

Привет, я Андрей Шальнев, QA Automation Lead в проекте Skyeng Vimbox. В течение года мы с командой занимались оптимизацией процессов автоматического тестирования и сейчас вплотную подошли к ее финальной стадии. А это хороший повод выдохнуть, пересмотреть бэклог и подвести какие-то промежуточные итоги. Для Хабры я решил сделать подборку из десяти наиболее полезных и при этом простых вещей, которые помогли нам справиться с задачей оптимизации автотестов. Надеюсь, статья пригодится QA-командам в растущих компаниях, где старые процессы тестирования уже не справляются с нагрузкой, и вопрос реорганизации встает ребром.
Как у нас сейчас устроены автотесты
Vimbox использует Angular для фронтенда, поэтому тесты мы пишем на довольно классическом для этого решения стеке – Protractor+Jasmine+JS/Typescript. За год мы существенно переработали сьют regression тестов. В начальном виде он был избыточен и не очень удобен – тесты по несколько сотен строк со временем прохождения 5-10 мин, при такой длине отдельного тестового сценария он очень часто не доходит до конца по причине ложного фейла. Сейчас разделили тесты на более короткие и стабильные сценарии, используем failFast, чтобы время прогона получалось приемлемым (тест, упавший в середине, не будет пытаться выполнить каждый следующий шаг и дожидаться его падения таймаутом). Кроме того, избавились от избыточных проверок: следим за тем, чтобы конкретная фича была работоспособна в целом, но не пытаемся проверять ее во всех возможных вариациях.
Aвтотесты разделены по приоритетам. Небольшой набор самых приоритетных – User acceptance test (UAT) – запускается каждый час по таймеру на проде, после деплоя основных проектов и при тестировании задач на тестовых стендах.
На стендах процесс выглядит так: разработчик переводит задачу в тестирование, QA деплоит ее к себе на стенд и запускает тесты – и UAT, и regression. В UAT у нас около 150 кейсов, regression – около 700 тестов, он постоянно дополняется. Большинство кейсов, относящихся к важным и критичным, этот сьют покрывает примерно на 80% и запускается на каждой итерации.
Десять лайфхаков
Явно указываем роль экземпляра браузера. Специфика тестов Vimbox в том, что в подавляющем большинстве случаев используются два, а то и больше экземпляра браузера, поскольку в уроке есть как минимум две стороны – учитель и студент. Раньше была проблема: экземпляр браузера обозначался номером, подразумевалось, что всем понятно, что
browser1– это преподаватель, аbrowser2и далее – студенты. Но это не везде так, случалось, что первым был браузер студента. Кроме того, бывают тесты, где сами студенты отличаются – например, нам надо убедиться, что нельзя случайно залезть в чужой урок. Чтобы всем было понятно, какой пользователь в каком экземпляре браузера, стали явно указывать роль в его названии:teacher.browser,student.browser,wrongStudent.browserи т.д. Получили более читабельные сценарии тестов.
Используем стрелочные функции:
() =>, а неfunction(). Во-первых, такая запись короче. Во-вторых, более современный синтаксис, мы стараемся уходить от архаики. В-третьих, стрелочные функции позволяют избегать проблем с указателемthisиз JavaScript. Стрелочная функция не создает своей лексической области видимости, поэтому в ней можно обращаться к определенному снаружиthis. Избавились от классического костыляself=this.
Применяем шаблонные строки вместо конкатенаций с плюсами: `Student ${studentName}`, а не "Student"+studentName. Стараемся применять шаблонные строки вместо конкатенаций с плюсами.
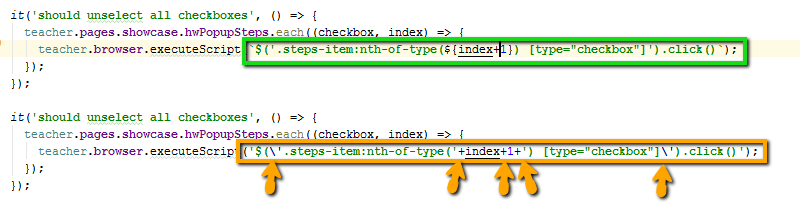
Это современный синтаксис, получается более читабельно, внутри строки можно использовать оба типа кавычек (одинарные и двойные) и ни один из них не экранировать.
Используем TypeScript. В основном ради более адекватных подсказок среды разработки и нормальной навигации по коду. Теперь в большинстве случаев вместо нескольких подсказок возможен прямой переход к методу/полю. При этом переход на TypeScript не потребовал большого количества рефакторинга одномоментно: для начала можно просто сменить расширения файлов с .js на .ts, проект остается работоспособным. Затем постепенно меняем синтаксис
requireнаImport, навигация улучшается.
