

«Ученый может открыть новую звезду, но не может создать её. Для этого ему пришлось бы обратиться к инженеру». Гордон Линдсей Глегг, «Дизайн дизайна» (1969)
Несколько месяцев назад я писал о различиях между специалистами по теории и методам анализа данных (data scientist) и специалистами по обработке данных (data engineer). Я говорил об их навыках и общих отправных точках. Произошло кое-что интересное: data scientist'ы начали наступать, утверждая, что они на самом деле так же компетентны в области инженерии данных, как и специалисты по обработке данных. Это было интересно, потому что специалисты по обработке данных не высказывали возражений и не говорили, что они являются специалистами по теории анализа данных.
Поэтому последние несколько месяцев я занимался сбором информации и наблюдением за поведением специалистов по теории анализа данных в их естественной рабочей среде. В этом посте я подробнее расскажу о том, почему data scientist не является data engineer'ом.
Почему это вообще важно?
Некоторые жалуются, что разница между специалистом по теории анализа данных и специалистом по обработке данных заключается только в названии. «Названия не должны мешать людям учиться или делать что-то новое», — утверждают они. Я согласен, нужно учиться как можно больше. Но знайте, что ваше обучение может только отдалённо касаться того, что необходимо будет делать на практике. В противном случае, это может привести к провалу проектов с big data.
Многое также зависит от уровня менеджмента в компаниях. Руководство нанимает специалистов по теории анализа данных, ожидая, что они будут специалистами по обработке данных.
Я слышал одну и ту же историю в разных компаниях: компания решает, что наука о данных — это способ получить деньги инвесторов, тонны прибыли, обрести авторитет в своем деловом кругу и т.д. Это решение принимается на уровне высшего руководства. К примеру, пусть к таким топ-менеджерам относится некая Элис. После продолжительных поисков компания находит лучшего в мире специалиста по теории анализа данных — назовем его Бобом.
Наступил первый рабочий день Боба. Элис подходит к нему и с нетерпением рассказывает обо всех своих планах.
«Прекрасно. Где конвейеры данных и ваш кластер Spark?», — спрашивает Боб.
Элис отвечает: «Именно это мы от вас и ждем. Мы наняли вас заниматься анализом данных».
«Я не знаю, как это делать», — говорит Боб.
Элис смотрит удивленно: «Но вы же специалист по теории обработки данных. Верно? Именно этим вы и занимаетесь».
«Нет, я использую уже созданные конвейеры и данные».
Элис возвращается в свой кабинет, чтобы выяснить, что произошло. Она смотрит на упрощенные диаграммы, вроде показанной на рисунке 1, и не может понять, почему Боб не в состоянии выполнить простые задачи с big data.
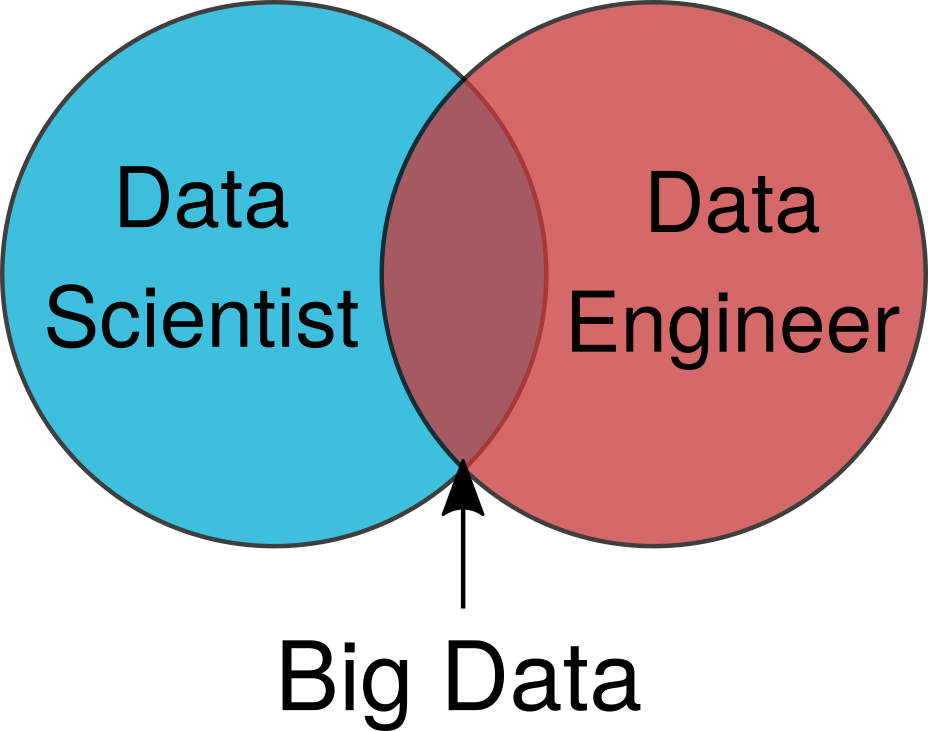
Рисунок 1. Упрощенная диаграмма Венна со специалистом по теории анализа данных и специалистом по обработке данных.
