
В далёком 2017 году я разрабатывал интерактивный текстовый редактор в браузере. Неудовлетворённый существующими библиотеками на ContentEditable, я подумал: «Эй, да просто заново реализую выделение текста! Разве это сложно?» Я был молод. Наивен. Прикинул, что справлюсь за две недели. На самом деле попытка решить эту проблему отняла несколько лет моей жизни, в том числе год оплачиваемой работы с утра до вечера по разработке текстового редактора для новой ОС.
На работе мне посчастливилось многое узнать у наставников с огромным опытом в этой области. Я слышал много, очень много страшных историй. В том числе об инженере, который поддерживал приложение Windows с кастомной реализацией текстового поля — и хотел перейти с устаревшего API ввода текста на новую версию. Вот список интерфейсов для ввода текста в этой новой версии:

Всё правильно, 128 интерфейсов для ввода текста. Почти уверен, что есть ещё восемь (8!) различных типов блокировок для устранения проблем параллелизма, хотя честно не читал их документацию, поэтому не цитируйте меня по этому поводу. Тот инженер полтора года (полный рабочий день!) дорабатывал свой редактор, но в итоге потерпел неудачу и остался на старом API.
Ввод текста — это сложно.
Алексис местами упоминает про выделение текста, но её личный опыт больше связан с рендерингом. Как человек с той стороны, могу добавить несколько моментов именно про ввод.
Вертикальное перемещение курсора
Я уже освещал это в предыдущей статье, но можем быстро повторить здесь.

В этом примере, если нажать вверх, курсор уйдёт в начало строки, перед словом hello. Пока всё довольно разумно. Но если нажать вверх, а затем вниз, курсор сначала прыгнет перед hello, а затем встанет после some.
Это может показаться не очень логичным. Вы спросите, почему он прыгает вправо? Ну, при вертикальных перемещениях каждый курсор запоминает позицию x в пикселях, и она обновляется только при нажатии влево или вправо, а не вверх и вниз. То же самое поведение предотвращает перемещение курсоров влево при вертикальном перемещении через короткие строки.
Близость
Ладно, теперь мы знаем, что при выделении текста у нас два фрагмента состояния: байтовое смещение внутри строки и координата x в пикселях, упомянутая выше. Проблема решена? Ну, нет.
Рассмотрим две позиции курсора на очень длинной строке:

Поскольку loooooooooong — это одно слово, у двух позиций курсора в точности одинаковое байтовое смещение в строке. Между ними нет символа новой строки, так как строка мягко переносится. Нашим курсорам нужен дополнительный бит, который скажет, на какую строку перенестись. Большинство систем называют этот бит affinity (близость). Он же используется в смешанном двунаправленном тексте, про который мы скоро поговорим.
Модификаторы эмодзи
Допустим, я отправляю другу сообщение. Для выражения своих чувств хочу добавить забавный эмодзи. Ввожу в текстовой области поднятый вверх большой палец, букву
a и модификатор эмодзи для тона кожи. Это выглядит так:
Ой, не хотел писать букву. Устанавливаю курсор после неё и нажимаю Backspace. Что произойдёт? Я видел несколько вариантов, в зависимости от редактора.

