
Задача: аппаратное декодирование и запись до 4-х кадров в оперативную память для последующей параллельной обработки (четырьмя ядрами процессора) с IP-камеры RTSP h.264. Обработанные кадры отображаю с помощью функций WinAPI. Как итог мы получим быстродействующую систему для компьютерной обработки RTSP-потока в параллельном режиме. Далее можно подключать алгоритмы Компьютерного зрения для обработки кадров Real Time.

Вступление
Зачем нужно аппаратное декодирование? Вы хотите слабым и дешевым процессором декодировать видео реал-тайм или хотите максимально разгрузить процессор, тогда пора знакомиться с аппаратным декодированием.
DirectX Video Acceleration (DXVA) — это API для использования аппаратного ускорения для ускорения обработки видео силами графических процессоров (GPU). DXVA 2.0 позволяет перенаправлять на GPU большее количество операций, включая захват видео и операции обработки видео.
После написания предыдущей статьи мне было задано не мало вопросов: «почему использован именно FFmpeg?» Начну с проблематики. Основная сложность аппаратного декодирования состоит в записи раскодированного кадра в ОЗУ. Для Full HD это 1920 х 1080 х 3 = 6 220 800 байт. Даже с учетом того что кадр хранится в формате NV12 – это тоже немало 1920 x 1080 x 1.5 = 3 110 400 байт. Перезаписывать 75 Мбайт в секунду серьезная задача для любого процессора. Для решения этой задачи Intel добавила команды SSE 4, которые позволяют переписывать данные без участия процессора. К сожалению, не во всех библиотеках это реализовано. Мной были опробованы следующие библиотеки:
- FFmpeg
- VLC
- OpenCV
VLC – работает с IP-камерами через аппаратное декодирование (очень низкая загрузка процессора), примитивный проигрыватель потока RTSP можно построить буквально в 10 строк кода, но получение декодированных кадров в оперативную память занимает слишком много процессорного времени.
OpenCV – для работы с потоком RTSP использует FFmpeg, поэтому решено работать без посредников, т.е. использовать библиотеку FFmpeg. К тому же FFmpeg, который установлен по умолчанию, в OpenCV собран без аппаратного декодирования.
FFmpeg – показала хорошие, на мой взгляд результаты, работает стабильно. Единственный недостаток не реализована работа с WEB-камерами для версии X86 (X64 вроде позволяет работать) в Windows.
Аппаратное декодирование видео — это просто
На самом деле аппаратное декодирование с помощью библиотеки FFmpeg — не сложнее программного. Настройки проекта такие же, как и для программной реализации, блок-схема осталась без изменений.
Вывести на экран список поддерживаемых FFmpeg методов аппаратного декодирования можно
fprintf(stderr, " %s", av_hwdevice_get_type_name(type));Первое, что нам нужно сделать — это сообщить FFmpeg с помощью какого аппаратного декодера Вы хотите декодировать видео. В моем случае Windows10 + Intel Atom Z8350 оставляют только DXVA2:
type = av_hwdevice_find_type_by_name("dxva2");Вы же в качестве аппаратного декодера можете выбрать CUDA, D3D11VA, QSV или VAAPI (только Linux). Соответственно у вас должно быть данное аппаратное решение и FFmpeg должен быть собран с его поддержкой.
