
Тестировать API и интерфейсы можно по-разному. В связи с открытием широкого доступа к Acronis Cyber Platform мы вынуждены были искать способы проверить сервисы “на прочность” с самых разных позиций. В этом посте ведущий архитектор программного обеспечения Acronis Дмитрий Саломатин рассказывает о том, как мы выбирали фреймворк для тестирования, с какими сложностями сталкивались, и какие доработки пришлось делать самостоятельно.

Сразу скажу, что мы в Acronis особенно внимательно относимся к тестированию API. Дело в том, что наши собственные продукты обращаются к сервисам через те же самые API, которые служат для подключения внешних систем. Поэтому необходимо перформанс-тестирование каждого интерфейса. Мы проверяем работу API и изолированно проверяем работу UI. Результаты тестов позволят оценить, хорошо ли работает само API, а также пользовательские интерфейсы. Подтвердить успешную разработку или сформулировать задание для дальнейшей доработки.
Но тесты тестам рознь. Иногда сервис демонстрирует деградацию не сразу. Даже если мы запускаем сервис, аналогичный уже выпущенным в релиз продуктам, для проверки можно нагрузить его теми же данными, которые используются “в проде”. В этом случае можно увидеть регрессию, но совершенно невозможно оценить перспективу. Вы просто не узнаете, что будет, если объем данных резко возрастет или увеличится частота запросов.
Ниже приведен график, показывающий как изменяется количество API обрабатываемых бэкендом в секунду с ростом объема данных в системе

Допустим, что тестируемый нами сервис находится в состоянии, характерном для начала данного графика. В этом случае даже при небольшом росте системы скорость работы данного API будет резко снижаться.
Чтобы исключить подобные ситуации мы в несколько раз увеличиваем объемы данных, наращиваем число параллельных потоков, чтобы понять, как поведет себя сервис, если нагрузка растет кардинально.
Но тут есть еще один нюанс. Если работа “знакомого” сервиса меняется в соответствии с ростом количества данных, его развитием, появлением новых функций, с новыми сервисами ситуация обстоит еще сложнее. Когда в продукте появляется концептуально новый сервис, его нужно рассмотреть с самых разных сторон. Для такой ситуации нужно подготовить специальные наборы данных, провести нагрузочное тестирование, предположив возможные сценарии использования.
Обычно наши процессы тестирования происходят по “спиральной схеме”. Одна из фаз тестирования подразумевает использование API для увеличения количества сущностей (sizing), а вторая выполнение новых операций на существующих наборах данных (usage). Все тесты запускаются в разное количество потоков. Например, у нас есть сервис Animals, и у него имеются следующие API:
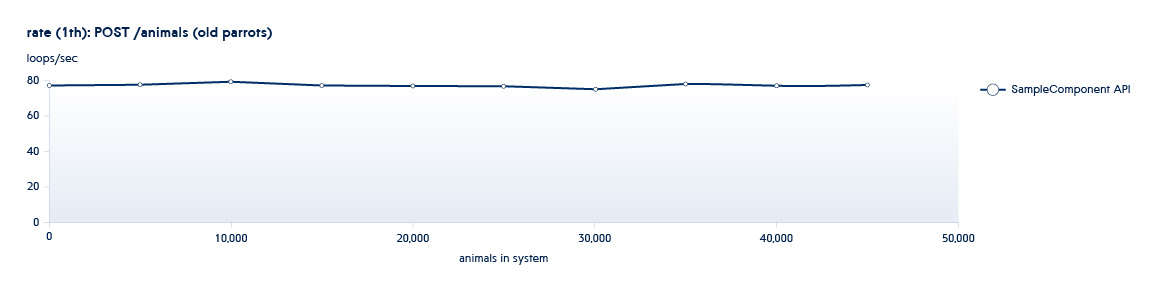
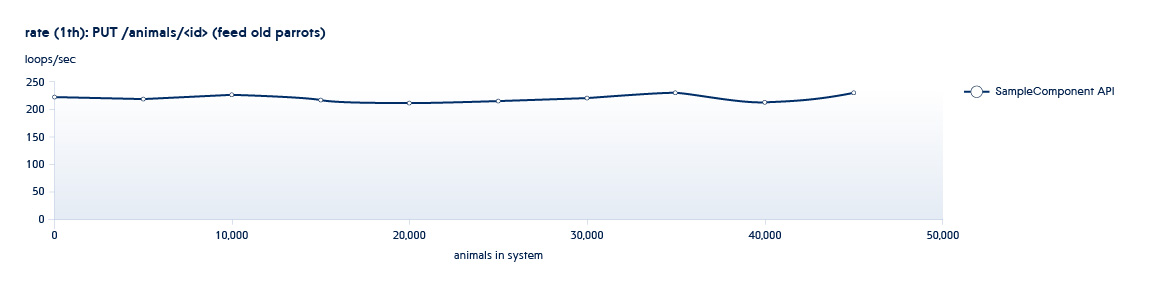
1 и 2 – это API, вызываемые в sizing тестах – они увеличивают количество новых сущностей в системе.
