

Нередко при диагностике проблем в кластере Kubernetes мы замечаем, что иногда моросит* один из узлов кластера и, конечно же, происходит это редко и странно. Так мы пришли к необходимости в инструменте, который бы делал ping с каждого узла на каждый узел и отдавал результаты своей работы в виде метрик Prometheus. Нам бы оставалось лишь нарисовать графики в Grafana и быстро локализовать сбойный узел (и при необходимости убрать с него все pod'ы, после чего произвести соответствующие работы**)…
* Под «моросит» я понимаю, что узел может переходить в статус
NotReady и вдруг возвращаться назад в работу. Или же, например, часть трафика в pod'ах может не доходить до pod'ов на соседних узлах.** Почему вообще такие ситуации возникают? Одной из частых причин могут быть сетевые проблемы на коммутаторе в дата-центре. К примеру, однажды в Hetzner мы настраивали vswitch, но в чудесный момент один из узлов перестал быть доступным по данному vswitch-порту: из-за этого получалось, что по локальной сети узел был полностью недоступен.
К тому же, мы хотели бы запускать такой сервис прямо в Kubernetes, чтобы весь деплой происходил с помощью установки Helm-чарта. (Предвосхищая вопросы — в случае использования того же Ansible, нам бы пришлось писать роли под различные окружения: AWS, GCE, bare metal…) Немного поискав в интернете уже готовые инструменты для поставленной задачи, мы ничего подходящего не нашли. Поэтому сделали свой.
Скрипт и конфиги
Итак, главный компонент нашего решения — скрипт, который следит за изменением у любых узлов поля
.status.addresses и, если у какого-то узла изменилось данное поле (т.е. новый узел был добавлен), с помощью Helm values передаёт в чарт данный список узлов в виде ConfigMap:---
apiVersion: v1
kind: ConfigMap
metadata:
name: node-ping-config
namespace: kube-prometheus
data:
nodes.json: >
{{ .Values.nodePing.nodes | toJson }}Сам скрипт на Python:
#!/usr/bin/env python3
import subprocess
import prometheus_client
import re
import statistics
import os
import json
import glob
import better_exchook
import datetime
better_exchook.install()
FPING_CMDLINE = "/usr/sbin/fping -p 1000 -A -C 30 -B 1 -q -r 1".split(" ")
FPING_REGEX = re.compile(r"^(\S*)\s*: (.*)$", re.MULTILINE)
CONFIG_PATH = "/config/nodes.json"
registry = prometheus_client.CollectorRegistry()
prometheus_exceptions_counter = prometheus_client.Counter('kube_node_ping_exceptions', 'Total number of exceptions', [], registry=registry)
prom_metrics = {"sent": prometheus_client.Counter('kube_node_ping_packets_sent_total',
'ICMP packets sent',
['destination_node',
'destination_node_ip_address'],
registry=registry), "received": prometheus_client.Counter(
'kube_node_ping_packets_received_total', 'ICMP packets received',
['destination_node', 'destination_node_ip_address'], registry=registry), "rtt": prometheus_client.Counter(
'kube_node_ping_rtt_milliseconds_total', 'round-trip time',
['destination_node', 'destination_node_ip_address'], registry=registry),
"min": prometheus_client.Gauge('kube_node_ping_rtt_min', 'minimum round-trip time',
['destination_node', 'destination_node_ip_address'],
registry=registry),
"max": prometheus_client.Gauge('kube_node_ping_rtt_max', 'maximum round-trip time',
['destination_node', 'destination_node_ip_address'],
registry=registry),
"mdev": prometheus_client.Gauge('kube_node_ping_rtt_mdev',
'mean deviation of round-trip times',
