
Многие, кто работал с Spark ML, знают, что некоторые вещи там сделаны "не совсем удачно"
или не сделаны вообще. Позиция разработчиков Spark в том, что SparkML — это базовая платформа, а все расширения должны быть отдельными пакетами. Но это не всегда удобно, ведь Data Scientist и аналитики хотят работать с привычными инструментами (Jupter, Zeppelin), где есть большая часть того, что нужно. Они не хотят собирать при помощи maven-assembly JAR-файлы на 500 мегабайт или руками скачивать зависимости и добавлять в параметры запуска Spark. А более тонкая работа с системами сборки JVM-проектов может потребовать от привыкшых к Jupyter/Zeppelin аналитиков и DataScientist-ов много дополнительных усилий. Просить же DevOps-ов и администраторов кластера ставить кучу пакетов на вычислительные ноды — явно плохая идея. Тот, кто писал расширения для SparkML самостоятельно, знает, сколько там скрытых трудностей с важными классами и методами (которые почему-то private[ml]), ограничениями на типы сохраняемых параметров и т.д.
И кажется, что теперь, с библиотекой MMLSpark, жизнь станет немного проще, а порог вхождения в масштабируемое машинное обучение со SparkML и Scala чуть ниже.
Введение
Из-за ряда трудностей, а также скудного набора готовых методов и решений в SparkML, многие компании пишут свои расширения для Spark. Один из примеров — PravdaML, которую разрабатывают в Одноклассниках и которая, судя по беглой оценке того, что есть в GitHub, выглядит очень перспективно. К сожалению, большая часть подобных решений либо вообще закрыты, либо открыты, но не имеют возможности установки через Maven/sbt и документацию API, что сильно затрудняет работу с ними.
Сегодня мы рассмотрим библиотеку MMLSpark.
Рассматривать будем, как обычно, на примере задачи классификации пассажиров Титаника. Все же цель показать как можно больше возможностей библиотеки MMLSpark, а не выбить SOTA на ImageNet показать крутой Machine Learning. Так что подойдет и Титаник.

Сама библиотека имеет нативный API для Scala (документация), Python API (документация), а также, судя по некоторым местам в GitHub репозитории, скоро будет иметь API и для R.
В GitHub проекта есть хорошие ноутбуки с примерами (PySpark+Jupyter), но мы пойдем другим путем. Как писал Дмитрий Бугайченко, если разрабатывать для Spark, то есть все основания использовать для этого Scala, более того, Scala позволяет гораздо эффективнее и более гибко определять собственные Transformer и Estimator, чтобы встраивать их в SparkML Pipeline, а про то, как медленно работает numpy/pandas код в UDF (вызываемый на экзекьюторах из JVM), уже много написано.
Кратко об установке
Ноутбук целиком доступен здесь. Для работы с Титаником за глаза хватит Docker-образа Zeppelin, запущенного локально на ноутбуке с дефолтными настройками. Docker можно найти тут. Библиотека MMLSpark находится не в Maven Central, а в spark-packages, и для ее добавления в Zeppelin необходимо запустить в начале ноутбука следующий блок:
%spark.dep
z.addRepo("bintray.com").url("http://dl.bintray.com/spark-packages/maven/")
z.load("Azure:mmlspark:0.17")Стоит сказать, что у библиотеки прекрасная обратная совместимость: в отличие, например, от XGBoost4j-spark, который требует минимум Spark 2.3+, эта штука завелась в Spark 2.2.1, который шел вместе с Docker-образом Zeppelin, и каких-либо трудностей я не заметил.
Замечание: большая часть библиотеки MMLSpark посвящена инференсу сеток на кластере, для чего в ней присутствует CNTK (который, судя по документации, должен читать готовые модели cntk) и огромный блок OpenCV. Мы же сосредоточимся на более приземленных задачах и попробуем "смоделировать" случай, когда у нас есть огромные массивы табличных данных, которые лежат в HDFS в виде .csv, таблиц или в другом формате. Итак, нам необходимо выполнить их предобработку и построить модель, при этом в память одной машины эти данные не помещаются. Поэтому все действия мы будем выполнять на кластере.