Центр внимания
Из этих взаимодействий вытекают два вопроса:
- Почему руководство не понимает, что специалист по теории анализа данных не является специалистом в области обработки данных?
- Почему некоторые специалисты по теории анализа думают, что они являются специалистами по обработке?
Я начну со стороны руководства. Позже мы поговорим о самих специалистах по теории анализа данных.
Давайте посмотрим правде в глаза: обработка данных не находится в центре внимания. Она не объявлена лучшей работой 21-го века. О ней не часто пишут в средствах массовой информации. На конференциях первым лицам компании не рассказывают о преимуществах обработки данных. Все сообщения касаются анализа данных и поиска специалистов по теории и методам анализа данных.
Но всё начинает меняться. У нас проводятся конференции по обработке данных. Постепенно признается необходимость разработки технических средств обработки данных. Я надеюсь, что моя работа поможет организациям осознать эту острую необходимость.
Признание и оценка
Даже в тех случаях, когда организации имеют команды специалистов по обработке данных, их работа часто по-прежнему не получает должной оценки.
Недостаток признания заслуг можно увидеть во время конференций. Специалист по теории анализа данных говорит о том, что он создал. Я вижу всеобъемлющую технологию обработки данных, которая легла в основу его модели, но она никогда не упоминается во время разговора. Я не ожидаю её подробного рассмотрения, но было бы неплохо отметить работу, которая была проделана для того, чтобы создание его модели стало возможным. Руководство и новички в сфере анализа данных считают, что с навыками специалиста по теории анализа данных возможно всё.
Как добиться признания заслуг
В последнее время специалисты по обработке данных спрашивают меня, как попасть в центр внимания в своих компаниях. Они чувствуют, что когда специалисты по теории анализа показывают свои последние разработки, то получают всю признательность от руководства. Основной вопрос, что мне задают инженеры: «Как мне заставить data scientist’а перестать считать нашу общую работу своей заслугой?»
Это вполне обоснованный вопрос, исходя из ситуаций, которые я вижу в компаниях. Менеджмент не осознает (и не оглашает) работу по обработке данных, которая касается всего, что связано с анализом данных. Если вы читаете это и думаете:
- Мои специалисты по теории анализа данных — специалисты по обработке данных.
- Мои специалисты по теории анализа данных создают действительно сложные конвейеры данных.
- Автор, должно быть, не знает, о чём говорит.
… то у вас наверняка есть специалист по обработке данных, который не находится в центре внимания.
Как специалисты по теории анализа данных увольняются при отсутствии инженеров, так и инженер, не получающий достаточного признания своей работы, уволится. Не обманывайте себя; для квалифицированных специалистов по обработке данных существует такой же горячий рынок труда, как и для специалистов по теории анализа данных.
