
Введение
Двухфакторная аутентификация сегодня повсюду. Благодаря ей, чтобы украсть аккаунт, недостаточно одного лишь пароля. И хотя ее наличие не гарантирует, что ваш аккаунт не уведут, чтобы ее обойти, потребуется более сложная и многоуровневая атака. Как известно, чем сложнее что-либо в этом мире, тем больше вероятность, что работать оно не будет.
Уверен, все, кто читают эту статью, хотя бы раз использовали двухфакторную аутентификацию (далее — 2FA, уж больное длинное словосочетание) в своей жизни. Сегодня я приглашаю вас разобраться, как устроена эта технология, ежедневно защищающая бесчисленное количество аккаунтов.
Но для начала, можете взглянуть на демо того, чем мы сегодня займемся.
Основы
Первое, что стоит упомянуть про одноразовые пароли, — это то, что они бывают двух типов: HOTP и TOTP. А именно, HMAC-based One Time Password и Time-based OTP. TOTP — это лишь надстройка над HOTP, поэтому сначала поговорим о более простом алгоритме.
HOTP описан спецификацией RFC4226. Она небольшая, всего 35 страниц, и содержит все необходимое: формальное описание, пример реализации и тестовые данные. Давайте рассмотрим основные понятия.
Прежде всего, что такое HMAC? HMAC расшифровывается как Hash-based Message Authentication Code, или по-русски "код аутентификации сообщений, использующий хэш-функции". MAC — это механизм, позволяющий верифицировать отправителя сообщения. Алгоритм MAC генерирует MAC-тэг, используя секретный ключ, известный только отправителю и получателю. Получив сообщение, вы можете сгенерировать MAC-тэг самостоятельно и сравнить два тэга. Если они совпадают — все в порядке, вмешательства в процесс коммуникации не было. В качестве бонуса этим же способом можно проверить, не повредилось ли сообщение при передаче. Конечно, отличить вмешательство от повреждения не выйдет, но достаточно самого факта повреждения информации.

Что же такое хэш? Хэш — это результат применения к сообщению Хэш-функции. Хэш-функции берут ваши данные и делают из него строку фиксированной длины. Хороший пример — всем известная функция MD5, которая широко использовалась для проверки целостности файлов.
Сам по себе MAC — это не конкретный алгоритм, а лишь общий термин. HMAC в свою очередь — уже конкретная реализация. Если точнее, то HMAC-X, где X — одна из криптографических хэш-функций. HMAC принимает два аргумента: секретный ключ и сообщение, смешивает их определенным образом, применяет выбранную хэш-функцию два раза и возвращает MAC-тэг.
Если вы сейчас думаете про себя, какое отношение все это имеет к одноразовым паролям — не волнуйтесь, мы почти дошли до самого главного.
Согласно спецификации, HOTP вычисляется на основе двух значений:
- K — секретный ключ, который знают клиент и сервер. Он должен быть минимум 128 бит длиной, а лучше 160, и создается когда, вы настраиваете 2FA.
- C — счетчик.
Счетчик — это 8-байтовое значение, синхронизированное между клиентом и сервером. Оно обновляется, по мере того как вы генерируете новые пароли. В схеме HOTP счетчик на стороне клиента инкрементируется каждый раз, когда вы генерируете новый пароль. На стороне сервера — каждый раз, когда пароль успешно проходит валидацию. Так как можно сгенерировать пароль, но не воспользоваться им, сервер позволяет значению счетчика немного забегать вперед в пределах установленного окна. Однако если вы слишком заигрались с генератором паролей в схеме HOTP, придется синхронизировать его повторно.
Итак. Как вы, наверное, заметили, HMAC тоже принимает два аргумента. RFC4226 определяет функцию генерации HOTP следующим образом:
HOTP(K,C) = Truncate(HMAC-SHA-1(K,C))Вполне ожидаемо, K используется в качестве секретного ключа. Счетчик, в свою очередь, используется в качестве сообщения. После того, как HMAC функция сгенерирует MAC-тэг, загадочная функция Truncate вытаскивает из результата уже знакомый нам одноразовый пароль, который вы видите в своем приложении-генераторе или на токене.
