
Предыдущая статья рассматривала архитектуру виртуализированной сети, underlay-overlay, путь пакета между VM и прочее.
Роман Горге вдохновился ею и решил написать обзорный выпуск о виртуализации вообще.
В данной статье мы затронем (или попытаемся затронуть) вопросы: а как собственно происходит виртуализация сетевых функций, как реализован backend основных продуктов, обеспечивающих запуск и управление VM, а также как работает виртуальный свитчинг (OVS и Linux bridge).
Тема виртуализации широка и глубока, объяснить все детали работы гипервизора невозможно (да и не нужно). Мы ограничимся минимальным набором знаний необходимым для понимания работы любого виртуализированного решения, не обязательно Telco.

История современных технологий виртуализации берет свое начало в 1999 году, когда молодая компания VMWare выпустила продукт под названием VMWare Workstation. Это был продукт обеспечивающий виртуализацию desktop/client приложений. Виртуализация серверной части пришла несколько позднее в виде продукта ESX Server, который в дальнейшем эволюционировал в ESXi (i означает integrated) — это тот самый продукт, который используется повсеместно как в IT так и в Telco как гипервизор серверных приложений.
На стороне Opensource два основных проекта принесли виртуализацию в Linux:
Сегодня VMWare ESXi и Linux QEMU/KVM это два основных гипервизора, которые доминируют на рынке. Они же являются представителями двух разных типов гипервизоров:
Обсуждение что лучше, а что хуже выходит за рамки данной статьи.

Производители железа также должны были сделать свою часть работы, дабы обеспечить приемлемую производительность.
Пожалуй, наиболее важной и самой широко используемой является технология Intel VT (Virtualization Technology) — набор расширений, разработанных Intel для своих x86 процессоров, которые используются для эффективной работы гипервизора (а в некоторых случаях необходимы, так, например, KVM не заработает без включенного VT-x и без него гипервизор вынужден заниматься чисто софтверной эмуляцией, без аппаратного ускорения).
Наиболее известны два из этих расширений — VT-x и VT-d. Первое важно для улучшения производительности CPU при виртуализации, так как обеспечивает аппаратную поддержку некоторых ее функций (с VT-x 99.9% Guest OS кода выполняется прямо на физическом процессоре, делая выходы для эмуляции только в самых необходимых случаях), второе для подключения физических устройств напрямую в виртуальную машину (для проброса виртуальных функций (VF) SRIOV, например, VT-d должен быть включен).
Следующей важной концепцией является отличие полной виртуализации (full virtualization) от пара-виртуализации (para-virtualization).
Полная виртуализация — это хорошо, это позволяет запускать какую угодно операционную систему на каком угодно процессоре, однако, это крайне неэффективно и абсолютно не подходит для высоконагруженных систем.
Пара-виртуализация, если коротко, это когда Guest OS понимает что она запущена в виртуальной среде и кооперируется с гипервизором для достижения большей эффективности. То есть появляется guest-hypervisor интерфейс.
Подавляющее большинство используемых операционных систем сегодня имеют поддержку пара-виртуализации — в Linux kernel это появилось начиная с ядра версии 2.6.20.
Для работы виртуальной машины нужны не только виртуальный процессор (vCPU) и виртуальная память (RAM), требуется также эмуляция PCI-устройств. То, есть по сути, требуется набор драйверов для управления виртуальными сетевыми интерфейсами, дисками и тд.
В гипервизоре Linux KVM данная задача была решена посредством внедрения virtio — фреймворка для разработки и использования виртуализированных устройств ввода/вывода.
Virtio представляет из себя дополнительный уровень абстракции, который позволяет эмулировать различные I/O устройства в пара-виртуализированном гипервизоре, предоставляя в сторону виртуальной машины единый и стандартизированный интерфейс. Это позволяет переиспользовать код virtio-драйвера для различных по своей сути устройств. Virtio состоит из:
Эта модульность позволяет изменять технологии, применяемые в гипервизоре, не затрагивая драйверы в виртуальной машине (этот момент очень важен для технологий сетевой акселерации и Cloud-решений в целом, но об этом позже).
То есть существует связь guest-hypervisor, когда Guest OS «знает» о том, что запущена в виртуальной среде.
Из чего же состоит виртуальная машина?
Выделяют три основных вида виртуальных ресурсов:
Теоретически QEMU способен эмулировать любой тип процессора и соотвествующие ему флаги и функциональность, на практике используют либо host-model и точечно выключают флаги перед передачей в Guest OS либо берут named-model и точечно включают\выключают флаги.
По умолчанию QEMU будет эмулировать процессор, который будет распознан Guest OS как QEMU Virtual CPU. Это не самый оптимальный тип процессора, особенно если приложение, работающее в виртуальной машине, использует CPU-флаги для своей работы. Подробнее о разных моделях CPU в QEMU.
QEMU/KVM также позволяет контролировать топологию процессора, количество тредов, размер кэша, привязывать vCPU к физическому ядру и много чего еще.
Нужно ли это для виртуальной машины или нет, зависит от типа приложения, работающего в Guest OS. Например, известный факт, что для приложений, выполняющих обработку пакетов с высоким PPS, важно делать CPU pinning, то есть не позволять передавать физический процессор другим виртуальным машинам.
Далее на очереди оперативная память — RAM. С точки зрения Host OS запущенная с помощью QEMU/KVM виртуальная машина ничем не отличается от любого другого процесса, работающего в user-space операционной системы. Соотвественно и процесс выделения памяти виртуальной машине выполняется теми же вызовами в kernel Host OS, как если бы вы запустили, например, Chrome браузер.
С точки зрения виртуальной машины память ей уже выделена на момент ее запуска, однако в реальности это не так, и kernel Host OS выделяет процессу QEMU/KVM новые участки памяти по мере того как приложение в Guest OS запрашивает дополнительную память (хотя тут тоже может быть исключение, если прямо указать QEMU/KVM выделить всю память виртуальной машине непосредственно при запуске).
