

В последнее время вышло несколько статей с критикой ImageNet, пожалуй самого известного набора изображений, использующегося для обучения нейронных сетей.
В первой статье Approximating CNNs with bag-of-local features models works surprisingly well on ImageNet авторы берут модель, похожую на bag-of-words, и в качестве "слов" используют фрагменты из изображения. Эти фрагменты могут быть вплоть до 9х9 пикселей. И при этом, на такой модели, где полностью отсутствует какая-либо информация о пространственном расположении этих фрагментов, авторы получают точность от 70 до 86% (для примера, точность обычной ResNet-50 составляет ~93%).
Во второй статье ImageNet-trained CNNs are biased towards texture авторы приходят к выводу, что виной всему сам набор данных ImageNet и то, как изображения воспринимают люди и нейронные сети, и предлагают использовать новый датасет – Stylized-ImageNet.
Более подробно о том, что на картинках видят люди, а что нейронные сети
ImageNet
Набор данных ImageNet начал создаваться в 2006 году усилиями профессора Fei-Fei Li и продолжает развиваться по сей день. На данный момент в нём содержится около 14 миллионов изображений, принадлежащих более 20 тысячам разных категорий.
С 2010 года подмножество этого набора данных, известное как ImageNet 1K с ~1 миллионом изображений и тысячей классов используется в соревновании ILSVRC (ImageNet Large Scale Visual Recognition Challenge). На этом соревновании в 2012 году "выстрелила" AlexNet, сверточная нейронная сеть, которая достигла top-1 точности в 60% и top-5 в 80%.
Именно на этом подмножестве датасета люди из академической среды меряются своими SOTA, когда предлагают новые архитектуры сетей.
Немного о процессе обучения на этом наборе данных. Речь пойдёт про протокол обучения на ImageNet именно в академической среде. То есть когда нам показывают в статье результаты какого-нибудь SE блока, ResNeXt или DenseNet сети, то процесс выглядит примерно так: сеть обучается в течении 90 эпох, скорость обучения снижается на 30 и 60 эпохе, каждый раз в 10 раз, в качестве оптимизатора выбирается обычный SGD с небольшим weight-decay, из аугментаций используется только RandomCrop и HorizontalFlip, картинка обычно ресайзится до 224х224 пикселей.
Вот пример скрипта из pytorch для обучения на ImageNet.
BagNet
Вернёмся к упомянутым ранее статьям. В первой из них авторы хотели получить модель, которую было бы легче интерпретировать чем обычные глубокие сети. Вдохновившись идеей bag-of-feature моделей, они создают свое семейство моделей – BagNets. Используя в качестве основы обычную ResNet-50 сеть.
Заменяя в ResNet-50 некоторые свертки 3х3 на 1х1, они добиваются того, что receptive field нейронов на последнем сверточном слое значительно уменьшается, вплоть до 9х9 пикселей. Тем самым они ограничивают информацию, доступную одному отдельному нейрону, до очень маленького фрагмента всего изображения – патча в несколько пикселей. Надо заметить, что для нетронутой ResNet-50 размер receptive field составляет более 400 пикселей что полностью покрывает картинку, которая обычно ресайзится до 224х224 пикселей.
Этот патч – это самый максимальный фрагмент изображения, из которого модель могла бы извлечь пространственные данные. В конце модели все данные просто суммировались и модель никаким образом не могла знать где каждый патч находится по отношению к другим патчам.
Всего проверялось три варианта сетей с receptive field 9x9, 17х17 и 33х33. И, несмотря на полное отсутсвие пространственной информации, такие модели смогли достичь неплохой точности в классификации на ImageNet. Top-5 accuracy для патчей 9х9 составила 70%, для 17х17 – 80%, для 33х33 – 86%. Для сравнения, у ResNet-50 top-5 accuracy составляет приблизительно 93%.

Структура модели показана на рисунке выше. Каждый патч из qxqx3 пикселей, вырезанный из изображения, превращается сетью в вектор длиной 2048. Далее этот вектор подаётся на вход линейного классификатора, который выдаёт scores для каждого из 1000 классов. Собрав scores каждого патча в 2d массив можно получить heatmap для каждого класса и каждого пикселя исходного изображения. Финальный scores для изображения получался путем суммирования heatmap каждого класса.
Примеры heatmaps для некоторых классов:

Как видно, самый большой вклад в пользу того или иного класса вносят патчи, расположенные по краям объектов. Патчи с фона практически игнорируются. Пока всё идет нормально.
Посмотрим на наиболее информативные патчи:

Для примера авторы взяли четыре класса. Для каждого из них выбрали по 2х7 наиболее значимых патчей (то есть патчей, где score данного класса был наивысшим). Верхний ряд из 7 патчей взят из изображений только соответствующего класса, нижний – из всей выборки изображений.
Что на этих картинках можно увидеть примечательного. Например, для класса tench (линь, рыба) характерным признаком являются пальцы. Да, обыкновенные человеческие пальцы на зеленом фоне. А все потому, что почти на всех изображениях с этим классом присутствует рыбак, который, собственно, данную рыбу и держит в руках, хвастаясь трофеем.

