
Кажется, что сфера интернет-рекламы должна быть максимально технологичной и автоматизированной. Ещё бы, ведь там работают такие гиганты и эксперты в своём деле, как Яндекс, Mail.Ru, Google и Facebook. Но, как оказалось, нет предела совершенству и всегда есть что автоматизировать.

Источник
Коммуникационная группа Dentsu Aegis Network Russia — крупнейший игрок на рекламном digital рынке и активно инвестирует в технологии, пытаясь в оптимизировать и автоматизировать свои бизнес-процессы. Одной из нерешенных задач рынка интернет-рекламы стала задача сбора статистики по рекламным кампаниям с разных интернет-площадок. Решение этой задачи в итоге вылилось в создание продукта D1.Digital (читать как ДиВан), о разработке которого мы и хотим рассказать.
1. На момент старта проекта на рынке не было ни одного готового продукта, решающего задачу автоматизации сбора статистики по рекламным кампаниям. Значит, никто кроме нас самих не закроет наши потребности.
Такие сервисы, как Improvado, Roistat, Supermetrics, SegmentStream, предлагают интеграцию с площадками, социальными сетями и Google Analitycs, а также дают возможность строить аналитические дашборды для удобного анализа и контроля рекламных кампаний. Перед тем, как начать развивать свой продукт, мы попробовали использовать в работе некоторые из этих систем для сбора данных с площадок, но, к сожалению, они не смогли решить наших задач.
Главной проблемой стало то, что тестируемые продукты отталкивались от источников данных, отображая статистику размещений в разрезах по площадкам, и не давали возможность агрегировать статистику по рекламным кампаниям. Такой подход не позволял увидеть статистику из разных площадок в одном месте и проанализировать состояние кампании целиком.
Другим фактором стало то, что на начальных этапах продукты были ориентированы на западный рынок и не поддерживал интеграцию с российскими площадками. А по тем площадкам, с которыми была реализована интеграция, не всегда выгружались все необходимые метрики с достаточной детализацией, а интеграция не всегда была удобной и прозрачной, особенно когда нужно было получить что-то, чего нет в интерфейсе системы.
В общем, мы решили не подстраиваться под сторонние продукты, а занялись разработкой своего…
2. Рынок интернет-рекламы растет из года в год, и в 2018 году по объему рекламных бюджетов он обогнал традиционно крупнейший рынок ТВ-рекламы. Значит, есть масштаб.
3. В отличие от рынка ТВ-рекламы, где продажа коммерческой рекламы монополизирована, в Интернете работает масса отдельных владельцев рекламного инвентаря разной величины со своими рекламными кабинетами. Так как рекламная кампания, как правило, идёт сразу на нескольких площадках, то для понимания состояния рекламной кампании, надо собрать отчеты со всех площадок и свести их в один большой отчет, который покажет картинку целиком. Значит, есть потенциал для оптимизации.
4. Нам казалось, что у владельцев рекламного инвентаря в интернете уже есть инфраструктура для сбора статистики и ее отображения в рекламных кабинетах, и они смогут предоставить API к этим данным. Значит, есть техническая возможность реализации. Скажем сразу, что оказалось не все так просто.
В общем, все предпосылки для реализации проекта были для нас очевидны, и мы побежали воплощать проект в жизнь…
Для начала мы сформировали видение идеальной системы:
Учитывая нашу приверженность гибким принципам разработки ПО (agile, все дела), мы решили сначала разработать MVP и далее двигаться к намеченной цели итеративно.
MVP мы решили строить на основе нашего продукта DANBo (Dentsu Aegis Network Board), представляющего из себя web приложение с общей информацией по рекламным кампаниям наших клиентов.
Для MVP проект был максимально упрощен с точки зрения реализации. Мы выбрали ограниченный список площадок для интеграции. Это были основные площадки, такие как Яндекс.Директ, Яндекс.Дисплей, RB.Mail, MyTarget, Adwords, DBM, VK, FB, и основные adserving системы Adriver и Weborama.
Для доступа к статистике на площадках через API мы использовали единый аккаунт. Менеджер клиентской группы, который хотел использовать автоматический сбор статистики по рекламной кампании, должен был сначала делегировать доступ к нужным рекламным кампаниям на площадках на аккаунт платформы.
Далее пользователь системы DANBo должен был загрузить в систему Excel файл определенного формата, в котором была прописана вся информация о размещении (рекламная кампания, площадка, формат, период размещения, плановые показатели, бюджет и т.д.) и идентификаторы соответствующих рекламных кампаний на площадках и счётчиков в adserving системах.
Выглядело это, честно говоря, ужасающе:

Загруженные данные сохранялись в базу данных, а потом отдельные сервисы собирали из них идентификаторы кампаний на площадках и загружали по ним статистику.
Для каждой площадки был написан отдельный windows сервис, который раз в сутки ходил под одним служебным аккаунтом в API площадки и выгружал статистику по заданным идентификаторам кампаний. Аналогично происходило и с adserving системами.