Разбиваем большие Page Objects на подклассы для облегчения поддержки таких объектов. Самый крупный наш Page Object урока доходил до четырех тысяч строк кода, его было тяжело листать, вспоминать, что заведено, что не заведено. Теперь самый длинный код – около 1300 строк. Можно сказать, что тем самым мы избавились от антипаттерна large class. Кроме того, удалили лишние комментарии и поработали над удобством и понятностью названий методов: в большинстве случаев, если метод назван в соответствии с понятной всем конвенцией, комментарий, поясняющий его работу, просто не нужен.
Выполняем UAT параллельно в несколько потоков, чтобы облегчить работу с UAT на проде. Дело в том, что у нас такой тест запускается раз в час и в один поток бежит 15 минут. Если в нем случится какой-то фейл, он перезапустится и в итоге будет работать полчаса. Во время деплоя это может стать проблемой, потому что задерживается очередь. Результат применения параллели – 2-3 минуты на UAT (или 6 с перезапуском). Быстрее движется очередь, быстрее поступает информация о проблеме или о том, что фейл оказался ложным.
Регулярно запускаем UAT и regression на тестовых стендах. У каждого нашего мануального тестировщика есть свой сервер. Раньше мы гоняли тесты regression на проде уже после того, как мануальный тестировщик нашел значительную часть багов – по сути, просто проверяли за ним. Теперь мы запускаем автотесты на каждой итерации ручного тестирования задачи, чем, во-первых, облегчаем работу мануальному тестировщику (ему не надо протыкивать то, что находится автоматически), а во-вторых, сокращаем цикл обратной связи. Если разработчик что-то сломал, он узнает об этом через полчаса после выкатки задачи, а не на следующий день. Плюс к тому на тестовом стенде можно делать множество вещей, нежелательных на продакшне: менять номер версии продукта, удалять/добавлять тестовый контент, безбоязненно править БД для подготовки тестовой ситуации и т.д.
Удаляем пустые файлы. Мы стараемся поддерживать соответствие между структурой директорий в автотестах и в Testrail. Но при этом в какой-то момент мы столкнулись с проблемой – в Testrail имеется огромное количество кейсов с низким приоритетом (всего около 9000+ кейсов), т.к. он используется в качестве базы знаний по проекту. При этом автотестами покрыты всего лишь около тысячи самых важных кейсов. Если добиваться идеального соответствия, то получаем большое количество неиспользуемых файлов и директорий. Это усложняет навигацию по проекту и ухудшает понимание того, что же реально проверяется. В итоге оставили только нужные папки и файлы, остальное удалили.
Фиксируем найденные баги. Главная задача автотестов – не найти баги, а быстро убедиться, что их нет, поэтому что-то обнаруживается довольно редко. Фиксация решает две задачи: во-первых, мы видим статистику, где чаще всего остаются проблемы и какие, и во-вторых, избавляемся от ощущения, что что-то делаем не так. Когда тесты ничего не находят, возникает вопрос: правильно ли мы все делаем, может, от наших тестов нет толку? А тут есть табличка, показывающая, что когда смогли отловить: более 60 багов за год. При этом стал очевидным смысл запуска тестов как на проде, так и на тестовых серверах. Частый запуск на проде – каждый час – помогает отлавливать инфраструктурные проблемы (недоступен внешний сервис, лег наш сервер), запуск перед ручным тестированием засекает поломки, привнесенные новым кодом.
Внедрили атрибуты data-qa-id, например,
[data-qa-id="btn-login"]. Цель: более стабильные селекторы. Мы договорились с командой разработки, что при изменении реализации каких-то элементов, если они видят там атрибутdata-qa-id, то понимают, что это для автотестов, не меняют и аккуратно переносят. У этого атрибута логически понятное название, само по себе способное подсказать, за что отвечает элемент. Кроме того, мы не зависим от конкретной реализации элемента – какой на нем висит обычный id, какой на нем висит класс, тэг, диф, ссылка. Стало спокойнее: селекторы реже ломаются, в некоторых случаях этим атрибутом можно выводить дополнительную информацию. Например, нужно название шага в уроке. Если обратиться к названию шага через XPath, селектор может получиться длинным, многоуровневым и малочитабельным, а если поработать с html-шаблоном в коде Ангуляра, можно это же название вывести в короткий понятный атрибут, минуя длинный XPath.
Делитесь своими лайфхаками и мыслями в комментах!