
Эффективное и надежное управление кластерами в любом масштабе с Tupperware

Сегодня на конференции Systems @Scale мы представили Tupperware — нашу систему управления кластерами, которая оркестрирует контейнеры на миллионах серверов, где работают почти все наши сервисы. Впервые мы развернули Tupperware в 2011 г., и с тех пор наша инфраструктура разрослась с 1 датацентра до целых 15 геораспределенных датацентров. Все это время Tupperware не стоял на месте и развивался вместе с нами. Мы расскажем, в каких ситуациях Tupperware обеспечивает первоклассное управление кластерами, включая удобную поддержку stateful-сервисов, единую панель управления для всех датацентров и возможность распределять мощности между сервисами в реальном времени. А еще мы поделимся уроками, которые усвоили по мере развития нашей инфраструктуры.
Tupperware выполняет разные задачи. Разработчики приложений с его помощью поставляют приложения и управляют ими. Он упаковывает код и зависимости приложения в образ и поставляет его на серверы в виде контейнеров. Контейнеры обеспечивают изоляцию между приложениями на одном сервере, чтобы разработчики занимались логикой приложения и не думали о том, как найти серверы или контролировать обновления. А еще Tupperware отслеживает работоспособность сервера, и если находит сбой, переносит контейнеры с проблемного сервера.
Инженеры по планированию мощностей с помощью Tupperware распределяют серверные мощности по командам в соответствии с бюджетом и ограничениями. А еще они используют его, чтобы повысить эффективность использования серверов. Операторы датацентров обращаются к Tupperware, чтобы правильно распределить контейнеры по датацентрам и останавливать или перемещать контейнеры на время техобслуживания. Благодаря этому обслуживание серверов, сети и оборудования требует минимального участия человека.
Архитектура Tupperware
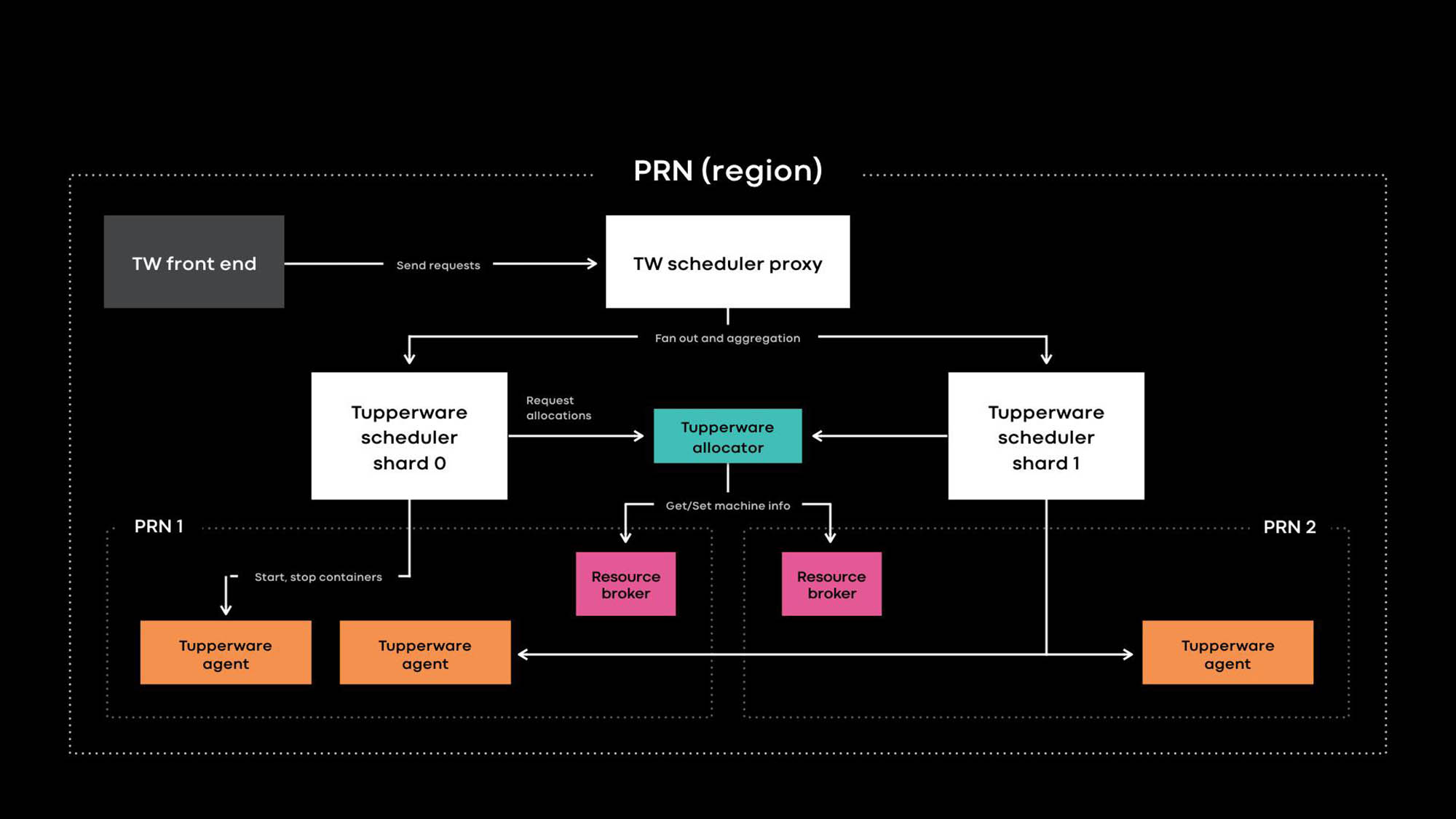
Архитектура Tupperware PRN — это один из регионов наших датацентров. Регион состоит из нескольких зданий датацентров (PRN1 и PRN2), расположенных рядом. Мы планируем сделать одну панель управления, которая будет управлять всеми серверами в одном регионе.
Разработчики приложений поставляют сервисы в виде заданий Tupperware. Задание состоит из нескольких контейнеров, и все они обычно выполняют один и тот же код приложения.