Для портативных компьютеров характерным признаком являются клавиши с буквами. Клавиши печатной машинки тоже засчитываются в этот класс.
Для книжной обложки характерным признаком являются буквы на цветном фоне. Пусть это даже будет надпись на футболке или на пакете.
Казалось бы, данная проблема не должна нас беспокоить. Так как она присуща только узкому классу сетей с очень ограниченным receptive field. Но далее авторы посчитали корреляцию между logits (выходами сети перед финальным softmax), присваиваемыми каждому классу BagNet с разными receptive field, и logits из VGG-16, которая имеет достаточно большой receptive field. И нашли её довольно высокой.

Авторы задались вопросом, не содержит ли BagNet каких-либо намёков на то, как другие сети принимают решения.
Для одного из тестов они использовали такую технику как Image Scrambling. Которая состояла в том, чтобы с помощью генератора текстур на основе gram матриц, составить такую картинку, где сохранены текстуры, но отсутствует пространственная информация.

VGG-16, обученная на обычных полноценных картинках, справилась с такими scrambled картинками довольно неплохо. Её top-5 accuracy упала с 90% до 80%. То есть, даже сети, обладающие довольно большими receptive field, всё равно предпочли запомнить текстуры и проигнорировать пространственную информацию. Поэтому их accuracy и не упала сильно на scrambled images.
Авторы провели ещё ряд экспериментов, где сравнивали какие части из изображений являются наиболее значимыми для BagNet и остальных сетей (VGG-16, ResNet-50, ResNet-152 и DenseNet-169). Всё намекало на то, что остальные сети так же как и BagNet при принятии решений опираются на небольшие фрагменты изображений и допускают примерно одинаковые ошибки. Особенно это было заметно для не очень глубоких сетей типа VGG.
Эта склонность сетей принимать решения на основе текстур, в отличии от нас — людей, предпочитающих форму (см. рисунок ниже), подтолкнула авторов второй статьи на создание нового набора данных на основе ImageNet.
Stylized ImageNet
Первым делом авторы статьи с помощью style transfer создали набор изображений, где форма (пространственные данные) и текстуры на одном изображении противоречили друг другу. И сравнили результаты людей и глубоких свёрточных сетей разных архитектур на синтезированном наборе данных из 16 классов.

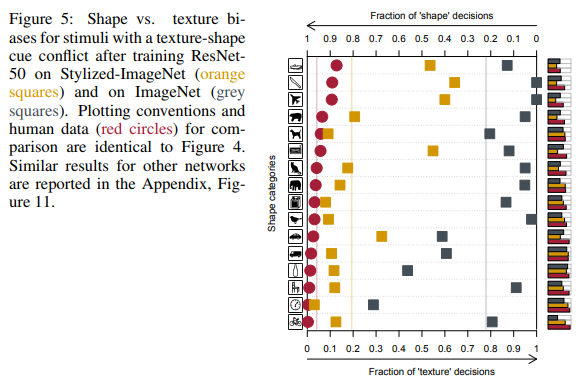
На крайнем справа рисунке люди видят кота, сети – слона.

Сравнение результатов людей и нейронных сетей.
Как видно, люди при отнесении объекта к тому или иному классу опирались на форму объектов, нейронные сети — на текстуры. На рисунке выше люди видели кота, сети — слона.
Да, тут можно придраться к тому, что сети тоже в чём-то правы и это, например, мог бы быть слон, сфотографированный с близкого расстояния, с татуировкой любимого котика. Но то, что сети при принятии решений ведут себя не так как люди, авторы посчитали проблемой и занялись поиском путей её решения.
Как было уже сказано выше, опираясь только на текстуры, сеть способна достичь неплохого результата в 86% top-5 accuracy. И речь идёт не о нескольких классах, где текстуры помогают правильно классифицировать изображения, а о большинстве классов.
Проблема именно в самом ImageNet, так как дальше будет показано, что сеть, способна выучить форму, но не делает этого, так как для получения хороших результатов на этом наборе данных достаточно и текстур, а нейроны, отвечающие за текстуры, находятся на неглубоких слоях, обучить которые гораздо легче.
Используя на этот раз несколько отличный механизм AdaIN fast style transfer авторы создали новый набор данных – Stylized ImageNet. Форма объектов бралась из ImageNet, а набор текстур из вот этого соревнования на Kaggle. Скрипт для генерации доступен по ссылке.