Открываем видеопоток:
avformat_open_input(&input_ctx, filename, NULL, NULL;Получаем информацию о видеопотоке:
av_find_best_stream(input_ctx, AVMEDIA_TYPE_VIDEO, -1, -1, &decoder, 0);Выделяем память:
frame = av_frame_alloc(); // здесь хранится декодированный файл вне ОЗУ
sw_frame = av_frame_alloc(); // Сюда мы перепишем декодированный файл в ОЗУДанная функция переписывает декодированный файл в ОЗУ:
av_hwframe_transfer_data(sw_frame, frame, 0);Немного о формате NV12
Итак, мы получили кадр в структуру sw_frame. Полученный кадр хранится в формате NV12. Данный формат был придуман Microsoft. Он позволяет хранить информацию о пикселе в 12 бит. Где 8 бит интенсивность, а 4 битами описывается цветность (вернее цветность сразу описывается для 4-х рядом стоящих пикселей 2х2). Причем, sw_frame.data[0] – хранится интенсивность, а в sw_frame.data[1] – хранится цветность. Для перевода из NV-12 в RGB можете воспользоваться следующей функцией:
void SaveFrame(uint8_t * f1, uint8_t * f2, int iFrame) {
FILE *pFile;
char szFilename[32];
int x, i, j;
// char buff[1920 * 1080 * 3];
uint8_t *buff = new uint8_t(1920*3*2);
int u=0, v=0, y=0;
// Open file
sprintf(szFilename, "frame%d.ppm", iFrame);
pFile = fopen(szFilename, "wb");
if (pFile == NULL)
return;
// Записуем заголовок файла
fprintf(pFile, "P6\n%d %d\n255\n", 1920, 1080);
for (j = 0; j < 1080 / 2; j++) {
for (i = 0; i < 1920; i +=2) {
// 1 точка rgb
y = *(f1 + j * 1920 * 2 + i);
v = *(f2 + j * 1920 + i) - 128;
u = *(f2 + j * 1920 + i + 1) - 128;
x = round(y + 1.370705 * v);
if (x < 0) x = 0;
if (x > 255) x = 255;
// if (j > 34) printf("%i, ",(j * 1920 * 2 + i) * 3);
buff[i * 3 + 2] = x;
x = round(y - 0.698001 * v - 0.337633 * u);
if (x < 0) x = 0;
if (x > 255) x = 255;
buff[i * 3 + 1] = x;
x = round(y + 1.732446 * u);
if (x < 0) x = 0;
if (x > 255) x = 255;
buff[i * 3] = x;
// 2 точка rgb
y = *(f1 + j * 1920 * 2 + i + 1);
x = y + 1.370705 * v;
if (x < 0) x = 0;
if (x > 255) x = 255;
buff[i * 3 + 5] = x;
x = y - 0.698001 * v - 0.337633 * u;
if (x < 0) x = 0;
if (x > 255) x = 255;
buff[i * 3 + 4] = x;
x = y + 1.732446 * u;
if (x < 0) x = 0;
if (x > 255) x = 255;
buff[i * 3 + 3] = x;
// 3 точка rgb
y = *(f1 + j * 1920 * 2 + 1920 + i);
x = y + 1.370705 * v;
if (x < 0) x = 0;
if (x > 255) x = 255;
buff[(1920 + i) * 3 + 2] = x;
x = y - 0.698001 * v - 0.337633 * u;
if (x < 0) x = 0;
if (x > 255) x = 255;
buff[(1920 + i) * 3 + 1] = x;
x = y + 1.732446 * u;
if (x < 0) x = 0;
if (x > 255) x = 255;
buff[(1920 + i) * 3 + 0] = x;
// 4 точка rgb
y = *(f1 + j * 1920 * 2 + 1920 + i + 1);
x = y + 1.370705 * v;
if (x < 0) x = 0;
if (x > 255) x = 255;
buff[(1920 + i) * 3 + 5] = x;
x = y - 0.698001 * v - 0.337633 * u;
if (x < 0) x = 0;
if (x > 255) x = 255;
buff[(1920 + i) * 3 + 4] = x;
x = y + 1.732446 * u;
if (x < 0) x = 0;
if (x > 255) x = 255;
buff[(1920 + i) * 3 + 3] = x;
// printf("%i, ", i);
} // for i
fwrite(buff, 1, 1920 * 3 * 2, pFile);
printf("\n %i\n", j);
} // for j
// printf("Save4\n");
// Write pixel data
// fwrite(buff, 1, 1920*1080*3, pFile);
// Close file
printf("close\n");
fclose(pFile);
printf("exit\n");
delete buff;
// return;
}
Хотя работа с NV12 позволяет ускорить выполнение таких процедур, как размывка, Retinex и получение изображения в оттенках серого (просто отбросив цветность). В моих задачах я не перевожу формат NV12 в RGB, так как это занимает дополнительное время.
И так мы научились аппаратно декодировать видеофайлы и выводить их в окно. Познакомились в форматом NV12 и как его преобразовывать в привычный RGB.
