
Основа любого крупномасштабного проекта по машинному обучению начинается с нейронной сети. В этой статье вы найдёте всё, что вам нужно знать о них.
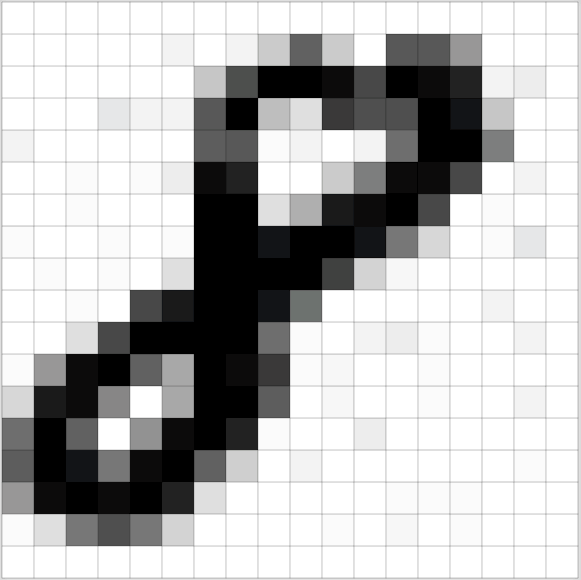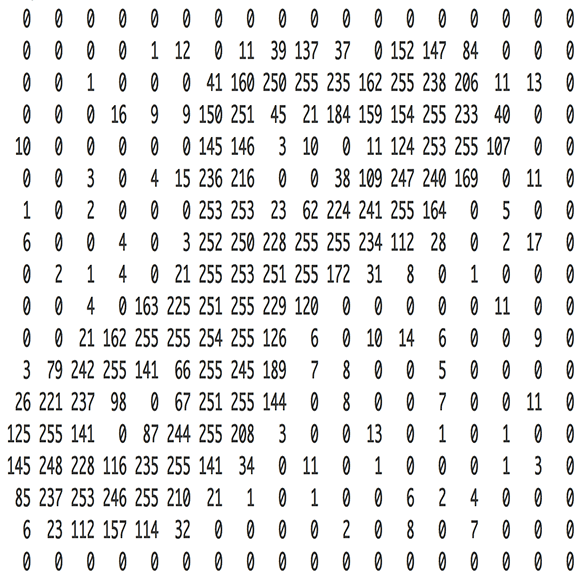
Нейронные сети (НС) используются практически везде, где нужен эвристический подход для решения проблемы. Эта статья научит вас всему, что вам нужно знать о НС. Прочитав её, вы будете иметь общие знания о НС — о том, как они работают, и о том, как их можно создавать самостоятельно.
Вот, что мы с вами пройдем:
Мне потребовалась неделя, чтобы написать всё содержание этой статьи, так что плюсуйте, если вы подчеркнули для себя что-то полезное. Надеюсь, эта статья научит вас чему-то новому, начнем!
Не буду утомлять вас историей о НС, и лишь кратко расскажу о ней. Вот статья в Вики на тему искусственной нейронной сети.
Все началось с того, что Warren McCulloch и Walter Pitts создали первую модель НС в 1943 году. Их модель была основана исключительно на математике и алгоритмах и не могла быть протестирована из-за нехватки вычислительных ресурсов.
Позже, в 1958 году, Frank Rosenblatt создал первую в мире модель, способную распознавать узоры. Это изменило бы всё. Однако он дал только обозначения и модель. Фактическая модель до сих пор не может быть проверена. До этого были проведены сравнительно небольшие исследования.
Первые НС, которые могли быть испытаны и имели много слоев, были опубликованы Алексеем Ивахненко и Lapa в 1965 году. После этого исследования по НС стагнировали из-за высокой выполнимости моделей машинного обучения. Это было сделано Marvin Minsky иSeymour Papert в 1969 году.
Эта стагнация была относительно кратковременной, так как 6 лет спустя, в 1975 году, Пол Вербос предложил обратное распространение, которое решило проблему XOR и в целом сделало обучение НС более эффективным.
