
Для всех хабравчан, у которых возникло ощущение дежавю: Написать этот пост меня побудили статья "Введение в Python" и комментарии к ней. К сожалению, качество этого "введения" кхм… не будем о грустном. Но ещё грустнее было наблюдать склоки в комментариях, из разряда "C++ быстрее Python", "Rust ещё быстрее C++", "Python не нужен" и т.д. Удивительно, что не вспомнили Ruby!
Как сказал Бьярн Страуструп,
«Есть всего два типа языков программирования: те, на которые люди всё время ругаются, и те, которые никто не использует».
Добро пожаловать под кат всем, кто хотел бы познакомиться с Python, не опускаясь при этом до грязных ругательств!
Утро в горах Восточного Кавказа ознаменовалось воплями. Два молодых человека сидели на большом валуне и что-то рьяно обсуждали, активно жестикулируя. Через минуту они начали толкать друг друга, а потом сцепились и свалились с валуна в (как оказалось) куст крапивы. Видно этот куст рос там неспроста, — он сразу утихомирил драчунов и внёс перемирие в их неугасающий спор. Как вы, наверное догадались, одним из спорщиков был я, другим — мой лучший друг (привет, Quaker_t!), ну а предметом нашей светской беседы — Visual Basic vs. Delphi!
Узнаёте себя? Иногда мы превращаем любимые языки программирования в культ и готовы отстаивать его до последнего! Но годы идут и наступает момент, когда "A vs. B" из предмета споров перерастает в "Мне комфортнее работать с А, но при необходимости я научусь работать с B, C, D, E и вообще, с чем угодно". Вот только когда мы сталкиваемся с новыми языками программирования, старые привычки и культура могут нас долго не отпускать.
Я хотел бы познакомить вас с Питоном и помочь перенести ваш опыт в новое русло. Как у любой технологии, у него есть свои сильные и слабые стороны. Python, как и C++, Rust, Ruby, JS, и все остальные — это инструмент. К любому инструменту прилагается инструкция и любым инструментом надо научиться пользоваться правильно.
"Автор, не пудри мозги, ты собирался нас с Питоном знакомить?". Давайте знакомиться!
Python — динамический, высокоуровневый язык программирования общего назначения. Python — зрелый язык программирования с богатой экосистемой и традициями. Хоть язык и увидел свет в 1991-м году, его современный облик начал формироваться в начале 2000-х. Python — заряженный язык, в его стандартной библиотеке есть решения на многие случаи жизни. Python — популярный язык программирования: Dropbox, Reddit, Instagram, Disqus, YouTube, Netflix, чёрт побери, даже Eve Online и многие другие активно используют Python.
В чём причина такой популярности? С вашего позволения, изложу собственную версию.
Python — простой язык программирования. Динамическая типизация. Сборщик мусора. Функции высшего порядка. Простой синтаксис для работы со словарями, множествами, кортежами и списками (в т.ч. для получения срезов). Питон отлично подходит для новичков: даёт возможность начать с процедурного программирования, потихоньку перейти к ООП и почуствовать вкус программирования функционального. Но эта простота — как верхушка айсберга. Стоит нырнуть в глубину, как натыкаешься на философию Питона — Zen Of Python. Ныряешь ещё дальше — и попадаешь в свод чётких правил по оформлению кода — Style Guide for Python Code. Погружаясь, программист постепенно вникает в понятие "Python way" или "Pythonic". В этот удивительный этап изучения языка, начинаешь понимать, почему хорошие программы на Питоне пишутся именно так, а не иначе. Почему язык эволюционировал именно в этом направлении, а не в другом. Питон не преуспел в скорости выполнения. Но он преуспел в важнейшем аспекте нашей работы — читабельности. "Пишите код для людей, а не для машины" — это основа из основ Питона.
Хороший код на Питоне выглядит красиво. А писать красивый код — чем не приятное занятие?
Совет 0: Перед тем как читать дальше, пожалуйста, загляните в уголок Дзена Питона. Язык зиждется на этих постулатах и наше общение будет намного приятнее, если и вы будете с ними знакомы.
Какой умник додумался до отступов?
Первым шоком для тех, кто никогда не видел код на Питоне, является обозначение тела инструкций отступами:
def main():
ins = input('Please say something')
for w in ins.split(' '):
if w == 'hello':
print('world!')Вспоминаю вечера в общаге Питерского Политеха, когда мой сосед, VlK, с горящими глазами рассказывал, что ещё нового он откопал в Питоне. "Тело инструкции отступами? Серьёзно?" — была моя реакция. Действительно, для человека прошедшего от Visual Basic (if ... end if) до C# (фигурные скобки), сквозь C, C++ и Java, подобный подход казался, мягко говоря, странным. "Ты же форматируешь код отступами?", спросил VlK. Конечно же я форматировал его. Точнее, за меня это делала спираченная Visual Studio. Она справлялась с этим чертовски хорошо. Я никогда не задумывался о форматировании и отступах — они появлялись в коде сами по себе и казались чем-то обыденным и привычным. Но крыть было нечем — код был всегда отформатирован отступами. "Тогда зачем тебе фигурные скобки, если тело инструкций в любом случае будет сдвинуто вправо?".
В тот вечер я засел за Python. Оглядываясь назад, я могут точно сказать, что? именно помогало быстро усваивать новый материал. Это был редактор кода. Под влиянием того же VlK, незадолго до вышеописанных событий, я перешёл с Windows на Ubuntu и Emacs в качестве редактора (на дворе 2007й год, до PyCharm, Atom, VS Code и прочих — ещё много лет). "Ну вот, сейчас будет пиарить Emacs..." — скажете вы. Совсем чуточку :) Традиционно, клавиша <tab> в Emacs не добавляет символов табуляции, а служит для выравнивания строки по правилам данного режима. Нажал <tab> — и строка кода сдвигается в следующее подходящее положение:
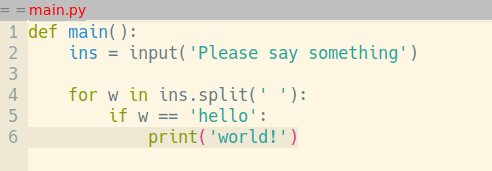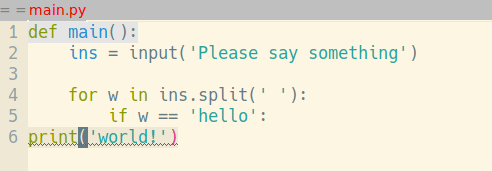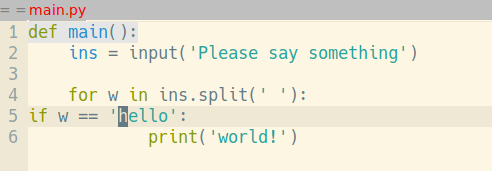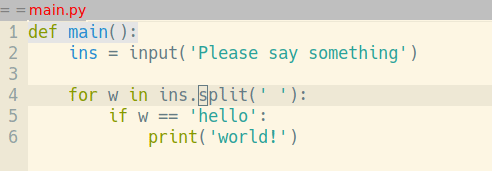
Таким образом вам никогда не приходится задумываться, правильно ли вы выровняли код.
Совет 1: При знакомстве с Python используйте редактор, который возьмёт на себя заботу об отступах.
А знаете, какой побочный эффект у всего этого безобразия? Программист старается избегать длинных конструкций. Как только размер функции выходит за вертикальные границы экрана, становится сложнее различать, к какой же конструкции относится данный блок кода. И чем больше вложений, тем сложнее. В результате стараешься писать как можно лаконичнее, разбивая длинные тела функций, циклов, условных переходов и т.д.
Да ну вашу динамическую типизацию
O, эта дискуссия существует почти столько же, сколько существует само понятие "программирование"! Динамическая типизация не плоха и не хороша. Динамическая типизация — это тоже наш инструмент. В Питоне динамическая типизация даёт огромную свободу действий. А там, где большая свобода действий — больше вероятность выстрелить себе в ногу.
Стоит уточнить, что типизация в Питоне строгая и сложить число со строкой не получится:
1 + '1'
>>> TypeError: unsupported operand type(s) for +: 'int' and 'str'Питон также проверяет сигнатуру функции при вызове и выбросит исключение, если сигнатура вызова не верна:
def sum(x, y):
return x + y
sum(10, 20, 30)
>>> TypeError: sum() takes 2 positional arguments but 3 were givenНо загружая скрипт, Python не скажет вам, что функция ожидает число а не строку, которую вы в неё передаёте. И узнаете вы об этом лишь во время исполнения:
def sum(x, y):
return x + y
sum(10, '10')
>>> TypeError: can only concatenate str (not "int") to strТем сильнее вызов программисту, особенно при написании больших проектов. Современный Питон ответил на этот вызов механизмом аннотаций и библиотекой типов, а сообщество разработало программы, выполняющие статическую проверку типов. В результате программист узнаёт о подобных ошибках до выполнения программы:
# main.py:
def sum(x: int, y: int) -> int:
return x + y
sum(10, '10')
$ mypy main.py
tmp.py:5: error: Argument 2 to "sum" has incompatible type "str"; expected "int"Питон не придаёт никакого значения аннотациям, хотя и сохраняет их в атрибуте __annotations__. Единственное условие — аннотации должны быть валидными значениями с точки зрения языка. С момента их появления в версии 3.0 (что было более десяти лет назад!), именно усилиями сообщества, аннотации стали использовать для типизированной маркировки переменных и аргументов.
# Для тех кто очень в теме, напоминаю: это пример :)
from typing import TypeVar, Iterable
Num = TypeVar('Num', int, float)
def sum(items: Iterable[Num]) -> Num:
accum = 0
for item in items:
accum += item
return accum
sum([1, 2, 3])
>>> 6Совет 2: На практике больше всего динамическая типизация вызывает проблемы при чтении и отладке кода. Особенно если этот код писался без аннотаций и вам приходится тратить много времени на выяснение типов переменных. Вам не обязательно указывать и документировать типы всего и вся, но время, потраченное на детальное описание публичных интерфейсов и наиболее критических участков кода, воздастся сторицей!
Кря! Утиная типизация
Порой знатоки Питона напускают на себя таинственный вид и говорят об "Утиной типизации".
Утиная типизация (Duck typing) — это применение "утиного теста" в программировании:
Если объект крякает как утка, летает как утка и ходит как утка, то скорее всего это утка.
Рассмотрим пример:
class RpgCharacter:
def __init__(self, weapon)
self.weapon = weapon
def battle(self):
self.weapon.attack()Тут — классическое внедрение зависимости (dependency injection). Класс RpgCharacter получает объект weapon в конструкторе и позже, в методе battle() вызывает weapon.attack(). Но RpgCharacter не зависит от конкретной имплементации weapon. Это может быть меч, BFG 9000, или кит с цветочным горшком, готовые приземлиться неприятелю на голову в любой момент. Важно, чтобы у объекта был метод attack(), всё остальное Питон не интересует.

