
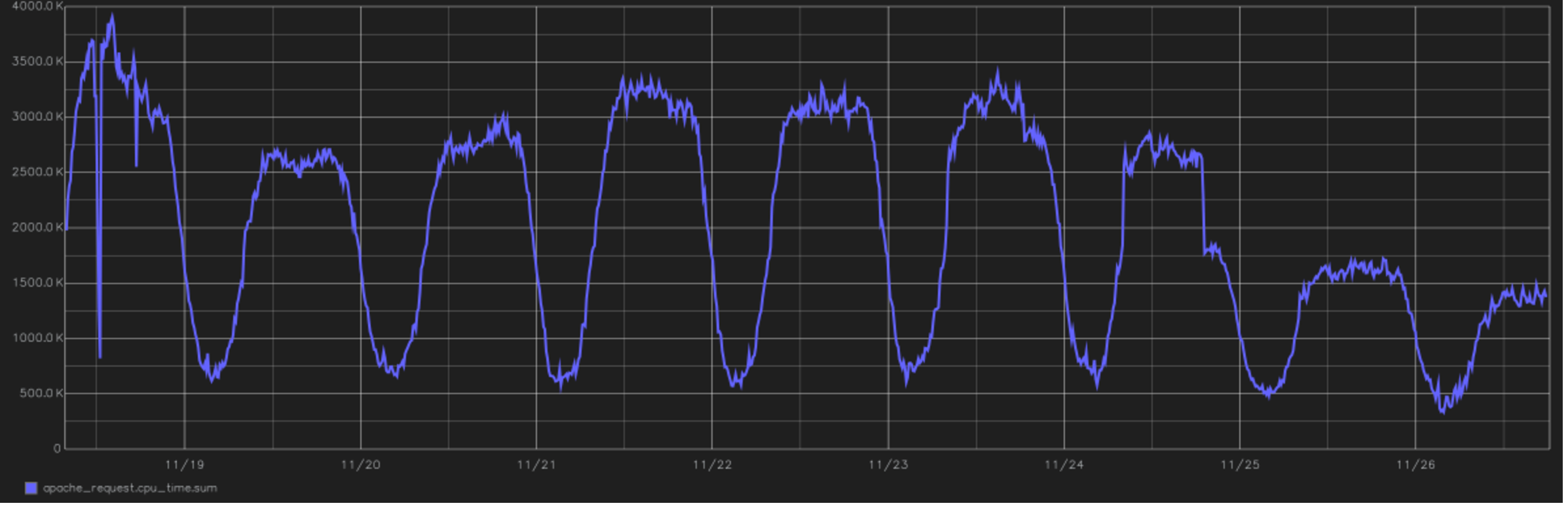
Это одно из самых крутых облегчений проекта. На картинке — график суммарного времени, затрачиваемого CPU на обработку всех пользовательских запросов. В конце видно переход на PHP 7.0. с версии 5.6. Это 2016 год, переключение во второй половине дня с 24 ноября.
Туту.ру с точки зрения вычислений — это в первую очередь возможность купить билет из точки А в точку Б. Для этого мы перемалываем огромное количество расписаний, собираем в кэш ответы множества систем авиакомпаний и периодически делаем невероятно длинные join-запросы к базе данных. В целом мы написаны на PHP и до недавних пор были полностью на нём (если язык правильно готовить, то можно даже строить на нём системы реального времени). С недавнего времени критичные по производительности участки стали рефакториться на Go.
У нас постоянно возникает технический долг. Причём это происходит быстрее, чем нам бы хотелось. Хорошая новость: его не надо закрывать весь. Плохая: по мере роста поддерживаемой функциональности техдолг тоже пропорционально растёт.
Вообще технический долг — это плата за ошибку при принятии решения. Вот ты что-то предсказал не так, как архитектор, то есть совершил ошибку прогнозирования или принимал решение в условиях недостаточной информации. В какой-то момент понимаешь, что надо что-то менять в коде (часто на уровне архитектуры). Дальше можно сразу поменять, а можно подождать. Если подождал — на техдолг набежали проценты. Поэтому хорошая практика — время от времени реструктуризировать его. Ну или признавать себя банкротом и писать весь блок заново.
