
С проблемой flaky-тестов сталкиваются многие проекты, и тема эта уже не раз поднималась на Хабре. Тесты, не определившиеся со своим состоянием, постоянно отнимают не только машинное время, но и время разработчиков и тестировщиков. И если в коммерческой компании можно выделить некий ресурс для решения этой проблемы и назначить ответственных лиц, то в opensource-сообществе все не так просто. Особенно когда речь идет о крупных проектах — например, таких как Apache Ignite, где насчитывается почти 60 тысяч различных тестов.

В этом посте мы, собственно, и расскажем, как решали эту проблему в Apache Ignite. Мы — это Дмитрий Павлов, lead software engineer/community manager в GridGain, и Николай Кулагин, IT-инженер Сбербанк-Технологий.
Все написанное ниже не представляет позицию какой-либо компании, в том числе Сбербанка. Это рассказ исключительно от участников сообщества Apache Ignite.
История Apache Ignite начинается в 2014 году, когда компанией GridGain была пожертвована в Apache Software Foundation первая версия внутреннего продукта. С того момента прошло уже более 4 лет, и за это время количество тестов приблизилось к отметке в 60 тысяч.
В качестве сервера непрерывной интеграции мы используем JetBrains TeamCity — спасибо ребятам из JetBrains за то, что поддерживают opensource-движение. Все наши тесты распределены по сьютам, количество которых для ветки master приблизилось к 140. В сьютах тесты сгруппированы по какому-либо признаку. Это может быть тестирования только функциональности Machine Learning [RunMl], только кэша [RunCache], или всего [RunAll]. В дальнейшем под прогоном тестов будет подразумеваться именно [RunAll] – полная проверка. Она занимает примерно 55 часов машинного времени.
В качестве основной библиотеки используется Junit, но модульных тестов встречается мало. По большей части все наши тесты интеграционные, так как содержат запуск одной и более нод (а это занимает несколько секунд). Конечно, интеграционные тесты удобны тем, что один такой тест покрывает множество аспектов и взаимодействий, чего довольно сложно добиться одним модульным тестом. Но есть и недостатки: в нашем случае это довольно долгое время выполнения, а также сложность поиска возникшей проблемы.
В части этих тестов возникают сложности с flaky. Сейчас по классификации TeamCity примерно 1700 тестов отмечены как flaky — то есть с изменением состояния без изменения кода или конфигурации. Такие тесты нельзя игнорировать, так как есть риск получение бага в продакшене. Поэтому их приходится перепроверять и перезапускать, иногда несколько раз, анализировать результаты падений – и на это тратится драгоценное время и силы. И если уже существующие участники сообщества справляются с этой задачей, то для новых контрибьюторов это может стать настоящим барьером. Согласитесь, что, делая правку Java Doc, никак не ожидаешь столкнуться с падением, да не с одним, а с несколькими десятками.

Половина проблем с flaky-тестами возникает из-за конфигурации оборудования, из-за размеров инсталляции. А вторая половина напрямую связана с людьми, пропустившими и не исправившими свой баг.
Условно всех членов сообщества можно разделить на две группы:
Контрибьютор из первой группы вполне может внести одну-единственную правку и покинуть сообщество. И достучаться до него в случае обнаружения бага практически невозможно. С людьми из второй группы взаимодействовать проще, они с большей вероятностью отреагируют на сломанный ими тест. Но бывает, что компания, ранее интересовавшаяся продуктом, перестала в нем нуждаться. Она покидает коммьюнити, а вместе с ней и ее сотрудники-контрибьюторы. Или возможно, что контрибьютор покидает компанию, а вместе с ней и сообщество. Конечно, после таких перемен некоторые все равно продолжают участвовать в жизни сообщества. Но далеко не все.
Если мы говорим о людях, покинувших сообщество, то их баги, естественно, достаются текущим контрибьюторам. Стоит заметить, что за правку, которая привела к багу, также несет ответственность и ревьюер, но и он может оказаться энтузиастом — то есть будет доступен далеко не всегда.
Бывает, что получается достучаться до человека, сообщить ему: вот здесь проблема. Но он говорит: нет, это не мой фикс внес баг. Так как полный прогон ветки master автоматически выполняется при относительно свободной очереди, то чаще всего это происходит ночью. Перед этим за весь день в ветку может быть влито несколько коммитов.
В TeamCity любая модификация кода расценивается как чейндж. Если после трех чейнджей у нас случается новое падение, то три человека будут говорить, что это связано не с их коммитом. Если пять чейнджей — то мы услышим это от пяти человек.
Другая проблема: донести до контрибьютора, что тесты необходимо запускать перед каждым ревью. Некоторые не знают, где, что и как запускать. Или тесты были запущены, но контрибьютор не написал об этом в тикете. На этом этапе тоже возникают проблемы.
