

Предыстория
Так произошло, что сервер был атакован вирусом шифровальщиком, который по "счастливой случайности", частично отставил нетронутыми файлы .ibd (файлы сырых данных innodb таблиц), но при этом полностью зашифровал файлы .fpm (файлы структур). При этом .idb можно было поделить на:
- подлежащие восстановлению через стандартные средства и гайды. Для таких случаев, есть отличная статья;
- частично зашифрованные таблицы. Преимущественно это большие таблицы, на которые (как я понял), злоумышленниками не хватило оперативной памяти на полное шифрование;
- ну и полностью зашифрованные таблицы, не подлежащие восстановлению.
Определить к какому из варианта относятся таблицы удалось открыв в любом текстовом редакторе под нужной кодировкой (в моём случае это UTF8) и просто просмотрев файл на наличие текстовых полей, например:
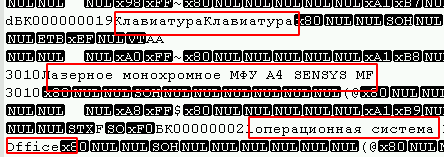
Также, в начале файла можно наблюдать большое количество 0-вых байт, а вирусы использующие алгоритм блочного шифрования (наиболее распространено), обычно и их затрагивают.

В моём случае, злоумышленники в конце каждого зашифрованного файла оставляли строку из 4 байт (1, 0, 0, 0), что упростило задачу. Для поиска незаражённых файлов хватило и скрипта:
def opened(path):
files = os.listdir(path)
for f in files:
if os.path.isfile(path + f):
yield path + f
for full_path in opened("C:\\some\\path"):
file = open(full_path, "rb")
last_string = ""
for line in file:
last_string = line
file.close()
if (last_string[len(last_string) -4:len(last_string)]) != (1, 0, 0, 0):
print(full_path)Таким образом получилось найти файлы принадлежащие к первому типу. Второй подразумевает долгую мануальщину, но найденного уже было достаточно. Всё бы хорошо, но необходимо знать абсолютно точную структуру и (разумеется) вышел такой случай, что пришлось работать с часто меняющейся таблицей. Никто и не помнил, то ли тип поля менялся, то ли добавлялся новый столбец.
Дебри сити к сожалению не смогли помочь с таким случаем, поэтому и пишется данная статья.
Ближе к делу
Есть структура таблицы 3-х месячной давности не совпадающая с текущей (возможно по одному полю, а возможное и более). Структура таблицы:
CREATE TABLE `table_1` (
`id` INT (11),
`date` DATETIME ,
`description` TEXT ,
`id_point` INT (11),
`id_user` INT (11),
`date_start` DATETIME ,
`date_finish` DATETIME ,
`photo` INT (1),
`id_client` INT (11),
`status` INT (1),
`lead__time` TIME ,
`sendstatus` TINYINT (4)
); при этом, нужно извлечь:
id_pointINT (11);id_userINT (11);date_startDATETIME ;date_finishDATETIME .
Для восстановления используется побайтовый анализ .ibd файла, с последующим переводом их в более читаемый вид. Так как для поиска требуемого, нам достаточно проанализировать такие типы данных как int и datatime, в статье будут описаны только они, но иногда будут ссылаться и на другие типы данных, что может помочь в иных подобных происшествиях.
Проблема 1: в полях с типами DATETIME и TEXT имелись NULL значение, и в файле они просто пропускаются, из-за этого, определить структуру для восстановления в моём случае не удалось. В новых столбцах значение по умолчанию было null, а часть транзакций могли быть потерянны из-за настройки innodb_flush_log_at_trx_commit = 0, поэтому для определения структуры пришлось бы потратить дополнительное время.
Проблема 2: следует учесть, что строки удалённые через DELETE, все ровно будут находиться в ibd файле, но при ALTER TABLE их структура обновляться не будет. В итоге, структура данных может варьироваться от начала файла, к его концу. Если вы часто используете OPTIMIZE TABLE, то с подобной проблемой вряд ли столкнетесь.
Обратите внимание, версия СУБД влияет на способ хранения данных, и данный пример может не сработать для других мажорных версий. В моём случае использовалась windows версия mariadb 10.1.24. Также, хоть и в mariadb вы работаете с InnoDB таблицами, но по факту они являются XtraDB, что исключает применяемость метода с InnoDB mysql.