Как всё начиналось: монолит и общие функции
Проект Туту.ру начинался в 2003 году как обычный веб-сайт Рунета тех времён. То есть это была куча файликов вместо базы данных, PHP-страницы на фронте HTML+JS. Там была пара отличных хаков моего коллеги Юрия, но это лучше он сам когда-нибудь расскажет. Я присоединился к проекту в 2006 году сначала как внешний консультант, который мог помочь как советом, так и кодом, а потом, в 2009-м, перешёл в штат на позицию технического директора. В первую очередь нужно было навести порядок в направлении авиабилетов: это была нагруженная и самая сложная по архитектуре часть.
В 2006 году, напомню, было расписание электричек и была возможность купить билет на поезд. Раздел авиабилетов мы решили делать как отдельный проект, то есть объединялось всё это только на фронте. Все три проекта (расписания электричек, ж/д и авиа) в итоге были написаны по-своему. На тот момент код казался нам нормальным, но несколько недоделанным. Неперфекционистским. Потом он старел, обкладывался костылями и на ж/д-направлении превратился в тыкву к 2010 году.
В ж/д мы техдолг отдать не успели. Рефакторить было нереально: проблемы были в архитектуре. Решили снести и переделать всё заново, но это тоже было сложно на живом проекте. В итоге оставили на фронте только старые URL, а дальше блок за блоком переписывали. В качестве основы взяли подходы, использованные за год до этого при разработке авиационного направления.
Переписывали на PHP. Тогда было понятно, что это не единственный способ, но для нас разумных альтернатив не было. Выбрали его потому, что уже были опыт и наработки, было понятно, что это неплохой язык в руках senior-разработчиков. Из альтернатив были безумно производительные C и C++, но любые пересборки или внедрения изменений на них тогда напоминали кошмар. Ладно, не напоминали. Были кошмаром.
MS и весь .NET с точки зрения высоконагруженного проекта даже не рассматривали. Тогда вариантов, кроме Linux-based, не было вообще. Java — хороший вариант, но она требовательна к ресурсам по памяти, никогда не прощает junior-ошибок и тогда не давала возможности выпускать релизы быстро — ну или мы такой не знали. Python мы и сейчас не рассматриваем как бекэнд, только для задач работы с данными. JS — чисто под фронт. Ruby on Rails-разработчиков тогда (да и сейчас) было не найти. Go не было. Оставался ещё Perl, но эксперты оценили его как неперспективный для веб-разработки, поэтому тоже отказались от него. Остался PHP.
Следующая холиварная история — это PostgreSQL против MySQL. Где-то лучше одно, где-то — другое. В целом тогда хорошей практикой было выбирать то, что получалось лучше, поэтому мы выбрали MySQL и его форки.
Подход разработки был монолитным, тогда других подходов просто не было, но с ортогональной структурой библиотек. Это зачатки современного API-centric-подхода, когда у каждой библиотеки есть фасад наружу, за который можно дёргать прямо внутри кода из других частей проекта. Библиотеки писались «слоями», когда каждый уровень имеет на входе определённый формат и отдаёт дальше в код тоже определённый формат, и между ними крутятся юнит-тесты. То есть что-то вроде test-driven-development, но пикселизированное и страшное.
Всё это размещалось на нескольких серверах, что позволяло масштабироваться под нагрузкой. Но при этом кодовая база разных проектов довольно сильно пересекалась на системном уровне. Это по факту означало, что изменения в проекте ж/д могли затронуть наше же авиа. И затрагивали часто. Например, в ж/д надо было расширить работу с платежами — это доработка общей библиотеки. А авиа работает с ней же, следовательно, нужно совместное тестирование. Зависимости мы экранировали тестами, и это было более-менее нормально. Даже на 2009 год метод был довольно передовым. Но всё равно нагрузка могла с одного ресурса сложить другой. Было и пересечение по базам данных, что приводило к неприятным эффектам в виде тормозов по всему сайту при локальных проблемах в одном продукте. Ж/д убивал авиа несколько раз по диску из-за тяжёлых запросов к базе данных.