['destination_node', 'destination_node_ip_address'],
registry=registry)}
def validate_envs():
envs = {"MY_NODE_NAME": os.getenv("MY_NODE_NAME"), "PROMETHEUS_TEXTFILE_DIR": os.getenv("PROMETHEUS_TEXTFILE_DIR"),
"PROMETHEUS_TEXTFILE_PREFIX": os.getenv("PROMETHEUS_TEXTFILE_PREFIX")}
for k, v in envs.items():
if not v:
raise ValueError("{} environment variable is empty".format(k))
return envs
@prometheus_exceptions_counter.count_exceptions()
def compute_results(results):
computed = {}
matches = FPING_REGEX.finditer(results)
for match in matches:
ip = match.group(1)
ping_results = match.group(2)
if "duplicate" in ping_results:
continue
splitted = ping_results.split(" ")
if len(splitted) != 30:
raise ValueError("ping returned wrong number of results: \"{}\"".format(splitted))
positive_results = [float(x) for x in splitted if x != "-"]
if len(positive_results) > 0:
computed[ip] = {"sent": 30, "received": len(positive_results),
"rtt": sum(positive_results),
"max": max(positive_results), "min": min(positive_results),
"mdev": statistics.pstdev(positive_results)}
else:
computed[ip] = {"sent": 30, "received": len(positive_results), "rtt": 0,
"max": 0, "min": 0, "mdev": 0}
if not len(computed):
raise ValueError("regex match\"{}\" found nothing in fping output \"{}\"".format(FPING_REGEX, results))
return computed
@prometheus_exceptions_counter.count_exceptions()
def call_fping(ips):
cmdline = FPING_CMDLINE + ips
process = subprocess.run(cmdline, stdout=subprocess.PIPE,
stderr=subprocess.STDOUT, universal_newlines=True)
if process.returncode == 3:
raise ValueError("invalid arguments: {}".format(cmdline))
if process.returncode == 4:
raise OSError("fping reported syscall error: {}".format(process.stderr))
return process.stdout
envs = validate_envs()
files = glob.glob(envs["PROMETHEUS_TEXTFILE_DIR"] + "*")
for f in files:
os.remove(f)
labeled_prom_metrics = []
while True:
with open("/config/nodes.json", "r") as f:
config = json.loads(f.read())
if labeled_prom_metrics:
for node in config:
if (node["name"], node["ipAddress"]) not in [(metric["node_name"], metric["ip"]) for metric in labeled_prom_metrics]:
for k, v in prom_metrics.items():
v.remove(node["name"], node["ipAddress"])
labeled_prom_metrics = []
for node in config:
metrics = {"node_name": node["name"], "ip": node["ipAddress"], "prom_metrics": {}}
for k, v in prom_metrics.items():
metrics["prom_metrics"][k] = v.labels(node["name"], node["ipAddress"])
labeled_prom_metrics.append(metrics)
out = call_fping([prom_metric["ip"] for prom_metric in labeled_prom_metrics])
computed = compute_results(out)
for dimension in labeled_prom_metrics:
result = computed[dimension["ip"]]
dimension["prom_metrics"]["sent"].inc(computed[dimension["ip"]]["sent"])
dimension["prom_metrics"]["received"].inc(computed[dimension["ip"]]["received"])
dimension["prom_metrics"]["rtt"].inc(computed[dimension["ip"]]["rtt"])
dimension["prom_metrics"]["min"].set(computed[dimension["ip"]]["min"])
dimension["prom_metrics"]["max"].set(computed[dimension["ip"]]["max"])
dimension["prom_metrics"]["mdev"].set(computed[dimension["ip"]]["mdev"])
prometheus_client.write_to_textfile(
envs["PROMETHEUS_TEXTFILE_DIR"] + envs["PROMETHEUS_TEXTFILE_PREFIX"] + envs["MY_NODE_NAME"] + ".prom", registry)Он запускается на каждом узле и 2 раза в секунду отправляет ICMP-пакеты на все остальные инстансы Kubernetes-кластера, а полученные результаты записывает результаты в текстовые файлы.
