
С каждым днём всё большее число устройств создаёт всё больше данных. Управлять ими приходится во множестве точек, а не в нескольких централизованных облачных ЦОД. Иными словами, процесс управления выходит за пределы традиционных центров обработки данных и смещается к тому месту, где данные создаются, — на периферию сети, ближе к конечным пользователям. Здесь данные генерируются различными датчиками, камерами, гаджетами и устройствами интернета вещей (IoT). Когда результаты их работы собираются и обрабатываются непосредственно на границе сети, их можно анализировать и использовать гораздо быстрее.

По мнению экспертов Gartner, к 2020 году более 50% всех данных, генерируемых предприятиями, будут обрабатываться за пределами традиционных ЦОД или облачной среды (сегодня этот показатель составляет лишь 10%). В такой архитектуре будут работать 5,6 млрд устройств интернета вещей (IoT). При этом объёмы продуцируемых устройствами данных исчисляются терабайтами, а интерпретировать и анализировать их зачастую нужно в реальном времени.
Чтобы помочь партнёрам и клиентам изучить этот тренд, Seagate объединилась с консорциумом компаний, которые специализируются на периферийных вычислениях, и выпустила отчёт «Data at the Edge». В нём также использовались результаты исследования, проведённого IDC. Целью отчёта было проиллюстрировать некоторые проблемы с данными, которые сегодня актуальны для компаний, и показать, как компаниям лучше управлять своими ИТ-ресурсами.
«Игроки рынка систем хранения данных прошли в развитии своего бизнеса несколько этапов. Пару десятилетий назад перспективными считались средства хранения для серверных систем, потом в центре внимания оказались локальные ЦОД. Это отразилось на линейках продуктов вендоров: они стали производить накопители для данного сегмента. Затем началось развитие облачного хранения, облачных вычислений. Следующий этап — периферийные вычисления, — рассказывает Александр Малинин, директор представительства компании Seagate в России и СНГ. — Поскольку данных становится очень много, и генерируются они не только людьми, но и машинами, отправлять всё это в ЦОД не всегда оптимально. Есть смысл произвести часть вычислений за пределами дата-центров и передать в ЦОД уже обработанные результаты. По сути, это создание ещё одного контура вычислений, где данные аккумулируются, хранятся какое-то время, обрабатываются и передаются в основной дата-центр для дальнейшего хранения и доступа к ним».
Поскольку миллиарды устройств продолжают подключаться к сети, собирая и генерируя зеттабайты данных, современным централизованным облачным средам требуется поддержка новой периферийной ИТ-архитектуры. А размещая вычислительные, сетевые ресурсы и ресурсы хранения в непосредственной близости от этих устройств, можно анализировать данные прямо на месте.
Благодаря тому, что данные проходят первичную обработку там же, где создаются, часть управленческих решений (например, для корректировки режима работы промышленного оборудования) можно принимать локально, с минимальной задержкой.
Периферия может располагаться где угодно: от заводских цехов до ферм, на крышах домов и на сотовых вышках, в любых транспортных средствах на суше, на море и в воздухе. Будучи внешней границей сети, она часто находится в сотнях километров от ближайшего корпоративного или облачного центра обработки данных и очень близко к источнику данных.
Согласно исследованию IDC, к 2020 году 45% всех данных, генерируемых устройствами интернета вещей, будут храниться и обрабатываться в пограничных сегментах сети или около них. Есть много случаев, когда вычислительный процесс лучше переместить на периферию. Так, в «умных городах» обработка и анализ данных ближе к их источнику сокращает время задержки и позволяет различным службам быстрее реагировать на ситуацию.
В интеллектуальных транспортных системах периферийные вычисления позволяют обрабатывать информацию локально, отправляя в облако только самые важные данные. Эта технология уже используется в интеллектуальных транспортных системах. Также этот подход повышает безопасность и эффективность перевозок. Самоуправляемые автомобили должны моментально реагировать на полученные данные, поскольку даже малейшая задержка может быть опасной.
Распространение периферийных вычислений потребует новой инфраструктуры для хранения и управления данными. Например, «умная фабрика» будет создавать около 5 петабайт видео в день, «умный город» с населением 1 миллион человек — 200 петабайт данных ежедневно, а автономный автомобиль — 4 терабайта.
