

В прошлых статьях я попытался рассказать про основы ценообразования и построения дерева принятия решений покупателя для классического ритейла. В данной статье расскажу про очень нестандартный кейс и постараюсь убедить вас, что использовать машинное обучение не так сложно, как кажется. Статья менее техничная и скорее призвана показать, что можно начать с малого и это уже принесет ощутимую пользу для бизнеса.
Изначальная проблема
На нашем континенте есть сеть магазинов, которая изменяет свой ассортимент раз в неделю, например сначала продает оверлоки, а затем мужскую спортивную одежду. Все нераспроданные товары отправляются на склады и через полгода опять возвращаются в магазины. Одновременно в магазине присутствует около 6 различных категорий товаров. Т.е. ассортимент магазинов на каждой неделе выглядят следующим образом:
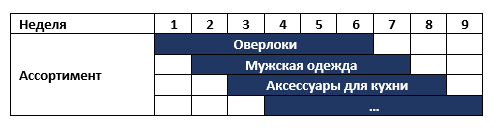
Сеть обратилась с запросом на систему планирования ассортимента с обязательным условием аналитической поддержки принятия решений для категорийных менеджеров. Пообщавшись с бизнесом, предложили два очень быстрых потенциальных решения, которые могут принести результат, пока будет идти развертывание системы планирования:
- распродажи товаров, которые не проданы за время основных продаж
- улучшение точности прогнозирования спроса на магазинах
Первый пункт заказчика не устроил – компания гордится тем, что не устраивает распродаж и поддерживает постоянный уровень маржинальности. При этом тратятся огромные деньги на логистику и хранение товара. В итоге было решено улучшить точность прогнозирования спроса для более точного распределения по магазинам и складам.
Текущий процесс
Ввиду особенностей бизнеса каждый отдельный товар не продается длительный срок и набрать достаточной истории для классического анализа проблематично. Текущий процесс прогнозирования очень прост и построен следующим образом – за несколько недель до старта основных продаж на малой части магазинов начинаются тестовые продажи. По итогам тестовых продаж принимается решение о вводе товара на всю сеть и предполагается, что каждый магазин будет продавать в среднем столько же, сколько было продано на тестовых магазинах.
Десантировавшись к заказчика, мы проанализировали текущие данные, поняли, что к чему, и предложили очень простое решение по улучшению точности прогноза.
Анализируем данные
Из данных нам предоставили:
- История транзакционных данных за 1 год и 2 месяца
- Товарная иерархия для планирования. К сожалению, в ней практически полностью отсутствовали атрибуты товаров, но об этом чуть позже
- Информация об ассортименте и ценах на конкретные недели
- Информация о городах, в которых находятся магазины
Нам не смогли в короткий срок выгрузить информацию об остатках, которая является критичной в подобного рода анализе (если не храните эту информацию – начинайте), поэтому в дальнейшем мы использовали предположение, что товар присутствует на полках и дефицита товара нет.
Сразу мы отделили 2 месяца на тестовую выборку для демонстрации результатов. Затем соединили все имеющиеся данные в одну большую витрину, очистив их от возвратов и странных продаж (например, количество в чеке 0,51 на штучный товар). На это ушло несколько дней. После подготовки витрины мы посмотрели на продажи товаров [шт.] на самом верхнем уровне и увидели следующую картину:
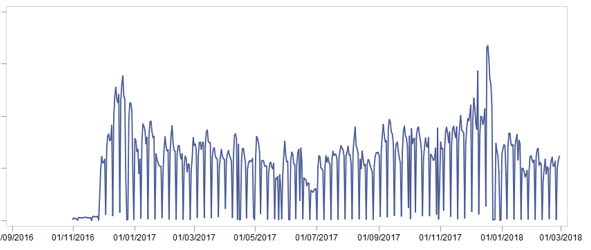
Чем нам может помочь эта картинка?.. А вот чем:
- Очевидно, что присутствует сезонность – продажи в конце года выше, чем в середине
- Существует сезонность в рамках месяца – в середине месяца продажи выше, чем в начале и в конце
- Существует сезонность в рамках недели – она не так интересна, т.к. в итоге прогноз строился по неделям
Описанные пункты подтвердил бизнес. А ведь это еще и отличные фичи для того, чтобы улучшить прогноз! Перед тем, как добавить их в модель прогнозирования давайте подумаем, какие еще особенности продаж следует учесть… В голову приходят “очевидные” идеи:
- Продажи в среднем различаются между различными товарными группами
- Продажи различаются между различными магазинами
- (Схож с предыдущим пунктом) Продажи различаются между различными городами
- (Менее очевидная идея) из-за специфики бизнеса видна следующая зависимость: если будущий и предыдущий ассортимент схожи, то продажи нового ассортимента будут ниже.
