне очень не нравится ваше объяснение вида «word2vec такого не может, поэтому нам пришлось долго и мучительно изобретать своё решение» — увы, боюсь, он про «мы не смогли сделать». Пройдите теперь чуть дальше: нелемматизированный word2vec внутри делает ровно то же самое, что делает ваш самописный алгоритм сравнения гистограмм распределений, и сработает даже на неразмеченном корпусе, может, будет лишь чуть-чуть более шумным.
3) Для решения более глобальных планов ваша идея с семантическим корпусом тоже кажется не лучшим способом движения вперёд. Я в 2012м году был наивным и тоже начал делать подобный словарь, и даже забытый ныне brown clustering и его бинарное дерево группировки слов легко позволяло подобный словарь расширять. Но потом при построении своего синтактико-семантического парсера я увидел, что в языке основные плохо решённые моменты связаны преимущественно с неоднозначностями разного вида: омонимами разного вида, различными смыслами слов (и отсутствием приличного словаря смыслов слов и многословных понятий), фразеологизмами, проблемой кореференции, и многословными сущностями (задачи NER и EMD). А потом пришли нейросети. Так вот: подобные найденных вами синтактико-семантические зависимости нейросетикушают на завтраклегко сами изучат и будут использовать при парсинге, здесь можно даже взять пример «положить в карман (чего?) куртки» vs «положить в сундук (что?) куртки» — представляете, нейросеть на большом датасете в режиме без учителя способна выучить даже весьма условное понимание наличия карманов у предмета, чтобы потом правильно строить синтаксическо-семантические связи между словами в данных предложениях. А у вас, наверное, и «карман» и «сундук» в один класс «ёмкостей» попадут, а в какой класс попадёт «болгарка» я даже боюсь предположить… ;)
Справедливости ради, вы про всё это пишете, однако вы считаете подобные проблемы принципиально неустранимыми (и в вашем словаре — так и есть, но есть нюанс...). Поэтому я просто призываю вас сразу же пробовать применять ваши идеи для решения практических задач, и в результате начать смотреть на языковые проблемы шире.kdenisk Автор
26.12.2018 20:43Очень крутой комментарий, спасибо!
1) Вы правы, семантик существует как минимум две — нативно-лингвистическая и энциклопедическая (те самые знания о мире). Вторую вычислять из текстов бессмысленно: на то они и знания о мире, что в общетематических текстах о них не написано, это и так всем известно.
Что касается синтаксиса — здесь он служит как вспомогательный инструмент, не более того. Хочется, чтобы компьютер понимал примерно такую цепочку: конструкция «убрать в рюкзак» возможна потому, что аргументом функции «убрать в X» частотно служат контейнеры, а рюкзак является таковым. Синтаксис позволяет понять только то, что на месте икса частотно стоит существительное в неодушевлённом винительном. Это слишком грубое знание, оставляющее массу неоднозначностей.
Касательно категории неодушевлённости — здесь речь идёт о настолько важной и частотной семантике, что язык «решил» её аж в синтаксис зашить. Но других таких случаев я не знаю. И опять же, в задачах синтаксической разметки один из самых сложных случаев — развести именительный неодушевлённый с совпадающим винительным неодушевлённым (пруфы: morphoRuEval-2017, Morphobabushka (M), стр. 19). Что говорит только об одном — эта задача решается человеком на уровень выше — на уровне семантики.

2) Да, действительно удивлюсь. Я очень много работал с word2vec в задаче кластеризации синонимов, крутил его и так и так, разговаривал на эту тему с создателями Watset. Не получается из него вытащить нужную информацию о семантических классах. Собственно данная работа не просто из вакуума появилась, а именно из fail'а при работе с дистрибутивными моделями. Поэтому я всегда сравниваю в статьях с word2vec'ом и делаю акцент на разнице в получаемой информации.
Если вы не согласны и считаете, что можно справиться дистрибутивными моделями — сделайте ответную статью с демонстрацией по фактам. Я без шуток. Это будет тот уровень дискуссии, который позволит получить новое знание для всех. И я буду среди благодарных ваших читателей.
3) Нейросети — огонь-технология, прорыв, никто здесь и не спорит. Но им нужны размеченные данные и каждый раз при переходе в новую предметную область или к новому целевому показателю в той же области — сиди размечай заново. Не говоря уже о тех же фундаментальных проблемах в виде отсутствия внеязыковых данных. И абсолютно непонятно, как их в сетку поставлять. А учёт дискурса, когда в одном отзыве клиент и доволен, и недоволен, и в затылке почесал, и пошутил, и собаку с вами обсудил. Тут вообще пиши-пропало.
Причём даже в задачах компьютерного зрения машине объясняют: тут собака, тут кошка, здесь машина, а это — пешеход. Хотя визуальная информация уже априори более богатая, чем текстовая. Так откуда берётся эта непонятная надежда, что тексты, являющиеся жатым-пережатым источником, компьютер вдруг автомагически научится сам понимать!? Для меня это загадка.
P.S. Ещё раз моя вам благодарность за комментарий — он заставляет думать и задумываться. Все эмоции относятся только к сложности решаемой проблемы и никак не к участником этого обсуждения.snakers4
27.12.2018 05:04К вопросу про сетки и тренировку Word2Vec.
Вы не упоминаете FastText. А надо. Он ловит все эти ваши суффиксы и приставки и падежи.
Откровенно говоря просто пробовал разные готовые вектора на downstream задачах. И FastText для русского языка всегда был лучше.
С сетками, вопрос конечно всегда сводится к поиску халявной разметки, но есть еще небольшой лайфхак — скрестить FastText внутри сетки собственно с сеткой — и сразу уйдут проблемы со словарем, нормализацией форм, итд итп
Еще бы придумать как это скрестить с языковым моделированием и NMT — и считай новая сота в «сложных» языках будет.
По сути получится как бы ансамбль внутри ансамбля. Инициализируем его фаст-текстом и профит. Только докинуть разметки.
> Так откуда берётся эта непонятная надежда, что тексты, являющиеся жатым-пережатым источником, компьютер вдруг автомагически научится сам понимать!?
Не научится. Будет оверфититься на какие-то гипер-окрестности в многомерном пространстве. Но мы все равно этого не поймем кроме как отсмотрев attention или просто увидев что сетка оверфитится на словарь или какие-то особенные косяки языка (редкие слова или имена например).
rotor
Большая и очень полезная работа была проделана.
Огромное вам спасибо!
kdenisk Автор
Спасибо! Сейчас предстоит ещё более сложная и интересная часть работы — перенести разметку в предложения с учётом контекста употребления. Там должен получится реальный буст к существующим алгоритмам прямо из коробки.