Tupperware отвечает за выделение контейнеров и управление их жизненным циклом. Он состоит из нескольких компонентов:
- Фронтенд Tupperware предоставляет API для пользовательского интерфейса, CLI и других инструментов автоматизации, через которые можно взаимодействовать с Tupperware. Они скрывают всю внутреннюю структуру от владельцев заданий Tupperware.
- Планировщик Tupperware — это панель управления, ответственная за управление жизненным циклом контейнера и задания. Он развертывается на региональном и глобальном уровнях, где региональный планировщик управляет серверами в одном регионе, а глобальный планировщик управляет серверами из разных регионов. Планировщик разделен на шарды, и каждый шард управляет набором заданий.
- Прокси планировщика в Tupperware скрывает внутреннее разделение на шарды и предоставляет удобную единую панель управления пользователям Tupperware.
- Распределитель Tupperware назначает контейнеры серверам. Остановкой, запуском, обновлением и отработкой отказа контейнеров занимается планировщик. В настоящее время один распределитель может управлять всем регионом без разделения на шарды. (Обратите внимание на разницу в терминологии. Например, планировщик в Tupperware соответствует панели управления в Kubernetes, а распределитель Tupperware называется в Kubernetes планировщиком.)
- Брокер ресурсов хранит источник истины для сервера и событий обслуживания. Мы запускаем один брокер ресурсов для каждого датацентра, и он хранит все сведения о серверах в этом датацентре. Брокер ресурсов и система управления мощностями, или система выделения ресурсов, динамически решают, какая поставка планировщика каким сервером управляет. Сервис проверки работоспособности мониторит серверы и хранит данные об их работоспособности в брокере ресурсов. Если у сервера проблемы или он нуждается в обслуживании, брокер ресурсов велит распределителю и планировщику остановить контейнеры или перенести их на другие серверы.
- Агент Tupperware — это демон, запущенный на каждом сервере, который занимается подготовкой и удалением контейнеров. Приложения работают внутри контейнера, что дает им больше изоляции и воспроизводимости. На прошлогодней конференции Systems @Scale мы уже описывали, как отдельные контейнеры Tupperware создаются с помощью образов, btrfs, cgroupv2 и systemd.