На этом мы решили остановиться и построить модель.
Построение ABT (analytical base table)
В рамках построения модели, все найденные особенности были переведены в “фичи” модели. Вот список использованных в итоге фичей:
- текущий прогноз, т.е. средние продажи тестовых магазинов в [шт.] распространенные на все магазины
- номер месяца и номер недели в месяце
- все категориальные переменные (город, магазин, товарные категории) были закодированы с помощью smoothed likelihood (полезная техника – кто еще не использует, берите на вооружение)
- посчитан лаг 4 средних продаж категории товара. Т.е. если компания планирует продавать майку синего цвета, то был рассчитан лаг средних продаж категории майки
ABT получилась простой, каждый параметр был понятен бизнесу и не вызывал непонимания или отторжения. Затем необходимо было понять, как мы будем сравнивать качество прогноза.
Выбор метрики
Заказчик измерял текущую точность прогнозирования, используя метрику MAPE. Метрика популярна и проста, но обладает определенными недостатками, когда речь идет о прогнозировании спроса. Дело в том, что при использовании MAPE, наибольшее влияние на итоговый показатель оказывают ошибки прогноза вида:

Относительная ошибка прогноза 900% — кажется большой, но давайте посмотрим на продажи другого товара:

Относительная ошибка прогноза составляет 33%, что гораздо меньше 900%, но абсолютное отклонение отклонение в 100 [шт.] гораздо важнее для бизнеса, чем отклонение 18 [шт.]. Для учета данных особенностей можно придумать свои интересные меры, а можно воспользоваться другой популярной мерой при прогнозировании спроса – WAPE. Данная мера дает больший вес товарам с более высокими продажами, что отлично подходит для задачи.
Про различные подходы к измерению ошибки прогноза мы рассказали компании, и заказчик охотно согласился с тем, что использовать WAPE в данной задаче более разумно. После этого мы запустили Random Forest практически без тюнинга гиперпараметров и получили следующие результаты.
Результаты
После прогнозирования тестового периода мы сравнили спрогнозированные значения с фактическими, а также с прогнозом компании. В результате MAPE уменьшился более чем на 15%, WAPE более чем на 10%. Рассчитав влияние улучшенного прогноза на бизнес показатели, получилось сокращение издержек на очень немаленькую сумму, исчисляемую миллионами долларов.
На всю работу потрачена 1 неделя!
Дальнейшие шаги
В качестве бонуса для заказчика мы провели небольшой DQ эксперимент. Для одной товарной группы из названий товаров мы распарсили характеристики (цвет, вид товара, состав и пр.) и добавили их в прогноз. Результат получился вдохновляющий – на данной категории обе меры ошибок улучшились дополнительно более чем на 8%.
В итоге заказчику было передано описание каждой фичи, параметры модели, параметры сборки ABT-витрины и описаны дальнейшие шаги по улучшения прогноза (использовать исторические данные более, чем за один год; использовать остатки; использовать характеристики товаров и пр.).