Идем дальше. Представим, что тесты прогнаны, и в тикете есть ссылка на результаты. Но, как оказалось, это не дает никаких гарантий анализа прогнанных тестов. Контрибьютор может посмотреть на свой прогон, увидеть там какие-то падения, но написать «TeamCity Looks Good». Ревьюер — особенно если он знаком с контрибьютором или успешно ревьюил его раньше — может толком и не посмотреть результат. И мы получим вот такой «TeamCity Looks Good»:
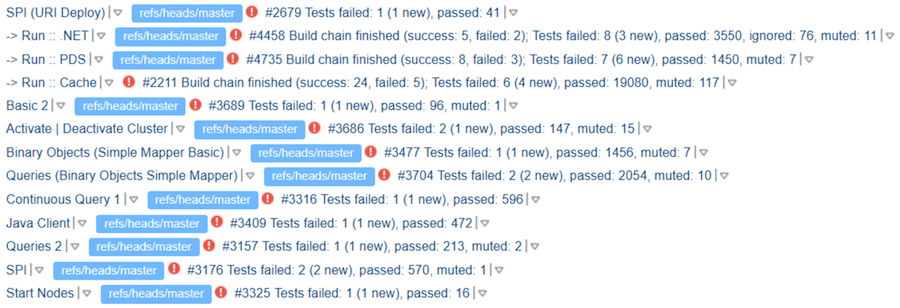
Где здесь «Good» — непонятно. Но судя по всему, авторы хотя бы знают, что тесты нужно запускать.
Мы разделили тесты на две группы. В первой, «чистой» — стабильные тесты. Во второй — нестабильные. Подход достаточно очевидный, но он не оправдался даже с двух попыток. Почему? Потому что сьют с нестабильными тестами превращается в такое гетто, где что-то начинает обязательно тайм-аутить, крэшится и т.д. В итоге все начинают просто игнорировать эти вечно проблемные тесты. В общем, никакого смысла делить тесты по сортам.
Второй вариант похож на первый — выделить более стабильные тесты, а остальные тесты по PR прогонять ночью. Если в стабильной группе что-то ломается, то контрибьютору стандартными средствами TeamCity отправляется сообщение о том, что нужно что-то пофиксить.
На эти сообщения отреагировало… 0 человек. Все их проигнорировали.
Мы поделили сьюты на несколько «наблюдателей», самых ответственных членов сообщества и подписали их на оповещения о падениях. В результате на практике подтвердили, что энтузиазм имеет свойство заканчиваться. Контрибьюторы бросают эту затею и перестают регулярно проверять. Тут пропустил, там просмотрел — и вот опять что-то пролезло в master.
После очередного неудачного метода ребята из GridGain вспомнили о ранее разработанной утилите, добавляющей отсутствующий на тот момент функционал на TeamCity. А именно возможность просмотра общей статистики по количеству падений: сколько и чего упало, ухудшился или улучшился результат на следующий день. Эту утилиту начали постепенно развивать, добавили репорты, переименовали. Потом добавили нотификации, снова переименовали. Так получился TeamСity Bot. Сейчас в нем почти 500 коммитов и 7 контрибьюторов и он есть в supplementary репозитории Apache.
Что делает бот? Его возможности можно объединить в две группы:
До появления Apache Ignite Teamcity Bot процесс «внесения вклада» в сообщество выглядел следующим образом:
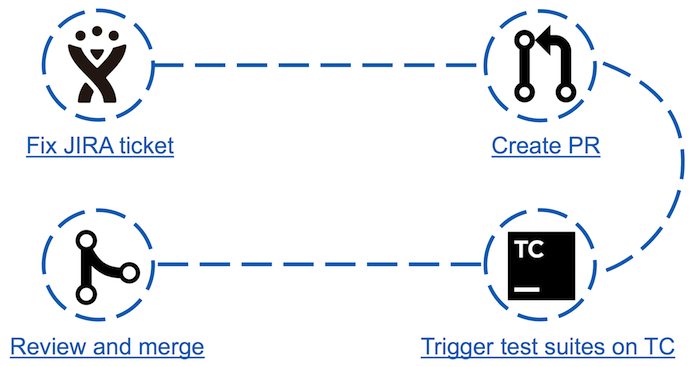
Выглядит просто, но на деле третий пункт может стать барьером для некоторых контрибьюторов. Например: новичок в коммьюнити решает внести свой первый вклад, выбирая максимально простой тикет. Это может быть правка Java Doc или обновление версий зависимостей maven. Анализируя результаты прогона по своему небольшому фиксу, он вдруг обнаруживает, что упало около 30 тестов. Откуда такое количество не пройденных тестов и как их анализировать — он не знает. Вполне ожидаемым последствием может стать то, что контрибьютор больше никогда сюда не вернется.
Более опытные участники коммьюнити также страдают от flaky — тратят время на анализ тестов, упавших по воле случая, и тем самым тормозят разработку продукта.
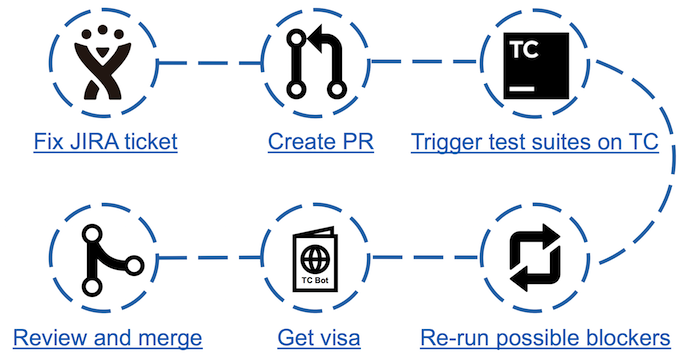
Схема контрибьюшна с TeamCity Bot
С появлением бота шагов в контрибьюшне прибавилось, но время, потраченное на анализ упавших тестов, существенно сократилось. Теперь достаточно запустить проверку и после ее прохождения заглянуть на соответствующую страницу бота. При наличии возможных блокеров (упавших тестов, не считающихся flaky) достаточно запустить перепроверку, по итогу которой получить визу в виде комментария в JIRA с результатами тестирования.