- Плохо №1 может показаться правильным. Но так работает текстовый редактор с поддержкой устаревшего рендеринга эмодзи, например, Sublime Text. Это плохо, потому что эмодзи светлого пальца кодируется как жёлтый палец, за которым сразу следует модификатор светлого тона кожи. Они не объединяются в один символ, как положено. Даже если я скопирую светлый палец из другого приложения, он всё равно отобразится неправильно, как здесь.
- Плохо №2 — это то, что Chrome 77 делает в адресной строке. Не на веб-страницах, а только в адресной строке. Это не проблема рендеринга, так как копипаст эмодзи с тоном кожи работает. Вместо этого Chrome удаляет букву, а заметив следующий за буквой модификатор, заодно удаляет и его. Упс.
- Плохо №3 соответствует спецификации Юникода, как положено сливать эмодзи. Но это довольно непонятно для пользователей, и, кстати, нужно сдвинуть курсор, чтобы он не застрял на полпути внутри эмодзи.
Все варианты плохие, поэтому вы можете предположить, что наверное есть какой-то четвёртый вариант. Есть! Многие редакторы, такие как TextEdit, даже не позволяет поставить курсор после буквы, так как модификатор тона кожи рассматривается как единое целое с предыдущим символом. Это имеет смысл в контексте эмодзи и даже хорошо работает в данном случае, но что если модификатор указан первым символом в строке?
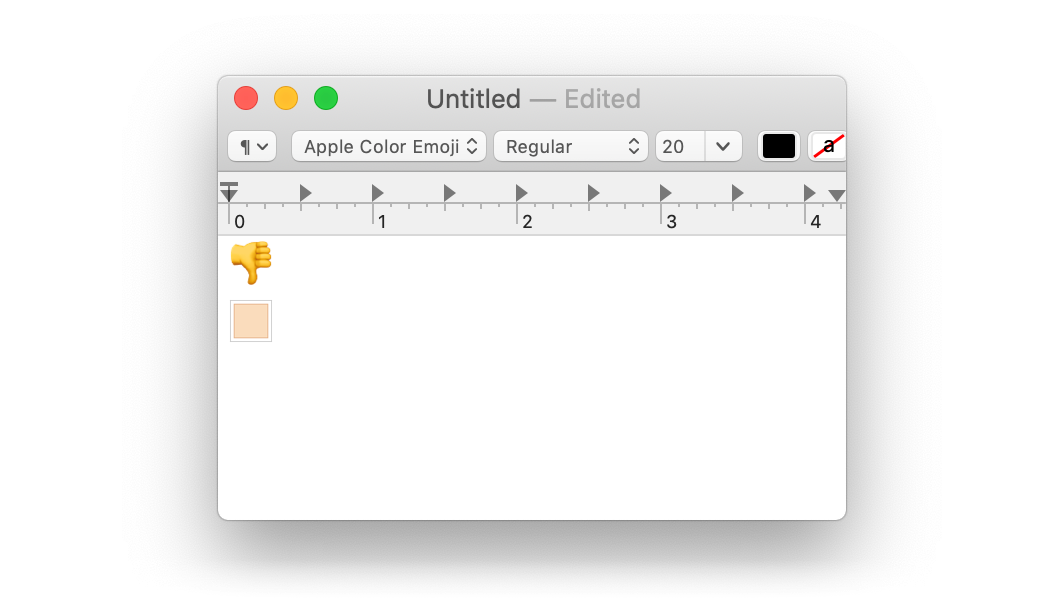
Теперь модификатор изменяет символ новой строки. TextEdit не позволит поместить курсор в начале второй строки! Я лично считаю это решение «тоже плохим».
Возможно, вы также заметили, что большой палец вверх стал большим пальцем вниз. Это я сам сделал, чтобы отразить свои чувства по поводу всей ситуации.
Кстати, TextEdit специально делает курсор на первой строке очень глючным. Например, угадайте, что произойдёт, если я здесь нажму
4?
Угу. Вы также можете подумать, что между цифрами есть пробелы. Их нет.
Двунаправленный текст
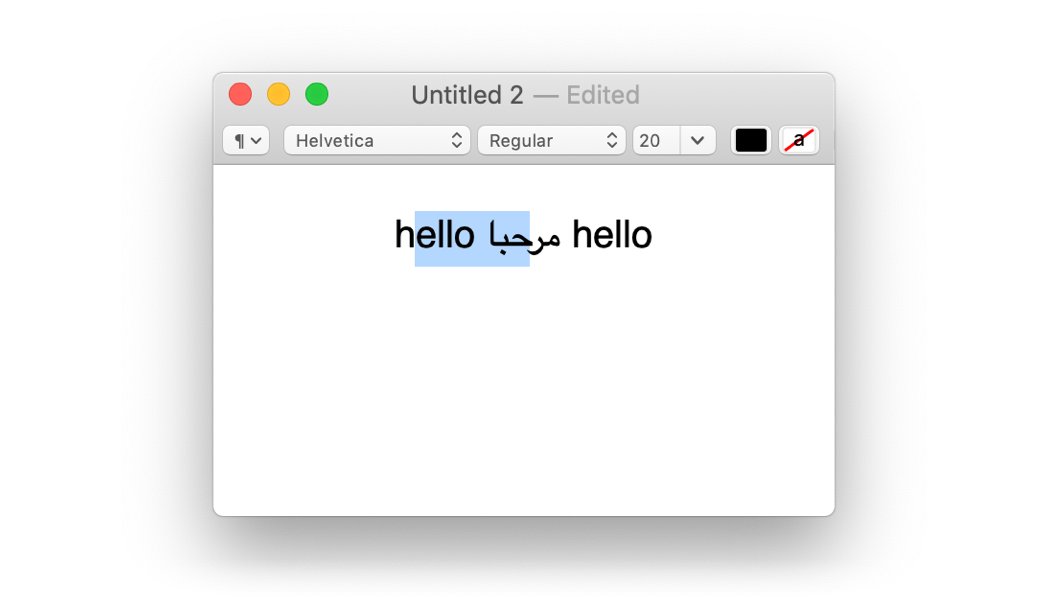
Алексис упоминает разделённые выделения в смешанном двунаправленном тексте, как в этом примере из TextEdit:

Это действительно имеет смысл, поскольку арабский язык в строках кодируется справа налево, так что выделение кажется разделённым, но по байтам представляет собой непрерывный диапазон.
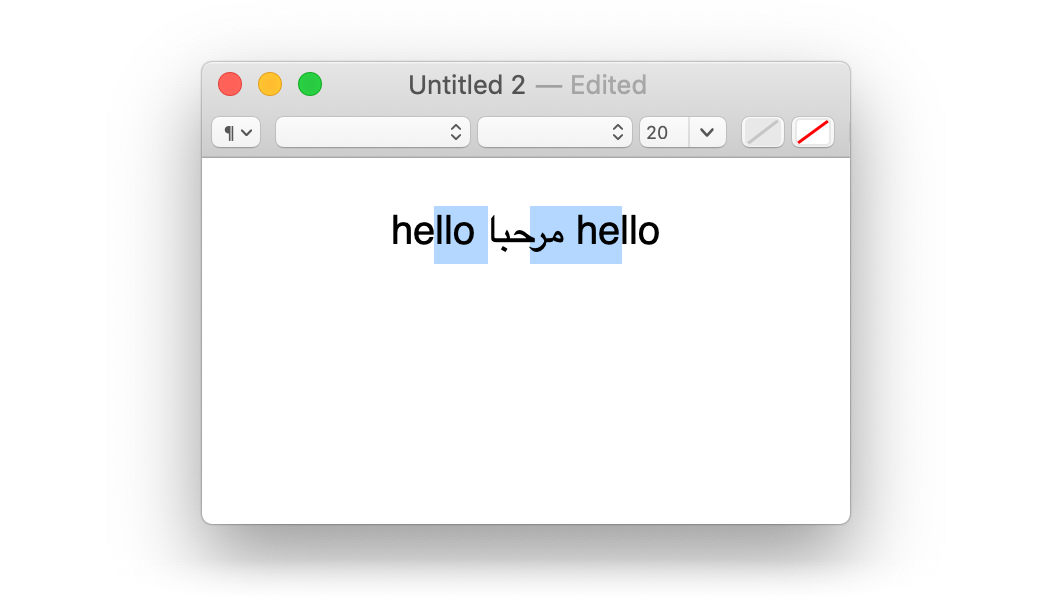
Поэтому немного удивительно, что мы можем получить такое выделение:
Да, это визуально непрерывное, но разделённое по байтам выделение. Да, плохо. Так делают некоторые редакторы, если выделять текст клавишами со стрелками вместо мыши. Альтернатива — поменять местами клавиши влево/вправо внутри текста с направлением справа налево, что тоже плохо. Здесь нет хороших вариантов.
В качестве бонуса, попробуйте понять, что происходит здесь:
Господи… не хочу это комментировать.
Дело в методах ввода
Программное обеспечение, которое переводит нажатия клавиш во ввод, называется «метод ввода» (input method) или «редактор метода ввода» (input method editor). Для латинского алфавита это не очень интересное ПО, так как каждое нажатие клавиши напрямую сопоставляется с вставкой одного символа. Но во многих письменностях символы не помещаются на клавиатуру, поэтому приходится проявлять творческий подход. Например, в некоторых методах ввода для китайского языка пользователь вводит звуки — и получает список похожих по звучанию иероглифов:
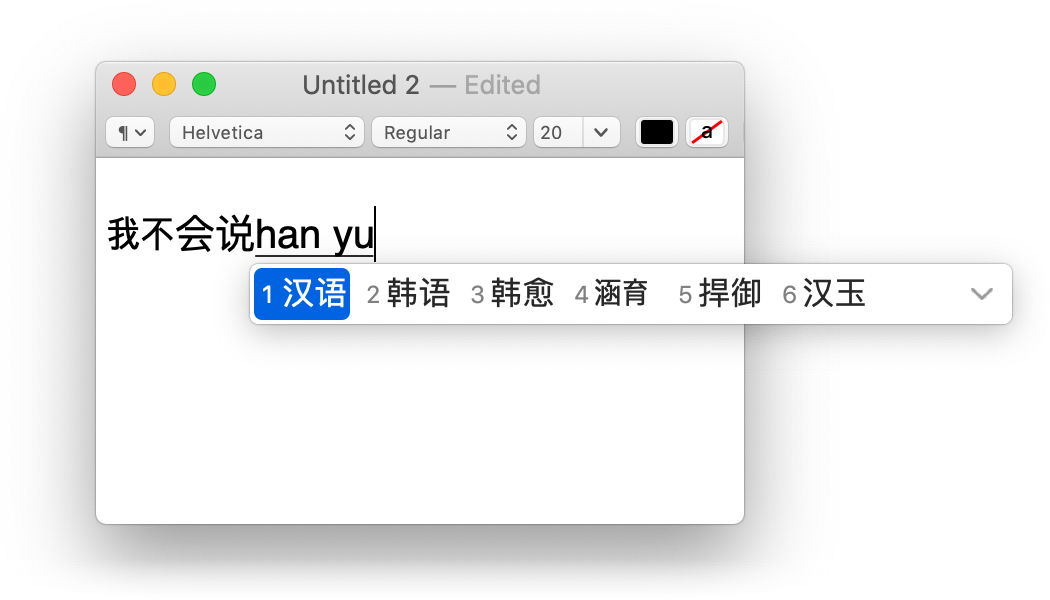
Это поле иногда называют композиционной областью (composing region), и она часто появляется над подчёркнутым текстом. Иногда метод ввода должен её стилизовать. Например, метод ввода японского языка на Android использует цвет фона для создания области разделения предложений:

(Спасибо Shae за скриншот!)
Взаимодействуют ли все эти выделения и композиционные области с двунаправленным текстом? Давайте не будем об этом думать.
Методы ввода должны работать везде, даже внутри терминала:

Ничего не отправится в Vim, пока не выбран китайский иероглиф из списка. Вероятно, вы думаете: «Но как это работает в командном режиме Vim?» Не очень хорошо. Вот почему в интернете ввод текста и нажатия клавиш являются отдельными событиями. В консоли они смешиваются, вызывая проблемы.
Это всего лишь один пример из множества различных способов ввода текста. (Не забывайте о методах ввода без клавиатуры, таких как голосовой и рукописный ввод!) К счастью, операционная система предоставляет вам все эти методы. Но, к сожалению, ваше текстовое поле должно говорить на общем протоколе ввода текста, используемом всеми этими методами. Для Windows это те 128 интерфейсов, перечисленные в начале статьи. В других ОС интерфейсы попроще, но их всё равно сложно реализовать.
Вы также могли заметить, что метод ввода — отдельный процесс, так что в состояние текстового поля могут вносить изменения и метод ввода, и приложение. Это фактически параллельный протокол редактирования. Windows решает проблему с помощью восьми (8!) видов блокировки. Хотя удержание блокировки через границы процесса может показаться сомнительным, большинство других платформ для устранения проблем параллелизма пытаются использовать несовершенные эвристики. Или просто надеются, что состояние гонки не произойдёт. По моему опыту, молитва — не очень эффективный примитив параллелизма.
Почему всё так сложно??
Джонатан Блоу в лекции о деградации софта упоминает текстовый редактор Кена Томпсона, который он написал за неделю. Большая часть кода в этой статье — случайно привнесённая сложность. Действительно ли Windows нужно 128 интерфейсов и 8 видов блокировок для ввода текста? Ни в коем случае. Являются ли ошибки в TextEdit результатом сложной модели редактирования? Да. Является ли россыпь багов в современных программах чем-то, о чём следует беспокоиться? По крайней мере, для меня это так.
Однако редактор Кена Томпсона был и намного, намного проще, чем то, что мы ожидаем от современных текстовых редакторов. Юникод поддерживает почти все живые языки в мире (их около 7000), и ещё много мёртвых. Там разные письменности, направления текста и методы ввода, каждый из которых накладывает сложные (и в некоторых случаях неразрешимые) ограничения на любой редактор. А ведь он должен ещё и поддерживать программы чтения с экрана.
Огромная сложность накапливается неизбежно, а в этой статье мы только слегка её тронули. Это настоящее чудо программирования, что можно просто шлёпнуть
<textarea> на веб-странице — и мгновенно обеспечить ввод текста для каждого пользователя интернета по всему миру. Комментарии (30)