Чтение и разведочный анализ
В целом, Spark+Zeppelin неплохо и сами справляются с задачей EDA, но мы попробуем расширить их возможности. Для начала импортируем необходимые нам классы:
- Все из spark.sql.types, чтобы объявить схему и правильно прочитать данные
- Все из spark.sql.functions, чтобы обращаться к колонкам и использовать встроенные функции
- com.microsoft.ml.spark.SummarizeData, который можно назвать аналогом pandas.DataFrame.describe
import com.microsoft.ml.spark.SummarizeData
import org.apache.spark.sql.functions._
import org.apache.spark.sql.types._Читаем наш файлик:
val titanicSchema = StructType(
StructField("Passanger", ShortType)
:: StructField("Survived", ShortType)
:: StructField("PClass", ShortType)
:: StructField("Name", StringType)
:: StructField("Sex", StringType)
:: StructField("Age", ShortType)
:: StructField("SibSp", ShortType)
:: StructField("Parch", ShortType)
:: StructField("Ticket", StringType)
:: StructField("Fare", FloatType)
:: StructField("Cabin", StringType)
:: StructField("Embarked", StringType)
:: Nil
)
val train = spark
.read
.schema(titanicSchema)
.option("header", true)
.csv("/mountV/titanic/train.csv")И теперь посмотрим на сами данные, а также их размер:
println(s"Train shape is: ${train.count} x ${train.columns.length}")
train.limit(5).createOrReplaceTempView("trainHead")Замечание: На самом деле нет необходимости использовать createOrReplaceTempView, когда можно просто писать .show(5). Но у show есть проблема: когда данные "широкие", то текстовое представление таблички "плывет", и становится вообще ничего не понятно.
Получаем размер наших данных: Train shape is: 891 x 12
И теперь в sql-ячейке можем посмотреть на первые 5 строк:
%sql
select * from trainHead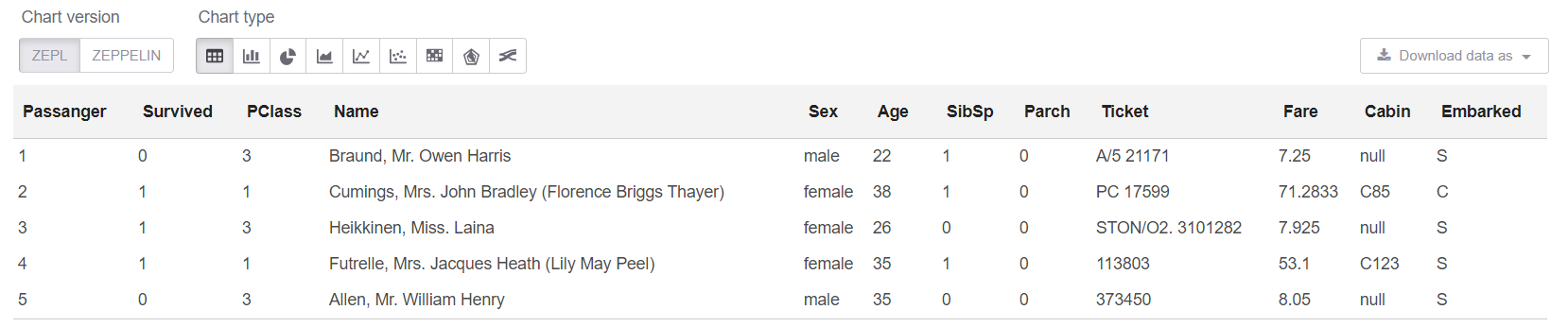
Ну и еще посмотрим Summary по нашей таблице:
new SummarizeData()
.setBasic(true)
.setCounts(true)
.setPercentiles(false)
.setSample(true)
.setErrorThreshold(0.25)
.transform(train)
.createOrReplaceTempView("summary")Класс SummarizeData обладает рядом преимуществ над простым Dataset.describe, так как позволяет считать число пропущенных и уникальных значений, а также позволяет задать точность вычисления квантилей. Это может быть критично для действительно больших данных.