Анализ файла
В python, тип данных bytes() отображает данные в юникоде вместо обычного набора чисел. Хоть рассматривать файл можно и в таком виде, но для удобства можно перевести байты в числовой вид переведя массив байт в обычный массив (list(example_byte_array)). В любом случае, для анализа пригодятся оба способа.
Просмотрев несколько ibd файлов, можно встретить следующие:
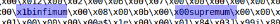
При чём, если делить файл по этим ключевым словам, получатся преимущественно ровные блоки данных. Будем использовать infimum как делитель.
table = table.split("infimum".encode())Интересное наблюдение, для таблиц с небольшим количеством данных, между infimum и supremum есть указатель на количество строк в блоке.
 — тестовая таблица с 1-ой строкой
— тестовая таблица с 1-ой строкой
 — тестовая таблица с 2-мя строками
— тестовая таблица с 2-мя строками
Массив строк table[0] можно пропустить. Просмотрев его, мне так и не удалось обнаружить сырые данные таблиц. Скорей всего, данный блок служит для хранения индексов и ключей.
Начиная с table[1] и переведя её в числовой массив, уже можно заметить некоторые закономерности, а именно:

Это int значения хранимые в строке. Первый байт указывает является ли число положительным, или отрицательным. В моём случае, всё числа положительные. Из остальных 3-х байт, можно определить число используя следующую функцию. Скрипт:
def find_int(val: str): # example '128, 1, 2, 3'
val = [int(v) for v in val.split(", ")]
result_int = val[1]*256**2 + val[2]*256*1 + val[3]
return result_intНапример, 128, 0, 0, 1 = 1, или 128, 0, 75, 108 = 19308.
В таблице имелся первичный ключ с автоинкрементом, и здесь его также можно обнаружить

Сопоставив данные из тестовых таблиц, было выявлено, что объект DATETIME состоит из 5 байт начинался с 153 (скорей всего указывает на годовые промежутки). Так как диапазон DATTIME равен '1000-01-01' to '9999-12-31', думаю число байт может разниться, но в моём случае, данные подпадают в промежуток от 2016 по 2019 года, поэтому будем считать, что 5 байт достаточно.
Для определения времени без секунд, были написанные следующие функции. Скрипт:
day_ = lambda x: x % 64 // 2 # {x,x,X,x,x }
def hour_(x1, x2): # {x,x,X1,X2,x}
if x1 % 2 == 0:
return x2 // 16
elif x1 % 2 == 1:
return x2 // 16 + 16
else:
raise ValueError
min_ = lambda x1, x2: (x1 % 16) * 4 + (x2 // 64) # {x,x,x,X1,X2}Для года и месяца не удалось написать здраво-работающую функцию, по-этому пришлось харкодить. Скрипт:
ym_list = {'2016, 1': '153, 152, 64', '2016, 2': '153, 152, 128',
'2016, 3': '153, 152, 192', '2016, 4': '153, 153, 0',
'2016, 5': '153, 153, 64', '2016, 6': '153, 153, 128',
'2016, 7': '153, 153, 192', '2016, 8': '153, 154, 0',
'2016, 9': '153, 154, 64', '2016, 10': '153, 154, 128',
'2016, 11': '153, 154, 192', '2016, 12': '153, 155, 0',
'2017, 1': '153, 155, 128', '2017, 2': '153, 155, 192',
'2017, 3': '153, 156, 0', '2017, 4': '153, 156, 64',
'2017, 5': '153, 156, 128', '2017, 6': '153, 156, 192',
'2017, 7': '153, 157, 0', '2017, 8': '153, 157, 64',
'2017, 9': '153, 157, 128', '2017, 10': '153, 157, 192',
'2017, 11': '153, 158, 0', '2017, 12': '153, 158, 64',
'2018, 1': '153, 158, 192', '2018, 2': '153, 159, 0',
'2018, 3': '153, 159, 64', '2018, 4': '153, 159, 128',
'2018, 5': '153, 159, 192', '2018, 6': '153, 160, 0',
'2018, 7': '153, 160, 64', '2018, 8': '153, 160, 128',
'2018, 9': '153, 160, 192', '2018, 10': '153, 161, 0',
