
Многие из вас читали предыдущую статью про то, как неправильная визуализация для объяснения работы JOIN-ов в некоторых случаях может запутать. Круги Венна не могут полноценно проиллюстрировать некоторые моменты, например, если значения в таблице повторяются.
При подготовке к записи шестого выпуска подкаста "Цинковый прод" (где мы договорились обсудить статью) кажется удалось нащупать один интересный вариант визуализации. Кроме того, в комментариях к изначальной статье тоже предлагали похожий вариант.
Все желающие приглашаются под кат
Итак, визуализация. Как мы выяснили в комментах к предыдущей статье, join — это скорее декартово произведение, чем пересечение. Если посмотреть, как иллюстрируют декартово произведение, то можно заметить, что зачастую это прямоугольная таблица, где по одной оси идет первое отношение, а по другой — второе. Таким образом элементы таблицы будут представлять собой все комбинации всего.
Сложно абстрактно это нарисовать, поэтому придется на примере.
Допустим, у нас есть две таблицы. В одной из них
id
--
1
1
6
5В другой:
id
--
1
1
2
3
5Сразу disclaimer: я назвал поле словом "id" просто для краткости. Многие в прошлой статье возмущались, как это так — id повторяются, безобразие. Не стоит сильно переживать, ну
представьте, например, что это таблица с ежедневной статистикой, где для каждого дня и каждого юзера есть данные по посещению какого-нибудь сайта. В общем, не суть.
Итак, мы хотим узнать, что же получится при различных джойнах таблиц. Начнем с CROSS JOIN:
CROSS JOIN
SELECT t1.id, t2.id
FROM t1
CROSS JOIN t2CROSS JOIN — это все все возможные комбинации, которые можно получить из двух таблиц.
Визуализировать это можно так: по оси x — одна таблица, по оси y — другая, все клеточки внутри (выделены оранжевым) — это результат
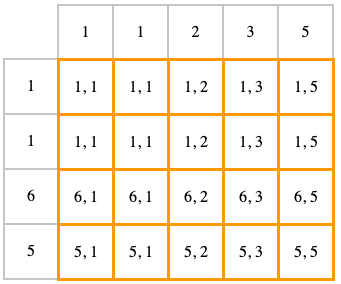
INNER JOIN
INNER JOIN (или просто JOIN) — это тот же самый CROSS JOIN, у которого оставлены только те элементы, которые удовлетворяют условию, записанному в конструкции "ON". Обратите внимание на ситуацию, когда записи дублируются — результатов с единичками будет четыре штуки.
SELECT t1.id, t2.id
FROM t1
INNER JOIN t2
ON t1.id = t2.id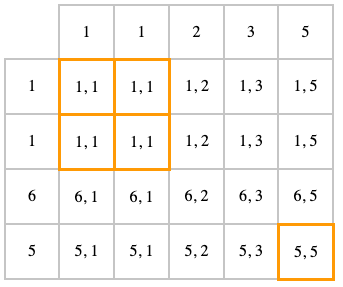
LEFT JOIN
LEFT OUTER JOIN (или просто LEFT JOIN) — это тоже самое, что и INNER JOIN, но дополнительно мы добавляем null для строк из первой таблицы, для которой ничего не нашлось во второй
SELECT t1.id, t2.id
FROM t1
LEFT JOIN t2
ON t1.id = t2.id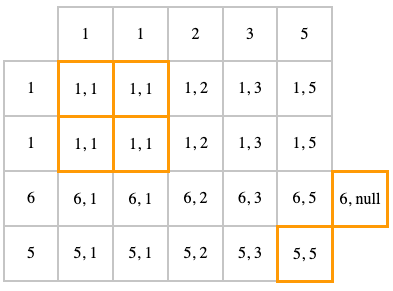
RIGHT JOIN
RIGHT OUTER JOIN ( или RIGHT JOIN) — это тоже самое, что и LEFT JOIN, только наоборот. Т.е. это INNER JOIN + null для строк из второй таблицы, для которой ничего не нашлось в первой
SELECT t1.id, t2.id
FROM t1
RIGHT JOIN t2
ON t1.id = t2.id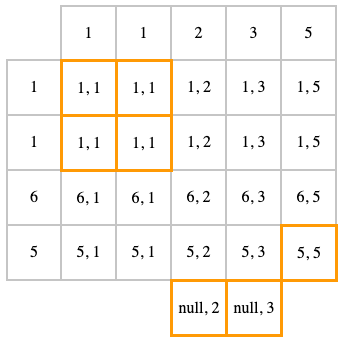
> Поиграть с запросами можно здесь
Выводы
Вроде бы получилась простая визуализация. Хотя в ней есть ограничения: здесь показан случай, когда в ON записано равенство, а не что-то хитрое (любое булево выражение). Кроме того не рассмотрен случай, когда среди значений таблицы есть null. Т.е. это всё равно некоторое упрощение, но вроде бы получилось лучше и точнее, чем круги Венна.
Подписывайтесь на наш подкаст "Цинковый прод", там мы обсуждаем базы данных, разработку софта и прочие интересные штуки.
Комментарии (28)

