

Когда дело доходит до создания Docker-контейнеров, лучше всегда стремиться к минимизации размера образов. Образы, которые используют одни и те же слои и весят меньше — быстрее переносятся и деполятся.
Но как контролировать размер, когда каждое выполнение оператора RUN создает новый слой? Плюс, еще нужны промежуточные артефакты до создания самого образа...
Возможно, вы знаете, что большинство Docker-файлов имеют свои, довольно странные, особенности, например:
FROM ubuntu
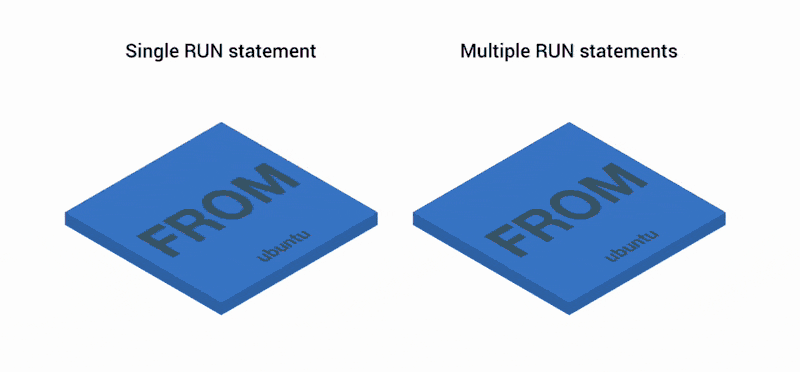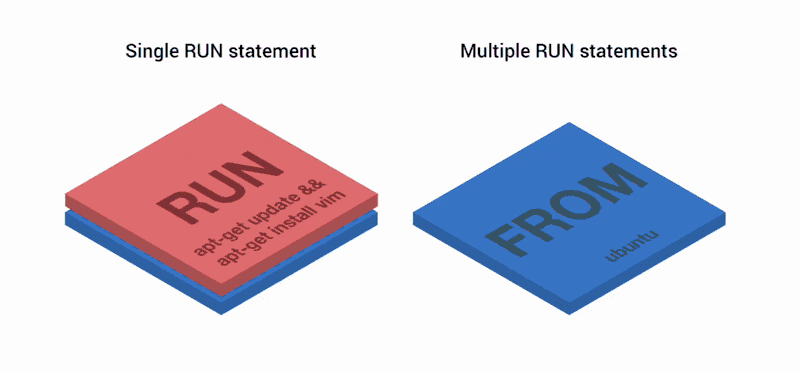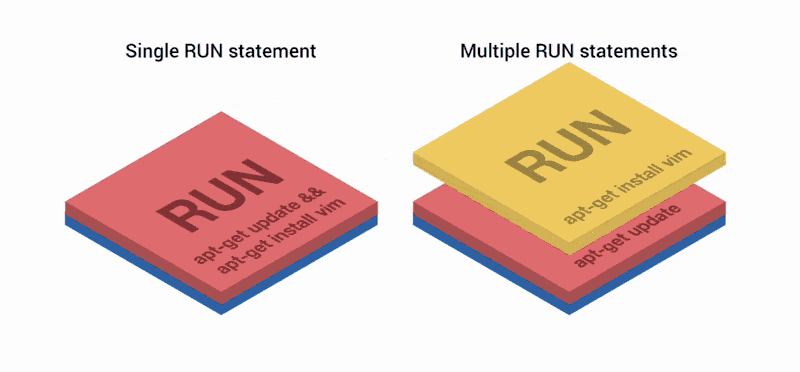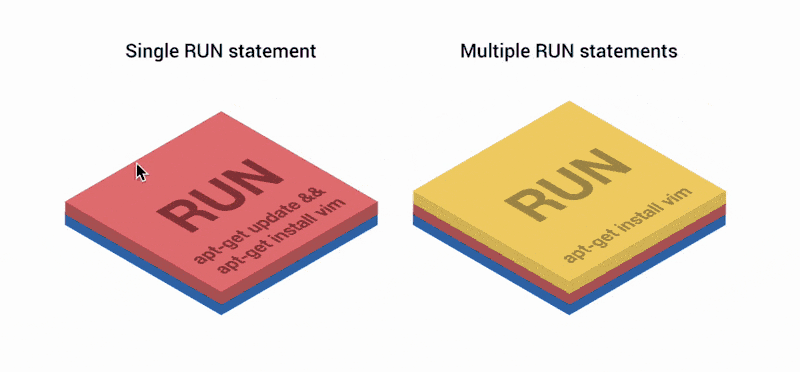
RUN apt-get update && apt-get install vimНу зачем тут &&? Разве не проще запустить два оператора RUN, как здесь?
