

Главная задача коммерческих (да и некоммерческих тоже) сервисов — быть всегда доступными для пользователя. Хотя сбои случаются у всех, вопрос в том, что делает IT-команда для их минимизации. Мы перевели статью Бена Трейнора, Майка Далина, Вивек Рау и Бетси Бейер «Расчёт надёжности сервиса», в которой рассказывается, в том числе, на примере Google, почему 100% — неверный ориентир для показателя надежности, что такое «правило четырёх девяток» и как на практике математически прогнозировать допустимость крупных и мелких отключений сервиса и\или его критических компонентов — ожидаемое количество простоя, время обнаружения сбоя и время восстановления сервиса.
Расчет надежности сервиса
Ваша система надежна настолько, насколько надежны её компоненты
Бен Трейнор, Майк Далин, Вивек Рау, Бетси Бейер
Как описано в книге «Site Reliability Engineering: Надежность и безотказность как в Google» (далее — книга SRE), разработка продуктов и сервисов Google может достигать высокой скорости выпуска новых функций, сохраняя при этом агрессивные SLO (service-level objectives, цели уровня обслуживания) для обеспечения высокой надежности и быстрого реагирования. SLO требуют, чтобы сервис почти всегда был в исправном состоянии и почти всегда был быстрым. При этом SLO также указывают точные значения этого «почти всегда» для конкретного сервиса. SLO основаны на следующих наблюдениях:
В общем случае для любого программного сервиса или системы 100% — неверный ориентир для показателя надежности, поскольку ни один пользователь не сможет заметить разницу между 100%-ной и 99,999%-ной доступностью. Между пользователем и сервисом находится множество других систем (его ноутбук, домашний Wi-Fi, провайдер, электросеть...), и все эти системы в совокупности доступны не в 99,999% случаев, а гораздо реже. Поэтому разница между 99,999% и 100% теряется на фоне случайных факторов, обусловленных недоступностью других систем, и пользователь не получает никакой пользы от того, что мы потратили кучу сил, добиваясь этой последней доли процента доступности системы. Серьёзными исключениями из этого правила являются антиблокировочные системы управления тормозами и кардиостимуляторы!
Подробное обсуждение того, как SLO соотносятся со SLI (service-level indicators, индикаторы уровня обслуживания) и SLA (service-level agreements, соглашения об уровне обслуживания), смотрите в главе «Целевой уровень качества обслуживания» книги SRE. В этой главе также подробно описывается, как выбрать метрики, имеющие значение для конкретного сервиса или системы, что, в свою очередь, определяет выбор соответствующего SLO для этого сервиса или системы.
Эта статья расширяет тему SLO, чтобы сосредоточиться на составных частях сервисов. В частности, мы рассмотрим, как надежность критических компонентов влияет на надежность сервиса, а также как проектировать системы так, чтобы смягчить влияние или сократить количество критически важных компонентов.
Большинство сервисов, предлагаемых Google, направлены на обеспечение 99,99-процентной (иногда называемой «четыре девятки») доступности для пользователей. Для некоторых сервисов в пользовательском соглашении указывается более низкое число, однако внутри компании сохраняются целевые 99.99%. Эта более высокая планка дает преимущество в ситуациях, когда пользователи высказывают недовольство производительностью сервиса задолго до случая нарушения условий соглашения, поскольку цель № 1 команды SRE состоит в том, чтобы пользователи были довольны сервисами. Для многих сервисов внутренняя цель 99,99% представляет собой «золотую середину», которая уравновешивает стоимость, сложность и надежность. Для некоторых других, в частности глобальных облачных сервисов, внутренняя цель составляет 99,999%.
Надежность 99.99%: наблюдения и выводы
Давайте рассмотрим несколько ключевых наблюдений и выводов о проектировании и эксплуатации сервиса с надежностью 99,99%, а затем перейдем к практике.
Наблюдение № 1: Причины сбоев
Сбои происходят по двум основным причинам: проблемы с самим сервисом и проблемы с критическими компонентами сервиса. Критический компонент — это компонент, который в случае сбоя вызывает соответствующий сбой в работе всего сервиса.
Наблюдение № 2: Математика надежности
Надежность зависит от частоты и продолжительности простоев. Она измеряется через:
- Частоту простоя, или обратную от нее: MTTF (mean time to failure, среднее время безотказной работы).