Вывод
За одну неделю совместной работы с заказчиком удалось значительно увеличить точность прогнозирования, при этом практически не изменяя бизнес-процесс.
Наверняка многие сейчас думают, что данный случай очень простой и у них в компании таким подходом уже не отделаешься. Опыт показывает, что практически всегда есть места, где используются лишь базовые предположения и экспертные мнения. С этих мест можно начать применение машинного обучения. Для этого нужно аккуратно подготовить и изучить данные, поговорить с бизнесом и попробовать применить популярные модели, не требующие долгого тюнинга. А стэкинг, embedding фичи, сложные модели – это все на потом. Надеюсь, я убедил вас, что это не так сложно, как может показаться, надо лишь немного подумать и не бояться начать.
Не бойтесь машинного обучения, ищите места, где его можно применить в процессах, не бойтесь исследовать свои данные и пускать к ним консультантов и получайте классные результаты.
P.S. Мы набираем в ритейл практику юных падаванов-студентов для стажировки под руководством опытных джедаев. Для старта достаточно здравого смысла и знания SQL, остальному научим. Развиться можно в бизнес-эксперта или технического консультанта, смотря, что будет интереснее. Если есть заинтересованность или рекомендации — пишите в личку
Комментарии (20)

eefadeev
10.01.2019 14:33Я, почему-то, всё время думаю про «эффект индейки»…
Dreamastiy Автор
10.01.2019 14:35Если вы про вот этот эффект, то в статье использовалась нелинейная модель
eefadeev
10.01.2019 16:16-1Да, про это. Правда первым про это сказал вовсе не Греф, а (скорее всего) Талеб, но суть от этого не меняется. Дело не в том линейная модель или нелинейная. Дело в том, что само по себе использование предыдущего опыта для предсказания будущего — не более чем попытка это будущее угадать.
Asgat_Akhmetshin
10.01.2019 16:51+1в Черном лебеде он писал про прогнозирование. Что пытаясь заглянуть в будущее, мы «туннелируем» – воображаем его обыденным, свободным от Черных лебедей, но в будущем нет ничего обыденного! И на моей практике прогноз это больше программирование поведения компании: яркий пример бюджет на следующий год, он строится на основе предыдущих периодов и иных факторов, которые повлияют/скорректируют показатели в прогнозе.
S_A
11.01.2019 16:49+1С точки зрения Талеба тут всё просто. Хвосты толстые у распределений, и редкие события не такие уж и невозможные. Только индейка их не видела, а когда увидит — будет поздно.
С точки зрения машинного обучения всё сложно. Если что-то подобное было в истории — модель всё поймет. Но это уже не черный лебедь, раз в истории было. Если не было — тут сложно, но некоторые алгоритмы (и это не random forest) могут всё разгадать.
Алгоритмы, которые могут разгадать, это нейросети, изредка градиентный бустинг над деревьями, и… линейные (с нелинейными фичами, преобразованным таргетом). На пальцах, они выучивают зависимость, поверхность управления (как в теории катастроф), а не сами данные (исключаем оверфит, меморайз и всё такое).
Хорошо генерализовавшая данные модель — может (и я сам с таким сталкивался, что не верил модели, а она предсказывала резкие изменения верно) говорить о серьезных поворотах в жизни системы.
Другое дело что запихать экономику США и глобальные взаимосвязи всё в одну модель — ну да вот так просто не сделать, тупо из-за тех же данных, хоть весь quandl купи.
Вот так я всё это вижу.
Asgat_Akhmetshin
10.01.2019 16:48Картину можно было другую поставить)
Сложно разобрать сезонность.
Например, как здесь:
Если есть понимание бизнеса, от каких параметров зависит спрос, то затоваривание и убытки с применением прогнозирования уменьшаются.
Достаточно определить наклон продаж каждой номенклатурной группы, выделить параметры влияющие на продажи, определить их корреляцию с продажами(порой и в течение года влияние/взаимосвязь параметра на продажи менялась) и строить прогноз на основе модели.
