
Введение
Приветствую вас, заинтересованные читающие разработчики на не важно каких языках, на которых я ориентирую эти статьи и чьи поддержку и мнения я ценю.
Для начала, по устоявшимся традициям, я приведу ссылки на предыдущие статьи:
Часть 1: пишем языковую ВМ
Часть 2: промежуточное представление программ
Для формирования в вашей голове полного понимания того, что в этих статьях мы пишем, вам стоит заранее ознакомиться с предыдущими частями.
Также мне стоит разместить сразу ссылку на статью о проекте, который был написан мной ранее и на основе которого идет весь этот разбор полётов: Клац сюды. С ним пожалуй стоит ознакомиться первым делом.
И немного о проекте:
> Небольшой сайт проекта
> GitHub репозиторий
Ну и также скажу сразу, что все написано на Object Pascal, а именно — на FPC.
Итак, начнем.
Принцип работы большинства трансляторов
Первым делом, стоит понимать что я не смог бы ничего путного написать, предварительно не ознакомившись с кучей теоретического материала и рядом статеек. Опишу основное в паре слов.
Задача транслятора первым делом — подготовить код к анализу (например удалить из него комментарии) и разбить код на токены (токен — минимальный значащий для языка набор символов).
Далее нужно путем анализа и преобразований разобрать код в некое промежуточное представление и затем уже собрать готовое к выполнению приложение или… Что там ему в общем нужно собрать.
Да, этой кучей текста я ничего толком то и не сказал, однако — сейчас задача разбита на несколько подзадач.
Пропустим то, как код подготавливается к выполнению, т.к. это слишком скучный для описания процесс. Предположим, что мы имеем уже готовый к анализу набор токенов.
Анализ кода
Вы могли слышать о построении дерева кода и его анализа или ещё более заумные вещи. Как всегда — это не более чем загромождение простого страшными терминами. Под анализом кода я понимаю гораздо более простой набор действий. Задача — пробежаться по списку токенов и разобрать код, каждую его конструкцию.
Как правило, в императивных языках код уже представлен в виде своеобразного дерева из конструкций.
Согласитесь, не приемлемо допустим начинать цикл «A» в теле цикла «B», а заканчивать — вне тела цикла «B». Код представляет собой структуру, состоящую из набора конструкций.
А что есть у каждой конструкции? Правильно — начало и конец (и возможно ещё что-то посередине, но не суть).
Соответственно, разбор кода можно сделать однопроходным, толком без построения дерева.
Для этого нужен цикл, который будет пробегать по коду и большущий switch-case, который будет выполнять основной разбор кода и анализ.
Т.е. пробегаем по токенам, перед нами токен (например пусть будет...) «if» — очень уж сомневаюсь, что такой токен может стоять в коде просто так -> это начало конструкции if..then[..else]..end!
Выполняем разбор всех последующих токенов, соответствующим образом для конструкции условий в нашем языке.
Немного об ошибках в коде
На этапе разбора конструкций и пробега по коду, на обработку ошибок лучше не забивать. Это полезный функционал транслятора. Если в ходе разбора конструкции возникает ошибка, то логично — конструкция построена не должным образом и следует уведомить об этом разработчика.
Теперь о Mash. Как происходит разбор языковых конструкций?
Выше я описал обобщенный концепт устройства транслятора. Теперь настало время поговорить о моих наработках.
По сути транслятор получился очень даже похожим на описанное выше. Но у меня он не разбивает код на кучу токенов для дальнейшего анализа.
Перед началом разбора код приводится в более красивый вид. Удаляются комментарии и все конструкции соединяются в длинные строки, если они описаны в несколько строк.
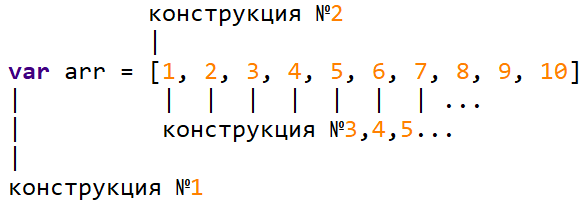
Таким образом, в каждой отдельно взятой строке находится языковая конструкция либо её часть. Это классно, теперь мы можем разбирать каждую строку в нашем большом switch-case, вместо поиска этих конструкций в наборе токенов. Также плюсом тут выступает то, что строка имеет конец и значит определять ошибки в конструкции с таким подходом проще.