Dll аппаратного декодирования
Кадры FFmpeg выдает через 40 мс (при 25 кадрах в секунду). Как правило, обработка кадра Full HD занимает значительно больше времени. Для этого требуется организовать многопоточность, для максимальной загрузки всех 4-х ядер процессора. Я на практике один раз запускаю 6 потоков и больше их не снимаю, что значительно упрощает работу и увеличивает надежность работы программы. Схема работы приведена на рис. 1
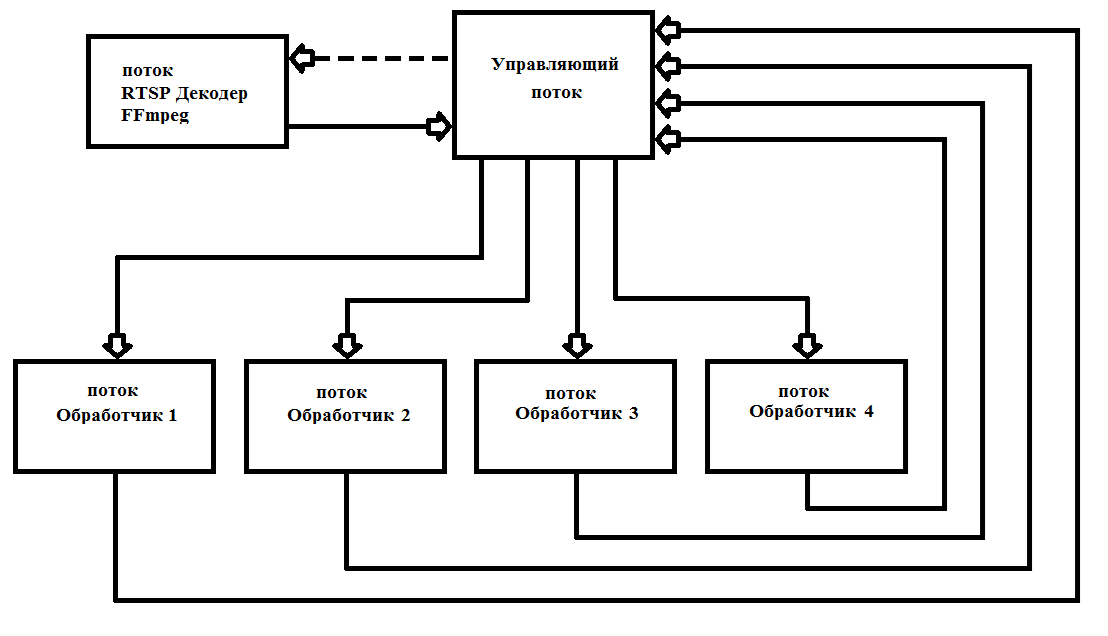
рис.1 Схема построения многопоточной программы с FFmpeg
Я написал свой декодер в виде *.dll (FFmpegD.DLL) для включения в свои проекты. Это позволяет сократить код-проекта, что повышает понимание кода и включать в любые языки программирования, вплоть до Ассемблера (проверено:) ). С помощью нее мы напишем свой проигрыватель RTSP-потока с IP-камеры.
Для начала работы с DLL нужно передать указатель массив int[13], HANDLE события поступления нового кадра, HANDLE начала обработки нового пакета данных с камеры и массив char адрес камеры.
Структура массива дана в таблице 1.
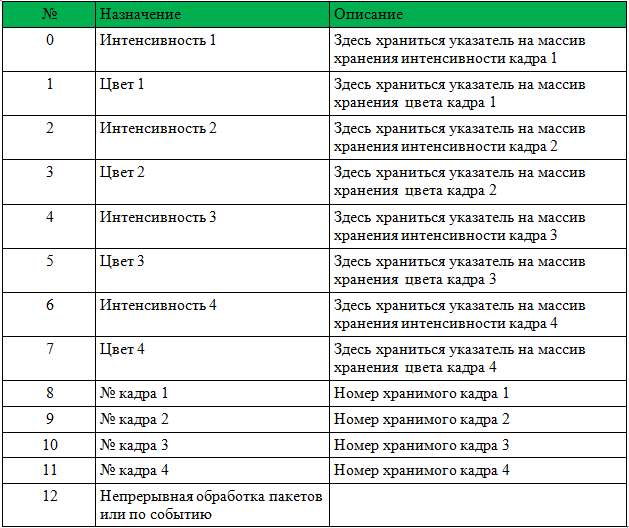
Перед вызовом необходимо обнулить номера кадров 1-4.
DLL выполнит все необходимые действия по инициализации FFmpeg и будет записывать указатели и номера кадров. После установит событие «Поступление нового кадра». Нужно только обрабатывать поступающие кадры и вместо номера кадра записывать 0 (это значит кадр обработан и больше не используется).
Ниже Вы найдете пример проигрывателя с исходным кодом. За основу взят пример ShowDib3 Charles Petzold.