Память выделяется не байт за байтом, а определенным размером — page. Размер page конфигурируем и теоретически может быть любым, но на практике используется размер 4kB (по умолчанию), 2MB и 1GB. Два последних размера называются HugePages и часто используются для выделения памяти для memory intensive виртуальных машин. Причина использования HugePages в процессе поиска соответствия между виртуальным адресом page и физической памятью в Translation Lookaside Buffer (TLB), который в свою очередь ограничен и хранит информацию только о последних использованных pages. Если информации о нужной page в TLB нет, происходит процесс, называемый TLB miss, и требуется задействовать процессор Host OS для поиска ячейки физической памяти, соответствующей нужной page.
Данный процесс неэффективен и медлителен, поэтому и используется меньшее количество pages бо?льшего размера.
QEMU/KVM также позволяет эмулировать различные NUMA-топологии для Guest OS, брать память для виртуальной машины только из определенной NUMA node Host OS и так далее. Наиболее распространенная практика — брать память для виртуальной машины из NUMA node локальной по отношению к процессорам, выделенным для виртуальной машины. Причина — желание избежать лишней нагрузки на QPI шину, соединяющую CPU sockets физического сервера (само собой, это логично если в вашем сервере 2 и более sockets).
Как известно, оперативная память потому и называется оперативной, что ее содержимое исчезает при отключении питания или перезагрузке операционной системы. Чтобы хранить информацию, требуется постоянное запоминающее устройство (ПЗУ) или persistent storage.
Существует два основных вида persistent storage:
Виртуальная машина нуждается в persistent storage, однако, как это сделать, если виртуальная машина «живет» в оперативной памяти Host OS? (кстати, именно поэтому невозможно запустить виртуальную машину с оперативной памятью меньше, чем размер ее qcow2 образа). Если вкратце, то любое обращение Guest OS к контроллеру виртуального диска перехватывается QEMU/KVM и трансформируется в запись на физический диск Host OS. Этот метод неэффективен, и поэтому здесь так же как и для сетевых устройств используется virtio-драйвер вместо полной эмуляции IDE или iSCSI-устройства. Подробнее об этом можно почитать здесь. Таким образом виртуальная машина обращается к своему виртуальному диску через virtio-драйвер, а далее QEMU/KVM делает так, чтобы переданная информация записалась на физический диск. Важно понимать, что в Host OS дисковый backend может быть реализован в виде CEPH, NFS или iSCSI-полки.
Наиболее простым способом эмулировать persistent storage является использование файла в какой-либо директории Host OS как дискового пространства виртуальной машины. QEMU/KVM поддерживает множество различных форматов такого рода файлов — raw, vdi, vmdk и прочие. Однако наибольшее распространение получил формат qcow2 (QEMU copy-on-write version 2). В общем случае, qcow2 представляет собой определенным образом структурированный файл без какой-либо операционной системы. Большое количество виртуальных машин распространяется именно в виде qcow2-образов (images) и являются копией системного диска виртуальной машины, упакованной в qcow2-формат. Это имеет ряд преимуществ — qcow2-кодирование занимает гораздо меньше места, чем raw копия диска байт в байт, QEMU/KVM умеет изменять размер qcow2-файла (resizing), а значит имеется возможность изменить размер системного диска виртуальной машины, также поддерживается AES шифрование qcow2 (это имеет смысл, так как образ виртуальной машины может содержать интеллектуальную собственность).
Далее, когда происходит запуск виртуальной машины, QEMU/KVM использует qcow2-файл как системный диск (процесс загрузки виртуальной машины я опускаю здесь, хотя это тоже является интересной задачей), а виртуальная машина имеет возможность считать/записать данные в qcow2-файл через virtio-драйвер. Таким образом и работает процесс снятия образов виртуальных машин, поскольку в любой момент времени qcow2-файл содержит полную копию системного диска виртуальной машины, и образ может быть использован для резервного копирования, переноса на другой хост и прочее.
В общем случае этот qcow2-файл будет определяться в Guest OS как /dev/vda-устройство, и Guest OS произведет разбиение дискового пространства на партиции и установку файловой системы. Аналогично, следующие qcow2-файлы, подключенные QEMU/KVM как /dev/vdX устройства, могут быть использованы как block storage в виртуальной машине для хранения информации (именно так и работает компонент Openstack Cinder).
Последним в нашем списке виртуальных ресурсов идут сетевые карты и устройства ввода/вывода. Виртуальная машина, как и физический хост, нуждается в PCI/PCIe-шине для подключения устройств ввода/вывода. QEMU/KVM способен эмулировать разные типы чипсетов — q35 или i440fx (первый поддерживает — PCIe, второй — legacy PCI ), а также различные PCI-топологии, например, создавать отдельные PCI-шины (PCI expander bus) для NUMA nodes Guest OS.
После создания PCI/PCIe шины необходимо подключить к ней устройство ввода/вывода. В общем случае это может быть что угодно — от сетевой карты до физического GPU. И, конечно же, сетевая карта, как полностью виртуализированная (полностью виртуализированный интерфейс e1000, например), так и пара-виртуализированная (virtio, например) или физическая NIC. Последняя опция используется для data-plane виртуальных машин, где требуется получить line-rate скорости передачи пакетов — маршрутизаторов, файрволов и тд.
Здесь существует два основных подхода — PCI passthrough и SR-IOV. Основное отличие между ними — для PCI-PT используется драйвер только внутри Guest OS, а для SRIOV используется драйвер Host OS (для создания VF — Virtual Functions) и драйвер Guest OS для управления SR-IOV VF. Более подробно об PCI-PT и SRIOV отлично написал Juniper.

Таким образом мы рассмотрели основные виды виртуальных ресурсов и следующим шагом необходимо понять как виртуальная машина общается с внешним миром через сеть.
Если есть виртуальная машина, а в ней есть виртуальный интерфейс, то, очевидно, возникает задача передачи пакета из одной VM в другую. В Linux-based гипервизорах (KVM, например) эта задача может решаться с помощью Linux bridge, однако, большое распространение получил проект Open vSwitch (OVS).
