

Это новая статья из разбора задач с собеседований в Google. Когда я там работал, то предлагал кандидатам такие задачи. Потом произошла утечка, и их запретили. Но у медали есть обратная сторона: теперь я могу свободно объяснить решение.
Для начала отличные новости: я ушёл из Google! Рад сообщить, что теперь работаю техническим руководителем Reddit в Нью-Йорке! Но эта серия статей всё равно получит продолжение.
Дисклеймер: хотя собеседование кандидатов является одной из моих профессиональных обязанностей, в этом блоге я делюсь личными наблюдениями, историями и личным мнением. Пожалуйста, не считайте это официальным заявлением Google, Alphabet, Reddit, любого другого лица или организации.
Вопрос
После двух последних статей о ходе конём в наборе телефонного номера мне пришли критические замечания, что это не реалистичная проблема. Как ни полезно изучить навыки мышления кандидата, но вынужден признать: задача действительно немного нереалистичная. Хотя у меня есть некоторые мысли по поводу корреляции между вопросами на собеседованиях и реальностью, но я пока оставлю их при себе. Будьте уверены, я везде читаю комментарии и мне есть что ответить, только не сейчас.
Но когда задачу про ход конём запретили несколько лет назад, я принял критику близко к сердцу и попытался заменить её вопросом, который немного больше относится к сфере деятельности Google. А что может актуальнее для Google, чем механика поисковых запросов? Так я нашёл этот вопрос и долгое время его использовал, прежде чем он тоже попал в паблик и был запрещён. Как и прежде, я сформулирую вопрос, погружусь в его объяснение, а затем расскажу, как использовал его на собеседованиях и почему он мне нравится.
Итак, вопрос.
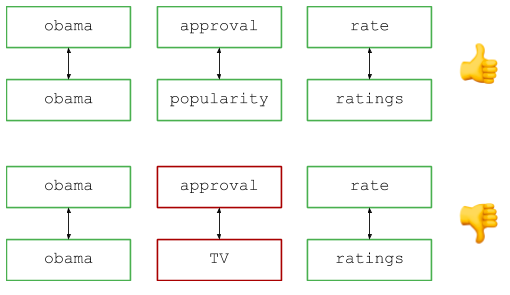
Представьте, что вы управляете популярной поисковой системой и в логах видите два запроса: скажем, «рейтинги одобрения Обамы» и «уровень популярности Обамы» (если я правильно помню, это реальные примеры из базы вопросов, хотя сейчас они немного устарели...). Мы видим разные запросы, но все согласятся: пользователи ищут по сути одну и ту же информацию, так что запросы следует считать эквивалентными при подсчёте количества запросов, показа результатов и т. д. Как определить, что два запроса являются синонимами?
Давайте формализуем задачу. Предположим, есть два набора пар строк: пары синонимов и пары запросы.
Если говорить конкретно, вот пример входных данных для иллюстрации:
SYNONYMS = [
('rate', 'ratings'),
('approval', 'popularity'),
]
QUERIES = [
('obama approval rate', 'obama popularity ratings'),
('obama approval rates', 'obama popularity ratings'),
('obama approval rate', 'popularity ratings obama')
]Нужно выдать список логических значений: являются ли синонимичными запросы в каждой паре.
Всё новые вопросы...
На первый взгляд, это простая задача. Но чем дольше думаете, тем сложнее она становится. Может ли у слова быть несколько синонимов? Имеет ли значение порядок слов? Являются ли синонимичные отношения транзитивными, то есть если А синонимично B, а B синономично С, то является ли А синонимом С? Могут ли синонимы охватывать несколько слов, как «США» является синонимом для фраз «Соединённые Штаты Америки» или «Соединённые Штаты»?
Такая неоднозначность сразу даёт возможность проявить себя хорошему кандидату. Первое, что он делает — выискивает такие двусмысленности и пытается их разрешить. Все делают это по-разному: одни подходят к доске и пытаются вручную решить конкретные случаи, а другие смотрят на вопрос и сразу видят пробелы. В любом случае, выявление этих проблем на раннем этапе имеет решающее значение.
Фаза «понимания проблемы» имеет большое значение. Я люблю называть программную инженерию фрактальной дисциплиной. Как у фракталов, приближение раскрывает дополнительную сложность. Вы думаете, что понимаете проблему, потом смотрите поближе — и видите, что упустили какую-то тонкость или деталь реализации, которую можно улучшить. Или другой подход к проблеме.

Множество Мандельброта
Калибр инженера во многом определяется тем, насколько глубоко он может понять проблему. Преобразовать расплывчатую постановку задачи в подробный набор требований — первый шаг в этом процессе, и умышленная недосказанность позволяет оценить, насколько хорошо кандидат подходит к новым ситуациям.
Оставим в стороне тривиальные вопросы, вроде «Имеют ли значение заглавные буквы?», которые не влияют на основной алгоритм. На эти вопросы я всегда даю самый простой ответ (в этом случае «Предположим, что все буквы уже предварительно обработаны и приведены к строчным»)
Часть 1. (Не совсем) простой случай
Если кандидаты задают вопросы, я всегда начинаю с самого простого случая: у слова может быть несколько синонимов, порядок слов имеет значение, синонимы не транзитивны. Это даёт довольно ограниченную функциональность поисковой системе, но в ней достаточно тонкостей для интересного собеседования.
Высокоуровневый обзор выглядит следующим образом: разбейте запрос на слова (например, по пробелам) и сравните соответствующие пары для поиска идентичных слов и синонимов. Визуально это выглядит так:
В коде:
def synonym_queries(synonym_words, queries):
'''
synonym_words: iterable of pairs of strings representing synonymous words
queries: iterable of pairs of strings representing queries to be tested for
synonymous-ness
'''
output = []
for q1, q2 in queries:
q1, q2 = q1.split(), q2.split()
if len(q1) != len(q2):
output.append(False)
continue
result = True
for i in range(len(q1)):
w1, w2 = q1[i], q2[i]
if w1 == w2:
continue
elif words_are_synonyms(w1, w2):
continue
result = False
break
output.append(result)
return outputЛегко, правда? Алгоритмически это довольно просто. Никакого динамического программирования, рекурсии, сложных структур и т. д. Простая манипуляция стандартной библиотекой и алгоритм, который работает за линейное время, верно?
Но здесь больше нюансов, чем кажется на первый взгляд. Безусловно, самым сложным компонентом является сравнение синонимов. Хотя компонент прост в понимании и описании, существует много способов ошибиться. Расскажу о наиболее распространённых ошибках.
Для ясности: никакие ошибки не дисквалифицируют кандидата; если что, я просто указываю на ошибку в реализации, он исправляет, и мы идём дальше. Однако собеседование — это, прежде всего, борьба со временем. Вы будете делать, замечать и исправлять ошибки, но это отнимает время, которое можно потратить на другое, например, на создание более оптимального решения. Практически все совершают ошибки, это нормально, но кандидаты, которые делают их меньше, показывают лучший результат просто потому, что тратят меньше времени исправления.
Вот почему мне нравится эта проблема. Если ход конём требует озарения в понимании алгоритма, а затем (надеюсь) простой реализации, то здесь решение — это множество шажков в правильном направлении. Каждый шаг представляет крошечное препятствие, через которое кандидат может либо изящно перепрыгнуть, либо споткнуться и подняться. Хорошие кандидаты благодаря опыту и интуиции избегают этих маленьких ловушек — и получают более подробное и правильное решение, в то время как более слабые тратят время и энергию на ошибки и обычно остаются с ошибочным кодом.
На каждом собеседовании я видел разное сочетание успехов и провалов, вот самые распространённые ошибки.
Случайные убийцы производительности
Во-первых, некоторые кандидаты реализовали обнаружение синонимов с помощью простого обхода списка синонимов:
...
elif (w1, w2) in synonym_words:
continue
...На первый взгляд, это кажется разумным. Но при ближайшем рассмотрении идея оказывается очень, очень плохой. Для тех из вас, кто не знает Python, ключевое слово
in — синтаксический сахар для метода contains и работает над всеми стандартными контейнерами Python. Это проблема, потому что synonym_words — список, который реализует ключевое слово in с помощью линейного поиска. Пользователи Python особенно чувствительны к этой ошибке, потому что язык скрывает типы, но пользователи C++ и Java тоже иногда делали похожие ошибки.За всю карьеру я всего несколько раз писал код с линейным поиском, и каждый по списку длиной не более двух десятков элементов. И даже в этом случае писал длинный комментарий с объяснением, почему выбрал такой, казалось бы, неоптимальный подход. Подозреваю, что некоторые кандидаты использовали его просто потому что не знали, как работает со списками ключевое слово
in в стандартной библиотеке Python. Это простая ошибка, не фатальная, но плохое знакомство с любимым языком — не очень хорошо.На практике этой ошибки легко избежать. Во-первых, никогда не забывайте типы своих объектов, даже если используете нетипизированный язык, такой как Python! Во-вторых, помните, что при использовании ключевого слова in в списке запускается линейный поиск. Если нет гарантии, что этот список всегда останется очень маленьким, он убьёт производительность.