Если у кого во время учёбы в универа был вопрос «зачем в жизни эконометрика?», то вот ответ.
rzykov
10.01.2019 17:00Напишите, когда задача отправится в production и бизнес будет полностью опираться на эти данные :) Мало сделать алгоритм, нужно заставить его работать в production, а это еще 90% работы
Dreamastiy Автор
10.01.2019 17:33Согласен на 100%. Правда на SAS это немного проще, чем на опен-сорсе, меньше 90% получится :)
Про вывод в прод хочется написать, но это сложно — с одной стороны нужно учесть все соглашения по неразглашениям, с другой не превратить рассказ в книгу размером с войну и мир
mandarinchik
11.01.2019 10:39Интересно, на основание чего принималось решение об эффективности новой системы прогнозирования для бизнеса. Как WAPE переводили в деньги? На каком уровне оценивалась ошибка, для всей сети? Отслеживали ли, что происходило в конкретных магазинах?
В итоге решение было реализовано в продакшене?
Dreamastiy Автор
11.01.2019 11:29Интересно, на основание чего принималось решение об эффективности новой системы прогнозирования для бизнеса. Как WAPE переводили в деньги?
В деньги переводится не само изменение WAPE, а изменение запасов и продаж на магазинах.
Если немного упростить, то бизнес-кейс рассчитывался двумя путями:
— на основании «benchmark» с предыдущих проектов
— на основании out-of-stock и упущенных продаж. Несмотря на то, что при построении модели использовалось предположение, что дефицита нет (т.к. нам не успели выдать остатки), при расчете бизнес-кейса мы рассчитали «вторичный» дефицит из данных продаж и оценили упущенные продажи
Цифры оказались одного порядка
На каком уровне оценивалась ошибка, для всей сети?
WAPE оценивался понедельно двумя способами:
— ошибка прогноза товаров на всю сеть (цифры из статьи)
— ошибка прогноза товаров на каждом магазине — здесь улучшение еще лучше
Отслеживали ли, что происходило в конкретных магазинах?
Конкретные магазины отслеживали — это один из шагов процесса, необходимый для понимания, что вносит наибольший вклад в ошибку прогнозирования.
В итоге решение было реализовано в продакшене?
Смотря что иметь ввиду под продакшн:
— в текущем процессе используется простой прогноз продаж, мы предложили заменить его на чуть более сложный, это практически не изменяет работу аналитиков
— если рассматривать целевую картину, то TO-BE процесс предложен, но еще не реализован, так что про этот конкретный кейс сможем рассказать чуть позже
— Если под продакшн имеется ввиду scheduling ETL и запуска моделей, то на SAS это делается довольно просто, но это тема отдельной статьиmandarinchik
11.01.2019 11:44В деньги переводится не само изменение WAPE, а изменение запасов и продаж на магазинах.
Как оценивалось изменение запасов и продаж, если прогноз не шел в магазин и не исполнялся?
на основании «benchmark» с предыдущих проектов
А вы можете поделиться бенчмарками или это закрытая информация? :)Dreamastiy Автор
11.01.2019 12:16Можно оценить из предположения, что исполнение происходит строго согласно прогнозу. Да это сильное ограничение, но позволяет оценить порядок влияния на историческом отрезке. Упрощенно это выглядит следующим образом — фактически товар находится в магазине в дефиците, старый прогноз этот дефицит не покрывает, а новый покрывает. Разница в покрытии считается изменением продаж за счет нового прогноза
Если вы подразумеваете, что на запасы и продажи влияют также процессы исполнения/пополнения, то да, их вклад можно оценить только после того как прогноз пройдет всю цепочку от аналитика до выставления товара на полку.