Есть несколько основных функциональностей, которые позволили OVS широко распространиться и стать de-facto основным методом коммутации пакетов, который используется во многих платформах облачных вычислений(например, Openstack) и виртуализированных решениях.
Архитектура OVS на первый взгляд выглядит довольно страшно, но это только на первый взгляд.
Для работы с OVS нужно понимать следующее:
Каким же образом сетевое устройство виртуальной машины оказывается в OVS?
Для решения данной задачи нам необходимо каким-то образом связать между собой виртуальный интерфейс, находящийся в user-space операционной системы с datapath OVS, находящимся в kernel.
В операционной системе Linux передача пакетов между kernel и user-space-процессами осуществляется посредством двух специальных интерфейсов. Оба интерфейса использует запись/чтение пакета в/из специальный файл для передачи пакетов из user-space-процесса в kernel и обратно — file descriptor (FD) (это одна из причин низкой производительности виртуальной коммутации, если datapath OVS находится в kernel — каждый пакет требуется записать/прочесть через FD)
Именно поэтому при запущенной виртуальной машине в Host OS можно увидеть созданные TAP-интерфейсы командой ip link или ifconfig — это «ответная» часть virtio, которая «видна» в kernel Host OS. Также стоит обратить внимание, что TAP-интерфейс имеет тот же MAC-адрес что и virtio-интерфейс в виртуальной машине.
TAP-интерфейс может быть добавлен в OVS с помощью команд ovs-vsctl — тогда любой пакет, скоммутированный OVS в TAP-интерфейс, будет передан в виртуальную машину через file descriptor.
Теперь, если нам необходимо получить возможность передачи пакетов между двумя и более виртуальными машинами, которые запущены на одном гипервизоре, нам потребуется лишь создать OVS bridge и добавить в него TAP-интерфейсы с помощью команд ovs-vsctl. Какие именно команды для этого нужны легко гуглится.
На гипервизоре может быть несколько OVS bridges, например, так работает Openstack Neutron, или же виртуальные машины могут находиться в разных namespace для реализации multi-tenancy.
А если виртуальные машины находятся в разных OVS bridges?
Для решения данной задачи существует другой инструмент — veth pair. Veth pair может быть представлен как пара сетевых интерфейсов, соединенных кабелем — все то, что «влетает» в один интерфейс, «вылетает» из другого. Veth pair используется для соединения между собой нескольких OVS bridges или Linux bridges. Другой важный момент что части veth pair могут находиться в разных namespace Linux OS, то есть veth pair может быть также использован для связи namespace между собой на сетевом уровне.
В предыдущих главах мы рассматривали теоретические основы виртуализации, в этой главе мы поговорим об инструментах, которые доступны пользователю непосредственно для запуска и изменения виртуальных машин на KVM-гипервизоре.
Остановимся на трех основных компонентах, которые покрывают 90 процентов всевозможных операций с виртуальными машинами:
libvirt — это масштабный open-source проект, который занимается разработкой набора инструментов и драйверов для управления гипервизорами. Он поддерживает не только QEMU/KVM, но и ESXi, LXC и много чего еще.
Основная причина его популярности — структурированный и понятный интерфейс взаимодействия через набор XML-файлов плюс возможность автоматизации через API. Стоит оговориться что libvirt не описывает все возможные функции гипервизора, он лишь предоставляет удобный интерфейс использования полезных, с точки зрения участников проекта, функции гипервизора.
И да, libvirt это де-факто стандарт в мире виртуализации сегодня. Только взгляните на список приложений, которые используют libvirt.

Хорошая новость про libvirt — все нужные пакеты уже предустановлены во всех наиболее часто используемых Host OS — Ubuntu, CentOS и RHEL, поэтому, скорее всего, собирать руками нужные пакеты и компилировать libvirt вам не придется. В худшем случае придется воспользоваться соответствующим пакетным инсталлятором (apt, yum и им подобные).
При первоначальной установке и запуске libvirt по умолчанию создает Linux bridge virbr0 и его минимальную конфигурацию.
Этот Linux bridge не будет подключен ни к одному физическому интерфейсу, однако, может быть использован для связи виртуальных машин внутри одного гипервизора. Libvirt безусловно может быть использован вместе с OVS, однако, для этого пользователь должен самостоятельно создать OVS bridges с помощью соответствующих OVS-команд.
Любой виртуальный ресурс, необходимый для создания виртуальной машины (compute, network, storage) представлен в виде объекта в libvirt. За процесс описания и создания этих объектов отвечает набор различных XML-файлов.
Детально описывать процесс создания виртуальных сетей и виртуальных хранилищ не имеет особого смысла, так как эта прикладная задача хорошо описана в документации libvirt:
Сама виртуальная машина со всеми подключенными PCI-устройствами в терминологии libvirt называется domain. Это тоже объект внутри libvirt, который описывается отдельным XML-файлом.
Этот XML-файл и является, строго говоря, виртуальной машиной со всеми виртуальными ресурсами — оперативная память, процессор, сетевые устройства, диски и прочее. Часто данный XML-файл называют libvirt XML или dump XML.
Вряд ли найдется человек, который понимает все параметры libvirt XML, однако, это и не требуется, когда есть документация.
В общем случае, libvirt XML для Ubuntu Desktop Guest OS будет довольно прост — 40-50 строчек. Поскольку вся оптимизация производительности описывается также в libvirt XML (NUMA-топология, CPU-топологии, CPU pinning и прочее), для сетевых функций libvirt XML может быть очень сложен и содержать несколько сот строк. Любой производитель сетевых устройств, который поставляет свое ПО в виде виртуальных машин, имеет рекомендованные примеры libvirt XML.
Утилита virsh — «родная» командная строка для управления libvirt. Основное ее предназначение — это управление объектами libvirt, описанными в виде XML-файлов. Типичными примерами являются операции start, stop, define, destroy и так далее. То есть жизненный цикл объектов — life-cycle management.
Описание всех команд и флагов virsh также доступно в документации libvirt.
Еще одна утилита, которая используется для взаимодействия с libvirt. Одно из основных преимуществ — можно не разбираться с XML-форматом, а обойтись лишь флагами, доступными в virsh-install. Второй важный момент — море примеров и информации в Сети.
