
Nginx — это веб-сервер, который решает десятки бизнес-задач, гибко настраивается, масштабируется и работает почти на всех ОС и платформах. Список функций, возможностей и решаемых проблем из коробки можно расписать в небольшой брошюре. Но порой, ряд бизнес-задач можно решить, только разработав собственные модули для nginx. Это модули, которые ориентированы на бизнес и содержат некоторую бизнес-логику, а не только обобщенное системное решение.

Вообще все в nginx — это модули, которые когда-то кем-то были написаны. Поэтому писать модули под nginx не только можно, но и нужно. Когда это необходимо делать и зачем, расскажет Василий Сошников (dedokOne) на примере нескольких кейсов.
Поговорим о причинах, которые побуждают писать модули на C, об архитектуре и ядре nginx, анатомии HTTP-модулей, о C-модулях, NJS, Lua и nginx.conf. Это важно знать не только тем, кто разрабатывает под nginx, но также тем, кто использует nginx-конфиги, Lua или другой язык внутри nginx.
Примечание: статья написана на основе доклада Василия Сошникова. Доклад постоянно модернизируется и обновляется. Информация в материале довольно техническая и, чтобы извлечь максимум пользы, читателям необходимо иметь опыт работы с кодом nginx на среднем уровне и выше.
Все, чем вы пользуетесь в nginx, — это модули. Каждая директива в nginx-конфигурации — отдельный модуль, который был заботливо написан коллегами из сообщества nginx.
Директивы в nginx.conf — это тоже модули, которые решают определенную задачу. Поэтому в nginx модули это всё. add_header, proxy_pass, любая директива — это модули или комбинации модулей, которые работают по определённым правилам.
Nginx — это фреймворк, в котором есть: Network & File I/O, Shared Memory, Configuration & Scripting. Это огромный пласт низкоуровневых библиотек, на которых можно сделать всё что угодно для работы с сетью, дисками.
Nginx быстрый и стабильный, но сложный. Вы должны писать такой код, чтобы не потерять эти качества nginx. Нестабильный nginx на продакшн — это недовольные клиенты, и все что из этого вытекает.
Преобразование HTTP-протокола в другой протокол. Это основная причина, которая часто мотивирует создавать тот или иной модуль.
Например, модуль memcached_pass преобразовывает HTTP в другой протокол, и можно работать с другими внешними системами. Модуль proxy_pass тоже позволяет преобразовать, правда из HTTP(s) в HTTP(s). Еще хороший пример — это fastcgi_pass.
Это все директивы вида: «пойти на такой-то backend, где не HTTP (но в случае proxy_pass HTTP)».
Динамическая врезка контента: обход AdBlock, врезка рекламы. Например, у нас есть backend и необходимо модифицировать контент, который из него приходит. Например, AdBlock, который анализирует код вставки рекламы, и нам надо с ним бороться — подстроить тем или иным образом.
Другая вещь, которую часто приходится делать для врезки контента — это проблема с кэшированием HLS. Когда параметры кэшируются внутри HLS, то два пользователя могут получить одну и ту же сессию или одни и те же параметры. Оттуда происходит вырезка или добавление некоторых параметров, когда вам надо что-то трекать.
Сборка Clickstream-данных с интернет/мобильных счетчиков. Популярный кейс в моей практике. Чаще всего это делают на nginx, но не на access.log, а чуть интеллектуальнее.
Преобразование разного рода контента. Например, модуль rtmp для позволяет работать не только с rtmp, но и с HLS. Этот модуль может очень многое делать с видео-контентом.
Обобщенная точка авторизации: SEP или Api Gateway. Это тот случай, когда nginx работает как часть инфраструктуры: авторизует, собирает метрики, отправляет данные в мониторинг и ClickStream. Nginx здесь работает как инфраструктурный хаб — единая точка входа для бэкендов.
Обогащение запросов для их последующей трассировки. Современные системы очень сложные, с несколькими типами бэкендов, которые делают разные команды. Как правило, их трудно дебажить, иногда даже трудно понять, откуда пришел запрос и куда он ушел. Чтобы упростить отладку, некоторые крупные компании применяют хитрую методику — добавляют в запросы определенные данные. Пользователь их не увидит, но по этим данным легко проследить путь запроса внутри системы. Это называется трассировкой.
S3-proxy. В этом году я часто вижу, как люди работают со своими объектами через s3. Но это необязательно делать на C-модулях, инфраструктуры достаточно и в nginx. Для решения некоторых из этих задач можно использовать Lua, что-то решается на NJS. Но иногда бывает необходимо писать модули на C.
Есть два критерия, чтобы понять, что пришло время.
Обобщение функционала. Когда вы поняли, что ваш продукт нужен еще кому-то, то контрибьютите это в Open Source, создаете обобщённый функционал, выкладываете и позволяете им пользоваться.
Решение бизнес-задач. Когда бизнес ставит такие требования, которым можно удовлетворить, только написав свой модуль для nginx. Например, динамическую врезку/изменение контента, сбор ClickStream можно сделать на Lua, но, скорее всего, работать нормально не будет.
Я пишу код на nginx уже давно. В продакшн крутятся 9 моих модулей, один из них — в Open Source, в продакшн у многих. Поэтому опыт и понимание у меня есть.
Над ядром выстроены upstreams, HTTP и scripting. Под scripting я подразумеваю nginx.conf, а не NJS. Поверх upstreams, HTTP и scripting уже выстроены HTTP-модули, о которых мы будем говорить.
