
Наша команда за короткое время прошла дистанцию от десятка сотрудников до целого подразделения почти в 200 человек и мы хотим поделиться некоторыми вехами из этого пути. Плюс порассуждаем о том, кто именно сейчас нужен в big data и каков реальный порог входа.

Работа с большими данными – относительно новая технологическая область, которая, как и все, по мере развития проходит по циклу взросления.
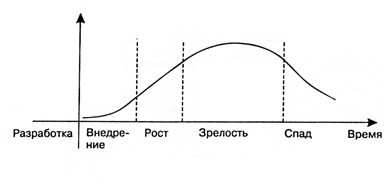
С точки зрения конкретного специалиста, работа в технологической области на каждом из этапов этого цикла имеет свои преимущества и недостатки.
Этап 1. Внедрение
На первом этапе это детище R&D-подразделений, которое еще не дает реальной прибыли.
Из плюсов: в него вкладываются немалые средства. Вместе с вложениями растут и надежды относительно решения ранее недоступных задач и возврата инвестиций.
Минусы: любая технология, какой бы перспективной она не выглядела на старте, имеет свои ограничения: ее нельзя использовать для устранения всех существующих проблем. Эти пределы обнаруживаются по мере экспериментов с новой идеей, что и приводит к охлаждению интереса к технологии после так называемого “пика завышенных ожиданий”.
Этап 2. Рост
Настоящий взлет будет только у технологии, которая преодолеет последующую котловину разочарований за счет своих реальных возможностей, а не маркетингового шума.
Плюсы: на этом этапе технология привлекает долгосрочные инвестиции: не только деньги, но время специалистов на рынке труда. Когда становится понятно, что это не просто хайп, а новый подход или даже сегмент рынка, самое время для специалистов встраиваться в “тренд”. Это идеальный момент для освоения перспективных технологий с точки зрения карьерного взлета.
Минусы: на этом этапе технология еще плохо документирована.
Этап 3. Зрелость
Зрелые технологии — настоящие “рабочие лошадки” рынка.
Плюсы: по мере взросления объем накопленной документации растет, появляются тренинги и курсы, становится легче войти в технологию.
Минусы: вместе с тем растет и конкуренция на рынке труда.
Этап 4. Спад
Этап спада (заката) наступает у всех технологий, хотя они продолжают работать.
Плюсы: к этому моменту технология уже полностью описана, понятны границы, доступно огромное количество документации, курсов.
Минусы: с точки зрения получения новых знаний и перспектив она уже не так привлекательна. По сути это уже сопровождение.
Этап роста наиболее привлекателен для всех, кто хочет начать работать в новой технологической области: как для молодых специалистов, так и для уже сложившихся профессионалов из смежных сегментов.
Развитие big data сейчас как раз на этом этапе. Завышенные ожидания остались за спиной. Бизнес уже доказал, что из больших данных можно получить прибыль, а поэтому впереди плато продуктивности. Этот момент дает отличный шанс специалистам на рынке труда.
Наша история big data
Внедрение технологии в любой отдельно взятой компании по сути повторяет общий цикл взросления. И наш опыт тут вполне типичен.
Собирать свою команду больших данных в X5 мы начали полтора года назад. Тогда это была лишь небольшая группа ключевых специалистов, а сейчас нас почти 200 человек.
Наши проектные команды прошли несколько эволюционных этапов, по мере которых мы получали более глубокое понимание ролей и задач. В результате у нас появился свой формат команды. Мы остановились на agile-подходе. Основная идея — в том, чтобы у команды были все компетенции для решения задачи, а как именно они распределены между специалистами, уже не так важно. Исходя из этого, состав ролей команд формировался постепенно, в том числе с учетом взросления технологии. И сейчас у нас есть:

Как мы пришли к dream team

Dream-не?dream, но, как я уже говорил, состав команд изменялся под воздействием зрелости аналитики больших данных и ее проникновения в повседневность X5 и наших торговых сетей.
“Быстрый старт” — минимум ролей, максимум скорости
Первая команда включала всего две роли:
Все быстро спланировали и вручную внедрили в бизнесе.
