

А что это за музыка и где она живет?
Звук – это волны, достигающие наших ушей через некоторую среду: газообразную, жидкую или даже твердую (мы всегда неправильно слышим собственный голос, так как он сотрясает не только воздух, но и кости черепа). Как и любая другая волна, звук характеризуется амплитудой, изменяющейся во времени. Почти весь звук, который мы храним на плеерах и смартфонах, качаем с интернета или покупаем на дисках, имеет цифровую природу. При оцифровке выполняется квантование звука по времени и амплитуде: он представляется в виде дискретных значений амплитуды в определенные моменты времени. Эти значения называются сэмплами. Простейшие звуковые форматы вроде WAV так и устроены: много-много последовательных сэмплов.
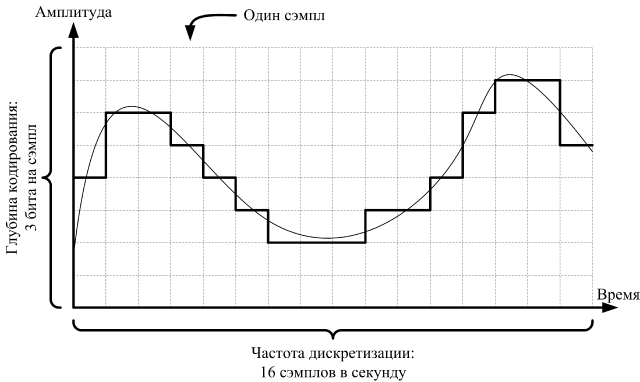
Значение каждого сэмпла – это целое число, обычно помещающееся в 1, 2 или 4 байта. Количество байтов, выделенное на хранение каждого сэмпла, называют глубиной кодирования звука. Количество сэмплов в секунду называют частотой дискретизации. Частота 8 кГц обеспечивает приемлемое качество звука, для хорошего качества требуется не менее 16 кГц, а оптимальным значением считается 44.1 кГц и выше.
Со звуком дело ясное, а вот с музыкой – темное. Проблема в том, что формально определить музыку не так-то просто, ведь это субъективное понятие: споры о дабстепе и Рахманинове не утихают до сих пор. Конечно, попытки формализовать музыку предпринимались не раз, и некоторые из них дали впечатляющий результат. Тем не менее, вопрос «что же такое музыка» закрывать пока еще рано.
Но мыжпрограммисты, у нас нет ни времени, ни желания разбираться с трансцендентной природой музыки. А значит, мы делегируем эту задачу компьютеру, а точнее, глубоким нейронным сетям.
Сочинение музыки и нейросети: смешать, но не взбалтывать
Процесс генерации случайной музыки можно представить так: берем несколько сэмплов, на их основе вычисляем следующий сэмпл, затем еще один, и еще, еще, еще… Если генерировать сэмплы «впопад», а не совершенно случайно, созданный звук имеет шансы оказаться музыкой. Получается, задача состоит в том, чтобы по предыдущим сэмплам удачно предсказывать следующий. Не секрет, что нейросети – неплохие предсказатели, поэтому мы обратимся к ним за помощью.
С нейросетями есть одна загвоздка. Классические нейросети – это слои связанных друг с другом нейронов. Вам наверняка попадалась на глаза такая картинка:
Помните, что каждая секунда звука содержит тысячи сэмплов? Это значит, в слоях будут тысячи нейронов, между ними протянутся миллионы связей, и обучение такой сети займет миллиарды лет. Для создания музыки нужны специальные нейросети, оптимизированные под это дело. К счастью, все придумано до нас: подходящие архитектуры нейронных сетей давно описаны. Самые известные из них – это WaveNet и SampleRNN.
