
Однако, все еще есть многочисленные детали, делающие задачу не столько неразрешимой, сколько… нудной, я бы сказал. Отнимающей слишком много времени, особенно если вы — новичок, которому нужно руководство, step-by-step, проект, выполненный прямо на ваших глазах, и выполненный от начала и до конца. Без обычных в таких случаях «пропустим эту очевидную часть» отговорок.
В этой статье мы рассмотрим задачу создания определителя пород собак (Dog Breed Identifier): создадим и обучим нейросеть, а затем портируем ее на Java для Android и опубликуем на Google Play.
Если вы хотите посмотреть на готовый результат, вот он: NeuroDog App на Google Play.
Веб сайт с моей робототехникой (в процессе): robotics.snowcron.com.
Веб сайт с самой программой, включая руководство: NeuroDog User Guide.
А вот скриншот программы:
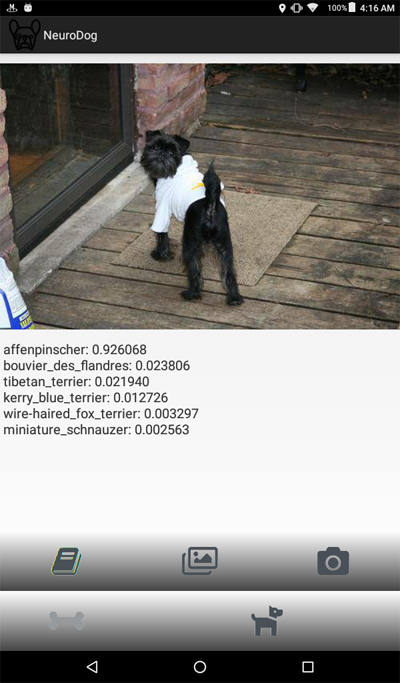
Постановка задачи
Мы будем использовать Keras: гугловскую библиотеку для работы с нейросетями. Это библиотека высокого уровня, что означает — ею проще пользоваться, по сравнению с известными мне альтернативами. Если что — в сети есть много учебников по Керас, высокого качества.
Мы будем использовать CNN — Convolutional Neural Networks. CNN (и более продвинутые конфигурации, основанные на них) являются de-facto стандартом в распознавании изображений. В то же время, обучить такую сеть не всегда просто: надо правильно подобрать структуру сети, параметры обучения (все эти learning rate, momentum, L1 and L2 и т.п.). Задача требует значительных вычислительных ресурсов, и поэтому, решить ее, просто перебрав ВСЕ параметры не получится.
Это одна из нескольких причин, по которым в большинстве случаев используют так называемый «transfer knowlege», вместо так называемого «vanilla» подхода. Transfer Knowlege использует нейросеть, обученную кем-то до нас (например, Гуглом) и обычно — для похожей, но все-таки другой задачи. Мы берем от нее начальные слои, заменяем конечные слои на свой собственный классификатор — и это работает, причем, работает прекрасно.
Поначалу подобный результат может вызвать удивление: как же так, мы взяли гугловскую сеть, обученную отличать кошек от стульев, и она нам распознает породы собак? Чтобы понять, как это происходит, нужно представлять себе основные принципы работы Deep Neural Networks, включая те, что используются для распознавания образов.
Мы «скормили» сети картинку (массив чисел, то есть) в качестве ввода. Первый слой анализирует изображение на предмет простых паттернов, вроде «горизонтальная линия», «дуга» и т.п. Следующий слой получает на вход эти паттерны, и выдает паттерны второго порядка, вроде «мех», «угол глаза»… В конечном счете, мы получаем некий паззл, из которого можно реконструировать собаку: шерсть, два глаза и человеческая рука в зубах.
Все вышеописанное было сделано с помощью предобученных слоев, полученных нами (например, от Гугла). Далее мы добавляем свои слои, и обучаем их из этих паттернов извлекать информацию о породе. Звучит логично.
Подводя итог, в этой статье мы создадим как «vanilla» CNN, так и несколько «transfer learning» вариантов сетей разных типов. Что касается «vanilla»: создать-то я ее создам, а вот настраивать, подбирая параметры, не планирую, поскольку «pre-trained» сети обучать и конфигурировать гораздо проще.
Поскольку мы планируем научить нашу нейросеть разпознавать породы собак, мы должны «показать» ей образцы различных пород. К счастью, есть набор фотографий вот здесь созданный для подобной задачи (оригинал здесь).
Потом я планирую портировать лучшую из полученных сетей под андроид. Портирование керасовских сетей под андроид относительно просто, хорошо формализовано и мы проделаем все необходимые шаги, так что воспроизвести эту часть будет несложно.
Затем мы опубликуем все это на Google Play. Естественно, Google будет сопротивляться, так что в ход пойдут дополнительные трюки. Например, размер нашего приложения (из-за громоздкой нейросети) будет больше, чем допустимый размер Android APK, принимаемый Google Play: нам придется использовать bundles. Кроме того, Google не будет показывать наше приложение в результатах поиска, это можно фиксить, прописывая поисковые тэги в приложении, либо просто подождать… неделю или две.
В результате мы получим полностью работоспособное «коммерческое» (в кавычках, так как выкладывается бесплатно) приложение для андроида и с использованием нейросетей.
Среда разработки
Программировать под Керас можно по-разному, в зависимости от OS, которую вы используете (рекомендуется Ubuntu), наличия или отсутствия видео карты и так далее. Ничего плоохого в разработке на локальном компьютере (и, соответственно, его конфигурировании) нет, за исключением того, что это — не самый простой путь.
Во-первых, установка и конфигурирование большого количества инструментов и библиотек требует времени, и потом, когда выйдут новые версии, вам придется тратить время снова. Во-вторых, нейросети требуют больших вычислительных мощностей для обучения. Вы можете ускорить (в 10 и более раз) этот процесс, если используете GPU… на момент написания данной статьи, топовые GPU, наиболее подходящие для этой работы, стоили 2000 — 7000 долларов. И да, их тоже надо конфигурировать.
Так что мы пойдем другим путем. Дело в том, что Google позволяет бедным ёжикам вроде нас использовать GPUs из своего кластера — бесплатно, для вычислений, связанных с нейросетями, он также предоставляет полностью сконфигурированное окружение, все вместе, это называется Google Colab. Сервис дает вам доступ к Jupiter Notebook с питоном, Keras и огромным количеством прочих библиотек, уже настроенных. Все, что вам нужно сделать, это получить Google account (получите Gmail account, и это даст доступ ко всему остальному).
В настоящий момент, Colab можно наяте здесь, но зная Гугл, это может измениться в любой момент. Просто погуглите «Google Colab».
Очевидная проблема с использованием Colab заключается в том, что это WEB сервис. Как нам получить доступ к НАШИМ данным? Сохранить нейросеть после обучения, например, загрузить данные, специфичные для нашей задачи и так далее?
Существует несколько (на момент написания данной статьи — три) разных способа, мы используем тот, который я полагаю наиболее удобным — мы используем Google Drive.
Google Drive это облачное хранилище данных, которое работает примерно как обычный жесткий диск, и оно может быть mapped на Google Colab (см. код ниже). После этого, вы можете работать с ним, как работали бы с файлами на локальном диске. То есть, например, чтобы получить доступ к фотографиям собак для обучения нашей нейросети, нам нужно загрузить их на Google Drive, вот и все.