Масштабировали мы добавлением инстансов и балансировкой между ними. Монолит как есть.
Эпоха шины
Дальше мы пошли по довольно маргинальному пути. С одной стороны, начали выделять сервисы (сегодня этот подход называется микросервисным, но мы не знали слова «микро»), но для взаимодействия начали использовать шину для передачи данных, а не REST или gRPC, как это делают сейчас. Выбрали AMQP как протокол, а RabbitMQ — как брокер сообщений. К тому времени мы довольно лихо освоили запуск демонов для PHP (да-да, там имеется вполне работающая реализация fork() и всего остального для работы с процессами), поскольку довольно долго в монолите использовали для распараллеливания запросов к системам бронирования такую вещь, как Gearman.
Сделали брокер поверх кролика, и оказалось, что всё это под нагрузкой не особо живёт. Какие-то сетевые потери, ретрансмиты, задержки. Например, кластер из нескольких брокеров «из коробки» ведёт себя несколько иначе, чем заявлено разработчиком (никогда такого не было, и вот опять). В общем, много узнали. Но в итоге получили требуемые для сервисов SLA. Например, самый нагруженный сервис по RPS имеет при 400 rps, 99-й перцентиль round-trip от клиента до клиента включая шину и обработку сервисом порядка 35 ms. Сейчас суммарно на шине мы наблюдаем около 18 krps.
Потом появилось направление автобусов. Его мы сразу писали без монолита на сервисной архитектуре. Поскольку писалось всё с нуля, то получилось очень хорошо, быстро и удобно, хотя и приходилось постоянно дорабатывать инструменты для нового подхода. Да, всё это крутилось на виртуальных машинах, внутри которых демоны на PHP общаются через шину. Демоны запускались внутри Docker-контейнеров, но никаких решений для оркестрации типа Openshift или Kubernetes тогда не было. На 2014-й про это только начинали говорить, однако на прод мы такой подход не рассматривали.
Если сравнить, сколько билетов на автобусы продаётся в сравнении с билетами на самолёт или поезд, то получится капля в море. А в поездах и самолётах переезд на новую архитектуру шёл тяжело, потому что там были работающая функциональность, реальная нагрузка, и всегда выбор встаёт между сделать что-то новое или потратиться на выплату технического долга.
Переезд на сервисы — дело хорошее, но долгое, а с нагрузкой и надёжностью надо разобраться уже сейчас. Поэтому параллельно начали принимать точечные меры по улучшению жизни монолита. Разделили бекэнды на типы продуктов, т. е. стали более гибко управлять роутингом запросов в зависимости от их типа: авиа отдельно от ж/д и т. п. Можно было прогнозировать нагрузку, масштабировать независимо. Когда знали, что в железных дорогах, например, — пик новогодних продаж, то добавляли несколько инстансов виртуальных машин. Он начинался тогда ровно за 45 дней до последнего рабочего дня года, и 14-15 ноября у нас была удвоенная нагрузка. Сейчас ФПК и другие перевозчики сделали много билетов со стартом продаж за 60, 90 и даже 120 дней, и этот пик размазался. Но в последний рабочий день апреля всегда будет нагрузка на электрички перед майскими, и есть ещё пики. Но про сезонность билетов и пути миграции дембеля мои коллеги из ж/д лучше расскажут, а я продолжу про архитектуру.
Где-то в 2014-м начали дербанить большую базу данных на много маленьких. Это было важно потому, что она опасно росла, и падение было критичным. Мы стали выделять отдельные маленькие базочки (на 5–10 таблиц) под конкретный функционал, чтобы сбои меньше аффектили другие сервисы, и чтобы всё это можно было легче масштабировать. Стоит отметить, что для распределения нагрузки и масштабирования мы использовали для чтения реплики. Восстановление реплик для большой базы после сбоя репликации могло занимать часы, и всё это время приходилось «лететь на честном слове и на одном крыле». Воспоминания о таких периодах до сих пор вызывают неприятный холодок где-то между ушами. Сейчас у нас — около 200 инстансов разных баз, и администрирование руками такого количества инсталляций — дело трудоёмкое и ненадёжное. Поэтому мы используем Github Orchestrator, который автоматизирует работу с репликами и proxySql для распределения нагрузки и защиты от сбоев конкретной БД.