Загруженные данные отображались на интерфейсе в виде небольшого самописного дашборда:
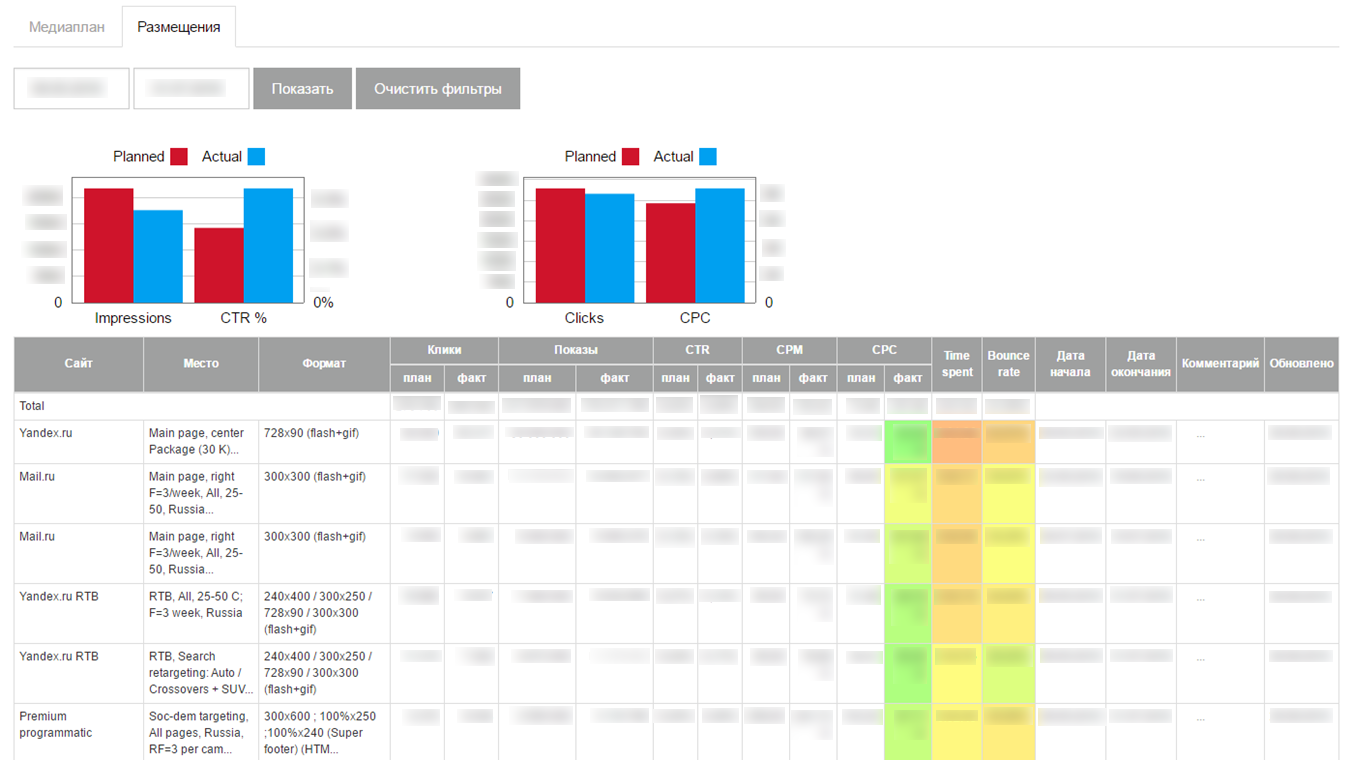
Неожиданно для нас самих MVP заработал и стал загружать актуальную статистику по рекламным кампаниям в Интернете. Мы внедрили систему на нескольких клиентах, но при попытке масштабирования наткнулись на серьезные проблемы:
Это натолкнуло нас на мысль, что первоисточником информации о размещении должна служить наша 1С система, в которую все данные вносятся аккуратно и в срок (тут дело в том, что на основании данных 1С формируются счета, поэтому корректное внесение данных в 1С стоит у всех в KPI). Так появилась новая концепция системы…
Первое, что мы решили сделать, это выделить систему сбора статистики по рекламным кампаниям в Интернет в отдельный продукт — D1.Digital.
В новой концепции мы решили загружать в D1.Digital информацию по рекламным кампаниям и размещениям внутри них из 1С, а потом подтягивать к этим размещениям статистику с площадок и из AdServing систем. Это должно было значительно упростить жизнь пользователям (и, как водится, добавить работы разработчикам) и уменьшить объем поддержки.
Первая проблема, с которой мы столкнулись, была организационного характера и связана с тем, что мы не смогли найти ключ или признак, по которому можно бы было сопоставить сущности из разных систем с кампаниями и размещениями из 1С. Дело в том, что процесс в нашей компании устроен так, что рекламные кампании в разные системы заносятся разными людьми (медиапленнеры, баинг и др.).
Чтобы решить эту проблему, нам пришлось изобрести уникальный хэшированный ключ, DANBoID, который бы связывал сущности в разных системах воедино, и который можно было бы довольно легко и однозначно идентифицировать в загружаемых наборах данных. Этот идентификатор генерируется во внутренней 1С системе для каждого отдельного размещения и прокидывается в кампании, размещения и счётчики на всех площадках и во всех AdServing системах. Внедрение практики проставления DANBoID во все размещения заняло определенное время, но мы с этим справились :)
Дальше мы выяснили, что далеко не у всех площадок есть API для автоматического сбора статистики, и даже у тех, у которых API есть, он возвращает не все нужные данные.
