
Линтеры помогают приводить код к единому стилю и избегать ошибок. Правда, только в том случае, если вы готовы к страданиям, а не отмахиваетесь в конце концов «pylint: disable», только чтобы оно отстало. Какой должен быть линтер, и почему таки не обойтись Pylint, знает Никита Соболев (sobolevn), который понимает и любит линтеры настолько, что даже свою компанию назвал так, чтобы их не расстраивать — wemake.services.
Ниже текстовая версия доклада на Moscow Python Conf++ про линтеры, как их делать правильно и как не нужно. В выступлении было много интерактива, онлайна и общения с аудиторией. Спикер по ходу дела проводил опросы и старался переубедить слушателей: смотрел на тренд, и как в дебатах, пытался выровнять соотношение и поменять общественное мнение. Какая-то часть с опросами попала в расшифровку, но не вся, поэтому для полноты картины прилагается видео.
Зачем нам линтеры?
Самая важная задача линтеров — приводить код к единообразию. Есть много вариантов написать одно и то же на Python: поставить запятую здесь или там, забыть закрыть скобки или не забыть. Когда люди долго пишут код, он становится похож на лоскутное одеяло из сшитых в разное время разрозненных кусков. Работать с таким одеялом неприятно, он отбивает желание читать код, а это очень плохо.
Линтеры облегчают жизнь на ревью. Я прихожу на код-ревью и думаю: «Я не хочу это делать! Сейчас будут лишние пробелы и прочая ерунда!» Хочется, чтобы кто-то другой подготовил хороший код, а после этого я оценю большие концептуальные вещи.
Иногда я смотрю на код и думаю, что вроде всё нормально, а потом вижу в какой-то функции слишком много переменных или ошибку, на которую я не обратил внимание. Автоматика нашла бы эту ошибку, а я просмотрел. Чтобы не попадать в такие ситуации — я использую линтер — он находит все, что скрыто и трудно найти.
Какие бывают линтеры?
Самые простые проверяют только стиль, например, Flake8. В какой-то степени ещё и Black, но скорее это автоформатор-линтер. Линтеры сложнее проверяют семантику, а не только стилистику: что вы делаете, зачем, и бьют вас по рукам, если пишете с ошибками. Хороший пример — Pylint, который мы все знаем, пользуемся и любим. Я называю такие линтеры — Best practices. Третий тип — Type checking, эти линтеры немного в стороне. Type checking в Python — новинка, её сейчас делают две конкурирующие платформы: Mypy и Pyre.
Как применять линтеры?
Я не утверждаю, что линтеры — это панацея и замена всему. Это не так. Линтеры — первая ступенька пирамиды, по которой код попадает в продакшен.
Ступеней в пирамиде три:
- Запускаете линтеры. Это очень быстро и не нужно ничего, кроме исходного кода — ни инфраструктуры, ни настроек. Проверяете: первый sanity check прошел — все хорошо, работаем дальше.
- Стадия тестов. Этот процесс сложнее и дольше из-за ошибок, не связанных с кодом. Нам уже потребуется правильный и полный сетап всего приложения.
- Этап ревью.
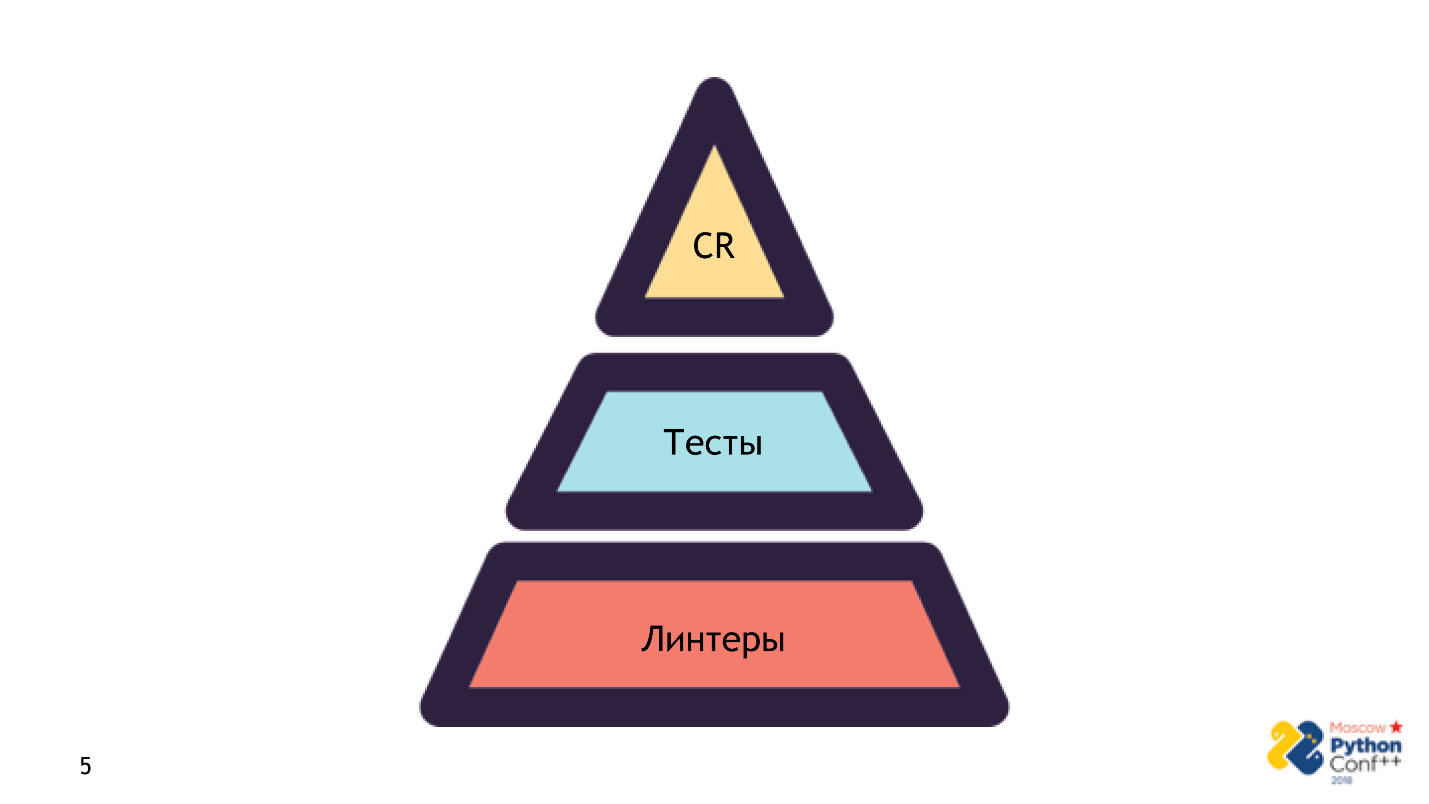
Это необходимые шаги, чтобы код попал в продакшен. Если вы не прошли одну ступень, что-то забыли или ревьюер, сказал, что так не пойдёт, вы увидите надпись: failed — плохой код в продакшен не попадает.