Вообще, мне лично показалось, что у Одноклассников в PravdaML аналог SummarizeData реализован лучше. В Microsoft пошли по простому пути и используют org.apache.spark.sql.functions, просто все удобно обернуто в единый класс. У Одноклассников это реализовано через их VectorStatCollector, что требует чуть более сложного кода при вызове (надо сначала все фичи в вектор сложить) и может потребовать дополнительных операций (например, VectorAssembler обычно отказывается переваривать DecimalType). Но у меня есть предположение, основанное на опыте работы со Spark, что SummarizeData из MMLSpark может упасть с ошибками типа StackOverflow в org.apache.spark.sql.catalyst, если колонок будет реально много, а граф вычислений к моменту запуска уже не маленький (хотя специально для таких любителей "экстрима" в Spark 2.4 добавили возможность вырубить оптимизатор графа Catalyst). Ну и кажется, что при реально большом количестве колонок, версия от Microsoft будет медленнее. Но это, конечно, надо проверять отдельно.
Очистка данных
В Титанике все как обычно — куча строковых колонок и есть пропущенные значения. И какой-то косяк в данных (кажется, конкретно эта версия данных не очень) — 25 строк из пропущенных значений. Для начала исправим это:
val trainFiltered = train.filter(!(isnan(col("Survived")) || isnull(col("Survived"))))Обработка строковых данных
Насколько я помню, в Титанике круче всего привозили признаки, вытащенные из полей Name и Cabin. Их там можно нагенерить очень много, но мы ограничимся несколькими, просто чтобы не приводить примеры почти одинакового кода.
Обычно для подобных вещей удобно использовать регулярные выражения.
Но мы хотим, чтобы при этом:
- все выполнялось распределенно, данные обрабатывались там же, где они находятся;
- все было оформлено в виде SpakrML Transformer или Spark ML Estimator классов, чтобы потом это можно было бы собрать в Pipeline.
Замечание: Pipeline, во-первых, гарантирует нам, что мы всегда применяем одни преобразования и к трейну, и к тесту, а также позволяет отловить ошибку "заглядывания в будущее" на кросс-валидации. И еще он дает нам простые возможности по сохранению, загрузке и предсказанию с использованием нашего пайплайна.
В SparkML есть "почти универсальный" класс для подобных задач — SQLTranformer, но писать на SQL это явно хуже, чем писать на Scala, хотя бы из-за возможности поймать синтаксические или типовые ошибки на этапе компиляции и подсветки синтаксиса в Idea. И тут нам на помощь приходит MMLSpark, где реализован действительно универсальный UDFTransformer:
import com.microsoft.ml.spark.UDFTransformerДля начала создадим нашу функцию преобразований, которая до предела простая, но у нас сейчас цель — показать процесс создания UDFTransformer. В принципе на базе подобных простых примеров, любой сможет дописать логику любого уровня сложности.
val miss = ".*miss\\..*".r
val mr = ".*mr\\..*".r
val mrs = ".*mrs\\..*".r
val master = ".*master.*".r
def convertNames(input: String): Option[String] = {
Option(input).map(x => {
x.toLowerCase match {
case miss() => "Miss"
case mr() => "Mr"
case mrs() => "Mrs"
case master() => "Master"
case _ => "Unknown"
}
})
}(Сразу можно увидеть, насколько удобна в Scala работа с пропущенными значениями, которые, кстати, бывают не только null, но еще и Double.NaN, а еще есть такой прикол такая редкая вещь, как пропуски в BooleanType переменных и т.д.)
Теперь объявим нашу UserDefinedFunction и сразу создадим на ее основе Transformer:
val nameTransformUDF = udf(convertNames _)
val nameTransformer = new UDFTransformer()
.setUDF(nameTransformUDF)
.setInputCol("Name")
.setOutputCol("NameType")Замечание: В Zeppelin ноутбуке все равно, но когда потом это все будет складываться в production-код, важно, чтобы все UDF были в классах или объектах, которые extends Serializable. Очевидная вещь, о которой иногда можно забыть и потом долго вникать, что же тут не так, читая длинные стэктрэйсы ошибок Spark.