FROM ubuntu
RUN apt-get update
RUN apt-get install vimНачиная с версии Docker 1.10, операторы COPY, ADD и RUN добавляют новый слой к образу. В предыдущем примере были созданы два слоя вместо одного.
Слои как Git-коммиты.
Docker-слои сохраняют различия между предыдущей и текущей версией образа. И как Git-коммиты, они удобны, если вы делитесь ими с другими репозиториями или образами. Фактически, при запросе образа из реестра, загружаются только недостающие слои, что упрощает разделение образов между контейнерами.
Но при этом, каждый слой занимает место, и чем их больше, тем тяжелее итоговый образ. Git-репозитории в этом отношении схожи: размер репозитория растет вместе с количеством слоев, потому что должен хранить все изменения между коммитами. Раньше была хорошая практика объединять несколько операторов RUN в одной строке, как в первом примере. Но теперь, увы, нет.
1. Объединяем нескольких слоев в один с помощью поэтапной сборки Docker-образов
Когда Git-репозиторий разрастается, можно просто свести всю историю изменений в один commit и забыть о нем. Оказалось, что нечто подобное можно реализовать и в Docker — посредством поэтапной сборки.
Давайте создадим контейнер Node.js.
Начнем с index.js:
const express = require('express')
const app = express()
app.get('/', (req, res) => res.send('Hello World!'))
app.listen(3000, () => {
console.log(`Example app listening on port 3000!`)
})и package.json:
{
"name": "hello-world",
"version": "1.0.0",
"main": "index.js",
"dependencies": {
"express": "^4.16.2"
},
"scripts": {
"start": "node index.js"
}
}Упакуем приложение со следующим Dockerfile:
FROM node:8
EXPOSE 3000
WORKDIR /app
COPY package.json index.js ./
RUN npm install
CMD ["npm", "start"]Создадим образ:
$ docker build -t node-vanilla .Проверим, что все работает:
$ docker run -p 3000:3000 -ti --rm --init node-vanillaТеперь можно пройти по ссылке: http://localhost:3000 и увидеть там «Hello World!».