Таким образом какой бы утилитой вы ни пользовались, управлять гипервизором в конечном счете будет именно libvirt, поэтому важно понимать архитектуру и принципы его работы.
В данной статье мы рассмотрели минимальный набор теоретических знаний, который необходим для работы с виртуальными машинами. Я намеренно не приводил практических примеров и выводов команд, поскольку таких примеров можно найти сколько угодно в Сети, и я не ставил перед собой задачу написать «step-by-step guide». Если вас заинтересовала какая-то конкретная тема или технология, оставляйте свои комментарии и пишите вопросы.
Роман Горге вдохновился ею и решил написать обзорный выпуск о виртуализации вообще.
В данной статье мы затронем (или попытаемся затронуть) вопросы: а как собственно происходит виртуализация сетевых функций, как реализован backend основных продуктов, обеспечивающих запуск и управление VM, а также как работает виртуальный свитчинг (OVS и Linux bridge).
Тема виртуализации широка и глубока, объяснить все детали работы гипервизора невозможно (да и не нужно). Мы ограничимся минимальным набором знаний необходимым для понимания работы любого виртуализированного решения, не обязательно Telco.

Содержание
- Введение и краткая история виртуализации
- Типы виртуальных ресурсов — compute, storage, network
- Виртуальная коммутация
- Инструменты виртуализации — libvirt, virsh и прочее
- Заключение
Введение и краткая история виртуализации
История современных технологий виртуализации берет свое начало в 1999 году, когда молодая компания VMWare выпустила продукт под названием VMWare Workstation. Это был продукт обеспечивающий виртуализацию desktop/client приложений. Виртуализация серверной части пришла несколько позднее в виде продукта ESX Server, который в дальнейшем эволюционировал в ESXi (i означает integrated) — это тот самый продукт, который используется повсеместно как в IT так и в Telco как гипервизор серверных приложений.
На стороне Opensource два основных проекта принесли виртуализацию в Linux:
- KVM (Kernel-based Virtual Machine) — модуль ядра Linux, который позволяет kernel работать как гипервизор (создает необходимую инфраструктуру для запуска и управления VM). Был добавлен в версии ядра 2.6.20 в 2007 году.
- QEMU (Quick Emulator) — непосредственно эмулирует железо для виртуальной машины (CPU, Disk, RAM, что угодно включая USB порт) и используется совместно с KVM для достижения почти «native» производительности.
На самом деле на сегодняшний момент вся функциональность KVM доступна в QEMU, но это не принципиально, так как бо?льшая часть пользователей виртуализации на Linux не использует напрямую KVM/QEMU, а обращается к ним как минимум через один уровень абстракции, но об этом позже.
Сегодня VMWare ESXi и Linux QEMU/KVM это два основных гипервизора, которые доминируют на рынке. Они же являются представителями двух разных типов гипервизоров:
- Type 1 — гипервизор запускается непосредственно на железе (bare-metal). Таковым является VMWare ESXi.
- Type 2 — гипервизор запускается внутри Host OS (операционной системы). Таковым является Linux KVM.
Обсуждение что лучше, а что хуже выходит за рамки данной статьи.
Производители железа также должны были сделать свою часть работы, дабы обеспечить приемлемую производительность.
Пожалуй, наиболее важной и самой широко используемой является технология Intel VT (Virtualization Technology) — набор расширений, разработанных Intel для своих x86 процессоров, которые используются для эффективной работы гипервизора (а в некоторых случаях необходимы, так, например, KVM не заработает без включенного VT-x и без него гипервизор вынужден заниматься чисто софтверной эмуляцией, без аппаратного ускорения).
Наиболее известны два из этих расширений — VT-x и VT-d. Первое важно для улучшения производительности CPU при виртуализации, так как обеспечивает аппаратную поддержку некоторых ее функций (с VT-x 99.9% Guest OS кода выполняется прямо на физическом процессоре, делая выходы для эмуляции только в самых необходимых случаях), второе для подключения физических устройств напрямую в виртуальную машину (для проброса виртуальных функций (VF) SRIOV, например, VT-d должен быть включен).
Следующей важной концепцией является отличие полной виртуализации (full virtualization) от пара-виртуализации (para-virtualization).
Полная виртуализация — это хорошо, это позволяет запускать какую угодно операционную систему на каком угодно процессоре, однако, это крайне неэффективно и абсолютно не подходит для высоконагруженных систем.
Пара-виртуализация, если коротко, это когда Guest OS понимает что она запущена в виртуальной среде и кооперируется с гипервизором для достижения большей эффективности. То есть появляется guest-hypervisor интерфейс.
Подавляющее большинство используемых операционных систем сегодня имеют поддержку пара-виртуализации — в Linux kernel это появилось начиная с ядра версии 2.6.20.
Для работы виртуальной машины нужны не только виртуальный процессор (vCPU) и виртуальная память (RAM), требуется также эмуляция PCI-устройств. То, есть по сути, требуется набор драйверов для управления виртуальными сетевыми интерфейсами, дисками и тд.
В гипервизоре Linux KVM данная задача была решена посредством внедрения virtio — фреймворка для разработки и использования виртуализированных устройств ввода/вывода.
Virtio представляет из себя дополнительный уровень абстракции, который позволяет эмулировать различные I/O устройства в пара-виртуализированном гипервизоре, предоставляя в сторону виртуальной машины единый и стандартизированный интерфейс. Это позволяет переиспользовать код virtio-драйвера для различных по своей сути устройств. Virtio состоит из:
- Front-end driver — то что находится в виртуальной машине
- Back-end driver — то что находится в гипервизоре
- Transport driver — то что связывает backend и frontend
Эта модульность позволяет изменять технологии, применяемые в гипервизоре, не затрагивая драйверы в виртуальной машине (этот момент очень важен для технологий сетевой акселерации и Cloud-решений в целом, но об этом позже).
То есть существует связь guest-hypervisor, когда Guest OS «знает» о том, что запущена в виртуальной среде.