Max-pool была изобретена позже, в 1992 году, что помогло с распознаванием трехмерных объектов, поскольку это было решением с минимальной инвариантностью сдвига и устойчивостью к деформации.
В период с 2009 по 2012 год рекуррентные НС и Deep Feed Forward НС, созданные исследовательской группой Jurgen Schmidhuber, стали победителями 8 международных конкурсов по распознаванию образов и машинному обучению.
В 2011 году Deep НС начали объединять сверточные слои со слоями максимального пула, выход которых затем передавался нескольким полностью соединенным слоям, за которыми следовал выходной слой. Они называются сверхточными нейронными сетями.
После этого было проведено еще несколько исследований, но то, о чем я уже рассказал — это основные моменты, о которых нужно знать.
Вы будете мыслить правильно, если будете считать НС как составную функцию. Вы даете ей некоторую информацию, и она дает вам в ответ некоторую информацию.
Есть 3 части, которые составляют архитектуру классической НС:
Все вышеперечисленное — это то, что вам нужно, чтобы создать архитектуру НС.
Вы можете думать о них как о строительных блоках/кирпичах здания. В зависимости от того, как вы хотите, чтобы здание функционировало, вы будете выстраивать кирпичи в определенном порядке и наоборот. Цемент можно рассматривать как вес. Независимо от того, насколько сильны ваши веса, если у вас нет достаточного количества кирпичей для решения проблемы, здание разрушится. Однако вы можете просто заставить здание функционировать с минимальной точностью (используя наименьшее количество кирпичей), а затем постепенно наращивать эту архитектуру для решения своей проблемы.
Будучи наименее важными из трех частей архитектуры НС, они представляют собой функции, которые содержат в себе весовые коэффициенты и смещения, ожидающие получения данных. После получения данных они выполняют некоторые вычисления, а затем используют функцию активации, чтобы ограничить данные диапазоном (в основном).
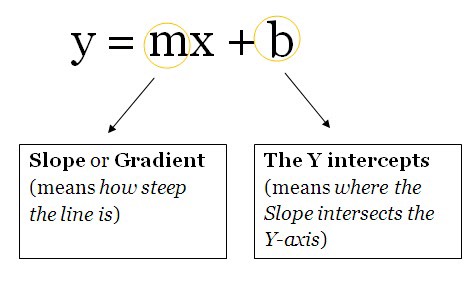
Думайте об этих единицах как о коробке, содержащей веса и уклоны. Коробка открыта с 2 концов. Один конец получает данные, другой конец выводит измененные данные. Затем данные начинают поступать в блок, блок затем умножает веса на данные и затем добавляет смещение к умноженным данным. Это единое целое, которое также можно рассматривать как функцию. Эта функция похожа на эту, которая является шаблоном функции для прямой линии:
Представьте, что их несколько. Теперь вы будете вычислять несколько выходов для одной и той же точки данных (вход). Эти выходные данные затем отправляются в другой модуль, который затем вычисляет окончательный выходной сигнал НС.
Будучи самой важной частью НС, они являются числами, которые НС должна знать, чтобы обобщить проблему.
Эти числа говорят о том, что НС «думает», что она должна добавить после умножения весов на данные. Конечно, это неправильно, но НС также изучает оптимальные отклонения.
Это значения, которые вы должны установить вручную. Если вы думаете о НС как о вычислительном алгоритме, то струны, которые изменяют поведение этого алгоритма, будут гиперпараметрами НС.
Они также известны как функции отображения. Они принимают некоторый вход по оси X и выводят значение в ограниченном диапазоне (в основном). Они используются для преобразования больших выходов из модулей в меньшее значение — в большинстве случаев, и способствуют нелинейности в вашей НС. Надо знать о том, что выбор функции активации может значительно улучшить или помешать работе вашей НС. Вы можете выбрать разные функции активации для разных юнитов, если в этом есть необходимость.