“А то ли мы считаем?” — мы учились понимать бизнес и выдавать наиболее полезный результат
Для взаимодействия с бизнесом появились новые роли:
“Нужно больше ресурсов” — локальные расчетные задачи переехали в кластер и начали касаться внешних систем
Для поддержки масштабирования потребовались:
Теперь Data Analyst / Data Scientist мог проверить несколько вариантов расчетов модели на кластере, хотя ручное внедрение в бизнесе все еще сохранилось.
“Нагрузки продолжают расти” — появляются новые данные, требуются новые мощности для их обработки
Эти изменения не могли не найти отражение в команде:
“Автоматизация во всем” — технология прижилась, пора автоматизировать внедрение в бизнес
На этом этапе в команде появился DevOps, который настроил автоматическую сборку, тестирование и установку функционала.
Ключевые мысли о формировании команд
1. Не факт, что все получилось бы, не будь у нас изначально правильные специалисты, вокруг которых мы смогли построить команду. Это скелет, на котором начали расти мышцы.
2. Рынок больших данных совсем зеленый, поэтому “готовых” специалистов под каждую из ролей не хватает. Конечно, было бы очень удобно набрать целое подразделение senior-ов, но, очевидно, подобных “звездных” команд нельзя построить много. Мы решили не гоняться только за “готовыми” кадрами. Как мы уже упоминали, придерживаясь agile, мы должны заботиться только о том, чтобы компетенций для решения определенной задачи хватило у команды в целом. Иными словами, мы можем взять (и берем) в одну команду профессионалов и новичков с определенной технической и математической базой, чтобы вместе они составили набор компетенций, необходимый для достижения нужных результатов.
3. Каждая из ролей подразумевает понимание принципов работы с большими данными, требуя, однако, свою глубину этого понимания. Наибольшая вариативность у ролей, имеющих прямые аналогии в классической разработке — тестировщиков, аналитиков и т.п. Для них есть как задачи, где принадлежность к big data практически незаметна, так и задачи, в которых надо погружаться чуть глубже. Так или иначе для старта карьеры определенного опыта, понимания IT, желания учиться и некоторых теоретических знаний об используемых инструментах (которые можно получить, почитав статьи) бывает достаточно.
4. Практика показала, что несмотря на то, что технология на слуху и многие хотели бы ей заняться, далеко не каждый специалист, который подошел бы для старта карьеры в больших данных (и в глубине души хотел бы там работать), действительно пытается сюда прийти.
Многие отличные кандидаты считают, что работа в командах BigData — это строго Data Science. Что это кардинальная смена деятельности с высоким порогом входа. Однако они недооценивают свои компетенции или просто не знают, что в больших данных востребованы люди самых разных профилей, и начать карьеру проще было бы в альтернативной роли — любой из перечисленных выше.
a. На самом деле для начала работы в смешанной команде на многих ролях не нужно узкое профильное образование именно в сфере больших данных.
b. Мы активно расширяли команду, придерживаясь идеи построения смешанных структурных единиц. И самое интересное, что пришедшие на наши задачи люди, ранее никогда не работавшие с большими данным, прекрасно прижились в компании, справившись с задачами. Они смогли за короткие сроки изучить практику больших данных.
5. Даже не обладая большим опытом, можно погружаться глубже, изучать необходимые языки и инструменты, будучи мотивированным вырасти в этом сегменте, чтобы заниматься более стратегическими задачами в рамках проекта. А накопленный опыт помогает переходить на те роли, где требуются познания именно в больших данных и понимание логики работы этого направления. Кстати, в этом смысле смешанная команда очень помогает ускорить развитие.
В нашем случае идея сбалансированных команд из специалистов разного уровня “взлетела” — группа реализовала уже не один внутренний проект. Мне кажется, при дефиците готовых кадров и росте потребности бизнеса в подобных командах к тому же сценарию будут приходить и другие компании.
Если вы всерьез хотите выбрать это направление, погрузиться именно в Data Sciense – Kaggle, ODS и другие профильные ресурсы помогут вам. При этом если вы не видите себя в ближайшее время именно в роли Data Scientist, но само по себе направление вам интересно, вы все равно нужны в Big Data!