Если вы хоть раз писали вопрос в RFP или отвечали на вопрос в RFP «Поддерживается ли в вашем продукте virtio?» Это как раз было о поддержке front-end virtio драйвера.
Типы виртуальных ресурсов — compute, storage, network
Из чего же состоит виртуальная машина?
Выделяют три основных вида виртуальных ресурсов:
- compute — процессор и оперативная память
- storage — системный диск виртуальной машины и блочные хранилища
- network — сетевые карты и устройства ввода/вывода
Compute
CPU
Теоретически QEMU способен эмулировать любой тип процессора и соотвествующие ему флаги и функциональность, на практике используют либо host-model и точечно выключают флаги перед передачей в Guest OS либо берут named-model и точечно включают\выключают флаги.
По умолчанию QEMU будет эмулировать процессор, который будет распознан Guest OS как QEMU Virtual CPU. Это не самый оптимальный тип процессора, особенно если приложение, работающее в виртуальной машине, использует CPU-флаги для своей работы. Подробнее о разных моделях CPU в QEMU.
QEMU/KVM также позволяет контролировать топологию процессора, количество тредов, размер кэша, привязывать vCPU к физическому ядру и много чего еще.
Нужно ли это для виртуальной машины или нет, зависит от типа приложения, работающего в Guest OS. Например, известный факт, что для приложений, выполняющих обработку пакетов с высоким PPS, важно делать CPU pinning, то есть не позволять передавать физический процессор другим виртуальным машинам.
Memory
Далее на очереди оперативная память — RAM. С точки зрения Host OS запущенная с помощью QEMU/KVM виртуальная машина ничем не отличается от любого другого процесса, работающего в user-space операционной системы. Соотвественно и процесс выделения памяти виртуальной машине выполняется теми же вызовами в kernel Host OS, как если бы вы запустили, например, Chrome браузер.
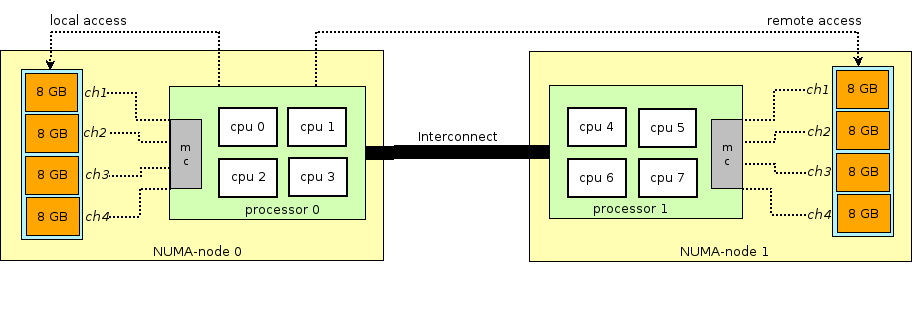
Перед тем как продолжить повествование об оперативной памяти в виртуальных машинах, необходимо сделать отступление и объяснить термин NUMA — Non-Uniform Memory Access.
Архитектура современных физических серверов предполагает наличие двух или более процессоров (CPU) и ассоциированной с ней оперативной памятью (RAM). Такая связка процессор + память называется узел или нода (node). Связь между различными NUMA nodes осуществляется посредством специальной шины — QPI (QuickPath Interconnect)
Выделяют локальную NUMA node — когда процесс, запущенный в операционной системе, использует процессор и оперативную память, находящуюся в одной NUMA node, и удаленную NUMA node — когда процесс, запущенный в операционной системе, использует процессор и оперативную память, находящиеся в разных NUMA nodes, то есть для взаимодействия процессора и памяти требуется передача данных через QPI шину.
С точки зрения виртуальной машины память ей уже выделена на момент ее запуска, однако в реальности это не так, и kernel Host OS выделяет процессу QEMU/KVM новые участки памяти по мере того как приложение в Guest OS запрашивает дополнительную память (хотя тут тоже может быть исключение, если прямо указать QEMU/KVM выделить всю память виртуальной машине непосредственно при запуске).
Память выделяется не байт за байтом, а определенным размером — page. Размер page конфигурируем и теоретически может быть любым, но на практике используется размер 4kB (по умолчанию), 2MB и 1GB. Два последних размера называются HugePages и часто используются для выделения памяти для memory intensive виртуальных машин. Причина использования HugePages в процессе поиска соответствия между виртуальным адресом page и физической памятью в Translation Lookaside Buffer (TLB), который в свою очередь ограничен и хранит информацию только о последних использованных pages. Если информации о нужной page в TLB нет, происходит процесс, называемый TLB miss, и требуется задействовать процессор Host OS для поиска ячейки физической памяти, соответствующей нужной page.
Данный процесс неэффективен и медлителен, поэтому и используется меньшее количество pages бо?льшего размера.
QEMU/KVM также позволяет эмулировать различные NUMA-топологии для Guest OS, брать память для виртуальной машины только из определенной NUMA node Host OS и так далее. Наиболее распространенная практика — брать память для виртуальной машины из NUMA node локальной по отношению к процессорам, выделенным для виртуальной машины. Причина — желание избежать лишней нагрузки на QPI шину, соединяющую CPU sockets физического сервера (само собой, это логично если в вашем сервере 2 и более sockets).
Storage
Как известно, оперативная память потому и называется оперативной, что ее содержимое исчезает при отключении питания или перезагрузке операционной системы. Чтобы хранить информацию, требуется постоянное запоминающее устройство (ПЗУ) или persistent storage.
Существует два основных вида persistent storage:
- Block storage (блоковое хранилище) — блок дискового пространства, который может быть использован для установки файловой системы и создания партиций. Если грубо, то можно воспринимать это как обычный диск.
- Object storage (объектное хранилище) — информация может быть сохранена только в виде объекта (файла), доступного по HTTP/HTTPS. Типичными примерами объектного хранилища являются AWS S3 или Dropbox.