Inspect Contribution – список всех незакрытых PR с выводом краткой информации по каждому: дата последнего обновления, номер PR, название, автор и тикет в JIRA.

Для каждого pull request’a доступна вкладка с более подробной информацией: правильное название PR, без которого бот не сможет найти нужный тикет в JIRA; были ли запущены тесты; готов ли результат проверки; оставлен ли комментарий в JIRA.
Анализ результатов тестирования:


Перед вами два отчета по тестированию одного и того же PR. Первый — от бота. Второй — стандартный отчет на Teamcity. Разница в объеме информации очевидна, и это без учета того, что для просмотра истории прогонов теста на TC необходимо будет также сделать несколько переходов на смежные страницы.
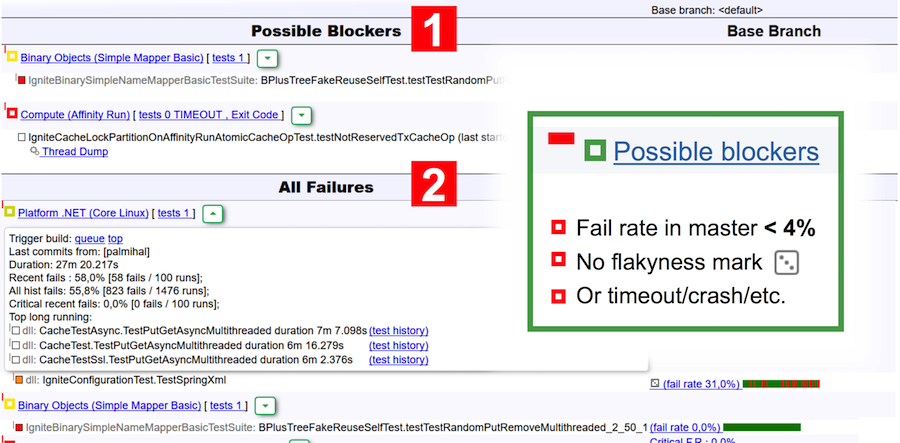
Вернемся к отчету бота. Этот отчет визуально разделен на две таблицы: возможные блокеры и все падения. К блокерам относятся тесты, которые:
Для примера на скриншоте выше в качестве возможных блокеров указаны две сьюты — в первой произошло падение теста, а во второй вылет по тайм-ауту.
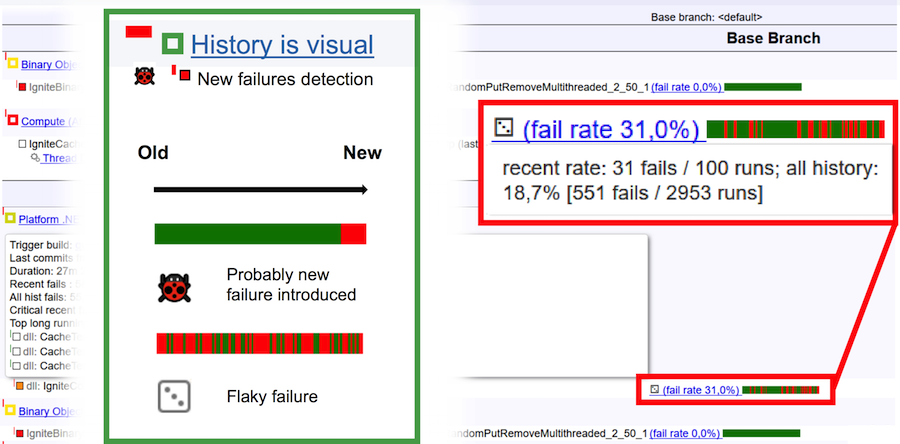
Чтобы окончательно разобраться, что же является flaky тестом, а что багом, рассмотрим картинку выше. Горизонтальная полоса — это 100 прогонов. Вертикальная зеленая полоса — успешное прохождение теста, красная — падение. В случае бага история прогона выглядит естественно: однотонная зеленая полоса под конец меняет цвет на красный. Это означает, что именно в этом месте появился баг и тест стал постоянно падать. Если же перед нами flaky-тест, то его история прогонов — это сплошное чередование зеленого и красного цветов.
Анализ результатов тестирования
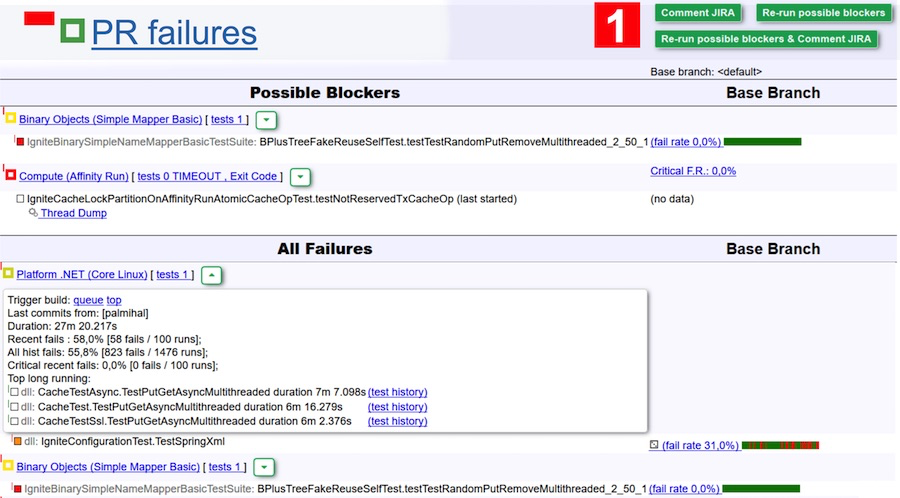
Для примера проанализируем результаты прохождения тестов на скриншоте выше. По версии бота падений из-за бага может быть два — они указаны в таблице Possible Blockers. Но это вполне могут быть flaky-тесты с низким fail rate’ом. Чтобы исключить этот вариант, достаточно нажать кнопку Re-run possible blockers, и эти две сьюты уйдут на перепроверку. Чтобы еще больше облегчить задачу, можно нажать Re-run possible blockers & comment JIRA, и получить комментарий (а с ним и уведомление на почту) от бота после окончания проверки. Потом зайти и посмотреть, есть ли проблема или нет.