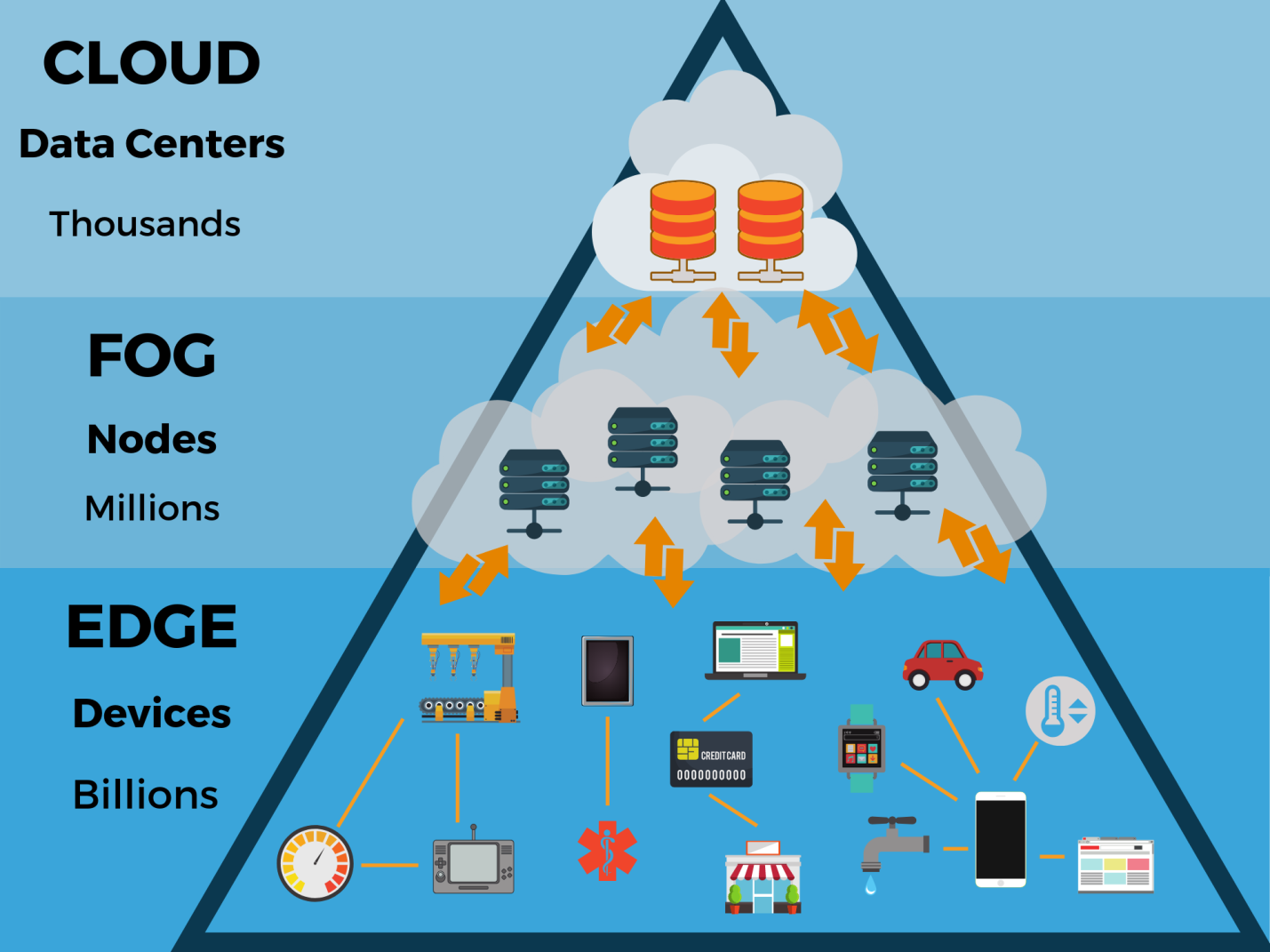
Что будут означать эти данные на границе? Как такая эволюция повлияет на структуру и функционирование существующих центров обработки данных и облачных ЦОД? Не вытеснят ли периферийные вычисления облачные, которые преобладают сегодня, потому что они более гибкие и масштабируемые в плане приложений?
Авторы отчёта «Data at the Edge» подчёркивают, что хотя периферийные вычисления позволяют более эффективно использовать данные, традиционная инфраструктура не утратит своё значение. Поскольку огромные объёмы данных будут создаваться вне традиционных центров их обработки, облако расширится до периферии. То есть речь не о сценарии «облако против периферии», а, скорее, об «облаке с периферией».