Далее для краткости ImageNet будем обозначать как IN, Stylized ImageNet как SIN.
Авторы взяли ResNet-50 и три BagNet с разными receptive field и обучили по отдельной модели для каждого из набора данных.
И вот что у них получилось:
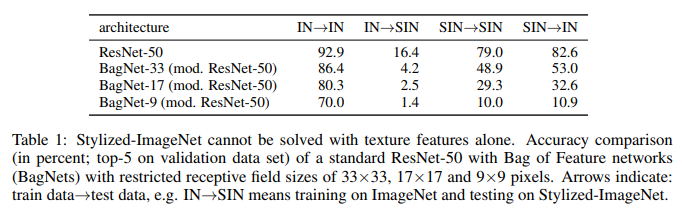
Что мы здесь видим. ResNet-50, натренированная на IN, полностью недееспособна на SIN. Что отчасти подтверждает то, что при тренировке на IN сеть оверфитится на текстуры и игнорирует форму объектов. В то же время ResNet-50 обученная на SIN прекрасно справляется и с SIN и с IN. То есть, если её лишить простого пути, сеть идет по трудному – учит форму объектов.
BagNet наконец-то начала вести себя ожидаемо, особенно на патчах малого размера, так как ей не за что зацепиться – текстурная информация попросту отсутствует в SIN.
На тех шестнадцати классах, что упоминались ранее, ResNet-50, обученная на SIN стала давать ответы больше похожие на те, что дают люди:
Кроме простого обучения ResNet-50 на SIN, авторы попробовали обучать сеть на смешанном наборе из SIN и IN, включая fine-tuning отдельно на чистом IN.

Как можно видеть, при использовании SIN+IN для обучения, результаты улучшились не только на основной задаче – классификации изображений на ImageNet, но и на задаче детектирования объектов на наборе данных PASCAL VOC 2007.
Кроме этого, сети, обученные на SIN стали более устойчивы к различному шуму в данных.
Заключение
Даже сейчас, в 2019 году, после семи лет прошедших с успеха AlexNet, когда нейронные сети широко используются в компьютерном зрении, когда ImageNet 1K де-факто стал стандартом для оценки работы моделей в академической среде, не совсем ясен механизм, как нейронные сети принимают решения. И как на это влияют наборы данных, на которых эти сети обучались.
Авторы первой статьи попытались пролить свет на то, как такие решения принимаются в сетях с архитектурой на основе bag-of-features с ограниченным receptive field, более простой для интерпретации. И, сравнив ответы BagNet и привычных глубоких нейронных сетей, пришли к выводу что процессы принятия решений в них довольно схожи.
Авторы второй статьи сравнили то, как картинки, на которых форма и текстуры противоречат друг другу, воспринимают люди и нейронные сети. И предложили для уменьшения различия в восприятии использовать новый набор данных – Stylized ImageNet. Получив в качестве бонуса прирост в точности классификации на ImageNet и детекции на сторонних наборах данных.
Основной вывод можно сделать такой: сети, обучающиеся на картинках, имея возможность запоминать более высокоуровневые пространственные свойства объектов, предпочитают более лёгкий путь для достижения цели – оверфитнуться на текстуры. Если набор данных, на котором они тренируются, позволяет это.
Кроме академичеcкого интереса проблема оверфиттинга на текстуры имеет значение и для всех нас, кто использует предобученные модели для transfer learning в своих задачах.
Важное для нас следствие из всего этого – не стоит доверять общедоступным предобученным на ImageNet весам моделей, так как для большинства из них использовались довольно простые аугментации, которые никак не способствуют избавлению от оверфиттинга. И лучше, при наличии возможностей, иметь в заначке модели, обученные с более серьёзными аугментациями или же на связке Stylized ImageNet + ImageNet. Чтобы всегда была возможность сравнить, какая из них лучше подходит для нашей текущей задачи.
Комментарии (57)

RGrimov Автор
29.05.2019 15:47Само по себе это и не хорошо и не плохо. Тут главное не делать вольных допущений о том, что сеть выучила. Основной посыл статей: сети могут принимать решения вовсе и не так, как мы от них ожидаем, руководствуясь нашим common sense.

promsoft
29.05.2019 16:59Почему сети, не оверфитнутые на текстуры, будут лучше для трансферлёрнинга? Часто предобученные сети используют для трансферлёрнинга на доменах, очень далеких Imagenet (например, конкурс про протеины). Как тут помешает оверфитнутость на текстуры и неспособность понять форму кошек и слонов?
RGrimov Автор
29.05.2019 17:17+1Зависит от задачи. Если картинки далеки от картинок с котиками, то да, сеть оверфитнутая на текстуры, может лучше справиться с ними, особенно, если не важна пространственная информация. И даже заметить то, что ускользает от нашего взгляда.
Но вот если у нас что-то близкое к натуральным картинкам и, допустим, мы заморозили все веса и обучаем только финальные слои — то в этом случае мы никак не сможем добиться от сети, чтобы она выучивала форму объектов.
Поэтому, собственно, лучше и иметь предобученные на Stylized ImageNet сети, чтобы всегда можно было сравнить.
RGrimov Автор
29.05.2019 17:21+1P.S. Грубо говоря, если нам надо классифицировать двухголовых котят и обычных (извиняюсь за всю криповость) и у нас есть предобученная сеть, то сеть, оверфитнутая на текстуры, не справится так хорошо, как сеть умеющая выделять признаки более высого уровня.
Но это всё imho, на практике ещё не проверял.
slonopotamus
29.05.2019 21:16-1https://upload.wikimedia.org/wikipedia/ru/5/57/CatDog.GIF
Интересно, что это с т.з. нейросети, классифицирующей двухголовых котят ;)