Для ревьюеров это очень здорово. Можно забыть о правках, которые не прошли какие-то проверки, а просто покликать по ряду правок, нажать большую зеленую кнопку Re-run и ждать письма.
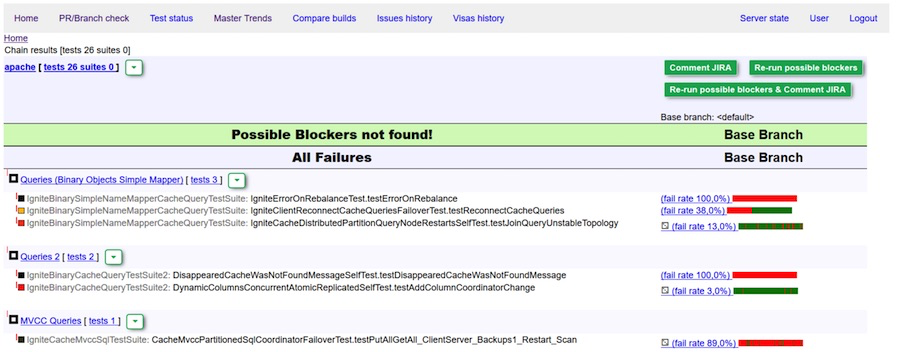
Идеальный отчет: блокеры не обнаружены

Зеленая виза (комментарий) бота. Блокеров не обнаружено.
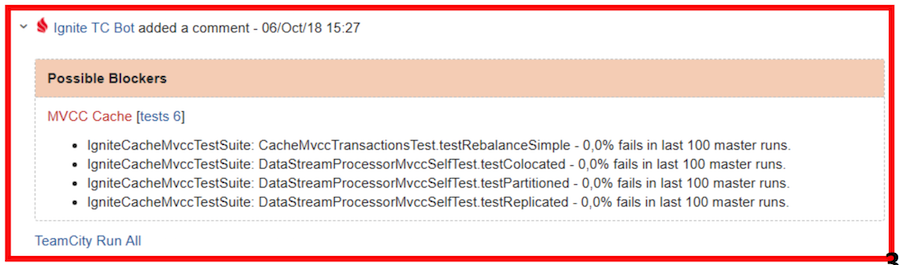
Красная виза — требуется перепроверка и/или правка багов
Бывает, что в «мастер» все-таки просачиваются некоторые баги. Как мы уже сказали, раньше с этим боролись через личные нотификации. Или какой-то человек следил за тем, чтобы ничего не упало. Сейчас мы используем более простое решение:

При обнаружении нового бага на dev-лист отправляется сообщение, в котором указаны контрибьюторы и их чейнджи, которые могут быть причиной ошибки. Так все сообщество узнает, из-за кого все произошло.
Таким образом нам удалось увеличить количество хот-фиксов и сильно сократить время, которое тратится на устранение проблемы.
Мониторинг состояния мастера
Еще одна из функций бота — мониторинг состояния мастера с выводом статистики по последним запускам.

Master trends

На странице Master trends сравнивается две выборки «мастера» за определенные промежутки времени. По каждому пункту в таблице выводится максимальное, минимальное значение и медиана.

Кроме общих результатов по всей выборке, в таблице присутствуют графики для каждого показателя с отображением значений каждого билда. Кликнув по точке, можно перейти к результатам прогона на TeamCity. Кроме того, есть возможно удалить результат из статистики. Это полезно, когда возникают совсем аномальные значения, из-за серьезных поломок, в которых наверняка виноват не контрибьютор. Такие результаты стоит исключать, чтобы они не учитывались при расчете тех же flaky-тестов. Кроме того, билд также можно выделить, чтобы проследить за результатами по каждому показателю.
В Apache Ignite Teamcity Bot сейчас зарегистрировано более 65 человек. За все время использования бота визы получили более 400 pull request’ов, а в среднем выдается пять виз в день.
Бот размещен на отдельном сервере, ходит на ignite.apache.org за данными, публично оповещает всех на dev-листе — это наша основная площадка для разработчиков Ignite — и пишет визы в тикеты через JIRA API.