Теперь у нас осталось еще поле Cabin. Посмотрим на него внимательнее:

Видим, что тут много пропущенных значений, есть буквы, цифры, разные комбинации и т.д. Возьмем отсюда число кабин (если больше одной), а также цифры — вероятно, в них есть какая-то логика, например, если нумерация от одного конца корабля, то у кают на носу было меньше шансов. Также создадим функции, а потом на их основе UDFTransformer:
def getCabinsCount(input: String): Int = {
Option(input) match {
case Some(x) => x.split(" ").length
case None => -1
}
}
val numPattern = "([a-z])([0-9]+)".r
def getNumbersFromCabin(input: String): Int = {
Option(input) match {
case Some(x) => {
x.split(" ")(0).toLowerCase match {
case numPattern(sym, num) => Integer.parseInt(num)
case _ => -1
}
}
case None => -2
}
}
val cabinsCountUDF = udf(getCabinsCount _)
val numbersFromCabinUDF = udf(getNumbersFromCabin _)
val cabinsCountTransformer = new UDFTransformer()
.setInputCol("Cabin")
.setOutputCol("CabinCount")
.setUDF(cabinsCountUDF)
val numbersFromCabinTransformer = new UDFTransformer()
.setInputCol("Cabin")
.setOutputCol("CabinNumber")
.setUDF(numbersFromCabinUDF)Теперь приступим к пропущенным значениям, а именно к возрасту. Для начала воспользуемся возможносятми Zeppelin по визуализации:
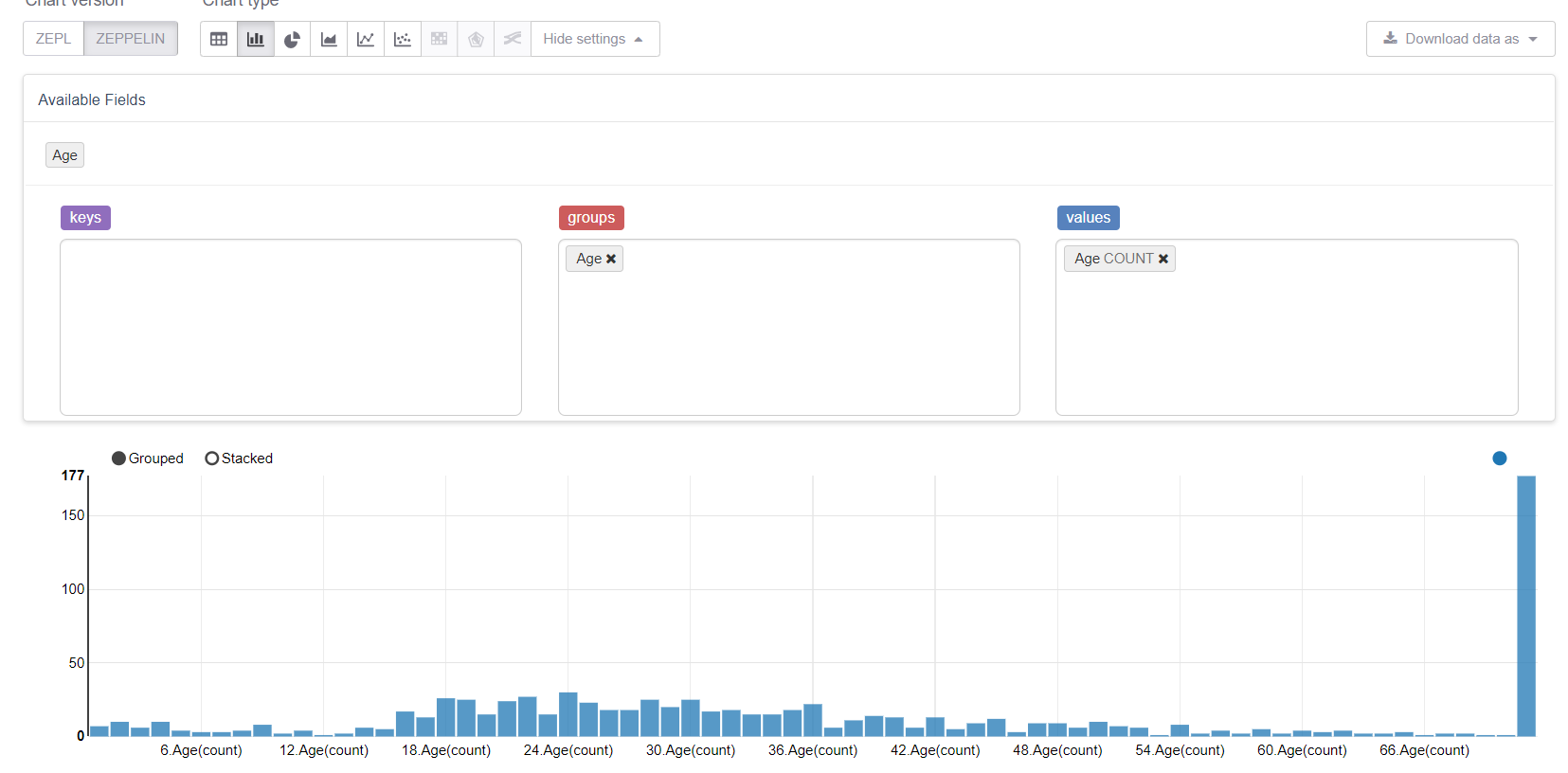
И увидим, как пропущенные значения все портят. Логично было бы заменить их средним (или медианой), но у нас цель рассмотреть все возможности библиотеки MMLSpark. Поэтому мы напишем свой Estimator, который бы считал групповые/средние на обучающей выборке и заменял ими соответствующие пропуски.
Нам понадобятся:
import org.apache.spark.sql.{Dataset, DataFrame}
import org.apache.spark.ml.{Estimator, Model}
import org.apache.spark.ml.param.{Param, ParamMap}
import org.apache.spark.ml.util.Identifiable
import org.apache.spark.ml.util.DefaultParamsWritable
import com.microsoft.ml.spark.{HasInputCol, HasOutputCol}
import com.microsoft.ml.spark.ConstructorWritable