Чтобы повысить свою ценность:
P.S. Кстати, прямо сейчас мы продолжаем активно расти и ищем дата-инженера, специалиста по тестированию, разработчика React, и UI/UX специалиста. 10-11 мая будем обсуждать в том числе работу в #bigdatax5 со всеми желающими на нашем стенде на DataFest.
Рецепт успеха в новой области
Работа с большими данными – относительно новая технологическая область, которая, как и все, по мере развития проходит по циклу взросления.
С точки зрения конкретного специалиста, работа в технологической области на каждом из этапов этого цикла имеет свои преимущества и недостатки.
Этап 1. Внедрение
На первом этапе это детище R&D-подразделений, которое еще не дает реальной прибыли.
Из плюсов: в него вкладываются немалые средства. Вместе с вложениями растут и надежды относительно решения ранее недоступных задач и возврата инвестиций.
Минусы: любая технология, какой бы перспективной она не выглядела на старте, имеет свои ограничения: ее нельзя использовать для устранения всех существующих проблем. Эти пределы обнаруживаются по мере экспериментов с новой идеей, что и приводит к охлаждению интереса к технологии после так называемого “пика завышенных ожиданий”.
Этап 2. Рост
Настоящий взлет будет только у технологии, которая преодолеет последующую котловину разочарований за счет своих реальных возможностей, а не маркетингового шума.
Плюсы: на этом этапе технология привлекает долгосрочные инвестиции: не только деньги, но время специалистов на рынке труда. Когда становится понятно, что это не просто хайп, а новый подход или даже сегмент рынка, самое время для специалистов встраиваться в “тренд”. Это идеальный момент для освоения перспективных технологий с точки зрения карьерного взлета.
Минусы: на этом этапе технология еще плохо документирована.
Этап 3. Зрелость
Зрелые технологии — настоящие “рабочие лошадки” рынка.
Плюсы: по мере взросления объем накопленной документации растет, появляются тренинги и курсы, становится легче войти в технологию.
Минусы: вместе с тем растет и конкуренция на рынке труда.
Этап 4. Спад
Этап спада (заката) наступает у всех технологий, хотя они продолжают работать.
Плюсы: к этому моменту технология уже полностью описана, понятны границы, доступно огромное количество документации, курсов.
Минусы: с точки зрения получения новых знаний и перспектив она уже не так привлекательна. По сути это уже сопровождение.
Этап роста наиболее привлекателен для всех, кто хочет начать работать в новой технологической области: как для молодых специалистов, так и для уже сложившихся профессионалов из смежных сегментов.
Развитие big data сейчас как раз на этом этапе. Завышенные ожидания остались за спиной. Бизнес уже доказал, что из больших данных можно получить прибыль, а поэтому впереди плато продуктивности. Этот момент дает отличный шанс специалистам на рынке труда.
Наша история big data
Внедрение технологии в любой отдельно взятой компании по сути повторяет общий цикл взросления. И наш опыт тут вполне типичен.
Собирать свою команду больших данных в X5 мы начали полтора года назад. Тогда это была лишь небольшая группа ключевых специалистов, а сейчас нас почти 200 человек.
Наши проектные команды прошли несколько эволюционных этапов, по мере которых мы получали более глубокое понимание ролей и задач. В результате у нас появился свой формат команды. Мы остановились на agile-подходе. Основная идея — в том, чтобы у команды были все компетенции для решения задачи, а как именно они распределены между специалистами, уже не так важно. Исходя из этого, состав ролей команд формировался постепенно, в том числе с учетом взросления технологии. И сейчас у нас есть:
- Product Owner (владелец продукта) — обладает пониманием предметной области, формулирует общую бизнес-идею и предсказывает, как она может быть монетизирована.
- Business Analyst (бизнес-аналитик) — прорабатывает эту задачу.
- Data quality (специалист по качеству данных) — проверяет, можно ли использовать существующие данные для решения поставленной задачи.
- Непосредственно Data Science/Data Analyst (дата-сайентист/дата-аналитик) — строит математические модели (есть разные подвиды, в том числе работающие только с электронными таблицами).
- Test Managers (тестировщики).
- Developers (разработчики).
В нашем случае инфраструктура и данные используются всеми командами, и следующие роли реализованы для команд как сервисы: - Infrastructure (инфраструктура).
- ETL (команда по загрузке данных).