Давайте начнем писать код и разберемся с остальным по ходу дела.
План реализации
Чтобы заполучить одноразовые пароли, нам понадобится выполнить следующие шаги.

- Сгенерировать HMAC-SHA1 хэш из параметров K и C. Это будет 20-байтовая строка.
- Вытащить 4 байта из этой строки определенным образом.
- Сконвертировать вытащенное значение в число и поделить его на 10^n, где n = количество цифр в одноразовом пароле (обычно n = 6). Ну и, наконец, взять остаток от этого деления. Это и будет наш пароль.
Звучит не слишком сложно, правда? Начнем с генерации хэша.
Генерируем HMAC-SHA1
Это, пожалуй, самый простой из перечисленных выше шагов. Мы не будем пытаться воссоздать алгоритм самостоятельно (никогда не надо самостоятельно пытаться реализовать что-то из криптографии). Вместо этого мы воспользуемся Web Crypto API. Небольшая проблема заключается в том, что это API по спецификации доступно только под Secure Context (HTTPS). Для нас это чревато тем, что мы не сможем пользоваться им, не настроив HTTPS на сервере разработки. Немного истории и дискуссии на тему того, насколько это правильное решение, вы можете найти здесь.
К счастью, в Firefox вы можете использовать Web Crypto в незащищенном контексте, и изобретать колесо или приплетать сторонние библиотеки не придется. Поэтому для целей разработки демо предлагаю воспользоваться FF.
Само по себе Crypto API определено в window.crypto.subtle. Если вас удивляет название, привожу цитату из спецификации:
API носит название SubtleCrypto как отражение того, что многие из алгоритмов имеют специфические требования к использованию. Только при соблюдении этих требований они сохраняют свою стойкость .Быстро пройдемся по методам, которые нам понадобятся. На заметку: все упомянутые здесь методы асинхронны и возвращают Promise.
Для начала нам понадобится метод importKey, поскольку мы будем использовать свой секретный ключ, а не генерировать его в браузере. importKey принимает 5 аргументов:
importKey(
format,
keyData,
algorithm,
extractable,
usages
);В нашем случае:
formatбудет'raw', т.е. ключ мы предоставим в виде байт-массиваArrayBuffer.keyData— это тот самый ArrayBuffer. Совсем скоро поговорим о том, как именно его генерировать.algorithm, согласно спецификации, будетHMAC-SHA1. Этот аргумент должен соответствовать формату HmacImportParams.extractableвыставим в false, поскольку планов экспортировать секретный ключ у нас нет- И, наконец, из всех
usagesнам понадобится только'sign'.
Наш секретный ключ будет длинной случайной строкой. В реальном мире это может быть последовательность байтов, которые могут быть непечатными, однако для удобства в этой статье мы будем рассматривать строку. Для конвертации ее в ArrayBuffer мы воспользуемся интерфейсом TextEncoder. С его помощью ключ подготавливается в две строчки кода:
const encoder = new TextEncoder('utf-8');
const secretBytes = encoder.encode(secret);Теперь соберем все вместе:
const Crypto = window.crypto.subtle;
const encoder = new TextEncoder('utf-8');
const secretBytes = encoder.encode(secret);
const key = await Crypto.importKey(
'raw',
secretBytes,
{ name: 'HMAC', hash: { name: 'SHA-1' } },
false,
['sign']
);Отлично! Криптографию заготовили. Теперь разберемся со счетчиком и, наконец, подпишем сообщение.