Akon32
30.05.2019 11:20Нет никакой "точки зрения", есть обучающая выборка, по которой определяются весовые коэффициенты, которые затем много раз перемножаются с пикселами картинки и много раз суммируются, затем определяется наибольшее среди результатов число, и на выход подается метка, соответствующая этому числу. Сеть выдаст те результаты из обучающей выборки, на которые наиболее похожа входная картинка.
Hardcoin
29.05.2019 18:16+1Интуитивно потому, что оверфиттинг на внешнее — это плохо. Люди тысячелетия учатся обращать внимание на форму и содержание, а не только на цвет.
Математического доказательства, что это важно, не существует, но делать сети по принципу работы людей — это неплохой путь.
Те же самые свертки были подсказаны зрительной корой.
dimonoid
30.05.2019 10:21Зато люди всегда пытаются уклониться например от большого летящего пакета сзади при взгляде периферическим зрением, тк это может быть автомобиль, велосипед либо ещё что то быстрое и опасное. В некоторых случаях в первую очередь лучше даже смотреть на скорость а не на текстуру или форму.

lostmsu
29.05.2019 18:26+1По-моему результаты багнета неинтересные. Во-первых, 14% ошибки аж в 2 раза больше 7% (что авторы яростно пытались скрыть везде упоминая accuracy). Во-вторых, они не пробовали удалить текстуру и тренировать без неё. Может получили бы те же 86% или даже выше. В классификации точность двух классификаторов не является суммой их точностей!
RGrimov Автор
29.05.2019 19:33Во второй статье авторы тренировали BagNet на датасете без текстур — точность BagNet сильно просела. Вверху таблица есть.
lostmsu
29.05.2019 19:59То есть 86%->80% — это «сильно просела», а 93%->86% — нет?
По-моему, эта цифра только подтверждает сказанное.RGrimov Автор
29.05.2019 20:04+2Может вы не там смотрите. Для BagNet с разными receptive fields:
33px: top-5 accuracy просела с 86.4% до 53.0%
17px: 80.3 -> 32.0
9px: 70.0 -> 10.9
habrastorage.org/webt/rm/bm/k7/rmbmk7uvvm9gigwy5xkh6fvfghm.pnglostmsu
30.05.2019 01:09Это доказывает только что возможности BagNet ограничены в сравнении с CNN, т.к. он умеет пользоваться только данными текстуры.
Но тогда о чём статья? О том, что можно сделать худшую по характеристикам сеть, которая не может работать с формой, потому что в ней нет stacked convolutions?RGrimov Автор
30.05.2019 01:40И такая ограниченная сеть по прежнему будет способна получить на ImageNet результат сопоставимый с полноценной CNN. Проблема не в сетях, а в ImageNet — он слишком простой для решения. Собственно об этом статья.
lostmsu
30.05.2019 02:50В 2 раза больше ошибка — это не сопоставимый результат. См. выше.
RGrimov Автор
30.05.2019 13:41Сопоставимый/несопоставимый — тут точного критерия нет. Разброс ошибки между разными архитектурами CNN больше, чем между BagNet-33 и ResNet-50. У AlexNet ошибка 19% была, у, GoogLeNet — 13%, а у SENet — 5%.
Я под сопоставимостью имел ввиду то, что сеть успешно распознала не 20% примеров, не 40%, а 86% — что лет пять назад считалось успехом и для CNN. Учитывая что в BagNet уменьшено количество параметров и сильно ограничен receptive field.
Hardcoin
30.05.2019 12:58Нет, статья не об этом. Статья о том, что классическая ResNet обучается на текстуры (а не на форму).
Во-первых, это утверждение не было очевидно.
Во-вторых, они его качественно подтвердили.
В-третьих, они проверили хороший способ аугментации и улучшили результаты для ResNet.
BagNet в данном случае нужна только для того, что бы подтвердить это утверждение (используется как лемма в доказательстве).
lostmsu
30.05.2019 19:34Это утверждение всё ещё ложно. Она обучается и на текстуры, и на форму.
Разумеется они никак его не подтвердили, т.к. точность упала.
Аугментация даже у них даёт крайне маленький прирост в доли процента. Не сравнивается даже с нашумевшим mixup'ом. Плюс надо следить за методологией, а то может весь прирост объясняется большим числом изображений в SIN+IN dataset'е (т.е. если они не компенсировали увеличение размера датасета соответствующим понижением числа эпох тренировки).Hardcoin
30.05.2019 22:09Разумеется они никак его не подтвердили, т.к. точность упала.
Они подтвердили это не повышением точности, а понижением при перекрёстном тестировании. Посмотрите Table 1. Генерализация полной сети, обученной на SIM очень не плоха. 82%. При этом в обратную сторону всего 16%. Почему?
Они объясняют это тем, что в случае SIM сеть обучается на форму. В датасете IN форма тоже есть, потому результат неплохой. А вот при обучении на IN сеть на форму НЕ обучается, поэтому в обратную сторону результат такой плохой.
Если вы не согласны с этим объяснением (даже после прочтения оригинала), то дайте свое. Если оно лучше, с удовольствием соглашусь с ним.
lostmsu
30.05.2019 22:26Генерализация полной сети, обученной на SIM очень не плоха. 82%. При этом в обратную сторону всего 16%. Почему?
Потому что SIN был специально построен, чтобы поломать самую весомую характеристику оригинального датасета.
А вот при обучении на IN сеть на форму НЕ обучается, поэтому в обратную сторону результат такой плохой.
Ничего подобного, она обучается на форму, но см. выше.
Вот если бы они оставили форму, а текстуру заменили нейтральным значением, и сеть всё равно не смогла бы классифицировать, можно было бы прийти к вашему выводу. Но они текстуры заменили на что-то совсем не нейтральное.Hardcoin
30.05.2019 22:36самую весомую характеристику оригинального датасета.