import com.microsoft.ml.spark.ConstructorReadable
import com.microsoft.ml.spark.WrappableОбратим внимание на ConstructorWritable, который очень сильно упрощяет жизнь. Если наш Model — "обученная" модель, которую возвращает метод fit(), полностью определяющаяся своим конструктором (а это, наверное, 99% случаев), то мы можем вообще не писать руками сериализацию. Это действительно сильно упрощает и ускоряет разработку, исключает ошибки, а также снижает порог вхождения для DataScientist и аналитиков, которые обычно не являются профессиональными программистами.
Определим наш класс Estimator. По сути самое важное тут — метод fit, остальное — технические моменты:
class GroupImputerEstimator(override val uid: String) extends Estimator[GroupImputerModel]
with HasInputCol with HasOutputCol with Wrappable with DefaultParamsWritable
{
def this() = this(Identifiable.randomUID("GroupImputer"))
val groupCol: Param[String] = new Param[String](
this, "groupCol", "Groupping column"
)
def setGroupCol(v: String): this.type = super.set(groupCol, v)
def getGroupCol: String = $(groupCol)
override def fit(dataset: Dataset[_]): GroupImputerModel = {
val meanDF = dataset
.toDF
.groupBy($(groupCol))
.agg(mean(col($(inputCol))).alias("groupMean"))
.select(col($(groupCol)), col("groupMean"))
new GroupImputerModel(
uid, meanDF, getInputCol, getOutputCol, getGroupCol
)
}
override def transformSchema(schema: StructType): StructType =
schema
.add(
StructField(
$(outputCol),
schema.filter(x => x.name == $(inputCol))(0).dataType
)
)
override def copy(extra: ParamMap): Estimator[GroupImputerModel] = {
val to = new GroupImputerEstimator(this.uid)
copyValues(to, extra).asInstanceOf[GroupImputerEstimator]
}
}Замечание: я не использовал defaultCopy, так как при вызове он почему-то ругался на то, что у меня нет конструктора .\<init>(java.lang.String), хотя, кажется, этого не должно было быть. Ну в любом случае реализовать copy нетрудно.