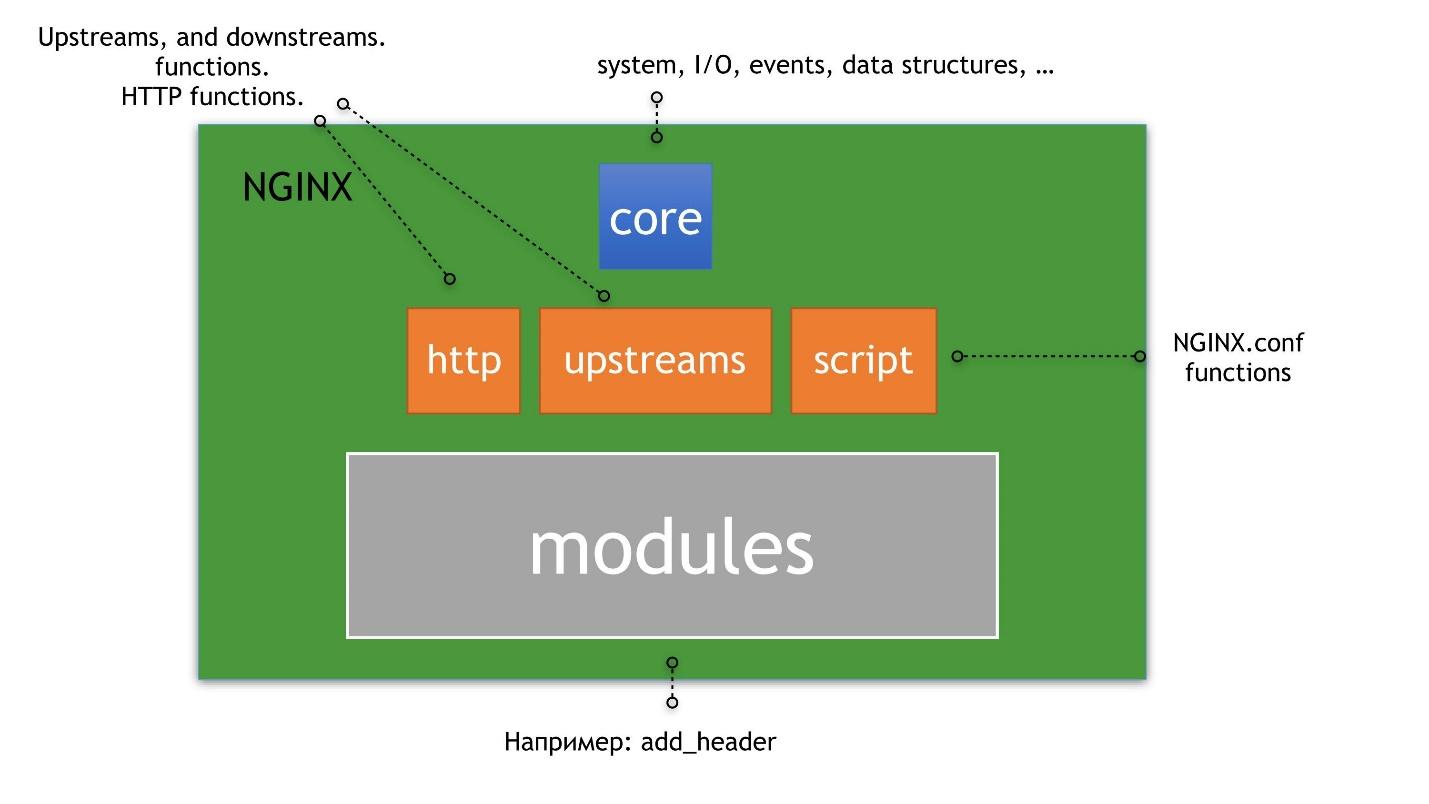
Классический пример upstreams и HTTP это upstream-серверы — директивы внутри конфига. Пример модулей для HTTP — это add_header. Пример scripting — сам файл конфига. В файле указаны модули, из которых состоит nginx, он как-то интерпретируется и что-то позволяет сделать вам, как администратору, или вашему пользователю.
Мы не будем рассматривать core и очень кратко остановимся на upstreams, потому что это отдельная вселенная внутри nginx. Рассказ о них достоин нескольких статей.
Даже если вы не пишете код на C внутри nginx, но его используете, запомните главное правило.

Когда разрабатываете модули или используете какую-то директиву на NJS и Lua, не забывайте, что ваш код может обрушить выполнение этой цепочки.
Ближайшая аналогия Chain of Responsibility — строка кода на Bash:
В коде все достаточно просто: если посередине строки упал AWK, то
Расскажу о каждом из этих типов и их предназначении.
Представим, что у нас есть несколько фаз, начиная от фазы доступа. В каждой фазе несколько модулей. Например, фаза ACCESS делится на соединение, запрос к nginx, проверка авторизации пользователя. Каждый модуль — это ячейка в цепочке. Таких модулей в фазе может быть бесконечное множество.
Последний, завершающий handler — это CONTENT-фаза, в которой происходит выдача контента по запросу.
Фазы можно перезаписать, добавить свой собственный обработчик. Не все из них нужны в реальной жизни, если вы не разработчик именно nginx core. Поэтому я не буду рассказывать о каждой фазе, а только об основных, которые я использовал.
Основная — это ACCESS_PHASE. Особенно пригодится, чтобы добавить в nginx свою авторизацию — для проверки исполнения запроса с точки зрения доступа.
Следующие важные фазы, которые я часто эксплуатирую — это фазы преконтента и контента. PRECONTENT_PHASE позволяет собирать метрики о контенте, который вот-вот отправится как ответ клиенту. CONTENT_PHASE позволяет генерировать собственный уникальный контент на основе чего-то.
Последняя фаза, которую часто использую — это фаза логирования LOG_PHASE. В ней, кстати, работает директива ACCESS_LOG. У фазы логирования дичайшие ограничения, которые меня сводят с ума: нельзя использовать subrequest и вообще нельзя использовать никакие request. У вас уже контент ушел пользователю, а handlers, posthandlers и какие-либо subrequest’ы исполнены не будут.
Объясню, почему это напрягает. Допустим, когда вы хотите скрестить nginx и Kafka в фазе логирования. В этой фазе уже все выполнилось: есть подсчитанный размер контента, статус, все данные, но вы не можете это сделать subrequest’ом. Они там не работают. Приходится писать на голых сокетах в фазе логирования, чтобы отправить данные в Kafka.
Есть два типа фильтров: Body filters и Headers filters.
Пример Body filter — это gzip filter module. Зачем нужны Body filters? Представьте что у вас есть некий proxy_pass, и вы хотите как-то преобразовать контент либо его проанализировать. В таком случае вы должны использовать Body filter.
Он работает так: к вам приходит много чанков, вы с ними что-то делаете, смотрите содержимое, агрегируете и т.д. Но в фильтре тоже есть существенные ограничения. Например, если вы решили изменить тело — сделать врезку или вырезку из тела ответа, помните, что заменятся атрибуты HTTP, например, контент-лента. Это может привести к странным эффектам, если не предусмотреть ограничения и не отразить правильно у себя в коде.