Отличительные особенности Tupperware
Tupperware во многом похож на другие системы управления кластерами, например Kubernetes и Mesos, но есть и отличия:
- Встроенная поддержка stateful-сервисов.
- Единая панель управления для серверов в разных датацентрах для автоматизации поставки контейнеров исходя из намерения, вывода кластеров из эксплуатации и обслуживания.
- Понятное разделение панели управления для увеличения масштаба.
- Эластичные вычисления позволяют распределять мощности между сервисами в реальном времени.
Мы разработали эти классные функции, чтобы поддерживать разнообразные stateless- и stateful-приложения в огромном глобальном общем парке серверов.
Встроенная поддержка stateful-севисов.
Tupperware управляет множеством критических stateful-сервисов, которые хранят постоянные данные продуктов для Facebook, Instagram, Messenger и WhatsApp. Это могут быть большие хранилища пар «ключ-значение» (например, ZippyDB) и хранилища данных мониторинга (например, ODS Gorilla и Scuba). Поддерживать stateful-сервисы непросто, ведь система должна гарантировать, что поставки контейнеров выдержат крупномасштабные сбои, включая обрыв сети или отключение электричества. И хотя обычные методы, например, распределение контейнеров по доменам сбоя, хорошо подходят для stateless-сервисов, stateful-севисам нужна дополнительная поддержка.
Например, если в результате серверного сбоя одна реплика базы данных станет недоступна, нужно ли разрешить автоматическое обслуживание, которое обновит ядра на 50 серверах из 10-тысячного пула? Зависит от ситуации. Если на одном из этих 50 серверов есть еще одна реплика той же базы данных, лучше подождать и не терять сразу 2 реплики. Чтобы в динамическом режиме принимать решения об обслуживании и работоспособности системы, нужны сведения о внутренней репликации данных и логике размещения каждого stateful-сервиса.
Интерфейс TaskControl позволяет stateful-сервисам влиять на решения, которые отразятся на доступности данных. С помощью этого интерфейса планировщик уведомляет внешние приложения об операциях с контейнером (перезапуск, обновление, миграция, обслуживание). Stateful-сервис реализует контроллер, который сообщает Tupperware, когда можно безопасно выполнить каждую операцию, и эти операции можно менять местами или временно откладывать. В приведенном выше примере контроллер базы данных может велеть Tupperware обновить 49 из 50 серверов, но пока не трогать определенный сервер (X). В итоге, если пройдет срок обновления ядра, а база данных так и не сможет восстановить проблемную реплику, Tupperware все равно обновит сервер X.

Многие stateful-сервисы в Tupperware используют TaskControl не напрямую, а через ShardManager — распространенную платформу создания stateful-сервисов на Facebook. С Tupperware разработчики могут указать свое намерение о том, как именно контейнеры должны распределяться по датацентрам. С ShardManager разработчики указывают свое намерение о том, как шарды данных должны распределяться по контейнерам. ShardManager знает о размещении данных и репликации своих приложений и взаимодействует с Tupperware через интерфейс TaskControl, чтобы планировать операции с контейнерами без прямого участия приложений. Эта интеграция значительно упрощает управление stateful-сервисами, но TaskControl способен на большее. Например, наш обширный веб-уровень является stateless и использует TaskControl для динамической корректировки скорости обновлений в контейнерах. В итоге веб-уровень способен быстро выполнить несколько выпусков ПО в день без ущерба для доступности.
Управление серверами в датацентрах
Когда Tupperware только появился в 2011 году, каждым кластером сервера управлял отдельный планировщик. Тогда кластером Facebook была группа серверных стоек, подключенных к одному сетевому коммутатору, а датацентр вмещал несколько кластеров. Планировщик мог управлять серверами только в одном кластере, то есть задание не могло распространяться на несколько кластеров. Наша инфраструктура росла, мы все чаще списывали кластеры. Раз Tupperware не мог без изменений переносить задание со списываемого кластера на другие кластеры, требовалось много усилий и тщательная координация между разработчиками приложений и операторами датацентра. Этот процесс приводил к напрасной трате ресурсов, когда серверы месяцами простаивали из-за процедуры вывода из эксплуатации.