Используете ли вы на работе линтер?
Если спросить разработчиков из сурового enterprise, в котором трудятся по 7 дней в неделю, применяют ли они линтер, то выяснится, что хотя бы треть из них используют линтеры очень строго: CI падает, проверки суровы. Остальные примерно в равной степени применяют линтеры только для проверки стиля, никогда и как отчётную систему: запускают линтер, генерируют отчет и смотрят, насколько всё плохо. Линтеры используются, и это хорошо. В нашей компании всё построено очень сурово: жёсткий линтинг, очень много проверок, двойной код-ревью.
Код-ревью
Проблемы возникают как раз на этом этапе. Это верхняя и самая сложная ступень пирамиды: код-ревью автоматизировать не получится, а если и возможно, то это приведёт к автоматизации написания кода. Тогда и программисты станут не нужны.
Стандартно процесс выглядит так: код приходит на ревью, я нахожу ошибки, и не хочу больше их допускать. Например, я увидел, что разработчик поймал BaseException: «Не надо так. Пожалуйста, не лови!». Спустя 10 дней то же самое. Ещё раз напоминаю:
— BaseException мы не ловим.
— Хорошо, я понял.
Проходит год — та же самая ошибка. Приходит новый человек — та же самая ошибка. Я думаю — как же всё автоматизировать, чтобы ситуация не повторялась, и на ум приходит только: «Давайте запилим свой линтер?» Создадим открытый пакет, поместим туда все правила, которые используем в работе и автоматизируем проверку правил, чтобы каждый раз на код-ревью не писать руками. Автоматизируем всё хорошо и сразу!
Естественно, вы можете сказать: «Готовые линтеры уже есть они работают, все ими пользуются — зачем делать своё?», и будете совершенно правы, потому что линтеры действительно есть. Посмотрим, какие именно и что они делают.
Pylint
В эфире рубрика «Почему не Pylint?» Этот вопрос я слышал много раз. Отвечу на него помягче. Pylint — прекрасный инструмент, рок-звезда для кода на Python, но у него есть особенности, которые я не хочу видеть в своём линтере.
Он смешивает всё воедино: стилистические проверки, проверки Best practices и Type checking. В Pylint Type checking недоразвит, потому что нет информации о типах: он пытается как-то её вывести, но получается не очень. Поэтому часто, когда на Django я пишу
model_name.some_property, то могу увидеть ошибку: «Извини, такого свойства нет — ты не можешь это использовать!» Вспоминаю, что есть плагин, ставлю, потом использую Celery, с ним тоже начинается какая-то беда, ставлю плагин для Celery, применяю ещё какую-нибудь магическую библиотеку, и в итоге везде просто пишу: «pylint: disable»… Это не то, что я хочу получить от линтера.Ещё одна особенность, скрытая от пользователя — у Pylint собственная реализация Abstract syntax tree в Python. Это то, как выглядит код, когда вы его распарсили и получили информацию о дереве узлов, из которых состоит код. Я не очень доверяю собственным реализациям, потому что они всегда ошибаются.
Кроме Pylint есть и другие линтеры, которые тоже выполняют свою работу.
SonarQube
Прекрасный, но отдельный инструмент, который живёт где-то рядом с вашим проектом.
- SonarQube не получится часто запускать: его нужно куда-то задеплоить, смотреть, мониторить, настраивать.
- Он написан на Java. Если захотите поправить свой линтер для Python, то будете писать код на Java. Я считаю, что концептуально это неправильно — разработчик, который умеет писать на Python, должен уметь написать код для проверки Python.
Компания, которая занимается развитием SonarQube, специфически смотрит на концепцию развития продукта. Это может быть проблемой.
Достоинство SonarQube в том, что у него очень крутые проверки, которые показывают сложность, возможные скрытые ошибки и баги. Проверки мне нравятся, я бы их оставил, а платформу — поменял.
Flake8
Замечательный линтер — очень простой, но с одной проблемой: мало правил, с помощью которых он проверяет, насколько код хорошо написан. При этом у Flake8 есть очень много очень простых плагинов: минимальный плагин — это 2 метода, которые нужно реализовать. Я подумал — давайте возьмём Flake8 как основу и напишем плагины, но со своим пониманием пользы для компании. И мы так и сделали.