Пример Header filter — add_header, которым все пользовались. Алгоритм работы как в Body filter. Клиенту готовится response, и add_header фильтр позволяет что-то там сделать: добавить header, удалить header, заменить header, отправить subrequest.
Кстати, в Body filter и в Header filter subrequest’ы доступны, там можно даже отправлять внутренние идентификации на дополнительный location.
Это самый сложный и неоднозначный тип модулей, которые позволяют проксировать запросы во внешние системы, например, преобразовывать HTTP в другой протокол. Примеры: proxy_pass, redis_pass, tnt_pass.
Proxy — это интерфейс, который предложили core-разработчики nginx, чтобы писать proxy-модули проще. Если это делать классическим путем, то для такой proxy будут выполняться PHASES handlers, filters, Balancers. Однако, если протокол, в который вы хотите преобразовать HTTP, как-то отличается от классики, то начинаются большие проблемы. API для proxy, который дает nginx, просто не подходит — придется изобретать с нуля этот proxy-модуль.
Хороший пример такого модуля — postgres_pass. Он позволяет nginx общаться с PostgreSQL. В модуле вообще не используется тот интерфейс, которые разработали в nginx — там свой собственный путь.
Задача Load balancers очень простая — работать в режиме round-robin. Представьте, что у вас есть секция upstream, в ней какие-то серверы, вы указываете веса и способы балансировки. Это типичный Load balancer.
Этот режим не всегда подходит. Поэтому был разработан Ketama CHash module, где условно можно прибывать запрос по консистентному хэшу к какому-то серверу. Порой это удобно. Nginx Lua предлагает balancer_by_lua. На Lua вообще можно написать любой балансер.
Дальше будет мое абсолютно субъективное мнение о разработке С-модулей. Для начала — мои субъективные правила.
Модуль начинается с nginx.conf-директив. Даже если вы делаете С-модуль, который будет эксплуатироваться только в вашей компании, всегда думайте о директивах. Начинайте проектировать модуль именно с них, потому что это то, с чем будет общаться системный администратор. Это важно — согласуйте все нюансы с ним или с человеком, который будет эксплуатировать ваш С-модуль. NGINX — это известный продукт, его директивы подчиняются определенным законам, которые знают системные администраторы. Поэтому всегда об этом думайте.
Используйте nginx сode style. Представьте, что ваш модуль будет поддерживать другой человек. Если он уже знаком с nginx и с его сode style, ему будет в разы проще прочитать и понять ваш код.
Недавно мой хороший знакомый из Германии попросил помочь ему разобраться с багом внутри его nginx-кода. Не знаю, по какому code style он его писал, но я даже прочитать код нормально не смог.
Используйте правильный memory pool.Всегда помните об этом, даже если у вас много опыта в nginx. Типичная ошибка начинающего разработчика модулей на С для nginx — взять не тот pool.
Небольшая предыстория: nginx в целом использует идеологию слабых аллокаторов. Там можно пользоваться malloc, но не рекомендуется. Там есть свои slabs, свой memory allocator, надо пользоваться им. Соответственно, у каждого объекта есть ссылка на его pool, и этим pool’ом как раз надо пользоваться. Типичная ошибка начинающего, использовать в header filter не pool request, а pool connection. Это означает, что если у нас keep-alive connection, pool будет пухнуть, пока случится out of memory либо другие побочные эффекты. Поэтому это важно.
Более того, такие ошибки крайне сложно дебажить. Valgrind («сишники» поймут) со slab allocation не работает — он покажет странную картину.
Не используйте блокирующее I/O. Типичная ошибка тех, кто хочет быстрее применить что-то внешнее — использовать блокирующий I/O и блокирующие сокеты. В nginx этого делать никогда нельзя — в нем много процессов, но каждый процесс использует один поток.
Можно сделать многопоточность, но, как правило, от этого только хуже. Если вы используете в такой архитектуре блокирующее I/O, то все будут ждать этого блокирующего куска.
Расшифрую то, о чем я сказал выше.
Все директивы в nginx живут в разных контекстах и разных скопах. Директива add_header может работать на HTTP-level, на location-level, на location-if-level. Это все, как правило, описано в документации.
Если вы указываете host port чего-то, то наоборот — поднимается pool сокетов. Это должно быть указано один раз.
Вообще я бы запретил любой мёржинг — вам это просто не нужно. Поэтому вы должны всегда четко определиться, в каких скопах nginx из конфига живет ваша директива либо набор директив.
Хороший пример:
Здесь add_header просто добавляется в location. Такой же add_header мог быть где-то выше, и все просто бы смёржилось. Это документированное и понятное поведение.
Такие же правила относятся ко всем фазовым handlers — нет гарантии, кто вызовется перед и кто после. Поэтому уважайте того, кто вызовется после, и помните о том, что к вам может неожиданно прилететь какой-нибудь gzip или еще что-нибудь.
Если в будущем вы займетесь разработкой модулей nginx, то будете хорошо знать исходники nginx. Вы их полюбите, потому что документации нет. Вы хорошо выучите структуру каталогов nginx, научитесь пользоваться Grep, возможно, Sed, когда вам потребуется перенести в свои модули какие-то куски из nginx.
Pool’ы надо использовать правильно. Например, «r->connection->pool != r->pool». Ни в коем случае при обработке request’ов нельзя использовать memory pool конфигурации — он будет пухнуть пока nginx не перезапустится.
Поймите время жизни объекта. Допустим, у request replay время жизни ровно этот pipeline. В этом pool можно много чего разместить, и освободить место. Connection может жить теоретически бесконечно — в нем лучше размещать что-то действительно важное.
Старайтесь не использовать внешние allocators, например, malloc/free. Это плохо влияет на фрагментацию памяти. Если вы оперируете большими объемами данных и много используете malloc, это неплохо тормозит nginx.
Для любителей Valgrind есть хак, который позволяет дебажить nginx-pool’ы, используя Valgrind. Это важно, если у вас очень много C-кода на nginx, потому что даже опытный разработчик в работе с памятью может допустить ошибку.
Я знаю случай, когда человек использовал Quora внутри nginx в блокирующем режиме (не спрашивайте, зачем). Это привело к тому, что keep-alive соединения отказались от жизнедеятельности и все время таймаутили. Так лучше не делать — все будет работать долго, неэффективно и вам сразу придется выкручивать миллион таймаутов, потому что nginx начнет таймаутить на многие вещи.
Но есть альтернатива C-модулям — NJS и Lua.