> Архив с проектом
> Архив FFmpegD.dll
ИТОГ: аппаратный детектор движения FFmpeg даже на Intel Atom Z8350 декодирует h264 Full HD в реальном времени с загрузкой процессора до 20% с подключенный детектором движения.
Пример работы детектора движения на Intel ATOM Z8350. Первые 30 сек идет подсчет фона. После работает детектор движения по методу вычитания фона.
P.S. Так же можете декодировать и видеофайлы (сжатые h.264)!!!
Ссылки:
Комментарии (29)

al_sh
31.07.2019 16:41+2почему бы Вам просто не скопипастить сюда ffmpeg_hw из примеров ffmpega? А еще лучше ffplay, он хоть YUV, через SDLные шейдеры рисует, а не терзает старичка GDI
2expres Автор
31.07.2019 16:56+1ffmpeg_hw и был взят за основу. Но у меня другая задача, мне нужно не просто отобразить кадры на экране, а держать в памяти до 4-х кадров для их обработки. Если бы у меня был 24-ядерный процессор, я бы держал 24 кадра в памяти, и для обработки одного кадра у меня было бы 40мс х 24 = 960 мс. А сейчас мне необходимо обработать 1 кадр за 160 мс.
Отображение кадра у меня это не основное, кстати, а чем плох GDI? Кроме того, что SDL кроссплатформенный, а GDI только под Windows.al_sh
31.07.2019 17:14тем, что SDL работает повер опенгл со всеми вытекающими(YUV->RGB, например конвертится в шейдере, бесплатный ресайз, кроп и т.д) и диффкцитные такты ЦП не расходуются, причем в текстурки льется по DMA. Проблем держать в памяти, хоть 44 кадра, тоже не вижу
2expres Автор
01.08.2019 15:41А еще лучше ffplay
А как Вы побороли задержки по воспроизведению rtsp в ffplay? Я пробовал только вначале на Pentium'е было секунды 3, что на мой взгляд не приемлемо.al_sh
01.08.2019 15:55о каких задержках идет речь? Если речь о задержке в начале, то ясно, что ничего не будет, пока не придет очередной I-фрэйм, если Вы о low latency, то что-то вроде -nocache -probesize и -analyzeduration, точно не помню. И конечно на источнике настроить h264 профиль без B-фреймов и RTSP поверх UDP. У меня с хайвижина 1980p@25 на малине 0.2 сек, кодек mmal льет в текстурку через EGL_KHR_image, в шейдере уив->ргб. Использую, как дверной глазок
2expres Автор
31.07.2019 17:51(YUV->RGB, например конвертится в шейдере, бесплатный ресайз, кроп и т.д)
Мне это не нужно. Цель не проигрыватель (их много, можно и VLC использовать, он еще меньше загружает ЦП, чем FFmpeg). Мне нужно получить кадр в памяти, запустить на одно из ядер для обработки алгоритмами компьютерного зрения, согласовать последовательность кадров (так как кадры могут обрабатываться за разное время) и результат отобразить на экране.
RabraBabr
01.08.2019 11:01Какой «чудный» код. У вас память течет.
2expres Автор
01.08.2019 12:15В коде, за спойлером (C++ перевод из NV12 в RGB) действительно не освобождался buff, чисто случайно вышло при удалении комментария. И я практически не применяю перевода NV12 в RGB. Этот пример демонстрирует работу с NV12 напрямую.
В кодах и dll утечек памяти нет, проверено на продолжительной работе.
yurror
01.08.2019 12:32uint8_t *buff = new uint8_t(1920*3*2); ... pFile = fopen(szFilename, "wb"); if (pFile == NULL) return; // вот тут она и потечет
Провререно. У вас просто временной интервал теста маловат.
Место на диске кончится, или сетевой диск отвалится, злой пользователь или антивирус права доступа поправит, и не откроется у вас это файл гарантированно.
Бонусом в коде еще слишком много всего прекрасного.