Анализ данных возможен только при поддержке наших друзей
Вы, наверное, слышали миф об Атланте. В качестве наказания он был вынужден держать на себе мир/небо/небесные сферы. Земля существует в её нынешнем виде только потому, что Атлант держит её.
Точно так же специалисты по обработке данных поддерживают мир анализа данных. Человек, который держит на своих плечах весь мир, получает не так уж много признательности, хотя должен бы. На всех уровнях организации следует понимать, что анализ данных возможен только благодаря работе группы специалистов по обработке данных.

Рис. 2. Даже итальянцы в 1400-х годах знали о важности специалистов по обработке данных.
Data scientist’ы не являются data engineer’ами
Это подводит нас к тому, почему специалисты по теории анализа данных думают, что они являются специалистами по обработке данных.
Прежде, чем мы продолжим, несколько оговорок, чтобы предупредить комментарии:
- Я знаю, что специалисты по теории анализа данных действительно очень умны, и мне нравится работать с ними.
- Интересно, вызывает ли такой интеллект более сильный эффект IQ Даннинга-Крюгера.
- Некоторые из лучших специалистов по теории анализа данных, которых я знал, были специалистами и в обработке данных, но их было очень немного.
- Мы постоянно переоцениваем наши собственные навыки.

Рис. 3. Эмпирическая диаграмма восприятия своих навыков специалистами по теории анализа в сравнении с их фактическими навыками.
Обсуждая со специалистами по теории анализа данных их навыки в области обработки, я обнаружил, что их самооценка сильно различается. Это интересный социальный эксперимент с предубеждениями. Большинство специалистов по теории анализа данных переоценивали свои собственные возможности по обработке данных. Некоторые дали точную оценку, но никто не дал оценку ниже своих фактических способностей.
В этой диаграмме не хватает двух вещей:
- Каков уровень квалификации специалистов по обработке данных?
- Какой уровень квалификации необходим для умеренно сложного конвейера данных?
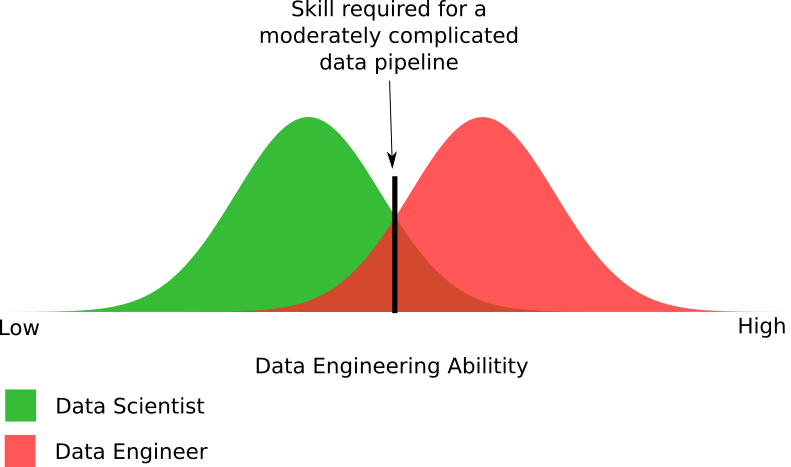
Рисунок 4. Эмпирическая диаграмма навыков специалистов по теории анализа и обработке данных, необходимых для создания умеренно сложного конвейера данных.
На рисунке видны различия в возможностях, необходимых для обработки данных. На самом деле, я немного преувеличил количеством ученых, способных создать умеренно сложный конвейер данных. Реальность может быть такова, что специалисты по теории анализа составляют половину от доли, показанной на диаграмме.
В целом, на ней представлены приблизительные части этих двух групп, которые могут и не могут создавать конвейеры данных. Да, кое-какие специалисты по обработке данных не могут создать умеренно сложный конвейер, как и большинство специалистов по теории анализа. Это возвращает нас к актуальной проблеме: организации отдают свои проекты с big data тем, у кого нет возможности правильно реализовать их.
Что такое умеренно сложный конвейер данных?