High39
11.01.2019 11:30Если использовать WAPE как метрику под которую оптимизируетесь, то прогноз будет стабильно занижен потому что данные по продажам строго позитивные и диапазон ошибок для недопрогноза ограничен нулем и не ограничен для перепрогноза. Для точек в нижней части массива данных деноминатор при вычислении процентной ошибки будет ниже и будет опускать прогноз. С MAPE история та же и получается что если эти метрики будут использоваться для оценок моделей то предпочтение будет отдано моделям с заниженным прогнозом.
Если прогнозы описанной в статье модели будут 1:1 выполнены то конечно издержки на остатки сократятся но каковы будут упущенные продажи и денежные потери? Так же не известно на какой горизонт вы прогнозируете и к чему это занижение приведет.Dreamastiy Автор
11.01.2019 11:51На самом деле дополнительно к WAPE смотрится метрика BIAS (тот же WAPE, только без знака модуля), как раз для того, чтобы следить за недо/перепрогнозами. Обычно (не всегда) рекомендуется немного перепрогнозить (иногда в ущерб WAPE), чтобы избежать проблем с упущенными продажами.
High39
11.01.2019 12:02Хорошо, для оценки можно посмотреть на BIAS, полагаю что он будет стабильно отрицательный, но оптимизируется ведь модель все так же под WAPE или MAPE? Тогда это просто дескриптивная статистика которая не помогает мне решить проблему недопрогноза.
Хорошо, если есть понимание что нужно немного перепрогнозить то насколько? Немного понятие относительное, и в добавок это же не будет достигнуто если под те же метрики отпимизироваться, а если корректировать вручную то это уже не совсем аналитическое решение.Dreamastiy Автор
11.01.2019 12:31Хорошо, если есть понимание что нужно немного перепрогнозить то насколько?
Для точного ответа на этот вопрос надо понимать все косты на всем сквозном процессе предприятия — ФОТ, закупка, логистика, хранение, списания и сотни других факторов, влияющих на себестоимость конкретного товара в конкретном магазине. Отсюда можно сделать свою функцию потерь и ее оптимизировать. Или Reinforcement Learning в помощь:). WAPE, MAPE, SMAPE — это некоторые приближения, которые выбираются под задачу. Определить баланс между BIAS и WAPE можно, например, экспериментально (если вам дадут это сделать КМ'ы).
Тогда это просто дескриптивная статистика которая не помогает мне решить проблему недопрогноза.
Дескриптивная статистика не так плохо, если у вас есть фабрика моделей и вы выбираете наилучшую с точки зрения бизнеса.
а если корректировать вручную то это уже не совсем аналитическое решение
Смотря что считать аналитическим решением. Конечно голубая мечта многих, что весь процесс будет работать без участия людей. Но конкретно в ритейле до этого пока далеко. Поэтому часто аналитика рассматривается как инструмент поддержки принятия решений, а не инструмент принятия решений
Ananiev_Genrih
11.01.2019 12:14"Заказчик измерял текущую точность прогнозирования, используя метрику MAPE. Метрика популярна и проста, но обладает определенными недостатками"
я ожидал дальше по тексту увидеть про SMAPE как серебряную пулю против низкой базы....
Ananiev_Genrih
11.01.2019 15:40посчитан лаг 4 средних продаж категории товара
я правильно понял что в итоге в качестве предикторов получили средние продажи по текущему магазину-товару за 4 недели относительно текущей (которая является откликом)?
Если да, то может быть лучше было бы в качестве предиктора использовать наклон линейной регрессии по этим 4 предыдущим неделям или это в вашем случае давало результаты хуже чем средние продажи за неделю?
Peter1010
Статью не читал и желание отпало на моменте чтения заголовка. Зашел что бы прокомментировать заголовок.
Тут как бы не жёлтая пресса. С такими заголовками читать хабр противно.
Kamenevdn
Но в отличие от желтой прессы тут на самом деле рассказали, что делали в течение недели. Мне как человеку из ритейла было интересно почитать, учитывая что сейчас занимаюсь схожей задачей.