Теперь необходимо реализовать Model — класс, который описывает обученную модель и реализует метод transform. Его мы построим на базе встроенной в org.apache.spark.sql.functions функции coalesce:
class GroupImputerModel(
val uid: String,
val meanDF: DataFrame,
val inputCol: String,
val outputCol: String,
val groupCol: String
)
extends Model[GroupImputerModel]
with ConstructorWritable[GroupImputerModel]
{
val ttag: TypeTag[GroupImputerModel] = typeTag[GroupImputerModel]
def objectsToSave: List[Any] = List(uid, meanDF, inputCol, outputCol, groupCol)
override def copy(extra: ParamMap): GroupImputerModel =
new GroupImputerModel(uid, meanDF, inputCol, outputCol, groupCol)
override def transform(dataset: Dataset[_]): DataFrame = {
dataset
.toDF
.join(meanDF, Seq(groupCol), "left")
.withColumn(
outputCol,
coalesce(col(inputCol), col("groupMean"))
.cast(IntegerType))
.drop("groupMean")
}
override def transformSchema (schema: StructType): StructType = schema
.add(
StructField(outputCol, schema.filter(x => x.name == inputCol)(0).dataType)
)
}Последний объект, который нам необходимо объявить, это Reader, который мы реализуем при помощи класса MMLSpark ConstructorReadable:
object GroupImputerModel extends ConstructorReadable[GroupImputerModel]Создание Pipeline
В Pipeline я бы хотел показать как обычные классы SparkML, так и невероятно удобную вещь из MMLSpark — MultiColumnAdapter, которая позволяет применять SparkML-трансформеры ко множеству колонок сразу (для справки, например, StringIndexer и OneHotEncoder принимают на вход ровно одну колонку, что превращает их объявление в боль):
import org.apache.spark.ml.feature.{StringIndexer, VectorAssembler}
import org.apache.spark.ml.Pipeline
import com.microsoft.ml.spark.{MultiColumnAdapter, LightGBMClassifier}Для начала объявим какие колонки у нас какого типа:
val catCols = Array("Sex", "Embarked", "NameType")
val numCols = Array("PClass", "AgeNoMissings", "SibSp", "Parch", "CabinCount", "CabinNumber")Теперь создадим кодировщик строк:
val stringEncoder = new MultiColumnAdapter()
.setBaseStage(new StringIndexer().setHandleInvalid("keep"))
.setInputCols(catCols)
.setOutputCols(catCols.map(x => x + "_freqEncoded"))Замечание: В отличие от scikit-learn в SparkML StringIndexer работает по принципу frequency-encoder, и его можно использовать для задания отношения порядка (т.е. категория 0 < категории 1, и в этом есть смысл) — такой подход часто хорошо работает для решающих деревьев.
Объявим наш Imputer:
val missingImputer = new GroupImputerEstimator()
.setInputCol("Age")
.setOutputCol("AgeNoMissings")
.setGroupCol("Sex")И VectorAssembler, так как классификаторам SparkML удобнее работать с VectorType:
val assembler = new VectorAssembler()
.setInputCols(stringEncoder.getOutputCols ++ numCols)
.setOutputCol("features")Теперь воспользуемся поставляемым с MMLSpark градиентным бустингом — LightGBM, который входит в "большую тройку" лучших реализаций этого алгоритма наравне с XGBoost и CatBoost. Он работает во много раз быстрее, лучше и стабильнее, чем реализация GBM, которая есть в SparkML (даже с учетом того, что JVM-порт все еще в активной разработке):
val catColIndices = Array(0, 1, 2)
val lgbClf = new LightGBMClassifier()
.setFeaturesCol("features")
.setLabelCol("Survived")
.setProbabilityCol("predictedProb")
.setPredictionCol("predictedLabel")
.setRawPredictionCol("rawPrediction")
.setIsUnbalance(true)
.setCategoricalSlotIndexes(catColIndices)
.setObjective("binary")Замечание: LightGBM поддерживает работу с категориальными переменными (почти как catboost), поэтому мы заранее указали ему, где в нашем векторе признаки категории, а он сам уже разберется, что с ними делать и как их кодировать.