SlavniyTeo
06.06.2019 13:52Отличная визуализация. Если в клетках пересечения, не удовлетворяющих условию (которые Вы не раскрашиваете), не писать чисел, восприниматься будет еще лучше.
Кажется мне, проблема веб-разработчиков, отвечающих на вопросы по SQL скорее в том, что у людей нет интуитивного понимания концепций SQL. Мы просто не встречаем их в быту. И без опыта близкого общения с базой, многие вещи принимаются интуитивно на основе похоже звучащих (выглядящих) бытовых концептов, и соответственно, не правильно. Плюс туториалы и объяснения «на пальцах».
В целом, про что ни спроси в плане SQL и реляционных баз, чаще всего в ответ получишь логично звучащее, но неверное мнение. И не было бы в этом ничего странного (технология старая и довольно сложная), если бы язык запросов не назывался Simple Query Language.
Боюсь, что в предыдущей статье мой комментарий потеряется, поэтому пишу здесь.
zetroot
06.06.2019 14:01+1Вроде же sql — structured query language, язык структурированных запросов.
SlavniyTeo
07.06.2019 10:23Большое спасибо за ответ. Это отличный пример интуитивного, логичного, но неверного понимания SQL.

Googolplex
08.06.2019 03:37Мне кажется, что zetroot имел в виду, что аббревиатура SQL расшифровывается как Structured Query Language, а не как Simple Query Language. Что есть абсолютная правда, см. например https://en.wikipedia.org/wiki/SQL

Ak-47
06.06.2019 14:03-2Зачем изобретать колесо, с точки зрения, ученика — диаграммы Венна — ясны и понятны, кому это не нужно — останутся с приблизительным пониманием, кто решит углубить свои знания со всем разберется… Не надо изобретать то, что изобретать не надо.

Sergery8205
06.06.2019 14:29+1Да вы просто гений. Спасибо большое — очень помог такой способ визуализации. Добавил в закладки, плюсануть не могу — карма низкая :)

varanio Автор
06.06.2019 15:51«Гений» — это уж слишком, но если кто плюсанет статью, будет и правда здорово
mayorovp
06.06.2019 16:51+1Визуализацию нужно повернуть на 45 градусов, и поменять в ней таблицы местами.
Вроде бы получилась простая визуализация. Хотя в ней есть ограничения: здесь показан случай, когда в ON записано равенство, а не что-то хитрое (любое булево выражение).
Отличие "любого булева выражения" от равенства — лишь в том, что "любые булевы выражения" чаще дают дублирующиеся строки. Но поскольку вы специально подобрали совпадающие идентификаторы — никакого отличия в визуализации не будет.