Чтобы кандидат опомнился, обычно достаточно напомнить ему, что входная структура является списком. Очень важно наблюдать, как кандидат реагирует на подсказку. Лучшие кандидаты сразу пытаются как-то предварительно обработать синонимы, что является хорошим началом. Однако этот подход не лишён своих подводных камней…
Используйте правильную структуру данных
Из приведённого выше кода сразу видно, что для реализации этого алгоритма в линейное время необходимо быстро находить синонимы. А когда мы говорим о быстром поиске, это всегда карта или массив хэшей.
Мне не важно, выберет кандидат карту или массив хэшей. Важно то, что он туда вложит (кстати, никогда не используйте dict/hashmap с переходом в
True или False). Большинство кандидатов выбирают какой-то dict/hashmap. Самая распространённая ошибка — подсознательное предположение, что у каждого слова не больше одного синонима:...
synonyms = {}
for w1, w2 in synonym_words:
synonyms[w1] = w2
...
elif synonyms[w1] == w2:
continue Я не наказываю кандидатов за эту ошибку. Задача специально сформулирована так, чтобы не заострять внимание на том, что у слов может быть несколько синонимов, а некоторые кандидаты просто не сталкивались с такой ситуацией. Большинство быстро исправляет ошибку, когда я на неё указываю. Хорошие кандидаты замечают её на раннем этапе и обычно не тратят много времени.
Чуть более серьёзная проблема — неосознание, что отношения синонимов распространяются в обоих направлениях. Заметьте, что в приведённом выше коде это учитывается. Но встречаются реализации с ошибкой:
...
synonyms = defaultdict(set)
for w1, w2 in synonym_words:
synonyms[w1].append(w2)
synonyms[w2].append(w1)
...
elif w2 in synonyms.get(w1, tuple()):
continueЗачем выполнять две вставки и использовать в два раза больше памяти?
...
synonyms = defaultdict(set)
for w1, w2 in synonym_words:
synonyms[w1].append(w2)
...
elif (w2 in synonyms.get(w1, tuple()) or
w1 in synonyms.get(w2, tuple())):
continueВывод: всегда думайте, как оптимизировать код! В ретроспективе перестановка функций поиска является очевидной оптимизацией, в ином случае можно сделать вывод, что кандидат не думал над вариантами оптимизации. Опять же, я рад дать подсказку, но лучше догадаться самому.
Сортировка?
Некоторые умные кандидаты хотят отсортировать список синонимов, а затем использовать двоичный поиск. На самом деле у такого подхода есть важное преимущество: он не требует дополнительного пространства, кроме списка синонимов (при условии, что допускается изменение списка).
К сожалению, мешает сложность по времени: сортировка списка синонимов требует
Nlog(N) времени, а затем ещё log(N) для поиска каждой пары синонимов, в то время как описанное решение предварительной обработки происходит в линейном, а затем постоянном времени. Кроме того, я категорически против того, чтобы заставлять кандидата реализовать сортировку и двоичный поиск на доске, потому что: 1) алгоритмы сортировки хорошо известны, поэтому, насколько я знаю, кандидат может выдать его не думая; 2) эти алгоритмы дьявольски сложно правильно реализовать, и часто даже лучшие кандидаты будут делать ошибки, которые ничего не говорят об их навыках программирования.Всякий раз, когда кандидат предлагал такое решение, я интересовался временем выполнения программы и спрашивал, есть ли вариант лучше. Для информации: если интервьюер спрашивает вас, есть ли вариант лучше, почти всегда ответ «да». Если я когда-нибудь задам вам этот вопрос, ответ точно будет таким.
Наконец, решение
В конце концов кандидат предлагает что-то правильное и достаточно оптимальное. Вот реализация в линейном времени и линейном пространстве для заданных условий:
def synonym_queries(synonym_words, queries):
'''
synonym_words: iterable of pairs of strings representing synonymous words
queries: iterable of pairs of strings representing queries to be tested for
synonymous-ness
'''
synonyms = defaultdict(set)
for w1, w2 in synonym_words:
synonyms[w1].add(w2)
output = []
for q1, q2 in queries:
q1, q2 = q1.split(), q2.split()
if len(q1) != len(q2):
output.append(False)
continue
result = True
for i in range(len(q1)):
w1, w2 = q1[i], q2[i]
if w1 == w2:
continue
elif ((w1 in synonyms and w2 in synonyms[w1])
or (w2 in synonyms and w1 in synonyms[w2])):
continue
result = False
break
output.append(result)
return outputНесколько быстрых замечний:
- Обратите внимание на использование
dict.get(). Вы можете реализовать проверку, находится ли ключ в dict, а затем получить его, но это усложнённый подход, хотя таким образом вы покажете свои знания стандартной библиотеки. - Я лично не поклонник кода с частыми
continue, и некоторые руководства по стилю запрещают или не рекомендуют их. Я сам в первой редакции этого кода забыл операторcontinueпосле проверки длины запроса. Это не плохой подход, просто знайте, что он подвержен ошибкам.
Часть 2: Становится сложнее!
У хороших кандидатов после решения задачи остаётся ещё десять-пятнадцать минут времени. К счастью, есть куча дополнительных вопросов, хотя вряд ли мы напишем много кода за это время. Впрочем, в этом нет необходимости. Я хочу знать о кандидате две вещи: способен ли он разрабатывать алгоритмы и умеет ли кодировать? Задача с ходом конём сначала отвечает на вопрос о разработке алгоритма, а затем проверяет кодирование, а здесь мы получаем ответы в обратном порядке.
К тому времени, когда кандидат завершил первую часть вопроса, он уже решил проблему с (удивительно нетривиальным) кодированием. На этом этапе я могу с уверенностью говорить о его способности разрабатывать рудиментарные алгоритмы и переводить идеи в код, а также о знакомстве со своим любимым языком и стандартной библиотекой. Теперь разговор становится намного интереснее, потому что требования к программированию можно смягчить, а мы погрузимся в алгоритмы.
С этой целью вернёмся к основным постулатам первой части: важен порядок слов, синонимы нетранзитивны и для каждого слова может быть несколько синонимов. По мере продвижения интервью я изменяю каждое из этих ограничений, и в этой новой фазе у нас с кандидатом происходит чисто алгоритмическое обсуждение. Здесь я приведу примеры кода, чтобы проиллюстрировать свою точку зрения, но в реальном интервью мы говорим только об алгоритмах.
Прежде чем начать, объясню свою позицию: все последующие действия на этом этапе интервью — в основном, «бонусные баллы». Мой личный подход заключается в выявлении кандидатов, которые точно проходят первый этап и подходят для работы. Второй этап нужен для выделения самых лучших. Первый рейтинг уже очень сильный и означает, что кандидат достаточно хорош для компании, а второй рейтинг говорит, что кандидат превосходен и его найм станет для нас большой победой.
Транзитивность: наивные подходы
Сначала я люблю снять ограничение на транзитивность, так что если синонимами являются пары A?B и В?С, то слова A и C тоже являются синонимами. Сообразительные кандидаты быстро поймут, как адаптировать своё предыдущее решение, хотя при дальнейшем снятии других ограничений основная логика алгоритма перестанет работать.
Тем не менее, как его адаптировать? Один из распространённых подходов — поддерживать полный набор синонимов для каждого слова на основе транзитивных отношений. Каждый раз, когда мы вставляем слово в набор синонимов, мы также добавляем его в соответствующие наборы для всех слов, находящихся в этом наборе:
synonyms = defaultdict(set)
for w1, w2 in synonym_words:
for w in synonyms[w1]:
synonyms[w].add(w2)
synonyms[w1].add(w2)
for w in synonyms[w2]:
synonyms[w].add(w1)
synonyms[w2].add(w1)Обратите внимание, что создавая код, мы уже углубились в это решение
Это решение работает, но далеко не оптимально. Чтобы понять причины, оценим пространственную сложность этого решения. Каждый синоним нужно добавить не только к набору начального слова, но и к наборам всех его синонимов. Если синоним один, то добавляется одна запись. Но если у нас 50 синонимов, придётся добавить 50 записей. На рисунке это выглядит следующим образом:

Обратите внимание, что мы перешли от трёх ключей и шести записей к четырём ключам и двенадцати записям. Слово с 50 синонимами потребует 50 ключей и почти 2500 записей. Необходимое пространство для представления одного слова квадратично растёт с увеличением набора синонимов, что довольно расточительно.
Есть и другие решения, но не буду слишком углубляться, чтобы не раздувать статью. Наиболее интересное из них — использование структуры данных синонимов для построения ориентированного графа, а затем поиск в ширину для нахождения пути между двумя словами. Это прекрасное решение, но поиск становится линейным по размеру набора синонимов для слова. Поскольку мы выполняем этот поиск для каждого запроса несколько раз, такой подход не оптимален.