- Продолжительность простоя, MTTR (mean time to repair, среднее время восстановления). Продолжительность простоя определяется временем пользователя: от начала неисправности до возобновления нормальной работы сервиса.
Таким образом, надежность математически определяется как MTTF/(MTTF+MTTR), используя соответствующие единицы измерения.
Вывод № 1: Правило дополнительных девяток
Сервис не может быть надежнее всех его критических компонентов вместе взятых. Если ваш сервис стремится обеспечить доступность на уровне 99,99%, то все критические составные части должны быть доступны значительно больше, чем 99,99% времени.
Внутри Google мы используем следующее эмпирическое правило: критические компоненты должны обеспечивать дополнительные девятки по сравнению с заявленной надёжностью вашего сервиса — в примере выше 99,999-процентную доступность — потому что любой сервис будет иметь несколько критических компонентов, а также свои собственные специфические проблемы. Это называется «правилом дополнительных девяток».
Если у вас есть критический компонент, который не обеспечивает достаточно девяток (относительно распространенная проблема!), вы должны минимизировать отрицательные последствия.
Вывод № 2: Математика частоты, времени обнаружения и времени восстановления
Сервис не может быть надежнее, чем произведение частоты инцидентов на время обнаружения и восстановления. Например, три полных отключения в год по 20 минут приводят в общей сложности к 60 минутам простоя. Даже если бы сервис работал отлично в остальное время года, 99,99-процентная надежность (не более 53 минут простоя в год) стала бы невозможной.
Это простое математическое наблюдение, но его часто упускают из виду.
Заключение из выводов № 1 и № 2
Если уровень надежности, на который полагается ваш сервис, не может быть достигнут, необходимо предпринять усилия для исправления ситуации — либо путем повышения уровня доступности службы, либо путем минимизации отрицательных последствий, как описано выше. Снижение ожиданий (т. е., объявленной надежности) тоже вариант, и зачастую — самый верный: дайте понять зависимому от вас сервису, что он должен либо перестроить свою систему, чтобы компенсировать погрешность в надежности вашей службы, либо сократить свои собственные цели уровня обслуживания. Если вы сами не устраните несоответствие, достаточно длительный выход системы из строя неизбежно потребует корректировок.
Практическое применение
Давайте рассмотрим пример сервиса с целевой надежностью в 99,99% и проработаем требования как к его компонентам, так и к работе с его сбоями.
Цифры
Предположим, что ваш 99,99-процентно доступный сервис имеет следующие характеристики:
- Одно крупное отключение и три незначительных отключения в год. Это звучит пугающе, но обратите внимание, что целевой уровень надежности в 99,99% подразумевает один 20-30-минутный масштабный простой и несколько коротких частичных отключений в год. (Математика указывает, что: а) отказ одного сегмента не считается отказом всей системы с точки зрения SLO и б) общая надежность вычисляется суммой надежности сегментов.)
- Пять критических компонентов в виде других независимых сервисов с надежностью 99,999%.
- Пять независимых сегментов, которые не могут отказать друг за другом.
- Все изменения проводятся постепенно, по одному сегменту за раз.
Математический расчет надежности будет выглядеть следующим образом:
Требования к компонентам
- Суммарный лимит ошибок за год составляет 0,01 процента от 525 600 минут в год, или 53 минуты (на основе 365-дневного года, при наихудшем сценарии).
- Лимит, выделяемый на отключения критических компонентов, составляет пять независимых критических компонентов с лимитом 0,001% каждый = 0,005%; 0,005% от 525 600 минут в год, или 26 минут.
- Оставшийся лимит ошибок вашего сервиса составляет 53-26=27 минут.
Требования к реагированию на отключения
- Ожидаемое количество простоев: 4 (1 полное отключение и 3 отключения, затрагивающие только один сегмент)
- Совокупное воздействие ожидаемых отключений: (1?100%) + (3?20%) = 1.6
- Время обнаружения сбоя и восстановления после него: 27/1.6 = 17 минут
- Время, выделенное мониторингу на обнаружение сбоя и оповещение о нем: 2 минуты
- Время, данное дежурному специалисту чтобы начать анализировать оповещение: 5 минут. (Система мониторинга должна отслеживать нарушения SLO и посылать сигнал на пейджер дежурному каждый раз, когда в системе происходит сбой. Многие сервисы Google находятся на поддержке посменных дежурных SR-инженеров, которые реагируют на срочные вопросы.)