Самый строгий линтер в мире
Мы сделали инструмент, в котором собрали всё, что считаем правильным для Python и назвали wemake-python-styleguide. Плагин выложили публично, так как я считаю, что Open Source by Default — это хорошая практика. Я глубоко убежден, что многие инструменты выиграют, если их выложат в Open Source. Для нашего инструмента мы придумали слоган: «Самый строгий линтер в мире!»
Ключевое слово в нашем линтере — строгий, что значит боль и страдания.
Если вы пользуетесь линтером, и он не заставляет вас страдать так, что хватаешься за голову: «Да что же тебе ещё не нравится, будь ты проклят», то это плохой линтер. Он пропускает ошибки, недостаточно следит за качеством кода, и нам не нужен. Нам нужен самый строгий в мире, который многое проверяет. Сейчас у нас порядка 250 разных проверок в обоих категориях: стилистических и Best practices, но без Type checking. Им занимается Mypy, мы к нему никак не относимся.
У нашего линтера нет компромиссов. У нас нет правил из разряда «Не хотелось бы это делать, но если сильно хочется, то можно». Нет, мы всегда говорим жёстко — это не делаем, потому что плохо. Потом приходят люди и говорят: «Есть же 2,5 use case, где это в принципе возможно!». Если такие кейсы, явно напиши, что здесь эта строчка позволительна, чтобы линтер её игнорировал, но объясни почему. Это должен быть комментарий, почему ты разрешил какую-то странную практику и зачем это делаешь. Этот подход еще и полезен для документирования кода.
Самый строгий линтер не требует настроек (WIP). У нас пока есть настройки, но мы хотим от них избавиться: имея свободу, пользователь обязательно настроит так, что линтер будет работать неправильно.
Хороший инструмент в настройках не нуждается — в нем хорошие значения по умолчанию.
С таким подходом код будет консистентный и будет работать у всех одинаково, по крайней мере, в теории. Мы над этим ещё работаем, и пока настройки есть, можете пользоваться нашим инструментом и настраивать его под себя.
От кого зависим?
От большого количества инструментов.
- Flake8.
- Eradicate — классный плагин, который находит закомментированные фрагменты в коде и заставляет вас их удалять, потому что хранить мёртвый код в проекте — это плохо. Мы не разрешаем так делать.
- Isort — инструмент, который заставляет правильно сортировать импорты: по порядку, делая отступы, красивые кавычки.
- Bandit — замечательная утилита для проверки безопасности кода статически. Находит вшитые пароли, корявые использования
assertв коде, вызовыPopen,sys.exitи говорит, что это все нельзя использовать, а если хочется, — то просит написать причину. - И ещё больше 20 плагинов, которые занимаются проверкой скобок, кавычек и запятых.
Что проверяем?
Есть 4 группы правил, которые мы используем и заставляем соблюдать.
Сложность — это самая большая проблема. Мы не знаем, что такое сложность и не видим её в коде. Смотрим на код, с которым работаем каждый день и кажется, что он не сложный — бери, читай, все работает. Это не так. Несложный код — привычный код. У сложности есть четкие критерии, которые мы проверяем. О самих критериях — позже. Если код нарушает критерии, то мы говорим: «Код сложный, переписывай!»
Имена для переменных — это нерешённая проблема программирования. Кто будет читать, когда и в каком контексте — непонятно. Мы стараемся делать имена максимально консистентными и понятными, но хотя и стараемся — проблему пока до конца не решили.
Для консистентности у нас есть простое правило — писать везде одинаково. Если есть какой-то утвержденный подход, используй его везде. Неважно, нравится он тебе или нет, консистентность важнее.
Мы стараемся использовать только лучшие практики. Если мы знаем, что какая-то практика не очень хороша, то запрещаем её использовать. Если разработчику хочется использовать запрещенную практику, то мы ждем от него аргументации: зачем и почему применять. Возможно, во время процесса описания придет понимание, почему она плоха.
Что такое сложность?
У сложности есть конкретные метрики, на которые можно посмотреть и сказать — сложно или нет. Их много.
Cyclomatic Complexity — всеми любимая цикломатическая сложность. Она находит в коде большое количество вложенных
if, for, других структур, и указывает на слишком большую разветвлённость кода и трудность чтения. С вложенным кодом всё плохо: читаешь, читаешь, читаешь — вернулся назад, читаешь, читаешь, читаешь — подпрыгнул вверх, потом в другой цикл. Невозможно спокойно пройти такой код сверху вниз.Arguments, Statements и Returns. Это количественные метрики: сколько аргументов в функции или в методе, сколько внутри тела этой функции или метода statements и returns.
Cohesion и Coupling — популярные метрики из мира ООП. Cohesion показывает связанность класса внутри. Например, есть класс, и ты внутри используешь все методы и свойства — всё, что объявил. Это хороший класс с высокой связанностью внутри. Coupling — это насколько связаны разные части системы: модули и классы. Мы хотим добиться максимальной связанности внутри класса и минимальной связанности вовне. Тогда система легко поддерживается и хорошо работает.
Jones Complexity — эту метрику я позаимствовал, но только потому что она бомба! Jones Complexity определяет сложность строчки — чем сложнее строчка, тем сложнее ее понять, потому что кратковременная человеческая память не может обработать больше 5-9 объектов сразу. Это, так называемый, «кошелек Миллера».
Мы смотрим на эти важные метрики и еще на некоторые другие, которых гораздо больше, и определяем — подходит код или нет. В нашем понимании сложность — это водопад.
Водопад сложности
Сложность начинается с того, что мы написали строчку, и она пока хорошая. Но потом приходит бизнес и говорит, что цены поднялись в два раза, и мы умножаем на 2. В этот момент Jones Complexity сходит с ума и сообщает, что теперь строчка слишком сложная — там слишком много логики.