Транзитивность: использование непересекающихся множеств
Оказывается, поиск синонимов возможен за (почти) постоянное время благодаря структуре данных под названием непересекающиеся множества (disjoint set). Эта структура предлагает несколько иные возможности, чем обычный набор данных (set).
Обычная структура набора (hashset, treeset) представляет собой контейнер, который позволяет быстро определить, находится объект внутри или вне его. Непересекающиеся множества решают совсем иную проблему: вместо определения конкретного элемента они позволяют определить, принадлежат ли два элемента одному набору. Более того, структура делает это за с ослепительно быстрое время
O(a(n)), где a(n) — обратная функция Аккермана. Если вы не изучали продвинутые алгоритмы, то можете не знать эту функцию, которая для всех разумных входов фактически выполняется за постоянное время.На высоком уровне алгоритм работает следующим образом. Наборы представлены деревьями с родителями у каждого элемента. Поскольку у каждого дерева есть корень (элемент, который сам себе родитель), мы можем определить, принадлежат ли два элемента одному набору, проследив их родителей до корня. Если у двух элементов один корень, они принадлежат одному набору. Объединение множеств тоже легко: просто находим корневые элементы и делаем один из них корнем другого.
Пока всё хорошо, но пока не видно ослепительной скорости. Гениальность этой структуры — в процедуре под названием сжатие. Предположим, у вас есть следующее дерево:
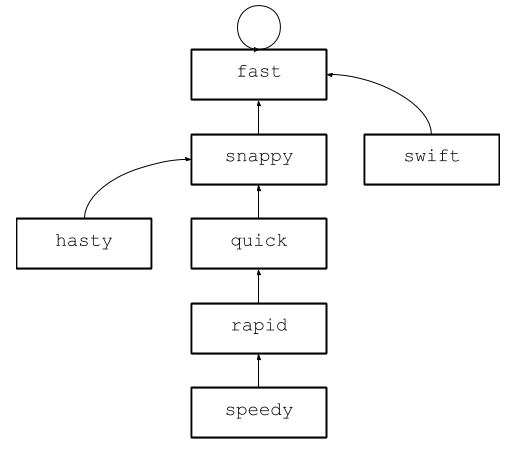
Представьте, что вы хотите узнать, являются ли синонимами слова speedy и hasty. Идёте по родителям каждого — и находите одинаковый корень fast. Теперь предположим, что мы выполняем аналогичную проверку для слов speedy и swift. Опять идём вверх до корня, причём от speedy мы идём тем же маршрутом. Можно ли избежать дублирования работы?
Оказывается, можно. В некотором смысле, каждому элементу в этом дереве суждено прийти к fast. Вместо того, чтобы каждый раз проходить по всему дереву, почему бы не изменить родителя для всех потомков fast, чтобы сократить маршрут к корню? Этот процесс называется сжатием, и в непересекающихся множествах он встроен в операцию поиска корня. Например, после первой операции по сравнению speedy и hasty структура поймёт, что они синонимы, и сожмёт дерево следующим образом:

Для всех слов между speedy и fast обновился родитель, то же самое произошло с hasty
Теперь все последующие обращения будут происходить в постоянном времени, потому что каждый узел в этом дереве указывает на fast. Здесь не очень просто оценить временную сложность операций: на самом деле, она не постоянна, потому что зависит от глубины деревьев, но близка к постоянной, потому что структура быстро оптимизируется. Для простоты будем считать, что время постоянное.
С этой концепцией реализуем несвязанные множества для нашей проблемы:
class DisjointSet(object):
def __init__(self):
self.parents = {}
def get_root(self, w):
words_traversed = []
while self.parents[w] != w:
words_traversed.append(w)
w = self.parents[w]
for word in words_traversed:
self.parents[word] = w
return w
def add_synonyms(self, w1, w2):
if w1 not in self.parents:
self.parents[w1] = w1
if w2 not in self.parents:
self.parents[w2] = w2
w1_root = self.get_root(w1)
w2_root = self.get_root(w2)
if w1_root < w2_root:
w1_root, w2_root = w2_root, w1_root
self.parents[w2_root] = w1_root
def are_synonymous(self, w1, w2):
return self.get_root(w1) == self.get_root(w2)Используя эту структуру, можно предварительно обработать синонимы и решить задачу за линейное время.
Оценка и примечания
К этому моменту мы достигли предела того, что кандидат может показать за 40?45 минут собеседования. Всем кандидатам, которые справились с вводной частью и добились значительного прогресса в описании (не реализации) несвязанных множеств, я присваивал рейтинг «Настоятельно рекомендуется принять на работу» и позволял им задавать любые вопросы. Никогда не видел, чтобы кандидат зашёл так далеко и у него осталось много времени.
В принципе, ещё есть варианты задачи с транзитивностью: например, убрать ограничение на порядок слов или на несколько синонимов для слова. Каждое решение будет сложным и восхитительным, но оставлю их на потом.
Достоинство этой задачи в том, что она позволяет кандидатам ошибаться. Ежедневная разработка ПО состоит из бесконечных циклов анализа, выполнения и уточнения. Эта проблема даёт возможность кандидатам продемонстрировать свои способности на каждом этапе. Рассмотрим навыки, необходимые для получения максимальной оценки по этому вопросу:
- Проанализируйте постановку задачи и определите, где она недостаточно чётко сформулирована, разработайте однозначную формулировку. Продолжайте делать это по мере решения и возникновения новых вопросов. Для максимальной эффективности производите эти операции как можно раньше, потому чем дальше зашла работа, тем больше времени займёт исправление ошибки.
- Сформулируйте проблему таким образом, чтобы к ней было легче подойти и решить. В нашем случае самым важным является наблюдение, что соответствующие слова в запросах выстраиваются друг относительно друга.
- Реализуйте свое решение. Это включает в себя выбор оптимальной структуры данных и алгоритмов, а также проектирование логики, читаемой и легко изменяемой в будущем.
- Вернитесь назад, попытайтесь найти баги и ошибки. Это могут быть фактические ошибки, как я забыл вставить оператор
continueвыше, или ошибки производительности, как использование неправильной структуры данных.
- Когда определение проблемы изменится, повторите весь процесс: адаптируйте своё решение, где это необходимо, или откажитесь от него, если оно не подходит. Понимание, когда нужно сделать одно или другое, является критически важным навыком и в собеседовании, и в реальном мире.
- Осваивайте структуры данных и алгоритмы. Непересекающиеся множества — не очень известная структура, но на самом деле не такая уж редкая и утончённая. Единственный способ гарантировать знание инструментария для работы — как можно больше учиться.
Ни один из этих навыков нельзя освоить по учебникам (за исключением, возможно, структур данных и алгоритмов). Единственный способ приобрести эти их — регулярная и обширная практика, которая хорошо согласуется с тем, что нужно работодателю: опытные кандидаты, способные эффективно применять свои знания. Смысл собеседований — найти таких людей, и задача из этой статьи долгое время хорошо мне помогала.
Планы на будущее
Как вы могли понять, задача в конце концов стала известна общественности. С тех пор я использовал несколько других вопросов, в зависимости от того, что спрашивали прошлые интервьюеры и от моего настроения (задавать всё время один вопрос скучно). Некоторые вопросы использую до сих пор, так что их буду держать в секрете, но некоторые нет! Можете узнать их в следующих статьях.
На ближайшее время я планирую две статьи. Во-первых, как и обещал выше, объясню решение двух оставшихся проблем для этой задачи. Я их никогда не задавал на собеседованиях, но они интересны сами по себе. Кроме того, поделюсь своими размышлениями и личным мнением о процедуре поиска сотрудников в IT, что мне особенно интересно сейчас, потому что я ищу инженеров для своей команды в Reddit.
Как всегда, если хотите узнать о выходе новых статей, следите за мной в твиттере или на Medium. Если вам понравилась эта статья, не забудьте прогголосовать за неё или оставить комментарий.
Благодарю за чтение!
P. S.: Можете изучить код всех статей в репозитории GitHub или поиграться с ним вживую благодаря моим добрым друзьям из repl.it.
vassabi
Недавно собеседовал на С++. Все кандидаты написали в резюме senior (у некоторых было даже tech-lead). Задача — «Дана матрица. Нужно повернуть числа в ней по часовой\против часовой стрелке. Предложите структуру(ы) для ее хранения, передачи и решения задачи».
Ни с одним не дошли до стадии «компилируется и хоть как-то выполняет задачу»…
Сейчас почитал статью — наверно надо было предлагать решить ее на питоне.
genuimous
Самое тупое чтобы не думать: создается матрица-копия и в нее пишется, потом оригинал уничтожается. Более сложное и правильное использовать простую перестановку 2х чисел (проще через третье в памяти) и циклы, но тут надо быть внимательным чтобы ничего не потерять. Вроде ответ очевиден, или что хочется услышать? Применение какой-либо готовой функции из общедоступных библиотек? Если что мопед не мой, я не программист уже четвертый год: )
vassabi
на самом деле, я смотрел в глаза, и при ответе типа: " создается матрица-копия и в нее пишется ...", уже ставил плюсик.