Скрипт включён в Docker-образ:
FROM python:3.6-alpine3.8
COPY rootfs /
WORKDIR /app
RUN pip3 install --upgrade pip && pip3 install -r requirements.txt && apk add --no-cache fping
ENTRYPOINT ["python3", "/app/node-ping.py"]Вдобавок, был создан ServiceAccount и роль к нему, что разрешают получать только список узлов (чтобы знать их адреса):
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: node-ping
namespace: kube-prometheus
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: kube-prometheus:node-ping
rules:
- apiGroups: [""]
resources: ["nodes"]
verbs: ["list"]
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: kube-prometheus:kube-node-ping
subjects:
- kind: ServiceAccount
name: node-ping
namespace: kube-prometheus
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: kube-prometheus:node-pingНаконец, потребуется DaemonSet, который и запускается на всех инстансах кластера:
---
apiVersion: extensions/v1beta1
kind: DaemonSet
metadata:
name: node-ping
namespace: kube-prometheus
labels:
tier: monitoring
app: node-ping
version: v1
spec:
updateStrategy:
type: RollingUpdate
template:
metadata:
labels:
name: node-ping
spec:
terminationGracePeriodSeconds: 0
tolerations:
- operator: "Exists"
serviceAccountName: node-ping
priorityClassName: cluster-low
containers:
- resources:
requests:
cpu: 0.10
image: private-registry.flant.com/node-ping/node-ping-exporter:v1
imagePullPolicy: Always
name: node-ping
env:
- name: MY_NODE_NAME
valueFrom:
fieldRef:
fieldPath: spec.nodeName
- name: PROMETHEUS_TEXTFILE_DIR
value: /node-exporter-textfile/
- name: PROMETHEUS_TEXTFILE_PREFIX
value: node-ping_
volumeMounts:
- name: textfile
mountPath: /node-exporter-textfile
- name: config
mountPath: /config
volumes:
- name: textfile
hostPath:
path: /var/run/node-exporter-textfile
- name: config
configMap:
name: node-ping-config
imagePullSecrets:
- name: antiopa-registryИтоговые штрихи в словах:
- Результаты работы Python-скрипта — т.е. текстовые файлы, размещаемые на хост-машине в каталоге
/var/run/node-exporter-textfile, — попадают в DaemonSet node-exporter. В аргументах его запуска указано--collector.textfile.directory /host/textfile, где/host/textfile— это hostPath на/var/run/node-exporter-textfile. (Про textfile collector в node-exporter можно прочитать здесь.) - В итоге, node-exporter считывает эти файлы, а Prometheus собирает все данные с node-exporter.