Используется сервер Jetty, Jersey сервлеты, ряд сервисов со сложной бизнес логикой самого бота, в том числе сервисы Teamcity, JIRA и GitHub, обращающиеся в Ignited Integration сервис. Поверх этого Pure Integration для http-запросов. В качестве хранилища — собственный продукт Apache Ignite в конфигурации Single Node embedded-режим с активным persistence. Помимо очевидных плюсов использования Ignite в качестве БД, это также помогает нам найти различные сферы применения Ignite и понять, что удобно, а что нет.
Первый вариант реализации бота был вдохновлен одной статьей о REST-кэшировании и представлял собой REST-кэш и сервисы GitHub и Teamcity. Возвращаемые с сервера Teamcity xml и json разбирались в Pure Java Objects, которые затем складывались в кэш. Поначалу это работало, причем довольно быстро. Но с увеличением количества данных результаты стали ухудшаться.
Тут стоит заметить, что TeamCity удаляет историю старше ~2 недель, а бот — нет. В конечном итоге при таком подходе появлялись тонны данных, которыми очень сложно управлять.
В новом подходе реализован вариант компактного хранения данных и сделан выбор в пользу малого количество партиций кэша. Большое количество партиций на одной ноде негативно сказывается на скорости синхронизации данных на диск и увеличивает время старта кластера.
Все основные обновления данных выполняются асинхронно, так как в противном случае мы рискуем получить плохой UX из-за медленной отдачи данных TeamCity.
Для строк, редко меняющих свои значения (например, названия тестов) сделан простой маппинг в id, который генерируется Atomic Sequence’ом. Вот пример такой Entry:

Длинному имени теста соответствует int-овое число, которое хранится во всех билдах. Это экономит огромное количество ресурсов. Поверх методов, которые возвращают эту строчку, стоит Guava in-memory cache interceptor. Благодаря аннотации cache, мы даже в heap’е не выделяем строчки, прочитав их из Ignite по id. И по id мы всегда получаем одну и ту же строку, что хорошо для производительности.
Для «непредсказуемых» строк, например, stack trace лога, используются различные виды сжатия — gzip-компрессия, snappy-компрессия или uncompressed, в зависимости от того, что окажется лучше. Все эти способы помогают уместить максимум данных в in-memory и быстро отдавать ответ клиенту.
Нельзя сказать, что в TeamСity нет перечисленных выше возможностей. Они есть, но разбросаны по куче разных мест. В боте же все собрано на одной странице и можно быстро понять, в чем проблема.
Приятное дополнение — это письмо, которое бот отправляет на dev-листе при обнаружении проблемы. Сразу же в комьюнити появляется повод начать дискуссию: «Давайте, может, сейчас ревертнем?». Это добавляет уверенности ревьюерам.
С ботом новым контрибьюторам намного проще влиться в процесс разработки. Делая свой первый фикс, не всегда знаешь, что могут за собой повлечь внесенные изменения. И ныряя с головой в анализ результатов тестирования на TeamCity, можно запросто потерять энтузиазм к дальнейшей разработке. Apache Ignite TeamCity Bot же поможет быстро понять, есть ли проблема, и сохранить энтузиазм.
Надеемся, что бот упростит жизнь текущим контрибьюторам и привлечет новых людей в коммьюнити. Напоследок советуем, конечно, не допускать появления огромного количество flaky-тестов, потому что с ними сложно бороться. И доверяйте роботам — у них нет предпочтений и они не верят людям на слово.
В этом посте мы, собственно, и расскажем, как решали эту проблему в Apache Ignite. Мы — это Дмитрий Павлов, lead software engineer/community manager в GridGain, и Николай Кулагин, IT-инженер Сбербанк-Технологий.
Все написанное ниже не представляет позицию какой-либо компании, в том числе Сбербанка. Это рассказ исключительно от участников сообщества Apache Ignite.
Apache Ignite и тесты
История Apache Ignite начинается в 2014 году, когда компанией GridGain была пожертвована в Apache Software Foundation первая версия внутреннего продукта. С того момента прошло уже более 4 лет, и за это время количество тестов приблизилось к отметке в 60 тысяч.
В качестве сервера непрерывной интеграции мы используем JetBrains TeamCity — спасибо ребятам из JetBrains за то, что поддерживают opensource-движение. Все наши тесты распределены по сьютам, количество которых для ветки master приблизилось к 140. В сьютах тесты сгруппированы по какому-либо признаку. Это может быть тестирования только функциональности Machine Learning [RunMl], только кэша [RunCache], или всего [RunAll]. В дальнейшем под прогоном тестов будет подразумеваться именно [RunAll] – полная проверка. Она занимает примерно 55 часов машинного времени.
В качестве основной библиотеки используется Junit, но модульных тестов встречается мало. По большей части все наши тесты интеграционные, так как содержат запуск одной и более нод (а это занимает несколько секунд). Конечно, интеграционные тесты удобны тем, что один такой тест покрывает множество аспектов и взаимодействий, чего довольно сложно добиться одним модульным тестом. Но есть и недостатки: в нашем случае это довольно долгое время выполнения, а также сложность поиска возникшей проблемы.
Проблемы с flaky
В части этих тестов возникают сложности с flaky. Сейчас по классификации TeamCity примерно 1700 тестов отмечены как flaky — то есть с изменением состояния без изменения кода или конфигурации. Такие тесты нельзя игнорировать, так как есть риск получение бага в продакшене. Поэтому их приходится перепроверять и перезапускать, иногда несколько раз, анализировать результаты падений – и на это тратится драгоценное время и силы. И если уже существующие участники сообщества справляются с этой задачей, то для новых контрибьюторов это может стать настоящим барьером. Согласитесь, что, делая правку Java Doc, никак не ожидаешь столкнуться с падением, да не с одним, а с несколькими десятками.