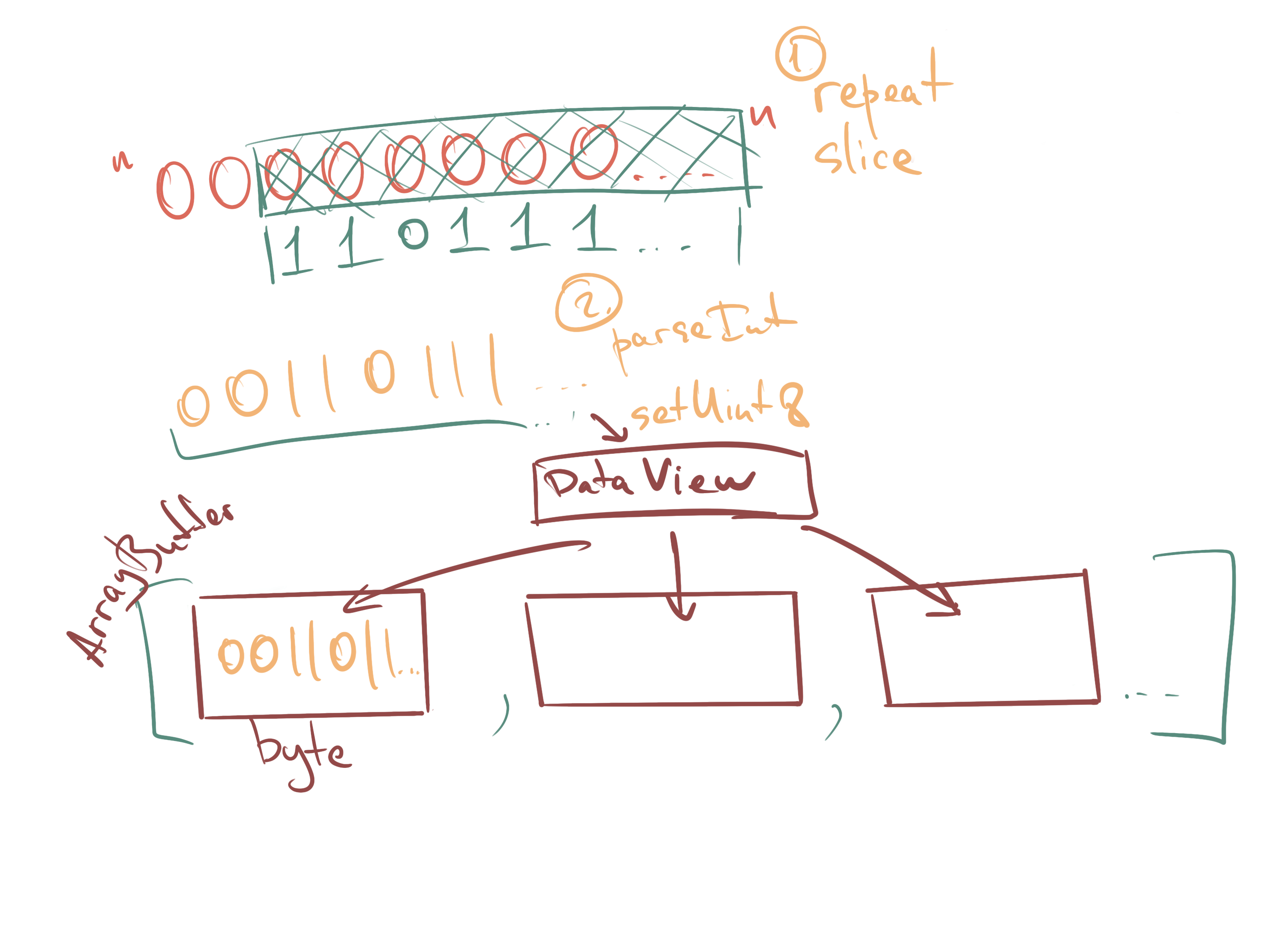
Согласно спецификации, наш счетчик должен иметь длину 8 байт. Мы будем работать с ним опять же, как с ArrayBuffer. Для перевода его в эту форму мы воспользуемся трюком, который обычно используется в JS, чтобы сохранить нули в старших разрядах числа. После этого каждый байт мы поместим в ArrayBuffer, используя DataView. Имейте в виду, что по спецификации для всех бинарных данных подразумевается формат big endian.