Как мы пришли к dream team
Dream-не?dream, но, как я уже говорил, состав команд изменялся под воздействием зрелости аналитики больших данных и ее проникновения в повседневность X5 и наших торговых сетей.
“Быстрый старт” — минимум ролей, максимум скорости
Первая команда включала всего две роли:
- Product Owner предложил модель, дал рекомендации.
- Data Analyst – собрал статистику на основе существующих данных.
Все быстро спланировали и вручную внедрили в бизнесе.
“А то ли мы считаем?” — мы учились понимать бизнес и выдавать наиболее полезный результат
Для взаимодействия с бизнесом появились новые роли:
- Business Analyst – описал требования к процессам.
- Data Quality – провел проверку на консистентность данных.
- В зависимости от задачи Data Analyst / Data Scientist анализировал статистику по данным / проводил расчет модели на локальной рабочей станции.
“Нужно больше ресурсов” — локальные расчетные задачи переехали в кластер и начали касаться внешних систем
Для поддержки масштабирования потребовались:
- Инфраструктура, которая подняла сервера HADOOP.
- Разработчики — они реализовали интеграцию с внешними IT-системами, а пользовательские интерфейсы на этом этапе проверили сами.
Теперь Data Analyst / Data Scientist мог проверить несколько вариантов расчетов модели на кластере, хотя ручное внедрение в бизнесе все еще сохранилось.
“Нагрузки продолжают расти” — появляются новые данные, требуются новые мощности для их обработки
Эти изменения не могли не найти отражение в команде:
- Инфраструктура развивала кластер HADOOP под растущие нагрузки.
- Команда ETL начала регулярные загрузки и обновления данных.
- Появилось тестирование функционала.
“Автоматизация во всем” — технология прижилась, пора автоматизировать внедрение в бизнес
На этом этапе в команде появился DevOps, который настроил автоматическую сборку, тестирование и установку функционала.
Ключевые мысли о формировании команд
1. Не факт, что все получилось бы, не будь у нас изначально правильные специалисты, вокруг которых мы смогли построить команду. Это скелет, на котором начали расти мышцы.
2. Рынок больших данных совсем зеленый, поэтому “готовых” специалистов под каждую из ролей не хватает. Конечно, было бы очень удобно набрать целое подразделение senior-ов, но, очевидно, подобных “звездных” команд нельзя построить много. Мы решили не гоняться только за “готовыми” кадрами. Как мы уже упоминали, придерживаясь agile, мы должны заботиться только о том, чтобы компетенций для решения определенной задачи хватило у команды в целом. Иными словами, мы можем взять (и берем) в одну команду профессионалов и новичков с определенной технической и математической базой, чтобы вместе они составили набор компетенций, необходимый для достижения нужных результатов.
3. Каждая из ролей подразумевает понимание принципов работы с большими данными, требуя, однако, свою глубину этого понимания. Наибольшая вариативность у ролей, имеющих прямые аналогии в классической разработке — тестировщиков, аналитиков и т.п. Для них есть как задачи, где принадлежность к big data практически незаметна, так и задачи, в которых надо погружаться чуть глубже. Так или иначе для старта карьеры определенного опыта, понимания IT, желания учиться и некоторых теоретических знаний об используемых инструментах (которые можно получить, почитав статьи) бывает достаточно.
4. Практика показала, что несмотря на то, что технология на слуху и многие хотели бы ей заняться, далеко не каждый специалист, который подошел бы для старта карьеры в больших данных (и в глубине души хотел бы там работать), действительно пытается сюда прийти.
Многие отличные кандидаты считают, что работа в командах BigData — это строго Data Science. Что это кардинальная смена деятельности с высоким порогом входа. Однако они недооценивают свои компетенции или просто не знают, что в больших данных востребованы люди самых разных профилей, и начать карьеру проще было бы в альтернативной роли — любой из перечисленных выше.
a. На самом деле для начала работы в смешанной команде на многих ролях не нужно узкое профильное образование именно в сфере больших данных.
b. Мы активно расширяли команду, придерживаясь идеи построения смешанных структурных единиц. И самое интересное, что пришедшие на наши задачи люди, ранее никогда не работавшие с большими данным, прекрасно прижились в компании, справившись с задачами. Они смогли за короткие сроки изучить практику больших данных.