Соответственно разбор отдельных конструкций происходит отдельными методами, которые возвращают промежуточное представление кода конструкций или её частей.
П.с. в предыдущей статье я описал построение транслятора с промежуточного языка в байткод для ВМ. Собственно — этот промежуточный язык и является промежуточным представлением.
Стоит понимать, что конструкции могут состоять из нескольких более простых конструкций. Т.к. у нас разбор каждой конструкции описан отдельными методами, то мы можем без проблем вызывать их друг из друга при разборе каждой конструкции.
Разминочная пробежка по коду
Для начала транслятору стоит бегло ознакомиться с кодом, пробежавшись по нему и уделив внимание некоторым конструкциям.
На этом этапе можно разобраться с глобальными переменными, uses конструкциями, а также импортами, процедурами & функциями и ООП конструкциями.
Промежуточное представление лучше генерировать в несколько объектов для хранения, чтобы
код для глобальных переменных вставить после инициализации, но перед началом выполнения main().
Код для ООП конструкций можно вставить в конце.
Сложные конструкции
Ок, с простыми конструкциями мы разобрались. Теперь пришло время сложных. Не думаю, что вы успели забыть пример с двумя циклами. Как мы знаем, конструкции обычно идут в виде некого дерева. А это значит, что мы можем разбирать сложные конструкции используя стек.
При чем тут стек? Притом.
Опишем сначала класс, который будем запихивать в стек. При разборе сложных конструкций мы можем генерировать промежуточное представление для начала и конца этого блока, так, например, происходит разбор цикла for, while, until, конструкций if, методов да и вообще всего в языке Mash.
Этому классу нужны поля для хранения промежуточных представлений, мета информации (Для некоторых вариативных конструкций) и, конечно же — для хранения типа блока.
Просто приведу код целиком, потому что его тут не много:
unit u_prep_codeblock;
{$mode objfpc}{$H+}
interface
uses
Classes, SysUtils;
type
TBlockEntryType = (btProc, btFunc, btIf, btFor, btWhile, btUntil, btTry, btClass,
btSwitch, btCase);
TCodeBlock = class(TObject)
public
bType: TBlockEntryType;
mName, bMeta, bMCode, bEndCode: string;
constructor Create(bt: TBlockEntryType; MT, MC, EC: string);
end;
implementation
constructor TCodeBlock.Create(bt: TBlockEntryType; MT, MC, EC: string);
begin
inherited Create;
bType := bt;
bMeta := MT;
bMCode := MC;
bEndCode := EC;
end;
end.
Ну и стек — простой TList, изобретать велосипед тут просто глупо.
Таким образом, разбор конструкции, допустим того же while цикла выглядит так:
function ParseWhile(s: string; varmgr: TVarManager): string;
var
WhileNum, ExprCode: string;
begin
Delete(s, 1, 5); //"while"
Delete(s, Length(s), 1); //":"
s := Trim(s);
//Циклов в коде много, а в промежуточном представлении структуры кода нету...
//Нужно точки входа все же отличать как то :)
WhileNum := '__gen_while_' + IntToStr(WhileBlCounter);
Inc(WhileBlCounter); //Номер очередной конструкции while в коде
//Метод проверяет, является ли строка логическим или математическим выражением
if IsExpr(s) then
ExprCode := PreprocessExpression(s, varmgr)
else
ExprCode := PushIt(s, varmgr);
//Теперь в ExprCode лежит промежуточное представление выражения
//Результат после выполнения будет лежать в вершине стека
//Проверка условия перед итерацией
//(промежуточное представление ставится на место начала конструкции)
Result := WhileNum + ':' + sLineBreak + 'pushcp ' + WhileNum + '_end' +
sLineBreak + ExprCode + sLineBreak + 'jz' +
sLineBreak + 'pop';
//Ну и соответственно генерация кода на завершение конструкции
//Последний аргумент - название точки входа на выход из цикла
//нужен для генератора break
BlockStack.Add(TCodeBlock.Create(btWhile, '', 'pushcp ' + WhileNum +
sLineBreak + 'jp' + sLineBreak + WhileNum +
'_end:', WhileNum + '_end'));
end;
Про математические выражения
Возможно вы могли этого не замечать, но математические/логические выражения — это тоже структурированный код.