Какую? И почему без неё точность 79%? Она точно самая весомая?
Ничего подобного, она обучается на форму, но см. выше.
Увидел ваше, где вы пишете это же утверждение, но тоже никак его не подтверждаете. Почему вы считаете, что resnet обучается на форму?
можно было бы прийти к вашему выводу
Вот они к этому выводу и пришли. Текстуру они заменили на что-то, что не говорит ничего о классе изображения. Вы бы хотели заменить её на что-то серое + контуры? Если попробуете, будет интересно.
lostmsu
31.05.2019 06:40Какую? И почему без неё точность 79%? Она точно самая весомая?
Ответ на этот вопрос содержится в моём сообщении верхнего уровня.
Увидел ваше, где вы пишете это же утверждение, но тоже никак его не подтверждаете. Почему вы считаете, что resnet обучается на форму?
Если бы она не обучалась на форму, то даже в отсутствии активно мешающей классификации текстуры она не смогла бы выдать 10% accuracy на этом наборе данных.
Вот они к этому выводу и пришли. Текстуру они заменили на что-то, что не говорит ничего о классе изображения.
Она может не говорить вам, но в рамках оригинального датасета полученные изображения просто кричат о классе «painting».
Вы бы хотели заменить её на что-то серое + контуры? Если попробуете, будет интересно.
Не, я чисто покритиковать в Интернете.Hardcoin
31.05.2019 10:22Ответ на этот вопрос содержится в моём сообщении верхнего уровня.
В верхнем сообщении речь про текстуры. Вы считаете текстуры самой весомой характеристикой оригинального датасета?
Если бы она не обучалась на форму
Это попытка докопаться лингвистически. Мол, пусть на 10%, но хоть немного формы resnet из датасета получает. Не надо так.
В рамках нашего разговора "не обучается на форму" и "обучается на форму незначительно" — одно и то же. Но вот вам переформулированный тезис.
Статья о том, что классическая ResNet обучается преимущественно на текстуры (а форму учитывает намного меньше).
lostmsu
31.05.2019 21:48+1В верхнем сообщении речь про текстуры. Вы считаете текстуры самой весомой характеристикой оригинального датасета?
Никакой разницы что я считаю весомой характеристикой.
Это попытка докопаться лингвистически. Мол, пусть на 10%, но хоть немного формы resnet из датасета получает. Не надо так.
Я специально выделил важную часть абзаца, а вы её пропустили. Сколько информации сеть получает из формы датасета нельзя судить по их эксперименту.
Статья о том, что классическая ResNet обучается преимущественно на текстуры
Этот вывод нельзя сделать из данной работы по причинам, которые я описал выше.
(а форму учитывает намного меньше)
Этот вывод ещё можно допустить, в плане, что если представить сеть как (TextureClassifier(img) * A + ShapeClassifier(img) * B) / (A + B), то из работы следует A > B.Hardcoin
31.05.2019 22:04Никакой разницы что я считаю весомой характеристикой.
Это важно для понимания ваших тезисов парой комментариев выше. Если эти ваши тезисы не важны, тогда согласен. То, что вы имеете ввиду под "самой весомой характеристикой" неважно.
Этот вывод нельзя сделать из данной работы по причинам, которые я описал выше.
Выше, это где про "весомую характеристику", которая оказалась неважна?
Извините, но связность ваших рассуждений недостаточна, что б разговор продолжал быть интересным. Слишком много ссылок на то, что "описано выше", а при попытке уточнить, что же вы имеете ввиду, опять ссылка на описание выше.
Этот вывод ещё можно допустить, в плане, что если представить сеть как (TextureClassifier(img) A + ShapeClassifier(img) B) / (A + B), то из работы следует A > B.
Благодарю и на этом.
lostmsu
31.05.2019 23:48Это важно для понимания ваших тезисов парой комментариев выше. Если эти ваши тезисы не важны, тогда согласен. То, что вы имеете ввиду под «самой весомой характеристикой» неважно.
Весомую с точки зрения тренированного ImageNet.
Выше, это где про «весомую характеристику», которая оказалась неважна?
Выше — это где я заметил, что замена текстур действует против классификатора.
Извините, но связность ваших рассуждений недостаточна, что б разговор продолжал быть интересным. Слишком много ссылок на то, что «описано выше», а при попытке уточнить, что же вы имеете ввиду, опять ссылка на описание выше.
Я не виноват, что вы задаёте вопросы или делаете утверждения, на которые я уже отвечал раньше.Благодарю и на этом.
Ну вы-то хоть поняли, что если в формулу (TextureClassifier(img)*A + ShapeClassifier(img)*B)/(A+B) где A >> B подставить картинки, на которых TextureClassifier заведомо выдаёт чушь, то результат TC*A+SC*B = 16% не означает, что SC = 16% или даже вообще что SC < 80%, например?Hardcoin
01.06.2019 00:12Я не виноват
А при чем тут вина? Либо вы хотите что-то рассказать, либо не хотите. Если хотите, то ваш прямой интерес поменьше запутывать обсуждение перекрестными ссылками, не так ли?
то результат TC*A+SC*B = 16% не означает, что SC = 16% или даже вообще что SC < 80%, например?
SC может быть любым, тут важно, что В маленькое. Учтите, что В не задано изначально, это тоже результат обучения сети. То есть при стандартной ResNet, с обычными картинками обучение приводит к тому, что влияние форм маленькое.
Однако SC в данном случае — это не какой-то классификатор внутри сети, который мы потом умножаем на коэффициент, а просто абстракция, которую вы ввели для иллюстрации идеи. Нет оснований считать, что внутри сети на самом деле есть участок с высоким уровнем распознавания форм.