Строго говоря, утиная типизация не является чем-то уникальным. Она присутствует во всех (знакомых мне) динамических языках, реализующих ООП.
Это ещё один пример того, как внимательно приходится программировать в мире динамической типизации. Плохо назвали метод? Неоднозначно нарекли переменную? Ваш коллега, или вы сами, спустя эдак пол-годика, будете счастливы разгребать подобный код :)
interface IWeapon {
void attack();
}
public class Sword implements IWeapon {
public void attack() {
//...
}
}
public class RpgCharacter {
IWeapon weapon;
public RpgCharacter(IWeapon weapon) {
this.weapon = weapon;
}
public void battle() {
weapon.attack();
}
}А была бы классическая статическая типизация, с проверкой соответствия типам на стадии компиляции. Цена — невозможность использовать объект, имеющий метод attack(), но при этом не реализующий интерфейс IWeapon явным образом.
Совет 3: При желании вы можете описать интерфейс, построив собственный абстрактный класс с методами и свойствами. А ещё лучше будет потратить время на тщательное тестирование и написание документации для себя и пользователей вашего кода.
Процедурный подход и __специальные_методы__()
Питон — объектно-ориентированный язык и в корне иерархии наследования стоит класс object:
isinstance('abc', object)
>>> True
isinstance(10, object)
>>> TrueНо там где в Java и C# используется obj.ToString(), в Питоне будет вызов функции str(obj). Или например вместо myList.length, в Питоне будет len(my_list). Создатель языка, Гвидо Ван Россум (Guido van Rossum), объяснил это следующим образом:
Когда я читаю код в котором говоритсяlen(x), то знаю, что запрашивается длина чего-то. Это сразу говорит мне о том, что результатом будет целое число, а аргументом — какой-то контейнер. И наоборот, читаяx.len(), мне необходимо знать, чтоx— это какой-то контейнер, имплементирующий определённый интерфейс или наследующий от класса, в котором имеется методlen(). [Источник].
Тем не менее внутри себя функции len(), str() и некоторые другие будут вызывать определённые методы объекта:
class User:
def __init__(self, name, last_name):
self.name = name
self.last_name = last_name
def __str__(self):
return f"Honourable {self.name} {self.last_name}"
u = User('Alex', 'Black')
label = str(u)
print(label)
>>> Honourable Alex BlackСпециальные методы также используются операторами языка, как математическими и булевыми, так и операторами цикла for ... in ..., оператором контекста with, оператором индекса [] и т.д.
Например, протокол итератора состоит из двух методов: __iter__() и __next__():
# Никаких Iterable, IEnumerable, std::iterator и т.д.
class InfinitePositiveIntegers:
def __init__(self):
self.counter = 0
def __iter__(self):
"""Возвращает объект по которому будет проводиться итерация.
Вызывается встроенной фунцкией iter().
"""
return self
def __next__(self):
"""Возвращает элементы итерации.
Вызывается встроенной фунцкией next().
"""
self.counter += 1
return self.counter
for i in InfinitePositiveIntegers():
print(i)
>>> 1
>>> 2
>>> ...
# чтобы остановить, нажмите Ctrl + CХорошо, допустим специальные методы. Но почему они выглядят так вырвиглазно? Гвидо объяснил это тем, что имей они обычные имена без подчёркиваний, программисты, сами того не хотя, рано или поздно переопределяли бы их. Т.е. __метод__() это своебразная защита от дурака. Как показало время — защита эффективная :)
Совет 4: Внимательно ознакомьтесь со встроенными функциями и специальными методами объектов. Они являются неотъемлимой частью языка, без которой невозможно полноценно на нём разговаривать.
Где инкапсуляция? Где мой private?! Где моя сказочка?!!
В Питоне нет модификаторов доступа к атрибутам класса. Внутренности объектов открыты для доступа без каких-либо ограничений. Однако существует конвенция, по которой атрибуты с префиксом _ считаются приватными, например:
import os
class MyFile:
# Поле считается приватным
_os_handle = None
def __init__(self, path: str):
self._open(path)
# Метод считается приватным
def _open(self, path):
# os.open() - *низкоуровневая* функция для открытия файлов.
# На практике используется встроенная функция open().
# Нам же os.open() отлично подойдёт для примера.
self._os_handle = os.open(path, os.O_RDWR | os.O_CREAT)
# А этот метод считается публичным
def close(self):
if self._os_handle is not None:
os.close(self._os_handle)
f = MyFile('/tmp/file.txt')
print(f._os_handle) # с доступом к "приватному" полю нет никаких проблем!
f.close()Почему?
В Питоне нет ничего приватного. Ни класс, ни его экземпляр не скроют от тебя того, что лежит внутри (благодаря чему возможна глубочайшая интроспекция). Питон доверяет тебе. Он как бы говорит "Приятель, если ты хочешь пошарить по тёмным углам — нет проблем. Я верю, что на то имеются хорошие причины и надеюсь, что ты ничего не сломаешь.
В конце концов мы все здесь взрослые люди.
— Karl Fast [Источник].
В Питоне есть специальный механизм искажения (mangling) имени атрибутов, начинающихся с двойного подчёркивания и не заканчивающихся на двойное подчёркивание (__my_attr)! Сделано это для избежания коллизий имён при наследовании. Для вызова вне тела методов класса, Питон добавляет префикс _ИмяКласса__атрибут. Но для внутреннего доступа ничего не меняется:
class C:
def __init__(self):
self.__x = 10
def get_x(self):
return self.__x
c = C()
c.__x
>>> 'C' object has no attribute '__x'
print(c.get_x())
>>> 10
print(c._C__x)
>>> 10Давайте рассмотрим практическое применение. Например, классу File, который читает файлы из локальной файловой системы, мы хотим добавить способности кеширования. Наш коллега успел написать для этих целей класс-миксин. Но чтобы отгородить методы и атрибуты от потенциальных коллизий, коллега добавил к их именам префикс __:
class BaseFile:
def __init__(self, path):
self.path = path
class LocalMixin:
def read_from_local(self):
with open(self.path) as f:
return f.read()
class CachedMixin:
class CacheMissError(Exception):
pass
def __init__(self):
# Tepeрь, даже если в соседнем классе в цепочке наследования
# будет атрибут __cache, или метод __from_cache(),
# коллизии, а точнее переопределения не произойдёт!
self.__cache = {}
def __from_cache(self):
return self.__cache[self.path]
def read_from_cache(self):
try:
return self.__from_cache()
except KeyError as e:
raise self.CacheMissError() from e
def store_to_cache(self, data):
self.__cache[self.path] = data
class File(CachedMixin, LocalMixin, BaseFile):
def __init__(self, path):
CachedMixin.__init__(self)
BaseFile.__init__(self, path)
def read(self):
try:
return self.read_from_cache()
except CachedMixin.CacheMissError:
data = self.read_from_local()
self.store_to_cache(data)
return dataЕсли вам интересно взглянуть на имплементацию этого механизма в CPython, прошу в Python/compile.c
Наконец, благодаря наличию свойств (properties) в языке, теряется смысл писать геттеры и сеттеры в стиле Java: getX(), setX(). Например, в изначально написанном классе Coordinates,
class Coordinates:
def __init__(self, x, y):
self.x = x
self.y = y
c = Coordinates(10, 10)
print(c.x, c.y)
>>> (10, 10)понадобилось управлять доступом к атрибуту x. Правильным подходом будет заменить его на property, тем самым сохраняя контракт с внешним миром.
class Coordinates:
_x = 0
def __init__(self, x, y):
self.x = x
self.y = y
@property
def x(self):
return self._x
@x.setter
def x(self, val):
if val > 10:
self._x = val
else:
raise ValueError('x should be greater than 10')
c = Coordinates(20, 10)
c.x = 5
>>> ValueError: x should be greater than 10Совет 5: Как и многое в Питоне, понятие о приватных полях и методах класса опирается на устоявшуюся конвенцию. Не обижайтесь на авторов библиотек, если "всё перестало работать" по той причите, что вы активно пользовались приватными полями их классов. В конце концов, мы все здесь взрослые люди :).
Немного об исключениях
В культуре Питона своеобразный подход к исключениям. Кроме привычного перехвата и обработки а-ля C++ / Java, вам придётся столкнуться с использованием исключений в контексте
"Проще попросить прощения, чем спрашивать разрешение" (Easier to ask for forgiveness, than permission — EAFP).
Перефразируя — не пиши лишнего if, если в большинстве случаев исполнение пойдёт по данной ветке. Вместо этого оберни логику в try..except.
Пример: представим обработчик POST-запросов, создающей пользователя в условной базе данных. На входе функции — словарь (dictionary) типа ключ-значение:
def create_user_handler(data: Dict[str, str]):
try:
database.user.persist(
username=data['username'],
password=data['password']
)
except KeyError:
print('There was a missing field in data passed for user creation')Мы не стали загрязнять код проверками "содержится ли username или password в data". Мы ожидаем, что скорее всего они там будут. Мы не просим "разрешения" пользоваться этими полями, но "просим прощения" когда очередной кулхацкер запостит форму с отсутствующими данными.
Например, вам хочется проверить, присутствуют ли фамилия пользователя в данных и при отсутствии установить её в пустое значение. if здесь будет куда уместнее:
def create_user_handler(data):
if 'last_name' not in data:
data['last_name'] = ''
try:
database.user.persist(
username=data['username'],
password=data['password'],
last_name=data['last_name']
)
except KeyError:
print('There was a missing field in data passed for user creation')Errors should never pass silently. — не замалчивайте исключения! У современного Питона есть замечательная консткрукция raise from, позволяющая сохранить контекст цепочки исключений. Например:
class MyProductError(Exception):
def __init__(self):
super().__init__('There has been a terrible product error')
def calculate(x):
try:
return 10 / x
except ZeroDivisionError as e:
raise MyProductError() from eБез raise from e цепочка исключений обрывается на MyProductError, и мы не сможем узнать, что именно было причиной этой ошибки. С raise from X, причина (т.е. X) выбрасываемого исключения сохраняется в атрибуте __cause__:
try:
calculate(0)
except MyProductError as e:
print(e.__cause__)
>>> division by zeroВ случае с итерацией, выкидывание исключения StopIteration является официальным способом сигнализировать о завершении итератора.
class PositiveIntegers:
def __init__(self, limit):
self.counter = 0
self.limit = limit
def __iter__(self):
return self
def __next__(self):
self.counter += 1
if self.counter == self.limit:
# никаких hasNext() или moveNext(),
# только исключения, только хардкор
raise StopIteration()
return self.counter
for i in PositiveIntegers(5):
print(i)
> 1
> 2
> 3
> 4Совет 6: Мы платим за обработку исключения, лишь в исключительных ситуациях. Не пренебрегайте ими!
There should be one-- and preferably only one --obvious way to do it.
switch или pattern matching? — используйте if и словари. do-циклы? — для этого есть while и for. goto? Думаю вы и сами догадались. Это же относится и к некоторым техникам и шаблонам проектирования, которые кажутся сами собой разумеющимися в других языках. Самое удивительное, что нет никаких технических ограничений на их реализацию, просто "у нас так не принято".
Например, в Питоне не часто встретишь паттерн "Builder". Вместо него используется возможность передавать и явным образом запрашивать именные аргументы функции. Вместо
human = HumanBuilder.withName("Alex").withLastName("Black").ofAge(20).withHobbies(['tennis', 'programming']).build()будет
human = Human(
name="Alex"
last_namne="Black"
age=20
hobbies=['tennis', 'programming']
)В стандартной библиотеке не используются цепочки методов для работы с коллекциями. Помню, как коллега, пришедший из мира Kotlin, показывал мне код следующего толка (взято из официальной документации по Котлину):
val shortGreetings = people
.filter { it.name.length < 10 }
.map { "Hello, ${it.name}!" }В Питоне map(), filter() и многие другие — функции, а не методы коллекций. Переписав этот код один в один получится:
short_greetings = map(lambda h: f"Hello, {h.name}", filter(lambda h: len(h.name) < 10, people))По-моему выглядит ужасно. Поэтому для длинных связок вроде .takewhile().filter().map().reduce() лучше использовать т.н. включения (comprehensions), или старые добрые циклы. Кстати, этот же пример на Котлине, приводится в виде соответствующего list comprehension. А на Питоне это выглядит так:
short_greetings = [
f"Hello {h.name}"
for h in people
if len(h.name) < 10
]Цепочки методов используются там, где они эффективнee стандартных средств. Например в web-фреймворке Django, цепочки используются для построение объекта-запроса к БД:
query = User.objects .filter(last_visited__gte='2019-05-01') .order_by('username') .values('username', 'last_visited') [:5]Совет 7: Перед тем, как сделать что-то очень знакомое из прошлого опыта, но не знакомое в Питоне, спросите себя, какое бы решение принял опытный питонист?
Питон медленный
Да.
Да, если речь идёт о скорости исполнения по сравнению с статически типизированными и компилируемыми языками.
Но вы, похоже, желаете развёрнутого ответа?
Референсная имплементация Питона (CPython) — далеко не самая его эффективная имплементация. Одна из важных причин — желание разработчиков не усложнять её. И логика вполне понятна — не слишком заумный код означает меньше ошибок, лучшую возможность внесения изменений и в конце концов, большее число людей, которые этот код захотят прочесть, понять и дополнить.
Jake VanderPlas в своём блоге разбирает, что происходит у CPython под капотом при сложении двух переменных, содержащих целочисленные значения:
a = 1
b = 2
c = a + bДаже если не углубляться в дебри CPython, можно сказать, что для хранения переменных a, b и c, интерпретатору придётся создать три объекта в куче (heap), в которых будут храниться тип и (указатели на) значения; повторно выяснять тип и значения при операции сложения, чтобы вызвать что-то вроде binary_add<int, int>(a->val, b->val); записать результат в c.
Это чудовищно неэффективно по сравнению с аналогичной программой на C.
Другая беда CPython — это т.н. Global Interpreter Lock (GIL). Этот механизм, по сути — булевое значение, огороженное мьютексом, используется для синхронизации выполнения байткода. GIL упрощает разработку кода, работающего в многопоточной среде: CPython не надо думать о синхронизации доступа к переменным или о взаимных блокировках (deadlocks). За это приходится платить тем, что лишь один поток получает доступ и выполняет байткод в данный момент времени:

UPD: Но это не значит, что программа на Питоне волшебным образом заработает в многопоточной среде! Код на Питоне не переносится в байткод один в один и нет никаких гарантий о совместимости байткода между версиями! Поэтому синхронизировать потоки в коде вам всё-таки придётся. К счастью и тут у Питона имеется богатый набор средств, например, позволяющих переключаться между многопоточной и многопроцессной моделью выполнения.
Рекомендую прочесть статью Anthony Shaw "Has the Python GIL been slain?".
Каковы выходы из ситуации?
- Питон отлично взаимодействует с нативными библиотеками. В простейшем варианте (CFFI) нужно описать источник и сигнатуру функции в Питоне и вызывать её из динамической библиотеки. Для полноценной же работы с интерпретатором и окружением Питон предоставляет API для написания расширений (extensions) на C/C++. А порывшись в Гугле, можно найти реализацию расширений на Rust, Go и даже Kotlin Native!
- Использовать альтернативную реализацию Питона, например:
- PyPy, со встроенным JIT-компилятором. Прирост скорости будет меньше, чем при использовании нативного расширения, но может в конкретном случае большего и не будет нужно?
- Cython — транспайлер и компилятор надмножества языка Python в код на C.
- IronPython — имплементация, работающая поверх .NET framework.
Совет 8: Если вам априори важна скорость выполнения, эффективнее будет использовать Питон как связку между нативными компонентами и не пытаться впихнуть невпихуемое. Если же вы работаете над приложением, в котором IO (сеть, БД, файловая система) является узким местом, то к тому моменту, когда скорость Питона перестанет вас устраивать, вы точно будете знать, как решить эту проблему :)
Основные инструменты
Как начинаются первые шаги в Питоне? Если у вас под рукой Linux или MacOS, то в 95% случаев Питон будет установлен из коробки. Если вы живёте на острие прогресса, то скорее всего это версия 3.х, а не отживающая свой век версия 2.7. Для товарищей на Windows всё чуточку сложнее. Вот несколько вариантов: использовать Docker, Windows Subsystem for Linux, Cygwin, наконец, официальный инсталлятор Питона для Винды.
Совет 9: По возможности пользуйтесь свежей версией Питона. Язык развивается, каждая версия — это работа над ошибками и всегда что-то новое и полезное.
Вы уже написали "Hello world" и он работает? Превосходно! Через пару дней вы займётесь machine learning-ом и вам понадобится какая-нибудь библиотека из каталога Python Package Index (PyPI).
Чтобы избежать конфликтов версий при установке пакетов (packages), в Питоне используются т.н. виртуальные окружения (virtual environments). Они позволяют частично изолировать среду путём создания директории, в которой будут находиться установленные пакеты. Там же будут лежать шелл-скрипты для управления этой средой. Установщик пакетов pip также идёт в комплекте. При активированной виртуальной среде pip будет устанавливать пакеты именно в неё. А объединяет всё это такие утилиты, как pipenv или poetry — аналоги npm, bundler, cargo и т.п.
Совет 0xA: Ваши главные помощники для управления зависимостями — это pip и virtualenv. Всё остальное — это удобные, красивые, высокоуровневые обёртки. Ведь всё, что нужно нам и Питону — это правильный sys.path — список директорий, по которым пойдёт поиск модулей при их импорте.
Что же дальше?
Вы уже прочли официальный туториал? Тогда не поленитесь взглянуть и на туториал по вышеописанным инструментам. И как в небезызвестной копипасте:
Завтра ищешь в интернете книжку Dive into python...
Уверен, что у вас скопилась гора идей и чешутся руки взяться за новый проект на Питоне. Ведь редкий день проходит на Хабре без появления статьи о применении Питона там где, казалось, ему совсем не место :)
Дерзайте, камрады!
Комментарии (131)