BorLaze
06.06.2019 16:57-1ИМХО — нет никакой трагедии в том, чтобы использовать диаграммы Венна. С одним условием — уточнять, что они применимы только для ключей (точнее, для unique полей). В случае же дубликатов схема другая. Да и все.
Диаграммы просты и понятны, а JOIN, ИМХО, в 99% случаев идет по ключу. Не знаю, как у других, а у меня лично за 20 лет программирования ни разу не возникла необходимость использовать какие-то другие поля.
Это, примерно, как с математикой — в школе нас несколько лет учат, что квадратный корень из отрицательного числа взять нельзя, а в институте внезапно появляется мнимая единица.apapacy
06.06.2019 18:57Диаграммы Венна тут вторичны. Первичен вопрос о том есть ли пересечение и что именно пересекается в случае JOIN (если JOIN понимать буквально как JOIN то есть соединение а не как фильтр по всему чему угодно).
zetroot
06.06.2019 19:20Кстати, а как же FULL OUTER JOIN? Ну так, чисто для полноты картины.
apapacy
06.06.2019 20:16Извините что я отправляю в Вики, но там все случаи описаны en.wikipedia.org/wiki/Relational_algebra Просто прежде чем дойти до формального определения FULL OUTER JOIN нужна вся предыстория. В случае с простым JOIN все более интуитивно понятно (если повторюсь под JOIN понимать только JOIN)
Mikluho
07.06.2019 09:19Вот запоминают джуны всякие картинки, а суть всё равно утекает. Далее канонического описания уйти не могут.
Самый банальный вопрос, на котором многие тупят на собеседовании — что будет, если среди значений попадётся null?
И хорошо, если сумеет вспомнить, что по стандарту null не равен ничему. Но сумеет ли домыслить результат?
Часто может для left join получить вот такую табличку:
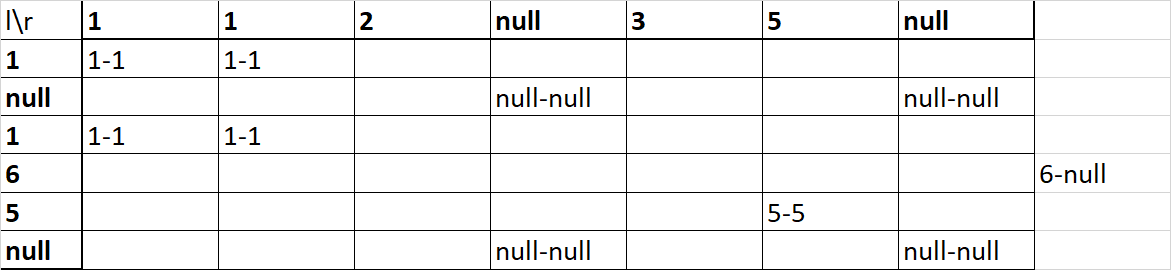
А должен был бы получить:
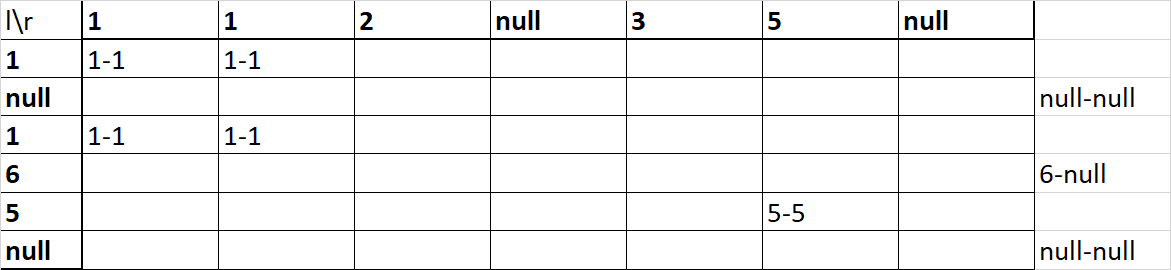
И даже если нарисует, поймёт ли, почему так? Что там ещё сокрыто под этими null-ми?
Куда нагляднее, если добавить ещё один столбец с данными и посмотреть на результат (кстати, многие осилив пример из статьи, сливаются на таком простом усложнении):
CREATE TABLE t1 (id int, v varchar(1)); CREATE TABLE t2 (id int, v varchar(1)); INSERT INTO t1 values (1, 'a'), (null, 'b'), (1, 'c'), (6, 'd'), (5, 'e'), (null, 'f'); INSERT INTO t2 VALUES (1, 'a'), (1, 'b'), (2, 'c'), (null, 'd'), (3, 'e'), (5, 'f'), (null, 'g'); SELECT t1.id, t2.id FROM t1 LEFT JOIN t2 ON t1.id = t2.id; SELECT t1.v, t2.v FROM t1 LEFT JOIN t2 ON t1.id = t2.id;
Первый select вернёт данные для второй картинки:

А что вернёт второй select?