- На нодах под управлением RadHat LightGBM любой версии, кроме самой-самой последней, будет падать из-за того, что ему не нравится версия
glibc. Это было исправлено совсем недавно, однако MMLSpark самой последней версии при установке через Maven тянет предпоследнюю версию LightGBM, так что на RadHat надо дополнительно добавлять руками зависимость последней версии. - LightGBM в своей работе создает на драйвере сокет для общения с экзекьюторами, причем делает он это при помощи
new java.net.ServerSocket(0), а следовательно используется случайный порт из эфемерных портов ОС. Если диапозон эфемерных портов отличается от диапазона портов, открытых firewall-ом, томожет сильно подгоретьможно получить интересный эффект, когда LightGBM иногда отрабатывает (когда выбрал удачный порт), а иногда нет. И ошибки там будут видаConnectionTimeOut, которые могут еще указывать, например, на вариант, когда на экзекьюторах виснет GC или что-то такое. В общем, не повторяйте моих ошибок.
Ну и наконец объявим наш Pipeline:
val pipeline = new Pipeline()
.setStages(
Array(
missingImputer,
nameTransformer,
cabinsCountTransformer,
numbersFromCabinTransformer,
stringEncoder,
assembler,
lgbClf
)
)Обучение
Разобьем наш обучающий набор на трейн и тест и проверим наш Pipeline. Тут как раз можно оценить удобство пайплайна, так как он совершенно независим от разбиения и гарантирует нам, что мы применим к train и test одинаковые преобразования, при этом все параметры преобразований будут "выучены" на трейне:
val Array(trainDF, testDF) = trainFiltered.randomSplit(Array(0.8, 0.2))
println(s"Train rows: ${trainDF.count}\nTest rows: ${testDF.count}")
// Train rows: 708
// Test rows: 158
val predictions = pipeline
.fit(trainDF)
.transform(testDF)Для удобного вычисления метрик воспользуемся еще одним классом из MMLSpark — ComputeModelStatistics:
import com.microsoft.ml.spark.ComputeModelStatistics
import com.microsoft.ml.spark.metrics.MetricConstants
val modelEvaluator = new ComputeModelStatistics()
.setLabelCol("Survived")
.setScoresCol("predictedProb")
.setScoredLabelsCol("predictedLabel")
.setEvaluationMetric(MetricConstants.ClassificationMetrics)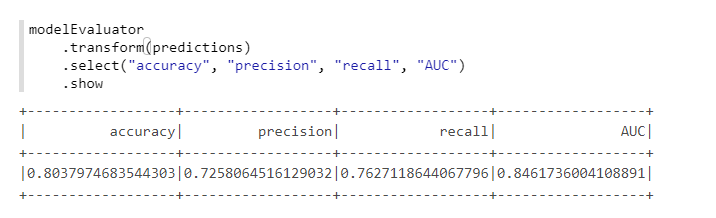
Неплохо, с учетом того, что мы никак не меняли параметры по умолчанию.
Подбор гиперпараметров
Для подбора гиперпараметров в MMLSpark есть отдельная классная штука TuneHyperparameters, в которой реализован случайный поиск по сетке. Однако, к сожалению, она пока не поддерживает Pipeline, поэтому воспользуемся обычным SparkML CrossValidator:
import org.apache.spark.ml.tuning.{ParamGridBuilder, CrossValidator}
import org.apache.spark.ml.evaluation.BinaryClassificationEvaluator
val paramSpace = new ParamGridBuilder()
.addGrid(lgbClf.maxDepth, Array(3, 5))
.addGrid(lgbClf.learningRate, Array(0.05, 0.1))
.addGrid(lgbClf.numIterations, Array(100, 300))
.build
println(s"Size of ParamsGrid: ${paramSpace.size}")
// Size of ParamsGrid: 8
val crossValidator = new CrossValidator()
.setEstimator(pipeline)
.setEstimatorParamMaps(paramSpace)
.setNumFolds(3)
.setSeed(42L)
.setEvaluator(
new BinaryClassificationEvaluator()
.setMetricName("areaUnderROC")
.setLabelCol("Survived")
.setRawPredictionCol("rawPrediction")
)
val bestModel = crossValidator