Вот некоторые общие функции активации:
Сигмоидная функция
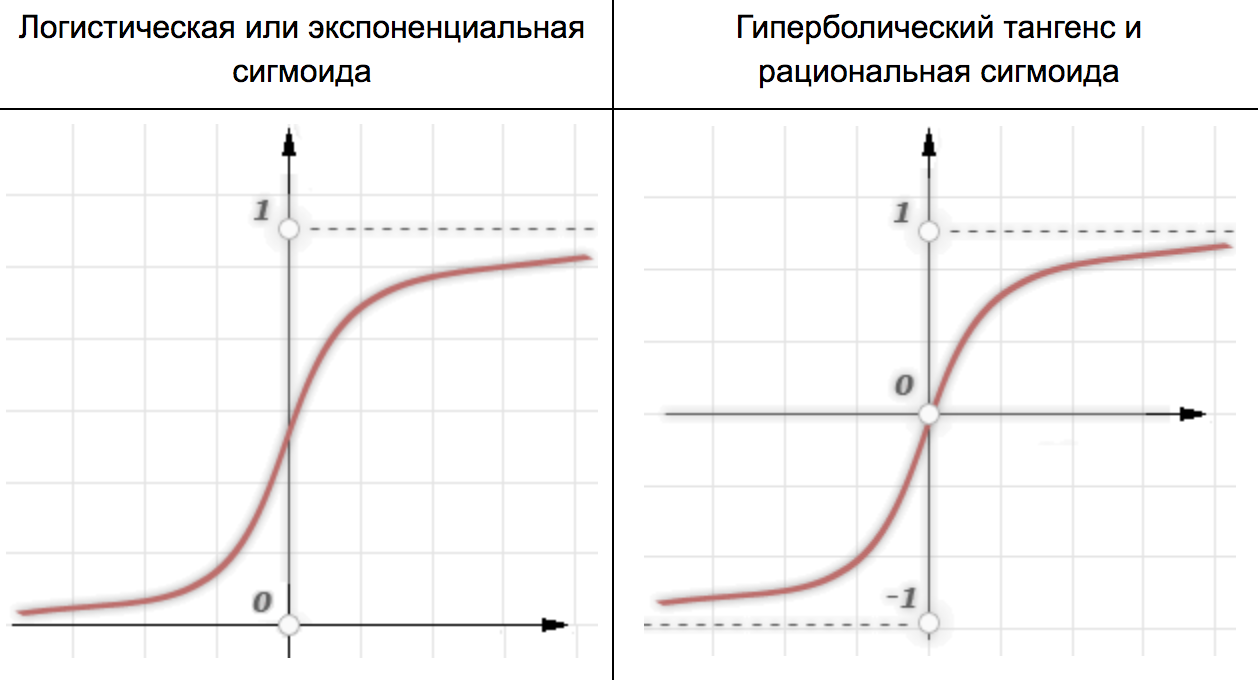
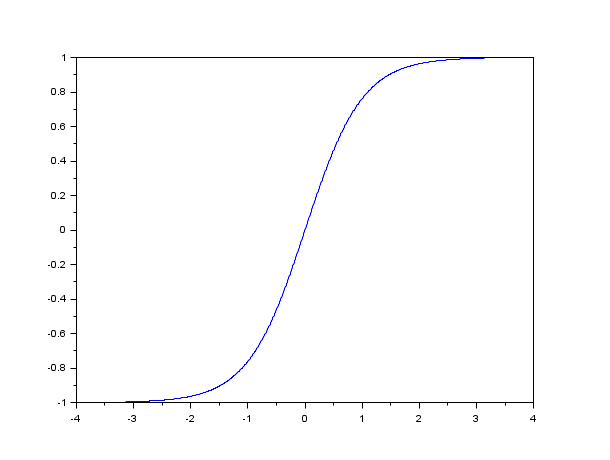
Гиперболический тангенс
Выпрямитель
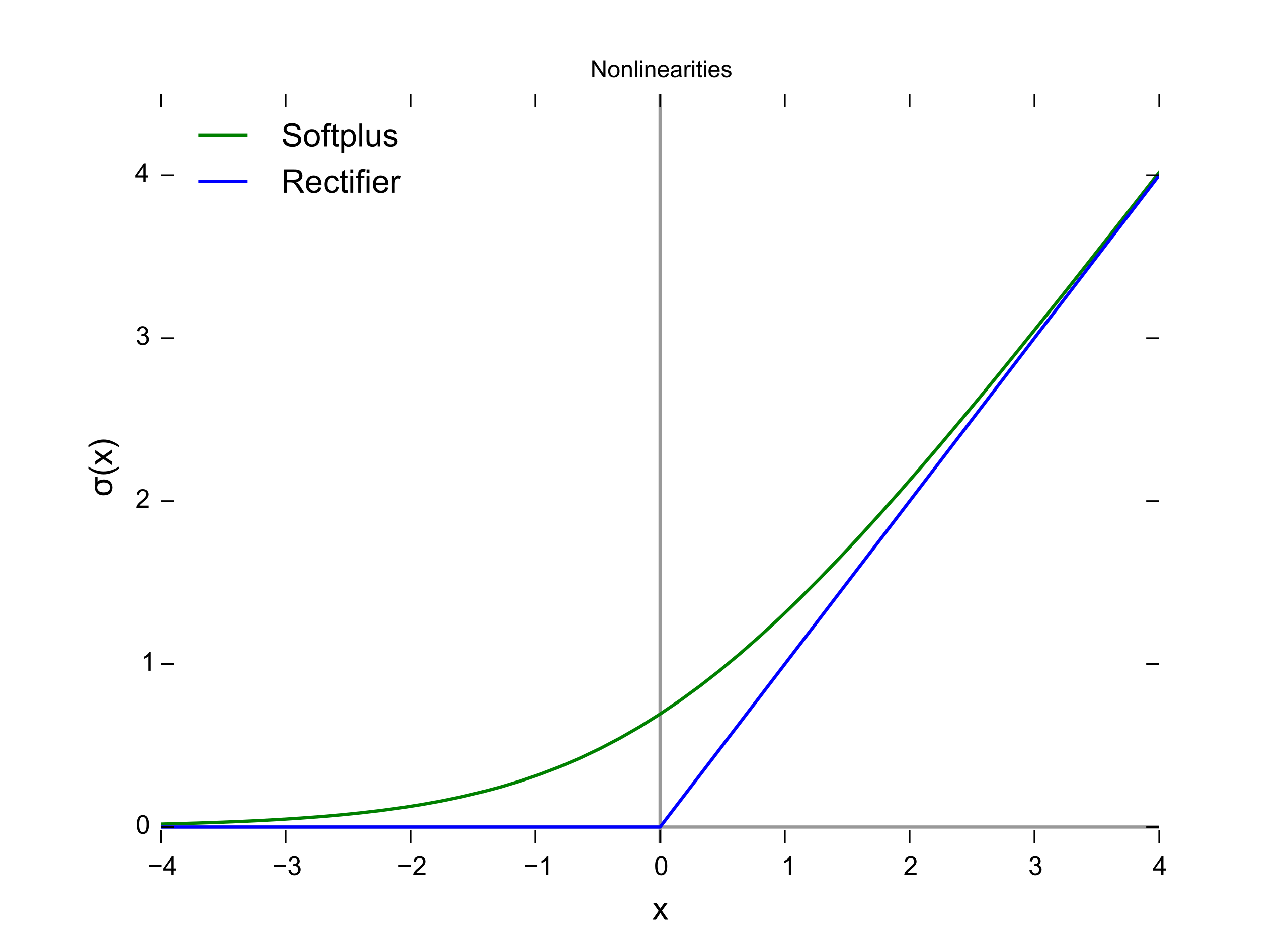
Это то, что помогает НС усложнить решение любой проблемы. Увеличивающиеся слои (с единицами измерения) могут увеличить нелинейность вывода НС. Каждый слой содержит некоторое количество единиц. Сумма в большинстве случаев полностью зависит от создателя. Однако наличие слишком большого количества слоев для простой задачи может излишне увеличить её сложность и в большинстве случаев дополнительно снизить её точность, и наоборот.