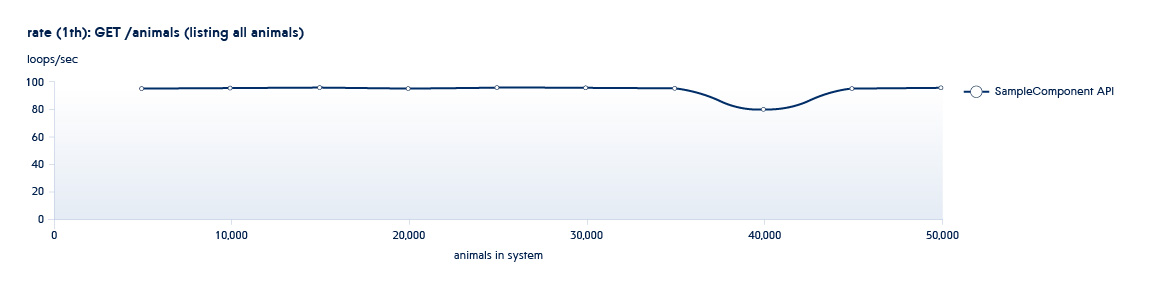
3 – это API, вызываемые в фазе usage. Данное API имеет массу параметров фильтрации. Соответственно будет более одного теста
Таким образом, запуская итеративно sizing и usage тесты, мы получаем картину изменения производительности системы с ее ростом

Чтобы проводить масштабное тестирование большого количества новых и обновленных сервисов, нам нужен был гибкий framework, который позволил бы запускать разные сценарии. А главное – действительно тестировать API, а не просто создавать нагрузку на сервисы однообразными операциями.
Performance тестирование может проходить как на синтетической нагрузке, так и с использованием паттерна нагрузки, записанной с production. Оба подхода имеют свои плюсы и минусы. Способ с реальной нагрузкой можно более охарактеризовать как стресс тестирование – мы получаем реальную картину работоспособности системы при такой нагрузке, но не имеем возможности легко определить проблемные места, измерить пропускную способность компонентов по отдельности, не получаем точных чисел какую нагрузку могут выдержать отдельные компоненты. В случае с синтетическим подходом мы получаем точные числа, имеем большую гибкость, и легко можем установить проблемные места, а запустив несколько тестовых сценариев в параллель мы можем воспроизвести и стрессовую нагрузку. Основными минусами второго подхода являются большие трудозатраты на написание тестовых сценариев, а также растущий риск упустить какой-то важный сценарий. Поэтому мы решили пойти более сложным путем.
Итак, выбор фреймворка определялся задачей. А наша задача заключается в том, чтобы:
На рынке существует очень много Performance фреймворков, которые могут выстреливать огромное количество одинаковых запросов. Многие из них ничего не позволяют менять внутри (например, Apache Benchmark) или с ограниченными возможностями для описания сценариев (например, JMeter).