- Оставшееся время для эффективной минимизации отрицательных последствий: 10 минут
Вывод: рычаги для увеличения надежности сервиса
Стоит внимательно посмотреть на представленные цифры, потому что они подчеркивают фундаментальный момент: есть три основных рычага, для увеличения надежности сервиса.
- Сократите частоту отключений — за счет политик выпуска, тестирования, периодических оценок структуры проекта и т.д.
- Уменьшите уровень среднего простоя — с помощью сегментирования, географического изолирования, постепенной деградации, или изолирования клиентов.
- Сократите время восстановления — с помощью мониторинга, спасательных действий «одной кнопкой» (например, откат к предыдущему состоянию или добавление резервной мощности), практики оперативной готовности и т. д.
Вы можете балансировать между этими тремя методами для упрощения реализации отказоустойчивости. Например, если трудно достичь 17-минутного MTTR, сосредоточьте свои усилия на сокращении времени среднего простоя. Стратегии минимизации отрицательных последствий и смягчения влияния критических компонентов рассматриваются более подробно далее в этой статье.
Уточнение «Правила дополнительных девяток» для вложенных компонентов
Случайный читатель может сделать вывод, что каждое дополнительное звено в цепочке зависимостей требует дополнительных девяток, так что для зависимостей второго порядка требуется две дополнительные девятки, для зависимостей третьего порядка — три дополнительные девятки и т. д.
Это неверный вывод. Он основан на наивной модели иерархии компонентов в виде дерева с постоянным разветвлением на каждом уровне. В такой модели, как показано на рис. 1, имеется 10 уникальных компонентов первого порядка, 100 уникальных компонентов второго порядка, 1 000 уникальных компонентов третьего порядка и т. д., что приводит к созданию в общей сложности 1 111 уникальных сервисов, даже если архитектура ограничена четырьмя слоями. Экосистема высоконадежных сервисов с таким количеством независимых критических компонентов явно нереалистична.
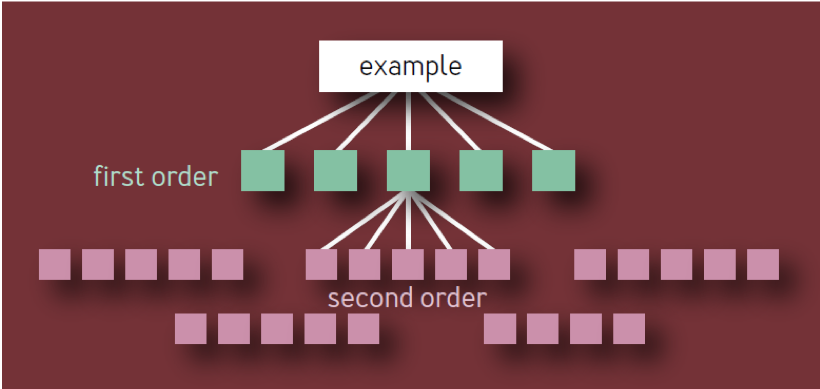
Рис. 1 — Иерархия компонентов: Неверная модель
Критический компонент сам по себе может вызвать сбой всего сервиса (или сегмента сервиса) независимо от того, где он находится в дереве зависимостей. Поэтому, если данный компонент X отображается как зависимость нескольких компонентов первого порядка, X следует считать только один раз, так как его сбой в конечном итоге приведет к сбою службы независимо от того, сколько промежуточных сервисов будут также затронуты.
Корректное прочтение правила выглядит следующим образом:
- Если сервис имеет N уникальных критических компонентов, то каждый из них вносит 1/N в ненадежность всего сервиса, вызванную этим компонентом, невзирая на то, как низко он расположен в иерархии компонентов.
- Каждый компонент должен учитываться только один раз, даже если он несколько раз появляется в иерархии компонентов (другими словами, учитываются только уникальные компоненты). Например, при подсчете компонентов Сервиса А на рис. 2, Сервис Б следует учитывать только раз.