Есть 2 слоя, которые есть у каждой НС. Это входной и выходной слои. Любой слой между ними называется скрытым слоем. НС на рисунке, показанном ниже, содержит входной слой (с 8 единицами), выходной слой (с 4 единицами) и 3 скрытых слоя, каждый из которых содержит 9 единиц.
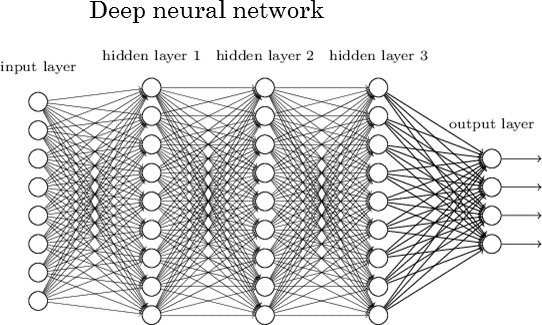
НС с 2 или более скрытыми слоями, каждый из которых содержит большое количество единиц, называется Deep Neural Network, которая породила новую область обучения под названием Deep Learning. НС, показанная на рисунке, является одним из таких примеров.
Наиболее распространенный способ научить НС обобщать проблему — это использовать Gradient Descent. В сочетании с GD есть и другие распространенные способы обучения НС, одним из таких является использование обратного распространения. Используя этот метод, ошибка в выходном слое НС распространяется в обратном направлении с использованием правила цепочки из исчисления. Для начинающего исследователя это очень сложно понять, без хорошего понимания исчисления, так что сильно не удивляйтесь этому. Кликайте здесь, чтобы просмотреть статью, которая действительно помогла мне, когда я боролся с Back-Propagation. Мне понадобилось полтора дня, чтобы понять, что происходит, и почему ошибки распространяются задом наперед.
Есть много разных предостережений в обучении НС. Тем не менее, просмотр их в статье, предназначенной для начинающих, было бы очень утомительным занятием и излишне подавляющим.
Чтобы объяснить, как все управляется в проекте, я создал книгу Jupyter Notebook, содержащую небольшую НС, которая изучает логические элементы XOR. Нажмите здесь, чтобы посмотреть блокнот.
После просмотра и понимания того, что происходит в Notebook, вы должны иметь общее представление о том, как устроена базовая НС.
Учебные данные в НС, созданные в Notebook, располагаются в виде матрицы. Именно так обычно располагаются данные. Размеры матриц, показанных в разных проектах, могут отличаться.
Обычно с большими объемами данных данные делятся на 2 категории: данные обучения (60%) и данные испытаний (40%). Затем НС обучается на данных обучения, а затем проверяет свою точность на данных испытаний.
На этом наша статья подошла к концу. Надеюсь, вы узнали для себя что-то новое!
YouTube:
Siraj Raval
3Blue1Brown
The Coding Train
Brandon Rohrer
giant_neural_network
Hugo Larochelle
Jabrils
Luis Serrano
Coursera:
Deep Learning Specialization
Introduction to Deep Learning
Всем знаний!
Нейронные сети (НС) используются практически везде, где нужен эвристический подход для решения проблемы. Эта статья научит вас всему, что вам нужно знать о НС. Прочитав её, вы будете иметь общие знания о НС — о том, как они работают, и о том, как их можно создавать самостоятельно.
Вот, что мы с вами пройдем:
- История нейронных сетей
- Что на самом деле является нейронной сетью?
- Единицы / Нейроны
- Веса / Параметры / Соединения
- Искажения
- Hyper-Parameters
- Функции активации
- Слои
- Что происходит, когда нейронная сеть учится?
- Детали реализации (Как все управляется в проекте)
- Подробнее о нейронных сетях (ссылки на дополнительные ресурсы)
Мне потребовалась неделя, чтобы написать всё содержание этой статьи, так что плюсуйте, если вы подчеркнули для себя что-то полезное. Надеюсь, эта статья научит вас чему-то новому, начнем!