andreymal
21.05.2019 20:33+1Вот, отличный пост.
sum([1, 2, 3)
Опечаточка
вам не надо думать о синхронизации доступа к переменным или о взаимных блокировках (deadlocks).
На самом деле надо. Освобождение GIL в общем случае случается в непредсказуемые моменты, и словить гонку при, например, манипуляции с одним и тем же объектом из нескольких потоков всё равно можно. Пример ниже, разумеется, говнокод, но суть проблемы всё равно демонстрирует, падая в KeyError:
from threading import Thread d = {} def thread1(): while True: if "foo" not in d: d["foo"] = 0 d["foo"] += 1 def thread2(): while True: if "foo" in d: del d["foo"] Thread(target=thread1).start() Thread(target=thread2).start()
Вот несколько вариантов: использовать Docker, Windows Subsystem for Linux, Cygwin
Ну точно так же и про линукс можно сказать, что есть вариант установить питон в Wine :)
Через пару дней вы займётесь machine learning-ом
Спойлер

zvulon
21.05.2019 20:45это верно, но я думаю имеется ввиду что из-за GIL выполняется всегда одна строка кода,
и прогнозировать лок в мультитреадед которые исполняют один и тот же код — проще,
атомарность на уровне строкиandreymal
21.05.2019 21:08+2из-за GIL выполняется всегда одна строка кода
В общем случае это тоже не всегда, в i+=1 тоже может поселиться GIL, из-за чего пример ниже не хочет печатать 1000000:
from threading import Thread i = 0 def func(): global i for _ in range(100000): i += 1 threads = [] for _ in range(10): threads.append(Thread(target=func)) threads[-1].start() for t in threads: t.join() print(i)

BasicWolf Автор
22.05.2019 09:18Спасибо за комментарий. Действительно написал двумысленно: хотел сказать, что разработчикам CPython и собственно самому CPython проще с гарантией выполнения байткода одним потоком. Подправил в тексте.
ni-co
21.05.2019 20:35" По возможности пользуйтесь свежей версией Питона." Много пакетов, на которых этот совет не прокатывает. Например, TensorFlow.
Siemargl
22.05.2019 07:55Не то слово. Например WebRTC (Chromium) build system — gclient тоже работает только на 2.8
Причем это нигде не написано и при попытке запустить на 3.6 она просто не работает _без_ адекватной диагностики.
Впрочем на 2.8 билд тоже пожужжал часов несколько и повис.
Такой вот прекрасный язык для крупных проектов =)
worldmind
22.05.2019 09:26А причём тут язык? Может дело в каких-то рукожопах написавших что-то криво?
worldmind
22.05.2019 09:36Мне кажется только гугл держится за вторую версию мёртвой хваткой, у них даже в облаке до сих пор нет третьего питона в продакшене, такая вот «технологичная» компания.
Хотя в данном случае всё должно быть ок судя по pypi.org/project/tensorflow всё поддерживается до 3.6Barafu_Albino_Cheetah
22.05.2019 18:02Ещё программа Calibre. Ведущий разработчик заявлял, что не перейдёт на Питон 3 даже после окончания поддержки второго. То, что он индус по национальности, не имеет никакого отношения ни к этому, ни к потрясающему количеству детских ошибок при работе с ДБ.

Stas911
23.05.2019 22:09Ну, справедливости ради, в aws тоже есть отдельные места, где до сих пор p27 только.
zvulon
21.05.2019 20:41я хочу заметить что атрибуты начинающиеся с _ protected а с __ private.
и это не просто конвенция, у прайватс происходит name hashing, так что у вас не получитсья переопределить прайват метод.

Pand5461
21.05.2019 21:10+2"Проще попросить прощения, чем спрашивать разрешение" (Easier to ask for forgiveness, than permission, EAFP).
А почему? А потому что
Питон медленный
А так есть ещё
Явное лучше, чем неявное.
Но если явно делать проверку валидности значений, то это анбоксинг переменной сначала для проверки условия, а потом ещё раз анбоксинг при передаче в обработку. Ясно, что быстрее, если в самой обработке уже сишная библиотека сделает проверку и кинет исключение.
Со словарями, конечно, отдельный случай. Там действительно есть проблема проверки наличия ключа — потому что занимает столько же времени, сколько и поиск элемента по ключу. Коммон Лисп на этот случай при извлечении элемента по ключу возвращает два значения — само значение или False, если ключ не найден, и то, найден ключ или нет — потому что False может само по себе лежать в словаре по искомому ключу. В других языках принято, если ключ не найден, кидать исключение — и после Лиспа это воспринимается как несколько экзотический способ просто вернуть второе значение.
Отсюда понятно, почему рекомендуется пользоваться try-except, когда нужно достать значение, но явным
if, если нужно добавить элемент при отсутствии — это ни черта не EAFP, а особенность работы хэш-таблиц. Ясен пень, если нужно вписать что-то, если его нет, — надо сначала убедиться, что его реально нет, и время на эту проверку никак не сэкономить. А вот если надо достать по ключу — то проверку действительно можно сэкономить, но нужно уметь как-то просигнализировать о неудачном поиске ключа. Можно было бы и без исключения обойтись, а возвращать, как в Лиспе, кортежем.worldmind
22.05.2019 09:27Со словарями, конечно, отдельный случай. Там действительно есть проблема проверки наличия ключа — потому что занимает столько же времени, сколько и поиск элемента по ключу.
т.е. очень быстро, а значит проблемы нет, тем более что есть dict.get() который позволяет задать дефолтное значение, о чём месье видимо не знаетPand5461
22.05.2019 10:06т.е. очень быстро, а значит проблемы нет
Достаточно медленно, чтобы уже рекомендовать не делать одну и ту же операцию дважды с нарушением принципа "явное лучше неявного". Это же анбоксинг, вычисление хеша, проход по таблице, разрешение коллизий — и всё это два раза, если сначала проверять наличие ключа, а потом брать значение по нему. Ну да, макс. 2000 инструкций против макс. 1000 — это всё равно O(1), если чисто по асимптотике считать.
тем более что есть dict.get() который позволяет задать дефолтное значение
Я же об этом написал. Пожалуйста, пусть возвращает. Как отличить — это дефолтное значение, которое по странному стечению обстоятельств было по искомому ключу положено или отсутствие ключа в таблице?
Ясно, что может быть алгоритм, по которому
Noneв словарь точно не положится, тогда его можно использовать как сигнальное значение. А что, блин, если нет?worldmind
22.05.2019 10:11Вот так понятнее, хотя ещё надо придумать реальные ситуации когда None нужен как значение.
Pand5461
23.05.2019 11:09Это да, но разработчик стандартной библиотеки понимает же, какой вой поднимется, сделай он "при отсутствии ключа в словаре возвращается
Noneбезо всяких там исключений".kt97679
23.05.2019 18:07Именно это происходит в ruby.
Pand5461
23.05.2019 20:20Я Руби не знаю. Доки пишут, что там при создании словаря определяется, что произойдёт при отсутствии ключа.
BasicWolf Автор
22.05.2019 10:35+1Камрады, давайте разберём:
class NotFound: pass val = dict.get(key, NotFound) if val is NotFound: ...
- без проблем.
Теперь разберём ситуацию, в которой
# допустим, что вероятность key not in dict ~ 10% val = dict.get(key, NotFound)
В синтетическом тесте, try..except может оказаться быстрее, например:
Много кодаN = 10000 P_IN = 0.90 d = dict(enumerate(range(int(N * P_IN)))) def sum_dict_in(): s = 0 for i in range(N): s += d.get(i, 0) return s def sum_dict_try(): s = 0 for i in range(N): try: s += d[i] except KeyError: s += 0 return s if __name__ == '__main__': import timeit print(f'Testing with {N} elements and probability of element in dictionary {P_IN}') print(timeit.timeit("sum_dict_in()", setup="from __main__ import sum_dict_in", number=1000)) print(timeit.timeit("sum_dict_try()", setup="from __main__ import sum_dict_try", number=1000))worldmind
22.05.2019 10:44не стоит погребать логику под if valid, если not valid — это исключительная ситуация.
Именно, если поля в словаре межет не быть в нормальной ситуации и это лишь повод для ветвления логики, то при чём тут исключения?
Более того, надо понимать, что исключения надо генерировать когда из внешнего мира пришли кривые данные или что-то во внешнем мире пошло не так, с чем программа не может справится, а это скажем так не так много мест.
А если мы валидируем входные данные для функции предполагая что своими кривыми руками что-то не так сделали, то это уже assert'ы, которые в продашене можно выключить и убрать оверхед.BasicWolf Автор
22.05.2019 10:58Давайте немного отойдём от словаря. Пусть это сокет, в который отправляются данные. Опять два варианта:
if socket.is_alive: socket.send(data)
try: socket.send(data) except NetworkError: ...
Пример из Oracle-овского драйвера в Django:
def close(self): try: self.cursor.close() except Database.InterfaceError: # already closed pass
Здесь нет проверок вроде
if self.is_closed. Django не думает, что кому-то вздумается вызывать.close()до покраснения :)worldmind
22.05.2019 11:05Тут как раз речь про внешний мир и это правильное место для использования исключений, это не ветвление логики, а именно попытка сделать то что нужно.
Pand5461
22.05.2019 11:04Пример для демонстрации принципа не очень хороший, имхо.
Там известно, что и где может пойти не так и известно, что в этом случае делать. А если всё это известно — как раз лучше явную проверку сделать. Именно со словарями лучше делать try-except по историческим причинам, в Лиспе вот отсутствие ключа не является исключительным случаем.
Логичнее сделать пример сферического калькулятора — от пользователя считывается строка как выражение, пользователю выводится результат вычисления. Пользовательский интерфейс понятия не имеет, как проверить выражение на корректность, алгоритмическая часть понятия не имеет, что делать в случае ошибки.
И ещё там так пишете, будто вылавливание исключения делает байпасс проверок — но проверка же где-то всё равно должна выполниться. Но если проверку делает под капотом какая-то сишная библиотека — то, действительно, может оказаться быстрее, чем в самом питоне.
Ну это я просто за другой подход — что лучше один раз подумать, где может пролезть исключительная ситуация и как её не допустить, чем каждую функцию писать в предположении, что на вход поступает полная абракадабра. Задачи численного моделирования такой подход очень сильно ускоряет.
assembled
22.05.2019 16:09dict.get не для проверки наличия ключа, значение по-умолчанию позволяет в некоторых случаях делать меньше проверок, например:
print(key, myDict.get(key, "N/A"), sep = ': ')