Хорошо, заводим новую переменную, а анализатор сложности функций говорит:
— Нет, так нельзя — теперь слишком много переменных внутри функции.
Сделаю новый метод, и в него передам аргументы. Теперь проверка количества аргументов функции, либо количества методов внутри класса говорит, что так тоже нельзя — слишком сложный класс и надо разбивать на две части. Разбили, выделив другой класс. Теперь стало больше классов и все хорошо, но проверка сложности модуля сообщает, что теперь модуль слишком сложный и надо рефакторить. Почему?!
Это называется страданием. Как раз поэтому я говорю, что линтер должен заставлять страдать. Мы начали с того, что умножили на 2 в одной строчке, а закончили рефакторингом всей системы. Добавление маленького кусочка кода ведет к рефакторингу целых модулей, потому что сложность расползается, как водопад, и закрывает собой все, что можно.
«Нужно рефакторить» — эта штука заставляет вас рефакторить код. Нельзя просто отсидеться: «Этот код не трогаю, вроде он работает». Нет, однажды ты поменяешь код в другом месте, и водопад сложности затопит модуль, который не трогал и тебе придется его рефакторить. Я считаю, что рефакторинг — это хорошо, и чем его больше — тем стабильнее и лучше работает твоя система. А все остальное субъективно!
Теперь поговорим про вкусы. Это холиварная и интерактивная часть!
Холивар
Давайте похоливарим, комментарии открыты. Сначала, напомню, что имена — сложная и нерешенная проблема. Можно подраться из-за того, как назвать переменную, но у нас есть некоторые подходы, которые помогают хотя бы не сделать явных ошибок.
Имена
Как вам такие: var, value, item, obj, data, result? Что такое data? Какие-то данные. Что такое result? Какой-то результат. Часто вижу переменную result и вызов какого-то адского метода у непонятного класса — и думаю: «Что это за result? Зачем он здесь?»
Есть много разработчиков, которые со мной не согласны, и говорят, что value — вполне нормальное имя переменной:
— Я всегда использую key и value!
— Почему бы использовать не key и value, а сказать, что ключ — имя, а value — фамилия? Почему нельзя назвать first_name и last_name — теперь есть контекст.
Обычно люди соглашаются, но все равно спорят. Это очень холиварная штук: как минимум 3 человека потратили на меня по часу своей жизни, чтобы про это со мной поспорить.
Называть переменные одной буквой — нормально?
Например, q? Все мы знаем классический кейс:
for i in some_iterable:. Что такое i? В C — это стандартная практика, и от нее все и идет. Но в Python — коллекции и итераторы. В коллекциях лежат элементы, у которых есть имена — давайте называть их как-то по-другому.Половина разработчиков считает, что называть переменные i, х, у, z — это нормально.
Я считаю, что называть имена одной буквой нельзя. Хочу больше контекста и хорошо, что со мной согласна вторая половина разработчиков. Если в C это еще как-то допустимо из-за исторического наследия, то в Python это очень большая проблема и так делать не надо.
Консистентность
Давайте просто выберем один способ из многих, и скажем: «Давайте делать так». Хорош он или плох — уже не важно — просто консистентно.
Мы говорим только про Python 3, легаси вообще не рассматриваем.
У меня есть аргумент: когда мы наследуемся от чего-то, то должны знать, от чего — неплохо бы увидеть имя родителя. Самое смешное, что обычно мы видим имя родителя, кроме случая, когда это object. Поэтому я сформулировал для себя правило: когда пишу класс, от чего-то наследуюсь — всегда пишу имя родителя. Неважно, что это будет — Model, object или еще что-то.
Если есть выбор писать
Class Some(object) или class Some, то я выберу первый. С одной стороны, он показывает, что мы явно пишем всегда то, от чего наследуемся. С другой стороны, в нем нет особой многословности: мы ничего не теряем от нескольких дополнительных нажатий клавиш.Две трети разработчиков привычнее второй вариант, и я даже знаю, почему. Моя гипотеза: все из-за того, что мы долго мигрировали из второй версии Python на третью, и теперь показываем, что пишем именно на третьем Python. Не знаю, насколько гипотеза правильная, но мне кажется, это так.
F-строки ужасны?
Варианты ответов:
- Да: они теряют контекст, засовывают логику в шаблон и не линтятся — (38%).
- Нет! Они — чудо! — (62%).
Есть гипотеза, что f-строки ужасны. В них засовывают что угодно! f-строки — это не то же самое, что
.format, отличия кардинальны. Когда мы объявляем некий шаблон, а потом его форматируем, то совершаем два действия по отдельности: сначала определяем шаблон, а потом форматируем. Когда мы объявляем f-строку, о совершаем одновременно два действия: сразу объявляем шаблон и форматируем — в один и тот же момент.C f-строками бывает две проблемы. Мы объявили шаблон для f-строки и всё работает. А потом мы решаем перенести шаблон на 2 строки вверх или вынести в другую функцию — и всё ломается. Теперь нет контекста, который позволял форматировать строки, и мы не можем их корректно обрабатывать. Вторая большая проблема с f-строками: они позволяют делать страшное — засовывать логику в шаблон. Допустим, есть строка, в которой просто вставляем имя пользователя и слово «Привет» — это нормально. Особо страшного ничего нет, но потом мы видим, что имя пользователя приходит заглавными буквами, решаем перевести его в Title case и пишем прямо в шаблоне
username.title(). Потом в шаблоне появляются условия, циклы, импорты. И все остальные части php.Все эти проблемы заставляют меня сказать, что f-строки — плохая тема, мы их не используем. Самое смешное, что у нас нет кейса, в котором нам подходят только f-строки. Обычно подходит любое форматирование, но мы выбрали
.format — все остальное нельзя — ни %, ни f-строки. Работу .format тоже линтим, потому что у него внутри можно ставить фигурные кавычки и писать либо имя переменной, либо ее порядок.Во время доклада количество противников f-строк выросло с 33 до 38% — это маленькая, но победа.