У нас в тестировании обычно используются более сложные сценарии. Часто вызовы API нужно делать последовательно — один за другим, либо менять параметры запросов в соответствии с какой-то логикой. Самый простой пример, когда мы хотим протестировать REST API вида
В этом случае нужно заранее узнать <id> ресурса, который мы хотим изменить, чтобы измерять чистое время выполнения запроса.
Поэтому нам необходима возможность создания скриптов для запуска сложных тестовых запросов.
Поскольку продукты Acronis рассчитаны на высокую нагрузку, мы тестируем API десятками тысяч запросов в секунду. Оказалось, что далеко не каждый фреймворк может позволить сделать это. Например, Python не всегда и не во всех случаях получается использовать для тестирования, так как из-за особенностей языка возможность создавать большую многопоточную нагрузку оказывается ограниченной
Другая проблема — использование ресурсов. Например, сначала мы рассматривали фреймворк Locust, который можно запустить сразу с нескольких аппаратных узлов (node) и получить хорошую производительность. Но при этом на работу тест-системы уходит много ресурсов, и она оказывается дорогой в эксплуатации.
В результате мы выбрали фреймворк К6, который позволяет описывать сценарии на полноценном Javascript, и обеспечивает производительность выше среднего. Этот фреймворк написан на Go, и стремительно набирает популярность. Например, на Github проект уже получил почти 5,5 тысяч звезд! K6 активно развивается, и сообщество уже предложило почти 3 тысячи коммитов, а проект насчитывает 50 контрибьюторов, создавших 36 веток кода. Конечно, К6 еще далек от идеала, но постепенно фреймворк становится все лучше, а о его сравнении с Jmeter можно почитать здесь.
Учитывая “молодость” К6, даже после взвешенного выбора фреймворка, мы столкнулись с целым рядом проблем. Например, перед тестированием API вида /endpoint/ необходимо сначала каким-то образом найти эти endpoint. Использовать одни и те же значения мы не можем, потому что из-за кеширования результаты будут некорректными.
Получить нужные данные можно разными способами:
Второй способ работает быстрее, а при использовании реляционных DB зачастую оказывается намного удобнее, так как он позволяет экономить значительное время при длительных тестах. Единственное “но” заключается в том, что использовать его можно только в случае, если код сервиса и тесты пишут одни и те же люди. Потому что для работы через БД тесты всегда должны быть в актуальном состоянии. Однако в случае с К6, фреймворк не имеет механизмов доступа к базам данных. Поэтому пришлось написать соответствующий модуль самостоятельно.
Еще одна проблема возникает при тестировании не идемпотентных API. В этом случае важно, чтобы они вызывались только раз с одними и теми же параметрами (например, API DELETE). В своих тестах готовим тестовые данные заранее, на этапе setup phase, когда происходит настройка и подготовка системы. А в процессе теста делаются замеры чистых вызовов API, так как времени и ресурсов на подготовку данных уже не требуется. Однако при этом возникает проблема распределения заранее подготовленных данных по не синхронизированным потокам основного теста. Данная проблема была успешно решена путем написания внутренней очереди данных. Но это целая большая тема, о которой мы расскажем в следующих постах.
Подводя итог, хочется отметить, что найти полностью готовый фреймворк оказалось непросто, и какие-то вещи все равно пришлось доделывать руками. Тем не менее, на сегодняшний день мы имеем подходящий нам инструмент, который с учетом доработок, позволяет проводить сложные тесты, создавая симуляцию высоких нагрузок, чтобы гарантировать работоспособность API и GUI в разных условиях.
В следующем посте я расскажу о том, как мы решали задачу тестирования сервиса, поддерживающего одновременное подключение сотен тысяч соединения используя минимальные ресурсы.
Сразу скажу, что мы в Acronis особенно внимательно относимся к тестированию API. Дело в том, что наши собственные продукты обращаются к сервисам через те же самые API, которые служат для подключения внешних систем. Поэтому необходимо перформанс-тестирование каждого интерфейса. Мы проверяем работу API и изолированно проверяем работу UI. Результаты тестов позволят оценить, хорошо ли работает само API, а также пользовательские интерфейсы. Подтвердить успешную разработку или сформулировать задание для дальнейшей доработки.