На этом этапе мы решили значительно сократить список площадок для интеграции и сосредоточиться на основных площадках, которые задействованы в подавляющем большинстве рекламных кампаний. В этот список попали все крупнейшие игроки рекламного рынка (Google, Яндекс, Mail.ru), социальные сети (VK, Facebook, Twitter), основные системы AdServing и аналитики (DCM, Adriver, Weborama, Google Analytics) и другие площадки.
У основной массы выбранных нами площадок был API, который отдавал необходимые нам метрики. В тех случаях, когда API не было, либо в нём не было нужных данных, для загрузки данных мы использовали отчёты, ежедневно приходящие на служебную почту (в одних системах есть возможность настройки таких отчётов, в других согласовали разработку таких отчётов для нас).
При анализе данных с разных площадок мы выяснили, что иерархия сущностей не одинакова в разных системах. Более того, из разных систем информацию необходимо загружать в разной детализации.
Для решения этой проблемы была разработана концепция SubDANBoID. Идея SubDANBoID довольно проста, мы помечаем основную сущность кампании на площадке сгенерированным DANBoID, а все вложенные сущности мы выгружаем с уникальными идентификаторами площадки и формируем SubDANBoID по принципу DANBoID + идентификатор вложенной сущности первого уровня + идентификатор вложенной сущности второго уровня +… Такой подход позволил нам связать рекламные кампании в разных системах и выгрузить детализированную статистику по ним.
Также нам пришлось решать проблему доступа к кампаниям на разных площадках. Как мы уже писали выше, механизм делегирования доступа к кампании на отдельный технический аккаунт не всегда применим. Поэтому нам пришлось разработать инфраструктуру для автоматической авторизации через OAuth с использованием токенов и механизмы обновления этих токенов.
Дальше в статье попробуем более подробно описать архитектуру решения и технические детали реализации.
Начиная реализацию нового продукта, мы понимали, что сразу нужно предусмотреть возможность подключения новых площадок, поэтому решили пойти по пути микросервисной архитектуры.
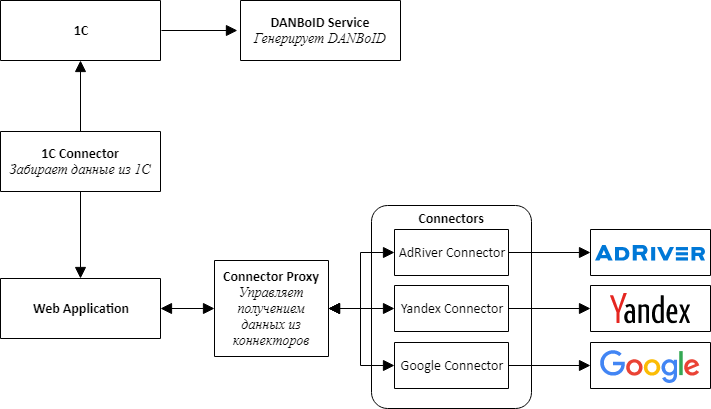
При проектировании архитектуры мы выделили в отдельные сервисы коннекторы ко всем внешним системам — 1С, рекламным площадкам и adserving системам.
Основная идея состоит в том, что все коннекторы к площадкам имеют одинаковое API и представляют собой адаптеры, приводящие API площадок к удобному нам интерфейсу.
В центре нашего продукта — веб-приложение, которое представляет собой монолит, который спроектирован таким образом, чтобы его можно было легко разобрать на сервисы. Это приложение отвечает за обработку загруженных данных, сопоставление статистики из разных систем и представление ее пользователям системы.
Для общения коннекторов с веб-приложением пришлось создать дополнительный сервис, который мы назвали Connector Proxy. Он выполняет функции Service Discovery и Task Scheduler. Этот сервис каждую ночь запускает задачи сбора данных для каждого коннектора. Написать сервис-прослойку было проще, чем подключать брокер сообщений, а для нас было важно получить результат как можно быстрей.
Для простоты и скорости разработки мы также решили, что все сервисы будут представлять собой Web API. Это позволило быстро собрать proof-of-concept и проверить, что вся конструкция работает.
Отдельной, достаточно сложной, задачей оказалась настройка доступов для сбора данных из разных кабинетов, которая, как мы решили, должна осуществляться пользователями через веб-интерфейс. Она состоит из двух отдельных шагов: сначала пользователь через OAuth добавляет токен для доступа к аккаунту, а потом настраивает сбор данных для клиента из определенного кабинета. Получение токена через OAuth необходимо, потому что, как мы уже писали, не всегда возможно делегировать доступ к нужному кабинету на площадке.
Чтобы создать универсальный механизм выбора кабинета с площадок, нам пришлось добавить в API коннекторов метод, отдающий JSON Schema, которая рендерится в форму при помощи модифицированного компонента JSONEditor. Так пользователи смогли выбирать аккаунты, из которых необходимо загружать данные.
Чтобы соблюдать лимиты запросов, существующие на площадках, мы объединяем запросы по настройкам в рамках одного токена, но разные токены можем обрабатывать параллельно.
В качестве хранилища для загружаемых данных как для веб-приложения, так и для коннекторов мы выбрали MongoDB, что позволило не сильно заморачиваться по поводу структуры данных на начальных этапах разработки, когда объектная модель приложения меняется через день.
Скоро мы выяснили, что не все данные хорошо ложатся в MongoDB и, например, статистику по дням удобнее хранить в реляционной базе. Поэтому для коннекторов, структура данных которых больше подходит под реляционную БД, в качестве хранилища мы начали использовать PostgreSQL или MS SQL Server.