В этом году у меня появился первый опыт работы на NJS, сложилось по нему свое субъективное впечатление, и я даже понял, чего там не хватает, чтобы совсем было все хорошо. Также я бы хотел рассказать про свой опыт работы на Lua под nginx, и, более того, поделиться проблемами, которые присутствуют в Lua.
В nginx используется не Lua, а LuaJit. Но это не Lua, потому что Lua уже ушла вперед на две версии, а LuaJit застрял где-то в прошлом. Автор практически не развивает LuaJit — он живет зачастую в форках. Самый актуальный форк — LuaJit2. Это добавляет странных ситуаций в том же OpenResty.
Garbage Collector требует внимания. Эту проблему LuaJit не побороть — только придумывать какие-то обходные пути. При огромной нагрузке, когда много keep-alive Garbage Collector будет виден на клиенте провалами на графике и ошибками 500. Есть много способов борьбы с Garbage Collector в Lua, я на них не буду здесь акцентироваться. В интернете много информации об этом.
Реализация строк приводит к проблемам производительности. Это просто зло LuaJit, а в Lua это починили. Реализация строк в LuaJit просто не поддается никакой логике. Строки тормозят дичайшим образом, что связано с внутренней реализацией.
Невозможность использовать многие готовые библиотеки. Lua изначально блокирующая, поэтому большинство библиотек на Lua и LuaJit используют блокирующий I/O. Из-за того, что nginx не блокирующий, невозможно использовать готовые библиотеки внутри nginx, которые используют любое блокирующий I/O. Это будет тормозить nginx.
Причины использовать LuaJit идентичны причинам использовать модули:
Где лучше не использовать LuaJit?
Shared memory или придет Garbage Collector. Не используйте Shared memory вместе с Lua — Garbage Collector быстро и с гарантией вынесет весь мозг на продакшн.
Не использовать корутины с большим количеством keep-alive соединений. Корутины порождают еще больше мусора внутри LuaJit Garbage Collector, что плохо.
Если вы его уже используете LuaJit, то помните:
Когда я был на NGINX Conf, меня убедили, что круто было бы не писать код на C. Я подумал, надо попробовать, и вот, что получил.
Авторизация. Она работает, код простой, на скорости не сказывается — все великолепно. Мой небольшой прототип, с которого я начинал — это 10 строчек кода. Но эти 10 строк делают авторизацию с s3.
Вычисление переменных для nginx.conf. Многие переменные можно вычислять с помощью NJS. Внутри nginx это классно. В Lua такая фишка есть, но там Garbage Collector, поэтому не так классно.
Однако не все так хорошо. Чтобы делать на NJS действительно классные вещи, ему не хватает нескольких вещей.
Shared Memory. Я запатчил Shared Memory, это мой собственный форк, поэтому теперь хватает.
Фильтров, поддержки большего количества фаз. В NJS есть только фаза контента и переменные, и очень не хватает header filter. Приходится писать костыли, чтобы добавить много headers. Не хватает body filter для сложной логики или работы с контентом.
Информации о том, как его мониторить и профилировать. Я теперь знаю, как, но мне пришлось изучать исходники. Не хватает ни информации, ни инструментов о правильном профилировании. Если она есть, то спрятана там, где не найти. В этом же пункте не хватает информации о том, где я могу использовать NJS, а где не могу?
С-модулей. У меня появилось желание расширить NJS.
Зачем создавать свои модули? Чтобы решать общие и бизнес-задачи.
Когда надо реализовывать модули на С? Если нет других вариантов. Например, большая нагрузка, врезка контента или элементарная экономия на железе. Тогда это надо делать гарантированно на С. В большинстве случаев подойдет Lua или NJS. Но надо всегда думать наперед.
А на Lua? Когда можно не писать на С. Например, не надо преобразовывать тело запроса при огромном RPS. У вас растет количество клиентов, в какой-то момент перестанете справляться — думайте об этом.
NJS? Когда LuaJit совсем надоел своим Garbage Collector и строками. Например, авторизация генерировала на Lua много Garbage-объектов, но это было не критично. Тем не менее, это отражалось в мониторинге и раздражало. Сейчас это перестало отображаться в моем мониторинге, и все стало хорошо.
Вообще все в nginx — это модули, которые когда-то кем-то были написаны. Поэтому писать модули под nginx не только можно, но и нужно. Когда это необходимо делать и зачем, расскажет Василий Сошников (dedokOne) на примере нескольких кейсов.
Поговорим о причинах, которые побуждают писать модули на C, об архитектуре и ядре nginx, анатомии HTTP-модулей, о C-модулях, NJS, Lua и nginx.conf. Это важно знать не только тем, кто разрабатывает под nginx, но также тем, кто использует nginx-конфиги, Lua или другой язык внутри nginx.
Примечание: статья написана на основе доклада Василия Сошникова. Доклад постоянно модернизируется и обновляется. Информация в материале довольно техническая и, чтобы извлечь максимум пользы, читателям необходимо иметь опыт работы с кодом nginx на среднем уровне и выше.
Кратко об nginx
Все, чем вы пользуетесь в nginx, — это модули. Каждая директива в nginx-конфигурации — отдельный модуль, который был заботливо написан коллегами из сообщества nginx.
Директивы в nginx.conf — это тоже модули, которые решают определенную задачу. Поэтому в nginx модули это всё. add_header, proxy_pass, любая директива — это модули или комбинации модулей, которые работают по определённым правилам.
Nginx — это фреймворк, в котором есть: Network & File I/O, Shared Memory, Configuration & Scripting. Это огромный пласт низкоуровневых библиотек, на которых можно сделать всё что угодно для работы с сетью, дисками.
Nginx быстрый и стабильный, но сложный. Вы должны писать такой код, чтобы не потерять эти качества nginx. Нестабильный nginx на продакшн — это недовольные клиенты, и все что из этого вытекает.
Зачем создавать свои модули
Преобразование HTTP-протокола в другой протокол. Это основная причина, которая часто мотивирует создавать тот или иной модуль.
Например, модуль memcached_pass преобразовывает HTTP в другой протокол, и можно работать с другими внешними системами. Модуль proxy_pass тоже позволяет преобразовать, правда из HTTP(s) в HTTP(s). Еще хороший пример — это fastcgi_pass.
Это все директивы вида: «пойти на такой-то backend, где не HTTP (но в случае proxy_pass HTTP)».