function padCounter(counter) {
const buffer = new ArrayBuffer(8);
const bView = new DataView(buffer);
const byteString = '0'.repeat(64); // 8 bytes
const bCounter = (byteString + counter.toString(2)).slice(-64);
for (let byte = 0; byte < 64; byte += 8) {
const byteValue = parseInt(bCounter.slice(byte, byte + 8), 2);
bView.setUint8(byte / 8, byteValue);
}
return buffer;
}
Наконец, подготовив ключ и счетчик, можно генерировать хэш! Для этого мы воспользуемся функцией sign из SubtleCrypto.
const counterArray = padCounter(counter);
const HS = await Crypto.sign('HMAC', key, counterArray);И на этом мы завершили первый шаг. На выходе мы получаем немного загадочно называющееся значение HS. И хотя это не самое лучшее название для переменной, именно так она (и некоторые последующие) называются в спецификации. Оставим эти названия, чтобы проще было сравнивать с ней код. Что дальше?
Step 2: Generate a 4-byte string (Dynamic Truncation)
Let Sbits = DT(HS) // DT, defined below,
// returns a 31-bit string
DT расшифровывается как Dynamic Truncation. И вот как она работает:
function DT(HS) {
// First we take the last byte of our generated HS and extract last 4 bits out of it.
// This will be our _offset_, a number between 0 and 15.
const offset = HS[19] & 0b1111;
// Next we take 4 bytes out of the HS, starting at the offset
const P = ((HS[offset] & 0x7f) << 24) | (HS[offset + 1] << 16) | (HS[offset + 2] << 8) | HS[offset + 3]
// Finally, convert it into a binary string representation
const pString = P.toString(2);
return pString;
}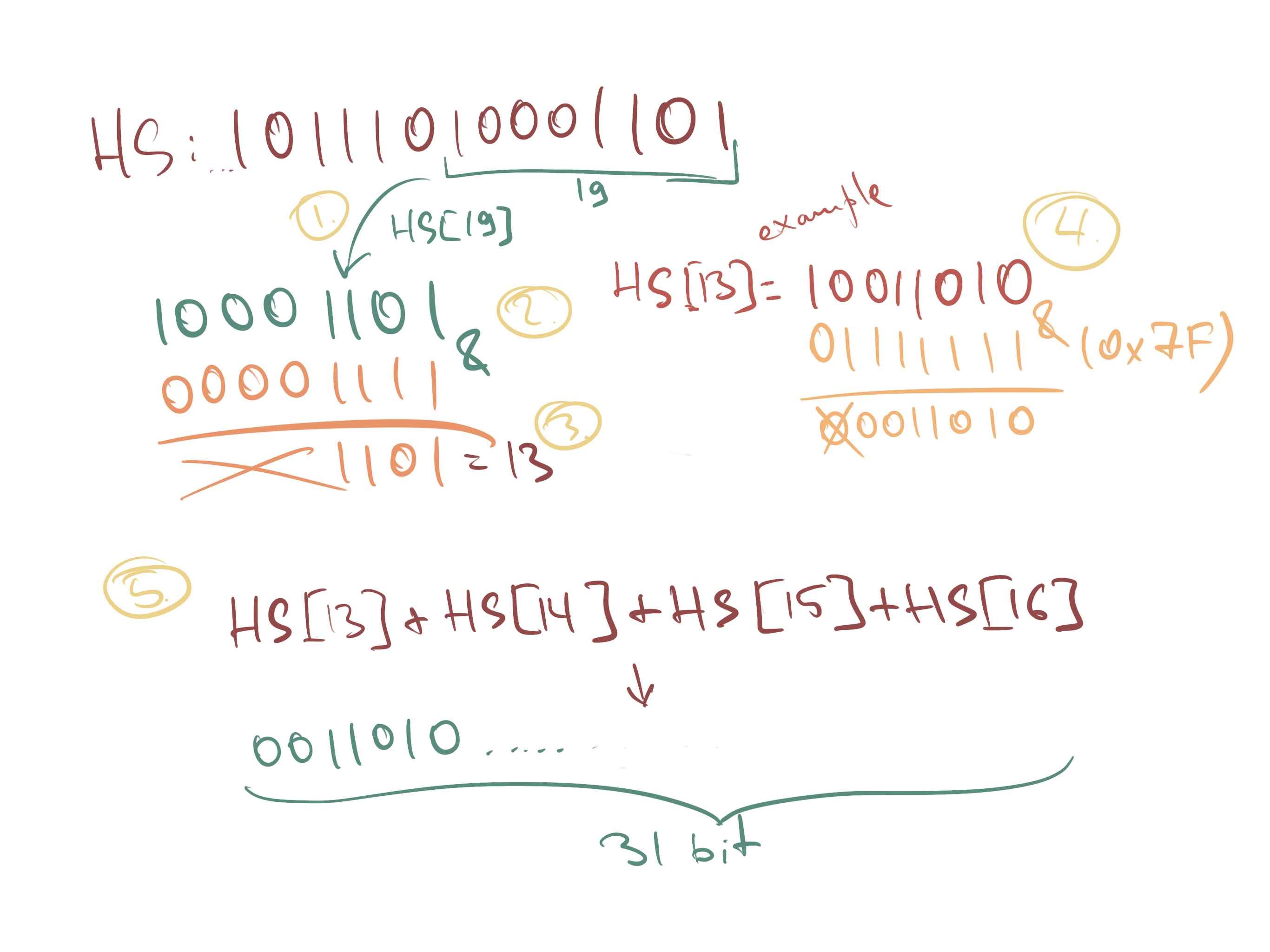
Заметьте, как мы применили побитовое И к первому байту HS. 0x7f в двоичной системе — 0b01111111, поэтому по сути мы просто отбрасываем первый бит. В JS на этом смысл данного выражения и заканчивается, но в других языках это также обеспечит отрезание знакового бита, чтобы убрать путаницу между положительными/отрицательными числами и представлять это число как беззнаковое.