Как сейчас
В общем, постепенно мы начали выделять асинхронные задачи и разделять их запуски в обработчике событий, чтобы одно не мешало другому.
Когда вышел PHP 7, мы увидели в тестах очень большой прогресс в производительности и снижении потребления ресурсов. Переезд на него прошёл с небольшим геморроем, на весь проект от начала тестов до полного перевода всего продакшна ушло чуть более полугода, но зато после этого потребление ресурсов упало почти вдвое. График времени загрузки CPU — вверху поста.
Монолит сохранился до сих пор и, по моей оценке, составляет примерно 40 % от кодовой базы. Стоит сказать, что задача заменить весь монолит на сервисы в явном виде не ставится. Двигаемся прагматично: всё новое делается на микросервисах, если же надо доработать старый функционал в монолите, то стараемся перевести его на сервисную архитектуру, если только доработка не совсем уж мелкая. При этом монолит покрыт тестами так, что мы можем деплоиться два раза в неделю с достаточным уровнем качества. Фичи покрываются по-разному, юнит-тесты довольно полные, UI-тесты и Acceptance-тесты покрывают почти весь функционал портала (у нас около 15 000 тест-кейсов), тесты на API более-менее полные. Нагрузочного тестирования почти не делаем. Точнее, у нас стейджинг похож на прод по структуре, но не по мощности, и обложен такими же мониторингами. Мы генерим нагрузку, если видим, что прошлый прогон на старом релизе отличается по таймингам, смотрим, насколько критично. Если новый релиз и старый примерно одинаковые, то выпускаем в прод. В любом случае все фичи выходят под рубильником, чтобы можно было в любую секунду отключить, если что-то пойдёт не так.
Тяжёлые фичи всегда тестируем под 1 % пользователей. Потом переходим на 2 %, на 5 %, на 10 % и так доходим до всех юзеров. То есть всегда можем увидеть атипичную нагрузку до убивающего серваки всплеска и отключить заранее.
Там, где было нужно, мы брали (и будем брать) 4-5 месяцев на проект реинжиниринга, когда команда фокусируется на конкретной задаче. Это хороший способ разрубать гордиев узел, когда локальный рефакторинг уже не помогает. Так мы сделали несколько лет назад с авиа: переделали архитектуру, сделали — сразу получили моментальное ускорение в разработке, смогли запустить много новых фич. За два месяца после реинжиниринга выросли на порядок по клиентам за счёт фич. Стали более аккуратно управлять ценами, подключением партнёров, всё стало быстрее. Радость. Надо сказать, сейчас пришла пора поступить аналогичным образом ещё раз, но такова судьба: способы построения приложений меняются, появляются новые решения, подходы, инструменты. Чтобы оставаться в бизнесе, необходимо развиваться.
Основная задача реинжиниринга для нас — ускорить разработку дальше. Если ничего нового не надо, то и реинжиниринг не нужен. Не надо придумывать новое: нет смысла вкладываться в модернизацию. А так при поддержании современного стека и архитектуры люди быстрее входят в работу, быстрее подключается новое, система ведёт себя более предсказуемо, разработчикам интереснее работать над проектом. Сейчас есть задача допилить монолит, не выкидывая его полностью, так, чтобы каждый продукт мог выкладывать обновления, не завися от других. Т. е. получить пофичный CI/CD в монолите.
На сегодняшний день мы используем для обмена информацией между сервисами не только кролика, но и REST, и gRPC. Часть микросервисов пишем на Golang: вычислительная скорость и работа с памятью там отличные. Был заход на внедрение поддержки nodeJS, но в итоге оставили ноду только для серверного рендеринга, а бизнес-логику оставили на PHP и Go. В принципе, выбранный подход позволяет разрабатывать сервисы практически на любых языках, но мы решили ограничивать зоопарк, чтобы не увеличивать сложность системы.