Числа
Любите ли вы такие числа:
final_score = 69 * previous result / 3.14. Кажется, что это стандартная строчка кода, но что такое 69? Такие вопросы часто возникают, когда я смотрю на код, который писал некоторое время назад, и менеджер в тот момент говорит:— Пожалуйста, умножь на 147.
— Почему на 147?
— У нас такая тарификация.
Я умножил и забыл, или долго подбирал какое-то значение коэффициента, чтобы все заработало — а потом забываю, как подобрал и почему. Получается, что важная исследовательская работа осталась скрыта за числом без названия. Я даже не знаю, что это за число, а могу только по коммиту потом как-то найти, вспомнить и восстановить.
Почему бы не делать по-другому — все сложные числа выносить в собственную переменную с именем и документацией? Например, для числа 69 написать, что это средний показатель на рынке, и теперь константа имеет имя и контекст. Я напишу комментарий, что константу взял на сайте вот такого исследования. Если исследование в будущем изменится, то зайду и обновлю данные.
Таким образом мы гарантируем, что никакие магические числа не проберутся наш код и не усложнят его изнутри. Они пробираются через проверку сложности каждой строчки и говорят: «Вот тебе число 4766. Что это такое, я не знаю, разбирайся сам!» Для меня это было большим открытием.
В итоге мы осознали, что за этим нужно следить, и никакие магические числа в код не пропускаем. Хорошо, что с нами согласны почти 100% коллег, и тоже не используют такие числа.
Но есть исключения — это числа от ?10 до 10, числа 100, 1000 и подобные, просто потому, что они часто встречаются и без них сложно. Мы жесткие, но не садисты и немного думаем.
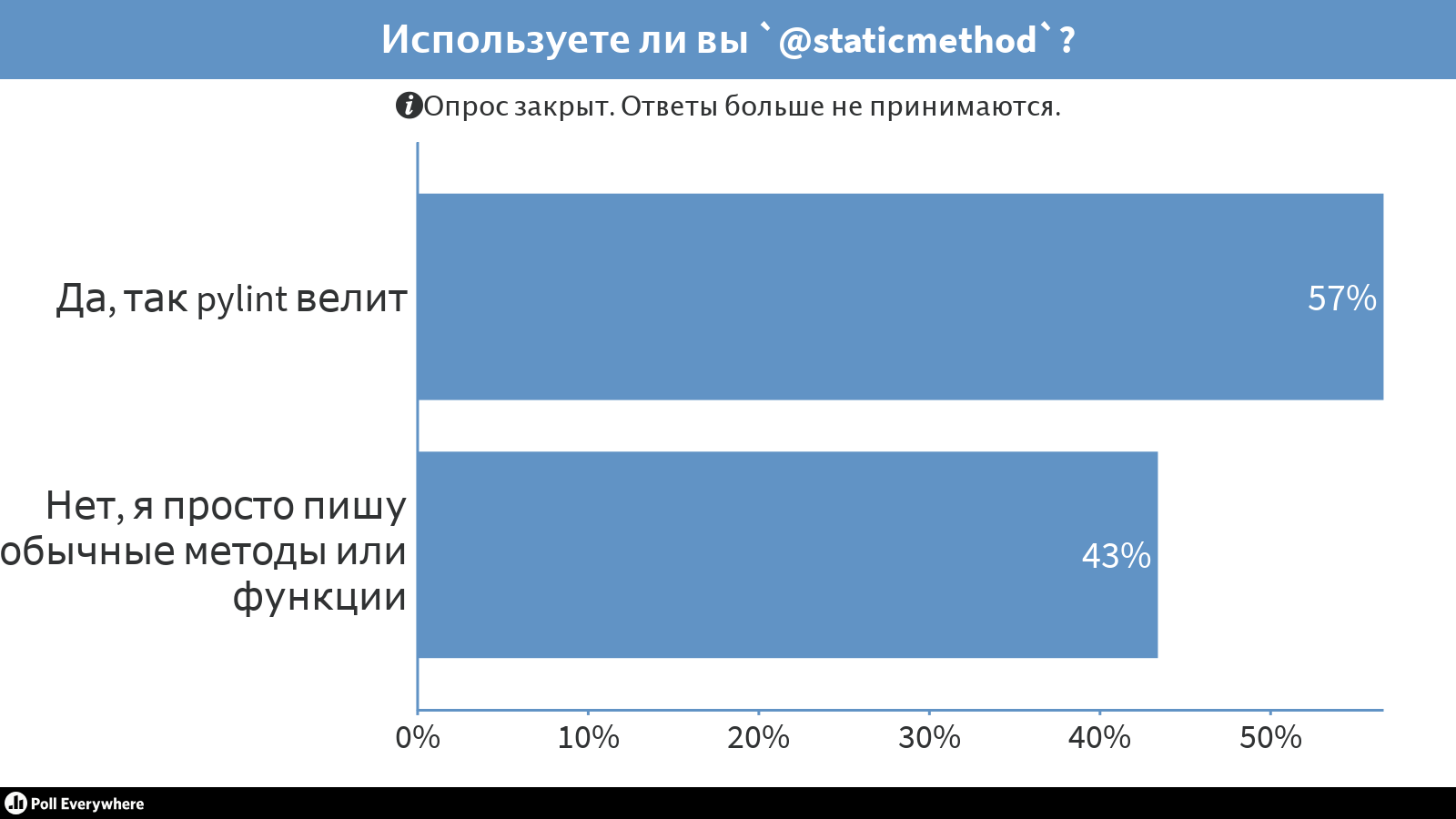
Используете ли вы ’@staticmethod’?