buriy
01.06.2019 21:04>TC*A+SC*B = 16% не означает, что SC = 16%
Нужно провести простой эксперимент: научить на IN (взять обученную сетку), а потом немного дообучить на SIN, чтобы B успел измениться относительно А, а вот TC и SC не сильно поменялись. Вот тогда будет какая-то оценка точности, получше, чем диапазон 16%..80%
Vasyutka
29.05.2019 19:22+2Да просто в архитектуре сверточных сетей уже заложено игнорирование пространственный архитектуры за счет max-pooling слоев. А там где не заложено, естественным образом получается во время оптимизации (большая часть сверточных ядер становятся согласованными фильтрами для низкочастотных фич, т.е. информация о позиции теряется). Здесь можно немного отыграться в архитектурах, где нет max-pooling-а, действительно за счет трансфер-ленинга, например. Для нас же, когда мы изображения воспринимаем, совершенно нормально отделять пространственную (и 2D и 3D) конфигурацию от текстуры, потому так и удивляемся провалам сверточных сетей. Это не означает, что нельзя придумать решение этой проблемы. Можно. К тому же там еще и совершенно нелепая история с тем, что классифицировать изображение — это вообще не та задача, что решается при восприятии изображения. Так что совершенно нормально, что сначала исследователи загнали себя в оверфит на текстуры, сейчас рефлексируют в статьях подобной приведенной, следующий этап будет переоценки критерия что же мы хотим. Например, неплохо хотеть: интерпретируемости, узнавание аномальных ситуаций, различная трактовка, возможности аналогий/абстракций. Тогда и новое поколение решений подтянется ИМХО. Да и уже много исследований в ту сторону

iroln
29.05.2019 20:12+1Сразу вспоминается диван леопардовой расцветки. :)
Интересные результаты. Радует, что на эту проблему стали обращать внимание, сначла капсульные сети, теперь вот это. А всё потому, что, грубо говоря, все production-ready архитектуры вообще не умеют в форму объектов. Человек чаще всего безошибочно и мгновенно распознает подавляющее большинство объектов, потому что знает, что это за объект, а не просто какое-то "серо-бурое образование в крапинку с контрастными границами", он знает, что это известный объект реального мира и зачем он нужен. И этот объект может обладать именно такой формой (или набором форм). Игнорирование формы — это большой изъян современных архитектур, который рано или поздно придётся исправлять. И вот почему-то мне кажется, что просто созданием синтетических абстракционистских датасетов тут не победить.
В этом плане было бы интересно совместить современные глубокие нейросети и статистический анализ и моделирование формы. Возможно, это могло бы дать лучшие результаты и новый толчок в этой области.
RGrimov Автор
29.05.2019 20:19«серо-бурое образование в крапинку с контрастными границами» — вот вы только что описали одну из недавних задач :-) — классификацию H&E stained гистологических снимков. На текущий момент нейронные сети неплохо справляются с такими задачами, наверное, потому так и популярны. А так да, в академической среде идёт вялотекущий поиск решения приблизить сети к человеческому зрению, и это радует.
goodok
29.05.2019 22:55Да, диван тоже вспомнился. Согласен, датасет и аугментация (таже стилизация) лишь смягчают проблему игнорирования формы… и вращения. И Хинтон мотивируя работу над архитектурой капсульных сетей пытается моделировать композицию объектов («рот», «глаз», «нос») — их относительного расположения и ориентации — в нечто целое («лицо») и это целое в свою очередь может быть частью чего-то другого.