В Dockerfile теперь у нас есть операторы COPY и RUN, так что фиксируем увеличение как минимум на два слоя, по сравнению с исходным образом:
$ docker history node-vanilla
IMAGE CREATED BY SIZE
075d229d3f48 /bin/sh -c #(nop) CMD ["npm" "start"] 0B
bc8c3cc813ae /bin/sh -c npm install 2.91MB
bac31afb6f42 /bin/sh -c #(nop) COPY multi:3071ddd474429e1… 364B
500a9fbef90e /bin/sh -c #(nop) WORKDIR /app 0B
78b28027dfbf /bin/sh -c #(nop) EXPOSE 3000 0B
b87c2ad8344d /bin/sh -c #(nop) CMD ["node"] 0B
<missing> /bin/sh -c set -ex && for key in 6A010… 4.17MB
<missing> /bin/sh -c #(nop) ENV YARN_VERSION=1.3.2 0B
<missing> /bin/sh -c ARCH= && dpkgArch="$(dpkg --print… 56.9MB
<missing> /bin/sh -c #(nop) ENV NODE_VERSION=8.9.4 0B
<missing> /bin/sh -c set -ex && for key in 94AE3… 129kB
<missing> /bin/sh -c groupadd --gid 1000 node && use… 335kB
<missing> /bin/sh -c set -ex; apt-get update; apt-ge… 324MB
<missing> /bin/sh -c apt-get update && apt-get install… 123MB
<missing> /bin/sh -c set -ex; if ! command -v gpg > /… 0B
<missing> /bin/sh -c apt-get update && apt-get install… 44.6MB
<missing> /bin/sh -c #(nop) CMD ["bash"] 0B
<missing> /bin/sh -c #(nop) ADD file:1dd78a123212328bd… 123MBКак видим, итоговый образ возрос на пять новых слоев: по одному для каждого оператора в нашем Dockerfile. Давайте теперь опробуем поэтапную Docker-сборку. Используем тот же самый Dockerfile, состоящий из двух частей:
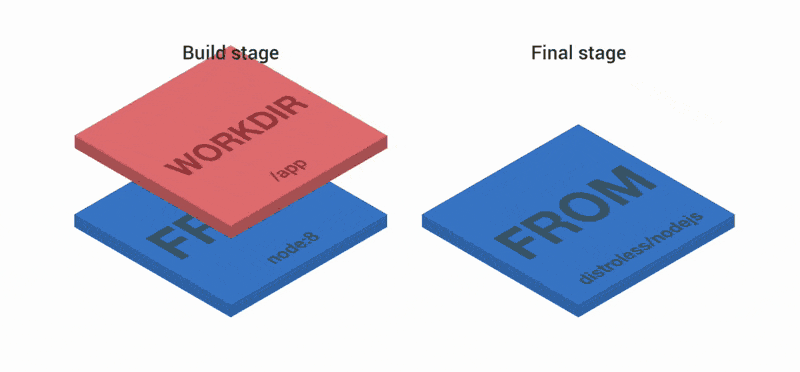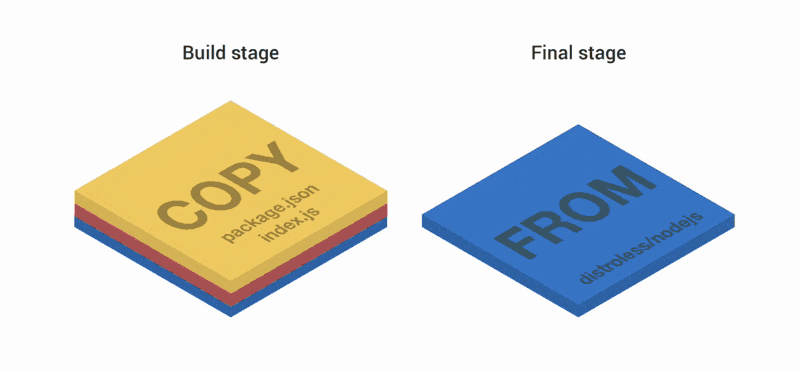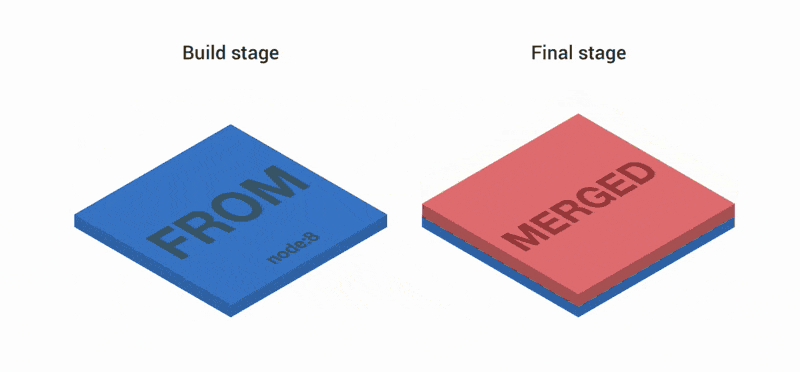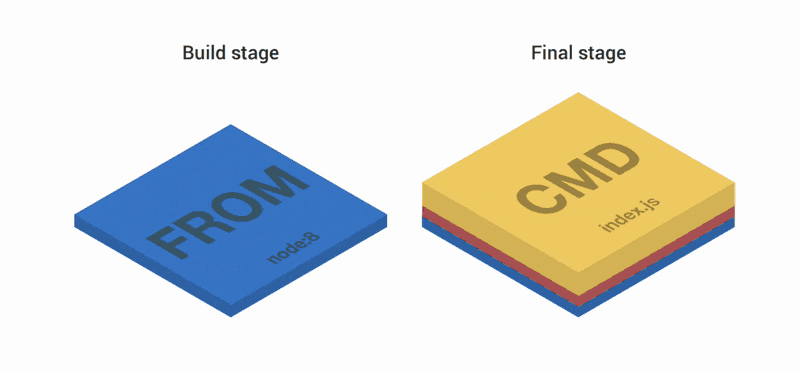
FROM node:8 as build
WORKDIR /app
COPY package.json index.js ./
RUN npm install
FROM node:8
COPY --from=build /app /
EXPOSE 3000
CMD ["index.js"]Первая часть Dockerfile создает три слоя. Затем слои объединяются и копируются на второй и заключительный этапы. Сверху в образ добавляются еще два слоя. В итоге имеем три слоя.