Мы создали брокер ресурсов, чтобы решить проблему списания кластеров и координировать остальные типы задач по обслуживанию. Брокер ресурсов отслеживает все физические сведения, связанные с сервером, и в динамическом режиме решает, какой планировщик управляет каждым сервером. Динамическая привязка серверов к планировщикам позволяет планировщику управлять серверами в разных датацентрах. Поскольку задание Tupperware больше не ограничено одним кластером, пользователи Tupperware могут указывать, как контейнеры должны распространяться по доменам сбоя. Например, разработчик может объявить свое намерение (допустим: «запусти мое задание на 2 доменах сбоя в регионе PRN»), не указывая конкретные зоны доступности. Tupperware сам найдет подходящие серверы, чтобы воплощать это намерение даже в случае списания кластера или обслуживания.
Масштабирование для поддержки всей глобальной системы
Исторически сложилось, что наша инфраструктура разделена на сотни выделенных пулов серверов для отдельных команд. Из-за фрагментации и отсутствия стандартов у нас были высокие операционные издержки, а простаивающие серверы было сложнее снова использовать. На прошлогодней конференции Systems @Scale мы представили инфраструктуру как услугу (IaaS), которая должна объединить нашу инфраструктуру в большой единый парк серверов. Но у единого парка серверов свои сложности. Он должен отвечать определенным требованиям:
- Масштабируемость. Наша инфраструктура росла по мере добавления датацентров в каждый регион. Серверы стали меньше и энергоэффективнее, поэтому в каждом регионе их разместилось гораздо больше. В результате единственный планировщик на регион не справляется с тем количеством контейнеров, которое можно запустить на сотнях тысячах серверов в каждом регионе.
- Надежность. Даже если масштаб планировщика можно настолько увеличить, из-за большой области действия планировщика риск ошибок будет выше, и целый регион контейнеров может стать неуправляемым.
- Отказоустойчивость. В случае сбоя огромной инфраструктуры (например, из-за обрыва сети или отключения электричества откажут серверы, где запущен планировщик) негативные последствия должны затронуть только часть серверов региона.
- Удобство использования. Может показаться, что надо запускать несколько независимых планировщиков на один регион. Но с точки зрения удобства единая точка входа в общий пул в регионе упрощает управление мощностями и заданиями.
Мы разделили планировщик на шарды, чтобы решать проблемы с поддержкой большого общего пула. Каждый шард планировщика управляет своим набором заданий в регионе, и это позволяет снизить риск, связанный с планировщиком. По мере роста общего пула мы можем добавлять больше шардов планировщика. Для пользователей Tupperware шарды и прокси планировщика выглядят как одна панель управления. Им не приходится работать с кучей шардов, которые оркестрируют задания. Шарды планировщика принципиально отличаются от планировщиков кластеров, которые мы использовали раньше, когда панель управления была разделена без статического разделения общего пула серверов по топологии сети.
Повышение эффективности использования с помощью эластичных вычислений
Чем больше наша инфраструктура, тем важнее эффективно использовать наши серверы, чтобы оптимизировать расходы на инфраструктуру и снизить нагрузку. Повысить эффективность использования серверов можно двумя способами:
- Эластичные вычисления — уменьшать масштаб онлайн-сервисов в спокойные часы и использовать освободившиеся серверы для офлайн-нагрузок, например, для машинного обучения и заданий MapReduce.
- Чрезмерная загрузка — размещать онлайн-сервисы и пакетные рабочие нагрузки на одних серверах, чтобы пакетные нагрузки выполнялись с низким приоритетом.
Узкое место в наших датацентрах — энергопотребление. Поэтому мы предпочитаем небольшие энергоэффективные серверы, которые вместе предоставляют больше вычислительной мощности. К сожалению, на маленьких серверах с маленьким объемом процессорных ресурсов и памяти чрезмерная загрузка менее эффективна. Конечно, мы можем разместить на одном маленьком энергоэффективном сервере несколько контейнеров маленьких сервисов, которые потребляют мало процессорных ресурсов и памяти, но у больших сервисов в такой ситуации будет низкая производительность. Поэтому мы советуем разработчикам наших больших сервисов оптимизировать их, чтобы они использовали серверы целиком.?