Создание и обучение нейросети
Ниже я привожу код на Python, блок за блоком (из Jupiter Notebook). Вы можете копировать этот код в свой Jupiter Notebook и запустить его, тоже блок за блоком, так как блоки могут исполняться независимо (разумеется, переменные, определенные в раннем блоке могут потребоваться в позднем, но это очевидная зависимость).
Инициализация
Прежде всего, давайте подмонтируем Google Drive. Всего две строчки. Этот код должен быть выполнен за сессию Colab лишь однажды (скажем, раз за 6 часов работы). Если вы вызовете его вторично, пока сессия еще «жива», он будет пропущен, так как диск уже подмонтирован.
from google.colab import drive
drive.mount('/content/drive/')
При первом запуске, вас попросят подтвердить ваши намерения, здесь нет ничего сложного. Вот как это выглядит:
>>> Go to this URL in a browser: ...
>>> Enter your authorization code:
>>> ··········
>>> Mounted at /content/drive/
Вполне стандартная include секция; вполне возможно, что некоторые из включаемых файлов не нужны, ну… простите. Также, поскольку я собираюсь тестировать разные нейросети, вам придется comment / uncomment некоторые из включаемых модулей для конкретных типов нейросетей: например, для того, чтобы использовать InceptionV3 NN, раскомментируйте включение InceptionV3, и закомментируйте, например, ResNet50. Или нет: все, что от этого изменится, это размер используемой памяти, и то не очень сильно.
import datetime as dt
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from tqdm import tqdm
import cv2
import numpy as np
import os
import sys
import random
import warnings
from sklearn.model_selection import train_test_split
import keras
from keras import backend as K
from keras import regularizers
from keras.models import Sequential
from keras.models import Model
from keras.layers import Dense, Dropout, Activation
from keras.layers import Flatten, Conv2D
from keras.layers import MaxPooling2D
from keras.layers import BatchNormalization, Input
from keras.layers import Dropout, GlobalAveragePooling2D
from keras.callbacks import Callback, EarlyStopping
from keras.callbacks import ReduceLROnPlateau
from keras.callbacks import ModelCheckpoint
import shutil
from keras.applications.vgg16 import preprocess_input
from keras.preprocessing import image
from keras.preprocessing.image import ImageDataGenerator
from keras.models import load_model
from keras.applications.resnet50 import ResNet50
from keras.applications.resnet50 import preprocess_input
from keras.applications.resnet50 import decode_predictions
from keras.applications import inception_v3
from keras.applications.inception_v3 import InceptionV3
from keras.applications.inception_v3
import preprocess_input as inception_v3_preprocessor
from keras.applications.mobilenetv2 import MobileNetV2
from keras.applications.nasnet import NASNetMobile
На Google Drive, мы создаём папку для наших файлов. Вторая строка выводит ее содержимое:
working_path = "/content/drive/My Drive/DeepDogBreed/data/"
!ls "/content/drive/My Drive/DeepDogBreed/data"
>>> all_images labels.csv models test train valid
Как выдите, фотографии собачек (скопированные из Stanford dataset (см. выше) на Google Drive), сначала сохранены в папке all_images. Позже, мы скопируем их в директории train, valid и test. Мы будем сохранять обученные модели в фолдере models. Что касается файла labels.csv, это часть датасета с фотографиями, он содержит таблицу соответствий имен картинок и пород собак.
Есть множество тестов, которые можно прогнать, чтобы понять, что именно мы получили во временное пользование от Гугла. Например:
# Is GPU Working?
import tensorflow as tf
tf.test.gpu_device_name()
>>> '/device:GPU:0'
Как видим, GPU действительно подключен, а если нет, надо в настройках Jupiter Notebook найти и включить эту опцию.
Далее нам нужно декларировать некоторые константы, как то размер картинок и т.п. Мы будем использовать картинки размером 256x256 пикселов, это достаточно большое изображение, чтобы не потерять детали, и достаточно маленькое, чтобы все поместилось в памяти. Заметим, однако, что некоторые типы нейросетей, которые мы будем использовать, ожидают изображения размером 224x224 пиксела. В таких случаях, мы комментируем 256 и раскомментируем 224.
Тот же подход (comment one — uncomment) будет применен к именам моделей, которые мы сохраняем, просто потому, что мы не хотим перезаписывать файлы, которые еще могут пригодиться.
warnings.filterwarnings("ignore")
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
np.random.seed(7)
start = dt.datetime.now()
BATCH_SIZE = 16
EPOCHS = 15
TESTING_SPLIT=0.3 # 70/30 %
NUM_CLASSES = 120
IMAGE_SIZE = 256
#strModelFileName = "models/ResNet50.h5"
# strModelFileName = "models/InceptionV3.h5"
strModelFileName = "models/InceptionV3_Sgd.h5"
#IMAGE_SIZE = 224
#strModelFileName = "models/MobileNetV2.h5"
#IMAGE_SIZE = 224
#strModelFileName = "models/NASNetMobileSgd.h5"
Загрузка данных
Прежде всего, давайте загрузим labels.csv файл и разобьем его на training и validation части. Заметьте, что пока еще нет части testing, поскольку я собираюсь «сжульничать», чтобы получить больше данных для обучения.
labels = pd.read_csv(working_path + 'labels.csv')
print(labels.head())
train_ids, valid_ids = train_test_split(labels,
test_size = TESTING_SPLIT)
print(len(train_ids), 'train ids', len(valid_ids),
'validation ids')
print('Total', len(labels), 'testing images')
>>> id breed
>>> 0 000bec180eb18c7604dcecc8fe0dba07 boston_bull
>>> 1 001513dfcb2ffafc82cccf4d8bbaba97 dingo
>>> 2 001cdf01b096e06d78e9e5112d419397 pekinese
>>> 3 00214f311d5d2247d5dfe4fe24b2303d bluetick
>>> 4 0021f9ceb3235effd7fcde7f7538ed62 golden_retriever
>>> 7155 train ids 3067 validation ids
>>> Total 10222 testing images
Далее, копируем файлы с картинками в training/validation/testing фолдеры, в соответствии с именами файлов. Следующая функция копирует файлы, имена которых мы передаем, в указанный фолдер.
def copyFileSet(strDirFrom, strDirTo, arrFileNames):
arrBreeds = np.asarray(arrFileNames['breed'])
arrFileNames = np.asarray(arrFileNames['id'])
if not os.path.exists(strDirTo):
os.makedirs(strDirTo)
for i in tqdm(range(len(arrFileNames))):
strFileNameFrom = strDirFrom +
arrFileNames[i] + ".jpg"
strFileNameTo = strDirTo + arrBreeds[i]
+ "/" + arrFileNames[i] + ".jpg"
if not os.path.exists(strDirTo + arrBreeds[i] + "/"):
os.makedirs(strDirTo + arrBreeds[i] + "/")
# As a new breed dir is created, copy 1st file
# to "test" under name of that breed
if not os.path.exists(working_path + "test/"):
os.makedirs(working_path + "test/")
strFileNameTo = working_path + "test/" + arrBreeds[i] + ".jpg"
shutil.copy(strFileNameFrom, strFileNameTo)
shutil.copy(strFileNameFrom, strFileNameTo)
Как видите, мы только копируем один файл на каждую породу собак как test. Также при копировании, мы создаем подпапки, по одной на каждую породу. Соответственно, фотографии копируются в подпапки по породам.