Виртуальная машина нуждается в persistent storage, однако, как это сделать, если виртуальная машина «живет» в оперативной памяти Host OS? (кстати, именно поэтому невозможно запустить виртуальную машину с оперативной памятью меньше, чем размер ее qcow2 образа). Если вкратце, то любое обращение Guest OS к контроллеру виртуального диска перехватывается QEMU/KVM и трансформируется в запись на физический диск Host OS. Этот метод неэффективен, и поэтому здесь так же как и для сетевых устройств используется virtio-драйвер вместо полной эмуляции IDE или iSCSI-устройства. Подробнее об этом можно почитать здесь. Таким образом виртуальная машина обращается к своему виртуальному диску через virtio-драйвер, а далее QEMU/KVM делает так, чтобы переданная информация записалась на физический диск. Важно понимать, что в Host OS дисковый backend может быть реализован в виде CEPH, NFS или iSCSI-полки.
Наиболее простым способом эмулировать persistent storage является использование файла в какой-либо директории Host OS как дискового пространства виртуальной машины. QEMU/KVM поддерживает множество различных форматов такого рода файлов — raw, vdi, vmdk и прочие. Однако наибольшее распространение получил формат qcow2 (QEMU copy-on-write version 2). В общем случае, qcow2 представляет собой определенным образом структурированный файл без какой-либо операционной системы. Большое количество виртуальных машин распространяется именно в виде qcow2-образов (images) и являются копией системного диска виртуальной машины, упакованной в qcow2-формат. Это имеет ряд преимуществ — qcow2-кодирование занимает гораздо меньше места, чем raw копия диска байт в байт, QEMU/KVM умеет изменять размер qcow2-файла (resizing), а значит имеется возможность изменить размер системного диска виртуальной машины, также поддерживается AES шифрование qcow2 (это имеет смысл, так как образ виртуальной машины может содержать интеллектуальную собственность).
Далее, когда происходит запуск виртуальной машины, QEMU/KVM использует qcow2-файл как системный диск (процесс загрузки виртуальной машины я опускаю здесь, хотя это тоже является интересной задачей), а виртуальная машина имеет возможность считать/записать данные в qcow2-файл через virtio-драйвер. Таким образом и работает процесс снятия образов виртуальных машин, поскольку в любой момент времени qcow2-файл содержит полную копию системного диска виртуальной машины, и образ может быть использован для резервного копирования, переноса на другой хост и прочее.
В общем случае этот qcow2-файл будет определяться в Guest OS как /dev/vda-устройство, и Guest OS произведет разбиение дискового пространства на партиции и установку файловой системы. Аналогично, следующие qcow2-файлы, подключенные QEMU/KVM как /dev/vdX устройства, могут быть использованы как block storage в виртуальной машине для хранения информации (именно так и работает компонент Openstack Cinder).
Network
Последним в нашем списке виртуальных ресурсов идут сетевые карты и устройства ввода/вывода. Виртуальная машина, как и физический хост, нуждается в PCI/PCIe-шине для подключения устройств ввода/вывода. QEMU/KVM способен эмулировать разные типы чипсетов — q35 или i440fx (первый поддерживает — PCIe, второй — legacy PCI ), а также различные PCI-топологии, например, создавать отдельные PCI-шины (PCI expander bus) для NUMA nodes Guest OS.
После создания PCI/PCIe шины необходимо подключить к ней устройство ввода/вывода. В общем случае это может быть что угодно — от сетевой карты до физического GPU. И, конечно же, сетевая карта, как полностью виртуализированная (полностью виртуализированный интерфейс e1000, например), так и пара-виртуализированная (virtio, например) или физическая NIC. Последняя опция используется для data-plane виртуальных машин, где требуется получить line-rate скорости передачи пакетов — маршрутизаторов, файрволов и тд.
Здесь существует два основных подхода — PCI passthrough и SR-IOV. Основное отличие между ними — для PCI-PT используется драйвер только внутри Guest OS, а для SRIOV используется драйвер Host OS (для создания VF — Virtual Functions) и драйвер Guest OS для управления SR-IOV VF. Более подробно об PCI-PT и SRIOV отлично написал Juniper.
Для уточнения стоит отметить что, PCI passthrough и SR-IOV это дополняющие друг друга технологии. SR-IOV это нарезка физической функции на виртуальные функции. Это выполняется на уровне Host OS. При этом Host OS видит виртуальные функции как еще одно PCI/PCIe устройство. Что он дальше с ними делает — не важно.
А PCI-PT это механизм проброса любого Host OS PCI устройства в Guest OS, в том числе виртуальной функции, созданной SR-IOV устройством
Таким образом мы рассмотрели основные виды виртуальных ресурсов и следующим шагом необходимо понять как виртуальная машина общается с внешним миром через сеть.
Виртуальная коммутация
Если есть виртуальная машина, а в ней есть виртуальный интерфейс, то, очевидно, возникает задача передачи пакета из одной VM в другую. В Linux-based гипервизорах (KVM, например) эта задача может решаться с помощью Linux bridge, однако, большое распространение получил проект Open vSwitch (OVS).
Есть несколько основных функциональностей, которые позволили OVS широко распространиться и стать de-facto основным методом коммутации пакетов, который используется во многих платформах облачных вычислений(например, Openstack) и виртуализированных решениях.
- Передача сетевого состояния — при миграции VM между гипервизорами возникает задача передачи ACL, QoSs, L2/L3 forwarding-таблиц и прочего. И OVS умеет это.
- Реализация механизма передачи пакетов (datapath) как в kernel, так и в user-space
- CUPS (Control/User-plane separation) архитектура — позволяет перенести функциональность обработки пакетов на специализированный chipset (Broadcom и Marvell chipset, например, могут такое), управляя им через control-plane OVS.
- Поддержка методов удаленного управления трафиком — протокол OpenFlow (привет, SDN).