germn
22.05.2019 09:56«Проще попросить прощения, чем спрашивать разрешение» (Easier to ask for forgiveness, than permission, EAFP).
А почему? А потому что
Питон медленный
Потому такой код легче читается и модифицируется: вы говорите что вам нужно получать, а клиентский код (вызываемая функция) либо возвращает результат, либо (с помощью исключения) сигнализирует об ошибке. Это задача клиентского кода проверять условия необходимые для выполнения задачи. Вызывающий код не должен знать про то что, как и где нужно проверять.Pand5461
23.05.2019 11:58Дело в том, что лет 8-10 назад была статья, кажется про PHP, где автор предлагал избавляться от условных выражений вообще и переходить на исключения. Ветвление — дорогая операция, мол, и т.д. ЧСХ, примеры показывали, что действительно — на исключениях быстрее.
Я в те времена был совсем молодой и глупый, слышал только про Си и никак не мог понять — НО КАК? Ну, компьютер, хоть бы и на исключениях, всё равно не может магически выбирать всегда правильную ветку выполнения. Где-то там для этих исключений должны ведь производиться эти самые проверки.
Сейчас думаю, что это всё в интерпретируемых языках может действительно быть быстрее, т.к. генерация и обработка исключений написана на быстром языке, который под капотом.
А потом придумывают какую-то философию вместо того, чтобы объяснять логически, почему в таких-то случаях так-то делать действительно лучше, быстрее и чище.
worldmind
23.05.2019 14:01Скорее всего эконмия на спичках, и в любом случае никто от условий отказываться не предлагает (кроме маргиналов всяких), у всего своё место в соответствии с семантикой.

Fen1kz
21.05.2019 23:02Хорошая статья, а есть где почитать про экосистему? Откуда брать библиотеки, как совладать с пипом и почему для каких-то либ надо ставить отдельные пакеты через sudo apt install?
Потому что после npm это кажется каким-то адом. Типа все зависимости всех проектов в кучу, что? Я уже молчу (хотя хочется кричать от ужаса) что питона 2 версии и все говорят «используй третий», но сами используют второй (-_- )andreymal
22.05.2019 00:03+3Откуда брать библиотеки
pypi.org
как совладать с пипом
В каком смысле? pip install обычно просто работает. Единственное, что нужно помнить, это что pip по умолчанию пытается ставить всё глобально, и обычно нужно создать virtualenv (в npm соответственно наоборот, аналог virtualenv он создаёт автоматически в виде node_modules)
почему для каких-то либ надо ставить отдельные пакеты через sudo apt install?
Так в npm то же самое: перед запуском какого-нибудь npm install opencv нужно не забыть сделать sudo apt-get install build-essential libopencv-dev. Причина и у pip, и у npm одна и та же: чтобы собрать биндинги к нативным библиотекам.
все зависимости всех проектов в кучу
Нет, см. virtualenv
но сами используют второй
Это называется легаси :(

hardtop
22.05.2019 00:32Экосистема сильно зависит от сферы деятельности\интересов. А так стаковерфлоу дай много ответов про Питон.
Sudo — лишь для того, что лезет в систему. Типа, библиотека Pillow использует libjpeg. А там компиляция нужна, если нет в системе.
Зависимости и кучи. Используйте virtualenv для каждого проекта — и все пакеты будут локально, в нужной песочнице. Удобно.
Да, сам сижу на 2-м. А потому что есть часть старого кода. Хотя один проект решил начать на 3-м питоне.
Но сейчас с нуля учить только 3-й питон. Ну, чтоб без вот этого u«это юникодная строка»
worldmind
22.05.2019 09:34Почитать про экосистему можно во всяких awesome python списках, навроде такого.
С пипом проблем нет, но лучше не ставить через него ничего с sudo, а делать
pip3 install --user needed_lib
тогда всё будет ставиться в хомдиру в .local/ (только стоит проверть что .local/bin прописал в PATH)
если проектов много с разным набором либ, то чтобы не они конфликтовали стоит использовать virtualenv, это позвоялет юзать разный набор либ, но с одной версией питона, если в разных проектах нужны разные версии питона, то есть pyenv со своей приблудой для venv.DonAgosto
23.05.2019 23:02если в разных проектах нужны разные версии питона, то есть pyenv со своей приблудой для venv.
мне кажется, что здесь уже точно стоит подключить Dockerandreymal
23.05.2019 23:52Мне кажется, нет никаких проблем установить несколько версий питона в систему без конфликтов (и даже без pyenv). Имею 2.7, 3.3, 3.4, 3.5, 3.6 и 3.7, поставленные штатным пакетым менеджером арчлинукса — отлично работают
DonAgosto
24.05.2019 09:19я не спорю, что можно, но мы же здесь про best practice все-таки.
такой зоопарк версий (и питона и всех бинарных пакетов со всеми зависимостями) однозначно ведь добавляет проблем при сопровождении, обновлениях системы, переездах/миграциях.
ну если конечно скрипты простые/одноразовые, мало зависимостей, продакшена не будет, то тут естественно пофиг (хотя тогда не понятно зачем такой зоопарк)andreymal
24.05.2019 12:14best practice — код, не приколоченный намертво к одному-единственному конкретному окружению :) Тестирую свои проекты в окружениях от 2.7 до 3.7 (или от 3.5, если решил дропнуть второй питон), по возможности и на PyPy, от фряхи до винды и иногда даже Termux на Android — отлично работают. (Впрочем, на серьёзный продакшен я действительно не претендую). А там уже хоть pyenv, хоть docker, хоть vagga+lithos
worldmind
24.05.2019 08:37Всё зависит от проекто/желания, конечно если проект будет деплоится в докер, то в нём его и надо тестить, а если что-то на попробовть, поэкспериментировать, то как по мне проще venv.
BasicWolf Автор
22.05.2019 09:41Если бы библиотеки Питона писались только на самом Питоне, то тогда бы подобных проблем было бы меньше. А теперь представьте, что вам нужна нативное расширение, например PIL/Pillow для обработки изображений? Есть два варианта — либо вы скачиваете кем-то скомпилированное и упаковонное расширение под вашу платформу и вашу версию Питона, либо скачиваете исходники и компилируете его сами!
pipможет сделать и то и другое, но для компиляции ему нужен собственно компилятор, заголовочные файлы Питона, исходники или бинарники зависимостей и т.д.
npm пришёл из экосистемы, где всё пишется на JS. А в Питоне, помимо пакетов с "чистым" Питоном есть расширения, которые могут быть написаны на C/C++ и т.д. Отсюда и разница.
staticlab
22.05.2019 12:15А в Питоне, помимо пакетов с "чистым" Питоном есть расширения, которые могут быть написаны на C/C++ и т.д.
В npm тоже достаточно таких пакетов.
Siemargl
22.05.2019 09:52все говорят «используй третий», но сами используют второй
Потому что библиотеки переписывать долго, муторно, и главное — зачем?
А питон весь в зависимостях. В папку пипа смотреть страшно.
germn
22.05.2019 10:00Потому что после npm это кажется каким-то адом.
Один раз установите глобально и используйте poetry (ну или pipenv) — это `npm` для Питона.
и все говорят «используй третий», но сами используют второй
Уже давно всё не так страшно. Не помню, когда последний раз сталкивался с отсутствием поддержки тройки.
Vitaly83vvp
22.05.2019 08:02Моё знакомство с Python было в 2008. Когда мне дали задание написать генератор PDF отчётов на основе данных из PostgreSQL, я даже и не слышал об этом языке. Но он оказался, на удивление, прост и реализация задания не составила особого труда. Благо, уже на тот момент были справочные материалы и примеры кода. Идея выравнивания кода с одной стороны хороша, но, как уже упоминал автор, при большом объёме кода становится сложнее читать. И, да, каждый язык это всего лишь инструмент. Удобство использования определяется привычками и опытом.
worldmind
22.05.2019 09:35Идея выравнивания кода с одной стороны хороша, но, как уже упоминал автор, при большом объёме кода становится сложнее читать.
атор и говорит, что это должно стимулировать не писать нечитаемый кодVitaly83vvp
22.05.2019 09:42Не спорю. Просто при переходе с других языков, это первое непонимание, что встречается на пути. Просто нужно перестроить стиль. В принципе, других сложностей до сих пор не встречал.
adictive_max
22.05.2019 09:43атор и говорит, что это должно стимулировать не писать нечитаемый код
Бывают случаи, когда от разбиения кода на отдельные функции, он становится только ещё менее читаемым.
germn
22.05.2019 10:04+1при большом объёме кода становится сложнее читать
Сложнее становится читать, не когда кода много, а когда пишете не в терминах предметной области (читай — не разбиваете код на понятные функции).
alkresin
22.05.2019 11:39А что мне надо установить у пользователя моей программы?
Питон, пип и все пакеты, использованные при разработке?BasicWolf Автор
22.05.2019 11:43Питон, пакеты и библиотеки которые требуются для работы программы. Есть также бандлеры, которые с переменным успехом собирают Питон и зависимости в единый исполняемый файл.
Barafu_Albino_Cheetah
22.05.2019 18:32В Windows есть возможность упаковать всё в один EXE. В Linux качать зависимости — это норма, никто не возмутится. (Но можно и упаковать, опять же). Вот в Android придётся заставлять юзера пошаманить руками, отчего Питон под Android толком и не взлетел.