Делается это потому, что Keras может работать с директорией подобной структуры, загружая файлы изображений по мере надобности, а не все сразу, что экономит память. Загружать все 15,000 картинок одновременно — плохая идея.
Вызывать эту функцию нам придется лишь однажды, поскольку она копирует изображения — и более не нужна. Соответственно, для дальнейшего использования, мы должны ее закомментировать:
# Move the data in subfolders so we can
# use the Keras ImageDataGenerator.
# This way we can also later use Keras
# Data augmentation features.
# --- Uncomment once, to copy files ---
#copyFileSet(working_path + "all_images/",
# working_path + "train/", train_ids)
#copyFileSet(working_path + "all_images/",
# working_path + "valid/", valid_ids)
Получаем список пород собак:
breeds = np.unique(labels['breed'])
map_characters = {} #{0:'none'}
for i in range(len(breeds)):
map_characters[i] = breeds[i]
print("<item>" + breeds[i] + "</item>")
>>> <item>affenpinscher</item>
>>> <item>afghan_hound</item>
>>> <item>african_hunting_dog</item>
>>> <item>airedale</item>
>>> <item>american_staffordshire_terrier</item>
>>> <item>appenzeller</item>
Обработка изображений
Мы собираемся использовать фичу библиотеки Keras, носящую название ImageDataGenerators. ImageDataGenerator может обрабатывать изображение, масштабировать, поворачивать, и так далее. Он также может принимать processing функцию, которая может обрабатывать изображения дополнительно.
def preprocess(img):
img = cv2.resize(img,
(IMAGE_SIZE, IMAGE_SIZE),
interpolation = cv2.INTER_AREA)
# or use ImageDataGenerator( rescale=1./255...
img_1 = image.img_to_array(img)
img_1 = cv2.resize(img_1, (IMAGE_SIZE, IMAGE_SIZE),
interpolation = cv2.INTER_AREA)
img_1 = np.expand_dims(img_1, axis=0) / 255.
#img = cv2.blur(img,(5,5))
return img_1[0]
Обратите внимание на следующий код:
# or use ImageDataGenerator( rescale=1./255...
Мы можем произвести нормализацию (подконку данных под диапазон 0-1 вместо исходных 0-255) в самом ImageDataGenerator. Зачем же тогда нам нужен preprocessor? В качестве примера, рассмотрим (закомментированный, я его не использую) вызов blur: это та самая custom image manipulation, которая может быть произвольной. Что угодно, от контрастирования до HDR.
Мы будем использовать два разных ImageDataGenerators, один для обучения, и второй для validation. Разница в том, что для обучения нам нужны повороты и масштабирование, чтобы увеличить «разнообразие» данных, а вот для валидации — не нужны, по крайней мере, не в этой задаче.
train_datagen = ImageDataGenerator(
preprocessing_function=preprocess,
#rescale=1./255, # done in preprocess()
# randomly rotate images (degrees, 0 to 30)
rotation_range=30,
# randomly shift images horizontally
# (fraction of total width)
width_shift_range=0.3,
height_shift_range=0.3,
# randomly flip images
horizontal_flip=True,
,vertical_flip=False,
zoom_range=0.3)
val_datagen = ImageDataGenerator(
preprocessing_function=preprocess)
train_gen = train_datagen.flow_from_directory(
working_path + "train/",
batch_size=BATCH_SIZE,
target_size=(IMAGE_SIZE, IMAGE_SIZE),
shuffle=True,
class_mode="categorical")
val_gen = val_datagen.flow_from_directory(
working_path + "valid/",
batch_size=BATCH_SIZE,
target_size=(IMAGE_SIZE, IMAGE_SIZE),
shuffle=True,
class_mode="categorical")
Создание нейросети
Как уже упоминалось, мы собираемся создать несколько типов нейросетей. Каждый раз мы будем вызывать другую функцию для создания, включать другие файлы и иногда определять другой размер изображения. Так что, для переключения между разными типами нейросетей, мы должны comment/uncomment соответствующий код.
Прежде всего, создадим «vanilla» CNN. Он работает плохо, поскольку я решил не тратить время на его доводку, но по крайней мере, он предоставляет основу, которую можно развивать, есл иесть желание (обычно, это плохая идея, поскольку предобученные сети дают лучший результат).
def createModelVanilla():
model = Sequential()
# Note the (7, 7) here. This is one of technics
# used to reduce memory use by the NN: we scan
# the image in a larger steps.
# Also note regularizers.l2: this technic is
# used to prevent overfitting. The "0.001" here
# is an empirical value and can be optimized.
model.add(Conv2D(16, (7, 7), padding='same',
use_bias=False,
input_shape=(IMAGE_SIZE, IMAGE_SIZE, 3),
kernel_regularizer=regularizers.l2(0.001)))
# Note the use of a standard CNN building blocks:
# Conv2D - BatchNormalization - Activation
# MaxPooling2D - Dropout
# The last two are used to avoid overfitting, also,
# MaxPooling2D reduces memory use.
model.add(BatchNormalization(axis=3, scale=False))
model.add(Activation("relu"))
model.add(MaxPooling2D(pool_size=(2, 2),
strides=(2, 2), padding='same'))
model.add(Dropout(0.5))
model.add(Conv2D(16, (3, 3), padding='same',
use_bias=False,
kernel_regularizer=regularizers.l2(0.01)))
model.add(BatchNormalization(axis=3, scale=False))
model.add(Activation("relu"))
model.add(MaxPooling2D(pool_size=(2, 2),
strides=(1, 1), padding='same'))
model.add(Dropout(0.5))
model.add(Conv2D(32, (3, 3), padding='same',
use_bias=False,
kernel_regularizer=regularizers.l2(0.01)))
model.add(BatchNormalization(axis=3, scale=False))
model.add(Activation("relu"))
model.add(Dropout(0.5))
model.add(Conv2D(32, (3, 3), padding='same',
use_bias=False,
kernel_regularizer=regularizers.l2(0.01)))
model.add(BatchNormalization(axis=3, scale=False))
model.add(Activation("relu"))
model.add(MaxPooling2D(pool_size=(2, 2),
strides=(1, 1), padding='same'))
model.add(Dropout(0.5))
model.add(Conv2D(64, (3, 3), padding='same',
use_bias=False,
kernel_regularizer=regularizers.l2(0.01)))
model.add(BatchNormalization(axis=3, scale=False))
model.add(Activation("relu"))
model.add(Dropout(0.5))
model.add(Conv2D(64, (3, 3), padding='same',
use_bias=False,
kernel_regularizer=regularizers.l2(0.01)))
model.add(BatchNormalization(axis=3, scale=False))
model.add(Activation("relu"))
model.add(MaxPooling2D(pool_size=(2, 2),
strides=(1, 1), padding='same'))
model.add(Dropout(0.5))
model.add(Conv2D(128, (3, 3), padding='same',
use_bias=False,
kernel_regularizer=regularizers.l2(0.01)))
model.add(BatchNormalization(axis=3, scale=False))
model.add(Activation("relu"))
model.add(Dropout(0.5))
model.add(Conv2D(128, (3, 3), padding='same',
use_bias=False,
kernel_regularizer=regularizers.l2(0.01)))
model.add(BatchNormalization(axis=3, scale=False))
model.add(Activation("relu"))
model.add(MaxPooling2D(pool_size=(2, 2),
strides=(1, 1), padding='same'))
model.add(Dropout(0.5))
model.add(Conv2D(256, (3, 3), padding='same',
use_bias=False,
kernel_regularizer=regularizers.l2(0.01)))
model.add(BatchNormalization(axis=3, scale=False))
model.add(Activation("relu"))
model.add(Dropout(0.5))
model.add(Conv2D(256, (3, 3), padding='same',
use_bias=False,
kernel_regularizer=regularizers.l2(0.01)))
model.add(BatchNormalization(axis=3, scale=False))
model.add(Activation("relu"))
model.add(MaxPooling2D(pool_size=(2, 2),
strides=(1, 1), padding='same'))
model.add(Dropout(0.5))