P.S. Скобки у new/delete точно правильные?
tangro
02.08.2019 11:35Суть не в том, что она течёт или не течёт, а в том, что код ужасен. Это уже не С, но ещё не С++. RAII, smart pointers, streams — вот это С++.
xaoc80
01.08.2019 12:39В состав ffmpeg входит библиотека swscale, которая позволяет конвертировать в разные цветовые пространства. Все функции там оптимизированы с использованием SSE
2expres Автор
01.08.2019 12:44Про swscale я писал в предыдущей статье, там есть пример. Но чем плохо работать с NV12 напрямую? Я делаю так для минимизации загрузки процессора.
xaoc80
01.08.2019 12:47+1Да в общем-то ни чем не плохо. Я писал нечто похожее для проекта распознавания лиц и там нужен был BGR, так как использовался opencv и каскады хаара.
xaoc80
01.08.2019 12:50avformat_open_input(&input_ctx, filename, NULL, NULL
Стоит добавить, что все функции ffmpeg API стоит проверять на возвращаемое значение и обрабатывать ошибки, так как в противном случае может вылезти сегфолт в самом неожиданном месте и вы долго будете искать почему так.
xaoc80
01.08.2019 12:52if (pFile == NULL)
return;
Возможно, здесь стоит возвращать код ошибки:
if (pFile == NULL)
return S_ERROR;
Так как вы не узнаете иначе про ошибку
xaoc80
01.08.2019 12:55fwrite(buff, 1, 1920 * 3 * 2, pFile);
Обратите внимание, что функция fwrite возвращает некоторое число, которое тоже надо обрабатывать, так как не всегда может получится записать ровно столько байт сколько задумано
xaoc80
01.08.2019 12:57char szFilename[32];
Такие вещи обычно именуются константой, хотя бы так: const int MAX_BUFF_SIZE = 32
Ну и 32 явно может не хватить для файла с длинным названием (например путь до него)
xaoc80
01.08.2019 13:01void SaveFrame(uint8_t * f1, uint8_t * f2, int iFrame)
f1, f2 не меняются в коде? Можно сделать их const это позволит избежать некоторых ошибок, тем более вы с памятью работаете
xaoc80
01.08.2019 13:02uint8_t *buff = new uint8_t(1920*3*2);
Так ли необходимо каждый раз буфер выделять?
Возможно, с точки зрения скорости, стоит выделить один раз и сделать его членом класса.
RomanArzumanyan
01.08.2019 13:48Перезаписывать 75 Мбайт в секунду серьезная задача для любого процессора
Пиковая пропускная способность планки памяти DDR4-1600 составляет 12.8 Гб/с
Память, как правило, работает в 2х-канальном режиме. Итого 25.6 Гб/с
Мобильные процессоры ARM 3-4 года назад выдавали 15-16 Гб/с на некоторых алгоритмах обработки изображений с 2х-канальной DDR4.
Вы ошиблись на 2 порядка.2expres Автор
01.08.2019 14:34Итого 25.6 Гб/с
Считаю 25.6/8=3.2 ГБайт в секунду. А зачем тогда нужен кеш 1,2 и 3 уровня???
P.S. https://habr.com/ru/company/otus/blog/343566/RomanArzumanyan
01.08.2019 14:51А зачем тогда нужен кеш 1,2 и 3 уровня???
Я надеюсь, вы сейчас не всерьёз это сказали. У кэшей совсем другое устройство на физическом и логическом уровне, а так же иные задержки доступа. Там другие политики согласованности данных (протоколы кэш-когерентности).
На самом деле, Н.264 — совсем несложный кодек, и даже одно ядро Atom в софтверном режиме спокойно понятет декодирование.
Извините за капитанский комментарий, но я бы на вашем месте начал со сборки последней версии ffmpeg из git master на свежем компиляторе, с оптимизациями. Затем проверил бы уровень загрузки ядер при (де)кодировании видео.
Вывод: программное декодирование потока RTSP Full HD H.264 занимает до двух ядер Intel ATOM Z8350 к тому же периодически происходит потеря пакетов, из-за чего часть кадров декодировано неправильно. Данный способ более применим для декодирования записанных видео файлов, т. к. не нужна работа в реальном масштабе времени.
Вот вывод из вашей прошлой статьи, но нет никакого анализа производительности. Для начала можно запустить ffmpeg под встроенным профилировщиком Visual Studio, посмотреть на hotspot'ы. Возможно, это не получится сделать на сборках zeranoe, если оттуда были вырезаны символы во время компиляции.
В целом подход, вы начинаете заниматься оптимизацией проекта, не зная, что именно тормозит вашу текущую имплементацию.
2expres Автор
01.08.2019 15:16Я надеюсь, вы сейчас не всерьёз это сказали.