История нейронных сетей
Не буду утомлять вас историей о НС, и лишь кратко расскажу о ней. Вот статья в Вики на тему искусственной нейронной сети.
Все началось с того, что Warren McCulloch и Walter Pitts создали первую модель НС в 1943 году. Их модель была основана исключительно на математике и алгоритмах и не могла быть протестирована из-за нехватки вычислительных ресурсов.
Позже, в 1958 году, Frank Rosenblatt создал первую в мире модель, способную распознавать узоры. Это изменило бы всё. Однако он дал только обозначения и модель. Фактическая модель до сих пор не может быть проверена. До этого были проведены сравнительно небольшие исследования.
Первые НС, которые могли быть испытаны и имели много слоев, были опубликованы Алексеем Ивахненко и Lapa в 1965 году. После этого исследования по НС стагнировали из-за высокой выполнимости моделей машинного обучения. Это было сделано Marvin Minsky иSeymour Papert в 1969 году.
Эта стагнация была относительно кратковременной, так как 6 лет спустя, в 1975 году, Пол Вербос предложил обратное распространение, которое решило проблему XOR и в целом сделало обучение НС более эффективным.
Max-pool была изобретена позже, в 1992 году, что помогло с распознаванием трехмерных объектов, поскольку это было решением с минимальной инвариантностью сдвига и устойчивостью к деформации.
В период с 2009 по 2012 год рекуррентные НС и Deep Feed Forward НС, созданные исследовательской группой Jurgen Schmidhuber, стали победителями 8 международных конкурсов по распознаванию образов и машинному обучению.
В 2011 году Deep НС начали объединять сверточные слои со слоями максимального пула, выход которых затем передавался нескольким полностью соединенным слоям, за которыми следовал выходной слой. Они называются сверхточными нейронными сетями.
После этого было проведено еще несколько исследований, но то, о чем я уже рассказал — это основные моменты, о которых нужно знать.
Что на самом деле является нейронной сетью?
Вы будете мыслить правильно, если будете считать НС как составную функцию. Вы даете ей некоторую информацию, и она дает вам в ответ некоторую информацию.
Есть 3 части, которые составляют архитектуру классической НС:
- Единицы/Нейроны;
- Соединения/Веса/Параметры;
- Искажения.
Все вышеперечисленное — это то, что вам нужно, чтобы создать архитектуру НС.
Вы можете думать о них как о строительных блоках/кирпичах здания. В зависимости от того, как вы хотите, чтобы здание функционировало, вы будете выстраивать кирпичи в определенном порядке и наоборот. Цемент можно рассматривать как вес. Независимо от того, насколько сильны ваши веса, если у вас нет достаточного количества кирпичей для решения проблемы, здание разрушится. Однако вы можете просто заставить здание функционировать с минимальной точностью (используя наименьшее количество кирпичей), а затем постепенно наращивать эту архитектуру для решения своей проблемы.
Единицы / Нейроны
Будучи наименее важными из трех частей архитектуры НС, они представляют собой функции, которые содержат в себе весовые коэффициенты и смещения, ожидающие получения данных. После получения данных они выполняют некоторые вычисления, а затем используют функцию активации, чтобы ограничить данные диапазоном (в основном).
Думайте об этих единицах как о коробке, содержащей веса и уклоны. Коробка открыта с 2 концов. Один конец получает данные, другой конец выводит измененные данные. Затем данные начинают поступать в блок, блок затем умножает веса на данные и затем добавляет смещение к умноженным данным. Это единое целое, которое также можно рассматривать как функцию. Эта функция похожа на эту, которая является шаблоном функции для прямой линии:
Представьте, что их несколько. Теперь вы будете вычислять несколько выходов для одной и той же точки данных (вход). Эти выходные данные затем отправляются в другой модуль, который затем вычисляет окончательный выходной сигнал НС.
Веса/Параметры/Соединения
Будучи самой важной частью НС, они являются числами, которые НС должна знать, чтобы обобщить проблему.
Искажения
Эти числа говорят о том, что НС «думает», что она должна добавить после умножения весов на данные. Конечно, это неправильно, но НС также изучает оптимальные отклонения.