# This is the end on "convolutional" part of CNN.
# Now we need to transform multidementional
# data into one-dim. array for a fully-connected
# classifier:
model.add(Flatten())
# And two layers of classifier itself (plus an
# Activation layer in between):
model.add(Dense(NUM_CLASSES, activation='softmax',
kernel_regularizer=regularizers.l2(0.01)))
model.add(Activation("relu"))
model.add(Dense(NUM_CLASSES, activation='softmax',
kernel_regularizer=regularizers.l2(0.01)))
# We need to compile the resulting network.
# Note that there are few parameters we can
# try here: the best performing one is uncommented,
# the rest is commented out for your reference.
#model.compile(optimizer='rmsprop',
# loss='categorical_crossentropy',
# metrics=['accuracy'])
#model.compile(
# optimizer=keras.optimizers.RMSprop(lr=0.0005),
# loss='categorical_crossentropy',
# metrics=['accuracy'])
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
#model.compile(optimizer='adadelta',
# loss='categorical_crossentropy',
# metrics=['accuracy'])
#opt = keras.optimizers.Adadelta(lr=1.0,
# rho=0.95, epsilon=0.01, decay=0.01)
#model.compile(optimizer=opt,
# loss='categorical_crossentropy',
# metrics=['accuracy'])
#opt = keras.optimizers.RMSprop(lr=0.0005,
# rho=0.9, epsilon=None, decay=0.0001)
#model.compile(optimizer=opt,
# loss='categorical_crossentropy',
# metrics=['accuracy'])
# model.summary()
return(model)
Когда мы создаем сети, используя transfer learning, процедура меняется:
def createModelMobileNetV2():
# First, create the NN and load pre-trained
# weights for it ('imagenet')
# Note that we are not loading last layers of
# the network (include_top=False), as we are
# going to add layers of our own:
base_model = MobileNetV2(weights='imagenet',
include_top=False, pooling='avg',
input_shape=(IMAGE_SIZE, IMAGE_SIZE, 3))
# Then attach our layers at the end. These are
# to build "classifier" that makes sense of
# the patterns previous layers provide:
x = base_model.output
x = Dense(512)(x)
x = Activation('relu')(x)
x = Dropout(0.5)(x)
predictions = Dense(NUM_CLASSES,
activation='softmax')(x)
# Create a model
model = Model(inputs=base_model.input,
outputs=predictions)
# We need to make sure that pre-trained
# layers are not changed when we train
# our classifier:
# Either this:
#model.layers[0].trainable = False
# or that:
for layer in base_model.layers:
layer.trainable = False
# As always, there are different possible
# settings, I tried few and chose the best:
# model.compile(optimizer='adam',
# loss='categorical_crossentropy',
# metrics=['accuracy'])
model.compile(optimizer='sgd',
loss='categorical_crossentropy',
metrics=['accuracy'])
#model.summary()
return(model)
Создание сетей других типов следует тому же шаблону:
def createModelResNet50():
base_model = ResNet50(weights='imagenet',
include_top=False, pooling='avg',
input_shape=(IMAGE_SIZE, IMAGE_SIZE, 3))
x = base_model.output
x = Dense(512)(x)
x = Activation('relu')(x)
x = Dropout(0.5)(x)
predictions = Dense(NUM_CLASSES,
activation='softmax')(x)
model = Model(inputs=base_model.input,
outputs=predictions)
#model.layers[0].trainable = False
# model.compile(loss='categorical_crossentropy',
# optimizer='adam', metrics=['accuracy'])
model.compile(optimizer='sgd',
loss='categorical_crossentropy',
metrics=['accuracy'])
#model.summary()
return(model)
Внимание: победитель! Эта NN показала лучший результат:
def createModelInceptionV3():
# model.layers[0].trainable = False
# model.compile(optimizer='sgd',
# loss='categorical_crossentropy',
# metrics=['accuracy'])
base_model = InceptionV3(weights = 'imagenet',
include_top = False,
input_shape=(IMAGE_SIZE, IMAGE_SIZE, 3))
x = base_model.output
x = GlobalAveragePooling2D()(x)
x = Dense(512, activation='relu')(x)
predictions = Dense(NUM_CLASSES,
activation='softmax')(x)
model = Model(inputs = base_model.input,
outputs = predictions)
for layer in base_model.layers:
layer.trainable = False
# model.compile(optimizer='adam',
# loss='categorical_crossentropy',
# metrics=['accuracy'])
model.compile(optimizer='sgd',
loss='categorical_crossentropy',
metrics=['accuracy'])
#model.summary()
return(model)
Еще одна:
def createModelNASNetMobile():
# model.layers[0].trainable = False
# model.compile(optimizer='sgd',
# loss='categorical_crossentropy',
# metrics=['accuracy'])
base_model = NASNetMobile(weights = 'imagenet',
include_top = False,
input_shape=(IMAGE_SIZE, IMAGE_SIZE, 3))
x = base_model.output
x = GlobalAveragePooling2D()(x)
x = Dense(512, activation='relu')(x)
predictions = Dense(NUM_CLASSES,
activation='softmax')(x)
model = Model(inputs = base_model.input,
outputs = predictions)
for layer in base_model.layers:
layer.trainable = False
# model.compile(optimizer='adam',
# loss='categorical_crossentropy',
# metrics=['accuracy'])
model.compile(optimizer='sgd',
loss='categorical_crossentropy',
metrics=['accuracy'])
#model.summary()
return(model)
Разные типы нейросетей могут быть использованы для разных задач. Так, в дополнение к требованиям точности предсказания, размер может иметь значение (mobile NN в 5 раз меньше, чем Inception) и скорость (если нам нужна обработка видео потока в реальном времени, то точностью придется пожертвовать).
Обучение нейросети
Прежде всего, мы экспериментируем, поэтому мы должны иметь возможность удалить нейросети, которые мы сохранили, но более не используем. Следующая функция удаляет NN, если она существует:
# Make sure that previous "best network" is deleted.
def deleteSavedNet(best_weights_filepath):
if(os.path.isfile(best_weights_filepath)):
os.remove(best_weights_filepath)
print("deleteSavedNet():File removed")
else:
print("deleteSavedNet():No file to remove")
То, как мы создаем и удаляем нейросети, достаточно просто и прямолинейно. Сначала удаляем. При вызове delete (только), следует иметь в виду, что у Jupiter Notebook есть функция «run selection» выделите только то, что хотите использовать, и запускайте.
Затем мы создаем нейросеть, если ее файл не существовал, или вызываем load, если он есть: разумеется, мы не можем вызвать «delete» и затем ожидать, что NN существует, так что, чтобы использовать сохраненную нейросеть, не вызывайтеdelete.