Sabubu
01.11.2019 01:50+3Выделение смешанного текста одним сплошным выделением выглядит логично при условии, что после копирования/вставки он будет выглядеть так же.
chelsea2
01.11.2019 09:36-15Потому адекватные люди для редактирования текста пользуются vim-ом, а не всяким тормознутым, глючным, без продуманной логики г-м.
lorc
01.11.2019 13:13+7Ага. И языков кроме английского не существует. Введите в виме что-то на японском. Желательно через последовательную консоль.
Вим хорош когда пишешь код или тексты на английском. Но человеческая деятельность этим не ограничивается.
mib
01.11.2019 12:10+3Я занимаюсь веб-программированием и всё время порываюсь написать статью гнева по поводу выделения и копирования текста.
Обычные сценарии: нажать в FF / Chrome F12, чтобы скопировать текст ошибки, или вывод консоли, или код хтмл. Выделяю, нажимаю скопировать — не скопировалось, там надо еще раз нажать и как-то по-другому выделить, чтобы область выделения стала еще темнее, или двойным щелчком.
Еще — phpmyadmin — часто нужно скопировать все названия полей — при этом копируются их тайтлы, дополнительные какие-то символы, это если повезло, и не сработал клик по сортировке.
О выделении слова двойным щелчком — отдельная песня. Даже здесь, в редакторе хабра слово выделяется с пробелом за ним. Это какое-то смарт-поведение?
Если какой-то интерфейс программы выводит алерт — я не могу выделить и скопировать нужную фразу. В лучшем случае скопируется весь контент алерта вместе с тайтлом.
И таких мелочей очень много везде, на каждом шагу. Мало кто заботится об удобстве работы с информацией, а выделение и копирование — не менее важно, чем читабельность.
Evengard
01.11.2019 17:02Если у вас Firefox, то автовыделение пробела после слова можно отключить в about:config. Буквально недавно проскакивала статья про тонкую настройку огнелиса, там и была информация по этой настройке.
Evir
01.11.2019 19:19Видимо, поведение Firefox всё же иногда зависит от чего-то ещё; по крайней мере, у меня под Linux нет проблемы с выделением пробела после слова в редакторе при двойном клике. Не то, чтобы я совсем никакой тонкой настройки не выполнял, включая about:config, но про редактирование поведения с автовыделением пробела первый раз слышу.
Evengard
01.11.2019 23:55Нашёл настройку. Попробуйте поменять layout.word_select.eat_space_to_next_word в false
Evir
03.11.2019 14:03
Вы не поняли. У меня под Linux нет такой проблемы – пробел при двойном клике по слову не выделяется вместе со словом. Но я уже после своего комментария под Windows на той же версии попробовал – там как раз выделяется. Но виндой я сравнительно редко пользуюсь, так что мне не страшно. Вообще, чаще раздражает (в том числе и в Firefox вроде бывало) выделение текста по словам через Ctrl+Shift+{<,>}. Например, в MonoDevelop есть плюсы (нравится наличие двух видов горячих клавиш – выделять по целым словам, или «частями» по camelCase) и минусы (выделяет чисто по словам, без учёта знаков препинания – в конце строки «прыгает» не к "};", а сразу выделяет до конца слова где-нибудь на следующей строке, а то и через одну).
Но спасибо, что указали настройку – кому-нибудь может пригодиться, так что пусть на виду будет.