amarao
22.05.2019 11:57Когда я познакомился с Python, мне обещали утиную типизацию. Если оно выглядит как строка, крякаяет как строка и плавает как строка, то это и есть строка...
class X: def __str__(self): return "I'm X" arr = [X()] ",".join(arr) Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: sequence item 0: expected str instance, X found
Oh, rly?
Потом я попробовал поймать несколько исключений:
expected = set([IOError, MemoryError, FileNotFoundError]) try: with open("/none"): pass except expected as e: print("Good exception", e) Traceback (most recent call last): File "<stdin>", line 4, in <module> TypeError: catching classes that do not inherit from BaseException is not allowed
WUT?
Если написать
expected = (IOError, MemoryError, FileNotFoundError), то код сработает. Причины? Утиная типизация — если оно выглядит как тапл, ведёт себя как тапл, крякает как тапл, то оно нифига не тапл. Питон ВСЁ ВИДИТ И НЕ ПРОЩАЕТ.
Но у нас же есть статическая типизация… Которая совершенно опциональна и не вызывает ошибок ни на каком этапе.
Ах, да, потом мне рассказали как пакетировать питон. С помощью wheel, setuptools distutils easy_setup через pycentral в pip. Если ничего не пропустил.
А ещё окончание итерации — это exception StopIteration. Отличный метод использовать exception'ы. Может, сделаем это стандартом?
with open("file") as f: raise Result(f.read())
Вот потеха будет-то...
Чуден язык, да и только.
worldmind
22.05.2019 12:01Например наличие метода __str__ никоим образом не означает что это строка, это не апи строки, это апи приведения к строковому виду.
amarao
22.05.2019 12:08А что надо сделать, чтобы данный класс начал утино типизироваться к строке?
fireSparrow
22.05.2019 12:45+1Вы путаете тёплое с мягким.
Если некий код ожидает от объекта наличие определённого метода, то он может просто дёрнуть этот метод у любого объекта, у которого такой метод есть, и коду вообще не нужно знать, от какого класса инстанцирован этот объект. Это и есть утиная типизация.
Но если код ожидает объект определённого класса, то ему нужно дать объект определённого класса. Никакой другой класс не подойдёт, какие бы вы методы в него не напихали.
Ваш пример со строкой, например, будет прекрасно работать, если вы унаследуете класс X от класса str. Но в любом случае, это уже вопрос не про утиную типизацию.amarao
22.05.2019 12:55Я не путаю тёплое с мягким. Я говорю, что когда "код ожитает объект определённого класса" — это нарушение утиной типизации. Зачем он ожидает объект определённого класса? Чтобы посмотреть некоторые его атрибуты или вызывать его методы. Если я сделал те же атрибуты и дал те же методы, зачем кто-то проверяет на "определённый класс"? Как только язык начинает требовать наследоваться от str, чтобы насладиться str.join, то у нас начинается какая-то java с virtual/final и ООП как "основы всего", а не питон.
fireSparrow
22.05.2019 13:00Ну то есть утиная типизация в самом языке есть, просто язык сам использует её не во всех случаях, где теоретически мог бы.
То есть ваше утверждение об отсутствии утиной типизации неверно.
BasicWolf Автор
22.05.2019 13:02amarao, давайте не будет переливать из пустого в порожнее. Как было сказано — "except принимает tuple и ничего больше, потому что у нас так принято" :) С вами с удовольствием обсудят это в Python mailing list и может даже дело дойдёт до PEP-a. Питон не закрытый язык, если у вас есть идея, как его улучшить или исправить — дело за малым :)
amarao
22.05.2019 13:05Окей. Я просто показал, насколько питон не такой, каким он кажется. Глубоко в недрах его стандарта много веселья и костылей уровня языка.
Исправлять их никто не будет, потому что "used in production".
geisha
22.05.2019 14:25+1Исправлять их никто не будет, потому что "used in production".
Там нечего исправлять. В первом случае дак-тайпинг вполне работает, просто вы его не поняли (ожидается Iterable и определять нужно __iter__, а не всякие __str__ и __repr__):
>>> x = 'a', 'b', 'c' >>> ''.join(x) 'abc'
С вашим видением ситуации можно докатиться и до абсурдного
>>> ('a', 'b', 'c') == 'abc' True >>> object() == "<object object at 0x7fb21a5e90c0>" True
Во втором вашем случае вполне оправданное ограничение, иначе придётся выслушивать на тупых собеседованиях тупые вопросы, вроде "что сделает этот код"
class A(BaseException): def __iter__(self): yield ValueError raise StopIteration try: raise A except A: print "A" except ValueError: print "B" except: print "C"
Питон и так достаточно гибкий язык для сексуальных утех, но для мазохизма не годится, да. Попробуйте джулию, что ли.
amarao
22.05.2019 14:50Окей, вы меня убедили. В питоне всё потрясающе! Надо больше exception'ов для нормального рабочего процесса, наподобие StopIterator, побольше внезапных isinstance. Что там там ещё хорошего питон обещает? (*args, **kwargs) как вершину динамической типизации?
BasicWolf Автор
22.05.2019 13:06P.S. https://hg.python.org/cpython/file/tip/Python/ceval.c#l5159 — причина по которой tuple логично использовать в CPython — это представления tuple в виде обычного массива с указателями. Работать с ним намного проще и быстрее чем с любой другой коллекцией.
worldmind
22.05.2019 15:20Реализовать апи строкового класса оно описано в документации, только учитывайте, что он наследник sequence.
Но для приведённого вами примера этого не требуется, вам тут в комментарих уже отвечали.
worldmind
22.05.2019 12:03Про исключения не очень понял что вы хотели сказать, что не так? Конечно если положить в множество ссылку на массив, а не сами значения, то оно не будет работать как множество значений.
amarao
22.05.2019 12:10Э… Что за ссылка на массив в моём питоне?
Возможно пример был слишком сложный. Объясняю: если вы хотите поймать несколько exception'ов в одном
except, вам надо положить их в tuple. И только в tuple. Что угодно другое, каким бы итерируемым, индексируемым и иммутабельным оно не было, не прокатит. Причём ошибка, которую выдаст питон, будет феерически запутанной. Это пример №2 нарушения утиной типизации в самом языке.BasicWolf Автор
22.05.2019 12:41Не соглашусь. Здесь затрагивается спецификация языка, в которой чёрным по белому написано:
...For an except clause with an expression, that expression is evaluated, and the clause matches the exception if the resulting object is “compatible” with the exception. An object is compatible with an exception if it is the class or a base class of the exception object or a tuple containing an item compatible with the exception.
tuple containing an item — ключевой момент. Спецификация не допускает каких либо других контейнеров в этом месте.
amarao
22.05.2019 12:44Так я про это и говорю.
Одной рукой пишем "утиная типизация", а другой говорим "только объекты класса tuple".
Я утверждаю, что это место в спецификации — это нарушение собственных принципов и яркий пример неконсистентности. Пример с str.join ровно о том же.
… Причём в каком-нибудь суперфашистском языке уровня Rust, где без правильных типов даже чихнуть нельзя, и то большая гибкость за счёт трейтов. А тут — динамически типизированный язык с утиной типизацией, который проверяет аргументы через isinstance. Позор, да и только.
fireSparrow
22.05.2019 12:46+1То, о чём вы пишете, не имеет отношения к утиной типизации. Посмотрите вот этот мой коммент — habr.com/ru/post/450724/#comment_20184610
BasicWolf Автор
22.05.2019 12:46По-поводу
str.join()требующей итерируемое со строками — это тот самый случай из дзена — "Явное лучше неявного" и в какой-то мере "Принцип единой ответственности" (Single responsibility principle). От вас требуется явным образом привести объекты, пераданныеstr.join()к строке, так как Вы отвечаете за представление каждого объекта в строковом виде, аstr.join()лишь за их конкатенацию.
Barafu_Albino_Cheetah
22.05.2019 19:05Иногда для скорости приходится жертвовать чистотой кода. Класс BaseException и tuple содержит элементы, написанные на С, и их невозможно имитировать средствами Питона. Поэтому есть жёсткое требования наследования от конкретного класса, чтобы получить эти элементы. Как вам такое?
1 2 class Point(tuple): 3 def __new__(self, x, y): 4 return tuple.__new__(Point, (x, y)) 5 6 expected = Point(IOError, FileNotFoundError) 7 try: 8 with open("/none"): 9 pass 10 except expected as e: 11 print("Good exception", e) #Работает!
Вообще, хорошая часть стандартной библиотеки Питона написана не на Питоне, что ограничивает число возможных выкрутасов с ней.
В первом примере со строкой вам нужно имитировать не класс str, а интерфейс iterable, про что уже написали.amarao
23.05.2019 09:35В первом примере у меня был arr=[X()], и мне, в силу моего скудного знания питона, кажется, что list вполне интерфейс iterable реализует.
fireSparrow
22.05.2019 11:59+3Всё-таки перенос строки с помощью слэша — не очень хорошо.
Во-первых, если после слэша вкрадётся пробел, то это всё сломает, и причина ошибки может быть довольно неочевидна.
Во-вторых, это, конечно, дело вкуса, но код со слэшами-переносами лично мне читать сложнее.
Вместо такого:
query = User.objects .filter(last_visited__gte='2019-05-01') .order_by('username') .values('username', 'last_visited') [:5]
я всегда пишу такое:
query = (User.objects .filter(last_visited__gte='2019-05-01') .order_by('username') .values('username', 'last_visited') )[:5]BasicWolf Автор
22.05.2019 12:50+1, обычно и сам так пишу. Использовал слеши, чтобы не пугать впервые видящих подобное :)
query = ( User.objects .filter(... ... .values('username', 'last_visited') [:5] )```
alex_zzzz
22.05.2019 15:38-1"Ты же форматируешь код отступами?", спросил VlK. Конечно же я форматировал его. Точнее, за меня это делала спираченная Visual Studio. Она справлялась с этим чертовски хорошо. Я никогда не задумывался о форматировании и отступах — они появлялись в коде сами по себе и казались чем-то обыденным и привычным. Но крыть было нечем — код был всегда отформатирован отступами.
Вот и покрыл. В то время как космические корабли бороздят просторы вселенной, а код на условном X# можно писать практически в одну строку и он сам форматируется, в Питоне приходится всё форматировать руками, как деды форматировали.
worldmind
22.05.2019 15:42на условном X# надо руками скобочки расставлять как деды делали
alex_zzzz
22.05.2019 16:01Скобочки отлично работают. Закрыл скобку-две-три ? и всё, что было внутри них, автоматом само перенеслось и само выровнялось как надо, согласно логике. Обрамил блок скобочками, он бац ? сдвинулся вправо. Убрал скобочки ? сдвинулся влево. Вырезал кусок из одной функции, вставил в другую, он на новом месте сам выровнялся как надо. А если форматирование вдруг перекосило, то наличие ошибки в коде понятно сразу, а после того как будешь исправлять форматирование руками и пасьянс не сойдётся.
Когда Питон придумывали, такого почти полного автоматизма не было. А теперь Питон придумали и уже поздно.
worldmind
22.05.2019 16:14При копипасте могут быть неудобства, хотя редко, нормальные инструменты справляются с типовыми случаями, а форматирование перекосило это выдуманная проблема.
alex_zzzz
22.05.2019 16:43Под "перекосило форматирование" я имел ввиду X#: когда вставляешь из буфера или удаляешь кусок и код вокруг разъехался. Если разъехалось, значит точно есть косяк. Не туда вставил, не всё скопировал, лишнего скопировал, не всё удалил, удалил лишнее. Автоформат — это как дополнительный контроль ошибок, который выполняет IDE, а не ты руками и глазами.
StriganovSergey
22.05.2019 18:18+1Вот, кстати, можно написать редактор или плагин к ребактору, который в коде питона отображает скобочки, и позволяет их вводить, а в файл сбрасывает так любимые питоном отступы :)
assembled
22.05.2019 15:57Попробуйте перейти с ed (или что у вас там?) на какую-нибудь современную иде. Они делают отступы автоматически. Вам понравится, я гарантирую!
alex_zzzz
22.05.2019 16:31Если речь про автоматические отступы в начале новой строки ? это фигня. Я свой код в разы больше редактирую, чем пишу с чистого листа.
Элементарное
if x < 0: x = 0 n = n + 1 if n > 100: w = 1
Если в конец или середину вставить несколько строк с каким-то своим отступом, современная IDE должна им отступ выправить? Конечно, чай не в блокноте пишем. А на какой? А на хз какой.
Да даже если пишем этот код с нуля и просто после w = 1 переходим на новую строку, нажать } ничем не сложнее, чем нажать Enter и Backspace для отмены одного уровня отступа.
worldmind
23.05.2019 10:38Вобщем моё видение такое, да, в редких случаях копирования куска кода на его форматирование нужно будет чуть больше времени чем в скобочных языках, но код пишется раз, а читается много раз, читаемость важнее писяемости, на мой взгляд питон значительно более читаем.
Тут в коментах был разговор про добавление скобочек в питон, пошёл глянул примеры — ужасно, хотя на питоне я пишу меньше года, а раньше писал как все со скобками.