Другими словами, мы можем создать новую NN, либо использовать существующую, в зависимости от ситуации и от того, с чем мы в данный момент экспериментируем. Простой сценарий: мы обучили нейросеть, затем уехали в отпуск. Вернулись, а Google прибил сессию, так что нам надо загрузить, сохраненную ранее: закомментируйте «delete» и раскомментируйте «load».
deleteSavedNet(working_path + strModelFileName)
#if not os.path.exists(working_path + "models"):
# os.makedirs(working_path + "models")
#
#if not os.path.exists(working_path +
# strModelFileName):
# model = createModelResNet50()
model = createModelInceptionV3()
# model = createModelMobileNetV2()
# model = createModelNASNetMobile()
#else:
# model = load_model(working_path + strModelFileName)
Checkpoints это очень важный элемент нашей программы. Мы можем создать массив функций, которые должны вызываться в конце каждой эпохи обучения, и передать его в чекпойнт. Например, можно сохранить нейросеть если она показывает результаты, лучшие чем у уже сохраненной.
checkpoint = ModelCheckpoint(working_path +
strModelFileName, monitor='val_acc',
verbose=1, save_best_only=True,
mode='auto', save_weights_only=False)
callbacks_list = [ checkpoint ]
Наконец, учим нейросеть на training наборе:
# Calculate sizes of training and validation sets
STEP_SIZE_TRAIN=train_gen.n//train_gen.batch_size
STEP_SIZE_VALID=val_gen.n//val_gen.batch_size
# Set to False if we are experimenting with
# some other part of code, use history that
# was calculated before (and is still in
# memory
bDoTraining = True
if bDoTraining == True:
# model.fit_generator does the actual training
# Note the use of generators and callbacks
# that were defined earlier
history = model.fit_generator(generator=train_gen,
steps_per_epoch=STEP_SIZE_TRAIN,
validation_data=val_gen,
validation_steps=STEP_SIZE_VALID,
epochs=EPOCHS,
callbacks=callbacks_list)
# --- After fitting, load the best model
# This is important as otherwise we'll
# have the LAST model loaded, not necessarily
# the best one.
model.load_weights(working_path + strModelFileName)
# --- Presentation part
# summarize history for accuracy
plt.plot(history.history['acc'])
plt.plot(history.history['val_acc'])
plt.title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['acc', 'val_acc'], loc='upper left')
plt.show()
# summarize history for loss
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['loss', 'val_loss'], loc='upper left')
plt.show()
# As grid optimization of NN would take too long,
# I did just few tests with different parameters.
# Below I keep results, commented out, in the same
# code. As you can see, Inception shows the best
# results:
# Inception:
# adam: val_acc 0.79393
# sgd: val_acc 0.80892
# Mobile:
# adam: val_acc 0.65290
# sgd: Epoch 00015: val_acc improved from 0.67584 to 0.68469
# sgd-30 epochs: 0.68
# NASNetMobile, adam: val_acc did not improve from 0.78335
# NASNetMobile, sgd: 0.8
Графики для accuracy и loss для лучшей из конфигураций выглядят следующим образом:
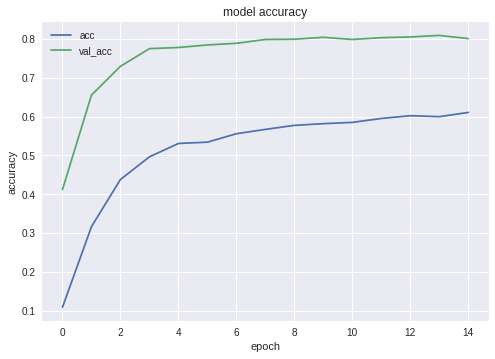

Как видите, нейросеть учится, и весьма неплохо.
Тестирование нейросети
После того, как обучение завершено, мы должны протестировать результат; для этого NN предъявляются картинки, которых она никогда ранее не видела — те, что мы скопировали в фолдер testing — по одной для каждой породы собак.
# --- Test
j = 0
# Final cycle performs testing on the entire
# testing set.
for file_name in os.listdir(
working_path + "test/"):
img = image.load_img(working_path + "test/"
+ file_name);
img_1 = image.img_to_array(img)
img_1 = cv2.resize(img_1, (IMAGE_SIZE, IMAGE_SIZE),
interpolation = cv2.INTER_AREA)
img_1 = np.expand_dims(img_1, axis=0) / 255.
y_pred = model.predict_on_batch(img_1)
# get 5 best predictions
y_pred_ids = y_pred[0].argsort()[-5:][::-1]
print(file_name)
for i in range(len(y_pred_ids)):
print("\n\t" + map_characters[y_pred_ids[i]]
+ " ("
+ str(y_pred[0][y_pred_ids[i]]) + ")")
print("--------------------\n")
j = j + 1
Экспорт нейросети в Java приложение
Прежде всего, нам нужно организовать загрузку нейросети с диска. Причина понятна: экспорт происходит в другом блоке кода, так что скорее всего, мы будем запускать экспорт отдельно — когда нейросеть будет доведена до оптимального состояния. То есть, непосредственно перед экспортом, в тот же прогон программы, мы сеть обучать не будем. Если вы будете использовать приведенный здесь код, то разницы нет, оптимальную сеть подобрали до вас. А вот если вы будете учить что-то свое, то тренировать все заново перед сохранением — пустая трата времени, если до этого вы все сохранили.
# Test: load and run
model = load_model(working_path + strModelFileName)
По этой же причине — чтобы не прыгать по коду — я включаю необходимые для экспорта файлы здесь. Никто не мешает вам передвинуть их в начало программы, если того требует ваше чувство прекрасного:
from keras.models import Model
from keras.models import load_model
from keras.layers import *
import os
import sys
import tensorflow as tf
Небольшой тест после загрузки нейросети, просто чтобы убедиться, что все загруженное — работает:
img = image.load_img(working_path
+ "test/affenpinscher.jpg") #basset.jpg")
img_1 = image.img_to_array(img)
img_1 = cv2.resize(img_1,
(IMAGE_SIZE, IMAGE_SIZE),
interpolation = cv2.INTER_AREA)
img_1 = np.expand_dims(img_1, axis=0) / 255.
y_pred = model.predict(img_1)
Y_pred_classes = np.argmax(y_pred,axis = 1)
# print(y_pred)
fig, ax = plt.subplots()
ax.imshow(img)
ax.axis('off')
ax.set_title(map_characters[Y_pred_classes[0]])
plt.show()

Далее, нам нужно получить имена входного (input) и выходного (output) слоев сети (либо так, либо в функции создания мы должны явным образом «назвать» слои, чего мы не сделали).
model.summary()
>>> Layer (type)
>>> ======================
>>> input_7 (InputLayer)
>>> ______________________
>>> conv2d_283 (Conv2D)
>>> ______________________
>>> ...
>>> dense_14 (Dense)
>>> ======================
>>> Total params: 22,913,432
>>> Trainable params: 1,110,648
>>> Non-trainable params: 21,802,784
Мы будем использовать имена входного и выходного слоев позже, когда будем импортировать нейросеть в Java приложение.