nuclight
01.11.2019 18:19И таких мелочей очень много везде, на каждом шагу. Мало кто заботится об удобстве работы с информацией, а выделение и копирование — не менее важно, чем читабельность.
Причем чем дальше, тем больше софт деградирует. Например в Telegram для Android нельзя скопировать часть сообщения для ответа, только целиком и потом трахатся в узком поле ввода.
mib
01.11.2019 19:38В скайпе тоже, если тебе присылают чужой quote — его содержимое нельзя выделить, только контекстное меню скопировать и потом куда-то вставить, и попробовать выделить там.
Такое ощущение, что все эти UI/UX эволюционируют куда-то в тупик.

mSnus
01.11.2019 12:10+3Для смешанного текста надо просто использовать два разных цвета выделения.

Для эмодзи должна выпадать панель как для иероглифов с вариантами цвета кожи и опцией "разбить на основной символ и модификатор". Собственно, эмодзи и есть иероглиф, странно с ним работать как с буквой латинского алфавита.
Nalivai
01.11.2019 13:33+1И что дает разный цвет? Это теперь не два а три буффера? Какую стрелку надо нажать чтобы выделить следующий символ? Где текущий курсор? Что скопируется? Что вставится?
mSnus
01.11.2019 14:25+2Разный цвет даёт то, что исчезает ложное ощущение непрерывности выделения. Буферы нужны разные, само собой, раз уж тут можно выделать два не связанных между собой куска текста (llo и he), не говоря уж об LTR/RTL.
Курсор при удержании, например, кнопки "вправо", должен бежать в направлении набора текста. То есть LTR, перескок на правый край для арабского RTL, перескок на начало следующего фрагмента LTR. Точно так же, как глаз читает эти смешанные тексты.
Для копирования/вставки — собственно, выделенный фрагмент как есть: llo+арабская вязь+he. Что смущает в этом подходе?
Evir
01.11.2019 19:32Мне понравилась фича, которую я заметил в отладочной консоли в QtCreator:

Небольшая стрелка, которая мигает вместе с курсором (даже без выделения текста) на строках со смешанным содержимым. На самом деле, эта штука присутствует и в редакторе кода, но почему-то там работает не очень адеватно.