Почти закончили! Осталось лишь сконвертировать полученное от DT значение в число и вперед, к третьему шагу.
function truncate(uKey) {
const Sbits = DT(uKey);
const Snum = parseInt(Sbits, 2);
return Snum;
}Третий шаг также довольно небольшой. Все, что нужно сделать, — это разделить получившееся число на 10 ** (количество цифр в пароле), после чего взять остаток от этого деления. Таким образом, мы отрезаем последние N цифр от этого числа. По спецификации наш код должен уметь вытаскивать минимум шестизначные пароли и потенциально 7 и 8-значные. Теоретически, раз это 31-битное число, мы могли бы вытащить и 9 знаков, но в реальности я лично никогда не видел больше 6 знаков. А вы?
Код для заключительной функции, которая объединяет все предыдущие, в таком случае будет выглядеть как-то так:
async function generateHOTP(secret, counter) {
const key = await generateKey(secret, counter);
const uKey = new Uint8Array(key);
const Snum = truncate(uKey);
// Make sure we keep leading zeroes
const padded = ('000000' + (Snum % (10 ** 6))).slice(-6);
return padded;
}Ура! Но как теперь проверить, что наш код верный?
Тестирование
Для того чтобы протестировать реализацию, воспользуемся примерами из RFC. Приложение D включает в себя тестовые значения для секретного ключа "12345678901234567890" и значений счетчика от 0 до 9. Также там есть подсчитанные хэши HMAC и промежуточные результаты функции Truncate. Довольно полезно для отладки всех шагов алгоритма. Вот небольшой пример этой таблицы (оставлены только счетчик и HOTP):
Count HOTP
0 755224
1 287082
2 359152
3 969429
...Если вы еще не смотрели демо, сейчас самое время. Можете повбивать в нем значения из RFC. И возвращайтесь, потому что мы приступаем к TOTP.