IGR2014
22.05.2019 16:55пример из статьи
@property def x(self): return self._x @x.setter def x(self, val): if val > 10: self._x = val else: raise ValueError('x should be greater than 10') ... c.x = 5
геттер/сеттер на С++
int SomeClass::getX() const { return this->x; } void SomeClass::setX(const int val) { if (val > 10) this->x = val; else std::cout << "x should be greater than 10/n"; } ... c.setX(5);
Объём работы по написанию кода примерно одинаков.
Хотя из преимуществ вижу «подкапотную» проверку, которая выполняется для x в Питоне.
Спорное удобство лично для меня т.к. привычней когда = является = без лишних проверок. В сеттере-же я буду ожидать с 50% вероятностью проверку значения на попадание в некий интервалworldmind
22.05.2019 17:08Дело в том, что геттеры и сеттеры в питоне нужно писать только если нужна дополнительная логика, если нет, всё работает словно они написаны, не нужно писать шаблонного кода.
IGR2014
23.05.2019 10:11Логично, в статье указано что все члены класса открыты. Но без дополнительной логики аналогичное поведение у полей struct в C/C++ — их поля по умолчанию открыты. Тоже не нужно писать ни строчки шаблонного кода.
andreymal
23.05.2019 11:30А если однажды понадобится переделать поле в проперти с геттером-сеттером?
IGR2014
23.05.2019 17:40С такой точки зрения да, это удобно программисту который работает над проектом сейчас. Но если на его место придёт другой, который продолжит поддержку — его явно не обрадует сеттер с условиями, скрывающийся за обычным c.x = 5. Поэтому я и пытаюсь сказать что словосочетание «правильный подход» в данном случае довольно субъективно
andreymal
23.05.2019 17:53+1А по-моему это как раз правильно, это больше походит на «каноничное» ООП с типа отправкой сообщения вида «уважаемый объект, пусть x будет 5, пожалуйста?». Я любое такое присваивание воспринимаю как синтаксический сахар для setX — независимо от того, есть ли сеттер на самом деле или нет.
(Я бы сказал, что то, что в C++ так нельзя, является недостатком C++, но он всё равно не позволит себе так делать из-за возникающих накладных расходов и/или несовместимостей ABI) (Или можно, а я не в курсе?) (Гугл предлагает перегружать operator=, но это слишком странно)
MacIn
23.05.2019 22:24Здесь удобен подход Delphi, пусть закидают меня помидорами.
Мы определяем property как
fX: integer; .. public .. property X: integer read fX write fX;
И если нам нужно перекинуть все в сеттер, мы делаем:
fX: integer; procedure SetX(AX: integer); public .. property X: integer read fX write SetX;
IGR2014:
скрывающийся за обычным c.x = 5. Поэтому я и пытаюсь сказать что словосочетание «правильный подход» в данном случае довольно субъективно
Да нет, напротив. Внутренние данные объекта, его внутреннее состояние — это его личное, интимное дело. Если бы это была структура — понятно, мы просто работаем с полем. Если это объект, то у него могут быть свои взгляды на то, как реагировать на внешнее изменение. На то он и объект, на то и инкапсуляция. Никаких предположений на тему «мы закинули 5 в х, там и должно быть 5» быть не может.Pand5461
24.05.2019 00:43Никаких предположений на тему «мы закинули 5 в х, там и должно быть 5» быть не может.
Вот такое ООП точно не нужно. Нет уж, если мы пытаемся закинуть 5 в x — пускай там будет или 5, или объяснение, почему именно 5 там быть не может.
MacIn
24.05.2019 01:29Нет уж, если мы пытаемся закинуть 5 в x — пускай там будет или 5, или объяснение, почему именно 5 там быть не может.
Потому что это не поле данных и не простой native тип, для которых определен контракт «что положили, то и есть». Это интерфейс взаимодействия с объектом, и он сам определяет, как реагировать. Допустим, внутри него вообще нет никакого X — что тогда?
Допустим, есть максимальное допустимое значение, которое меньше 5 или более оптимальное значение Х, которое известно самому объекту (например, Х — это количество элементов, которое может хранить объект, а ему выгоднее выделять память степенями двойки).DonAgosto
24.05.2019 08:40мне кажется в большинстве случаев логичнее и понятнее все-же строить такой интерфейс по типу «уставка» в терминах автоматики — а она должна оставаться такой же, какой ее первый раз сделали. вот что объект будет с ней внутри делать — это его «интимное» дело, да
и даже если с Х нужно что-то сделать и вернуть его-же, но в измененном виде, все равно стоит делать явные и раздельные «вход» и «выход»
Pand5461
24.05.2019 09:18Потому что это не поле данных и не простой native тип, для которых определен контракт «что положили, то и есть». Это интерфейс взаимодействия с объектом, и он сам определяет, как реагировать.
Да, но если этот интерфейс выглядит так же, как команда простого присваивания для "простого native типа", то уж пусть он и работает примерно так же. Если надо что-то именно сложное и странное — то использовать явный сеттер, чтоб было видно, а неявный через
=пускай вообще бросает исключение всегда.
Этак можно дойти до "руль и педали — это вообще-то интерфейс взаимодействия с автомобилем, решили мы сделать ускорение / торможение поворотом руля, а повороты нажатием педалей — всё ОК, читайте документацию".
Допустим, внутри него вообще нет никакого X — что тогда?
В Питоне — оно там появится (не то чтобы мне это нравилось).
Допустим, есть… более оптимальное значение Х, которое известно самому объекту (например, Х — это количество элементов, которое может хранить объект, а ему выгоднее выделять память степенями двойки).
Тогда количество элементов должно называться Y, а сеттер для X менять именно Y на степень двойки, а X — на то, что сказали.