.fit(trainFiltered)К сожалению, я не нашел удобного способа, как можно посмотреть результаты вместе с теми, параметрами, на которых они получены. Поэтому приходится использовать "монструозные" конструкции:
crossValidator
.getEstimatorParamMaps
.zip(bestModel.avgMetrics)
.foreach(x => {
println(
"\n" +
x._1
.toSeq
.foldLeft(new StringBuilder())(
(a, b) => a
.append(s"\n\t${b.param.name} : ${b.value}"))
.toString
+ s"\n\tMetric: ${x._2}"
)
})Что дает нам примерно такую картину:
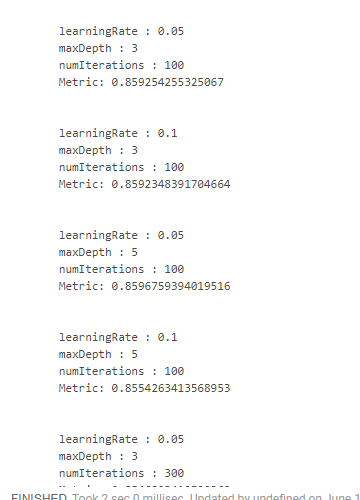
Лучший результат мы получили при уменьшении скорости обучения и увеличении глубины деревьев. На этом основании можно было бы скорректировать пространство поиска и прийти к еще более оптимальному результату, но у нас просто нет такой цели.
Заключение
На самом деле пока MMLSpark имеет версию 0.17 и все еще содержит отдельные баги. Но из всех расширений Spark, которые я встречал, MMLSpark на мой взгляд имеет наиболее полную документацию и наиболее понятный процесс установки и внедрения в процессы. Microsoft пока не особо пиарили ее, был лишь доклад на Databricks, но там скорее про DeepLearning, а не про такие рутинные вещи, о которых писал я.
Лично мне, в наших задачах, эта библиотека очень сильно помогла, позволив чуть меньше продираться через дебри исходников Spark и не использовать reflect для доступа к private[ml] методам, а саму библиотеку нашел один мой коллега почти случайно. При этом, из-за того, что библиотека в активной разработке, структура файлов исходников полная каша несколько запутанная. Ну а из-за того, что особых примеров и иной документации нет (кроме голых scaladoc), по началу в исходники приходилось залезать постоянно.
Поэтому я очень надеюсь, что этот мини-туториал (несмотря на всю его очевидность и простоту) будет кому-то полезен и поможет съэкономить много времени и сил!
sshikov
Спасибо, занимательно.
Вот только абзац про сборку jar файлов на 500 мегабайт я не очень понял. Спарковские параметры --files или --archives — они же работают по любому протоколу, в том числе hdfs:, или скажем http:, и вам в общем-то никто не мешает свои зависимости любого вида туда сложить. Туда, куда вам удобно.
Я не исключаю, что в этой логике баги есть, например, когда я пытался таким образом распределить по узлам справочники размером 30 гигабайт — на Spark 2.2.0 получалось очень плохо, судя по всему, где-то в этом коде есть бутылочное горлышко, однопоточное возможно. Но 500 мегабайт тут точно не предел — на границе 4 гигабайта у меня все еще прекрасно работает.
SemyonSinchenko Автор
Рад, что Вам было интересно)
Я имел ввиду сборку толстых jar, если я хочу использовать что-то (например, из тех же spark-packages), чего нет на кластере. Да, я могу клась jar-ники в hdfs и указывать в параметрах запуска. Но в том и преимущество Maven, что он гарантирует мне, что скачаны все зависимости и нет конфликтов версий. Качать jar руками не всегда удобно.
Но ок, я подумаю, как перефразировать, спасибо за замечание!
sshikov
На самом деле я примерно так этот абзац и понял. Если дело именно в зависимостях, есть один неплохой на мой взгляд способ — собрать все без maven, но aether. Скажем, Игорь Сухоруков тут об этом много раз писал, например вот тут. Aether в чистом виде — конечно слегка посложнее просто maven, но совсем не сильно. Если вы ничего не публикуете — то строк в 50 кода можно уложиться.
SemyonSinchenko Автор
Еще раз спасибо!
Обязательно посмотрю!