Lsh
01.11.2019 22:07-1Эмодзи надо бойкотировать и не реализовывать никак. Сама их идея очень так себе и вызывает кучу проблем.
mSnus
02.11.2019 15:59Эмодзи отличаются только тем, что они цветные. Вы же не расист?
Псевдографика быба и в ASCII, а лигатуры (комбинации букв) есть и в типографике европейских языков. Просто со времён всеобщей работы в текстовом режиме прогресс идёт довольно медленно, а так — возможность использовать комбинации и варианты символов это мощная и полезная штука, возвращающая утерянные по сравнению с рукописным текстом возможности.
Если для этого нужны эмодзи — пусть будут. Кстати, эмодзи это тоже не только желтые смайлики, но и куча полезной псевдографики.
Как говорится, чем бы дитя ни тешилось, лишь бы эмодзи не анимировало ))
Lsh
02.11.2019 16:16Псевдографика быба и в ASCII
Так это был костыль, т.к. не было нормального графического режима или мощностей для него.
Если проводить аналогию с псевдографикой, то давайте сделаем не только символы вертикальной и горизонтальной линии, но и линии под 45 градусов, под 30, 15, пунктирные, штрих-пунктирные, красно-зелёные. Вы же не расист, вы что, против красно-зелёных линий?
а лигатуры (комбинации букв) есть и в типографике европейских языков
А в русском языке есть буква «ё», с точками. Но я не предлагаю её выкинуть, как и лигатуры. И буква «ё» и лигатуры появились до компьютеров, мы ими пишем, просто так отказаться от них не можем. И никто не добавляет постоянно новые лигатуры в кодировки, при чём разные, для людей традиционной и нетрадиционной ориентации.
Кстати, эмодзи это тоже не только желтые смайлики
Прекрасно! Только эмодзи на мой взгляд даже с этой задачей справляются достаточно плохо.
В разных шрифтах, на разных системах они отличаются. Что, если весёлая какашка на моём устройстве выглядит не так, как на устройстве получателя сообщения? Вдруг она там недостаточно весёлая?
И какой из всего этого вывод? Правильно! Всей это ерунде не место в Unicode. Для этого есть просто картинки. Есть векторные картинки. Давайте какой-нибудь комитет по эмодзи выйдет и скажет, вот вам SVG, поддерживайте его все! И тогда весёлая какашка будет точно такой же, что на моём экране, что на экране получателя сообщения.mSnus
02.11.2019 16:35Так ведь смысл псевдографики как раз в том, чтобы парой байтов вроде :happyshithead: закодировать графику, которая иначе займёт в тысячи раз больше. Точность отображения неважна.
Lsh
02.11.2019 16:47Но нельзя же запихнуть в Unicode всё варианты.
Где какашка с азиатскими глазами? Нет? Расизм!
А картинка может быть какой угодно, как раз картинки ближе по возможностям к рукописному вводу.mSnus
02.11.2019 16:52Во-первых, можно, с комбинацией символов — пожалуйста. :happyshitehead:asian:
И здесь легко сделать graceful degradation, а с картинками — никак.
Конечно же, картинки более универсальны, но через SMS вы картинку уже не отправите, на слабом устройстве типа часов — не отрендерите (или подвесите часы) и так далее. Да и просто в броузере памяти и ресурсов уйдёт в разы больше, чтобы рендерить это всё каждый раз заново.
Evir
03.11.2019 14:15Вот только в итоге этих эмодзи такая куча, что на телефоне сложно найти даже просто обычный смайлик с нужной эмоцией. И это даже не учитывая, что смайлики/эмодзи – не то же самое, что выражения эмоций на лицах (которые, в общем-то, универсальны), и их можно воспринимать по-разному. Я имею в виду, что изображение «смущённого» другой человек может воспринять, например, как потеющего (мало ли, чего он там красный). А если учесть, что у собеседника может быть другая мобильная OS (или другая версия той же), с другой отрисовкой… А ещё десктопы же есть, и там, чаще всего, с этими самыми эмодзи зачастую вообще беда.
Таким образом, скоро любое приложение с вводом текста превратится в мини-версию фотошопа с редактором вида «выберите смайл, пол/возраст/цвет кожи каждого персонажа на нём, шапочку, разрез глаз, очки, настроение и ещё 101 параметр». Возможно, получившийся эмодзи в одну смс уже не поместится.
При этом в том же QIP 2005 было десятка два с половиной «колобков», и их хватало! Мне до сих пор хочется иногда отправить *WALL* или его аналог; только обычно ничего подобного нет.mSnus
03.11.2019 16:35Да, отсутствие стандартной текстовой транслитерации меня тоже расстраивает — иногда это очень удобно, например, в комментах выше. И отсутствие привычных по BBcode или QIP смайликов тоже вызывает сожаление.
Да и дрейф в толерантность кажется излишним — в конце концов, никто же не воспринимал желтых колобков как бодипозитивных китайцев и не требовал сделать смайлики розовыми и худыми!
Но сама по себе возможность ввода и использования иероглифов, лигатур и вариантов начертания буквы — это здорово, особенно когда используется здраво ))
perfect_genius
Этими несколькими особыми случаями не убедили. Будут ли ещё другие?
perfect_genius
Перевод хорош, не смог распознать. Глянул источник — статья новая и больше пока нет.
Здесь на Хабре было про сложности, если пропустили: «Текстовый редактор — это вам не высшая математика, тут думать надо»
namikiri
Спасибо за напоминание об этой статье. С удовольствием вспомнил те самые примеры, на которых демонстрировалась обработка текста. Не то что здесь, скучное «hello».