Выбранная архитектура и технологии позволили нам относительно быстро построить и запустить продукт D1.Digital. За два года развития продукта мы разработали 23 коннектора к площадкам, получили бесценный опыт работы со сторонними API, научились обходить подводные камни разных площадок, которые у каждой оказались свои, способствовали развитию API как минимум 3 площадок, автоматически загрузили информацию по почти 15 000 кампаний и по более чем 80 000 размещений, собрали много обратной связи от пользователей по работе продукта и успели несколько раз поменять основной процесс работы продукта, основываясь на этой обратной связи.
Прошло два года после старта разработки D1.Digital. Постоянный рост нагрузки на систему и появление все новых источников данных постепенно вскрыли проблемы в существующей архитектуре решения.
Первая проблема связана с объемом данных, загружаемых с площадок. Мы столкнулись с тем, что сбор и обновление всех необходимых данных с самых больших площадок стало занимать слишком много времени. Например, сбор данных по adserving системе AdRiver, с помощью которой мы отслеживаем статистику по большей части размещений, занимает около 12 часов.
Чтобы решить эту проблему, мы начали использовать всевозможные отчеты для загрузки данных с площадок, пытаемся развивать вместе с площадками их API, чтобы скорость его работы удовлетворяла нашим потребностям, и параллелить загрузку данных, на сколько это возможно.
Другая проблема связана с обработкой загруженных данных. Сейчас при поступлении новой статистики по размещению, запускается многоступенчатый процесс пересчета метрик, который включает в себя загрузку сырых данных, просчет агрегированных метрик по каждой площадке, сопоставление данных из разных источников между собой и расчет сводных метрик по кампании. Это вызывает большую нагрузку на веб-приложение, которое производит все расчеты. Несколько раз приложение в процессе пересчета съедало всю память на сервере, порядка 10-15 Гб, что самым пагубным образом сказывалось на работе пользователей с системой.
Обозначенные проблемы и грандиозные планы на дальнейшее развитие продукта привели нас к необходимости пересмотреть архитектуру приложения.
Начали мы с коннекторов.
Мы заметили, что все коннекторы работают по одной модели, поэтому построили фреймворк-конвейер, в котором для создания коннектора нужно было только запрограммировать логику шагов, остальное было универсальным. Если какой-то коннектор требует доработки, то мы одновременной с доработкой коннектора сразу переводим его на новый фреймворк.
Параллельно мы начали размещать коннекторы в докер и Kubernetes.
Переезд в Kubernetes планировали довольно долго, экспериментировали с настройками CI/CD, но переезжать начали только тогда, когда один коннектор из-за ошибки стал отъедать более 20 Гб памяти на сервере, практически убивая остальные процессы. На время расследования коннектор переселили в кластер Kubernetes, где он в итоге и остался, даже когда ошибка была исправлена.
Довольно быстро мы поняли, что Kubernetes это удобно, и за полгода перенесли в кластер продакшена 7 коннекторов и Connectors Proxy, которые потребляют больше всего ресурсов.
Вслед за коннекторами мы решили менять архитектуру остального приложения.
Основной проблемой было то, что данные приходят из коннекторов в прокси большими пачками, а потом бьются по DANBoID и отдаются в центральное web приложение для обработки. Из-за большого количества пересчетов метрик возникает большая нагрузка на приложение.
Также оказалось довольно сложно мониторить статусы отдельных заданий на сбор данных и передавать ошибки, происходящие внутри коннекторов, в центральное web приложение, чтобы пользователи могли видеть, что происходит, и из-за чего не собираются данные.
Для решения этих проблем мы разработали архитектуру 2.0.
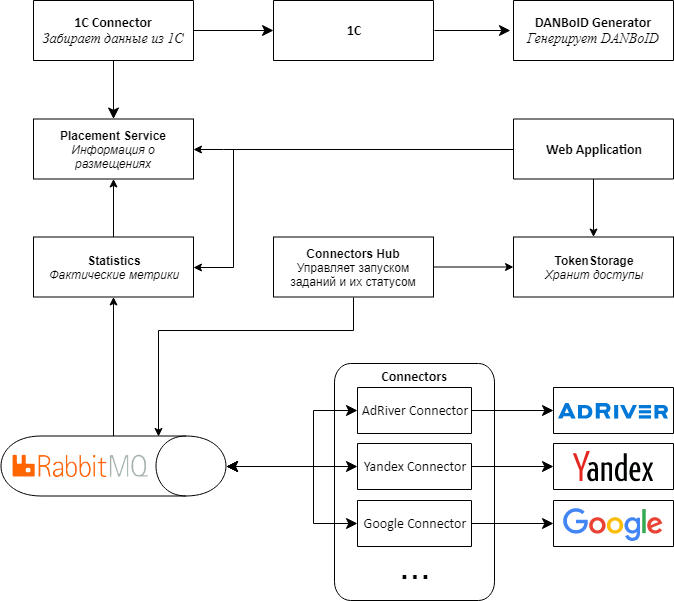
Главное отличие новой версии архитектуры состоит в том, что вместо Web API мы используем RabbitMQ и библиотеку MassTransit для обмена сообщениями между сервисами. Для этого пришлось практически полностью переписать Connectors Proxy, сделав из него Connectors Hub. Название поменяли потому, что основная роль сервиса теперь не в пробросе запросов в коннекторы и обратно, а в управлении сбором метрик с коннекторов.