Но тесты тестам рознь. Иногда сервис демонстрирует деградацию не сразу. Даже если мы запускаем сервис, аналогичный уже выпущенным в релиз продуктам, для проверки можно нагрузить его теми же данными, которые используются “в проде”. В этом случае можно увидеть регрессию, но совершенно невозможно оценить перспективу. Вы просто не узнаете, что будет, если объем данных резко возрастет или увеличится частота запросов.
Ниже приведен график, показывающий как изменяется количество API обрабатываемых бэкендом в секунду с ростом объема данных в системе
Допустим, что тестируемый нами сервис находится в состоянии, характерном для начала данного графика. В этом случае даже при небольшом росте системы скорость работы данного API будет резко снижаться.
Чтобы исключить подобные ситуации мы в несколько раз увеличиваем объемы данных, наращиваем число параллельных потоков, чтобы понять, как поведет себя сервис, если нагрузка растет кардинально.
Но тут есть еще один нюанс. Если работа “знакомого” сервиса меняется в соответствии с ростом количества данных, его развитием, появлением новых функций, с новыми сервисами ситуация обстоит еще сложнее. Когда в продукте появляется концептуально новый сервис, его нужно рассмотреть с самых разных сторон. Для такой ситуации нужно подготовить специальные наборы данных, провести нагрузочное тестирование, предположив возможные сценарии использования.
Особенности перформанс-тестирования в Acronis
Обычно наши процессы тестирования происходят по “спиральной схеме”. Одна из фаз тестирования подразумевает использование API для увеличения количества сущностей (sizing), а вторая выполнение новых операций на существующих наборах данных (usage). Все тесты запускаются в разное количество потоков. Например, у нас есть сервис Animals, и у него имеются следующие API:
POST /animals
PUT /animals/<id>
GET /animals?filter=criteria1 и 2 – это API, вызываемые в sizing тестах – они увеличивают количество новых сущностей в системе.
3 – это API, вызываемые в фазе usage. Данное API имеет массу параметров фильтрации. Соответственно будет более одного теста
Таким образом, запуская итеративно sizing и usage тесты, мы получаем картину изменения производительности системы с ее ростом
Framework needed…
Чтобы проводить масштабное тестирование большого количества новых и обновленных сервисов, нам нужен был гибкий framework, который позволил бы запускать разные сценарии. А главное – действительно тестировать API, а не просто создавать нагрузку на сервисы однообразными операциями.
Performance тестирование может проходить как на синтетической нагрузке, так и с использованием паттерна нагрузки, записанной с production. Оба подхода имеют свои плюсы и минусы. Способ с реальной нагрузкой можно более охарактеризовать как стресс тестирование – мы получаем реальную картину работоспособности системы при такой нагрузке, но не имеем возможности легко определить проблемные места, измерить пропускную способность компонентов по отдельности, не получаем точных чисел какую нагрузку могут выдержать отдельные компоненты. В случае с синтетическим подходом мы получаем точные числа, имеем большую гибкость, и легко можем установить проблемные места, а запустив несколько тестовых сценариев в параллель мы можем воспроизвести и стрессовую нагрузку. Основными минусами второго подхода являются большие трудозатраты на написание тестовых сценариев, а также растущий риск упустить какой-то важный сценарий. Поэтому мы решили пойти более сложным путем.
Итак, выбор фреймворка определялся задачей. А наша задача заключается в том, чтобы:
- Находить узкие места в API
- Проверять устойчивость к высоким нагрузкам
- Оценивать эффективность работы сервиса при росте объемов данных
- Выявлять накапливающиеся ошибки, проявляющиеся со временем
На рынке существует очень много Performance фреймворков, которые могут выстреливать огромное количество одинаковых запросов. Многие из них ничего не позволяют менять внутри (например, Apache Benchmark) или с ограниченными возможностями для описания сценариев (например, JMeter).