Давайте пробовать. Сначала создаем контейнер:
$ docker build -t node-multi-stageПроверяем историю:
$ docker history node-multi-stage
IMAGE CREATED BY SIZE
331b81a245b1 /bin/sh -c #(nop) CMD ["index.js"] 0B
bdfc932314af /bin/sh -c #(nop) EXPOSE 3000 0B
f8992f6c62a6 /bin/sh -c #(nop) COPY dir:e2b57dff89be62f77… 1.62MB
b87c2ad8344d /bin/sh -c #(nop) CMD ["node"] 0B
<missing> /bin/sh -c set -ex && for key in 6A010… 4.17MB
<missing> /bin/sh -c #(nop) ENV YARN_VERSION=1.3.2 0B
<missing> /bin/sh -c ARCH= && dpkgArch="$(dpkg --print… 56.9MB
<missing> /bin/sh -c #(nop) ENV NODE_VERSION=8.9.4 0B
<missing> /bin/sh -c set -ex && for key in 94AE3… 129kB
<missing> /bin/sh -c groupadd --gid 1000 node && use… 335kB
<missing> /bin/sh -c set -ex; apt-get update; apt-ge… 324MB
<missing> /bin/sh -c apt-get update && apt-get install… 123MB
<missing> /bin/sh -c set -ex; if ! command -v gpg > /… 0B
<missing> /bin/sh -c apt-get update && apt-get install… 44.6MB
<missing> /bin/sh -c #(nop) CMD ["bash"] 0B
<missing> /bin/sh -c #(nop) ADD file:1dd78a123212328bd… 123MBСмотрим, изменился ли размер файла:
$ docker images | grep node-
node-multi-stage 331b81a245b1 678MB
node-vanilla 075d229d3f48 679MBДа, он стал меньше, но пока не значительно.
2. Сносим все лишнее из контейнера с помощью distroless
Текущий образ предоставляет нам Node.js, yarn, npm, bash и много других полезных бинарников. Также, он создан на базе Ubuntu. Таким образом, развернув его, мы получаем полноценную операционную систему со множеством полезных бинарников и утилит.
При этом они не нужны нам для запуска контейнера. Единственная нужная зависимость — это Node.js.
Docker-контейнеры должны обеспечивать работу одного процесса и содержать минимально необходимый набор инструментов для его запуска. Целая операционная система для этого не требуется.
Таким образом, мы можем вынести из него все, кроме Node.js.
Но как?
В Google уже пришли к подобному решению — GoogleCloudPlatform/distroless.
Описание к репозиторию гласит:
Distroless-образы содержат только приложение и зависимости для его работы. Там нет менеджеров пакетов, shell'ов и других программ, которые обычно есть в стандартном дистрибутиве Linux.
Это то, что нужно!
Запускаем Dockerfile, чтобы получить новый образ:
FROM node:8 as build
WORKDIR /app
COPY package.json index.js ./
RUN npm install
FROM gcr.io/distroless/nodejs
COPY --from=build /app /
EXPOSE 3000
CMD ["index.js"]Собираем образ как обычно:
$ docker build -t node-distrolessПриложение должно нормально заработать. Чтобы проверить, запускаем контейнер:
$ docker run -p 3000:3000 -ti --rm --init node-distrolessИ идем на http://localhost:3000. Стал ли образ легче без лишних бинарников?
$ docker images | grep node-distroless
node-distroless 7b4db3b7f1e5 76.7MBЕще как! Теперь он весит всего 76,7 МБ, на целых 600 Мб меньше!
Все круто, но есть один важный момент. Когда контейнер запущен, и надо его проверить, подключиться можно с помощью:
$ docker exec -ti <insert_docker_id> bashПодключение к работающему контейнеру и запуск bash очень похоже на создание SSH-сессии.