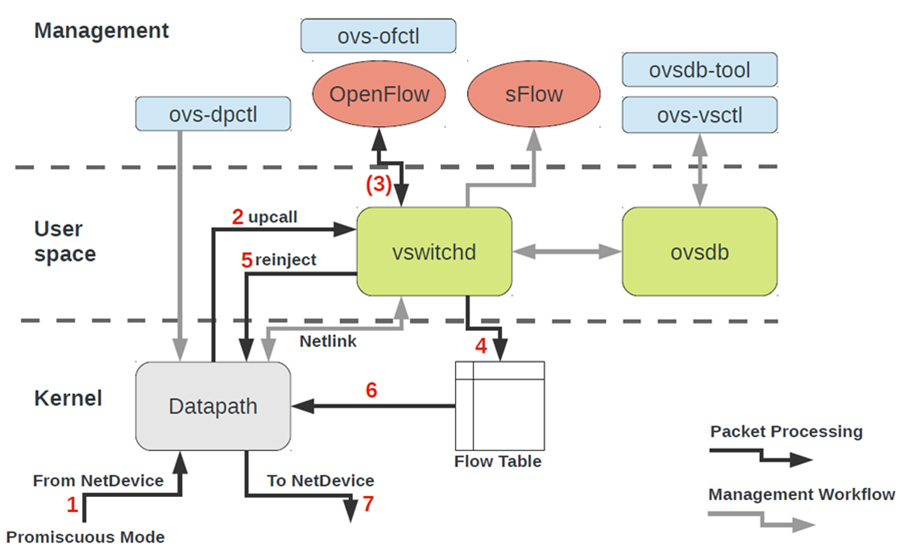
Архитектура OVS на первый взгляд выглядит довольно страшно, но это только на первый взгляд.
Для работы с OVS нужно понимать следующее:
- Datapath — тут обрабатываются пакеты. Аналогия — switch-fabric железного коммутатора. Datapath включает в себя приём пакетов, обработку заголовков, поиск соответствий по таблице flow, который в Datapath уже запрограммирован. Если OVS работает в kernel, то выполнен в виде модуля ядра. Если OVS работает в user-space, то это процесс в user-space Linux.
- vswitchd и ovsdb — демоны в user-space, то что реализует непосредственно сам функциональность коммутатора, хранит конфигурацию, устанавливает flow в datapath и программирует его.
- Набор инструментов для настройки и траблшутинга OVS — ovs-vsctl, ovs-dpctl, ovs-ofctl, ovs-appctl. Все то, что нужно, чтобы прописать в ovsdb конфигурацию портов, прописать какой flow куда должен коммутироваться, собрать статистику и прочее. Добрые люди написали статью по этому поводу.
Каким же образом сетевое устройство виртуальной машины оказывается в OVS?
Для решения данной задачи нам необходимо каким-то образом связать между собой виртуальный интерфейс, находящийся в user-space операционной системы с datapath OVS, находящимся в kernel.
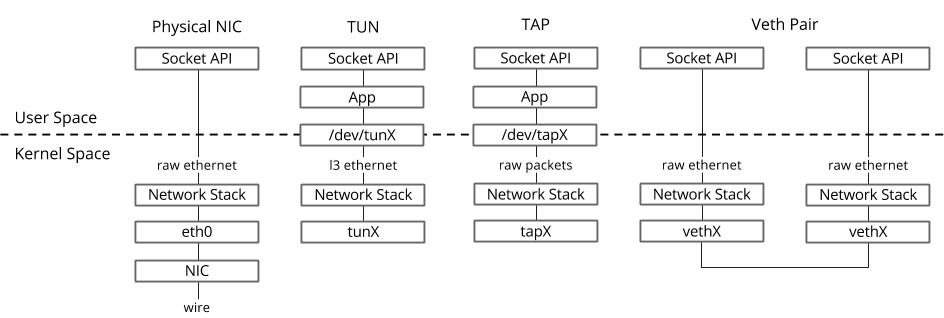
В операционной системе Linux передача пакетов между kernel и user-space-процессами осуществляется посредством двух специальных интерфейсов. Оба интерфейса использует запись/чтение пакета в/из специальный файл для передачи пакетов из user-space-процесса в kernel и обратно — file descriptor (FD) (это одна из причин низкой производительности виртуальной коммутации, если datapath OVS находится в kernel — каждый пакет требуется записать/прочесть через FD)
- TUN (tunnel) — устройство, работающее в L3 режиме и позволяющее записывать/считывать только IP пакеты в/из FD.
- TAP (network tap) — то же самое, что и tun интерфейс + умеет производить операции с Ethernet-фреймами, т.е. работать в режиме L2.
Именно поэтому при запущенной виртуальной машине в Host OS можно увидеть созданные TAP-интерфейсы командой ip link или ifconfig — это «ответная» часть virtio, которая «видна» в kernel Host OS. Также стоит обратить внимание, что TAP-интерфейс имеет тот же MAC-адрес что и virtio-интерфейс в виртуальной машине.
TAP-интерфейс может быть добавлен в OVS с помощью команд ovs-vsctl — тогда любой пакет, скоммутированный OVS в TAP-интерфейс, будет передан в виртуальную машину через file descriptor.
Реальный порядок действий при создании виртуальной машины может быть разным, т.е. сначала можно создать OVS bridge, потом указать виртуальной машине создать интерфейс, соединенный с этим OVS, а можно и наоборот.
Теперь, если нам необходимо получить возможность передачи пакетов между двумя и более виртуальными машинами, которые запущены на одном гипервизоре, нам потребуется лишь создать OVS bridge и добавить в него TAP-интерфейсы с помощью команд ovs-vsctl. Какие именно команды для этого нужны легко гуглится.
На гипервизоре может быть несколько OVS bridges, например, так работает Openstack Neutron, или же виртуальные машины могут находиться в разных namespace для реализации multi-tenancy.
А если виртуальные машины находятся в разных OVS bridges?
Для решения данной задачи существует другой инструмент — veth pair. Veth pair может быть представлен как пара сетевых интерфейсов, соединенных кабелем — все то, что «влетает» в один интерфейс, «вылетает» из другого. Veth pair используется для соединения между собой нескольких OVS bridges или Linux bridges. Другой важный момент что части veth pair могут находиться в разных namespace Linux OS, то есть veth pair может быть также использован для связи namespace между собой на сетевом уровне.