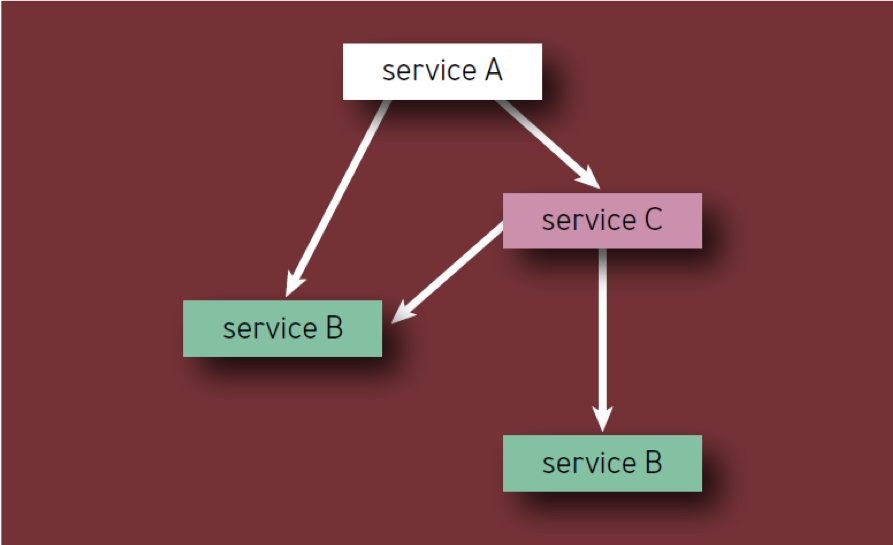
Рис. 2 — Компоненты в иерархии
Например, рассмотрим гипотетический сервис A с лимитом ошибок 0,01 процента. Владельцы сервиса готовы потратить половину этого лимита на собственные ошибки и потери, а половину — на критические компоненты. Если сервис имеет N таких компонентов, то каждый из них получает 1/N оставшегося лимита ошибок. Типичные сервисы часто имеют от 5 до 10 критических компонентов, и поэтому каждый из них может отказать только в одной десятой или одной двадцатой степени от лимита ошибок Сервиса A. Следовательно, как правило, критические части сервиса должны иметь одну дополнительную девятку надежности.
Лимиты ошибок
Концепция лимитов ошибок довольно подробно освещена в книге SRE, но и здесь следует ее упомянуть. SR-инженеры Google используют лимиты ошибок, чтобы сбалансировать надежность и темпы внедрения обновлений. Этот лимит определяет допустимый уровень отказа для сервиса в течение некоторого периода времени (обычно — месяц). Лимит ошибок — это просто 1 минус SLO сервиса, поэтому ранее обсуждавшаяся 99,99-процентно доступная служба имеет 0,01% «лимита» на ненадежность. До тех пор, пока сервис не израсходовал свой лимит ошибок в течение месяца, команда разработчиков свободна (в пределах разумного) запускать новые функции, обновления и т. д.
Если лимит ошибок израсходован, внесение изменений в сервис приостанавливается (за исключением срочных исправлений безопасности и изменений, направленных на то, что вызвало нарушение в первую очередь), пока служба не восполнит запас в лимите ошибок или пока не сменится месяц. Многие сервисы в Google используют метод скользящего окна для SLO, чтобы лимит ошибок восстанавливался постепенно. Для серьёзных сервисов с SLO более 99,99%, целесообразно применять ежеквартальное, а не ежемесячное обнуление лимита, поскольку количество допустимых простоев у них невелико.
Лимиты ошибок устраняют напряженность в отношениях между отделами, которая в противном случае могла бы возникнуть между SR-инженерами и разработчиками продукта, предоставляя им общий, основанный на данных механизм оценки риска запуска продукта. Они также дают и SR-инженерам, и командам разработки общую цель развития методов и технологий, которые позволят внедрять нововведения быстрее и запускать продукты без «раздувания бюджета».