Но поскольку distroless — это урезанная версия исходной операционной системы, там нет ни дополнительных бинарников, ни, собственно, shell!
Как подключиться к запущенному контейнеру, если нет shell?
Самое интересное, что никак.
Это не очень хорошо, так как исполнять в контейнере можно только бинарники. И единственный, который можно запустить — это Node.js:
$ docker exec -ti <insert_docker_id> nodeНа самом деле в этом есть и плюс, ведь если вдруг какой-то злоумышленник сможет получить доступ к контейнеру, он причинит намного меньше вреда, чем если бы у него был доступ к shell. Иными словами, меньше бинарников — меньше вес и выше безопасность. Но, правда, ценой более сложной отладки.
Тут надо бы оговориться, что подключать и отлаживать контейнеры на prod-окружении не стоит. Лучше положиться на правильно настроенные системы логирования и мониторинга.
Но что, если нам-таки нужен дебаггинг, и при этом мы хотим, чтобы docker-образ имел наименьший размер?
3. Уменьшаем базовые образы с помощью Alpine
Можно заменить distroless на Alpine-образ.
Alpine Linux — это ориентированный на безопасность, легкий дистрибутив на основе musl libc и busybox. Но не будем верить на слово, а лучше проверим.
Запускаем Dockerfile с использованием node:8-alpine:
FROM node:8 as build
WORKDIR /app
COPY package.json index.js ./
RUN npm install
FROM node:8-alpine
COPY --from=build /app /
EXPOSE 3000
CMD ["npm", "start"]Создаем образ:
$ docker build -t node-alpineПроверяем размер:
$ docker images | grep node-alpine
node-alpine aa1f85f8e724 69.7MBНа выходе имеем 69.7MB — это даже меньше, чем distroless-образ.
Проверим, можно ли подключиться к работающему контейнеру (в случае с distrolles-образом мы не могли этого сделать).
Запускаем контейнер:
$ docker run -p 3000:3000 -ti --rm --init node-alpine
Example app listening on port 3000!И подключаемся:
$ docker exec -ti 9d8e97e307d7 bash
OCI runtime exec failed: exec failed: container_linux.go:296: starting container process caused "exec: \"bash\": executable file not found in $PATH": unknownНеудачно. Но, возможно, у контейнера есть sh'ell…:
$ docker exec -ti 9d8e97e307d7 sh / #Отлично! У нас получилось подключиться к контейнеру, и при этом его образ имеет ещё и меньший размер. Но и тут не обошлось без нюансов.
Alpine-образы основаны на muslc — альтернативной стандартной библиотеке для C. В то время, как большинство Linux-дистрибутивов, таких как Ubuntu, Debian и CentOS, основаны на glibc. Считается, что обе эти библиотеки предоставляют одинаковый интерфейс для работы с ядром.
Однако у них разные цели: glibc является наиболее распространенной и быстрой, muslc же занимает меньше места и написана с уклоном в безопасность. Когда приложение компилируется, как правило, оно компилируется под какую-то определенную библиотеку C. Если потребуется использовать его с другой библиотекой, придется перекомпилировать.
Другими словами, сборка контейнеров на Alpine-образах может привести к неожиданному развитию событий, поскольку используемая в ней стандартная библиотека C отличается. Разница будет заметна при работе с прекомпилируемыми бинарниками, такими как расширения Node.js для C++.
Например, готовый пакет PhantomJS не работает на Alpine.
Так какой же базовый образ выбрать?
Alpine, distroless или ванильный образ — решать, конечно, лучше по ситуации.
Если имеем дело с prod-ом и важна безопасность, возможно, наиболее уместным будет distroless.
Каждый бинарник, добавленный к Docker-образу, добавляет определенный риск к стабильности всего приложения. Этот риск можно уменьшить, имея только один бинарник, установленный в контейнере.
Например, если злоумышленник смог найти уязвимость в приложении, запущенном на базе distroless-образа, он не сможет запустить в контейнере shell, потому что его там нет!
Если же по каким-то причинам размер docker-образа для вас крайне важен, определенно стоит присмотреться к образам на основе Alpine.