Если там была еще и хорошая мысль — то второй плюс, и так за каждое улучшение. Как у автора оригинальной заметки: «это фрактальная дисциплина».
genuimous
Вот честно, когда дают задание что-то написать конкретное, особенно абстрактное, и чтобы компилировалось и работало и эффективно, то возникает желание взять и уе… с мыслями вроде «что я тут делаю» и «может они так себе задачи нахаляву решают». Алгоритмически обсудить, нарисовать простейшую блок-съему и т.п. всегда пожалуйста, но писать, компилить и дебажить код — увольте. Это скучно и займет много времени без всякого производительного результата. Например я уверен что смогу запрограммировать свои идеи, а вот программировать их в коде просто так не горю желанием. Нанимайте меня и тогда буду кодить. Но то может я такой хреновый программист, а хорошему и закодить за 5 минут нетрудно на любом предложенном языке.
BugM
Вы отказываетесь писать работающий код на собеседовании на должность программиста? Не домашнее задание на неделю работы, а именно на собеседовании в офисе.
Вот мне даже интересно как такие люди вообще работу находят?
genuimous
Не знаю, ни разу не приходилось. Один лишь раз Тандер выдал домашнее задание, но мне было лень его делать. Все остальные разы было достаточно предъявления опыта работы, теоретической беседы и тестов. Написание кода если и было то лишь буквально 3-4 строчки и то для иллюстрации сказанного, без компиляции на компьютере. Как нахожу работу сам не понимаю.
P.S. не ну я ж сразу сказал я плохой программист, на 100% им никогда не был, и код взрослый не писал, так что-нибудь в продакшен оператора связи наживую запулить и все, не операционную систему ж для ракеты созидаю.
BalinTomsk
Я себе так нашел. Только словесное техническое интервью с директором и просто знакомство с тимлидами.
После гуглей, блумбергов, амазонов с 8 интервью за день, просто душой отдыхал.
springme
Это подмена понятий.
Во-первых, писать работающий код без инструментария, к которому я привык за годы работы не хочу. IDE, хоткеи – без них я чувствую себя некомфортно. Вполне реально забыть как в той же джаве инициализируются двумерные массивы, если их не используешь.
Во-вторых, в реальности код всегда пишется в каком-либо контексте и чтобы в этот контекст войти часто нужны недели. Писать абстрактный код без контекста (нет, алгоритм это не контекст, а условие) – уровень университетской лабораторной работы, это не проверяет ничего.
BugM
Я не понимаю этого нехотения писать код. Писать код это то что мы хорошо умеем делать. Это то за что нам платят деньги. Просто логично на собеседовании показать свое лучшее умение.
Забытый кусок синтаксиса это ну настолько мелкая проблема. Всегда можно честно сказать я забыл как именно это пишется. Поэтому считаем массив заранее инициализированным. Тонкости синтаксиса гуглятся за минуту. Все в курсе.
Есть множество людей которые не способны писать код. Вообще. При этом у них будет красивое резюме (мы же не хотим проводить расследование о правдивости резюме для каждого кандидата?), они будут очень красиво говорить общие слова и даже смогут ответить на типовые теоретические вопросы. На работе они будут копипастить со SO без понимания как и почему. Как таких отсеять? Отсеивание на испытательном сроке это очень печально, его надо всеми силами избегать.
Проверяем умение писать код. Простой. Абстрактный. Это точно проще чем любой продакшен код. И это как минимум гарантирует что человек лабы в университете делал сам. Таких меньшинство.
i360u
Ага, писать код мы любим и умеем, а вот писать код стоя в гамаке обутыми в лыжи — не очень. Лично я — отказываюсь писать код в лыжах, хотя очень люблю писать код и посвящаю этому все свое свободное и рабочее время.
Элементарно: поговорите с человеком. Не задавайте тупых «типовых теоритеческих вопросов», спросите что человеку интересно, узнайте о его философии, подходах к работе, симпатиях и антипатиях. Попробуйте поспорить, обязательно на позитиве, на какую-то тему. Попросите показать код, которым человек гордится, попробуйте выяснить почему. Я вас уверяю, все будет ясно, если вы сами обладаете хоть каким-то боевым опытом.
tyomitch
Умение писать код в условиях стресса и цейтнота — тоже нужный на практике навык («сервер ни с того ни с сего лёг, теряем сотни денег каждую минуту!»)
Интересно: сколько лично вы собеседовали соискателей?
По-моему, навык «очаровать собеседника при беседе» никак не коррелирует с «писать код быстро и хорошо»
i360u
Ну да, как же без «ее величества» — стрессоустойчивости. Вас, когда «лег сервер» заставляют писать абстрактный код на бумажке? Отбирают все доки, мануалы, анализаторы? Заставляют одновременно решать, подходит ли мне этот работодатель? Заставляют вспоминать теоретические моменты, напрямую к ситуации никак не относящиеся? Думаю что нет.
Не помню точно, но не один десяток. Достаточно, чтобы иметь обоснованное мнение по данному вопросу.
Ага, попробуйте «очаровать» технического специалиста, рассуждая на технические темы, о которых имеете слабое представление. Беседа ведь предполагается вовсе не о погоде. И никто вам не даст абсолютно никакой гарантии, что человек, решивший «быстро и хорошо» задачку на бумажке, будет работать «быстро и хорошо». Все эти задачки — это просто способ переложить личную ответственность за принятое решение о найме на формальный критерий, слабо коррелирующий с реальными боевыми условиями.
RomanArzumanyan
Лучшее умение программиста — читать код. Чем меньше кода в итоге написано, тем лучше. Меньше кода — меньше багов.
RussDragon
А что может показать написание кода за полчаса на интервью? То, что человек смог заучить десяток ключевых слов языка и имеет приблизительное понимание того, что такое код программы?
Код может написать и хреновый программист. Описать, формализовать и обсудить решение – только хороший. Беседа на общие и даже отдаленные темы показывает свою куда бОльшую эффективность в долгосрочной перспективе, чем решенное тестовое.
BugM
То что человек может писать код. Странно правда?
Я лично собеседовал человека у которого в резюме было слово SQL, а в вакансии было слово Оракл. У него судя по резюме был опыт, он довольно красиво рассказывал про нормальные формы и прочую теорию.
Только вот с задачей написать простенький селект с джойном и групбаем из пары табличек на бумажке он не справился. От слова вообще. Такое ощущение, что он синтаксис sql впервые увидел. О чем после такого может идти речь?
Я сильно подозреваю что на вакансии Java, С итп такие же кадры приходят. Резюме вроде хорошее работал, сделал итд. Теорию зазубрить несложно. На собеседованиях очень типовые вещи по теории спрашивают. А вот написать десяток строк кода человек не может.
Отмазки мол я не могу без IDE написать десять строк кода это глупости. Базовый синтаксис у любого человека пишущего код за деньги в подкорке сидит. Каждый день же используешь. В практических задачах использовать что-то кроме базового синтаксиса никогда не надо. О сложных вещах можно и просто поговорить.
Спрашивать сложные вещи по теории хуже чем заставлять писать код. Они как раз каждый день не используются и великолепно забываются.
karminski
Если вы ходите на работу только для того, чтобы писать код, я вам сочувствую. Я своих подопечных никогда не просил на собеседовании тратить время на написание кода. В конце концов есть испытанный срок, с человеком можно и расстаться.
roscomtheend
А можно не терять время на испытательный. Если на собеседование по SQL человек не может сделать create table с 3 полями(выбрав их тип под задачу и объяснить почему выбрал этот), а потом написать селект с 1 join и парой условий (а таких много, если не предлагать зарплату в два рынка), то тратить бумагу на договор не стоит. Так же, когда человек заявляет опыт в чём-то типа ++ в 5-10-15 лет, но не может сделать простой класс (на любом удобном ему языке), путается между наследованием и методом, то опять не вижу смысла продолжать. Если какой-то рокстар отсеется на этом этапе, то и пусть (обычно задачи сильно прозаичнее, чем он бы хотел).
vassabi
ну, иногда бывает мандраж на собеседовании.
Я видел много людей, которые не могли сделать простейший джойн, но если они могли объяснить и нарисовать — то никого не отсеивал (в принципе тех кто действительно не знает от тех кто подзабыл достаточно легко отличить).
0o00oo00o0
Квадратную матрицу можно сначала транспонировать (против ч.с. — относительно главной диагонали, по — относительно побочной), затем обменять местами строки (первую с последней, вторую с предпоследней и т.д.). Достаточно swap'а элементов.
lgorSL
Да и неквадратную тоже можно, при транспонировании её форма как раз "повернётся".
Хотя я вместо этого думал сделать обертку, которая отображает индексы типа x, y => y, width — x и потом либо сделать просто обертку над старой матрицей, которая притворяется "новой", либо с таким отображением индексов скопировать всё в новую матрицу. (Копировать можно поблочно, чтобы кеш работал)
Но вариант с траспонированием и переворотом строчек более красивым кажется, в том же питоне numpy такое быстро сделает, в отличие от ручного перекладывания элементов.