Сейчас идём в микросервисы, которые будут работать в Docker-контейнерах под оркестрацией OpenShift. Задача в течение года-полутора — 90 % всего крутить внутри платформы. Почему? Так быстрее деплоиться, быстрее проверять версии, меньше отличия прода от devel-окружения. Разработчик может думать больше о фиче, которую реализует, а не о том, как развернуть окружение, как его настроить, где запустить, т. е. больше пользы. Опять же — вопросы эксплуатации: микросервисов много, их надо автоматизировать по управлению. Вручную — очень большие расходы, риски ошибок при ручном управлении, а платформа даёт нормальное масштабирование.
Каждый год у нас рост нагрузки — на 30–40 %: всё больше людей осваивает фокусы с Интернетом, перестаёт ходить в физические кассы, мы добавляем новые продукты и фичи к уже существующим. Сейчас около 1 миллиона пользователей в день приходит на портал. Разумеется, не все пользователи одинаково генерируют нагрузку. Что-то совсем не требует вычислительных ресурсов, а, например, поиски — довольно ресурсоёмкая составляющая. Там одна-единственная галочка «плюс-минус три дня» в авиации увеличивает нагрузку в 49 раз (при поиске туда-обратно получается матрица 7 на 7). Всё остальное в сравнении с поиском билета внутри ж/д-систем и авиа достаточно простое. Самое лёгкое в ресурсах — приключения и поиск туров (там не самый простой с точки зрения архитектуры кэш, но всё равно туров куда меньше, чем комбинаций билетов), потом — расписание электричек (оно легко кэшируется стандартными средствами), а уже потом — всё остальное.
Конечно, технический долг всё равно копится. Со всех сторон. Главное — понимать вовремя, где можно успеть отрефакториться, и всё будет хорошо, где не надо ничего трогать (бывает и такое: живём с легаси, если изменений не планируется), а где-то прямо нужно бросаться и реинжинириться, потому что без этого будущего не будет. Понятное дело, допускаем ошибки, но в целом Туту.ру существует 16 лет, и мне нравится динамика проекта.
Комментарии (29)

TyVik
18.06.2019 10:35А вот за python прям обидно. Что ж вы его даже не рассматриваете?

Molodoi Автор
18.06.2019 11:05+1Мы знаем, что в мире существует множество проектов, использующих Python на бекэнде. Но исторически сложилось, что у нас не было достаточной внутренней экспертизы по этому языку. Для аналитических задач и машинного обучения он зашел прекрасно. Но мы так и не встретили людей, которые бы своим примером показали, что Python отличный язык для бека.

blind_oracle
19.06.2019 09:46Если нужен хайлоад, то ребята правильно сделали что ушли сразу на Go. При всей моей любви к Питону — скорость не его сильная сторона.

NikitchenkoSergey
18.06.2019 12:16+1Спасибо! Хотелось бы подробнее узнать (например в следующих статьях) о нюансах работы с шиной сообщений (что делаете, если сообщение теряется, как гарантируете целостность данных), как собираете бекапы с кучи маленьких баз данных, но самое интересное — как распиливаете фичи на микросервисы: как понять, где провести грань, чтобы не было кучи сетевых взаимодействий с другими сервисами, какие данные храните в сервисе и тд. Хочется такое пособие, как из монолита потихоньку выдирать куски и превращать в микросервисы и чтобы потом не страдать. Про деплой тоже хочется узнать подробно.
Molodoi Автор
18.06.2019 12:42+1Спасибо за интерес! Да, идея хорошая, напишу еще. Единственное, хочу сказать, что вряд ли получится руководство на все случаи жизни: даже в рамках одного проекта мы используем разные подходы. Все сильно зависит от конкретного приложения, но могу поделиться именно нашим опытом.

VolCh
18.06.2019 23:14+1Вот не согласен, что в основе техдолга — ошибки прогнозирования. Обычно в основе управленческие решения типа "пока и так сойдёт".
dimm_ddr
19.06.2019 11:19Ну, так-то, это тоже ошибка прогнозирования, просто другого человека. Руководитель решает что если вот сейчас сделать вот так, то в будущем будет ок. Дальше либо это сбывается и компания живет с легаси говнокодом в проекте и не парится из-за этого, либо не сбывается и нужно исправлять технический долг чтобы развиваться или просто не загнуться. Есть, конечно, случаи когда стоит выбор между накоплением технического долга и смертью бизнеса, но я сомневаюсь что таких случаев значимое количество.