Давайте подумаем, что такое staticmethod. Задумывались ли вы, зачем он в Python? Я — нет. У меня был прекрасный Pylint, который говорил:
— Смотри, ты не используешь
self, cls — сделай staticmethod!— Хорошо, Pylint, сделаю staticmethod.
Потом я преподавал Python новичкам, и они задали вопрос, что такое staticmethod и зачем он нужен. Я не знал ответа и задумался — можно ли то же написать функцией, или в обычной функции не использовать
self, просто потому что это такой класс и что-то происходит. Зачем нам конструкция staticmethod?Я погуглил вопрос, и он оказался глубоким, как кроличья нора. Есть много других языков программирования, в которых staticmethod тоже не любят. Причем аргументировано — staticmethod ломает объектную модель. В результате я понял — staticmethod здесь не место, и мы его выпилили. Теперь, если мы используем декоратор staticmethod, линтер скажет: «Нет, извини, рефактори!»
Большинство разработчиков со мной не согласны, но примерно половина все-таки считает, что лучше писать вместо staticmethod либо обычные методы, либо обычные функции.
Логика в __init__.ру — хорошо или плохо?
Это моя любимая тема. Наверняка, когда вы создаете новый пакет и как-то его называете — у него создаётся __init__.ру и вы задумываетесь, что в него положить? Что поместить в __init__.ру, а что — в файлики рядышком? Для меня это был нетривиальный вопрос, и я всегда терялся: наверное, что-то самое важное? Потом я подумал — нет, наоборот, самое важное помещу в самый понятный контекст. Если положить что-то в __init__.ру, и потом это все импортить, получаются циклические импорты — тоже плохо.
Я посмотрел разные популярные библиотеки, полазил по их __init__.ру, и заметил, что в основном там либо мусор, либо обратная совместимость. Для меня этот вопрос встал остро, когда я начал создавать большие пакеты с множеством подпакетов — теряешься. В итоге мы решили выносить всю возможную логику в отдельные модули, и это работает. Никто не ломает Python, все хорошо, как и прежде, просто в __init__.ру логики нет, и 90% опрошенных коллег с нами согласны.
Вы скажете — хорошо, ты поменял API, но хочешь, чтобы пользователи по-прежнему импортировали то, что хотят, и откуда хотят? Да, так можно, потому что вопрос совместимости стоит отдельно. Мы не хотим ломать пользовательский API рефакторингом внутреннего кода. Поэтому есть случаи, в которых в __init__.ру может быть какая-то логика: импорты, редефиниции того, что вы удалили.
Но есть настройка, которая называется
I_CONTROL_CODE — я контролирую код. Это тот случай, когда она обоснована. Когда я контролирую код, которым пользуюсь, в __init__.ру логики нет — только документация. Но если код не контролирую, им пользуются другие люди, которые скачивают мою библиотеку, что-то делают, тогда можно туда положить редефиниции и импорты.Функция hasattr часто вам нужна?
Как часто нужна функция hasattr? Мне кажется, что достаточно часто, потому что в Python динамическая типизация — утиная. Нам hasattr иногда нужен, чтобы проверить наличие аргумента или атрибута у класса (провокация).
На самом деле, я считаю, что в hasattr нет надобности, эта функция работает не так, как вы думаете. Когда я разговаривал с разработчиками и спрашивал, как работает hasattr, они часто отвечали, что функция смотрит на наличие атрибута. Из-за того, что Python динамически и утино-типизированный, hasattr может выполнить вообще все что угодно. Иногда может даже в базу данных ходить, а вы об этом даже не будете знать. Поэтому лучше применять getattr и подход «Лучше попросить извинения, чем разрешения». С комбинацией этих двух подходов вы откажетесь от функции hasattr — либо getattr, либо exception.
На конференции зал разделился 50 на 50 — пожалуй, это была самая упорная борьба из всех опросов, но все равно мой кандидат проиграл на выборах.
Что мы хотим добавить в наш линтер
Этого нет в нашем линтере, но мы очень хотим layer-linter. Что он делает? Вы задаете в текстовом формате контракты: что можно импортировать, а что нет, в каких местах можно импортировать, а в каких нет. Вы создаете контракт на то, как внутри вашего кода бизнес-логика будет поделена на слои. Благодаря этому вы получаете отличный прирост качества без каких-либо телодвижений. Очень рекомендую.
Я уже говорил про cohesion. У нас нет этого плагина в основе, но мы его используем. Cohesion смотрит, насколько связан ваш класс внутри. У него есть достаточно много False Positive ошибок и использовать его в продакшене нельзя, но мы его применяем для аналитики — смотрим, какие классы хорошие, какие плохие.
Плагин vulture использует поиск неиспользуемого кода в Python и позволяет его удалять. Из-за того, что Python очень динамический язык, плагин дает много погрешностей. Поэтому мы его применяем как сohesion.
Radon позволяет смотреть разные метрики вашего кода, их очень много: Halstead, Maintainability Index, цикломатическая сложность. Попробуйте, прогоните код и посмотрите его коэффициент — это круто.