WaveNet была разработана в 2016 году в недрах секретных лабораторий компании DeepMind. В основу этой нейросети легла операция свертки: анализируя пары последовательных сэмплов, она выделяет их базовые особенности (например, «первый сэмпл больше второго»); затем из пар этих особенностей выделяются более сложные особенности, и так далее. В конце концов, на основе высокоуровневых особенностей вычисляется прогноз следующего сэмпла. При этом пары выбираются таким образом, чтобы на прогноз следующего сэмпла влияло как можно больше предыдущих.
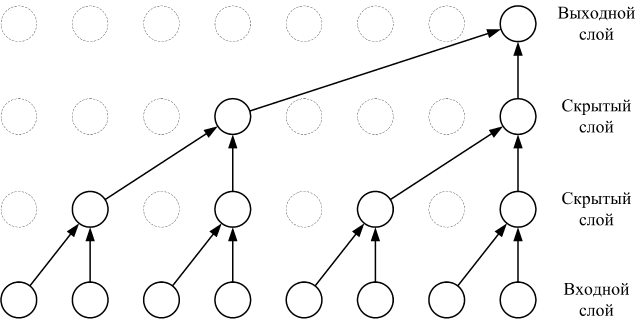
SampleRNN также была разработана в 2016 году, но принцип работы у нее совсем другой. Это рекуррентная нейросеть: она обрабатывает сэмплы один за другим, при этом на следующую итерацию передается результат предыдущей. Для ускорения работы используется хитрый трюк. Нейронная сеть состоит из нескольких уровней. Первый уровень обрабатывает большую последовательность сэмплов и передает результат работы на второй уровень. Там этот результат используется для обработки нескольких более коротких последовательностей. Результат каждой обработки передается на третий уровень, и так далее. Последний уровень отвечает непосредственно за предсказание значения следующего сэмпла. Таким образом, медленные уровни, обрабатывающие большие последовательности, запускаются редко.
Впихивая невпихуемое
И WaveNet, и SampleRNN генерируют прогноз значения следующего сэмпла в виде распределения вероятностей его значений (сэмпл примет значение 0 с вероятностью 15%, значение 1 – с вероятностью 25%, и так далее). Конкретное значение следующего сэмпла выбирается случайным образом в соответствии с этим распределением. Распределение можно представить себе как отрезок, разбитый на части: чем больше вероятность, тем длиннее часть. Для выбора сэмпла мы бросаем в отрезок дротик. В какой сэмпл попали, такой и отправляется «на выход».
В любом процессе, который использует случайность, при желании можно организовать скрытый канал передачи информации (он есть даже в алгоритме цифровой подписи по ГОСТу: приложение, формирующее подписи, может в каждой из них сливать часть вашего закрытого ключа). Создание случайной музыки – не исключение. Манипулируя случайностью, мы можем встроить в композицию свои тайные данные.
Алгоритм встраивания проще всего показать на примере. Пусть глубина кодирования звука составляет два бита, у каждого сэмпла всего четыре возможных значения: 0, 1, 2 или 3. Предположим, мы хотим встроить секретное сообщение длиной 1 байт. Его можно представить как число от 0 до 255:

Процесс генерации музыки начинается с выбора N начальных сэмплов (их можно взять случайно или вырезать кусок из уже имеющейся музыки). «Скормив» эти сэмплы обученной нейросети, мы получаем прогноз следующего сэмпла, например: 0 – 15%, 1 – 25%, 2 – 45%, 3 – 15%. Мы делим отрезок на части, пропорциональные вероятностям:

Секретное сообщение попало во второй отрезок. Значит, у следующего сэмпла будет значение 1. Мы записываем этот сэмпл в музыкальный файл, а затем сужаем изначальный отрезок:

После этого процесс повторяется: мы используем нейросеть, чтобы по N последним сэмплам спрогнозировать значение следующего, делим отрезок, смотрим, куда попало сообщение, выбираем следующий сэмпл и сужаем отрезок. Вся эта джига-дрыга продолжается до тех пор, пока длина отрезка не окажется меньше единицы. Теперь встраивание завершено, и секретное сообщение может быть однозначно извлечено.
Извлечение сообщения очень похоже на встраивание. Мы берем тот же самый отрезок, по первым сэмплам генерируем прогноз следующего и разбиваем отрезок пропорционально вероятностям. В этот раз мы не знаем, куда попало сообщение, зато нам известно, какой сэмпл был выбран в качестве следующего! Поэтому мы можем сузить отрезок точно так же, как и при встраивании.
Повторив этот процесс для всех сэмплов, мы получим тот же самый отрезок, что и при встраивании. Его длина будет меньше единицы, а значит, внутри окажется всего одно целое число. Оно и есть наше секретное сообщение.
Покажите мне Москву результаты
Для экспериментов мы использовали SampleRNN, реализованный с помощью фреймворка PyTorch. В качестве музыки для обучения взяли кое-что не очень структурированное: джаз. Нейросеть обучалась на видеокарте GeForce GTX 1070 Ti около суток, и значение функции потерь (это что-то вроде средней ошибки прогноза) стабильно уменьшалось. Потом нейросетке резко поплохело: она стала выдавать шум вместо музыки, функция потерь взлетела до небес и перестала уменьшаться, и мы были вынуждены констатировать факт: пациент скорее мертв, чем жив.
Тем не менее, у нас сохранилось состояние, в котором нейросеть работала стабильно. Поэтому мы смогли поэкспериментировать с ней, встраивая и извлекая данные разного объема. Вот несколько примеров треков, содержащих 128 кб данных:
Самое классное: в формате FLAC (без потерь) эти отрывки весят примерно 170 кб, то есть полезные данные занимают 75% контейнера. Такое могущество ни одному стеганографическому алгоритму и во сне не снилось.
Но есть и ложка дегтя: встраивание занимает довольно много времени. При встраивании 128 кб за одну секунду генерируется всего 40 сэмплов, то есть на создание одной секунды музыки уходит 6-7 минут. Чем больше данных нужно встроить, тем медленнее будет генерироваться музыка, так как придется работать с очень длинными числами, занимающими килобайты или даже мегабайты. Это далеко не четырехбайтный int.
Проблему можно решить, если разбивать данные на небольшие блоки и встраивать их друг за другом. Это позволяет добиться скорости 100-200 сэмплов в секунду. Для генерации в реальном времени, конечно, маловато, но хоть что-то.
Вот и сказке конец, а кто слушал — молодец
В статье мы рассмотрели, как можно прятать данные в музыку. Но область применения описанного алгоритма не ограничивается лишь звуковыми форматами: нейросети отлично умеют генерировать картинки, а также учатся создавать видео и писать осмысленные тексты. Учитывая высокий КПД (отношение объема полезных данных к объему контейнера) при встраивании и генерацию контейнера на лету, можно предположить, что будущее в области стеганографии – за нейронными сетями.
<Тут могла быть ваша реклама>
И кстати, о рекламе: с 14 по 25 марта пройдет NeoQUEST-2019, и регистрация на него уже открыта здесь!
На этот раз события будут развиваться в Древней Греции, по мотивам всем известных мифов и легенд. Узнаем, готов ли ты искать уязвимости с упорством Сизифа, со стойкостью Прометея реверсить прошивки и стремиться к победе, как Орфей к Эвридике?
До 14 марта еще есть немного времени, чтобы проапгрейдить свой уровень знаний: реверс, Android, криптография, OSINT, web-уязвимости и еще парочка подводных камней мира кибербезопасности уже ждут тебя! По всем вопросам пиши на support@neoquest.ru – команда NeoQUEST на связи!
Комментарии (12)

Cerberuser
27.02.2019 11:15Сильно смахивает на арифметическое кодирование при сжатии данных, только, так сказать, наоборот: наша информация — это "архив" (одно число), а встраиваем мы его в "распакованную" музыку (поток байт).