VolCh
19.06.2019 17:21Немного не так. Он решил "сейчас так сойдёт, а потом исправим", не поставив задачи на исправление, не выделив ресурсы и т. п. Ну или выделили даже, но что-то более приоритетено "появилось"

Jef239
18.06.2019 23:44технический долг — это плата за ошибку при принятии решения.
Не обязательно. Ну как пример. Придумали новый метод поиска, с ускорением в 10 раз относительно старого. Поиск используют 20 модулей. 3 модуля, где ускорение сильно нужно, обновили. Ещё 17 — остались в техническом долге.
Где тут ошибка при принятии решения?
P.S. Я бы сказал, что технический долг такого рода — это плата за стремление к ортогональности, совместимости и за перфекционизм.

smart
19.06.2019 02:42Приятная статья ) Вадим, ну теперь ты просто обязан писать дальше подробности и детали – например, про тонкую настройку вашей кроличьей шины для больших нагрузок.

vintage
19.06.2019 08:54А почему VibeD не рассматривали?
blind_oracle
19.06.2019 09:48Серьёзно? Тогда уж сразу на Elixir/Erlang надо уходить :)
vintage
19.06.2019 09:51Серьёзно. А чем Elixir лучше? Слышал от человека, что пробовал его использовать, что он довольно медленный. Что не удивительно, ибо он крутится на VM.
nightwolf_du
19.06.2019 10:36Если можно, встряну в вашу дискуссию.
По впечатлению семилетней давности:
Математика и работа со строками в привычном формате на эрланговской виртуальной машине действительно слабовата. Хочешь быстрые строки — работай с байтами, хочешь числодробилку — пиши на с/плюсах и биндся с ними.
Но если тебе нужно поднять кластер из нескольких сотен узлов с разными задачами — это, наверное, самый старый и отлаженный язык & фреймворк в котором есть для этого буквально всё и из коробки.
Ну, и с тех пор 7 лет прошло, скорее всего какие-то части работы с математикой/строками переделали и оптимизнули.
Для меня слабым местом до сих пор видится отсутствие налаженного «стартового пакета», основной IDE со всеми современными фичами. Не плагина к IntelliJ IDEA с которым еще помучаться надо было, а коробочного решения.
blind_oracle
19.06.2019 10:49Что не удивительно, ибо он крутится на VM.
Большинство языков с автоматическим управлением памяти крутится либо в VM (Java и ее деривативы, Erlang и т.п.), либо имеет некий рантайм в бинари (Go). Это не мешает этим языкам быть быстрыми при умелом использовании.
Про D я скажу одно: я еще ни разу не видел девелопера, который бы на нем писал. А видел я их много. Поэтому вывод простой: даже если этот язык волшебный (в чем я сомневаюсь, но судить не буду), то нанять под него людей будет сложно.
У меня тут в памяти история от техдира autoscout24.de, которые начали писать бэк на Scala, но через несколько лет им пришлось полностью его переделать на обычной Java т.к. нанять нужное количество девелоперов умеющих в Scala (который явно популярнее D) не удавалось никак, а развивались они быстро и разработчиков нужно было много. Да и читабельность кода на Scala была не на высоте.vintage
19.06.2019 12:34Любой вменяемый девелопер, знакомый с любым статически типизированным языком, освоит его за неделю в процессе онбординга в компанию. Это не рокетсаенс.
blind_oracle
19.06.2019 12:53Это очень оптимистичная точка зрения. Как минимум девелопер должен захотеть это сделать. И оценить пользу для себя в изучении этого языка. Я бы, например, не пошел изучать какой-то D, знание которого не принесет мне пользы на рынке. Это замкнутый круг в некотором роде.