Что в виде наглядной таблички выглядит так:


folal
07.06.2019 09:37-1Вот простенькая визуализация по сабжу — две частично пересекающиеся таблицы и full join, inner join, left join, левое исключение:










demche
07.06.2019 18:27-1join — это скорее декартово произведение, чем пересечение.
Не просто «скорее»: соединение как раз и определяется как декартово произведение, к которому применена выборка по указанному условию соединения. В SQL это легко увидеть, например:
SELECT t1.id, t2.id FROM t1 INNER JOIN t2 ON t1.id = t2.id
эквивалентно декартовому произведению с условием:
SELECT t1.id, t2.id FROM t1, t2 WHERE t1.id = t2.id
или используем альтернативный синтаксис с CROSS JOIN:
SELECT t1.id, t2.id FROM t1 CROSS JOIN t2 WHERE t1.id = t2.id
apapacy
Вроде бы в предыдущей статье в комментариях разобрались, что диаграммы Венна все ясно и доступно иллюстрируют. Только показывают они не пересечение или объединение строк таблиц, а пересечение или объединение ключей. Я на всякий случаю дублирую этим комментарием эту мысль.
varanio Автор
Я не понимаю, зачем при объяснении джойнов завязываться на какие-то там ключи.
apapacy
В подавляющем большинстве случаев JOIN связывают отношения по первичным и внешним ключам. Хотя технически можно связывать по произвольному выражению. И по скорости тоже — были бы индексы. Поэтому я склоняюсь к тому чтобы в JOIN-ах использовать только первичные и внешние ключи а в условиях WHERE — условия фильтрации. Вот почему для объяснения джойнов завязываться на первичные и внешние ключи не только обсуждаемо но и необходимо.
Hardcoin
Предлагаете изменить стандарт или просто не учить людей стандарту, что бы они на сложных вещах ошибались? Если стандарту всё же учить, диаграммы Венна не подходят.
Как диаграммы Венна покажут пересечение ключей при расчёте накопительного итога?
apapacy
В чем я предлагаю нарушить стандарт? Это все в рамках стандарта. В стандарте в качестве условий WHERE и JOIN выступает одна и та же спецификация *search condition* что фактически означает что можно задавать условия соединения двух таблиц в WHERE а условия фильтрации в JOIN. Но почему бы не сделать семантическое разделение и в условии JOIN задавать условия соединения таблиц а в условиях WHERE — условия фильтрации полученных соединений.
Что касается накопительный итог — не совсем понимаю что имеется в виду. Если можно поясните пожалуйста на примере?
eefadeev
Это, например, когда у вас
apapacy
В этом выражении (в общем случае) нет ни первичных ни внешних ключей. Следовательно не будет и их объединений и пересечений. И я бы записал этот факт в равнозначном выражении FROM A, B WHERE B.date <= A.date
Мне кажется что сразу становится понятным что берется просто декартово произведение таблиц и фильтруется по значению.
Случай с JOIN конечно не покроет того случая когда нужно взять левый или проавый JOIN: FROM A LEFT JOIN B ON B.date <= A.date Но это уже как бы гангстерский метод получения итогов. Я скорее применил что-то вроде этого запроса
SELECT ID, (SELECT SUM(amount) FROM B WHERE B.date <= A.date) as total_amouint FROM A
eefadeev
В таких случаях, обычно, не фильтруется, а агрегируется (например считается тот самый «нарастающий итог»).
И да, автор статьи немного смешал понятия (то есть статья, в большей степени, академическая, чем промышленная). Обычно в качественно спроектированных БД, которые эксплуатируются в реальной жизни соединения (JOIN) происходят по ключам (первичные-внешние), в ключах не бывает NULL'ов и так далее. Но так бывает не всегда. О чём, собственно, и статья.
Hardcoin
Вы не предлагаете его нарушить, вы видимо предлагаете его поменять.
Про накопительный итог вам ниже рассказали. Каким образом диаграммы Венна покажут пересечение ключей при расчёте накопительного итога?
Нельзя. LEFT JOIN не взаимозаменяем с WHERE, если есть null.
apapacy
Да по этому итогу я кстати и ответил.