Из центрального web приложения мы выделили в отдельные сервисы информацию о размещениях и статистику с площадок, что дало возможность избавиться от лишних пересчетов и на уровне размещений хранить только уже рассчитанную и агрегированную статистику. Также мы переписали и оптимизировали логику расчета основных статистик на основе сырых данных.
Параллельно мы переносим все сервисы и приложения в докер и Kubernetes, чтобы решение проще масштабировалось и им было удобно управлять.
Proof-of-concept архитектуры 2.0 продукта D1.Digital готов и работает в тестовом окружении с ограниченным набором коннекторов. Дело за малым — переписать еще 20 коннекторов на новую платформу, протестировать, что данные корректно загружаются, а все метрики правильно считаются, и выкатить всю конструкцию в продакшн.
На самом деле, этот процесс будет происходить постепенно и нам придется оставить обратную совместимость со старыми API, чтобы все продолжало работать.
В ближайших наших планах стоит разработка новых коннекторов, интеграция с новыми системами и добавление дополнительных метрик в набор данных, выгружаемых из подключенных площадок и adserving систем.
Также планируем перенести все приложения, в том числе и центральное web приложение, в докер и Kubernetes. В сочетании с новой архитектурой, это позволит заметно упростить развертывание, мониторинг и контроль потребляемых ресурсов.
Еще есть идея поэкспериментировать с выбором БД для хранения статистики, которая сейчас хранится в MongoDB. Несколько новых коннекторов мы уже перевели на SQL-базы, но там разница почти незаметна, а для агрегированной статистики по дням, которую можно запрашивать за произвольный период, выигрыш может быть достаточно серьезным.
В общем, планы грандиозные, двигаемся дальше :)
Авторы статьи R&D Dentsu Aegis Network Russia: Георгий Остапенко (shmiigaa), Михаил Коцик (hitexx)
Источник
Коммуникационная группа Dentsu Aegis Network Russia — крупнейший игрок на рекламном digital рынке и активно инвестирует в технологии, пытаясь в оптимизировать и автоматизировать свои бизнес-процессы. Одной из нерешенных задач рынка интернет-рекламы стала задача сбора статистики по рекламным кампаниям с разных интернет-площадок. Решение этой задачи в итоге вылилось в создание продукта D1.Digital (читать как ДиВан), о разработке которого мы и хотим рассказать.
Зачем?
1. На момент старта проекта на рынке не было ни одного готового продукта, решающего задачу автоматизации сбора статистики по рекламным кампаниям. Значит, никто кроме нас самих не закроет наши потребности.
Такие сервисы, как Improvado, Roistat, Supermetrics, SegmentStream, предлагают интеграцию с площадками, социальными сетями и Google Analitycs, а также дают возможность строить аналитические дашборды для удобного анализа и контроля рекламных кампаний. Перед тем, как начать развивать свой продукт, мы попробовали использовать в работе некоторые из этих систем для сбора данных с площадок, но, к сожалению, они не смогли решить наших задач.
Главной проблемой стало то, что тестируемые продукты отталкивались от источников данных, отображая статистику размещений в разрезах по площадкам, и не давали возможность агрегировать статистику по рекламным кампаниям. Такой подход не позволял увидеть статистику из разных площадок в одном месте и проанализировать состояние кампании целиком.
Другим фактором стало то, что на начальных этапах продукты были ориентированы на западный рынок и не поддерживал интеграцию с российскими площадками. А по тем площадкам, с которыми была реализована интеграция, не всегда выгружались все необходимые метрики с достаточной детализацией, а интеграция не всегда была удобной и прозрачной, особенно когда нужно было получить что-то, чего нет в интерфейсе системы.
В общем, мы решили не подстраиваться под сторонние продукты, а занялись разработкой своего…
2. Рынок интернет-рекламы растет из года в год, и в 2018 году по объему рекламных бюджетов он обогнал традиционно крупнейший рынок ТВ-рекламы. Значит, есть масштаб.
3. В отличие от рынка ТВ-рекламы, где продажа коммерческой рекламы монополизирована, в Интернете работает масса отдельных владельцев рекламного инвентаря разной величины со своими рекламными кабинетами. Так как рекламная кампания, как правило, идёт сразу на нескольких площадках, то для понимания состояния рекламной кампании, надо собрать отчеты со всех площадок и свести их в один большой отчет, который покажет картинку целиком. Значит, есть потенциал для оптимизации.
4. Нам казалось, что у владельцев рекламного инвентаря в интернете уже есть инфраструктура для сбора статистики и ее отображения в рекламных кабинетах, и они смогут предоставить API к этим данным. Значит, есть техническая возможность реализации. Скажем сразу, что оказалось не все так просто.
В общем, все предпосылки для реализации проекта были для нас очевидны, и мы побежали воплощать проект в жизнь…
Грандиозный план
Для начала мы сформировали видение идеальной системы:
- В нее должны автоматически загружаться рекламные кампании из корпоративной системы 1С с их названиями, периодами, бюджетами и размещениями по разнообразным площадкам.
- Для каждого размещения внутри рекламной кампании должна автоматически загружаться вся возможная статистика с площадок, на которых идет размещение, такая как количество показов, кликов, просмотров и прочее.