Ну и еще давай возьмем С++. Статический типизированный? Да. Многие ли могут сказать что знают его хорошо учитывая новые стандарты начиная с C++11? Не думаю.vintage
19.06.2019 15:06-1Ценность разработчика в знании предметной области и умении решать бизнес задачи, а не в знании языка и капризах. И если разработчик чурается расширить свой кругозор, изучением новой для себя технологии, которая сулит повысить его эффективность, то я бы не хотел с таким работать.
Вы сейчас спорите о вкусе устриц с тем, кто их ел. Не нужно быть экспертом в C++, чтобы быстро освоить D. Достаточно знать основы. D гораздо проще, при той же мощности.
nightwolf_du
19.06.2019 15:32Но есть еще нюанс с часто употребимыми библиотеками на новом языке…
Как логировать, чем сериализовать, как здесь работают с базами…
Конечно, всегда можно писать в консоль/файл, написать свой сериализатор в json и использовать первый попавшийся драйвер к бд… но как-то это некрасиво.vintage
19.06.2019 18:17Нет там никаких нюансов, вот чего вы фантазируете?
Есть стандартная библиотека покрывающая 90% нужд программирования вообще: https://dlang.org/phobos/index.html
Есть веб-фреймворк покрывающий 90% нужд веб-программирования: https://vibed.org/api/
Ну и есть репозиторий пакетов, если в первых двух чего-то не хватило: https://code.dlang.org/VolCh
19.06.2019 18:51Есть веб-фреймворк покрывающий 90% нужд веб-программирования:
Я правильно понимаю, что 90% веб-программирования из баз данных нужны только Mongo и Redis? А для 10% полноценная ORM появилась только 5 месяцев назад и имеет аж 22 скачивания за это время?
vintage
19.06.2019 19:32Я не знаю, зачем они вкорячили клиенты к Монге и Редиске прямо во фреймворк. Делать им там нечего.
О которой "полноценной ОРМ" идёт речь?
blind_oracle
19.06.2019 16:08Вы очень идеализированно смотрите на мир. Идеально-сферических разработчиков в вакууме не так много на рынке, к сожалению, я тоже бы хотел работать только с такими.
Опять таки изучение нового языка и всей экосистемы вокруг него — это большая инвестиция времени — за неделю нельзя стать экспертом в любом языке и его либах, кто бы что не говорил.
Если я не вижу каких-то веских оснований этим заниматься (интерес, потенциал и т.п.), то я потрачу это время на что-то другое.
VolCh
19.06.2019 17:24+1Основы языка изучит — это даже не полбеды, а малая часть того, что нужно знать, чтобы решать бизнес-задачи. Всю остальну экосистему надо изучить, библиотеки, фреймворки, лучшие практики и антипаттерны,...

sarapinit
19.06.2019 11:28если язык правильно готовить, то можно даже строить на нём системы реального времени
Я думал что системы реального времени нельзя строить на языках со сборкой мусора. Из-за блокировки потоков сборщиком мусора. Или в php есть какая-то магия по управлению памятью?Molodoi Автор
19.06.2019 13:46Конечно, речь не идет о жестких ОСРВ — там требования сильно выше. Да и учитывая, что PHP скрипты запускаются внутри какой-то ОС (в нашем случае Linux), то уже на этом уровне появляется мягкость. О запуске в QNX речи, конечно, не идет. Тем не менее, в PHP есть возможность работы с прерываниями, мьютексами и т.п. так что некоторое подобие системы реального времени вполне можно построить.
По управлению памятью: есть возможность принудительно освободить память, что мы и использовали для долгоживущих процессов, чтобы не разрастались. Там есть тонкости, безусловно, но получилось сделать так, чтобы память реально высвобождалась в процессе работы скрипта.
Но да, PHP все же надо использовать для другого.
Slonopotamych
19.06.2019 13:46А сколько по времени у вас выполняются все тесты?
Molodoi Автор
19.06.2019 13:48+1Полный набор отрабатывает чуть более, чем за час. Полный набор запускается при финальных сборках и по ночам. Разработчик может запустить только тот сегмент, который его интересует в рамках выполняемой задачи.
PQR
Отличный пост! Написано явно с душой и любовью к проекту, читается на одном дыхании. Захотелось отправить вам резюме :)