Они реально маленькие, но, правда, ценой совместимости. Alpine использует немного другую стандартную библиотеку C — muslc, так что иногда будут всплывать какие-то проблемы. С примерами можно ознакомиться по ссылкам: https://github.com/grpc/grpc/issues/8528 и https://github.com/grpc/grpc/issues/6126.
Ванильные же образы идеально подойдут для тестирования и разработки.
Да, они большие, но зато максимально похожи на полноценную машину с установленной Ubuntu. Кроме того, доступны все бинарники в ОС.
Подытожим размер полученных Docker-образов:
node:8 681MB
node:8 с пошаговой сборкой 678MB
gcr.io/distroless/nodejs 76.7MB
node:8-alpine 69.7MB
Напутствие от переводчика
Читайте другие статьи в нашем блоге:
Резервное копирование большого количества разнородных web-проектов
Комментарии (20)

TyVik
26.01.2019 11:20Alpine Linux — клёвая вещь! По возможности на нём всё делаю, но надо быть осторожнее. Допустим, тех же библиотек для PostGIS в репах нет, и приходится шаманить. Не скажу, что это проблема, но легко на создание образа вместо 20 минут можно потратить 3 часа.

gecube
26.01.2019 11:45У alpine есть недостаток. На маленьких и простых образах — alpine впереди, образ реально меньше debian/ubuntu. Но если alpine накачать python + numpy + scikit + pandas и прочую дичь, то размер получается такой же как у соответствующего образа на ubuntu + в минусах более долгое время сборки на alpine.
TyVik
26.01.2019 12:36Это уже после удаления зависимостей компиляции и очистки кеша? Имею ввиду вот это:
RUN apk update \
&& apk add --no-cache --virtual .build-deps libffi-dev build-base zlib-dev jpeg-dev \
&& pip install -r /tmp/requirements.txt --no-cache-dir \
&& apk del .build-deps
gecube
26.01.2019 12:39я, по-моему, вполне конкретно высказался.
Да, это после удаления зависимостей.
А еще Вы в курсе, что как Вы делаете — не стоит так? Потому что в Вашем сниппете инструкция RUN будет каждый раз выполняться при измененииrequirements.txt. Т.е. мы сильно проигрываем в двух вещах: в кэшировании последующих слоев. И во времени сборки.
И еще подтвержу свою точку зрения ссылкой на статью https://habr.com/ru/post/415513/
Вывод простой — чем больше пакетов — тем меньше выгода от alpine.TyVik
26.01.2019 12:45Про удаление кеша Вы не сказали, так что я предположил.
Ну и про RUN спасибо, конечно, но знаю. Это кусок из базового образа для продукта, который обновляется вручную только при изменении зависимостей. В CI/CD у нас собирается другой, который основан на этом.

Akuma
26.01.2019 11:50+4Так какой же базовый образ выбрать?
Здесь огромная ошибка. Нужно для dev и prod выбирать одно и то же. Они могут отличаться способом внедрения исходников, но базовый образ и все библиотеки должны быть одни и те же. Иначе у вас получаются разные окружения с соответствующими последствиями.gecube
26.01.2019 12:47Я соглашусь. Но можно попробовать сделать как. dev — пускай разрабы делают что угодно и как им удобно. Но вот тогда нам понадобится еще одна pre-prod среда (stage? uat?), в которой образы будут уже собираться "по науке" и идентично prod'у.
Иначе у вас получаются разные окружения с соответствующими последствиями.
prod никогда не будет 100% такой же, как и тестовая среда. Всегда придется чем-то жертвовать. Тем же объемом вливаемых данных в среду. Иначе держать две полностью идентичные среды с зеркалированием трафика влетает в очень большую копеечку и попросту не нужно. Поэтому задача админов, программистов — выбрать те параметры, критерии, которые не очень существенны. И именно ими пожертвовать при моделировании тестовой среды.Akuma
26.01.2019 14:06+2Верно, но можно перестать кататься на квадратных колесах и сразу сесть за круглые.
У нас на сервисе, например, построено примерно так:
1. Есть базовый образ с необходимым ЯП, модулями пр. зависимостями. Эти образы меняются крайне редко.
2. dev работает именно на этих образах путем монтирования в них исходников с машины разработки.
3. prod образы билдятся на CI/CD, но содержат только ADD исходников в образ. Больше никаких изменений не допускается.