- Некоторые рекламные кампании отслеживаются с помощью стороннего мониторинга так называемыми adserving системами, такими как Adriver, Weborama, DCM и т.д. Также есть индустриальный измеритель Интернета в России — компания Mediascope. Данные независимого и индустриального мониторингов по нашей задумке также должны автоматически подгружаться к соответствующим рекламным кампаниям.
- Большинство рекламных кампаний в Интернет нацелены на определённые целевые действия (покупка, звонок, запись на тест-драйв и т.д.), которые отслеживаются с помощью Google Analytics, и статистика по которым тоже важна для понимания состояния кампании и должна загружаться в наш инструмент.
Первый блин комом
Учитывая нашу приверженность гибким принципам разработки ПО (agile, все дела), мы решили сначала разработать MVP и далее двигаться к намеченной цели итеративно.
MVP мы решили строить на основе нашего продукта DANBo (Dentsu Aegis Network Board), представляющего из себя web приложение с общей информацией по рекламным кампаниям наших клиентов.
Для MVP проект был максимально упрощен с точки зрения реализации. Мы выбрали ограниченный список площадок для интеграции. Это были основные площадки, такие как Яндекс.Директ, Яндекс.Дисплей, RB.Mail, MyTarget, Adwords, DBM, VK, FB, и основные adserving системы Adriver и Weborama.
Для доступа к статистике на площадках через API мы использовали единый аккаунт. Менеджер клиентской группы, который хотел использовать автоматический сбор статистики по рекламной кампании, должен был сначала делегировать доступ к нужным рекламным кампаниям на площадках на аккаунт платформы.
Далее пользователь системы DANBo должен был загрузить в систему Excel файл определенного формата, в котором была прописана вся информация о размещении (рекламная кампания, площадка, формат, период размещения, плановые показатели, бюджет и т.д.) и идентификаторы соответствующих рекламных кампаний на площадках и счётчиков в adserving системах.
Выглядело это, честно говоря, ужасающе:
Загруженные данные сохранялись в базу данных, а потом отдельные сервисы собирали из них идентификаторы кампаний на площадках и загружали по ним статистику.
Для каждой площадки был написан отдельный windows сервис, который раз в сутки ходил под одним служебным аккаунтом в API площадки и выгружал статистику по заданным идентификаторам кампаний. Аналогично происходило и с adserving системами.
Загруженные данные отображались на интерфейсе в виде небольшого самописного дашборда:
Неожиданно для нас самих MVP заработал и стал загружать актуальную статистику по рекламным кампаниям в Интернете. Мы внедрили систему на нескольких клиентах, но при попытке масштабирования наткнулись на серьезные проблемы:
- Главная проблема была в трудоёмкости подготовки данных для загрузки в систему. Также данные по размещению надо было приводить к строго фиксированному формату перед загрузкой. В файл для загрузки нужно было прописывать идентификаторы сущностей из разных площадок. Мы столкнулись с тем, что технически неподготовленным пользователям очень сложно объяснить, где найти эти идентификаторы на площадке и куда в файле их нужно проставить. Учитывая количество сотрудников в подразделениях, ведущих кампании на площадках, и текучку, это вылилось в огромный объем поддержки на нашей стороне, что нас категорически не устраивало.
- Другой проблемой было то, что не на всех рекламных площадках были механизмы делегирования доступа к рекламным кампаниям на другие аккаунты. Но даже если механизм делегирования был доступен, не все рекламодатели были готовы предоставлять доступ к своим кампаниям сторонним аккаунтам.
- Немаловажным стал фактор негодования, которое у пользователей вызывало то, что все плановые показатели и детали размещения, которые они уже вносят в нашу учётную 1С систему, они должны повторно вносить и в DANBo.
Это натолкнуло нас на мысль, что первоисточником информации о размещении должна служить наша 1С система, в которую все данные вносятся аккуратно и в срок (тут дело в том, что на основании данных 1С формируются счета, поэтому корректное внесение данных в 1С стоит у всех в KPI). Так появилась новая концепция системы…
Концепция
Первое, что мы решили сделать, это выделить систему сбора статистики по рекламным кампаниям в Интернет в отдельный продукт — D1.Digital.
В новой концепции мы решили загружать в D1.Digital информацию по рекламным кампаниям и размещениям внутри них из 1С, а потом подтягивать к этим размещениям статистику с площадок и из AdServing систем. Это должно было значительно упростить жизнь пользователям (и, как водится, добавить работы разработчикам) и уменьшить объем поддержки.
Первая проблема, с которой мы столкнулись, была организационного характера и связана с тем, что мы не смогли найти ключ или признак, по которому можно бы было сопоставить сущности из разных систем с кампаниями и размещениями из 1С. Дело в том, что процесс в нашей компании устроен так, что рекламные кампании в разные системы заносятся разными людьми (медиапленнеры, баинг и др.).
Чтобы решить эту проблему, нам пришлось изобрести уникальный хэшированный ключ, DANBoID, который бы связывал сущности в разных системах воедино, и который можно было бы довольно легко и однозначно идентифицировать в загружаемых наборах данных. Этот идентификатор генерируется во внутренней 1С системе для каждого отдельного размещения и прокидывается в кампании, размещения и счётчики на всех площадках и во всех AdServing системах. Внедрение практики проставления DANBoID во все размещения заняло определенное время, но мы с этим справились :)
Дальше мы выяснили, что далеко не у всех площадок есть API для автоматического сбора статистики, и даже у тех, у которых API есть, он возвращает не все нужные данные.
