
Вот уже почти год я пользуюсь сервисом Яндекс Музыка и меня все устраивает. Но есть в этом сервисе одна интересная страница — история. Она хранит все треки, которые были прослушаны, в хронологическом порядке. И мне, конечно, захотелось скачать ее и проанализировать, что я там наслушал за все время.

Первые попытки
Начав разбираться с этой страницей, я сразу же столкнулся с проблемой. Сервис не загружает все треки сразу, а только по мере скроллинга. Скачивать сниффер и разбираться в трафике мне не хотелось, да и навыков у меня в этом деле на тот момент не было. Поэтому я решил пойти более простым путем эмулирования браузера с помощью selenium.
Скрипт был написан. Но работал он очень нестабильно и долго. Но загрузить историю у него всё-таки получилось. После просто анализа я оставил скрипт без доработок, пока через какое-то время мне снова не захотелось загрузить историю. Надеясь на лучшее, я запустил его. И, конечно же, он выдал ошибку. Тогда я понял, что пора сделать все по-человечески.
Рабочий вариант
Для анализа трафика я выбрал для себя Fiddler из-за более мощного интерфейса для http трафика в отличие от wireshark. Запустив сниффер, я ожидал увидеть запросы к api с токеном. Но нет. Наша цель оказалась по адресу music.yandex.ru/handlers/library.jsx. И запросы к ней требовали полноценной авторизации на сайте. С нее и начнем.
Авторизация
Здесь ничего сложного. Заходим на passport.yandex.ru/auth, находим параметры для запросов и делаем два запроса для авторизации.
auth_page = self.get('/auth').text
csrf_token, process_uuid = self.find_auth_data(auth_page)
auth_login = self.post(
'/registration-validations/auth/multi_step/start',
data={'csrf_token': csrf_token,
'process_uuid': process_uuid,
'login': self.login}
).json()
auth_password = self.post(
'/registration-validations/auth/multi_step/commit_password',
data={'csrf_token': csrf_token,
'track_id': auth_login['track_id'],
'password': self.password}
).json()И вот мы авторизовались.
Загрузка истории
Дальше переходим на music.yandex.ru/user/<user>/history, где тоже забираем пару параметров, который нам пригодятся при получении информации о треках. Теперь можно загружать историю. Id треков мы получаем по адресу music.yandex.ru/handlers/library.jsx с параметрами {'owner': <user>, 'filter': 'history', 'likeFilter': 'favorite', 'lang': 'ru', 'external-domain': 'music.yandex.ru', 'overembed': 'false', 'ncrnd': '0.9546193023464256'}. Интерес у меня вызвал тут параметр ncrnd. При запросах Яндекс присваивает этому параметру всегда разные значения, но с одинаковым все тоже работает. Обратно мы получаем историю в виде id треков и Подробную информацию о первых десятках треков. Из подробной информации треков можно сохранить много интересных данных для последующего анализа. Например год выхода, длительность трека и жанр. Информацию об остальных треках получаем c music.yandex.ru/handlers/track-entries.jsx. Все это дело сохраняем в csv и переходим к анализу.
Анализ
Для анализа используем стандартные инструменты в виде pandas и matplotlib.
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv('statistics.csv')
df.head(3)| № | artist | artist_id | album | album_id | track | track_id | duration_sec | year | genre |
|---|---|---|---|---|---|---|---|---|---|
| 0 | Coldplay | 671 | Viva La Vida — Prospekt's March Edition | 51399 | Death And All His Friends | 475739 | 383 | 2008 | rock |
| 1 | Coldplay | 671 | Hypnotised | 4175645 | Hypnotised | 34046075 | 355 | 2017 | rock |
| 2 | Coldplay | 671 | Yellow | 49292 | No More Keeping My Feet On The Ground | 468945 | 271 | 2000 | rock |
Меняем питоновские None на NaN и выбрасываем их.
df = df.replace('None', pd.np.nan).dropna()Начнем с простого. Посмотрим время, которое мы потратили на прослушивание всех треков
duration_sec = df['duration_sec'].astype('int64').sum()
ss = duration_sec % 60
m = duration_sec // 60
mm = m % 60
h = m // 60
hh = h % 60
f'{h // 24} {hh}:{mm}:{ss}''15 15:30:14'Но тут можно поспорить насчет точности этой цифры, тк не понятно какую часть трека нужно прослушать, чтобы яндекс добавил ее в историю.
Теперь посмотрим на распределение треков по году выпуска.
plt.rcParams['figure.figsize'] = [15, 5]
plt.hist(df['year'].sort_values(), bins=len(df['year'].unique()))
plt.xticks(rotation='vertical')
plt.show()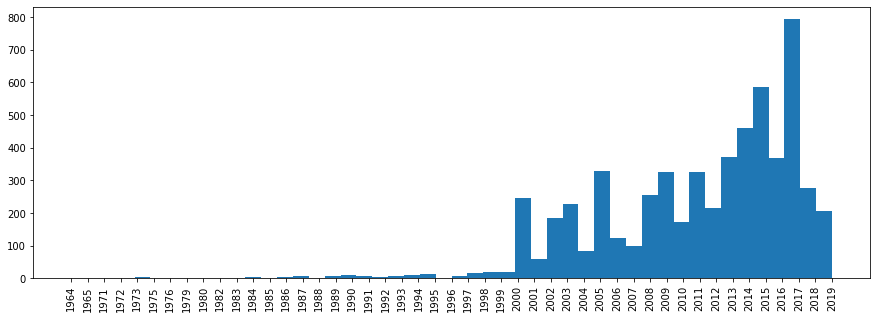
Тут то же не все так однозначно, тк у разнообразных сборников “Best Hits” будет стоять более поздний год.
Остальные статистики будут строиться по очень схожему принципу. Приведу пример самых прослушиваемых треков
df.groupby(['track_id', 'artist','track'])['track_id'].count().sort_values(ascending=False).head()| track_id | artist | track | |
|---|---|---|---|
| 170252 | Linkin Park | What I've Done | 32 |
| 28472574 | Coldplay | Up&Up | 31 |
| 3656360 | Coldplay | Charlie Brown | 31 |
| 178529 | Linkin Park | Numb | 29 |
| 289675 | Thirty Seconds to Mars | ATTACK | 27 |
и самых прослушиваемых треков исполнителя
artist_name = 'Coldplay'
df.groupby([
'artist_id', 'track_id', 'artist', 'track'
])['artist_id'].count().sort_values(ascending=False)[:,:,artist_name].head(5)| artist_id | track_id | track | |
|---|---|---|---|
| 671 | 28472574 | Up&Up | 31 |
| 3656360 | Charlie Brown | 31 | |
| 340302 | Fix You | 26 | |
| 26285334 | A Head Full of Dreams | 26 | |
| 376949 | Yellow | 23 |
Полный код можно найти тут
Комментарии (5)

oldbie
18.09.2019 14:25Прочитав заголовок было решил что это не мы прослушиваем Я.Музыку, а она нас. Хотя кто знает, кто знает…

rdnve
Почему бы не использовать last.fm и их API? Я.Музыка легко подключается и кладёт туда всю историю.
Platun0v Автор
Не знал про существование такого сервиса