Hyper-Parameter
Это значения, которые вы должны установить вручную. Если вы думаете о НС как о вычислительном алгоритме, то струны, которые изменяют поведение этого алгоритма, будут гиперпараметрами НС.
Функции активации
Они также известны как функции отображения. Они принимают некоторый вход по оси X и выводят значение в ограниченном диапазоне (в основном). Они используются для преобразования больших выходов из модулей в меньшее значение — в большинстве случаев, и способствуют нелинейности в вашей НС. Надо знать о том, что выбор функции активации может значительно улучшить или помешать работе вашей НС. Вы можете выбрать разные функции активации для разных юнитов, если в этом есть необходимость.
Вот некоторые общие функции активации:
Сигмоидная функция
Гиперболический тангенс
Выпрямитель
Слои
Это то, что помогает НС усложнить решение любой проблемы. Увеличивающиеся слои (с единицами измерения) могут увеличить нелинейность вывода НС. Каждый слой содержит некоторое количество единиц. Сумма в большинстве случаев полностью зависит от создателя. Однако наличие слишком большого количества слоев для простой задачи может излишне увеличить её сложность и в большинстве случаев дополнительно снизить её точность, и наоборот.
Есть 2 слоя, которые есть у каждой НС. Это входной и выходной слои. Любой слой между ними называется скрытым слоем. НС на рисунке, показанном ниже, содержит входной слой (с 8 единицами), выходной слой (с 4 единицами) и 3 скрытых слоя, каждый из которых содержит 9 единиц.
НС с 2 или более скрытыми слоями, каждый из которых содержит большое количество единиц, называется Deep Neural Network, которая породила новую область обучения под названием Deep Learning. НС, показанная на рисунке, является одним из таких примеров.
Что происходит, когда нейронная сеть учится?
Наиболее распространенный способ научить НС обобщать проблему — это использовать Gradient Descent. В сочетании с GD есть и другие распространенные способы обучения НС, одним из таких является использование обратного распространения. Используя этот метод, ошибка в выходном слое НС распространяется в обратном направлении с использованием правила цепочки из исчисления. Для начинающего исследователя это очень сложно понять, без хорошего понимания исчисления, так что сильно не удивляйтесь этому. Кликайте здесь, чтобы просмотреть статью, которая действительно помогла мне, когда я боролся с Back-Propagation. Мне понадобилось полтора дня, чтобы понять, что происходит, и почему ошибки распространяются задом наперед.
Есть много разных предостережений в обучении НС. Тем не менее, просмотр их в статье, предназначенной для начинающих, было бы очень утомительным занятием и излишне подавляющим.
Детали реализации (Как всё управляется в проекте)
Чтобы объяснить, как все управляется в проекте, я создал книгу Jupyter Notebook, содержащую небольшую НС, которая изучает логические элементы XOR. Нажмите здесь, чтобы посмотреть блокнот.
После просмотра и понимания того, что происходит в Notebook, вы должны иметь общее представление о том, как устроена базовая НС.
Учебные данные в НС, созданные в Notebook, располагаются в виде матрицы. Именно так обычно располагаются данные. Размеры матриц, показанных в разных проектах, могут отличаться.
Обычно с большими объемами данных данные делятся на 2 категории: данные обучения (60%) и данные испытаний (40%). Затем НС обучается на данных обучения, а затем проверяет свою точность на данных испытаний.
На этом наша статья подошла к концу. Надеюсь, вы узнали для себя что-то новое!
Полезные ссылки
YouTube:
Siraj Raval
3Blue1Brown
The Coding Train
Brandon Rohrer
giant_neural_network
Hugo Larochelle
Jabrils
Luis Serrano
Coursera:
Deep Learning Specialization
Introduction to Deep Learning
Всем знаний!
Подпишись на канал «Нейрон» в Телеграме (@neurondata) ? там свежие статьи и новости из мира науки о данных появляются каждую неделю. Спасибо всем, кто помогает с полезными ссылками, особенно Игорю Мариарти, Валентину Шабашину.