Кто виноват?
Половина проблем с flaky-тестами возникает из-за конфигурации оборудования, из-за размеров инсталляции. А вторая половина напрямую связана с людьми, пропустившими и не исправившими свой баг.
Условно всех членов сообщества можно разделить на две группы:
- Энтузиасты, попавшие в сообщество по собственному желанию, и делающие вклад в свое свободное время.
- Full-time контрибьюторы, работающие в компаниях, которые каким-то образом используют этот open source продукт или связаны с ним.
Контрибьютор из первой группы вполне может внести одну-единственную правку и покинуть сообщество. И достучаться до него в случае обнаружения бага практически невозможно. С людьми из второй группы взаимодействовать проще, они с большей вероятностью отреагируют на сломанный ими тест. Но бывает, что компания, ранее интересовавшаяся продуктом, перестала в нем нуждаться. Она покидает коммьюнити, а вместе с ней и ее сотрудники-контрибьюторы. Или возможно, что контрибьютор покидает компанию, а вместе с ней и сообщество. Конечно, после таких перемен некоторые все равно продолжают участвовать в жизни сообщества. Но далеко не все.
Кто будет фиксить?
Если мы говорим о людях, покинувших сообщество, то их баги, естественно, достаются текущим контрибьюторам. Стоит заметить, что за правку, которая привела к багу, также несет ответственность и ревьюер, но и он может оказаться энтузиастом — то есть будет доступен далеко не всегда.
Бывает, что получается достучаться до человека, сообщить ему: вот здесь проблема. Но он говорит: нет, это не мой фикс внес баг. Так как полный прогон ветки master автоматически выполняется при относительно свободной очереди, то чаще всего это происходит ночью. Перед этим за весь день в ветку может быть влито несколько коммитов.
В TeamCity любая модификация кода расценивается как чейндж. Если после трех чейнджей у нас случается новое падение, то три человека будут говорить, что это связано не с их коммитом. Если пять чейнджей — то мы услышим это от пяти человек.
Другая проблема: донести до контрибьютора, что тесты необходимо запускать перед каждым ревью. Некоторые не знают, где, что и как запускать. Или тесты были запущены, но контрибьютор не написал об этом в тикете. На этом этапе тоже возникают проблемы.
Идем дальше. Представим, что тесты прогнаны, и в тикете есть ссылка на результаты. Но, как оказалось, это не дает никаких гарантий анализа прогнанных тестов. Контрибьютор может посмотреть на свой прогон, увидеть там какие-то падения, но написать «TeamCity Looks Good». Ревьюер — особенно если он знаком с контрибьютором или успешно ревьюил его раньше — может толком и не посмотреть результат. И мы получим вот такой «TeamCity Looks Good»:
Где здесь «Good» — непонятно. Но судя по всему, авторы хотя бы знают, что тесты нужно запускать.
Как мы с этим боролись
Метод 1. Разделение тестов
Мы разделили тесты на две группы. В первой, «чистой» — стабильные тесты. Во второй — нестабильные. Подход достаточно очевидный, но он не оправдался даже с двух попыток. Почему? Потому что сьют с нестабильными тестами превращается в такое гетто, где что-то начинает обязательно тайм-аутить, крэшится и т.д. В итоге все начинают просто игнорировать эти вечно проблемные тесты. В общем, никакого смысла делить тесты по сортам.
Метод 2. Разделение и нотификация
Второй вариант похож на первый — выделить более стабильные тесты, а остальные тесты по PR прогонять ночью. Если в стабильной группе что-то ломается, то контрибьютору стандартными средствами TeamCity отправляется сообщение о том, что нужно что-то пофиксить.
На эти сообщения отреагировало… 0 человек. Все их проигнорировали.
Метод 3. Ежедневный мониторинг
Мы поделили сьюты на несколько «наблюдателей», самых ответственных членов сообщества и подписали их на оповещения о падениях. В результате на практике подтвердили, что энтузиазм имеет свойство заканчиваться. Контрибьюторы бросают эту затею и перестают регулярно проверять. Тут пропустил, там просмотрел — и вот опять что-то пролезло в master.
Метод 4. Автоматизация
После очередного неудачного метода ребята из GridGain вспомнили о ранее разработанной утилите, добавляющей отсутствующий на тот момент функционал на TeamCity. А именно возможность просмотра общей статистики по количеству падений: сколько и чего упало, ухудшился или улучшился результат на следующий день. Эту утилиту начали постепенно развивать, добавили репорты, переименовали. Потом добавили нотификации, снова переименовали. Так получился TeamСity Bot. Сейчас в нем почти 500 коммитов и 7 контрибьюторов и он есть в supplementary репозитории Apache.
Что делает бот? Его возможности можно объединить в две группы:
- Мониторинг проекта — визуальный мониторинг путем просмотра результатов прогонов, а также автоматическое оповещение в мессенджеры (например, slack)
- Проверка ветки — анализ тестирования PR, а также выдачу визы в тикете.
Схема работы TeamСity Bot
До появления Apache Ignite Teamcity Bot процесс «внесения вклада» в сообщество выглядел следующим образом:
- В JIRA выбирается и фиксится один из тикетов;
- Создается pull request;
- Прогоняются тесты, на которые могут повлиять внесенные изменения;
- Если тесты пройдены, pull request может быть проревьюен и вмержен коммитером.
