
Disclaimer. Эта статья написана из интереса к теме и желания опробовать изученный материал на практике, без претензий на максимально точный и детальный анализ.
Для анализа был использован python, код доступен на github.
Данные
База сейчас содержит 1952 цитаты со следующим распределением по политикам:
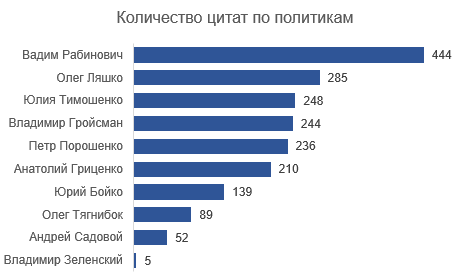
Для целей анализа я выбрала людей с > 200 цитатами. Соответственно, выпали из анализа Юрий Бойко, Олег Тягнибок, Андрей Садовой и Владимир Зеленский. В массиве осталось 1667 цитат. Из шести оставшихся спикеров четверо (кроме Гройсмана и Рабиновича) — зарегистрированные кандидаты на ближайшие президентские выборы.
Цитаты бывают разные, от коротких, порядка 30 знаков («Я подал уже 112 законопроектов.») до длинных, около 1200 знаков. Средняя длина цитаты — около 200 знаков (это, например, «Скоро наші діти корову бачитимуть лише у музеї поряд із динозавром чи в підручниках із природознавства – у результаті тієї політики, яку проводить нинішня влада. Поголів’я скота — менше 2-х мільйонів.»)
TF-IDF
Для начала посмотрим, какие слова являются более характерными для тех или иных спикеров. Вот топ-10 слов с самым большим значением TF-IDF для каждого кандидата:

Для подсчета TF-IDF был применен стемминг (stemming) — приведение слова к основе.
Зеленым выделены те слова, которые я хотела бы прокомментировать по каждому спикеру, чтобы дать немного контекста.
Олег Ляшко:
- Польша: Ляшко часто упоминает Польшу в связи с рабочей миграцией туда украинцев, а также сравнивает доходы в Польше и Украине
- Зерновые: Ляшко говорит о том, что Украина экспортирует зерно и теряет на этом, потому что могла бы дороже эспортировать муку
- Онкология, лекарства: Ляшко ярый противник нынешней медицинской реформы и часто говорит о том, что расходы на онкологию почти не покрывается государством
Порошенко и Гриценко много говорят о военном конфликте, что довольно логично: Порошенко президент и соответственно верховный главнокомандующий, а Гриценко военный и был министром обороны.
Гройсман премьер-министр, и в основном говорит об экономике, в т.ч.о государственном долге.
В цитатах Вадима Рабиновича специфической тематики не прослеживается, возможно потому что он говорит очень много (444 цитаты из 1952, у всех остальных — менее 300 цитат).
Юлия Тимошенко много говорит о газотранспортной системе Украины, о ликвидации банков, а также о низких экономических показателях страны.
Классификация цитат
Итак, у нас получается 6 классов (спикеров). Для классификации я использовала наивный Байесовский классификатор. Из текста исключены стоп-слова русского и украинского языков (с помощью пакета stopwords). Включены n-граммы длиной до 2-х (варианты с длиной до 3-х тоже тестировался, но показал оверфиттинг). Тестовая выборка взята в пропорции 20% от общей.
Итоговая точность модели (доля правильно классифицированных цитат) на тренинговой выборке — 74,8%, на тестовой — 75,7%
Перекрестные результаты по авторам:

Выше всего точность для Вадима Рабиновича (97%) — скорее всего потому, что он единственный русскоязычный спикер из шести. Высокая точность классификации Гройсмана и Ляшко (78% и 77%).
Чуть выше 60% показатели точности определения цитат Порошенко и Тимошенко. Их обоих модель чаще определяет как Гройсмана. Гройсман как премьер-министр часто говорит на тему экономики в форме «отчета о проделанной работе», и неправильно классифицированные цитаты Порошенко и Тимошенко тоже об этом (только у Порошенко как представителя власти это позитив, а у Тимошенко наоборот).
Например, вот цитата Порошенко, определенная моделью как цитата Гройсмана:
5 млрд грн, (тобто) 4 млрд грн того року і 1 млрд грн цього року спрямовані на сільську медицину
А также цитата Тимошенко, определенная как цитата Гройсмана:
В наступному бюджеті на утримання тюрем виділили вдвічі більше грошей, ніж на науку, яка робиться в Академії наук України.
Ниже всего точность (57%) у цитат Анатолия Гриценко. Его модель часто определяет как Порошенко (что логично, учитывая военную тематику их цитат), а также как Ляшко. В случае с Ляшко неправильная классификация — это цитаты с критикой власти, в т.ч., например, о миграции: Я не кажу про те, що той же член вашого уряду, Володимире Борисовичу, пан Клімкін сказав, що мільйон щороку покидає країну.
В целом, как мне кажется, для таких коротких цитат схожего формата (устные выступления политиков) и тематики (украинская политика) результат неплохой. Кстати, на этих же данных я пробовала сделать модель, определяющую категорию цитаты (правда / неправда / манипуляция), но точность получилась очень низкая. Что в принципе логично: глядя на цитату по типу «Столько-то денег было потрачено на вот это, а в вот такой стране на это тратят вот столько-то» сложно определить правдивость изложенных в ней данных :)
Комментарии (25)

dididididi
11.03.2019 16:40+1Круто, так потенциальных друзей в соцсетях можно искать, схожих по интересам, культуре и образованию, языку.

red_perez
11.03.2019 17:02Можно ли по цитате определить, кто из политиков ее автор?
Для этого должно быть гарантировано соблюдение условия что политик думает сам а не читает то что ему спичрайтер пишет. Иначе анализ не имеет смысла.suharik
11.03.2019 17:21+1Зато в обратном случае можно определять политиков, которым пишет один автор.
red_perez
11.03.2019 17:31Вот это, пожалуй, гораздо познавательнее.
Неплохо было бы научиться делать анализ «фэйк-ньюз», чтобы определять по тому же принципу «сигнатуру» автора вброса, и дальше по такому принципу помечать новости со «cxожими сигнатурами». Если журналист «зашкварился» фейком, чтоб он потом не смог прятаться за псевдонимами.
pro100olga Автор
11.03.2019 17:39Была такая работа на «Текстах» (по определению фейков): texty.org.ua/d/2018/mnews
(англ вариант: texty.org.ua/d/2018/mnews/eng)
IgorKh
11.03.2019 18:58+1Очень много подобных работ есть, да и обычный частотный анализ по текстам работает очень хорошо.
sim3x
11.03.2019 17:21Не было идеи включить тексты одного из «кандидатов» из его шоу?
Также непонятно почему ЮБ не вошел в таблицу? Есть чувство, что он бы перекся с ВР
определяющую категорию цитаты (правда / неправда / манипуляция)
тут нужно fact extraction делать, а потом его еще пробовать пересечь с микро выборкой от vox (тк кроме них никто не делает человеческий фактчекинг)pro100olga Автор
11.03.2019 17:37Не было идеи включить тексты одного из «кандидатов» из его шоу?
Я брала уже готовый массив цитат, а VoxCheck отбирают цитаты по определенным правилам (устные выступления в определенных условиях, можно почитать по ссылке вверху поста). Если вы про Зеленского, то он таких выступлений (соответствующих критериям отбора) немного делает — и я думаю, это неслучайно :) А просто добавлять цитаты, сделанные в других условиях — мне кажется, это искажает выборку.
Что касается Бойко, то я выбрала минимум 200 цитат как лимит, потому что интервал 200-300 включал много авторов, а потом снижение до 139 довольно резкое. Но да, если его добавить, то у него большое пересечение с Рабиновичем.Scorobey
11.03.2019 22:01+1Статья мне понравилась, очевидно курсы по NLP не прошли для Вас даром. Попробуйте мою методику по определению авторства habr.com/ru/users/scorobey/posts/page4 есть и возможности определения скрытых латентно семантических связей. Удачи!!!