Динамическая врезка контента: обход AdBlock, врезка рекламы. Например, у нас есть backend и необходимо модифицировать контент, который из него приходит. Например, AdBlock, который анализирует код вставки рекламы, и нам надо с ним бороться — подстроить тем или иным образом.
Другая вещь, которую часто приходится делать для врезки контента — это проблема с кэшированием HLS. Когда параметры кэшируются внутри HLS, то два пользователя могут получить одну и ту же сессию или одни и те же параметры. Оттуда происходит вырезка или добавление некоторых параметров, когда вам надо что-то трекать.
Сборка Clickstream-данных с интернет/мобильных счетчиков. Популярный кейс в моей практике. Чаще всего это делают на nginx, но не на access.log, а чуть интеллектуальнее.
Преобразование разного рода контента. Например, модуль rtmp для позволяет работать не только с rtmp, но и с HLS. Этот модуль может очень многое делать с видео-контентом.
Обобщенная точка авторизации: SEP или Api Gateway. Это тот случай, когда nginx работает как часть инфраструктуры: авторизует, собирает метрики, отправляет данные в мониторинг и ClickStream. Nginx здесь работает как инфраструктурный хаб — единая точка входа для бэкендов.
Обогащение запросов для их последующей трассировки. Современные системы очень сложные, с несколькими типами бэкендов, которые делают разные команды. Как правило, их трудно дебажить, иногда даже трудно понять, откуда пришел запрос и куда он ушел. Чтобы упростить отладку, некоторые крупные компании применяют хитрую методику — добавляют в запросы определенные данные. Пользователь их не увидит, но по этим данным легко проследить путь запроса внутри системы. Это называется трассировкой.
S3-proxy. В этом году я часто вижу, как люди работают со своими объектами через s3. Но это необязательно делать на C-модулях, инфраструктуры достаточно и в nginx. Для решения некоторых из этих задач можно использовать Lua, что-то решается на NJS. Но иногда бывает необходимо писать модули на C.
Когда пора создавать модули
Есть два критерия, чтобы понять, что пришло время.
Обобщение функционала. Когда вы поняли, что ваш продукт нужен еще кому-то, то контрибьютите это в Open Source, создаете обобщённый функционал, выкладываете и позволяете им пользоваться.
Решение бизнес-задач. Когда бизнес ставит такие требования, которым можно удовлетворить, только написав свой модуль для nginx. Например, динамическую врезку/изменение контента, сбор ClickStream можно сделать на Lua, но, скорее всего, работать нормально не будет.
Архитектура nginx
Я пишу код на nginx уже давно. В продакшн крутятся 9 моих модулей, один из них — в Open Source, в продакшн у многих. Поэтому опыт и понимание у меня есть.
Nginx— это матрешка, в которой все построено вокруг ядра.Так я понимаю nginx.
Core — это обертки над epoll.Epoll — это метод, который позволяет работать асинхронно с любыми файлами дескрипторами, а не только с сокетами, потому что дескриптор — это не только сокет.
Над ядром выстроены upstreams, HTTP и scripting. Под scripting я подразумеваю nginx.conf, а не NJS. Поверх upstreams, HTTP и scripting уже выстроены HTTP-модули, о которых мы будем говорить.
Классический пример upstreams и HTTP это upstream-серверы — директивы внутри конфига. Пример модулей для HTTP — это add_header. Пример scripting — сам файл конфига. В файле указаны модули, из которых состоит nginx, он как-то интерпретируется и что-то позволяет сделать вам, как администратору, или вашему пользователю.
Мы не будем рассматривать core и очень кратко остановимся на upstreams, потому что это отдельная вселенная внутри nginx. Рассказ о них достоин нескольких статей.
Анатомия HTTP-модулей
Даже если вы не пишете код на C внутри nginx, но его используете, запомните главное правило.
В nginx всё подчиняется паттерну Chain of Responsibility — COR.Как перевести это на русский не знаю, но опишу логику. Ваш request проходит через плеяду настроенных chain-модулей, начиная от location. Каждый из этих модулей возвращает какой-то результат. Если результат плохой — цепочка прерывается.
Когда разрабатываете модули или используете какую-то директиву на NJS и Lua, не забывайте, что ваш код может обрушить выполнение этой цепочки.
Ближайшая аналогия Chain of Responsibility — строка кода на Bash:
grep -RI pool nginx | awk -F":" '{print $1}' | sort -u | wc -lВ коде все достаточно просто: если посередине строки упал AWK, то
sort и следующие команды не выполнятся. Nginx-модуль работает подобно, но правда в nginx и это можно обойти — перезапустить код. Но вы должны быть готовы к падению и запуску, как и ваши модули, которые вы используете в конфиге, но не факт, что это так.Типы HTTP-модулей
HTTP и nginx — это куча разных PHASE.
- Обработка фаз — PHASE handlers.
- Фильтры — Body/Headers filters. Это фильтрация либо Headers, либо тела запроса.
- Proxies. Типичные proxy модули — proxy_pass, fastcgi_pass, memcached_pass.
- Модули для определенной балансировки нагрузки — Load balancers. Это самый нераскрученный тип модулей, их мало разрабатывают. Пример — Ketama CHash module, который позволяет делать консистентное хэширование внутри nginx, чтобы распределять запросы на backend’ы.
Расскажу о каждом из этих типов и их предназначении.