На этом этапе мы решили значительно сократить список площадок для интеграции и сосредоточиться на основных площадках, которые задействованы в подавляющем большинстве рекламных кампаний. В этот список попали все крупнейшие игроки рекламного рынка (Google, Яндекс, Mail.ru), социальные сети (VK, Facebook, Twitter), основные системы AdServing и аналитики (DCM, Adriver, Weborama, Google Analytics) и другие площадки.
У основной массы выбранных нами площадок был API, который отдавал необходимые нам метрики. В тех случаях, когда API не было, либо в нём не было нужных данных, для загрузки данных мы использовали отчёты, ежедневно приходящие на служебную почту (в одних системах есть возможность настройки таких отчётов, в других согласовали разработку таких отчётов для нас).
При анализе данных с разных площадок мы выяснили, что иерархия сущностей не одинакова в разных системах. Более того, из разных систем информацию необходимо загружать в разной детализации.
Для решения этой проблемы была разработана концепция SubDANBoID. Идея SubDANBoID довольно проста, мы помечаем основную сущность кампании на площадке сгенерированным DANBoID, а все вложенные сущности мы выгружаем с уникальными идентификаторами площадки и формируем SubDANBoID по принципу DANBoID + идентификатор вложенной сущности первого уровня + идентификатор вложенной сущности второго уровня +… Такой подход позволил нам связать рекламные кампании в разных системах и выгрузить детализированную статистику по ним.
Также нам пришлось решать проблему доступа к кампаниям на разных площадках. Как мы уже писали выше, механизм делегирования доступа к кампании на отдельный технический аккаунт не всегда применим. Поэтому нам пришлось разработать инфраструктуру для автоматической авторизации через OAuth с использованием токенов и механизмы обновления этих токенов.
Дальше в статье попробуем более подробно описать архитектуру решения и технические детали реализации.
Архитектура решения 1.0
Начиная реализацию нового продукта, мы понимали, что сразу нужно предусмотреть возможность подключения новых площадок, поэтому решили пойти по пути микросервисной архитектуры.
При проектировании архитектуры мы выделили в отдельные сервисы коннекторы ко всем внешним системам — 1С, рекламным площадкам и adserving системам.
Основная идея состоит в том, что все коннекторы к площадкам имеют одинаковое API и представляют собой адаптеры, приводящие API площадок к удобному нам интерфейсу.
В центре нашего продукта — веб-приложение, которое представляет собой монолит, который спроектирован таким образом, чтобы его можно было легко разобрать на сервисы. Это приложение отвечает за обработку загруженных данных, сопоставление статистики из разных систем и представление ее пользователям системы.
Для общения коннекторов с веб-приложением пришлось создать дополнительный сервис, который мы назвали Connector Proxy. Он выполняет функции Service Discovery и Task Scheduler. Этот сервис каждую ночь запускает задачи сбора данных для каждого коннектора. Написать сервис-прослойку было проще, чем подключать брокер сообщений, а для нас было важно получить результат как можно быстрей.
Для простоты и скорости разработки мы также решили, что все сервисы будут представлять собой Web API. Это позволило быстро собрать proof-of-concept и проверить, что вся конструкция работает.
Отдельной, достаточно сложной, задачей оказалась настройка доступов для сбора данных из разных кабинетов, которая, как мы решили, должна осуществляться пользователями через веб-интерфейс. Она состоит из двух отдельных шагов: сначала пользователь через OAuth добавляет токен для доступа к аккаунту, а потом настраивает сбор данных для клиента из определенного кабинета. Получение токена через OAuth необходимо, потому что, как мы уже писали, не всегда возможно делегировать доступ к нужному кабинету на площадке.
Чтобы создать универсальный механизм выбора кабинета с площадок, нам пришлось добавить в API коннекторов метод, отдающий JSON Schema, которая рендерится в форму при помощи модифицированного компонента JSONEditor. Так пользователи смогли выбирать аккаунты, из которых необходимо загружать данные.
Чтобы соблюдать лимиты запросов, существующие на площадках, мы объединяем запросы по настройкам в рамках одного токена, но разные токены можем обрабатывать параллельно.
В качестве хранилища для загружаемых данных как для веб-приложения, так и для коннекторов мы выбрали MongoDB, что позволило не сильно заморачиваться по поводу структуры данных на начальных этапах разработки, когда объектная модель приложения меняется через день.
Скоро мы выяснили, что не все данные хорошо ложатся в MongoDB и, например, статистику по дням удобнее хранить в реляционной базе. Поэтому для коннекторов, структура данных которых больше подходит под реляционную БД, в качестве хранилища мы начали использовать PostgreSQL или MS SQL Server.
Выбранная архитектура и технологии позволили нам относительно быстро построить и запустить продукт D1.Digital. За два года развития продукта мы разработали 23 коннектора к площадкам, получили бесценный опыт работы со сторонними API, научились обходить подводные камни разных площадок, которые у каждой оказались свои, способствовали развитию API как минимум 3 площадок, автоматически загрузили информацию по почти 15 000 кампаний и по более чем 80 000 размещений, собрали много обратной связи от пользователей по работе продукта и успели несколько раз поменять основной процесс работы продукта, основываясь на этой обратной связи.