Умеренно сложный конвейер данных на один шаг выше минимального уровня, необходимого для создания конвейера данных. Пример минимального уровня — обработка текстовых файлов, хранящихся в HDFS/S3, с помощью Spark: скажем, начало оптимизации хранилища с помощью правильно используемой NoSQL-базы.
Я думаю, что специалисты по теории анализа данных думают, что их простой конвейер — это и есть обработка данных. Но на самом деле они говорят о самых простых решениях, а требуется гораздо более сложный конвейер. В прошлом специалист по обработке данных за кулисами выполнял действительно сложную инженерную обработку, и экспертам по теории анализа не приходилось иметь с этим дело.
Вы можете подумать: «Хорошо, 20 % моих специалистов по теории анализа данных справятся с этим. В конце концов, мне не нужен специалист по обработке». Во-первых, помните, что эта диаграмма преувеличивает способности специалистов по теории анализа данных. Умеренно сложный уровень — это всё еще довольно низкий уровень. Мне нужно создать еще одну диаграмму, чтобы показать, как мало специалистов по теории анализа данных могут осилить следующий шаг. Именно на этом этапе их доля среди специалистов, занимающихся теорией анализа данных, снижается до 1 % или менее.
Почему data scientist’ы не являются data engineer’ами?
Иногда я предпочитаю рассматривать отраженные проявления проблем. Вот несколько таких проблем, которые приводят к тому, что специалистам по теории анализа данных недостает навыков в области обработки.
Университет и курсы
Анализ данных — это новая востребованная программа для университетов и онлайн-курсов. Существуют всевозможные предложения, но практически везде встречается одна и та же проблема: учебная программа либо вовсе не содержит занятий по обработке данных, либо выделяется всего одна пара.
Когда я вижу новую учебную программу по анализу данных, то просматриваю её. Иногда меня просят прокомментировать предлагаемые университетами курсы. Я всем говорю одно и то же: «Вам нужны опытные программисты? Потому что ваш курс совсем не касается программирования или систем, необходимых для использования созданного конвейера данных».
Курс, в общих чертах, сосредоточен на необходимых статистических инструментах и математике. Это отражает то, как, по мнению компаний и учёных, должен выглядеть анализ данных. Но реальный мир выглядит совсем по-другому. Бедным студентам остаётся только перемаяться до конца этих нетривиальных занятий.
Мы можем сделать шаг назад и взглянуть на всё с академической точки зрения, рассмотрев требования к званию магистра в сфере распределенных систем. Очевидно, что специалисту по теории анализа данных не нужен настолько глубокий уровень, но это помогает показать, какие пробелы существуют в навыках специалиста по теории анализа данных. Существует несколько серьезных пробелов.
Обработка данных != Spark
Распространенное заблуждение среди специалистов по теории анализа данных и менеджмента заключается в том, что они думают, будто обработка данных — это просто написание некоего Spark-кода для обработки файла. Spark — это хорошее решение для пакетных вычислений, но это не единственная технология, которая вам понадобится. Решение на основе больших данных потребует 10-30 различных технологий, которые будут работать вместе.
Такое заблуждение лежит в основе неудач в сфере big data. Руководство считает, что у компании появилось новое универсальное решение для устранения проблем с big data. Реальность намного сложнее.
Когда я консультирую организацию по вопросам big data, то проверяю наличие этого заблуждения на всех уровнях компании. Если оно есть, я должен быть уверен, что перечислю все технологии, которые им понадобятся. Это устраняет ошибочное представление о том, что в области big data существует простая кнопка и единая технология для решения всех проблем.
Откуда взялся код?
Иногда специалисты по теории анализа данных рассказывают мне, насколько проста технология обработки данных. Я спрашиваю их, почему они так думают? «Я могу получить код, который мне нужен, из StackOverflow или Reddit. Если мне нужно создать что-то с нуля, я могу скопировать чей-то проект в лекцию на конференции или в технический документ».