Инструменты виртуализации — libvirt, virsh и прочее
В предыдущих главах мы рассматривали теоретические основы виртуализации, в этой главе мы поговорим об инструментах, которые доступны пользователю непосредственно для запуска и изменения виртуальных машин на KVM-гипервизоре.
Остановимся на трех основных компонентах, которые покрывают 90 процентов всевозможных операций с виртуальными машинами:
- libvirt
- virsh CLI
- virt-install
Конечно, существует множество других утилит и CLI-команд, которые позволяют управлять гипервизором, например, можно напрямую пользоваться командами qemu_system_x86_64 или графическим интерфейсом virt manager, но это скорее исключение. К тому же существующие сегодня Cloud-платформы, Openstack, например, используют как раз libvirt.
libvirt
libvirt — это масштабный open-source проект, который занимается разработкой набора инструментов и драйверов для управления гипервизорами. Он поддерживает не только QEMU/KVM, но и ESXi, LXC и много чего еще.
Основная причина его популярности — структурированный и понятный интерфейс взаимодействия через набор XML-файлов плюс возможность автоматизации через API. Стоит оговориться что libvirt не описывает все возможные функции гипервизора, он лишь предоставляет удобный интерфейс использования полезных, с точки зрения участников проекта, функции гипервизора.
И да, libvirt это де-факто стандарт в мире виртуализации сегодня. Только взгляните на список приложений, которые используют libvirt.
Хорошая новость про libvirt — все нужные пакеты уже предустановлены во всех наиболее часто используемых Host OS — Ubuntu, CentOS и RHEL, поэтому, скорее всего, собирать руками нужные пакеты и компилировать libvirt вам не придется. В худшем случае придется воспользоваться соответствующим пакетным инсталлятором (apt, yum и им подобные).
При первоначальной установке и запуске libvirt по умолчанию создает Linux bridge virbr0 и его минимальную конфигурацию.
Именно поэтому при установке Ubuntu Server, например, вы увидите в выводе команды ifconfig Linux bridge virbr0 — это результат запуска демона libvirtd
Этот Linux bridge не будет подключен ни к одному физическому интерфейсу, однако, может быть использован для связи виртуальных машин внутри одного гипервизора. Libvirt безусловно может быть использован вместе с OVS, однако, для этого пользователь должен самостоятельно создать OVS bridges с помощью соответствующих OVS-команд.
Любой виртуальный ресурс, необходимый для создания виртуальной машины (compute, network, storage) представлен в виде объекта в libvirt. За процесс описания и создания этих объектов отвечает набор различных XML-файлов.
Детально описывать процесс создания виртуальных сетей и виртуальных хранилищ не имеет особого смысла, так как эта прикладная задача хорошо описана в документации libvirt:
Сама виртуальная машина со всеми подключенными PCI-устройствами в терминологии libvirt называется domain. Это тоже объект внутри libvirt, который описывается отдельным XML-файлом.
Этот XML-файл и является, строго говоря, виртуальной машиной со всеми виртуальными ресурсами — оперативная память, процессор, сетевые устройства, диски и прочее. Часто данный XML-файл называют libvirt XML или dump XML.
Вряд ли найдется человек, который понимает все параметры libvirt XML, однако, это и не требуется, когда есть документация.
В общем случае, libvirt XML для Ubuntu Desktop Guest OS будет довольно прост — 40-50 строчек. Поскольку вся оптимизация производительности описывается также в libvirt XML (NUMA-топология, CPU-топологии, CPU pinning и прочее), для сетевых функций libvirt XML может быть очень сложен и содержать несколько сот строк. Любой производитель сетевых устройств, который поставляет свое ПО в виде виртуальных машин, имеет рекомендованные примеры libvirt XML.
virsh CLI
Утилита virsh — «родная» командная строка для управления libvirt. Основное ее предназначение — это управление объектами libvirt, описанными в виде XML-файлов. Типичными примерами являются операции start, stop, define, destroy и так далее. То есть жизненный цикл объектов — life-cycle management.
Описание всех команд и флагов virsh также доступно в документации libvirt.
virt-install
Еще одна утилита, которая используется для взаимодействия с libvirt. Одно из основных преимуществ — можно не разбираться с XML-форматом, а обойтись лишь флагами, доступными в virsh-install. Второй важный момент — море примеров и информации в Сети.
Таким образом какой бы утилитой вы ни пользовались, управлять гипервизором в конечном счете будет именно libvirt, поэтому важно понимать архитектуру и принципы его работы.
Заключение
В данной статье мы рассмотрели минимальный набор теоретических знаний, который необходим для работы с виртуальными машинами. Я намеренно не приводил практических примеров и выводов команд, поскольку таких примеров можно найти сколько угодно в Сети, и я не ставил перед собой задачу написать «step-by-step guide». Если вас заинтересовала какая-то конкретная тема или технология, оставляйте свои комментарии и пишите вопросы.
Полезные ссылки
Спасибы
- Александру Шалимову — моему коллеге и эксперту в области разработки виртуальных сетей. За комментарии и правки.
- Евгению Яковлеву — моему коллеге и эксперту в области виртуализации за комментарии и правки.
Комментарии (7)


iwram
19.09.2019 04:24В статье написано что KVM относится к виртуализации 2 типа. Что может вызвать повод к дискуссии. Я не хочу ничего доказывать, а просто скину ссылку www.redhat.com/en/topics/virtualization/what-is-KVM
«KVM converts Linux into a type-1 (bare-metal) hypervisor.»
Даже Hyper-V относится к 1му типу.
Гипервизоры 2-го типа: VMware Workstation, Oracle Virtual Box, OpenVZ.


philldm
20.09.2019 08:28Если Вы так хорошо разбираетесь в виртуализации, скажите пожалуйста, можно Вам тоже известно как сделать .qcow2 image используя Cisco ASA ios, которая имеет .SPA экстензию?
boiler5
20.09.2019 09:41Про то что у Cisco есть софт для виртуализации никогда не слышал. Скорее всего существует способ конвертнуть его в raw файл. А raw уже превратить в qcow2 через qemu-img.
saipr
И вам спасибо. Отправляю статью сыну. Ему будет очень полезно прочитать.