Выглядит просто, но на деле третий пункт может стать барьером для некоторых контрибьюторов. Например: новичок в коммьюнити решает внести свой первый вклад, выбирая максимально простой тикет. Это может быть правка Java Doc или обновление версий зависимостей maven. Анализируя результаты прогона по своему небольшому фиксу, он вдруг обнаруживает, что упало около 30 тестов. Откуда такое количество не пройденных тестов и как их анализировать — он не знает. Вполне ожидаемым последствием может стать то, что контрибьютор больше никогда сюда не вернется.
Более опытные участники коммьюнити также страдают от flaky — тратят время на анализ тестов, упавших по воле случая, и тем самым тормозят разработку продукта.
Схема контрибьюшна с TeamCity Bot
С появлением бота шагов в контрибьюшне прибавилось, но время, потраченное на анализ упавших тестов, существенно сократилось. Теперь достаточно запустить проверку и после ее прохождения заглянуть на соответствующую страницу бота. При наличии возможных блокеров (упавших тестов, не считающихся flaky) достаточно запустить перепроверку, по итогу которой получить визу в виде комментария в JIRA с результатами тестирования.
Обзор возможностей
Inspect Contribution – список всех незакрытых PR с выводом краткой информации по каждому: дата последнего обновления, номер PR, название, автор и тикет в JIRA.
Для каждого pull request’a доступна вкладка с более подробной информацией: правильное название PR, без которого бот не сможет найти нужный тикет в JIRA; были ли запущены тесты; готов ли результат проверки; оставлен ли комментарий в JIRA.
Анализ результатов тестирования:
Перед вами два отчета по тестированию одного и того же PR. Первый — от бота. Второй — стандартный отчет на Teamcity. Разница в объеме информации очевидна, и это без учета того, что для просмотра истории прогонов теста на TC необходимо будет также сделать несколько переходов на смежные страницы.
Вернемся к отчету бота. Этот отчет визуально разделен на две таблицы: возможные блокеры и все падения. К блокерам относятся тесты, которые:
- имеют fail rate в мастере менее 4% (менее 4 запусков из 100 оказались неудачными);
- не являются flaky по классификации TeamCity;
- упали по причине тайм-аута, нехватки памяти, кода выхода, cбоя JVM.
Для примера на скриншоте выше в качестве возможных блокеров указаны две сьюты — в первой произошло падение теста, а во второй вылет по тайм-ауту.
Чтобы окончательно разобраться, что же является flaky тестом, а что багом, рассмотрим картинку выше. Горизонтальная полоса — это 100 прогонов. Вертикальная зеленая полоса — успешное прохождение теста, красная — падение. В случае бага история прогона выглядит естественно: однотонная зеленая полоса под конец меняет цвет на красный. Это означает, что именно в этом месте появился баг и тест стал постоянно падать. Если же перед нами flaky-тест, то его история прогонов — это сплошное чередование зеленого и красного цветов.
Анализ результатов тестирования
Для примера проанализируем результаты прохождения тестов на скриншоте выше. По версии бота падений из-за бага может быть два — они указаны в таблице Possible Blockers. Но это вполне могут быть flaky-тесты с низким fail rate’ом. Чтобы исключить этот вариант, достаточно нажать кнопку Re-run possible blockers, и эти две сьюты уйдут на перепроверку. Чтобы еще больше облегчить задачу, можно нажать Re-run possible blockers & comment JIRA, и получить комментарий (а с ним и уведомление на почту) от бота после окончания проверки. Потом зайти и посмотреть, есть ли проблема или нет.
Для ревьюеров это очень здорово. Можно забыть о правках, которые не прошли какие-то проверки, а просто покликать по ряду правок, нажать большую зеленую кнопку Re-run и ждать письма.
Идеальный отчет: блокеры не обнаружены
Зеленая виза (комментарий) бота. Блокеров не обнаружено.
Красная виза — требуется перепроверка и/или правка багов
Бывает, что в «мастер» все-таки просачиваются некоторые баги. Как мы уже сказали, раньше с этим боролись через личные нотификации. Или какой-то человек следил за тем, чтобы ничего не упало. Сейчас мы используем более простое решение:
При обнаружении нового бага на dev-лист отправляется сообщение, в котором указаны контрибьюторы и их чейнджи, которые могут быть причиной ошибки. Так все сообщество узнает, из-за кого все произошло.
Таким образом нам удалось увеличить количество хот-фиксов и сильно сократить время, которое тратится на устранение проблемы.
Мониторинг состояния мастера
Еще одна из функций бота — мониторинг состояния мастера с выводом статистики по последним запускам.
Master trends
На странице Master trends сравнивается две выборки «мастера» за определенные промежутки времени. По каждому пункту в таблице выводится максимальное, минимальное значение и медиана.
Кроме общих результатов по всей выборке, в таблице присутствуют графики для каждого показателя с отображением значений каждого билда. Кликнув по точке, можно перейти к результатам прогона на TeamCity. Кроме того, есть возможно удалить результат из статистики. Это полезно, когда возникают совсем аномальные значения, из-за серьезных поломок, в которых наверняка виноват не контрибьютор. Такие результаты стоит исключать, чтобы они не учитывались при расчете тех же flaky-тестов. Кроме того, билд также можно выделить, чтобы проследить за результатами по каждому показателю.