В сети бродит еще один код для получения этих данных:
def print_graph_nodes(filename):
g = tf.GraphDef()
g.ParseFromString(open(filename, 'rb').read())
print()
print(filename)
print("=======================INPUT===================")
print([n for n in g.node if n.name.find('input') != -1])
print("=======================OUTPUT==================")
print([n for n in g.node if n.name.find('output') != -1])
print("===================KERAS_LEARNING==============")
print([n for n in g.node if n.name.find('keras_learning_phase') != -1])
print("===============================================")
print()
#def get_script_path():
# return os.path.dirname(os.path.realpath(sys.argv[0]))
Но мне он не нравится и я его не рекомендую.
Следующий код экспортируем Keras Neural Network в pb формат, тот, что мы будем захватывать из Android.
def keras_to_tensorflow(keras_model, output_dir,
model_name,out_prefix="output_",
log_tensorboard=True):
if os.path.exists(output_dir) == False:
os.mkdir(output_dir)
out_nodes = []
for i in range(len(keras_model.outputs)):
out_nodes.append(out_prefix + str(i + 1))
tf.identity(keras_model.output[i],
out_prefix + str(i + 1))
sess = K.get_session()
from tensorflow.python.framework import graph_util
from tensorflow.python.framework graph_io
init_graph = sess.graph.as_graph_def()
main_graph =
graph_util.convert_variables_to_constants(
sess, init_graph, out_nodes)
graph_io.write_graph(main_graph, output_dir,
name=model_name, as_text=False)
if log_tensorboard:
from tensorflow.python.tools
import import_pb_to_tensorboard
import_pb_to_tensorboard.import_to_tensorboard(
os.path.join(output_dir, model_name),
output_dir)
Вызов этих функций для экспорта нейросети:
model = load_model(working_path
+ strModelFileName)
keras_to_tensorflow(model,
output_dir=working_path + strModelFileName,
model_name=working_path + "models/dogs.pb")
print_graph_nodes(working_path + "models/dogs.pb")
Последняя строка печатает структуру полученной нейросети.
Создание Android приложения использующего нейросети
Экспорт нейросетей в Android хорошо формализован и не должен вызывать затруднений. Есть, как всегда, несколько способов, мы используем наиболее (на момент написания статьи) популярный.
Прежде всего, используем Android Studio чтобы создать новый проект. Мы будем «срезать углы», поскольку наша задача — не учебник по андроиду. Так что приложение будет содержать лишь одну activity.

Как видите, мы добавили фолдер «assets» и скопировали в него нашу нейросеть (ту, что до этого экспортировали).
Файл Gradle
В этом файле надо сделать несколько изменений. Прежде всего, нам нужно импортировать библиотеку tensorflow-android. Она используется для того, чтобы работать с Tensorflow (и, соответственно, Keras) из Java:
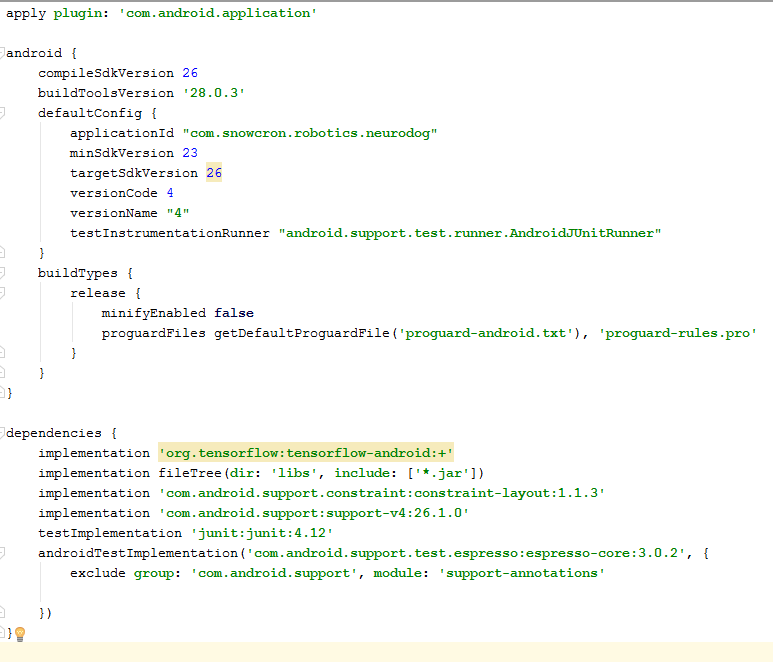
Еще один неочевидный камень преткновения: versionCode и versionName. Когда приложение будет меняться, вам нужно будет выкладывать новые версии в Google Play. Без изменения версий в gdadle (например, 1 -> 2 -> 3...) вы не сможете этого сделать, Гугл будет выдавать ошибку «эта версия уже есть».
Манифест
Прежде всего, наше приложение будет «тяжелым» — 100 Mb Neural Network легко поместится в память современных сотовых телефонов, но открывать отдельный instance для каждой фотографии «расшаренной» из Facebook определенно является плохой идеей.
Так что мы запрещаем создавать более одного instance нашего приложения:
<activity android:name=".MainActivity"
android:launchMode="singleTask">
Добавив android:launchMode=«singleTask» к MainActivity, мы говорим Android, что надо открывать (активировать) существующую копию приложения, вместо того, чтобы создавать еще одну instance.
Затем нам нужно включить наше приложение в список, который система показывает, когда кто-то «расшаривает» картинку:
<intent-filter>
<!-- Send action required to display
activity in share list -->
<action android:name="android.intent.action.SEND" />
<!-- Make activity default to launch -->
<category android:name="android.intent.category.DEFAULT" />
<!-- Mime type i.e. what can be shared with
this activity only image and text -->
<data android:mimeType="image/*" />
</intent-filter>
Наконец, нам нужно запросить фичи и разрешения, которые будет использовать наше приложение:
<uses-feature
android:name="android.hardware.camera"
android:required="true" />
<uses-permission android:name=
"android.permission.WRITE_EXTERNAL_STORAGE" />
<uses-permission
android:name="android.permission.READ_PHONE_STATE"
tools:node="remove" />
Если вы знакомы с программированием под Android, эта часть не должна вызвать вопросов.
Layout приложения.
Мы создадим два layouts, один для портретной, и второй для альбомной ориентации. Так выглядит Portrait layout.
Что мы впдим: большое поле (view) чтобы показывать картинку, надоедливый список рекламы (показывается, когда нажата кнопка с «косточкой»), кнопка «Help», кнопки для загрузки картинки из File/Gallery и захвата с камеры, и наконец (изначально скрытая) кнопка «Process» для обработки картинки.
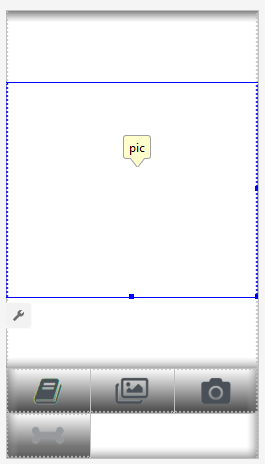
Активность сама по себе содержит всю логику показа и скрытия, а также enabling/disabling кнопок, в зависимости от состояния приложения.
MainActivity
Это activity наследует (extends) стандартное Android Activity:
public class MainActivity extends Activity
Рассмотрим код, ответственный за работу нейросети.