Будет что-то типа А.T[::-1, :]
Kell
Если уж пользоваться numpy, так там вообще просто есть rot90, который делает именно то, что нужно.
Более того, в numpy (во многих операциях, в документации заметно по «returns — view of m») используется именно идея с оберткой и отображением индексов, что позволяет не проводить фактически никаких операций с массивом на самом деле, но зато ухудшает работу кэша.
Итого, нам, на самом то деле, недостаточно данных: если из массива далее будут интенсивно последовательно читать данные, то лучше перенести на самом деле, иначе — можно воспользоваться отображением.
vassabi
а можно сначала свапнуть, а потом транспонировать — и тогда не нужно побочной диагонали.
j8kin
Если не ошибаюсь подобную встречал на LeetCode. Или Cracking Code Interview. Вообще имхо доводить на бумажке или доске до состояния компилируется ИМХО все же не правильно, я, например, могу от волнения тупо забыть методы из stl, какие в них параметры передаются, порядок, что выдают на гору. Мне кажется во всех подобных задачах при решении у доски важен именно диалог, который дает понять как у человека с алгоритмизацией и мышлением. А вот если уже комп дают, то можно уже смотреть с точки зрения компилирования, но там и ide помогает.В таких случаях я, например, начинал писать с юнит тестов (TDD), а потом итеративно писал алгоритм и придумывал дополнительные кейсы после того, как основная часть уже готова, но часто просили просто обсудить граничные условия, а не их реализацию и мы переходили к следующей.
P.S. Вакансия С++, просить написать на Python — будет странно смотреться))) Яб сильно задумался на месте собеседуемых, что от меня будут требовать в будущем.
vassabi
Есть замечательные онлайн-компиляторы с возможностью совместного редактирования (и для С и для С++17 и проч и проч). Там можно накалякать простой код и запустить.
А про питон — вот я сейчас сам для себя дома пишу всякую всячину на питоне (на который перешел с перла), и размышляю, что не так важен язык, как умение сесть и действительно задуматься над задачей (а не фигачить код).
Вот когда алгоритм уже линейный-логарифмический, а скорости все равно нехватает — тогда наверно можно и переписать на чем-то быстром, но до такого пока не доходило…
springme
А почему senior должен решать такие задачки лучше джуна со свеженькими знаниями из университета по «верчению» разных матриц, деревьев и прочих laba2.cpp?
Вы бы еще попросили поделить столбиком на бумажке два числа – я бы не смог, а вот третьеклассники умеют. Только какое это все имеет отношение к компетенции программиста?
masai
Тут важно не решение задачи, а то, как кандидат рассуждает, и то, как глубоко он видит контекст. Собственно, об этом в статье говориться.
Разумеется, задача хоть немного должна быть привязана к тематике его будущей работы. Если предлагается потом писать высокооптимизированный код для обработки изображений, то задача с поворотом матрицы вполне годится как повод для начала разговора.
Это как задачка «Расскажите, что происходит, когда вы вводите адрес в браузере и нажимаете Enter». Тоже можно до бесконечности углубляться.
Ну и есть другой аспект. Иногда люди претендующие на высокие должности просто не дотягивают до них. Таких можно отсеять подобными задачками.
springme
Такими «задачками» можно лишь отсеять людей, которые на такие должности как раз дотягивают. Если вы будете и на работе давать tech lead'ам задачки на выкручивание матриц по кругу – нужна ли ему такая работа? А если не будете давать на работе, то зачем тратить его и ваше время на возню с университетскими i,j,k?
Конечно, вышесказанное не относится к обработке изображений или какому-нибудь ML. Но, учитывая, что подавляющая часть вакансий это перегонка SQL в JSON и обратно, то задача типа «сделайте BFS обход дерева» смотрится неуместно.
masai
Ну вот об этом и речь. Нет универсальной задачи на собеседования для всех случаев. И если берут программиста программировать фронтэнд, то понятно, что повороты матриц будут смотреться оторванно от реальности.
faiwer
Ага, вот такие вот задачи дают frontend-ерам:
t13s
О, а я даже знаю, что это за контора — самому присылали такое. Правда, на backend-вакансию. А потом на собесе сходу заявили, что я в девопс не умею, поэтому не пошел-ка бы лесом.
technic93
Чтобы перегонять SQL в json и в университет ходить не надо было.
springme
А вы каждый день ПО для лунных миссий пишите?
Для документации, тестов и общения с заказчиком тоже в университет ходить не надо, но это занимает бОльшую часть времени любого программиста.
masai
Ого, аж три минуса! Надеюсь, это из-за опечатки с -ться.
Я смотрю, аргументы такие:
Это всё хорошо в теории. Но посмотрите на первый пост в этой ветке. Вот экспериментальный факт — люди, претендующие на должность senior, не справляются с элементарной задачей.
Я ещё раз повторю, важно знать, какие именно задачи будет решать человек. Ответьте для себя на вопрос, вы бы взяли такого кандидата, чтобы он, скажем, решал задачи обработки изображений на микроконтроллерах? Понятно, что веб-разработчику такую задачу давать бессмысленно.
Если же кандидат быстро решил задачу, то можно побеседовать с ним дальше — как оптимизировать код с точки зрения какого-то из критериев.
Например, как избежать копирования всех данных в матрице? А как оптимизировать последовательный обход? А как оптимизировать поворот, если матрица хранится на диске в каком-то хитром формате и в память не влезает? А что если нужно поворачивать квадратные участки большой матрицы? Тут масса поводов поговорить на не такие уж и простые темы.
Можно, конечно сразу вести разговор не требуя что-то запрограммировать. Но дьявол кроется в деталях. Я видел людей, которые абстрактно, на словах знают, как решать задачи (часто встречающиеся реальные, не оторванные от жизни). Например: «Тут нужно применить такую-то структуру и такой-то алгоритм». Но как эту структуру реализовать или какую библиотеку использовать, они уже не знают. Почему бы не взять человека, который знает и не будет тратить время на гугление, а не того, который не знает? Или если senior, то уметь программировать не нужно?
Если не нужно, то да, ОК, можно задачи на программирование и не давать, а просто поговорить.
По поводу последнего аргумента о том, что программист большую часть времени тратит вовсе не на задачки. Не забывайте, что программисты разные. Да, не все каждый день пишут ПО для лунных миссий, обработку изображений, числодробилки. Но есть люди, которые этим действительно занимаются каждый день.
Собственно, весь мой пост — это выражение удивления, что люди сходу говорят, что так собеседовать нельзя, такие задачи не подходят, но никто не спросил, а на какие задачи кандидата собеседуют, и все почему-то неявно считают, что собеседование было одно и состояло только из одной простой задачи.
Denis631
а что это за senior что не может решить задачки джуна?
adictive_max
Denis631
ну как минимум сравнение не уместное, так как джун, это будущий сениор, когда медсестра это будущая старшая медсестра (а не врач).
Тогда переформулируем в:
Да и вообще, задачу, которую тут обсуждают, ничего общего со «свежими» знаниями из университета не имеет.
Есть 2d массив, нужно свапануть элементы. И все.
Вас никто не спрашивает написать AVL или Red-Black Tree.
Спрашивают азы, базу.
masai
> «Дана матрица. Нужно повернуть числа в ней по часовой\против часовой стрелке. Предложите структуру(ы) для ее хранения, передачи и решения задачи».
Многое зависит от контекста задачи.
Навскидку, что приходит в голову:
1) Если матрица всегда маленькая и скорость некритична, то просто создаём новую и заполняем как надо. Или делаем перестановки прямо на месте.
2) Если матрица очень большая и копировать данные не хочется — храним данные построчно и делаем 4 индексатора для каждого из углов поворота.
Пусть данные хранятся в массиве
A. Храним поля: номер последней строки —r, число столбцов —c, номер последнего элемента –N = (r + 1) * c - 1. Пусть запрашивается элемент(i, j). (Имена полей, разумеется, в реальном коде надо сделать человекочитаемыми.)0° –
A[c * i + j],90° –
A[c * (r - j) + i],180° –
A[N - (c * i + j)],270° –
A[N - (c * (r - j) + i)].При каждом повороте записываем адрес нужного индексатора, который и будем вызывать при запросе элемента.
3) Если часто выполняется последовательный проход, в прошлом варианте могут быть проблемы с непопаданием в кэш, если обходим по строкам повёрнутую на 90° матрицу. Тут тоже есть разные варианты решения. Можно хранить два варианта матрицы — по строкам и столбцам. Или можно в фоновом потоке выполнять поворот, пока нет обращений к матрице.
4) Матрица может быть разреженной и т. д. Короче, тут можно до бесконечности усложнять.
По поводу передачи матрицы — отдельный разговор.
DocJester
Прошу прощения, вопрос дилетанта.