Final type
Я люблю Final-классы в Python. Их недавно добавили в Typing Extensions, а до этого у меня был собственный пакет, который я написал сам. Я считаю, что если ты сделал какой-то класс, и его больше нельзя наследовать — это хорошо, потому что ты просто зафиксировал реализацию. Если человек говорит, что он все-таки хочет что-то изменить, то зачем? Не надо. Используй композицию. Если что-то менять — напиши документацию, и тогда, возможно, можно.
Gratis
Наш линтер появился благодаря труду многих людей, и я им очень благодарен.

Все контрибьюторы линтера вынесены на этот слайд, чтобы сказать им публичное спасибо.
Если вы хотите контрибьютить наш линтер, вы тоже можете это сделать. Присылайте пул реквесты, будем их ревьюить. Мы вместе будем делать крутую штуку, которая поможет нашему Python-коду стать намного чище, качественнее и приятнее.
Кстати, Никита Соболев вступил в программный комитет Moscow Python Conf++, и помогает в подготовке классной программы. Конференция через два месяца, а у нас уже отобрано две трети докладов, можно изучить их тут и решить участвовать в нашем продуктивном мероприятии для Python-программистов.
А теперь разожжем немного холивара посредством интерактива. Результаты голосования во время выступления под спойлером. Проголосуйте и проверьте, а так ли поступает большинство разработчиков, или читерски подсмотрите, а потом топите за свой вариант.



Комментарии (13)

Shrim
13.02.2019 14:55+1Имена
В большинстве случаев шаблонные имена достаточны. И они общеприняты. Конкретно по key и value: есть словарь с вполне понятным именем (контекстом), я перебираю в цикле его ключи и что-то делаю с его значениями. Зачем мне использовать имена с контекстом? А они к слову могут быть весьма длинными.
Называть переменные одной буквой — нормально?
Да, нормально, но только если уместно. for i in range(100):... Любой программист читающий эту часть кода поймёт, что за переменная i, более того, в таком коде большинство программистов ожидают именно эту переменную, так уж исторически сложилось. А именно для того, чтобы программист понял контекст имена переменным и дают, не правда ли?
Консистентность
Если не ошибаюсь, то сlass Some(object) и class Some совсем не одно и то же. https://wiki.python.org/moin/NewClassVsClassicClass
F-строки ужасны?
Нет, это просто ещё один инструмент. Инструмент мы выбираем по ситуации. Могу привести кучу примеров, как из кода, так и из жизни, но надеюсь и так понятно.
Числа
Спасибо КО. Литеры и константы, первые страницы любого учебника по программированию.
Используете ли вы ’@staticmethod’?
Да, я использую. И вам советую. Все мы помним мантру, что функция/метод не должны быть длинее n строк. При разбиении может получится статический метод. Почему я должен выносить его из класса? Потому что кто-то не любит ’@staticmethod’? Выносить в отдельную функцию имеет смысл, если эта функция будет использоваться где-то ещё, иначе выгодней оставить метод в составе класса.
Логика в __init__.ру — хорошо или плохо?
Полностью с вами согласен.
Функция hasattr часто вам нужна?
Не убедили. Приведите хоть пару примеров, а то голословно как-то. Почему я должен вместо нужного мне инструмента использовать другой, предназначенный для других целей? Потому что вы так считаете?Balek
13.02.2019 16:53Давайте дружить?) Полностью с вами согласен, хотел только добавить, что мантра «не засовывать логику в шаблон» озвученная в разделе об F-строках ужасно надоела. Это всё продолжение той же истории, что и про @staticmethod и прочую разбивку кода на основе «синтаксиса», а не смысла. Люди с огромной радостью проглатывают идею складывать все компоненты в одну директорию, делать тонкие html-шаблоны и т.д. Потому что так не надо использовать голову. Чуть лучше, но в ту же степь, все эти проверки на количество операций в строчке, количество переменных, методов и классов. Хороший код структурируется на основе логической взаимосвязи его кусков, а не «синтаксиса». Длинное выражение, функция или класс могут в принципе не иметь разбивки на смысловые куски. Тот же вызов username.title() в шаблоне — восхитителен. При чтении мы сразу видим, зачем вызывается метод title. Мы автоматически пропускаем вызов метода, если нас не интересует содержание строчки. Этот вызов логически привязан к шаблону и должен быть с ним как можно ближе.
Для любителей всё возводить в абсолют: это не значит, что весь код нужно писать в одном файле, одной функции и одной строчке. Именно в том и смысл, что какого-то абсолютного, бездумного правила не может быть. Нужно смотреть на логические взаимосвязи.

Levitanus
13.02.2019 19:36подписываюсь почти подо всем.
Но с однобуквенными переменными есть кое-какое рациональное зерно:
Сейчас почти каждый редактор умеет в пакетное выделение через ctrl+D.
И поленившись добавить вторую буквуimport unittest as tвы обрекаете себя на мытарства в дальнейшем. А стоило-то:import unittest as ut.
И, чтобы два коммента не писать:
почему f-strings рассматриваются в контексте html? Это отличный инструмент для производительного мелкого форматирования в одну строчку. через %-форматирование можно наткнуться на некоторые проблемы.
Допустим, у меня в компиляторе бывает так:%some_array[<и чего сюда писать для форматирования?>].
Andy_U
13.02.2019 15:54Если не ошибаюсь, то сlass Some(object) и class Some совсем не одно и то же.
В третьем питоне — одно и тоже.

amarao
13.02.2019 17:40Только что попробовал pylint на первом попавшемся питоновом скрипте. У меня это крутой скрипт, полностью покрытый тестами. Т.к. это скрипт, а не программа, тесты прилагаются внутри самого скрипта (набор функций
def test_foo...в конце файла).