Phase handlers
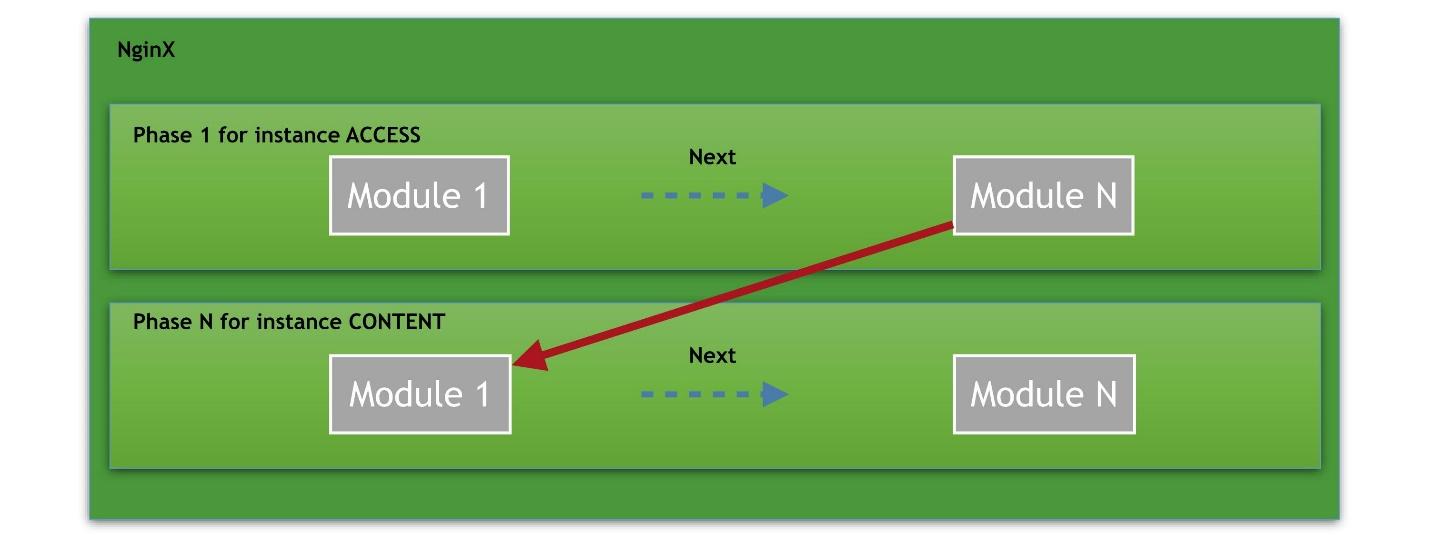
Представим, что у нас есть несколько фаз, начиная от фазы доступа. В каждой фазе несколько модулей. Например, фаза ACCESS делится на соединение, запрос к nginx, проверка авторизации пользователя. Каждый модуль — это ячейка в цепочке. Таких модулей в фазе может быть бесконечное множество.
Последний, завершающий handler — это CONTENT-фаза, в которой происходит выдача контента по запросу.
Путь всегда такой: запрос — цепочка handlers — контент на выходе.Фазы, которые доступны разработчикам модулей из исходников NGINX:
typedef enum {
NGX_HTTP_POST_READ_PHASE = 0,
NGX_HTTP_SERVER_REWRITE_PHASE,
NGX_HTTP_FIND_CONFIG_PHASE,
NGX_HTTP_REWRITE_PHASE,
NGX_HTTP_POST_REWRITE_PHASE,
NGX_HTTP_PREACCESS_PHASE,
NGX_HTTP_ACESS_PHASE,
NGX_HTTP_POST_ACESS_PHASE,
NGX_HTTP_PRECONTENT_PHASE,
NGX_HTTP_CONTENT_PHASE,
NGX_HTTP_LOG_PHASE,
} ngx_http_phases;Фазы можно перезаписать, добавить свой собственный обработчик. Не все из них нужны в реальной жизни, если вы не разработчик именно nginx core. Поэтому я не буду рассказывать о каждой фазе, а только об основных, которые я использовал.
Основная — это ACCESS_PHASE. Особенно пригодится, чтобы добавить в nginx свою авторизацию — для проверки исполнения запроса с точки зрения доступа.
Следующие важные фазы, которые я часто эксплуатирую — это фазы преконтента и контента. PRECONTENT_PHASE позволяет собирать метрики о контенте, который вот-вот отправится как ответ клиенту. CONTENT_PHASE позволяет генерировать собственный уникальный контент на основе чего-то.
Последняя фаза, которую часто использую — это фаза логирования LOG_PHASE. В ней, кстати, работает директива ACCESS_LOG. У фазы логирования дичайшие ограничения, которые меня сводят с ума: нельзя использовать subrequest и вообще нельзя использовать никакие request. У вас уже контент ушел пользователю, а handlers, posthandlers и какие-либо subrequest’ы исполнены не будут.
Объясню, почему это напрягает. Допустим, когда вы хотите скрестить nginx и Kafka в фазе логирования. В этой фазе уже все выполнилось: есть подсчитанный размер контента, статус, все данные, но вы не можете это сделать subrequest’ом. Они там не работают. Приходится писать на голых сокетах в фазе логирования, чтобы отправить данные в Kafka.
Body/Headers filters
Есть два типа фильтров: Body filters и Headers filters.
Пример Body filter — это gzip filter module. Зачем нужны Body filters? Представьте что у вас есть некий proxy_pass, и вы хотите как-то преобразовать контент либо его проанализировать. В таком случае вы должны использовать Body filter.
Он работает так: к вам приходит много чанков, вы с ними что-то делаете, смотрите содержимое, агрегируете и т.д. Но в фильтре тоже есть существенные ограничения. Например, если вы решили изменить тело — сделать врезку или вырезку из тела ответа, помните, что заменятся атрибуты HTTP, например, контент-лента. Это может привести к странным эффектам, если не предусмотреть ограничения и не отразить правильно у себя в коде.
Пример Header filter — add_header, которым все пользовались. Алгоритм работы как в Body filter. Клиенту готовится response, и add_header фильтр позволяет что-то там сделать: добавить header, удалить header, заменить header, отправить subrequest.
Кстати, в Body filter и в Header filter subrequest’ы доступны, там можно даже отправлять внутренние идентификации на дополнительный location.
Proxy
Это самый сложный и неоднозначный тип модулей, которые позволяют проксировать запросы во внешние системы, например, преобразовывать HTTP в другой протокол. Примеры: proxy_pass, redis_pass, tnt_pass.
Proxy — это интерфейс, который предложили core-разработчики nginx, чтобы писать proxy-модули проще. Если это делать классическим путем, то для такой proxy будут выполняться PHASES handlers, filters, Balancers. Однако, если протокол, в который вы хотите преобразовать HTTP, как-то отличается от классики, то начинаются большие проблемы. API для proxy, который дает nginx, просто не подходит — придется изобретать с нуля этот proxy-модуль.
Хороший пример такого модуля — postgres_pass. Он позволяет nginx общаться с PostgreSQL. В модуле вообще не используется тот интерфейс, которые разработали в nginx — там свой собственный путь.
Помните о proxy, но желательно не пишите. Чтобы писать proxy, придется выучить весь nginx наизусть — это очень долго и сложно.
Load balancers
Задача Load balancers очень простая — работать в режиме round-robin. Представьте, что у вас есть секция upstream, в ней какие-то серверы, вы указываете веса и способы балансировки. Это типичный Load balancer.