«Повернуть» — это элемент a[0][0] в a[0][n-1] перевести?
vassabi
давайте я «на пальцах» —
дано: есть матрица 3х3:
1 2 3
4 5 6
7 8 9
надо: чтобы в stdout она была выведена
1) по часовой стрелке:
7 4 1
8 5 2
9 6 3
2) против часовой стрелки:
3 6 9
2 5 8
1 4 7
индексы, размеры матрицы и её прямоугольность, способ хранения, алгоритм и тд и пр — все на ваше усмотрение.
Всё является предметом обсуждения, потому что мне лично было все интересно, даже с какого места начиналась работа мысли — написать на бумажке формулу, или нарисовать на бумажке диаграмму, или написать сначала пустую обертку в коде (а потом думать над алгоритмом), или ничего не писать а задавать уточняющие вопросы.
Мой самый любимый момент на собеседованиях — это момент «ага!», когда голова у человека включается и он задумывается над проблемой. (ну или нет — и тогда извините)
AndreyGaskov
В качестве шутки:
Yavanosta
Задача как мне кажется довольно простая, при этом очень муторная. В ней много корнер кейсов которые надо дополнительно обрабатывать (например не специфицирована операция «поворота по часовой стрелке» матрицы 1xN или Nx1 которая обязательно появится для неквадратной матрицы). Никакой специфичной структуры данных для такой задачи не могу придумать, кажется достаточно определить функцию трансформации координат что-то вроде
transformXY(sizeX, sizeY, x, y) -> {x, y}(псевдокод) а затем обойти матрицу «по слоям» от краев к центру, свапая элементы. Так мы получимО(1)по памяти иО(NxM)по времени что кажется является теоретическим пределом (нельзя потратить памяти меньше константной, нельзя провернуть матрицу не потрогав каждый её элемент).Но на пути к рабочему решению лежит бесчисленное множество граблей, минус единиц, и прочих
<\<=требующих сильной концентрации и внимательности.Мне кажется что это не очень хорошая задача для собеседования, потому что по ней не очень много можно понять о кандидате. Как уже говорили выше, её может решить студент первокурсник, а может накосячить опытный разработчик.
a-l-e-x
В Google мне конечно не попасть, но, при чтении статьи, меня не покидала мысль, что я бы стал всё это делать на SQL, а при необходимости отладки, тестов, и демонстрации результатов — использовал бы BigQuery.
transcengopher
Думаю, SQL — это жульничество, ведь там, по факту, реализацией алгоритма занимается демон-оптимизатор базы данных. Хотя это действительно отличный способ решить такую проблему.
Правда, про disjoint set индексы в базах я пока что не слышал. Может, просто плохо слушал.
BugM
Я наверно что-то не понял, но зачем так сложно? Нечто вроде баскет сорта великолепно сработает.
Заводим лист с номерами корзин и мапу с самими корзинами.
HashMap<String, Integer> baskets;
List basketNumbers;
Первую пару кладем в нулевую.
Далее для каждой пары: Если любое слово из пары найдено в любой корзине, второе добавляем в туже. Если ничего не найдено заводим новую с новым номером. Если найдены в разных, то ставим им одинаковый номер.
Далее тривиально ищем номера корзин для всех отличающихся слов в строках для поиска.
Сложность O(m+n)
m количество пар
n количество слов в минимальной строке для поиска
datacompboy
Указатель на рут и есть по сути баскет номер. Разница в сложности есть (худший случай когда добавление каждого следующего слова меняет номер корзины для половины имеющихся слов, например) но да, это тоже отличный вариант!
BugM
Пока ехал и сам понял что одно и то же по сути.
И слияние без перебора никак не придумывается. Точнее придумывается, но деревья появляются и вообще одинаково со статьей получается.
samsdemon
Вот интересно, а есть ли инженерные позиции в гугл-фэйсбук-***, где не нужны такие знания?
Условный сетап — я умею в деревья, но никогда в жизни не делал дп, красно-чёрное дерево было два раза на лабе. 40% рабочего времени — это формочки, 20% — что-то задеплоить (вебпак-докер-ci/cd) и ещё 40 — разное от интервью до талент менеджерства. Есть шансы, или пора открывать книжки с алгоритмами?)
*Просто каждый пост с собесами про гугл имеет слова, похожие на `обратная функция Аккермана` — там просто люди есть?)
Zuy
В Apple и Tesla точно есть обычные люди и есть позиции куда не спрашивают алгоритмов сложнее стеков и очередей. Во всяком случае в embedded разработке это так.
datacompboy
я точно не помню чтоб про офА писал :))
деревья — но не списки, не рекурсия, не матрицы? вот такая узкая специализация?
или просто другие ветки не прокачаны, но общие сведения есть?
в последнем случае тот же leetcode на 3-4 недели по 2 часа вечером = всё вспомнено и готов к собесу…
samsdemon
В вашей статье нет, в самом деле :) И да, общие сведения, разумеется.
Просто судите сами, я сделал запрос на хабре про собеседования в гугл — второй, пятый, шестой результаты — везде алгоритмы.
Мой вопрос скорее даже не про интервью, а про как там работать. Можно за два месяца накачаться в алгоритмах, пройти интервью, даже проскочив на шару с какой-то задачей, которую решал до этого — а дальше-то что? Какой скилл реально нужен для работы?
tyomitch
Насколько я понимаю, особенность Гугла в том, что «просто людей» им нанимать нет смысла — и так на каждое место у них претендует 100500 «ракетных учёных», и они могут себе позволить выбирать среди них. Так что и формочками и деплоем у них тоже занимаются «ракетные учёные».
romangoward
Даже если это — их подсознательное желание, оно не соответствует действительности.
Рынок говорит нам о том, что соотношение спрос/предложение на инженера с опытом 10+ лет улетает в комос по экспоненте. И имеется тенденция увеличение стартовой скорости ;-)
Вот Facebook даёт з/п в 1.5 раза больше в кэше, Microsoft лоббирует возможность завозить разрабов из стран третьего мира пачками, кто-то открывает офисы разработки не в it-долинах, и отвоёвывет локальные рынки труда. Все пытаются доставить своих космонавтов на орбиту по-разному.
Касательно же самого Google… по моим личным наблюдениям, у них явно прослеживаются циклы закручивания и откручивания гаек при найме.
Но компании с некоторой задержкой понимают, что нельзя нанимать интернов пачками на работу, иначе они через 3-4 года сгорят и всем отрядом уедут на острова пить ром. (нет, ну круто же в 25 лет быть миллионером?), и что если не нанять толкового человека, который a little bit below the line, то потеря времени просто чудовищная, и значительно лучше дообучить сотрудника в контексте компании, потому что так или иначе, но синдром самозванца начинает жрать всех, кому за ..
Короче, посомтрите замечательный доклад Growing the Site Reliability Team at LinkedIn: Hiring is Hard
PS. Почему-то большинство людей думает, что в %big_company_name% всё сложно-сложно и ничерта не понятно. Но это же не так, потому что сложные системы сложно деббажить и разрабатывать, а на сотнях и тысячах банок — это вообще ад и погибель, поэтому системы состоят из более мелких и максимально тупых подсистем. Об этом говорят на каждой конфе.
tyomitch
Я про конкуренцию Гугла не с Фейсбуком и Амазоном, а с «сайтостроительными артелями» из дюжины-двух человек. «Простые люди», занимающиеся формочками и деплоем, нужны и там и там, но техногигантам нет смысла их нанимать, потому что могут на их место нанять «непростых».
romangoward
Я вам ровно об этом и писал: не может нанять, потому что нельзя из /dev/urandom сгенерировать инженера.
Кроме того, любой техногигант — это в первую очередь множество legacy, которое надо поддерживать. Об это разбилась ни одна сотня, а может и тысячи инженеров, которые приходили двигать индустрию вперёд, но бизнес говорил им делать другое :-P
dididididi
Еще одна задачка, угадай что я думаю. Итого дано две пары синонимов. ('rate', 'ratings'),
('approval', 'popularity') И первое что я должен спросить у собеседующего:«Есть ли у слова еще синонимы? » Вопрос такой с подвохом: Типа у Маши и Кати 6 яблок они поделили поровну, сколько у них яблок? А вот нет, они в процессе дележки три потеряли и и два Витя отнял!
Второй про транзитивность, это тоже умно с учетом, что у нас два слова и нет третьего, я должен спросить, а не транзитивны ли они? ДА какая мне разница, если всего два слова?
О порядке слов я тоже почему-то должен спросить, хотя по моему это очевидно что рейтинг популярности и популярность рейтинга — это немного разные вещи.
В итоге все сводится к тому, что решая задачу про дележку яблок между Катей и Таней, я должен спросить, а точно ли это яблоки, мож еще груши были и равны ли груши яблокам, был ли Витя и с кем он дружит, и не имеет ли яблоки способности спонтанно делиться на две груши или нет.
datacompboy
Да, почему-то в реальной жизни приходится задачу доопределять и вообще понять о чем идёт речь. Требовать точного ТЗ и 100% определения можно только кодерам на галере. Даже в универе ответ чаще всего будет «а вы подумайте.»