Что получилось?
Теперь — к долгожданному результату. Когда такие метрики были созданы, мы можем на них посмотреть и, конечно, нарисовать наглядные графики. Вот как всё выглядит.
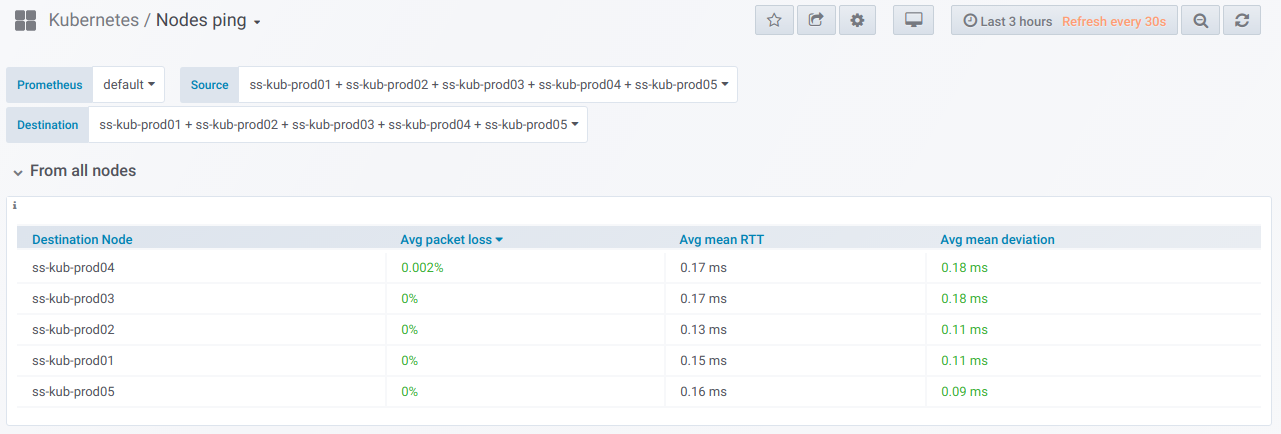
Во-первых, есть общий блок с возможностью (с помощью селектора) выбрать список узлов, с которых и на которые выполняется ping. Так выглядит сводная таблица по пингу между выбранными узлами за период, указанный в Grafana dashboard:
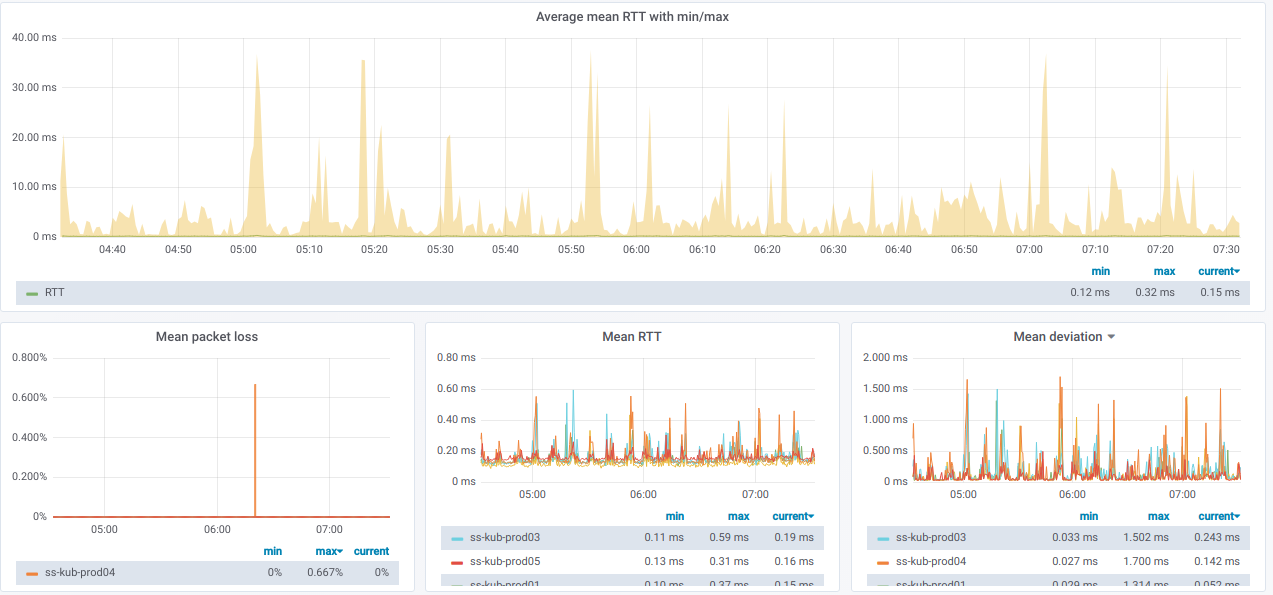
А вот графики с общей информацией по выбранным узлам:
Также у нас имеется список строк, каждая из которых — графики по одному отдельному узлу из селектора Source node:

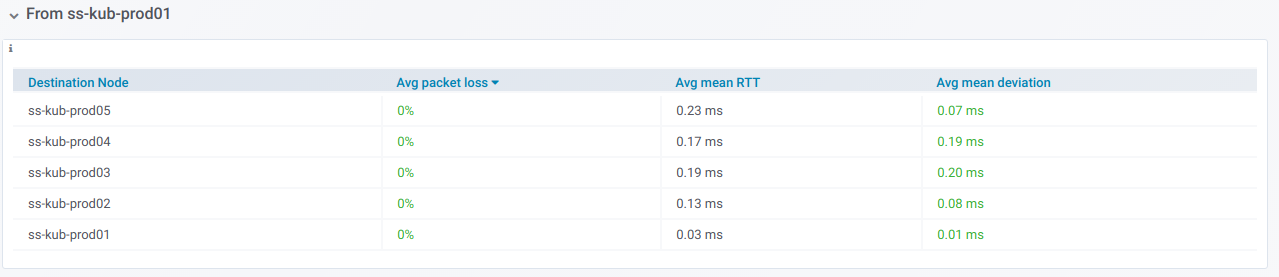
Если развернуть такую строку, то видно информацию по пингам с конкретного узла на все остальные, что были выбраны в селекторе Destination nodes:
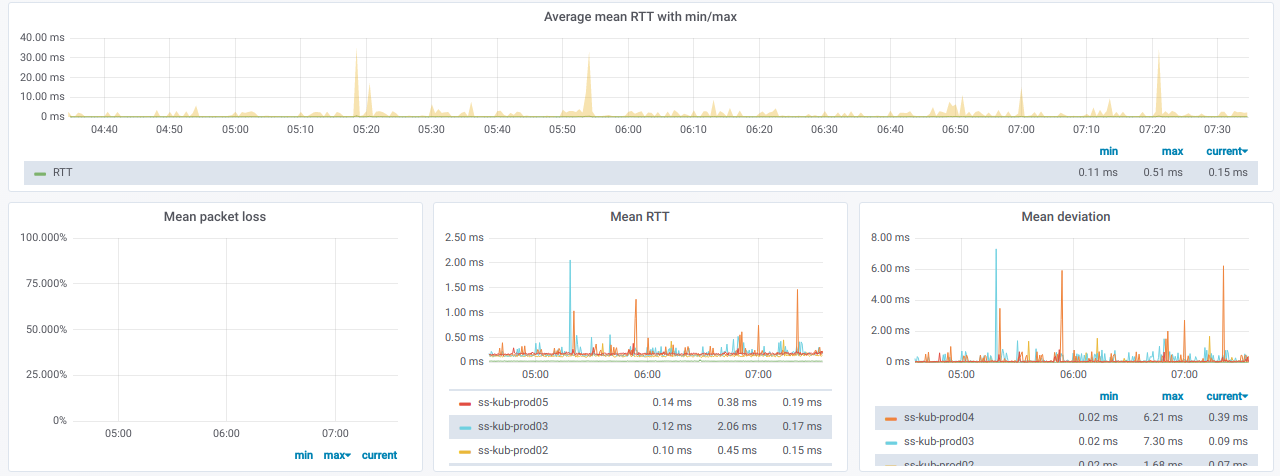
Эта информация в графиках:
Наконец, как же будут выглядеть заветные графики с плохим пингом между узлами?