Прежде всего, нейросеть принимает Bitmap. Изначально, это большой Bitmap (произвольного размера) от камеры или из файла (m_bitmap), потом мы трансформируем его, приводя к стандарту 256x256 пикселей (m_bitmapForNn). Мы также храним размер битмапа (256) в константе:
static Bitmap m_bitmap = null;
static Bitmap m_bitmapForNn = null;
private int m_nImageSize = 256;
Мы должны сообщить нейросети имена входного и выходного слоев; мы получили их ранее (см. листинг), но имейте в виду, что в вашем случае они могут отличаться:
private String INPUT_NAME = "input_7_1";
private String OUTPUT_NAME = "output_1";
Затем мы декларируем переменную для хранения объекта TensofFlow. Также, мы храним путь к файлу нейросети (который лежит в assets):
private TensorFlowInferenceInterface tf; private String MODEL_PATH = "file:///android_asset/dogs.pb";
Породы собак храним в списке, чтобы потом показать пользователю их, а не индексы массива:
private String[] m_arrBreedsArray;
Изначально, мы загрузили Bitmap. Однако, нейросеть ожидает массив RGB значений, а ее выход — это массив вероятностей того, что данная порода — это то, что показано на картинке. Соответственно, нам нужно добавить еще два массива (заметьте, что 120 это число пород собак, присутствующих в наших обучающих данных):
private float[] m_arrPrediction = new float[120];
private float[] m_arrInput = null;
Загружаем tensorflow inference library:
static
{
System.loadLibrary("tensorflow_inference");
}
Так как нейросетевые операции требуют времени, то нам нужно выполнить их в отдельном потоке, иначе есть шанс, что мы получим системное сообщение «приложение не отзывается», на говоря уже о недовольном пользователе.
class PredictionTask extends
AsyncTask<Void, Void, Void>
{
@Override
protected void onPreExecute()
{
super.onPreExecute();
}
// ---
@Override
protected Void doInBackground(Void... params)
{
try
{
# We get RGB values packed in integers
# from the Bitmap, then break those
# integers into individual triplets
m_arrInput = new float[
m_nImageSize * m_nImageSize * 3];
int[] intValues = new int[
m_nImageSize * m_nImageSize];
m_bitmapForNn.getPixels(intValues, 0,
m_nImageSize, 0, 0, m_nImageSize,
m_nImageSize);
for (int i = 0; i < intValues.length; i++)
{
int val = intValues[i];
m_arrInput[i * 3 + 0] =
((val >> 16) & 0xFF) / 255f;
m_arrInput[i * 3 + 1] =
((val >> 8) & 0xFF) / 255f;
m_arrInput[i * 3 + 2] =
(val & 0xFF) / 255f;
}
// ---
tf = new TensorFlowInferenceInterface(
getAssets(), MODEL_PATH);
//Pass input into the tensorflow
tf.feed(INPUT_NAME, m_arrInput, 1,
m_nImageSize, m_nImageSize, 3);
//compute predictions
tf.run(new String[]{OUTPUT_NAME}, false);
//copy output into PREDICTIONS array
tf.fetch(OUTPUT_NAME, m_arrPrediction);
}
catch (Exception e)
{
e.getMessage();
}
return null;
}
// ---
@Override
protected void onPostExecute(Void result)
{
super.onPostExecute(result);
// ---
enableControls(true);
// ---
tf = null;
m_arrInput = null;
# strResult contains 5 lines of text
# with most probable dog breeds and
# their probabilities
m_strResult = "";
# What we do below is sorting the array
# by probabilities (using map)
# and getting in reverse order) the
# first five entries
TreeMap<Float, Integer> map =
new TreeMap<Float, Integer>(
Collections.reverseOrder());
for(int i = 0; i < m_arrPrediction.length;
i++)
map.put(m_arrPrediction[i], i);
int i = 0;
for (TreeMap.Entry<Float, Integer>
pair : map.entrySet())
{
float key = pair.getKey();
int idx = pair.getValue();
String strBreed = m_arrBreedsArray[idx];
m_strResult += strBreed + ": " +
String.format("%.6f", key) + "\n";
i++;
if (i > 5)
break;
}
m_txtViewBreed.setVisibility(View.VISIBLE);
m_txtViewBreed.setText(m_strResult);
}
}
In onCreate() of the MainActivity, we need to add the onClickListener for the «Process» button:
m_btn_process.setOnClickListener(new View.OnClickListener()
{
@Override
public void onClick(View v)
{
processImage();
}
});
Здесь processImage() просто вызывает поток, который мы описали выше:
private void processImage()
{
try
{
enableControls(false);
// ---
PredictionTask prediction_task
= new PredictionTask();
prediction_task.execute();
}
catch (Exception e)
{
e.printStackTrace();
}
}
Дополнительные замечания
Мы не планируем обсуждать детали UI-программирования под Андроид, поскольку это совершенно точно не относится к задаче портирования нейросетей. Однако, одну вещь все же упомянем.
Когда мы предотвратили создание дополнительных instances нашего приложения, мы также заодно сломали нормальный порядок создания и удаления активности (flow of control): если вы «расшарите» картинку из Facebook, а затем расшарите еще одну, то приложение не перезапустится. Это значит, что «традиционный» способ ловли переданных данных в onCreate будет недостаточен, поскольку onCreate не будет вызван.
Вот как можно решить эту проблему:
1. В onCreate в MainActivity, вызываем функцию onSharedIntent:
protected void onCreate(
Bundle savedInstanceState)
{
super.onCreate(savedInstanceState);
....
onSharedIntent();
....
Также добавляем обработчик для onNewIntent:
@Override
protected void onNewIntent(Intent intent)
{
super.onNewIntent(intent);
setIntent(intent);
onSharedIntent();
}
Вот сама функция onSharedIntent:
private void onSharedIntent()
{
Intent receivedIntent = getIntent();
String receivedAction =
receivedIntent.getAction();
String receivedType = receivedIntent.getType();
if (receivedAction.equals(Intent.ACTION_SEND))
{
// If mime type is equal to image
if (receivedType.startsWith("image/"))
{
m_txtViewBreed.setText("");
m_strResult = "";
Uri receivedUri =
receivedIntent.getParcelableExtra(
Intent.EXTRA_STREAM);
if (receivedUri != null)
{
try
{
Bitmap bitmap =
MediaStore.Images.Media.getBitmap(
this.getContentResolver(),
receivedUri);
if(bitmap != null)
{
m_bitmap = bitmap;
m_picView.setImageBitmap(m_bitmap);
storeBitmap();
enableControls(true);
}
}
catch (Exception e)
{
e.printStackTrace();
}
}
}
}
}
Теперь мы обрабатываем переданные данные в onCreate (если приложения не было в памяти) либо в onNewIntent (если оно было запущено ранее).
Удачи! Если вам понравилась статья, пожалуйста, «лайкните» ее всеми возможными способами, «социальные» кнопки есть также на сайте.
Комментарии (34)

amarao
16.04.2019 14:03Попробовал. Уровень угадывания совершенно неприличный — для одной и той же собаки породы гуляют так, что я могу это написать в две строки с
random.choice(). Можно даже без фотографии.
FizpokPak Автор
16.04.2019 20:28+1Я правильно понимаю, что собака не породистая? Я не кинолог, но судя по фотке :) Если так, то вероятности будут гулять — это нормально.