В основном, мы повышаем эффективность использования с помощью эластичных вычислений. Интенсивность использования многих наших крупных сервисов, например, ленты новостей, функции сообщений и фронтенд-веб-уровня, зависит от времени суток. Мы намеренно уменьшаем масштаб онлайн-сервисов в спокойные часы и используем освободившиеся серверы для офлайн-нагрузок, например, для машинного обучения и заданий MapReduce.
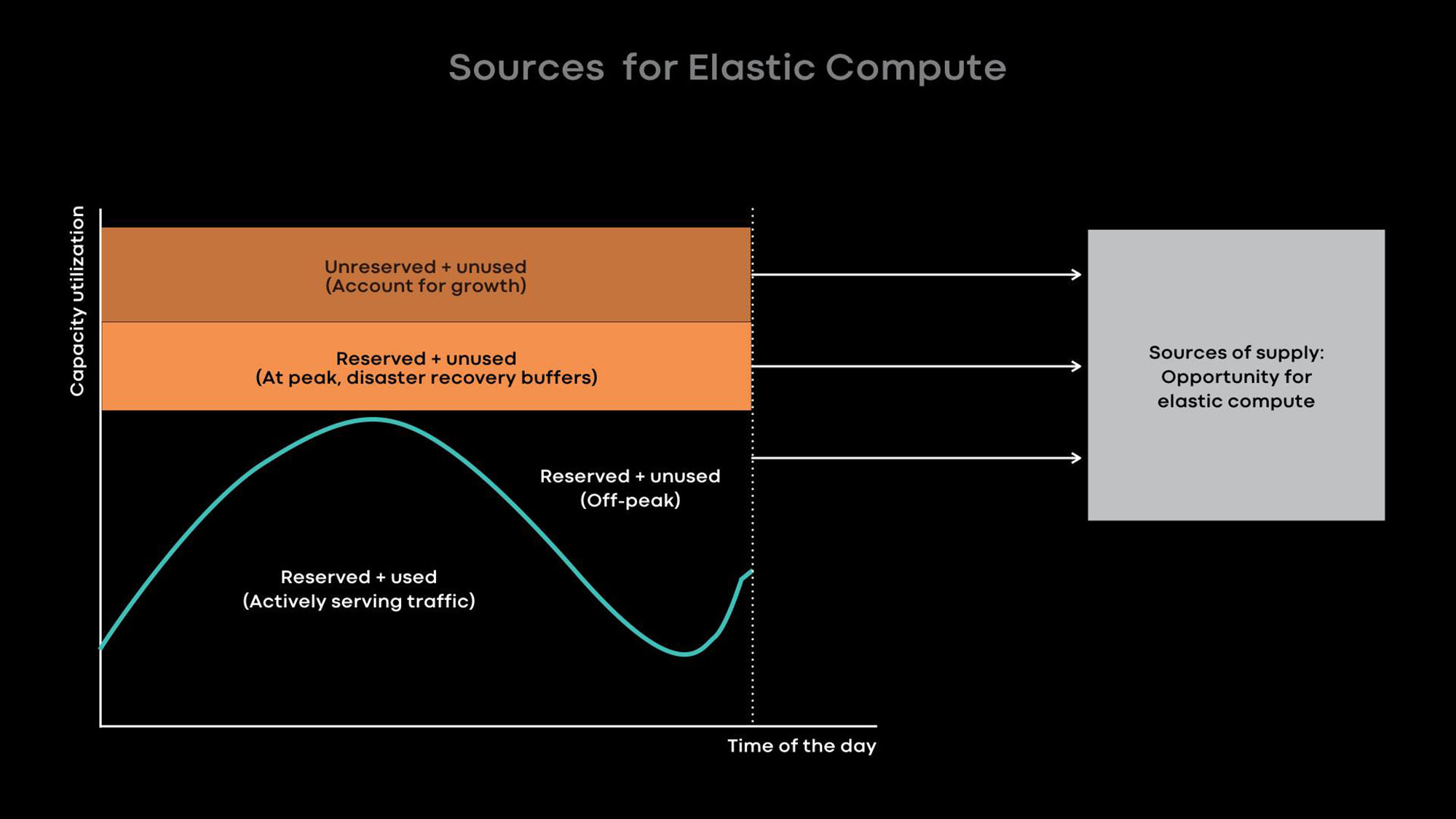
По опыту мы знаем, что лучше всего предоставлять целые серверы в качестве единиц эластичной мощности, потому что большие сервисы — это одновременно главные доноры и главные потребители эластичной мощности, и они оптимизированы для использования целых серверов. Когда сервер освобождается от онлайн-сервиса в спокойные часы, брокер ресурсов отдает сервер во временное пользование планировщику, чтобы он запускал на нем офлайн-нагрузки. Если в онлайн-сервисе возникает пик нагрузки, брокер ресурсов быстро отзывает одолженный сервер и вместе с планировщиком возвращает его онлайн-сервису.