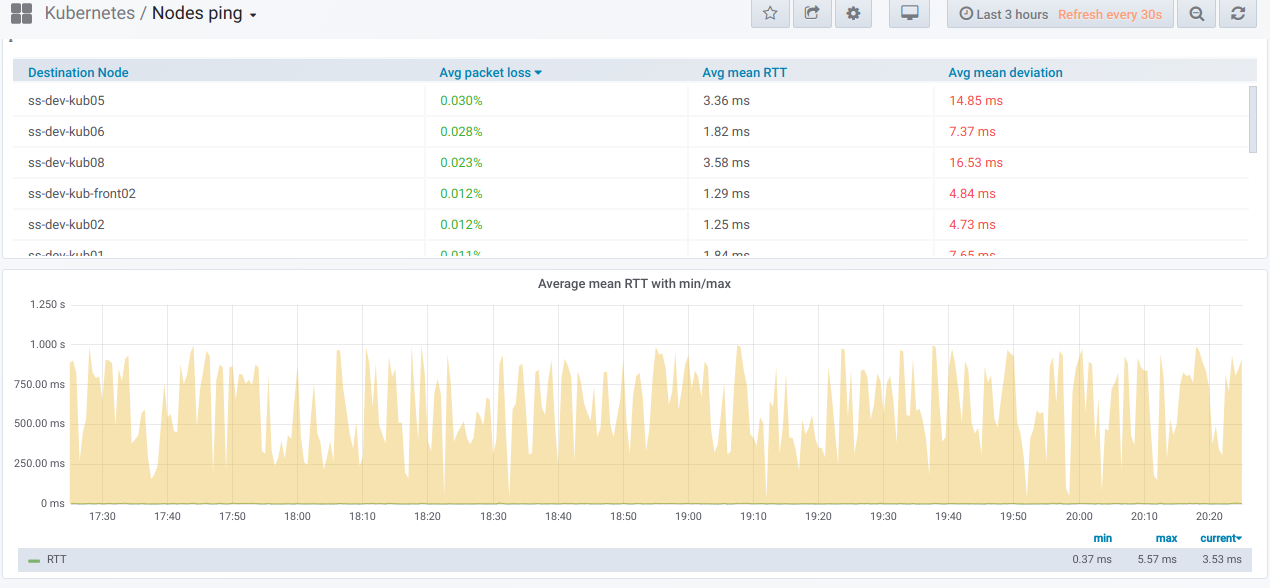
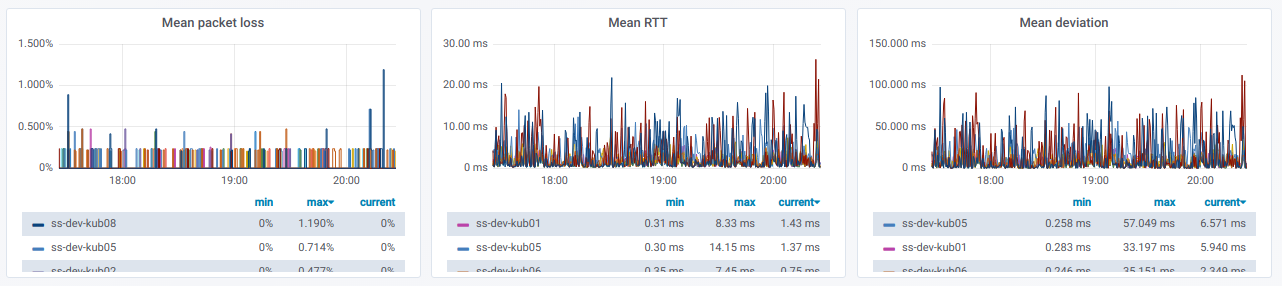
Если вы наблюдаете подобное в реальном окружении — самое время разобраться с причинами.
P.S.
Читайте также в нашем блоге:
Комментарии (10)


epicfile
12.03.2019 17:25Немного поискав в интернете уже готовые инструменты для поставленной задачи, мы ничего подходящего не нашли.
github.com/bloomberg/goldpinger
Wimbo Автор
12.03.2019 17:29Да, мы видели это, я лукавил.
НО нам не подошло это решение из-за того, что тут HTTP мониторинг. Мы хотели именно icmp — так как он более точно покажет сетевую задержку и потери, без оверхеда на стороне HTTP и userspcae процессов.
Было бы более правильно сделать PR в goldpinger, но так было быстрее и проще. Как всегда :)
whitehat
Спасибо, очень полезно для диагностики сетевых проблем k8s.
Вас не затруднит шаблон для grafana дашборда выложить?
Wimbo Автор
Конечно! Вот gist.
Там нужны минимальные правки для того чтобы оно стало рабочим (поменять datasource, исправить interval_rv на interval, возможно что-то еще)
Wimbo Автор
Или можете наложить патч для grafana с добавлением interval_rv