gatoazul
22.05.2019 17:22Прежде, чем учить язык, я всегда спрашиваю себя: зачем его придумали? Какие задачи он должен был легко решать?
Для Питона ответ такой:
Его придумали как противовес Перлу. Чтобы делать то же самое, что на Перле, но с красивым и ясным синтаксисом.worldmind
22.05.2019 17:47Перл тут ни при чём, есть ниша для этого класса языков (быстрая разработка, небольшие проекты с возможностью роста, всякая автоматизация) и питон похоже становится лидером в этой нише несмотря на долгий кризис из-за затянувшегося перехода со второго на третий.
gatoazul
23.05.2019 10:24Как это ни при чем? Перл первым занял нишу массовых динамических языков. Чем Питон лучше Перла? Только синтаксисом.
StriganovSergey
22.05.2019 17:22+1Лично для меня, сложность перехода на Питон, заключается в отсутствии необходимости. Бритва Оккама. Если я уже умею решать любые задачи, более чем на шести языках программирования, на любой случай имею кое-какие готовые наработки, то трудно доказать необходимость решать задачи не так, как знаешь и умеешь.
worldmind
22.05.2019 17:44Да никто и не заставляет, должна быть внутренняя мотивация, я вот решил что питон позволяет мне писать значительно более читаемый код и перешёл на него.
melesik
22.05.2019 18:47С какого языка перешли? Я вот всё не могу Перл бросить. У меня так быстро получается делать что угодно на нём, и это всё кушает мало памяти и cpu, что никак не могу понять, что с этим Питоном не так.
worldmind
22.05.2019 18:49С перла и перешёл, понял что не воспринимаю его как эффективный инструмент.
assembled
23.05.2019 09:46Раз вы так любите спецсимволы и смыслоёмкие конструкции, ни в коем случае не учите J, а то без работы останетесь ;)

Megadeth77
22.05.2019 18:48Дзен про явное лучше неявного крайне своеобразный в Питоне. Типа self надо таскать везде, но при этом к магической комбинации подчеркиваний само собой имя класса прицепится и узнаешь ты об этом (если конечно не вызубрил все пепы) случайно из статьи на хабре.
asdfgh
22.05.2019 20:34А знаете, какой побочный эффект у всего этого безобразия? Программист старается избегать длинных конструкций.Как только размер функции выходит за вертикальные границы экрана, становится сложнее различать, к какой же конструкции относится данный блок кода
Отступы используются во всех языках, а если не видно начало/конце функции (и скобок) — в чем отличие от других языков?BasicWolf Автор
23.05.2019 08:25+1Скобки явным образом определяют тело инструкции. Ингода, это выливается в ложное видение области — думаешь, что находишься в теле какого-нибудь огроменного if-а, а на самоме деле уже давно вылез куда-то ещё.
В Питоне, с отсутствием скобок, становится не комфортно писать подобные простыни.assembled
23.05.2019 10:00Так не пишите простыни, со скобками тоже не сразу понятно в каком блоке находишся, например:
} } } doSomething(); } } } return x; }
Тут помогает только подсветка скобочек в редакторе или свёртка блоков кода, что и с питонокодом работает. Так что проблема надуманная.alex_zzzz
23.05.2019 13:15И ещё два варианта:
- Отступы не в два пробела, а 4 минимум. Я два пробела почти не воспринимаю, что они есть, что их нет.
- Block Structure Guides ? вертикальные полоски, которые связывают начало и конец блока (https://dailydotnettips.com/turning-onoff-structure-guide-lines-in-visual-studio-2017/)

mithron
23.05.2019 10:09Привет! Это ностальгия? ))
По теме: в ходе разговора тут понял, что еще одна не очень очевидная особенность Python — чтобы нормально писать python-код, надо его отлаживать. На Си достаточно просто написать достаточно сложный код, ни разу его не запустив, только компилируя и проверяя ошибки. На python проще всего несколько раз написать ошибочный код, запустить его, посмотреть что там внутри происходит и переписать. Грубо говоря, для нормальной быстрой разработки на python нужен рабочий runtime. Из-за динамической утиной типизации.
Или надо больше доков читать и исходников библиотек.BasicWolf Автор
23.05.2019 10:35TDD :)
mithron
23.05.2019 11:09И это тоже. Но еще и необходимость на рабочем месте запускать весь env/иметь доступ к нему. Поэтому и необходимо наличие тестовой инфраструктуры и еще и ограничитель на сложность env — большие проекты сложно на одном рабочем месте развернуть.
andreymal
23.05.2019 11:35На Си достаточно просто написать достаточно сложный код, ни разу его не запустив
Когда я так пытался делать, у меня при первом запуске обычно случался незамедлительный сегфолт. Не потому что я тупой, а просто по невнимательности и где-то какую-то мелочь забыл прописать. Так что для «нормальной быстрой» разработки на Си нужно быть чудовищно опытным, хорошо выспавшимся и изолированным от мира, чтобы не отвлекали и не сбивали внимательность
mithron
23.05.2019 11:44IDE помогают )) Сильно. Особенно в крупном проекте. В Python даже в крупном проекте часто IDE не могут подсказать, что именно в этом объекте — утиная динамическая типизация.
andreymal
23.05.2019 11:49Верю, что помогают, конечно, но блог PVS-Studio демонстрирует, что IDE и даже cppcheck помогают всё же не всегда.
Слыш купи
В Python даже в крупном проекте часто IDE не могут подсказать, что именно в этом объекте
Поэтому я сейчас стал прописывать аннотации типов абсолютно везде: и PyCharm подсказывать может, и mypy позволяет выловить ошибки без запуска. Не все, конечно (утиную типизацию даже с аннотациями никто не отменял, да и легаси тоже), но тем не менее «помогают )) Сильно.»
mithron
23.05.2019 11:54Согласен. Собственно разница как раз в том, что в языках со статической типизацией есть принуждение ко всему этому, а в Python принуждения нет. Это помогает легче стартовать, но потом в большом проекте становится сложнее.
P.S. Пришел в голову язык с обязательными тестами.worldmind
23.05.2019 11:55Это же гибкость, пока тебе не нужна типизация никто не принуждает, а когда проект дозрел — вот пожалуйста.
andreymal
23.05.2019 11:59А когда проект дозрел — уже поздно.) Взять и расставить типы в произвольном коде в общем случае довольно трудно, если он тщательно обмазан всякими там декораторами, ленивостью, генерируемыми на лету классами, getattr'ами и прочим метапрограммированием, так что mypy выпадает в осадок
worldmind
23.05.2019 14:02Я слышал про вполне успешные кейсы, хотя проблемы есть, но в основном из-за внешних библиотек без тайпхинтов.
Stas911
23.05.2019 22:14Выше много писали про форматирование — я просто запускаю flake8 и black (vscode поддерживает оба, кстати). То же самое можно и в CI прикрутить.
HeaTTheatR
Отличная статья!
BasicWolf Автор
Спасибо! А ещё большое спасибо berez за помощь с орфографией, пунктуацией и стилистикой :)