Для постороннего человека это может показаться нормальным. Для специалиста по обработке данных это сигнал тревоги. Если оставить в стороне юридические вопросы, это — не обработка данных. В области big data очень мало шаблонных проблем. Всё, что происходит после «hello, world», имеет более сложную структуру, для которой требуется специалист по обработке данных, поскольку шаблонный подход для работы с ней отсутствует. Копирование проекта из технической документации может привести к низкой производительности или к чему-нибудь похуже.
Мне доводилось иметь дело с несколькими группами по теории анализа данных, которые пробовали подход «обезьяна видит — обезьяна делает». Он работает не очень хорошо. Это связано с резким увеличением сложности big data и пристальным вниманием к случаям использования. Команда специалистов по теории анализа данных часто отказывается от проекта, поскольку он выходит за рамки их возможностей в области обработки данных. Проще говоря, существует большая разница между «я могу скопировать код из StackOverflow» или «я могу изменить что-то, что уже было написано» и «я могу создать эту систему с нуля».
Лично меня беспокоит то, что группы специалистов по теории анализа данных могут стать источником огромного технического долга, который снижает эффективность big data в организациях. К тому времени, когда это выяснится, технический долг будет настолько велик, что исправить его будет невозможно.
Какой самый длинный код был введен для промышленного использования?
Основным отличием специалистов по теории анализа данных является их глубина. Эту глубину можно показать двумя способами. Какой самый долгий период применения их кода на практике — и был ли он вообще введен в эксплуатацию? Какую самую длинную, самую большую или сложную программу они когда-либо написали?
Речь идёт не о соревновании, а о том, знают ли они, что происходит, когда вы вводите что-то в эксплуатацию, и как поддерживать код. Написать программу из 20 строк кода сравнительно просто. Совсем другое дело — написать 1000 строк кода, связного и удобного в сопровождении. Люди, которые никогда не писали более 20 строк, не понимают разницы в удобстве сопровождения. Все их жалобы на многословность Java и необходимость использования лучших практик в программировании связаны с крупными программными проектами.
При оценке и обнаружении данных нужно работать быстро и переделывать код. А работать с кодом для production-использования требуется на ином, более глубоком уровне. Именно поэтому код большинства специалистов по теории анализа данных приходится переписывать до введения в эксплуатацию.
Проектирование распределенной системы
Один из способов узнать разницу между специалистами по теории анализа данных и специалистами по обработке заключается в том, чтобы увидеть, что происходит, когда они пишут свои собственные распределенные системы. Специалист по теории анализа данных напишет что-то очень сосредоточенное на математике, но плохо работающее. Специалист по обработке данных, который занимается написанием распределенных систем, создаст распределённое решение, которое будет хорошо работать (но лучше не пишите собственные системы). Я расскажу несколько историй о моем взаимодействии с организациями, в которых специалисты по теории анализа данных создали распределенную систему.
Итак, в компании моего заказчика отдел, состоящий из специалистов по теории анализа данных, создал такую систему. Меня послали поговорить с ними и понять, почему они написали собственное решение и что оно может делать. Они занимались (распределенной) обработкой изображений.
Я начал с того, что спросил их, почему они создали свою собственную распределенную систему? Они ответили, что сделать алгоритм распределённым невозможно. Для подтверждения своих выводов они заключили контракт с другим специалистом по теории анализа данных, специализирующимся на обработке изображений. Специалист-подрядчик подтвердил невозможность распределения алгоритма.
За два часа, которые я провел с командой, стало ясно, что алгоритм можно распределить на универсальном вычислительном движке, вроде Spark. Также стало ясно, что написанная система не будет масштабироваться и имеет серьезные недостатки. Отдав свои разработки на проверку другому data scientist’e вместо data engineer’а, тем самым они доверили проверку своих незрелых разработок программисту-новичку.
В другой компании, которой руководят математики, мне рассказали о написанной ими распределенной системе. Она была написана так, чтобы задачи по математике можно было выполнять на других компьютерах. После разговора с ними стало ясно несколько вещей. Они могли бы использовать универсальный вычислительный движок, и это было бы лучше. Распределение и порядок выполнения работ были неэффективными. Передача по сети RPC-трафика занимала больше времени, чем сам расчёт.