TOTP
Вот мы, наконец, и добрались до более современной части 2FA. Когда вы открываете свой генератор одноразовых паролей и видите маленький таймер, отсчитывающий, сколько еще будет валиден код, — это TOTP. В чем разница?
Time-based означает, что вместо статического значения, в качестве счетчика используется текущее время. Или, если точнее, "интервал" (time step). Или даже номер текущего интервала. Чтобы вычислить его, мы берем Unix-время (количество миллисекунд с полуночи 1 января 1970 года по UTC) и делим на окно валидности пароля (обычно 30 секунд). Сервер обычно допускает небольшие отклонения ввиду несовершенства синхронизации часов. Обычно на 1 интервал вперед и назад в зависимости от конфигурации.
Очевидно, это гораздо безопаснее, чем схема HOTP. В схеме, завязанной на время, валидный код меняется каждые 30 секунд, даже если он не был использован. В оригинальном алгоритме валидный пароль определен текущим значением счетчика на сервере + окном допуска. Если вы не аутентифицируетесь, пароль не будет изменен бесконечно долго. Больше про TOTP можно почитать в RFC6238.
Поскольку схема с использованием времени — это дополнение к оригинальному алгоритму, нам не потребуется вносить изменения к изначальной реализации. Мы воспользуемся requestAnimationFrame и будем на каждый фрейм проверять, до сих пор ли мы находимся внутри временного интервала. Если нет — генерируем новый счетчик и вычисляем HOTP заново. Опуская весь управляющий код, решение выглядит как-то так:
let stepWindow = 30 * 1000; // 30 seconds in ms
let lastTimeStep = 0;
const updateTOTPCounter = () => {
const timeSinceStep = Date.now() - lastTimeStep * stepWindow;
const timeLeft = Math.ceil(stepWindow - timeSinceStep);
if (timeLeft > 0) {
return requestAnimationFrame(updateTOTPCounter);
}
timeStep = getTOTPCounter();
lastTimeStep = timeStep;
<...update counter and regenerate...>
requestAnimationFrame(updateTOTPCounter);
}Последние штрихи — поддержка QR-кодов
Обычно, когда мы настраиваем 2FA, мы сканируем начальные параметры с QR-кода. Он содержит всю необходимую информацию: выбранную схему, секретный ключ, имя аккаунта, имя провайдера, количество цифр в пароле.
В предыдущей статье я рассказывал, как можно сканировать QR-коды прямо с экрана, используя API getDisplayMedia. На основе того материала я сделал маленькую библиотеку, которой мы сейчас и воспользуемся. Библиотека называется stream-display, и в дополнение к ней мы используем замечательный пакет jsQR.
Закодированная в QR-код ссылка имеет следующий формат:
otpauth://TYPE/LABEL?PARAMETERSНапример:
otpauth://totp/label?secret=oyu55d4q5kllrwhy4euqh3ouw7hebnhm5qsflfcqggczoafxu75lsagt&algorithm=SHA1&digits=6&period=30Я опущу код, который настраивает процесс запуска захвата экрана и распознавания, так как все это можно найти в документации. Вместо этого, вот как можно распарсить эту ссылку:
const setupFromQR = data => {
const url = new URL(data);
// drop the "//" and get TYPE and LABEL
const [scheme, label] = url.pathname.slice(2).split('/');
const params = new URLSearchParams(url.search);
const secret = params.get('secret');
let counter;
if (scheme === 'hotp') {
counter = params.get('counter');
} else {
stepWindow = parseInt(params.get('period'), 10) * 1000;
counter = getTOTPCounter();
}
}В реальном мире секретный ключ будет закодированной в base-32 (!) строкой, поскольку некоторые байты могут быть непечатными. Но для простоты демонстрации мы опустим этот момент. К сожалению, я не смог найти информации, почему именно base-32 или именно такой формат. По всей видимости, никакой официальной спецификации к этому формату URL не существует, а сам формат был придуман Google. Немного о нем вы можете почитать здесь
Для генерации тестовых QR-кодов рекомендую воспользоваться FreeOTP.