У нас в тестировании обычно используются более сложные сценарии. Часто вызовы API нужно делать последовательно — один за другим, либо менять параметры запросов в соответствии с какой-то логикой. Самый простой пример, когда мы хотим протестировать REST API вида
PUT /endpoint/resource/<id>В этом случае нужно заранее узнать <id> ресурса, который мы хотим изменить, чтобы измерять чистое время выполнения запроса.
Поэтому нам необходима возможность создания скриптов для запуска сложных тестовых запросов.
Быстрее
Поскольку продукты Acronis рассчитаны на высокую нагрузку, мы тестируем API десятками тысяч запросов в секунду. Оказалось, что далеко не каждый фреймворк может позволить сделать это. Например, Python не всегда и не во всех случаях получается использовать для тестирования, так как из-за особенностей языка возможность создавать большую многопоточную нагрузку оказывается ограниченной
Другая проблема — использование ресурсов. Например, сначала мы рассматривали фреймворк Locust, который можно запустить сразу с нескольких аппаратных узлов (node) и получить хорошую производительность. Но при этом на работу тест-системы уходит много ресурсов, и она оказывается дорогой в эксплуатации.
В результате мы выбрали фреймворк К6, который позволяет описывать сценарии на полноценном Javascript, и обеспечивает производительность выше среднего. Этот фреймворк написан на Go, и стремительно набирает популярность. Например, на Github проект уже получил почти 5,5 тысяч звезд! K6 активно развивается, и сообщество уже предложило почти 3 тысячи коммитов, а проект насчитывает 50 контрибьюторов, создавших 36 веток кода. Конечно, К6 еще далек от идеала, но постепенно фреймворк становится все лучше, а о его сравнении с Jmeter можно почитать здесь.
Трудности и их решения
Учитывая “молодость” К6, даже после взвешенного выбора фреймворка, мы столкнулись с целым рядом проблем. Например, перед тестированием API вида /endpoint/ необходимо сначала каким-то образом найти эти endpoint. Использовать одни и те же значения мы не можем, потому что из-за кеширования результаты будут некорректными.
Получить нужные данные можно разными способами:
- Вы можете запросить их через API
- Можно использовать прямой доступ в базу данных
Второй способ работает быстрее, а при использовании реляционных DB зачастую оказывается намного удобнее, так как он позволяет экономить значительное время при длительных тестах. Единственное “но” заключается в том, что использовать его можно только в случае, если код сервиса и тесты пишут одни и те же люди. Потому что для работы через БД тесты всегда должны быть в актуальном состоянии. Однако в случае с К6, фреймворк не имеет механизмов доступа к базам данных. Поэтому пришлось написать соответствующий модуль самостоятельно.
Еще одна проблема возникает при тестировании не идемпотентных API. В этом случае важно, чтобы они вызывались только раз с одними и теми же параметрами (например, API DELETE). В своих тестах готовим тестовые данные заранее, на этапе setup phase, когда происходит настройка и подготовка системы. А в процессе теста делаются замеры чистых вызовов API, так как времени и ресурсов на подготовку данных уже не требуется. Однако при этом возникает проблема распределения заранее подготовленных данных по не синхронизированным потокам основного теста. Данная проблема была успешно решена путем написания внутренней очереди данных. Но это целая большая тема, о которой мы расскажем в следующих постах.
Готовый фреймворк
Подводя итог, хочется отметить, что найти полностью готовый фреймворк оказалось непросто, и какие-то вещи все равно пришлось доделывать руками. Тем не менее, на сегодняшний день мы имеем подходящий нам инструмент, который с учетом доработок, позволяет проводить сложные тесты, создавая симуляцию высоких нагрузок, чтобы гарантировать работоспособность API и GUI в разных условиях.
В следующем посте я расскажу о том, как мы решали задачу тестирования сервиса, поддерживающего одновременное подключение сотен тысяч соединения используя минимальные ресурсы.
sfunx
Интересен следующий пост, и надеюсь, что его удастся написать и опубликовать ещё в этом году. Спасибо!