У всех этих историй есть общие черты:
- Специалисты по теории анализа данных сосредоточены на математике, а не на системе. Система предназначена для решения математических задач, но не гарантирует эффективное выполнение.
- Специалисты по обработке данных знают приемы, которые не являются математическими.
- Специалист по теории анализа данных спрашивает: «Как мне использовать компьютер для решения математических задач?» Специалист по обработке данных спрашивает: «Как мне использовать компьютер для максимально быстрого и эффективного решения математических задач?»
- Организации могли бы сэкономить себе время, деньги и нервы, воспользовавшись универсальным движком, а не создавая свои собственные.
В чём заключается разница?
Если вы дочитали до этого момента, то надеюсь, что уже убедил вас: специалист по теории анализа данных — это не специалист по обработке данных. Но на самом деле, какая разница? Что это меняет?
Разница между специалистом по теории анализа данных и специалистом по обработке данных — это разница между двумя компаниями, преуспевшей и потерпевшей неудачу в своем проекте с big data.
Наука о данных с инженерной точки зрения
Когда я впервые начал работать со специалистами по теории анализа данных, то был удивлен тем, как мало они просили и брали из сферы обработки данных. В этой сфере существуют хорошо зарекомендовавшие себя передовые методики, которые не используются в области теории анализа данных. Вот некоторые из них:
- Управление источниками
- Непрерывная интеграция
- Структуры управления проектами, такие как Agile или Scrum
- IDE
- Отслеживание ошибок
- Проверка кода
- Комментирование кода
Вы, наверное, заметили, что я мимоходом упомянул о техническом долге, который я наблюдал в командах специалистов по теории анализа данных. Позвольте мне подробнее рассказать, почему я так беспокоюсь об этом. Когда я говорю, что команда специалистов по обработке данных должна использовать передовой опыт, то получаю два ответа: «мы знаем и сделаем это позже» или «нам не нужны эти тяжеловесные приемы обработки. Мы проворны и ловки. Эти модели еще не запущены для промышленного использования». Но лучшие практики никогда не внедряются, и именно эти модели сразу же запускаются в эксплуатацию. Каждый из этих вопросов ведет к усугублению технического долга.
Качество кода
Вы бы запустили в эксплуатацию код своего практиканта? Если вы занимаетесь управлением, спросите вице-президента по техническим вопросам, ввел бы он в production код студента второго курса информатики? Вы услышите категорическое «нет». Или он может сказать, что это возможно только после проверки кода другими членами команды.
Так запустили бы вы в эксплуатацию код вашего data scientist’а? Частично суть этой статьи заключается в том, что специалисты по теории анализа данных являются новичками в программировании (в лучшем случае), но их код внедряют в эксплуатацию. Ознакомьтесь с лучшими практиками, которые не применяются командами специалистов по теории анализа данных. Сдерживание и противовесы для предотвращения запуска «любительского» кода в производство отсутствуют.
Почему они преуспели?
Я хочу закончить статью обращением к людям, которые всё еще думают, что их data scientist’ы являются одновременно data engineer’ами. Или к тем специалистам по теории анализа данных, которые считают себя компетентными в обработке. Напомню им: на графике видно, что это возможно, но маловероятно.
Если это так, мне хотелось бы, чтобы вы подумали, почему так получается.
По моему опыту, это происходит, когда соотношение между data scientist’ами и data engineer’ами сильно несбалансированно, инвертировано, или если в организации нет специалистов по обработке данных. На одного специалиста по теории анализа данных должно приходиться 2-5 специалистов по обработке. Такое соотношение необходимо, поскольку обработка данных занимает больше времени, чем их анализ.