Заключение
И на этом все! Еще раз, не забывайте посмотреть демо. Там же есть ссылка на репозиторий с кодом, который за этим всем стоит.
Сегодня мы разобрали достаточно важную технологию, которой пользуемся на ежедневной основе. Надеюсь, вы узнали для себя что-то новое. Эта статья заняла гораздо больше времени, чем я думал. Однако довольно интересно превратить бумажную спецификацию в нечто работающее и такое знакомое.
До новых встреч!
Комментарии (10)

Focushift
09.08.2019 13:09Можно глупый вопрос?
Можно ли с этим апи обрабатывать/использовать персональные ключи выдаваемые АЦСК для подписывания документов в банках и тп?khovansky Автор
09.08.2019 17:37Честно говоря, затрудняюсь ответить. Но вы можете проверить используемые алгоритмы и поддерживаются ли они этим АПИ, и уже от этого думать дальше.
Focushift
09.08.2019 18:10Я подозреваю что мне нужно сначала прочитать сам ключ с паролем, и после того как получу расшифрованный ключ, я смогу его передать в АПИ.
Функции расшифровки ключей в этом АПИ же нет?

akdes
09.08.2019 15:27Спасибо, не ожидал столь глубокой информации, т.к. всегда пологал, что при зарпосе 2FA Токена, он генерируется (рандомом или хэш юзерных данных с таймстэмп) на бэйкенде, пишется в базу и паралельно отсылается клиенту (смс, сокет, long polling и т.д.), а опосля введённый код сравнивается со значением в базе.
Отсюда и удивление, от увиденной глубины.
Все ли 2FA так работают, как Вы описали?khovansky Автор
09.08.2019 17:35Думаю, что какие-то предки современной двухфакторки, особенно которые посылают код по почте или в смс (псевдо-2FA) работают на своих алгоритмах. В том числе, вероятно, просто генерируют число.
Однако те, которые можно забить в Google Authenticator или иные приложения/токены — точно подчиняются описанным алгоритмам.
EminH
10.08.2019 09:09+1Например один из предков, mobileOTP, использует md5 хеш строки составленной из: текущего времени, секрета и 4-значного пин-кода. Особенность mobileOTP в том что пинкод в приложении не хранится — пользователь вводит его каждый раз.
Protos
Привет. Очень понятно написано как мне кажется. А что насчёт применения HOTP для генерации OTP на основе динамических данных платежного поручения (номер счёта, сумма и т.д). К сожалению ЦБ обязывает это делать. Безопасно ли в HOTP К делать не общим, а каждый раз разным: К= динамические данные платежного поручения сконкатенированные со случайной величиной, при этом клиент ничего не должен знать о значении К на случай чтобы злоумышленник не мог угадывать следующие ОТП. Или тут лучше вообще что-то другое применять для генерации ОТР?
khovansky Автор
Привет! Спасибо. Суть стандартного алгоритма в том, что сервер и клиент знают секрет, который статичен, и знают значение счетчика. Благодаря этому они могут генерировать ключи, которые не покидают устройства и не могут быть нигде перехвачены. В схеме, где клиент не знает о K, я так понимаю сами пароли приходят к нему каким-то другим способом, и в таком случае теряются изначальные преимущества.
Можно было бы, наверное, сделать подобие оригинального алгоритма, если все же иметь пошаренный секрет, который перемешивается или склеивается с данными платежного поручения. Тогда формально они будут использованы, но основа алгоритма в целом остается. И использовать счетчик на основе времени.
Но это так, быстрая мысль.