{kind=link}

napa3um
29.05.2019 23:09Кажется, дальнейшим развитием понимания и формализации методов распознавания изображений будут нейросетки, выдающие не «это кот», а «это кот, а не слон» («это кот на заданном параметризуемом уровне онтологии распознаваемых образов»). Путь к strong AI «снизу».
tretyakovpe
30.05.2019 08:20Обезьяны, не умеющие выделить на фоне ландшафта хищника — сдохли.
Поэтому мы предпочитаем форму текстуре.
vesper-bot
30.05.2019 10:05Верхний ряд из 7 патчей взят из изображений только соответствующего класса, нижний – из всей выборки изображений.
Нижний ряд взят из остальных изображений, а не всех вообще, т.е. это куски, отзывающиеся на заданный класс, но всё изображение относится к другому классу.
dimonoid
30.05.2019 10:31Так почему нейросети не тренируют на картах нормалей различных размеров? Сразу и форму и текстуру будут распознавать. У человека ведь 2 глаза. Я думаю можно скармливать сразу много каналов в каждой картинке, а не только 3 цвета.

oracle_and_delphi
30.05.2019 10:46Видео нужно нейросетям скармливать, а не плоский набор пикселей.
AC130
30.05.2019 10:56Вот кстати да. Для того, чтобы имело смысл сравнение возможностей НС с возможностями человека надо НС подавать на вход как минимум два потока изображений, снятых с разных позиций камеры, и в каждом потоке каждое изображение снято слегка сдвинутой камерой. Люди настолько привыкли к тому, что им показывает мозг, что забыли как глаза видят.
Akon32
30.05.2019 11:33Почему не тренируют?) У меня в одной сильно специфической задаче входные данные в виде карты глубин давали лучшие результаты, чем вход rgb.
А ещё есть масса вариантов наподобие "первым шагом делать 3D реконструкцию по стереоснимкам, а затем распознавать трёхмерные образы", или, скажем, обучать на снимках в ИК-диапазоне, на дополненной реальности и т.д. Пред- и пост-обработка данных может быть любой.
svp777
30.05.2019 13:35Вот на эту же тему есть очень сильное ощущение, что детекторы возраста человека по фоточке лица очень сильно переобучены на текстуру кожи. Соответственно получается, что зимой, когда кожа суше, чем летом, возраст человека оценивается старше, чем возраст летом. Было бы неплохо уметь выключать и включать зависимость возраста от гладкости кожи лица.
goodok
А может и не так уж и плохо, на текстуры реагировать? Лучше ошибиться и в панике отскочить от предмета, текстура которого напоминает слона (бенгальского тигра), чем переваривать внутренними слоями нейронной сети форму. :-)
Hardcoin
Если вы делаете что-то с интеллектом кузнечика, то да. Если задача приблизиться к интеллекту человека (пусть и на ограниченном классе задач), то учитывать форму необходимо.
goodok
Задача — решить задачу :-), можно даже хуже человека, зато дешевле и быстрей.
Я был бы рад что-то сделать даже с интеллектом кошки, которые, уверен способны различать формы и имеют в голове модель мира и объектов его населяющих пусть и не такую совершенную как у большинства людей. Роботы и дроны с интеллектуальными возможностями кошачих уже зрелищно решат большой спектр задач.
Кстати, свёрточные слои были вдохновлены экспериментами на мозгах как раз кошек. Может у них ещё что есть подсмотреть? Например, может не случайно правое полушарие обрабатывает детали образа, а левое полушарие отвечает за абстракции. Просто разговоры о том, чтобы сделать «интеллект как у людей» с середины прошлого века ещё шли и иногда заводили не совсем туда (экспертные системы, тот ещё механистический машинный перевод и тп.) излишне зацикливаясь на человеке. А «кошачий» deep learning «взлетел».
Arqwer
За всех говорить не надо, у разных людей разные задачи. У меня — понять как сделать общий искусственный интеллект.
roryorangepants
Тогда вам не в современный deep learning (а возможно даже не в machine learning вообще).
Arqwer
Я лучше знаю, куда мне :)
Безусловно, современных ML и DL недостаточно, но возможности DL быстро расширяются. Например, ещё пару лет назад, синтез программ относился к конференциям по языкам программирования, а теперь всё больше переходит в NeurIPS. RL тоже развивается неожиданно хорошо. В целом, у меня нет оснований полагать, что DL не пригодится. Даже скорее наоборот, похоже, что DL в некоторой видоизменённой форме будет существенной частью AGI. И что ещё важно, чем больше всего можно скинуть на плечи DL, тем проще и гибче получится архитектура.
goodok
И в мыслях не было. Но, кстати, надеюсь помог Вам уточнить и условия Вашей задачи. Мне кажется это понимание будет смутным, если полагать, что распознование формы это прерогативатолько человека. А то получится как раньше «Сейчас мы сделаем общий ИИ, для этого надо чтобы он смог приблизился к человеку в игре в шахматы… ой, в игру Го… ой, решал задачу машинного перевода… ой, распознавал кошек и собак… ой, различал форму».