Стратегии сокращения и смягчения влияния критических компонентов
К данному моменту, в этой статье мы установили, что можно назвать «Золотым правилом надежности компонентов». Это значит, что надежность любого критического компонента должна в 10 раз превышать целевой уровень надежности всей системы, чтобы его вклад в ненадежность системы оставался на уровне погрешности. Отсюда следует, что в идеальном варианте задача состоит в том, чтобы сделать как можно больше компонентов некритическими. Это означает, что компоненты могут придерживаться более низкого уровня надежности, давая разработчикам возможность вводить новшества и идти на риск.
Наиболее простой и очевидной стратегией уменьшения критических зависимостей является устранение единых точек отказа (SPOF, single points of failure) всегда, когда это возможно. Более крупная система должна быть в состоянии работать приемлемо без какого-либо заданного компонента, который не является критической зависимостью или SPOF.
На самом деле, вы, скорее всего, не можете избавиться от всех критических зависимостей; но вы можете следовать некоторым рекомендациям по проектированию системы для оптимизации надежности. Хотя это не всегда возможно, проще и эффективнее достичь высокой надежности системы, если вы закладываете надежность на этапах проектирования и планирования, а не после того, как система работает и влияет на фактических пользователей.
Оценка структуры проекта
При планировании новой системы или сервиса, а также при перепроектировании или улучшении существующей системы или сервиса, обзор архитектуры или проекта может выявить общую инфраструктуру, а также внутренние и внешние зависимости.
Разделяемая инфраструктура
Если ваш сервис использует разделяемую инфраструктуру (например, сервис основной базы данных, используемый несколькими продуктами доступными пользователям), подумайте, правильно ли используется эта инфраструктура. Четко определите владельцев разделяемой инфраструктуры в качестве дополнительных участников проекта. Кроме того, остерегайтесь перегрузки компонентов — для этого тщательно координируйте процесс запуска с владельцами этих компонентов.
Внутренние и внешние зависимости
Иногда продукт или сервис зависит от факторов вне контроля вашей компании — например, от программных библиотек или услуг и данных третьих сторон. Выявление этих факторов позволит минимизировать непредсказуемые последствия их использования.
Планируйте и проектируйте системы внимательно
При проектировании вашей системы обращайте внимание на следующие принципы:
Резервирование и изоляция
Можно попытаться сократить влияние критического компонента, создав несколько его независимых экземпляров. Например, если хранение данных в одном экземпляре обеспечивает 99,9-процентную доступность этих данных, то хранение трех копий в трех широко рассредоточенных экземплярах обеспечит, в теории, уровень доступности равный 1 — 0,013 или девять девяток, если сбои экземпляра независимы при нулевой корреляции.
В реальном мире корреляция никогда не равна нулю (рассмотрите сбои магистральной сети, которые влияют на многие ячейки одновременно), таким образом, фактическая надежность никогда не приблизится к девяти девяткам, но намного превысит три девятки.
Аналогично, отправка RPC (remote procedure call, удаленный вызов процедур) в один пул серверов в одном кластере может обеспечить 99-процентную доступность результатов, в то время как отправка трех одновременных RPC в три разных пула серверов и принятие первого поступившего ответа помогает достигнуть уровня доступности выше чем три девятки (см. выше). Эта стратегия также может сократить «хвост» задержки времени ответа, если пулы серверов равноудалены от отправителя RPC. (Поскольку стоимость отправки трех RPC одновременно высока, Google часто стратегически распределяет время этих вызовов: большинство наших систем ожидают часть выделенного времени перед отправкой второго RPC и немного больше времени перед отправкой третьего RPC.)
Резерв и его применение
Настройте запуск и перенос программного обеспечения так, чтобы системы продолжали работать при отказе отдельных частей (fail safe) и изолировались при возникновении проблем автоматически. Основной принцип здесь в том, что к тому времени, когда вы подключите человека для включения резерва, вы, вероятно, уже превысите свой лимит ошибок.
Асинхронность
Чтобы компоненты не становились критическими, проектируйте их асинхронными везде, где это возможно. Если сервис ожидает ответного RPC от одной из своих некритических частей, которая демонстрирует резкое замедление времени ответа, это замедление без нужды ухудшит показатели родительского сервиса. Установка RPC для некритического компонента в режим асинхронности освободит показатели времени ответа родительской службы от привязки к показателям этого компонента. И хотя асинхронность может усложнить код и инфраструктуру сервиса, все же этот компромисс стоит того.