При этом у меня была проблема — как использовать mock'и и другие вкусные вещи, если я их не хочу грузить для исполнения скрипта. Решение простое:
def setup(): global pytest global mock global builtins import unittest.mock as mock import pytest import builtins
После чего pytest, mock и builtins можно использовать внутри тестов.
И догадайтесь, за что мне поставили -3 в pylint'е? Правильно, за то, что переменные не определены.
def test_get_scenario_none(): with pytest.raises(AssertionError): get_scenario([])
script.py:473:13: E0602: Undefined variable 'pytest' (undefined-variable)
Грош цена этому линтеру, если он разумное не понимает.

SirEdvin
13.02.2019 19:18-1разумное не понимает.
Вы же знаете, что за глобальные переменные в менее терпимые временами сжигали сразу?)
amarao
13.02.2019 19:21+1Если вы внимательно посмотрите, то поймёте, что это очень осмысленный приём. Я в setup() настраиваю среду для тестов таким образом, чтобы не засорять модуль тестовым хламом на время нормального исполнения. Если вы мне пожете предложить лучший вариант сохранить тесты и код в одном файле без загрязнения тесто-ориентированными import'ами самого кода, я буду крайне благодарен.
То есть мы можем сейчас обсуждать правильно это или нет, но уж точно это не «undefined variable». А причина проста — pylint пытается статически анализировать динамический язык, т.е. как линтер никуда не годится. (А если бы у меня инъекция производилась во внешнем модуле?)SirEdvin
13.02.2019 19:24-1Если вы внимательно посмотрите, то поймёте, что это очень осмысленный приём. Я в setup() настраиваю среду для тестов таким образом, чтобы не засорять модуль тестовым хламом на время нормального исполнения. Если вы мне пожете предложить лучший вариант сохранить тесты и код в одном файле без загрязнения тесто-ориентированными import'ами самого кода, я буду крайне благодарен.
Могу вам только предложить таки вынести тесты из файла, как минимум потому, что это ну… более правильно?
А причина проста — pylint пытается статически анализировать динамический язык, т.е. как линтер никуда не годится.
На самом деле, pylint все вам правильно сказал. Он не знает, что функция setup выполняется как-то автоматически. А если еще представить ситуацию, когда pylint в самом деле бы выполнял код, то можно прийти к выводу, что он бы крушил CI воркеров направо и налево, так как почти каждое крупное приложение на питоне что-то да и сделает при запуске.
amarao
13.02.2019 19:27+1… Это скрипт. Он не «устанавливается» в систему, у него нет этапа сборки. Его нельзя импортнуть через entrypoints. Он не является модулем. Таким образом, класть рядом тесты и танцевать с путями для импорта будет крайне неудобно. Можете считать частью ТЗ — тесты и код в одном файле.
pylint просто пытается делать вещи, которые делать не должен. В отличие от flake'а, который в нормальном режиме вполне себе адекватное требует, pylint требует неадекватного — чтобы «ему объяснили что там происходит».
SirEdvin
13.02.2019 19:10+2Имена
Вы упускаете то, что в контексте почти всегда понятно, что такоеresult,dataи так далее. В приведенном примере тоже не сильно понятно, что такоеfirst_nameиlast_name, и почему они так странно лежат в словаре.
Называть переменные одной буквой — нормально?
index вместо i просто обмажет вас контекстом с ног до головы.
Консистентность
Я приведу в пример кусок кода, что бы проиллюстировать состоятельность тезисов в этом пункте (реальный код с реального проекта)
class GetMethodProcessApiView(general.ApiView): """ view for get method """ def get(request): """ Perform get method processing """ # get method processing
Зачем писать больше одного раза?
F-строки ужасны?
Я как-то попробовал запихнуть цикл в f-строку, как то не очень получается.
Используете ли вы ’@staticmethod’?
А как в противном случае группируете функции? Пихаете все в объекты или же чисто храните в модулях?
Функция hasattr часто вам нужна?
То есть вместо такого:
def _correct_compare(arg1, arg2) -> bool: if hasattr(arg1, '__corrupted_eq_check__'): return arg1._equals(arg2) return arg1 == arg2
мне писать
def _correct_compare(arg1, arg2) -> bool: try: if arg1.__corrupted_eq_check__: return arg1._equals(arg2) except AttributeError: return arg1 == arg2
А вместо
def _type_check(value: Any, target_type: Type) -> bool: if hasattr(target_type, '__args__'): if target_type.__origin__ is Union: return any(_type_check(value, x) for x in target_type.__args__) checking_type = target_type if not hasattr(target_type, '_gorg') else target_type._gorg if sys.version[0:3] == '3.7': base_result = isinstance(value, checking_type.__origin__) else: base_result = isinstance(value, checking_type) # TODO: process advanced type checking! return base_result return isinstance(value, target_type)
получится
def _type_check(value: Any, target_type: Type) -> bool: try: if target_type.__origin__ is Union: return any(_type_check(value, x) for x in target_type.__args__) try: checking_type = target_type._gorg except AttributeError: checking_type = target_type if sys.version[0:3] == '3.7': base_result = isinstance(value, checking_type.__origin__) else: base_result = isinstance(value, checking_type) # TODO: process advanced type checking! return base_result except AttributeError: return isinstance(value, target_type)
На мой взгляд, так выглядит немного хуже. И опять же, а зачем?
amarao
13.02.2019 19:24+2Я понимаю, что линтер суров, но мне он ругнулся на вот это:
with open(config_path, 'r') as f: self.conf = yaml.load(f)
У меня есть острое ощущение, что
with open(file) as f— очень даже идиоматичненько и не требует раскрытия смысла 'f'. Или требует?
Andy_U
А почему вы не упомянули Pycharm?
eyeofhell Автор
В комменты приглашается sobolevn