FINTER
У меня вот обратная проблема, я наоборот слишком усложняю решения задач там, где можно оператору написать в инструкции «вот в этом случае не нажимать». Все зависит от размера компании и бюджета.
Например, вместо пандусов и лифтов в пешеходных переходах можно инвалидам за счет города выделить бесплатное такси за счет муниципалитета. Возможно это в разы дешевле, хотя инженерно пандусы и лифты выглядят куда круче. (Я кстати не утверждаю, что так будет правильно, я не урбанист и не архитектор, я лишь привел другой вариант, который может оказаться в определенных условиях лучше, и я думаю, что именно это делает меня инженером, а не знание алгоритмов и стеков технологий)
Мастер не тот, кто все знает, а тот — кто знает то, чего он не знает. Имхо если на собеседовании спрашивать «что бы вы хотели изучить, и что даже трогать не станете по крайней мере сейчас», то можно куда полнее картину о кандидате построить.
dididididi
Не спорю. Если б данный товарищ, сказал вот вопросик к нему можно задать кучу дополнительных вопросиков и потрындеть с кандидатом за жизнь в процессе чего выяснится его уровень знаний, то да.
Но автор сказал, что вот есть список «правильных» вопросов для хорошего кандидата, которые он обязан задать. Правильные они только в его мозгу. Банально:
if len(q1) != len(q2):
output.append(False)
C чего бы это? «рейтинг популярности Обамы» и «рейтинг популярности Барака Обама» и «популярность Обамы» не могут быть синонимами? Автор ни слова не сказал, про это оно как будто так и должно написал этот код. То есть у него, например, по умолчанию, количество слов является мерилом синонимичности фраз, а у меня по умолчанию например транзитивность синонимов, и будем справедливым, я логичней в этом вопросе.
По этому я и говорю задача на «угадай мыслю», что собеседующий считает важным, а что не очень, притом, что он может быть неправ.
n43jl
В реальной жизни, задачи — это "угадай мыслю", что заказчик считает важным, а что не очень, притом, что он может быть неправ. По-моему уточнение требований, и понятие видения задачи постановщиком на собеседовании — это очень приближенный к реальности скилл.
tamapw
Казалось бы, да, всё верно.
Однако, на собеседовании нас собеседуют обычно разработчики, лиды, старшие разработчики и прочие, казалось бы, разумные личности.
Поэтому, если за заказчиком нужно изначально додумывать, дорасспрашивать, доставать с целью вынуть нужную информацию — то при общении с разработчиками и получении от них задач мы невольно считаем их полными и точными, если не сказано обратного. Ведь, не будете же вы давать своему коллеге таск из разряда «есть такая фигня, почини», верно?) Вы изложите детально все ньюансы и проблемы. Скорее всего даже с вариантами решения.
И на собеседовании невольно может сработать та же аналогия и человек может даже не подумать спросить вопрос, который он задал бы в другое время, просто из-за того, что считает человека, сидящего перед ним, разумным человеком.
datacompboy
Ох, сколько я в своей жизни пронаблюдал багов вида «есть фигня, разберитесь»…
И от тестеров приходят только симптомы.
От клиентов приходит вообще «шеф, всё пропало».
У лидов обычно не хватает времени всё разжевать.
Чем больше может человек додумать / выяснить / найти сам — тем ценнее работник.
datacompboy
А вы задаёте правильные вопросы. Это и требуется на собеседовании — думать.
И да, продовить черту когда еще надо докапываться, а когда уже пора лабать код.
Список правильных вопросов он всегда есть в подсознании, но оцениваются те вопросы, которые задают кандидаты. И таки да — многие очень креативны, и я лично когда встречаю вопрос которые задают 1 из 20 всегда очень радуюсь. Это всегда хороший знак, особенно если потом закрепляется впечатление более-менее корректным кодом.
Politura
Неужели за все то время, что он собеседовал этой задачкой, никто на этом этапе так и не сказал, что можно обойтись все тем-же словарем и для 50 синонимов иметь 49 ключей с одинаковым значением — первый синоним?
типа, есть словарь
fast — quick
rapid — quick
для добавления fast — speedy достаточно добавить в словарь еще один ключ:
speedy — quick
упд:
Но ведь в моем варианте можно сделать то-же самое за два запроса к словарю со сложостью O(1), или я дурак и где-то ошибаюсь?
Politura
Ой, действительно я дурак, что не дочитал до конца, а побежал комментировать, там в итоге к тому-же самому и пришли.
mk2
Не совсем к тому же. У вас запрос O(1), у них запрос O(a(1)). С другой стороны, у них одна пара синонимов обрабатывается за те же О(1), а у вас как бы не О(n) будет. Так что такую структуру, как у вас — придется долго строить.
Politura
Хм, действительно, реализации все-таки разные, там приходят к ссылкам на один общий синоним во время поиска синонимов, из-за чего повышается сложность этого шага, а я предлагаю сразу писать в словарь ссылки на общий синоним.
Почему? Если посмотреть предложенную реализацию класса DisjointSet, там в итоге используется все тот-же словарь но самая долгая операция это поиск корня get_root(), которая, кроме всего прочего, приводит одинаковые синонимы к одному значению (и поэтому имеет цикл), и этот метот вызывается дважды как во время добавления пары синонимов, так и во время поиска синонимов.
Я думаю, что гораздо более эффективно сразу на этапе добавления слов в словарь писать в него нужные значения: увеличивается скорость добавления пар синонимов, скорость поиска синонимов, кроме того ключами в словаре у нас будут не все возможные слова, а на одно слово, коренной синоним, меньше для каждой группы синонимов. То есть, если синонимов только два, то будет одна запись, когда один синоним это ключ, а второй синоним это значение; если синонимов три, то будет две записи, первый синоним ключ, второй значение, плюс еще одна запись где ключ третий синоним, а значение — второй; и тд.
Этого можно достичь добавив дополнительный HashSet (уж не знаю какой его аналог в Питоне), в котором будут храниться синонимы — значения словаря.
Будет что-то вроде этого (прошу прощения за любые ошибки, ибо я не питоновец и написал просто по-аналогии с кодом из статьи):
Операция чтения словаря/hashSet — O(1), добавления значения — либо O(1), либо O(n) если вдруг нам понадобилось увеличить емкость.
В моем случае для каждой пары синонимов добавляется либо одна запись в parents, либо две записи: одна в parents и одна в root_values. В реализации из статьи записи будут добавляться в один единственный словарь, из-за чего n того словаря будет больше, а значит и емкость словаря придется увеличивать чаще, и сложность O(n) этой операции будет расти быстрее. Это не говоря уже о возможности нарваться на цикл при каждом добавлении синонима.
Для проверки синонимов мне в худшем случае надо прочитать два раза из словаря, в реализации из статьи в худшем случае можно нарваться на цикл и свертку.
mk2
В питоне я тоже не особо, так что не беспокойтесь.
Во-первых, ваша реализация работает некорректно. Проверим на парах (1, 2), (3, 4), (2,4). После добавления всех трёх у вас parents = {{1, 2}, {3, 4}, {4, 2}}, и root_values = {2, 4}. are_synonymous(1, 3) выдаёт false, хотя должен true. Сами догадаетесь, что не так?
Во-вторых, в настоящем DisjointSet, примерно как в статье, время одной операции действительно может быть большим — как из-за увеличения словаря (хотя его обычно заполняют сразу, parent[w] = w]), так и из-за длинного цикла (не больше O(logn)). Но при этом в среднем запрос выполняется за константу — точно так же, как хотя иногда добавление в массив выполняется за О(n), в среднем оно выполняется за O(1).
Politura
Да, действительно, такой случай я не учел, спасибо!
Чтобы его покрыть, в моей реализации необходимо делать root_values словарем, где в качестве значения держать список синонимов и в случае когда пришла пара у которой оба слова уже есть в root_values — приводить ветки к одному значению. Такая реализация уже будет проигрывать по памяти реализации из статьи и вероятно проигрывать по скорости добавления синонимов. Скорость are_synonymous все равно будет быстрее, из-за не слишком удачной реализации в статье get_root, хотя если get_root переделать, то скорость извлечения будет одинаковой.
mk2
Знаете, это у вас заплатки получаются какие-то, причем даже не в том месте. Ваша реализация всё ещё работает некорректно. Пример — пары (1, 2), (3, 4), (1, 3),. Получается parents = {{1,2},{3,1}}, и проверим are_synonymous(2, 4) — выдаёт false. Да даже are_synonymous(3, 4) теперь выдаст false, хотя у нас есть прямо такая пара.
Politura
Я-же не привел никакую реализацию, только описание, а вы даже по нему нашли ошибки, снимаю шляпу :)
Я так не умею, пришлось-таки проверять в Питоне.
Вот такой вариант add_synonyms работает без ошибок. Ну, как минимум, покрывает ваш случай и то, что я смог придумать:
datacompboy
А теперь прикиньте сложность полученного кода…
Алгоритмическую — кодовую сложность я уже вижу.