PavelMSTU
27.02.2019 11:20Все решается хеш-стеганографией.
Генерируете семпл в N милисекунд. N — параметр. Берёте хеш от этого семпла. От хеша берёте первый бит, если он совпадает с первым битом передаваемого сообщения — добавляем семпл, иначе ещё раз генерируем.
Функция генерации должна быть стохастической.
И не нужны никакие отрезки.
Декодирование — вообще тривиальная задача.Cerberuser
27.02.2019 11:36А с точки зрения звукового файла получится ли при этом что-то вменяемое? Соль же в том, чтобы на слух получившийся звук выглядел достаточно естественно, по идее, а для этого надо учитывать связь последовательных семплов.
PavelMSTU
28.02.2019 12:42Абсолютно верно. Стохастическая функция с параметрами. Где параметры — учитывают музыку, сгенерированную ДО текущего сампла.

NWOcs Автор
27.02.2019 17:06Результат хеш-стеганографии будет хуже по ряду причин:
1. Во-первых, при встраивании более-менее объемных данных будет появляться высокочастотный шум, ведь хеш-стеганография — это обобщение LSB-стеганографии: возьмем hash(x) = x, n = 1 и получим LSB в чистом виде.
2. Во-вторых, у хеш-стеганографии будет гораздо более низкий КПД. Даже при n = 1 в примеры из статьи не удастся встроить более 40-50 кб, для n > 1 объем полезной нагрузки будет еще меньше.
3. В-третьих, непонятно, какую проблему решает хеш-стеганография. Увеличивает скорость встраивания? Но львиная доля времени при встраивании (если данные бьются на блоки, как описано в статье) тратится на запуск нейросети. Если придется запускать нейронку несколько раз для генерации каждого сэмпла (в поисках нужного хэша), то скорость, наоборот, упадет.PavelMSTU
28.02.2019 12:41п.2 — верно. Но можно встроить не сам контент, а ссылку на контент. Да и обычно с помощью стеганографии передают небольшие данные (команды, ключи, ссылки, настройки зловредов и т.д.) Для практических целей этого более чем достаточно.
п.3. — основной смысл хеш-стеганографии в РАЗДЕЛЕНИИ проблемы поиска «незаметного контента» и встраивания информации. Таким образом энтропийные подходы стегоаналитики (для любителей академических работ: тыц) вообще все идут в трубу!!! В общем случае вам нужна некая стохастическая функция с параметрами, при каждом запуске выдающая какой-либо контент и/или часть контента. Параметры должны задавать состояния (в вашем случае учитывать музыку, которая УЖЕ сгенерирована) Всё! Далее нужно уже работать с конкретной средой передачи и создании «умной» стохастической фунцкии
п.1 — не верно вообще. Никакого отношения к LSB это не имеет в принципе. Напишу пост отдельно.

Serge78rus
27.02.2019 12:57При оцифровке выполняется квантование звука по времени и амплитуде: он представляется в виде дискретных значений амплитуды в определенные моменты времени.
Не амплитуды, а мгновенных значений.
Sly_tom_cat
Почему-то с самого начала подумал — звук — отстой, вот сколько в видео можно запихнуть… ух…
Но и сеточка под видео нужна будет нехилая. Поэтому как демонстрация идеи — звук все-таки канает :)
fireSparrow
Но видеофайл и весит значительно больше, чем звуковой той же длины. Единственно показательная метрика — это отношение объёма спрятанных данных к общему объёму файла.
А оно, если верить автору статьи, в данном случае весьма впечатляющее — 75%. И не ясно, может ли видео дать больший коэффициент.
Sly_tom_cat
Да, мне кажется создать «не вызывающее подозрения» видео и запихнуть туда 75% инфы будет гораздо сложнее чем с музыкой. Но больше объемы контейнера — больше и впихнется даже при худшем соотношении… ну конечно если оно не сильно хуже…
fireSparrow
А что мешает создать подборку музыки в несколько гигабайт размером?
Тем более на данном этапе проблемой является не только генерация видео с вшитыми данными, но и вообще генерация правдоподобного видео. Музыка по природе своей в значительной степени абстрактна, её гораздо проще генерить. А в не вызывающем подозрение видео должны присутствовать объекты реального мира, их так просто не погенеришь. Сейчас даже статичные изображения людей и котиков генерятся довольно неровно — 50% норм (если не присматриваться), а 50% стрёмные и скособоченные.