Планирование ресурсов
Убедитесь, что все компоненты обеспечены всем необходимым. Если сомневаетесь, лучше обеспечить избыточный резерв — но без увеличения расходов.
Конфигурация
По возможности стандартизируйте конфигурацию компонентов, чтобы минимизировать расхождения между подсистемами и избежать одноразовых режимов отказа \ обработки ошибок.
Обнаружение и устранение неполадок
Сделайте обнаружение ошибок, устранение неполадок и диагностику проблем максимально простыми. Эффективный мониторинг является важнейшим фактором своевременного выявления проблем. Диагностировать систему с глубоко встроенными компонентами крайне сложно. Всегда держите наготове такой способ нивелировать ошибки, который не требует детального вмешательства дежурного.
Быстрый и надежный откат в предыдущее состояние
Включение ручной работы дежурных в план по устранению последствий сбоев существенно снижает возможность выполнить жесткие цели SLO. Выстраивайте системы, которые смогут легко, быстро и бесперебойно вернуться к предыдущему состоянию. По мере того, как ваша система совершенствуется, и уверенность в вашем способе мониторинга растет, вы можете снизить MTTR разработав систему автоматического запуска безопасных откатов.
Систематически проверяйте все возможные режимы отказа
Изучите каждый компонент и определите, как сбой в его работе может повлиять на всю систему. Задайте себе следующие вопросы:
- Может ли система продолжать работать в режиме ограниченной функциональности в случае сбоя одного из них? Другими словами, проектируйте возможность постепенной деградации.
- Как вы решите проблему недоступности компонента в различных ситуациях? При запуске сервиса? Во время работы сервиса?
Проведите тщательное тестирование
Разработайте и внедрите развитую среду тестирования, которая будет гарантировать, что каждый компонент покрыт тестами, включающими в себя основные сценарии использования этого компонента другими составляющими среды. Вот несколько рекомендуемых стратегий для такого тестирования:
- Используйте интеграционное тестирование для отработки внесения неисправностей -убедитесь, что система может выстоять при отказе любого из компонентов.
- Проведите аварийное тестирование для выявления слабых мест или скрытых/незапланированных зависимостей. Зафиксируйте порядок действий для исправления выявленных недостатков.
- Не тестируйте обычную нагрузку. Намеренно перегрузите систему, чтобы увидеть, как снижается ее функциональность. Так или иначе, реакция вашей системы на перегрузку станет известна; но лучше не оставлять нагрузочное тестирование пользователям, а заранее протестировать систему самостоятельно.
План на будущее
Ожидайте изменений, связанных с масштабированием: сервис, начинавшийся как относительно простой двоичный файл на одном компьютере, может обрасти множеством очевидных и неочевидных зависимостей при развертывании в большем масштабе. Каждый порядок масштаба выявит новые сдерживающие факторы — не только для вашего сервиса, но и для ваших зависимостей. Подумайте, что произойдет, если ваши зависимости не смогут масштабироваться так быстро, как вам нужно.
Также имейте в виду, что системные зависимости со временем развиваются и список зависимостей может со временем увеличиваться. Когда дело доходит до инфраструктуры, типичная рекомендация Google заключается в создании системы, которая будет масштабироваться до 10 раз от начальной целевой нагрузки без значительных изменений в архитектуре.
Заключение
В то время как читатели, вероятно, знакомы с некоторыми или многими понятиями, описанными в этой статье, конкретные примеры их использования помогут лучше разобраться в их сущности и передать это знание другим. Наши рекомендации непросты, но не недостижимы. Ряд сервисов Google неоднократно демонстрировали надежность выше четырех девяток не за счет сверхчеловеческих усилий или интеллекта, но благодаря продуманному применению принципов и передовых практик, выработанных в течение многих лет (см. книга SRE, Приложение B: Практические рекомендации для сервисов в промышленной эксплуатации).
roscomtheend
(Статью не читал, но заголовок в тему) Как в Гугл не надо — сегодня у них легла навигация (как во времена славной битвы РКН с разумом), ни пробки, ни последние места, ни поиск по названию не работали.
tbl
В статье и говорится, что они 99.99% обеспечивают для внутренних инструментов типа инфраструктуры, а наружу в sla прописаны цифры гораздо ниже.