Такую плотность минного поля для опечаток w1/w2 можно только в рамочку :)
hard_sign
Очень странный подход — писать код со структурами данных в памяти. Очевидно ведь, что ответ на вопрос, явдяются ли два слова синонимами, не задаётся офицеру поисковой службы, а вычисляется на основе заранее составленного словаря. Соответственно, поиск должен проходить в два шага: приведение запроса к «каноническому» виду по словарю и поиск «канонических» ключевых слов. То есть код достаточно простой, а вот структуры данных — не такие простые.
funca
while self.parents[w] != w: words_traversed.append(w) w = self.parents[w]Только мне кажется, что нижний вариант на питоне выглядит как бред? Или у гугла какой то свой особенный интерпретатор для задач на собеседованиях?
Lunmijo
Когда я проходил собеседование в одну аутсорсинговую контору на должность Trainee/Junior (выше не претендовал) Angular Developer, меня тоже поспрашивали теории, потом перешли к практике.
Дали несложную задачку на элементарное умение находить оптимальное решение (уровень Easy LeetCode думаю, т.к. и должность не столь высокая, и фронт-энд разработчику не так остро нужны алгоритмы как другим), но так как я очень разнервинался (первое собеседование в жизни!), с фразой «Не будем привязываться к языку» накатал решение на доске на суржике из Python, псевдокода и JS.
Потому что компилировать код в голове, предвидеть ошибки на тот момент я ещё не умел, анализировать задачу я ещё не умел.
В общем задачки были очень простые, но тоже, со своеобразным подвохом, нужно было подумать.
Это я к чему веду? Я не считаю нужным при решении задач на белой доске привязываться к конкретной технологии/языку. Мы все пользуемся IDE, которая решает большое количество рутинных задач за нас, наша задача остаётся — думать и анализировать возможное решение поставленной задачи.
Кроме SQL конечно, ИМХО, SQL это такой язык, который нужно в голове уметь «запускать», он слишком простой, чтобы не уметь этого делать.
Уровень понимания языка — открывайте GitHub интервьируемого. Теорию можно заучить. А вот умение анализировать и думать в решении задачек подделать крайне сложно, как мне кажется. Разве что если человек перерешает все задачи, которые есть хотя бы с LeetCode. И то к тому моменту он уже сможет выделить общие паттерны решений и решать любые подобные задачи без проблем.
ИМХО, проверку на знание языка на собеседовании есть смысл только в IDE давать, потому что на работе-то всё равно все пользуются IDE'шками.
tendium
Плюсуюсь к вопросу @samsdemon. Я вот тоже типа там и техлид, и тимлид (небольшая команда у нас). Но в нашей работе алгоритмирование нужно на весьма простом уровне, ибо интернет-магазин. Если же нам все-таки нужно будет использовать какой-то сложный алгоритм, то за изобретение велосипеда никто не заплатит, ибо в большинстве случаев есть реализации и они в общем случае лучше, чем был бы наш собственный велосипед. Там больше других сложностей — миграция данных между системами, интеграция различных API (в основном для маркетинга, но и не только), продумывание архитектуры микросервисов (границы, взаимодействие, мониторинг, авторизация/аутентификация, и т.п.). И всё это требует определенного опыта и понимания проблемы. Но всё это, как я понимаю, абсолютно иррелевантно для всяких там MS, Google и подобных им. И у меня, в связи с этим, вопрос, неужели вот прям в каждодневной работе программисты данных корпораций пишут всякие вот такие вещи интересные? Или на самом деле собеседование — ширма, а за ней жесткие рамки и минимум креатива? Как оно по ту сторону собеседования, отражает ли оно вашу каждодневную работу?
vassabi
у меня коллега вообще сторонник теории, что чем изощреннее собеседование — тем попсовее потом будет работа. Он рассказывал истории из своей карьеры, как его собеседовали на кеши процессоров, а потом посадили .bat файлы писать для внутренней самописной билдсистемы.
datacompboy
Для меня лично: каждодневную — нет. Регулярно сталкиваюсь? Да.
Ну то есть доопределять задачи (а то и вообще ставить их самому по запаху) — ежедневная по сути работа.
Писать нетривиальные алгоритмы — раз в месяц или реже.
Читать и понимать натривиальные алгоритмы — раз в месяц или чаще.
Искать баги в нетривиальных местах — раз в месяц или чаще.
Находить баги в нетривиальных местах — раз или два в квартал.
tendium
Более или менее это бывает и в моей сфере… Но дело в том, что если что-то делаешь один раз, то лично у меня это так — сделал и забыл. То есть если через месяц меня спросят о деталях, то так вот навскидку и не вспомню — ибо уже нахожусь в другом контексте.
Вот, например, я поднимал для внутренних целей (не для продакшна) K8s кластер. Разобрался, сделал, забыл. Сейчас понимаю только в общих чертах. А ведь кто-то может уцепиться за строчку в CV, и начать долбать по тонкостям тюнинга K8s, а я это делал всего один раз в жизни — естественно, что на многие вопросы сходу не отвечу. Со стороны человека, который этим занимается, возможно, каждый день, конечно же это будет выглядеть несоответствием слов и дела.
И вот мне видится, что на собеседованиях надо давать задания близкие если не по теме, то по духу к тому, что будет каждодневной работой. А то, что нужно делать раз в месяц или реже, может быть лишь бонусной задачей, возможно, при приёме влияющей лишь на размер начальной компенсации. ИМХО, конечно.
datacompboy
Есть вещи общие (прочел доку — сделал), есть вещи тонкие, когда понимание как устроено меняет с «долбал год» на «сделал за неделю».
Строчка в резюме… Может не добавлять туда такие вещи не в раздел «знаю» а в раздел «сталкивался»? Просто чтоб ставить соответствующие ожидания.
Я считаю что если человек сталкивался, решил, и забыл — это нормально.
Если он каждый день с ними и так и не понял (как выше про SQL и DBA с «огромным» опытом) — это уже звоночек…
technic93
Сначала на интервью все такое оптимизированное а потом гмаил по пол часа открывается. Как так?
technic93
Сначала на интервью все такое оптимизированное а потом гмаил по пол часа открывается. Как так?
technic93
Мобильная версия хабра. Извините.
NoRegrets
onborodin
>Калибр инженера во многом определяется тем, насколько глубоко он может понять проблему.
Да, спасибо, я понял. Проблема в генном коде экзаменатора.
PS
Шутка =)
caveeagle
Один я при прочтении задачи подумал, что решал бы её с другого конца?
Я бы не воодил список синонимов (так как живой язык — дело сложное, и синонимы в списки никак не укладываются). Я бы решал от того, что выбирает пользователь при запросе.
То есть, первым пользователям показываем поисковую выдачу по текущему простомы алгоритму. Смотрим, что из этой выдачи он выбирает. Если при разных запросах выбираются одинаковые ссылки — значит, запросы синонимичные. С поправками, коррекциями и расстояниями Левенштейна.
gks
Мне кажется, что для серьезной позиции и задачи поиска синонимов нужно какой-то кардинально другой подход к базовому алгоритму. Так как в реальности задача будет постоянно усложняться. И бог его знает как. Добавить ML алгоритмы. Учесть ошибки ввода и т.д. И в результате будет во первых сплошной if… else. Во вторых код будут писать скорее всего разные разработчики, и возможно одновременно. То есть будет постоянная конкуренция за файл с основным циклом. Третье, возможно при большом словаре нужно буде делать горизонтальное масштабирование. Четвертое, задача добавления данных в словари — это задача отличная от задачи поиска. Ее не должно быть в теле основного алгоритма. Так как словарь формируется отдельно.
И это все на мой взгляд более важно и критично, чем сам алгоритм в реальных задачах. То есть умение абстрагироваться от реализации и умение учитывать возможность масштабирования задачи, более важное умения для опытного программиста работающего в большом коллективе и разрабатывающие сложные системы с большими данными. Даже если линейная сложность, и все делать так, как спрашивают, при миллионных записей, рано или поздно на одном ядре все будет тормозить.
ivan2kh
Проблема с задачами такого рода, что всегда человек может предложить сложное решение. Это очевидно: сложная задача с разными вариантами решения, значит можно накрутить пару-тройку оптимизацирующих алгоритмов. И не дай бог вставить сюда метод, который интервьюер не знает. Это крайне негативно скажется на результате собеседования.
vassabi
интервьюера «забанили в гугле»?
mk2
Забавное. Заметил, что DisjointSet в статье на самом деле написан неправильно.
В этой структуре есть две эвристики — сжатие путей и подвешивание по рангу/весу. Первая — что при поиске корня мы записываем корень в предки всех, по кому прошли — в коде есть. А вторая — что мы выбираем, какой корень записать в parent другому при слиянии по рангу, или по весу множеств, или хотя бы случайно(это тоже работает, хотя сложнее доказывается) — отсутствует. То есть среднее время на операцию в написанной в статье структуре — O(logn), а вовсе не O(a(n)).
datacompboy
Я всегда в таких статьях жду когда же уже кто-нибудь прочитает код из статьи :D