Этот режим не всегда подходит. Поэтому был разработан Ketama CHash module, где условно можно прибывать запрос по консистентному хэшу к какому-то серверу. Порой это удобно. Nginx Lua предлагает balancer_by_lua. На Lua вообще можно написать любой балансер.
С-модули
Дальше будет мое абсолютно субъективное мнение о разработке С-модулей. Для начала — мои субъективные правила.
Модуль начинается с nginx.conf-директив. Даже если вы делаете С-модуль, который будет эксплуатироваться только в вашей компании, всегда думайте о директивах. Начинайте проектировать модуль именно с них, потому что это то, с чем будет общаться системный администратор. Это важно — согласуйте все нюансы с ним или с человеком, который будет эксплуатировать ваш С-модуль. NGINX — это известный продукт, его директивы подчиняются определенным законам, которые знают системные администраторы. Поэтому всегда об этом думайте.
Используйте nginx сode style. Представьте, что ваш модуль будет поддерживать другой человек. Если он уже знаком с nginx и с его сode style, ему будет в разы проще прочитать и понять ваш код.
Недавно мой хороший знакомый из Германии попросил помочь ему разобраться с багом внутри его nginx-кода. Не знаю, по какому code style он его писал, но я даже прочитать код нормально не смог.
Используйте правильный memory pool.Всегда помните об этом, даже если у вас много опыта в nginx. Типичная ошибка начинающего разработчика модулей на С для nginx — взять не тот pool.
Небольшая предыстория: nginx в целом использует идеологию слабых аллокаторов. Там можно пользоваться malloc, но не рекомендуется. Там есть свои slabs, свой memory allocator, надо пользоваться им. Соответственно, у каждого объекта есть ссылка на его pool, и этим pool’ом как раз надо пользоваться. Типичная ошибка начинающего, использовать в header filter не pool request, а pool connection. Это означает, что если у нас keep-alive connection, pool будет пухнуть, пока случится out of memory либо другие побочные эффекты. Поэтому это важно.
Более того, такие ошибки крайне сложно дебажить. Valgrind («сишники» поймут) со slab allocation не работает — он покажет странную картину.
Не используйте блокирующее I/O. Типичная ошибка тех, кто хочет быстрее применить что-то внешнее — использовать блокирующий I/O и блокирующие сокеты. В nginx этого делать никогда нельзя — в нем много процессов, но каждый процесс использует один поток.
Можно сделать многопоточность, но, как правило, от этого только хуже. Если вы используете в такой архитектуре блокирующее I/O, то все будут ждать этого блокирующего куска.
Расшифрую то, о чем я сказал выше.
Модуль начинается с nginx.conf-директив
Определитесь в каких скопах ваша директива должна обитать: Main, Server, HTTP, location, location if.Старайтесь избегать location if — как правило, это приводит к очень странному использованию nginx-конфигурации.
Все директивы в nginx живут в разных контекстах и разных скопах. Директива add_header может работать на HTTP-level, на location-level, на location-if-level. Это все, как правило, описано в документации.
Поймите, на каких уровнях ваша директива может работать, место исполнения директивы: PHASE Handler, Body/Header filter.Это важно, потому что в nginx конфиг мёржится. Условно, когда вы пишете add_header где-то наверху, это значение смёржится в самом нижнем add_header, который у вас уже в location. Соответственно, у вас добавятся два headers. Это относится к любой директиве.
Если вы указываете host port чего-то, то наоборот — поднимается pool сокетов. Это должно быть указано один раз.
Вообще я бы запретил любой мёржинг — вам это просто не нужно. Поэтому вы должны всегда четко определиться, в каких скопах nginx из конфига живет ваша директива либо набор директив.
Хороший пример:
location /my_location/ {
add_header “My-Header” “my value”;
}Здесь add_header просто добавляется в location. Такой же add_header мог быть где-то выше, и все просто бы смёржилось. Это документированное и понятное поведение.
Подумайте, что может помешать выполнению директивы.Представьте, что вы разрабатываете Body filter. Как я сказал выше, nginx просто помещает ваш модуль в общий chain, и у вас нет гарантии, что gzip модуль на этапе компиляции не встал в chain перед вашим Body filter. В таком случае если кто-то включит gzip-модуль, в ваш модуль придут за’gzip’ованные данные. Это грозит тем, что вы просто не сможете ничего сделать с контентом. Вы сможете его пере’gzip’овать, например, но это издевательство с точки зрения CPU.
Такие же правила относятся ко всем фазовым handlers — нет гарантии, кто вызовется перед и кто после. Поэтому уважайте того, кто вызовется после, и помните о том, что к вам может неожиданно прилететь какой-нибудь gzip или еще что-нибудь.
Nginx сode style
Когда вы создали продукт, помните, что его кто-то будет поддерживать. Не забывайте о code style nginx.Перед тем, как писать свой модуль nginx, ознакомьтесь с исходниками: один и второй.
Если в будущем вы займетесь разработкой модулей nginx, то будете хорошо знать исходники nginx. Вы их полюбите, потому что документации нет. Вы хорошо выучите структуру каталогов nginx, научитесь пользоваться Grep, возможно, Sed, когда вам потребуется перенести в свои модули какие-то куски из nginx.
Memory pool
Pool’ы надо использовать правильно. Например, «r->connection->pool != r->pool». Ни в коем случае при обработке request’ов нельзя использовать memory pool конфигурации — он будет пухнуть пока nginx не перезапустится.
Поймите время жизни объекта. Допустим, у request replay время жизни ровно этот pipeline. В этом pool можно много чего разместить, и освободить место. Connection может жить теоретически бесконечно — в нем лучше размещать что-то действительно важное.
Старайтесь не использовать внешние allocators, например, malloc/free. Это плохо влияет на фрагментацию памяти. Если вы оперируете большими объемами данных и много используете malloc, это неплохо тормозит nginx.
Для любителей Valgrind есть хак, который позволяет дебажить nginx-pool’ы, используя Valgrind. Это важно, если у вас очень много C-кода на nginx, потому что даже опытный разработчик в работе с памятью может допустить ошибку.
Блокирующий I/O
Здесь все просто — не используйте блокирующий I/O.Иначе, как минимум, будут проблемы с keep-alive соединениями, а как максимум, все будет работать очень долго.