4. Все конфиги (nginx, mysql, php, webpack и т.д.) вынесены в docker config. Единственный минус, докер не может их обновлять, только менять имя или удалять/создавать.
Каких-то проблем с такой конфигурацией не наблюдается. Размер образов может быть внушительный, но, честно говоря, не на столько, чтобы создавать этим проблемы.gecube
26.01.2019 15:45Размер образов может быть внушительный, но, честно говоря, не на столько, чтобы создавать этим проблемы.
Соглашусь, что это не является проблемой, если речь не идет про образы по 5ГиБ, но ведь есть и такие кейсы.
И легко можно потратиться на трафик, если будет куча скачиваний.
https://www.brianchristner.io/docker-image-base-os-size-comparison/
https://nickjanetakis.com/blog/the-3-biggest-wins-when-using-alpine-as-a-base-docker-image

neenik
26.01.2019 12:13+1bash в Alpine «называется» ash.
gecube
26.01.2019 12:43ну-ну
/ # mbp-gaal:~ gaal$ docker run -it --rm alpine /bin/sh / # readlink /bin/sh /bin/busybox / # which ash /bin/ash / # readlink /bin/ash /bin/busybox```neenik
26.01.2019 13:30+1Пройдите этот квест дальше. Следующий этап: найдите информацию о командной оболочке, которая используется в busybox.
gecube
26.01.2019 15:42Можете продолжить за меня.
И еще — если бы bash там был полноценный, то не пришлось делатьapk add bash, чтобы работали стандартные баш-скрипты....

faiwer
26.01.2019 12:57+2Я новичок в
dockerи не понял из статьи 1 вещь. Зачем мы используем вначалеnode:8(с Ubuntu, 700+ MiB) а потом во второй стадииnode:alpine(50+ MiB), если… мы просто можем без всяких стадий сразу взятьalpineи нашnpm installсделать уже прямо там по месту.
Я столкнулся с парой проблем, когда
npm installвalphineне мог собрать ряд бинарников из third-party npm packages, но все они решились за счётapk add. В итоге размеры nodejs-app образа всё равно копеечные.
И сразу вопрос. Вот допустим мы решили остаться с Ubuntu и двумя стадиями. В итоге у нас результирующий образ мелкий, а промежуточный большой. Мы можем использовать мелкий-образ, удалив большой? Там ведь unionFS. Она не будет пытаться обратиться к "большому слою" за файлами из него? Или
COPY --fromкопирует по настоящему и привязки нет?gecube
26.01.2019 15:42+1Мы можем использовать мелкий-образ, удалив большой?
они абсолютно независимы. На целевой сервер уедет мелкий оьбраз.
Или COPY --from копирует по настоящему и привязки нет?
ответил выше
Я столкнулся с парой проблем, когда npm install в alphine не мог собрать ряд бинарников из third-party npm packages
верно, поэтому все стадии сборки должны быть сделаны на совместимых образах. Условно — можно на первой стадии скомпилировать некий проект в убунту, а на второй стадии запустить его в эльпайн, но придется добавить все необходимые библиотеки рантайма (ну, типа libc). Либо, что проще — на каждой стадии использовать эльпайн (к сожалению, не всегда возможно из-за зависимостей).

ivanych
26.01.2019 00:32> Как видим, итоговый образ возрос на пять новых слоев
Вы наверное хотели сказать на шесть?
Akuma
Замуровать свой дом, чтобы ничего не украли? Так себе плюс. Хотя экономия 500 МБ конечно существенна.
gecube
Согласен. Вообще статья выглядит как реклама distroless. Гуголь в каждый дом )
На самом деле микроменеджмент докер-образов реально помогает. И тут есть больше возможностей, чем в статье.
1. всегда существует squash. У него минус в том, что он схлопывает все слои и поэтому суммарный объем ВСЕХ докер-образов в системе может увеличиться (т.к. нет общих слоев).
2. правильная расстановка requirements.txt, npm install и пр. в файле (лучше максимально в конец, но еще до внедрения пользовательского кода).
3. чистить в том же блоке RUN зависимости, которые нужны для сборки образа (убираем кэши и пр.). Про мультистейдж, кстати, сказали — супер!
и многое-многое другое.