Если это соотношение в команде неправильное, то время специалистов по теории анализа данных используется нерационально. Они, как правило, застревают на программировании тех частей, в которых хорошо разбираются специалисты по обработке данных. Я видел очень много специалистов по теории анализа, которые тратят дни на то, что заняло бы не более часа у специалиста по обработке. Эта проблема, которая ошибочно понята и некорректно решена, вынуждает компании нанимать больше специалистов по теории анализа данных, вместо того, чтобы нанять нужных людей, которые сделают процесс более эффективным.
Иногда люди ошибочно понимают, кем является специалист по обработке данных. Наличие в штате неквалифицированных или некомпетентных специалистов по обработке так же плохо. Нужно убедиться, что вы получаете квалифицированную помощь. Может возникнуть заблуждение, что вам не нужен специалист по обработке данных, если те специалисты, с которыми вы работали, были некомпетентны.
Руководители часто спрашивают меня, как им повысить техническую компетентность своих инженеров. Я отвечаю, что вопрос, скорее, в том, станут ли их специалисты более компетентными в технических вопросах. Это важно по нескольким причинам:
- Существует низкая точка убывающей доходности для команды специалистов по теории анализа данных. Они могут учиться месяцами, но, возможно, так никогда и не повысят свои навыки.
- Предполагать, что специалист по теории анализа данных является специалистом по обработке — неверно. Лучше сформировать команду теоретиков из пары человек, которые способны совершенствоваться.
- Существует ли окупаемость инвестиций от такого совершенствования? Если команда специалистов по теории анализа данных совершенствуется, что она может сделать лучше или по-другому?
- Предполагается, что самое большое значение имеет совершенствование data scientist’ов. Но иногда лучше инвестировать в совершенствование команды специалистов по обработке данных и упрощение коммуникаций между теоретиками и инженерами.
- Предполагается, что специалисты по теории анализа данных стремятся совершенствоваться с технической точки зрения. Я выяснил, что они рассматривают обработку данных как средство достижения цели. Для них обработка — нечто прикольное, связанное с анализом данных.
Что же делать?
Учитывая, что специалист по теории анализа данных не является специалистом по их обработке, что же нам остаётся делать? Прежде всего следует понять, что делают те и другие. Дело не в названиях должностей и не в связанных с этим ограничениях. Речь идёт о фундаментальных различиях в сильных сторонах и ключевых навыках каждого человека.
Чревато заставлять специалиста по теории анализа данных заниматься их обработкой, как инженера заставлять заниматься теоретическими изысканиями. Если ваша организация пытается заниматься теорией и методами анализа данных, вам нужны оба этих специалиста. Каждый из них выполняет свои функции.
В крупных организациях начинает ощущаться потребность в людях, которые понимают разницу между специалистом по теории анализа данных и специалистом по обработке данных. Я рекомендую руководству рассмотреть вопрос о создании должности специалиста в области машинного обучения.
Успех с big data
Как вы уже поняли, путь к успеху с big data лежит не только в технической области — он также связан с важными элементами управления. Пожалуй, одним из них является понимание сути специалистов по теории анализа данных и специалистов по обработке. Если у вас возникли проблемы с big data-проектами, ищите не только технические причины. Основная проблема может заключаться в руководстве или команде.
Когда вы анализируете первопричины почему big data-проект застопорился или провалился, не стоит рассматривать или винить только технологии. Кроме того, не следует слепо верить объяснениям группы специалистов по теории анализа данных, поскольку у них может не хватать опыта. Вместо этого следует внимательнее (что часто довольно неприятно) взглянуть на недостатки в управлении или команде, которые привели к провалу проекта.
Подобные неудачи формируют повторяющийся паттерн. Вы можете перейти на новейшие технологии, но забыть устранить системные проблемы. Только исправив корневую проблему, вы сможете начать свой путь к успеху.
Комментарии (2)

AN3333
01.05.2019 08:26+1Стало быть наука это то, что делается в коммерческих компаниях на компьютерах.
Это 5
sergeyns
Почему бухгалтер != разработчик 1С?
Кстати, хороший разработчик знает бухгалтерию гораздо лучше обычного бухгалтера.
Но и среди бухгалтеров попадаются разработчики. Но гораздо реже.