Я знаю случай, когда человек использовал Quora внутри nginx в блокирующем режиме (не спрашивайте, зачем). Это привело к тому, что keep-alive соединения отказались от жизнедеятельности и все время таймаутили. Так лучше не делать — все будет работать долго, неэффективно и вам сразу придется выкручивать миллион таймаутов, потому что nginx начнет таймаутить на многие вещи.
Но есть альтернатива C-модулям — NJS и Lua.
Когда не надо разрабатывать С-модули
В этом году у меня появился первый опыт работы на NJS, сложилось по нему свое субъективное впечатление, и я даже понял, чего там не хватает, чтобы совсем было все хорошо. Также я бы хотел рассказать про свой опыт работы на Lua под nginx, и, более того, поделиться проблемами, которые присутствуют в Lua.
Главное о Lua/LuaJit
В nginx используется не Lua, а LuaJit. Но это не Lua, потому что Lua уже ушла вперед на две версии, а LuaJit застрял где-то в прошлом. Автор практически не развивает LuaJit — он живет зачастую в форках. Самый актуальный форк — LuaJit2. Это добавляет странных ситуаций в том же OpenResty.
Garbage Collector требует внимания. Эту проблему LuaJit не побороть — только придумывать какие-то обходные пути. При огромной нагрузке, когда много keep-alive Garbage Collector будет виден на клиенте провалами на графике и ошибками 500. Есть много способов борьбы с Garbage Collector в Lua, я на них не буду здесь акцентироваться. В интернете много информации об этом.
Реализация строк приводит к проблемам производительности. Это просто зло LuaJit, а в Lua это починили. Реализация строк в LuaJit просто не поддается никакой логике. Строки тормозят дичайшим образом, что связано с внутренней реализацией.
Невозможность использовать многие готовые библиотеки. Lua изначально блокирующая, поэтому большинство библиотек на Lua и LuaJit используют блокирующий I/O. Из-за того, что nginx не блокирующий, невозможно использовать готовые библиотеки внутри nginx, которые используют любое блокирующий I/O. Это будет тормозить nginx.
Причины использовать LuaJit идентичны причинам использовать модули:
- прототипирование сложных модулей;
- расчеты HMAC, SHA для авторизаций;
- балансировщики;
- небольшие приложения: обработчики хэдеров, правила для редиректов;
- вычисление переменных для nginx.conf.
Где лучше не использовать LuaJit?
Главное правило: не обрабатывайте огромный body на Lua — это не работает.Handlers на контент на Lua тоже не работает. Старайтесь минимизировать логику до нескольких
if. Простой balancer будет работать, но врезка в тело на Lua будет работать очень плохо.Shared memory или придет Garbage Collector. Не используйте Shared memory вместе с Lua — Garbage Collector быстро и с гарантией вынесет весь мозг на продакшн.
Не использовать корутины с большим количеством keep-alive соединений. Корутины порождают еще больше мусора внутри LuaJit Garbage Collector, что плохо.
Если вы его уже используете LuaJit, то помните:
- о мониторинге памяти;
- о мониторинге и оптимизации работы Garbage Collector;
- о принципах работы Garbage Collector, если вы все-таки написали сложное приложение для LuaJit, потому что вам придется добавить что-то новое.
NJS
Когда я был на NGINX Conf, меня убедили, что круто было бы не писать код на C. Я подумал, надо попробовать, и вот, что получил.
Авторизация. Она работает, код простой, на скорости не сказывается — все великолепно. Мой небольшой прототип, с которого я начинал — это 10 строчек кода. Но эти 10 строк делают авторизацию с s3.
Вычисление переменных для nginx.conf. Многие переменные можно вычислять с помощью NJS. Внутри nginx это классно. В Lua такая фишка есть, но там Garbage Collector, поэтому не так классно.
Однако не все так хорошо. Чтобы делать на NJS действительно классные вещи, ему не хватает нескольких вещей.
Shared Memory. Я запатчил Shared Memory, это мой собственный форк, поэтому теперь хватает.
Фильтров, поддержки большего количества фаз. В NJS есть только фаза контента и переменные, и очень не хватает header filter. Приходится писать костыли, чтобы добавить много headers. Не хватает body filter для сложной логики или работы с контентом.
Информации о том, как его мониторить и профилировать. Я теперь знаю, как, но мне пришлось изучать исходники. Не хватает ни информации, ни инструментов о правильном профилировании. Если она есть, то спрятана там, где не найти. В этом же пункте не хватает информации о том, где я могу использовать NJS, а где не могу?
С-модулей. У меня появилось желание расширить NJS.
Послесловие
Зачем создавать свои модули? Чтобы решать общие и бизнес-задачи.
Когда надо реализовывать модули на С? Если нет других вариантов. Например, большая нагрузка, врезка контента или элементарная экономия на железе. Тогда это надо делать гарантированно на С. В большинстве случаев подойдет Lua или NJS. Но надо всегда думать наперед.
А на Lua? Когда можно не писать на С. Например, не надо преобразовывать тело запроса при огромном RPS. У вас растет количество клиентов, в какой-то момент перестанете справляться — думайте об этом.
NJS? Когда LuaJit совсем надоел своим Garbage Collector и строками. Например, авторизация генерировала на Lua много Garbage-объектов, но это было не критично. Тем не менее, это отражалось в мониторинге и раздражало. Сейчас это перестало отображаться в моем мониторинге, и все стало хорошо.
На HighLoad++ 2019 Василий Сошников продолжит тему nginx-модулей и расскажет больше об NJS, не забывая о сравнении с LuaJit и C.
Полный список докладов смотрите на сайте, и до встречи 7 и 8 ноября на самой большой конференции для разработчиков высоконагруженных систем. Следите за нашими новыми задумками в рассылке и telegram-канале.
Комментарии (8)


chemtech
16.10.2019 16:40А автоматизировать сборку nginx с модулями можно с помощью Nginx-builder
Вот пост Собираем свой Nginx парой команд

spirit1984
17.10.2019 12:00Примечание: статья написана на основе доклада Василия Сошникова, который постоянно модернизируется и обновляется.
Кто на ком стоял? (с) Василий Сошников постоянно модернизируется и обновляется, я не сомневаюсь, ибо так функционируют внутренние системы организма. Надо все-таки фразу как-то поправить.

gfarniev
Очень хотелось бы чтобы завезли возможность передавать переменные в include, очень неудобно организован конфиг из-за этого.