'2018, 11': '153, 161, 64', '2018, 12': '153, 161, 128',
'2019, 1': '153, 162, 0', '2019, 2': '153, 162, 64',
'2019, 3': '153, 162, 128', '2019, 4': '153, 162, 192',
'2019, 5': '153, 163, 0', '2019, 6': '153, 163, 64',
'2019, 7': '153, 163, 128', '2019, 8': '153, 163, 192',
'2019, 9': '153, 164, 0', '2019, 10': '153, 164, 64',
'2019, 11': '153, 164, 128', '2019, 12': '153, 164, 192',
'2020, 1': '153, 165, 64', '2020, 2': '153, 165, 128',
'2020, 3': '153, 165, 192','2020, 4': '153, 166, 0',
'2020, 5': '153, 166, 64', '2020, 6': '153, 1, 128',
'2020, 7': '153, 166, 192', '2020, 8': '153, 167, 0',
'2020, 9': '153, 167, 64','2020, 10': '153, 167, 128',
'2020, 11': '153, 167, 192', '2020, 12': '153, 168, 0'}
def year_month(x1, x2): # {x,X,X,x,x }
for key, value in ym_list.items():
key = [int(k) for k in key.replace("'", "").split(", ")]
value = [int(v) for v in value.split(", ")]
if x1 == value[1] and x2 // 64 == value[2] // 64:
return key
return 0, 0Уверен, если потратить n число времени, то и это недоразумение можно исправить.
Далее, функция возвращающая объект datetime из строки. Скрипт:
def find_data_time(val:str):
val = [int(v) for v in val.split(", ")]
day = day_(val[2])
hour = hour_(val[2], val[3])
minutes = min_(val[3], val[4])
year, month = year_month(val[1], val[2])
return datetime(year, month, day, hour, minutes)Удалось обнаружить часто повторяющиеся значения из int, int, datetime, datetime 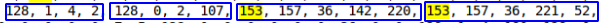 , похоже это то что нужно. Причём, такая последовательность дважды за строку не повторяется.
, похоже это то что нужно. Причём, такая последовательность дважды за строку не повторяется.
Используя регулярное выражение, находим необходимые данные:
fined = re.findall(r'128, \d*, \d*, \d*, 128, \d*, \d*, \d*, 153, 1[6,5,4,3]\d, \d*, \d*, \d*, 153, 1[6,5,4,3]\d, \d*, \d*, \d*', int_array)Обратите внимание, что при поиске по данному выражению, не удастся определить NULL значения в требуемых полях, но в моём случае это не критично. После в цикле перебираем найденное. Скрипт:
result = []
for val in fined:
pre_result = []
bd_int = re.findall(r"128, \d*, \d*, \d*", val)
bd_date= re.findall(r"(153, 1[6,5,4,3]\d, \d*, \d*, \d*)", val)
for it in bd_int:
pre_result.append(find_int(bd_int[it]))
for bd in bd_date:
pre_result.append(find_data_time(bd))
result.append(pre_result)Собственно всё, данные из массива result, это и есть необходимые нам данные. ###PS.###
Я понимаю что такой способ подойдёт далеко не всем, но основная цель статьи скорей натолкнуть на действие, чем решить все ваши проблемы. Думаю наиболее правильное решение было бы начать изучать исходный код самой mariadb, но в связи с ограниченным временем, текущий способ показался наиболее быстрый.
В некоторых случаях, проанализировав файл, вы сможете определить примерную структуру и восстановить одним из стандартных способов из ссылок выше. Это будет гораздо правильней и вызовет меньше проблем.
Shished
Надо было делать бекапы.
Tzimie
Как всегда, героизм как следствие раздолбайства до этого
lubezniy
Надо было. Но мне в одном случае после аварийного развёртывания проблемной таблицы из бэкапа четырёхдневной давности с актуальной структурой пришлось ещё восстанавливать кучу данных за 4 дня, благо это можно было теоретически сделать путём анализа содержимого других таблиц, в результате чего удалось написать и прогнать скрипт.
Saylermb Автор
Луди ведь и делятся на тех, кто ещё не делает бекапы и кто уже делает бекапы)