Их разбор я реализовывал стековым путем. Сначала все отдельные элементы выражения ложатся в стек, затем в несколько проходов генерируется код промежуточного представления.
В несколько раз — т.к. есть приоритетные математические операции, такие как умножение.
Код тут приводить не вижу смысла, т.к. его много и он скучный.
П.с. /lang/u_prep_expressions.pas — тут он целиком и полностью выставлен на ваше обозрение.
Итоги
Итак, мы реализовали транслятор, который может преобразовать… Например такой вот код:
proc PrintArr(arr):
for(i ?= 0; i < len(arr); i++):
PrintLn("arr[", i, "] = ", arr[i])
end
end
proc main():
var arr = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
PrintArr(arr)
InputLn()
end
Чего же не хватает нашему языку? Правильно, поддержки ООП. Об этом мы и поговорим в следующей моей статье.
Спасибо, что дочитали до конца, если вы это сделали.
Если вам что-то не понятно, то я жду ваших комментариев. Или вопросов на форуме, да-да… Я его иногда проверяю.
А теперь небольшой опрос (чтобы я смотрел на него и радовался значимости своих статей):
Комментарии (22)

AgentSmith
09.01.2019 16:18>«Причем тут стек? При том.»
Автор, ну неужели ты не видишь логики? В первом случае написал неправильно, а во втором случае правильно.
«при чём»? — при том
RoPi0n Автор
09.01.2019 16:26+1Эх, гумманитарии…
mwambanatanga
09.01.2019 16:47Правильный ответ: «Спасибо, исправил». На юмор можно отвечать юмором, можно отвечать серьёзностью, но не агрессией.
impwx
09.01.2019 17:06Статья-самоучитель по напписанию парсера должна начинаться с маленького, но полноценного примера языка, который вы хотите распарсить. Потом в ней хорошо бы прочитать про этапы разбора (лексический, синтаксический, семантический), потом про способы записи грамматики (БНФ), потом про алгоритмы разбора (LL/LR/LALR), потом про промежуточное представление. А завершиться она должна полным примером реализации парсера и примером генерируемого им IR.
Сейчас же у вас есть только маленький кусочек входных данных, и маленький кусочек кода, которые еще и не связаны между собой, а в качестве «промежуточного представления» генерируется строка (!). Вы сильно поторопились с написанием этой статьи, и в результате для знающих людей она абсолютно бесполезна, а для новичков даже опасна тем, что прививает плохие практики.RoPi0n Автор
09.01.2019 18:05У меня было желание написать небольшую статью понятным языком (а не книгу — мануал) и рассказать про принцип работы транслятора на примере написанного мной проекта.
Про алгоритмы разбора, разного рода анализаторы и способы записи грамматики люди могут прочитать и так.
Но, согласитесь, приятно прочитать о чем то сложном в простой форме.
Не все пишут на FPC. Моей задачей было рассказать по какому принципу можно написать транслятор, а не закидать читателя кучей кода (!), который возможно и не каждый поймет даже, потому что не будет сидеть разбираться в нем (!).
Считаю, что в статье довольно подробно описаны основные этапы реализации транслятора.
Полный код доступен в репозитории (!).
Примеры входных и выходных текстов тоже (!).
В качестве промежуточного представления в конечном счете генерируется листинг на ассемблер-подобном языке (!), который я описывал в предыдущей статье, чем вам не промежуточное представление?)
Разве моя практика плоха, чтобы её прививать новичкам?(
Цель написания транслятора была поставлена и была успешно выполнена. Да, не самым оптимальным способом и транслятор работает медленнее, чем мог бы. Но тут есть и положительная сторона — разработка транслятора шла в быстром темпе, благодаря такой архитектуре. Да и разве критична скорость трансляции, если в конечном итоге приложение собирается в независимый формат и будет выполняться на ВМ.