5. Даже не обладая большим опытом, можно погружаться глубже, изучать необходимые языки и инструменты, будучи мотивированным вырасти в этом сегменте, чтобы заниматься более стратегическими задачами в рамках проекта. А накопленный опыт помогает переходить на те роли, где требуются познания именно в больших данных и понимание логики работы этого направления. Кстати, в этом смысле смешанная команда очень помогает ускорить развитие.
Как попасть в BigData?
В нашем случае идея сбалансированных команд из специалистов разного уровня “взлетела” — группа реализовала уже не один внутренний проект. Мне кажется, при дефиците готовых кадров и росте потребности бизнеса в подобных командах к тому же сценарию будут приходить и другие компании.
Если вы всерьез хотите выбрать это направление, погрузиться именно в Data Sciense – Kaggle, ODS и другие профильные ресурсы помогут вам. При этом если вы не видите себя в ближайшее время именно в роли Data Scientist, но само по себе направление вам интересно, вы все равно нужны в Big Data!
Чтобы повысить свою ценность:
- обновите знания по математике. Для решения рядовых задач big data не требуется докторская степень, но базовые знания по высшей математике все-таки нужны. Понимая механизмы, заложенные в основу матстатистики, вам будет проще осознавать процессы;
- выберите роли, которые ближе всего к вашей текущей специальности. Выясните, с какими задачами придется сталкиваться в рамках этой роли (и в конкретной компании, куда хотите пойти). И если вы решали подобные задачи ранее, на них стоит сделать акцент в резюме;
- очень важны инструменты, специфичные для выбранной роли, даже если кажется, что к большим данным это не имеет отношения. К примеру, при развитии нашего внутреннего решения выяснилось, что нужно много фронтенд-разработчиков, которые работают со сложными интерфейсами;
- помните, что рынок активно развивается. Кто-то строит и прокачивает команды внутри, а кто-то рассчитывает найти готовых специалистов на рынке труда. Если вы новичок, постарайтесь попасть в сильную команду, где будет возможность получить дополнительные знания.
P.S. Кстати, прямо сейчас мы продолжаем активно расти и ищем дата-инженера, специалиста по тестированию, разработчика React, и UI/UX специалиста. 10-11 мая будем обсуждать в том числе работу в #bigdatax5 со всеми желающими на нашем стенде на DataFest.
Комментарии (9)

nikola_sa
09.05.2019 10:30Data Quality – провел. Это шедевр. Data Quality – ничего провести не может. Пишите все по русски.

X5RetailGroup Автор
09.05.2019 16:49-1Тогда уж надо критику англицизмов еще раньше — с Big Data начинать. К сожалению, в ИТ прижилось использование калек с английского.

McKinseyBA
09.05.2019 16:40+1кто именно сейчас нужен в big data
подобные необычные словоформы и некорректные англицизмы вместе с маркетинговым «булшитом» не позволили прочитать статью целиком.
На мой взгляд, было бы полезнее рассказать о реальных бизнес-кейсах из вашей практики с примерами кода и более подробным описанием инфраструктуры вашего решения ML. 3 года назад, когда я работал в логистике X5, единственным известным мне примером был поиск оптимального месторасположения новых распределительных центров на основе анализа и прогноза плеча доставок / товарных потоков. Может конкретика будет в следующих статьях?X5RetailGroup Автор
09.05.2019 22:33Будет обязательно в следующих постах. #bigdataХ5 появилась год назад, так что наши кейсы не старее года ;).

orreanix
11.05.2019 13:09Отличный пост!
Можете рассказать про Product Owner — кто он (профайл человека, ключевые компетенции)? Из какой он функции (в бизнесе или в ИТ)? какой у него уровень в иерархии и, если не секрет, какой роли репортит.
sim3x
Очень часто спрашивают на тостере
mr_Darwin
Вообще, идея была написать статью о том что большие данные не равно ML (Как впрочем ML не равно Data Science) поэтому набор ключевых слов для изучения будет свой для каждой роли в команде. Если интересно в таком разрезе — можно попробовать составить.
Конкретно про ML и DS лучше всего смотреть тут Open Data Science (не реклама, но дань уважения)