kikiwora
12.03.2019 07:55Помню, занимался подобным на лабораторных работах на 3м курсе :)
Но конечно анализ политиков куда веселее чем то что делали мы, я бы от такого в ВУЗе не отказался бы.
Статья маленькая да удаленькая. Если бы мог, плюсанул бы.
Но я не могу — люди хабра не любят правду и уничтожили мою карму.
nullptr4this
12.03.2019 10:19+2Сначала ИИ изучает речь политиков, потом научится имитировать, а потом достаточно будет их подменить и можно незаметно править человеками.
Надежда только на таких людей, как Виталий Кличко. Об него сломает зубы любая нейросеть!
anikavoi
12.03.2019 10:33Ничего не понимаю в украинской политике, но вроде как Зеленский является одним из лидеров рейтингов, не ошибаюсь? Тогда почему в исходной базе было так мало его, и так много Рабиновича (про которого я вообще ничего не слышал)?
Чисто статистически, мне кажется что исходные данные не совсем корректны.
ЗЫ: Говорю только о цифрах, никакой политической окраски коммент не несет.IgorKh
12.03.2019 11:39Потому что Зеленский — комик, который влез в политику под самую предвыборную гонку, а остальные там сидят и «наговаривают» годами.
Olehor
12.03.2019 12:05Для целей анализа я выбрала людей с > 200 цитатами. Соответственно, выпали из анализа Юрий Бойко, Олег Тягнибок, Андрей Садовой и Владимир Зеленский. (200+ по теме «политика»).
kylroma
12.03.2019 12:05Зеленскому не дают говорить, потому что, когда говорит — его тупость сразу становится явной. А так сидит себе тихо, отмалчивается. У людей складывается впечатление умного человека.
pro100olga Автор
12.03.2019 12:31Зеленский подтвердил свое участие в выборах только в начале года. При этом он практически не выступает на ток-шоу, а дает интервью некоторым СМИ — думаю, потому что с экспромтом у него не очень хорошо, что видно по некоторым высказываниям, когда его все-таки подлавливают журналисты. Его высокий рейтинг обусловлен в первую очередь запросом на «новые лица» в политике. Поэтому такое несоответствие рейтинга и количества цитат.
Рабинович же, во-первых, был депутатом Оппоблока, сам владел ТВ-каналом, и его нынешний партнер Мураев тоже владелец (другого) ТВ-канала. То есть у него были и возможности, и, видимо, желание много выступать.
iig
12.03.2019 13:29Было бы более интересно сравнить высказывания политиков (спичрайтеров?) сейчас и 4 года назад. Или по данным 4 и 8 летней давности спрогнозировать сегодняшние тексты.
Vlad_fox
12.03.2019 16:21Зеленский не политик от слова вообще. Политик, кторого он представляет, вернее играет доверенную ему роль кандидата в президенты — Беня (ИБ Коломойский).
Если анализировать его живую речь — не выученные заготовки для развелекательных шоу 95-квартала или развлекательного сериала про политику, то ее суть можно передать фразой Лаврова «дебилы б… ть». Только с шутками и заискиванием.
Популярность его обьясняется высоким % достаточно тупого населения… вскормленного тупыми сериалами, вконтактом с однокласниками и плохим образованием.pro100olga Автор
12.03.2019 16:29Я не думаю, что дело в тупости. Скорее люди просто хотят кого-то другого настолько, что готовы принять любого. Если бы Вакарчук баллотировался — у него тоже был бы высокий рейтинг. Мне так кажется.
KSA
Владимр Гройсман не зарегистрирован кандидатом на ближайшие президентские выборы.
pro100olga Автор
Вы правы, досадная ошибка с моей стороны. Поправила, спасибо!