Nehc
Вы… НЕ совсем правы. Хотя я понимаю о чем вы.
Решить задачу — значит находить закономерности, так? Т.е. создать некую предсказательную модель, которая «работает». Однако в статье речь идет как раз о том, что не смотря на то, что модель работает, она работает на определенной все-таки выборке (считающейся релевантной), и вот возникли сомнения, что она работает «правильно». И определенные эксперименты (с котом и пальцами) показали некоторые «особенности», которые не позволяют сказать, что сеть работает «правильно».
Это как с решением задач школьниками — иногда так получается, что неправильным способом можно получить правильный ответ. И нужно понять ход мысли, что бы вскрыть ошибку. Хотя можно было бы подойти формально — решил правильно? Молодец — пять. За это часто ругают испытания в виде тестов.
Так вот эта самая «баг нет» — это как бы способ посмотреть процесс решения, дабы понять ход мысли. И он показал, что сеть «ленится» и склонна выделять простейшие признаки для решения задачи не углубляясь слишком сильно! И по мне это шикарный результат! Мне кажется
нашинастоящий нейронные сети часто именно так и работают! У человека все несколько сложнее…Akon32
Если нужно учитывать форму, то надо строить сеть соответствующим образом и обучать её на специальном наборе данных, в котором большое значение имеет форма. Судя по данным из статьи, исходные нейросети обучены наилучшим образом распознавать примеры, на которых они обучались (совершенно неудивительно). Если они распознают текстуры, а не форму — это всего лишь значит, что для распознавания на обучающей выборке текстуры имеют большее значение, чем форма, и что той архитектуры нейросети достаточно для хорошего распознавания на обучающей выборке.
Вообще заголовки вида "Нейронные сети не умеют ..." истинны только при указании конкретной архитектуры сети и конкретной обучающей выборки. Наверняка можно предложить другую архитектуру сети, которая не делает конкретных глупых ошибок. Или даже переобучить существующую архитектуру на более актуальной в данном случае выборке.
Приблизиться в выполнении каких задач? Если каких-то конкретных задач — достаточно таких несложных и специализированных вещей, как упомянутые в статье архитектуры НС. Если "всех" задач, то с нейросетевым подходом как минимум нужна соответствующая обучающая выборка. И плюс какие-то ещё неизвестные алгоритмы для сильного ИИ.
Hardcoin
Это всего лишь значит, что разработчики архитектуры не знали, каким образом нейросеть распознает примеры (и это на самом деле так).
Другую архитектуру (или другую аугментацию изображений) можно предложить теперь, когда ответ есть. Вы же не считаете, что ответ был очевиден до этой работы?
Потенциально в любых, конечно.
napa3um
«Это всего лишь значит, что разработчики архитектуры не знали, каким образом нейросеть распознает примеры (и это на самом деле так).» — похоже не на разработку архитектуры, а на гадание на ромашке «распознает / не распознает». Кто-то проектирует нейросети, а кто-то проектирует сборник рецептов и шаманских книг по их приготовлению неразумными крестьянами.
Akon32
Думаю, здесь будет более точной формулировка из статьи "не совсем ясен механизм, как нейронные сети принимают решения", чем "не знали". Частичное понимание было и есть.
Предпосылки к этому ответу были. Например, были работы, в которых менялись несколько пикселей, чтобы "обмануть" НС. Уже тогда было ясно, что глубокие свёрточные сети могут ошибаться в некоторых случаях, что могут терять (а могут и не терять) пространственную информацию, что для "типичных" архитектур 4 собачьих глаза и 3 собачьих ноги в сумме могут дать собаку. Здесь же более чётко показано, что на "стандартных" датасетах пространственная информация скорей теряется, предпочтение отдаётся текстурам.
Nehc
Авторы обращают внимание, что возможно выборка все-таки не так хороша, как ранее считалось… Особенно мне понравилось про пальцы и рыбу. ;)
algotrader2013
Надо от задач идти. В большинстве актуальных задач реагировать (только) на текстуры не просто плохо, а очень плохо. Кому нужен автопилот, который примет человека в нестандартной одежде за мусор, а рекламу на корме автобуса за перебегающего дорогу кота? Или face recognition, который не узнает лицо своего хозяина после драки?) Или еще пример, уверен, что очень хорошо детектить автомобиль по фрагменту номерного знака. Но что делать с автомобилем, который едет без номера, или с номером другой страны, где другой формат?