Нет, очень серьезно. Я занимаюсь обработкой в Реал-Тайм. Работа с основной памяти занимает 100-150 тактов машинного времени (я же привел ссылку https://habr.com/ru/company/otus/blog/343566/). А по вашему на тактовой частоте процессора могу считывать и записывать 1 байт информации в основную память? Можете привести пример кода перезаписи 100 МБайт за 31*2 = 62 мс?RomanArzumanyan
02.08.2019 13:05А по вашему на тактовой частоте процессора могу считывать и записывать 1 байт информации в основную память? Можете привести пример кода перезаписи 100 МБайт за 31*2 = 62 мс?
Не понял вашу мысль. Сильно упрощённо, процесс чтения из памяти происходит так:
У процессора есть инструкция чтения из памяти. Грубо говоря, ReadWord. Принимает указатель, кладёт содержимое памяти в регистр.
Есть контроллер DMA, который:
- принимает череду таких команд ReadWord
- преобразует их в набор запросов на чтение согласно спеки интерфейса шины памяти
При этом используются оптимизационные техники, такие как address coalescing (множество мелких чтений преобразуются в один длинных запрос DMA) и прочие.
Этот процесс, как правило, асинхронный (пока приходят новые данные, процессор делает вычисления над тем, что уже прочёл). Такая техника (latency hiding) лежит в основе высокой производительности GPU, например. Если процесс асинхронный, то частота процессора влияет только на то, как много запросов в единицу времени он генерирует.
Таким образом, процесс чтения и записи в память можно рассматривать как схему «производитель — потребитель», где производителем является процессор (генерирует запросы ReadWord), а потребителем — контроллер памяти, который эти запросы читает, оптимизирует и выполняет.
В реальной жизни всё сложнее, контроллеры DMA могут выполнять много всякой разной работы — например, транспонировать маленькие матрицы на лету, чтобы процессор читал столбцы кусочков изображений в векторные регистры. Могут преобразовывать цветовые пространства и ещё много чего.
Можете привести пример кода перезаписи 100 МБайт за 31*2 = 62 мс?
#include <iostream> #include <algorithm> #include <chrono> #include <vector> using namespace std; using namespace chrono; // 1024 * 1024 elements; static const size_t numElems = 1048576UL; int main() { vector<int> src(numElems), dst(numElems); vector<double> bandwidth; const size_t vectorSize = src.size() * sizeof(src.front()); for (int numLaps = 0; numLaps < 1024; numLaps++) { void* const source = src.data(); void* destination = dst.data(); auto start = system_clock::now(); memcpy(destination, source, vectorSize); auto end = system_clock::now(); auto time = duration_cast<microseconds>(end - start).count(); auto bw = double(vectorSize) / double(time); cout << bw << " megabytes / s" << endl; bandwidth.push_back(bw); } double acc = 0; for (auto bw : bandwidth) { acc += bw; } acc = acc / bandwidth.size(); cout << "Avg bandwidth: " << acc << " megabytes / s" << endl; return 0; }
Выдаёт чуть меньше 7 Гбайт/с на моей машине. Это примерно те 75Мб/с, умноженные на 100, о которых я говорил в первом комментарии. Машина вот такая: VS 2019, Core i7-7770, DDR4 (не знаю частоту, скорее всего 2133). У вас на Atom'е будет меньше. Но не на порядок.
2expres Автор
02.08.2019 19:17Спасибо, за информацию по перезаписи из оперативной памяти в оперативную память.
Но декодированный кадр после DXVA2 я получаю в uncacheable speculative write combining (USWC). Память USWC очень медленно читается (раз в 20 медленней). ATOM с этой перезаписью плохо справляется (проверено на VLC). Для ускорения используются инструкции SSE4, как написано в статье.
dobrobelko
Быстро аппаратно декодировать H.264 на GPU чтобы потом попиксельно конвертировать NV12 в RGB на хосте. Вместо того же GPU, который создан для этого. Ладно не привели CUDA или OpenCL кернел, хотя бы упомянули об этом, или о векторизации на хосте.
2expres Автор
1. А зачем переводить NV12 в RGB? В статье я написал почему я этого не делаю, хотя такая возможность имеется.
2. Я пишу на ATOM Z8350, какое там CUDA?
3. На OpenCL можно перевести в RGB, но какой в этом смысл вместо 3 МБайт(NV12), нужно переписать 6 МБайт(RGB)?
dobrobelko
1. Для вывода на экран.
2. CUDA или OpenCL, внимательно читаете?
3. Приведенный пример конвертации мягко говоря неудачный, вам было на это указано.