В Apache Ignite Teamcity Bot сейчас зарегистрировано более 65 человек. За все время использования бота визы получили более 400 pull request’ов, а в среднем выдается пять виз в день.
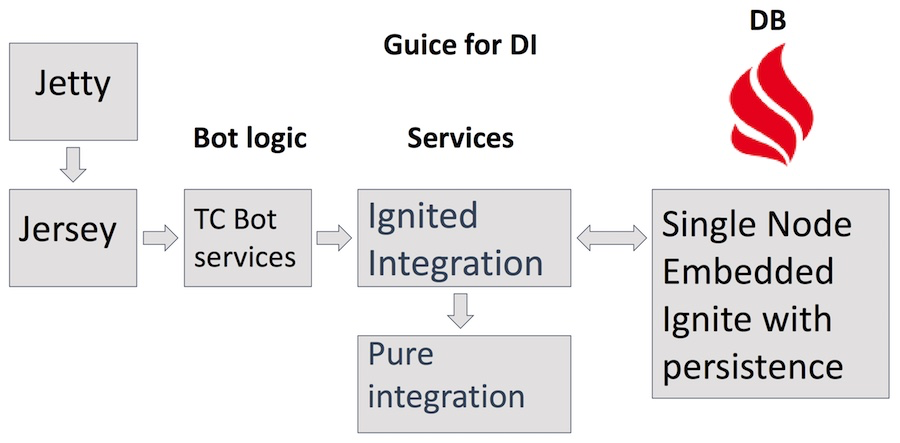
Структура TeamCity Bot
Бот размещен на отдельном сервере, ходит на ignite.apache.org за данными, публично оповещает всех на dev-листе — это наша основная площадка для разработчиков Ignite — и пишет визы в тикеты через JIRA API.
Используется сервер Jetty, Jersey сервлеты, ряд сервисов со сложной бизнес логикой самого бота, в том числе сервисы Teamcity, JIRA и GitHub, обращающиеся в Ignited Integration сервис. Поверх этого Pure Integration для http-запросов. В качестве хранилища — собственный продукт Apache Ignite в конфигурации Single Node embedded-режим с активным persistence. Помимо очевидных плюсов использования Ignite в качестве БД, это также помогает нам найти различные сферы применения Ignite и понять, что удобно, а что нет.
Первый вариант реализации бота был вдохновлен одной статьей о REST-кэшировании и представлял собой REST-кэш и сервисы GitHub и Teamcity. Возвращаемые с сервера Teamcity xml и json разбирались в Pure Java Objects, которые затем складывались в кэш. Поначалу это работало, причем довольно быстро. Но с увеличением количества данных результаты стали ухудшаться.
Тут стоит заметить, что TeamCity удаляет историю старше ~2 недель, а бот — нет. В конечном итоге при таком подходе появлялись тонны данных, которыми очень сложно управлять.
Развитие TeamCity Bot
В новом подходе реализован вариант компактного хранения данных и сделан выбор в пользу малого количество партиций кэша. Большое количество партиций на одной ноде негативно сказывается на скорости синхронизации данных на диск и увеличивает время старта кластера.
Все основные обновления данных выполняются асинхронно, так как в противном случае мы рискуем получить плохой UX из-за медленной отдачи данных TeamCity.
Для строк, редко меняющих свои значения (например, названия тестов) сделан простой маппинг в id, который генерируется Atomic Sequence’ом. Вот пример такой Entry:
Длинному имени теста соответствует int-овое число, которое хранится во всех билдах. Это экономит огромное количество ресурсов. Поверх методов, которые возвращают эту строчку, стоит Guava in-memory cache interceptor. Благодаря аннотации cache, мы даже в heap’е не выделяем строчки, прочитав их из Ignite по id. И по id мы всегда получаем одну и ту же строку, что хорошо для производительности.
Для «непредсказуемых» строк, например, stack trace лога, используются различные виды сжатия — gzip-компрессия, snappy-компрессия или uncompressed, в зависимости от того, что окажется лучше. Все эти способы помогают уместить максимум данных в in-memory и быстро отдавать ответ клиенту.
Почему с TeamCity Bot лучше
Нельзя сказать, что в TeamСity нет перечисленных выше возможностей. Они есть, но разбросаны по куче разных мест. В боте же все собрано на одной странице и можно быстро понять, в чем проблема.
Приятное дополнение — это письмо, которое бот отправляет на dev-листе при обнаружении проблемы. Сразу же в комьюнити появляется повод начать дискуссию: «Давайте, может, сейчас ревертнем?». Это добавляет уверенности ревьюерам.
С ботом новым контрибьюторам намного проще влиться в процесс разработки. Делая свой первый фикс, не всегда знаешь, что могут за собой повлечь внесенные изменения. И ныряя с головой в анализ результатов тестирования на TeamCity, можно запросто потерять энтузиазм к дальнейшей разработке. Apache Ignite TeamCity Bot же поможет быстро понять, есть ли проблема, и сохранить энтузиазм.
Надеемся, что бот упростит жизнь текущим контрибьюторам и привлечет новых людей в коммьюнити. Напоследок советуем, конечно, не допускать появления огромного количество flaky-тестов, потому что с ними сложно бороться. И доверяйте роботам — у них нет предпочтений и они не верят людям на слово.
VlK
Простите мое, так сказать, ignorance. Но что означает flaky-тесты в терминологии организации Sberbank? Неплохо бы ввести definition.