Архитектура решения 2.0
Прошло два года после старта разработки D1.Digital. Постоянный рост нагрузки на систему и появление все новых источников данных постепенно вскрыли проблемы в существующей архитектуре решения.
Первая проблема связана с объемом данных, загружаемых с площадок. Мы столкнулись с тем, что сбор и обновление всех необходимых данных с самых больших площадок стало занимать слишком много времени. Например, сбор данных по adserving системе AdRiver, с помощью которой мы отслеживаем статистику по большей части размещений, занимает около 12 часов.
Чтобы решить эту проблему, мы начали использовать всевозможные отчеты для загрузки данных с площадок, пытаемся развивать вместе с площадками их API, чтобы скорость его работы удовлетворяла нашим потребностям, и параллелить загрузку данных, на сколько это возможно.
Другая проблема связана с обработкой загруженных данных. Сейчас при поступлении новой статистики по размещению, запускается многоступенчатый процесс пересчета метрик, который включает в себя загрузку сырых данных, просчет агрегированных метрик по каждой площадке, сопоставление данных из разных источников между собой и расчет сводных метрик по кампании. Это вызывает большую нагрузку на веб-приложение, которое производит все расчеты. Несколько раз приложение в процессе пересчета съедало всю память на сервере, порядка 10-15 Гб, что самым пагубным образом сказывалось на работе пользователей с системой.
Обозначенные проблемы и грандиозные планы на дальнейшее развитие продукта привели нас к необходимости пересмотреть архитектуру приложения.
Начали мы с коннекторов.
Мы заметили, что все коннекторы работают по одной модели, поэтому построили фреймворк-конвейер, в котором для создания коннектора нужно было только запрограммировать логику шагов, остальное было универсальным. Если какой-то коннектор требует доработки, то мы одновременной с доработкой коннектора сразу переводим его на новый фреймворк.
Параллельно мы начали размещать коннекторы в докер и Kubernetes.
Переезд в Kubernetes планировали довольно долго, экспериментировали с настройками CI/CD, но переезжать начали только тогда, когда один коннектор из-за ошибки стал отъедать более 20 Гб памяти на сервере, практически убивая остальные процессы. На время расследования коннектор переселили в кластер Kubernetes, где он в итоге и остался, даже когда ошибка была исправлена.
Довольно быстро мы поняли, что Kubernetes это удобно, и за полгода перенесли в кластер продакшена 7 коннекторов и Connectors Proxy, которые потребляют больше всего ресурсов.
Вслед за коннекторами мы решили менять архитектуру остального приложения.
Основной проблемой было то, что данные приходят из коннекторов в прокси большими пачками, а потом бьются по DANBoID и отдаются в центральное web приложение для обработки. Из-за большого количества пересчетов метрик возникает большая нагрузка на приложение.
Также оказалось довольно сложно мониторить статусы отдельных заданий на сбор данных и передавать ошибки, происходящие внутри коннекторов, в центральное web приложение, чтобы пользователи могли видеть, что происходит, и из-за чего не собираются данные.
Для решения этих проблем мы разработали архитектуру 2.0.
Главное отличие новой версии архитектуры состоит в том, что вместо Web API мы используем RabbitMQ и библиотеку MassTransit для обмена сообщениями между сервисами. Для этого пришлось практически полностью переписать Connectors Proxy, сделав из него Connectors Hub. Название поменяли потому, что основная роль сервиса теперь не в пробросе запросов в коннекторы и обратно, а в управлении сбором метрик с коннекторов.
Из центрального web приложения мы выделили в отдельные сервисы информацию о размещениях и статистику с площадок, что дало возможность избавиться от лишних пересчетов и на уровне размещений хранить только уже рассчитанную и агрегированную статистику. Также мы переписали и оптимизировали логику расчета основных статистик на основе сырых данных.
Параллельно мы переносим все сервисы и приложения в докер и Kubernetes, чтобы решение проще масштабировалось и им было удобно управлять.
Где мы сейчас
Proof-of-concept архитектуры 2.0 продукта D1.Digital готов и работает в тестовом окружении с ограниченным набором коннекторов. Дело за малым — переписать еще 20 коннекторов на новую платформу, протестировать, что данные корректно загружаются, а все метрики правильно считаются, и выкатить всю конструкцию в продакшн.
На самом деле, этот процесс будет происходить постепенно и нам придется оставить обратную совместимость со старыми API, чтобы все продолжало работать.
В ближайших наших планах стоит разработка новых коннекторов, интеграция с новыми системами и добавление дополнительных метрик в набор данных, выгружаемых из подключенных площадок и adserving систем.
Также планируем перенести все приложения, в том числе и центральное web приложение, в докер и Kubernetes. В сочетании с новой архитектурой, это позволит заметно упростить развертывание, мониторинг и контроль потребляемых ресурсов.
Еще есть идея поэкспериментировать с выбором БД для хранения статистики, которая сейчас хранится в MongoDB. Несколько новых коннекторов мы уже перевели на SQL-базы, но там разница почти незаметна, а для агрегированной статистики по дням, которую можно запрашивать за произвольный период, выигрыш может быть достаточно серьезным.
В общем, планы грандиозные, двигаемся дальше :)
Авторы статьи R&D Dentsu Aegis Network Russia: Георгий Остапенко (shmiigaa), Михаил Коцик (hitexx)
Hektoliss
Вся боль индустрии перед глазами пронеслась :-)