Спасибо за комментарий, теперь, если заинтересованные люди увидят его и не поймут половину аббревиатур — они полезут в гугл и прокачают свой мозг.impwx
09.01.2019 18:59+4Во время разработки дизайна и реализации языка вы приняли множество решений не на основе фактов и сравнений, а на основе вашего «представления о прекрасном». Поэтому эти решения наивны и неоптимальны, и для pet project это вполне нормально, но проблема в том, что вы на голубом глазу выдаете их как пример для подражания. Для того, чтобы советовать свой подход кому-то другому, его сперва нужно защитить и обосновать, и «мне так было проще» в данном случае не считается за аргумент.
Например, почему вы решили объединять длинные строки в одну, а не просто пропускать символы перевода строки? Почему вы не разделяете текст на лексемы, а работаете с ним как с массивом символов? Почему промежуточное представление — это строка, а не дерево или хотя бы массив объектов?
sshikov
09.01.2019 20:47+4>Разве моя практика плоха, чтобы её прививать новичкам?(
Местами — ужасна. Причем заметьте, какой-нибудь LL(1) парсер, сделанный автоматически на базе грамматики, будет содержать кода строк на 20, то есть на порядок проще, то есть весь будет меньше по размеру того, что вы написали для разбора while. И атрибутные грамматики и AST, которые вам очевидно активно не нравятся — вещь на самом деле чрезвычайно простая. Даже с базовой обработкой ошибок.
При этом вся реализация, сделанная на базе правильных алгоритмов, будет правильно же структурирована, а то что вы тут показали — чистой воды каша.RoPi0n Автор
09.01.2019 23:10Mash — так и переводится :D
Возможно в будущем я решусь реализовать парсер с построением AST дерева.
Так уж вышло, что транслятор я писал уровнями, обвешивая код местами не нужными механизмами. Но в итоге получился рабочий код. На русском языке трудно найти стоящую документацию по написанию трансляторов. Я постараюсь это исправить, насколько мне под силу.samsergey
10.01.2019 00:21Литература есть, но ориентироваться стоит не на статьи или блоги, а на книги. Могу порекомендовать С.З.Свердлова "Языки программирования и методы трансляции", там очень хорошо рассказано про принципы построения ЯП, заложенные Н. Виртом и в Паскаль и в Модулу и в Оберон.
sshikov
10.01.2019 15:40Да книг на самом деле полно. Даже древняя книга Люис, Розенкранц и Стирнз, Теоретически основы проектирования компиляторов, по которой я когда-то учился, и та в сети доступна.
SmartyTimmi
10.01.2019 13:17Не сочтите за агрессию, но сколько Ваших ответов ни читал, постоянно «Всё в репозитории» и т.д. Зачем тогда вообще статьи, если «Всё в репозитории есть»?
Касательно того, о чем Вам говорят: нужно различать сложное в простой форме и короткие записки о сложном. У Вас второе. Вроде примерно всё понятно, но смотрится это не цельно. На Хабре есть несколько статей по компиляторам и пр., которые гораздо лучше и подробнее, без потери простоты объяснения, разбирают что да как.
phantom-code
09.01.2019 17:27Если перед парсингом вы соединяете многострочные выражения в единые длинные строки, как тогда у вас организовано формирование сообщений об ошибках, ведь информация о текущей строке/колонке должна теряться?
RoPi0n Автор
09.01.2019 18:06Да, она собственно говоря и теряется. Транслятор выводит имя метода, в котором ошибка и описание ошибки.
Поиск ошибок в коде — довольно сложный процесс. Возможно в будущем я напишу более хитрый код для этого.
phantom-code
09.01.2019 21:13+3Ваше решение обладает самобытностью, оно доведено до весьма приличного уровня и в принципе заслуживает уважения. Но я бы все же рекомендовал рассмотреть более «классический» вариант: Обычно входные данные разбиваются на токены лексическим анализатором, при этом каждому токену можно присвоить его местоположение (строка, столбец). В дальнейшем парсер анализирует последовательности токенов на предмет принадлежности грамматике, и, при нахождении «неправильного» токена, может извлечь нужную информацию о местоположении для указания точного места ошибки.
mikechips
Занятно. У меня предел экспериментов пока был только создание скриптового языка на регулярках, который на месте интерпретировался. Но это, конечно, куда более лайтово, и получается на выходе отнюдь не ЯП)