Усвоенные уроки и планы на будущее
В последние 8 лет мы развивали Tupperware, чтобы не отставать от быстрого развития Facebook. Мы рассказываем о том, чему научились, и надеемся, что это поможет другим управлять быстро растущими инфраструктурами:
- Настраивайте гибкую связь между панелью управления и серверами, которыми она управляет. Эта гибкость позволяет панели управления управлять серверами в разных датацентрах, помогает автоматизировать списание и обслуживание кластеров и обеспечивает динамическое распределение мощностей с помощью эластичных вычислений.
- С единой панелью управления в регионе становится удобнее работать с заданиями и проще управлять крупным общим парком серверов. Обратите внимание, что панель управления поддерживает единую точку входа, даже если ее внутренняя структура разделена по соображениям масштаба или отказоустойчивости.
- Используя модель плагина, панель управления может уведомлять внешние приложения о предстоящих операциях с контейнером. Более того, stateful-сервисы могут использовать интерфейс плагина, чтобы настраивать управление контейнером. С помощью такой модели плагина панель управления обеспечивает простоту и при этом эффективно обслуживает множество различных stateful-сервисов.
- Мы считаем, что эластичные вычисления, при которых мы забираем у донорских сервисов целые серверы для пакетных заданий, машинного обучения и других несрочных сервисов, — это оптимальный способ повысить эффективность использования маленьких и энергоэффективных серверов.
Мы еще только приступаем к реализации единого глобального общего парка серверов. Сейчас около 20% наших серверов находятся в общем пуле. Чтобы достичь 100%, нужно решить множество вопросов, включая поддержку общего пула для систем хранения, автоматизирование обслуживания, управление требованиями разных клиентов, повышение эффективности использования серверов и улучшение поддержки рабочих нагрузок машинного обучения. Нам не терпится взяться за решение этих задач и поделиться своими успехами.
Комментарии (7)


cy-ernado
11.06.2019 14:04Вот мне интересно, почему именно "убийца"? Настолько убийственный Tupperware, что без Kubernetes в заголовке на статью не кликают что ли?

m0nstermind
11.06.2019 14:40-1Это перевод статьи с code.fb.com/data-center-engineering/tupperware о чем компания Southbridge скромно умалчивает. Оригинальная статья называется «Efficient, reliable cluster management at scale with Tupperware» — ни слова про убийц.
Но, на что не пойдешь, чтобы твой бложик читали.
Vadem
11.06.2019 19:45Это многое объясняет. А то выглядело так, что это новый продукт, который скоро можно будет использовать вместо кибернейтеса.

gecube
13.06.2019 09:26Абсолютно верно — убийцем он был бы при условии, что его релизнули в паблик. Как я понимаю — нет, его в паблике нет (ну, может какие-то несущественные куски есть), и, нет — FB его релизить не планирует (т.к. это их внутреннее ноу-хау).
Поэтому — больше клибейтных заголовков богу кликбейтных заголовков ))))
Vadem
Open source?