kloppspb
16.04.2019 16:25Предлагаю обратную задачу :) Угадать, фотки каких пород были показаны, если выводы (неправильные) были сделаны:
1)
тибетский терьер 0,446979
шотландский терьер 0,196114
гигантский шнауцер 0,190018
керри блю терьер 0,110089
минишнауцер 0,018280
аффенпинчер 0,014331
2)
керри блю терьер 0,644562
гигантский шнауцер 0,289565
фландрский бувье 0,051159
миттельшнауцер 0,005855
минишнауцер 0,005740
шотландский терьер 0,002523
Не спорю, задачка не из простых, и породы во многом похожи. Но фото честные, чёткие, человеческий глаз моментально поймёт какая имено это порода, при условии что он хоть немного разбирается, конечно. Интересно оценить пороговые различия, при которых AI в принципе может справиться.FizpokPak Автор
16.04.2019 20:29Можно попросить фотки? В приват, например. Потому, что если вероятность определения меньше 0.9Х, значит нейросеть вообще не знает этого зверя. Вероятно, микс.
kloppspb
16.04.2019 20:35Сейчас пришлю. В обоих случаях типичные представители: 1) русская болонка чёрного цвета — гигантский шнауцер, ага :) 2) русский чёрный терьер — минишнауцер, тоже прикольно :) А может и правда не знает таких пород.
FizpokPak Автор
16.04.2019 20:37Список (120 пород) здесь: www.kaggle.com/c/dog-breed-identification/data
Там файлик с метками. Но фотки пришлите, плиз.kloppspb
16.04.2019 23:49OK, устроим ещё подлянку :) Тут и ракурсы не очень, и не порода вовсе — метис, пополам американский бульдог и питбультерьер. Тем не менее, близко:
что выдало


FizpokPak Автор
17.04.2019 12:52Прекрасный пример того, как встречаются хороший тестер и ленивый программист.
Сеть, получив два изображения, выдает веса (вероятности), которые ничему реальному не соответствуют. По этой же причине не выйдет определить веса родителей в миксе. То есть, наверное, можно, но обучение должно быть другим.
А ленивый программист, потому, что я должен был сделать выделение отдельных собак и анализ выделенного участка изображения :)
Теперь насчет анализа головы собаки. Если вы посмотрите на обучающий набор, там только собаки целиком. Так что сеть с головой работать вроде и не умеет. Опять же, хороший программист сделал бы прогу, отрезающую собаке голову, и обучил бы сеть, в том числе, на головах…kloppspb
17.04.2019 14:53Не-не, про микс речи нет. Это ж провокация :) Ну и с учётом того, что практического смысла в программе ноль…
Более того, многие человеческие эксперты как раз согласны с оценкой породной принадлежности Варьки :) Тут программа сработала прекрасно. Особенно если посмотреть на обучающие образцы.
FizpokPak Автор
16.04.2019 20:59-1Вот список пород, которые должна узнавать сеть.
Похоже, ничего русского там нет :(
affenpinscher
afghan_hound
african_hunting_dog
airedale
american_staffordshire_terrier
appenzeller
australian_terrier
basenji
basset
beagle
bedlington_terrier
bernese_mountain_dog
black-and-tan_coonhound
blenheim_spaniel
bloodhound
bluetick
border_collie
border_terrier
borzoi
boston_bull
bouvier_des_flandres
boxer
brabancon_griffon
briard
brittany_spaniel
bull_mastiff
cairn
cardigan
chesapeake_bay_retriever
chihuahua
chow
clumber
cocker_spaniel
collie
curly-coated_retriever
dandie_dinmont
dhole
dingo
doberman
english_foxhound
english_setter
english_springer
entlebucher
eskimo_dog
flat-coated_retriever
french_bulldog
german_shepherd
german_short-haired_pointer
giant_schnauzer
golden_retriever
gordon_setter
great_dane
great_pyrenees
greater_swiss_mountain_dog
groenendael
ibizan_hound
irish_setter
irish_terrier
irish_water_spaniel
irish_wolfhound
italian_greyhound
japanese_spaniel
keeshond
kelpie
kerry_blue_terrier
komondor
kuvasz
labrador_retriever
lakeland_terrier
leonberg
lhasa
malamute
malinois
maltese_dog
mexican_hairless
miniature_pinscher
miniature_poodle
miniature_schnauzer
newfoundland
norfolk_terrier
norwegian_elkhound
norwich_terrier
old_english_sheepdog
otterhound
papillon
pekinese
pembroke
pomeranian
pug
redbone
rhodesian_ridgeback
rottweiler
saint_bernard
saluki
samoyed
schipperke
scotch_terrier
scottish_deerhound
sealyham_terrier
shetland_sheepdog
shih-tzu
siberian_husky
silky_terrier
soft-coated_wheaten_terrier
staffordshire_bullterrier
standard_poodle
standard_schnauzer
sussex_spaniel
tibetan_mastiff
tibetan_terrier
toy_poodle
toy_terrier
vizsla
walker_hound
weimaraner
welsh_springer_spaniel
west_highland_white_terrier
whippet
wire-haired_fox_terrier
yorkshire_terrier
andrey_aksamentov
17.04.2019 07:22Если на собаках будет работать.
Можно попробовать определять породу людей…FizpokPak Автор
17.04.2019 13:00Гугл на этом уже обломался :) Опознал горилл… получил судебный иск. Хотя, если бы вы видели то фото…

Plesser
17.04.2019 10:14Только вчера осваивал colab сам :). Замечу один нюанс, данные с google drive лучше скопировать на саму виртуальную машину. Так как при работе с данными находящимися на google drive обучение будет происходить очень медленно из низкой скорости получения данных с google drive (прошу прощения за тавтологию).
FizpokPak Автор
17.04.2019 13:06Спасибо.
Можете привести пример?Plesser
17.04.2019 13:12!cp -r '/content/drive/My Drive/cats_vs_dogs/' './'
В моем случае (датасет кошечки против собак) было так. До копирования данных у меня на одну эпоху тратилось несколько минут (на моем ноуте эпоха занимала около 26 секунд), после копирования на эпоху стало тратиться около 10 секундFizpokPak Автор
17.04.2019 17:52Спасибо. Кстати, я заметил, что на Colab эпоха может занимать от секунды до минуты — перестартуешь блок Jupiter — и все меняется.
Plesser
17.04.2019 17:55Я когда увидел жуткие тормоза очень удивился. Первым делом рестартовал блок, не помогло. Потом рестартовал само ядро. Не помогло. В итоге полез гуглить и на первой же ссылке понял, что я не один кто наступил на сей грабли.
puyol_dev2
17.04.2019 12:21Не очень понимаю зачем было постить закомментированный код. Лишняя информация сказывается на восприятии
FizpokPak Автор
17.04.2019 13:08Этот код нужно раскомментировать при определенных условиях. Например:
useNNofType_1()
#useNNofType_2()
В зависимости от того, какую сеть вы хотите получить (а я их там штук 5 привел), вы меняете комментарий.
vitalijlysanov
17.04.2019 13:08Все сложно, пока нашел что код ниже должен быть в одной строчке.
Может это и так должно быть понятно
from keras.applications.inception_v3 import preprocess_input as inception_v3_preprocessor
FizpokPak Автор
17.04.2019 17:56www.kaggle.com/c/dog-breed-identification/data
Там правильный датасет
Caustic
Есть какие-то требования к телефону для работы с приложением? Мне google play говорит: «Приложение не совместимо ни с одним из ваших устройств». Основной телефон Xiaomi Redmi Note 3.
FizpokPak Автор
should be anything after Lollypop