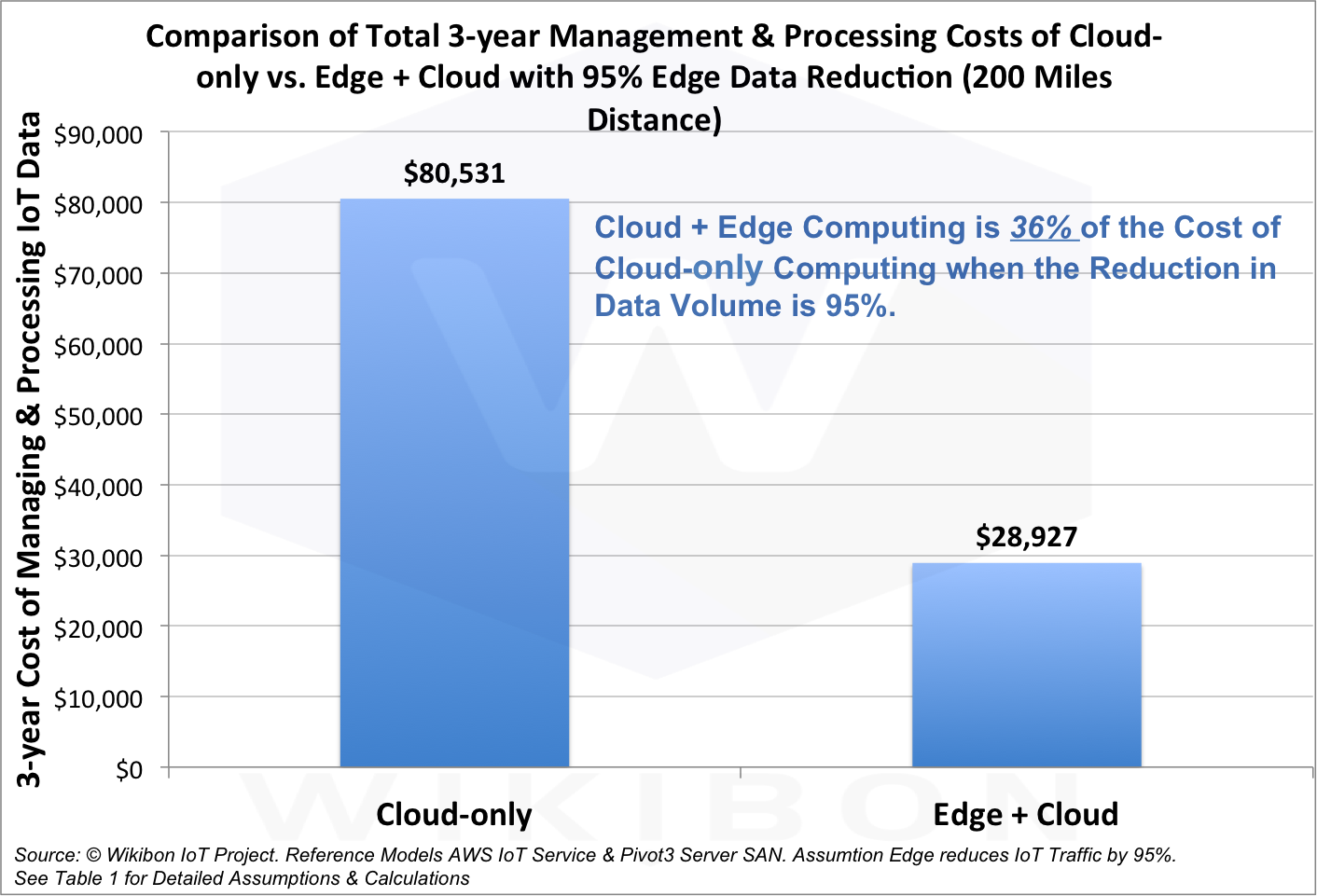
Как подсчитали аналитики, скомбинировать облачные и периферийные вычисления обойдётся всего в 36% стоимости чисто облачного варианта, а объём передаваемых данных при этом сократится на 95%.
Таким образом, будущее — за совместной работой периферии и облака. Это поможет предприятиям мгновенно принимать более взвешенные решения, повысить их производительность, эффективность работы и лучше удовлетворять потребности клиентов.
Сегодня почти любой бизнес или организация связаны с обработкой и хранением данных. Инновации в управлении информацией проложили путь к более эффективным способам её использования. Это относится и к данным на периферии.
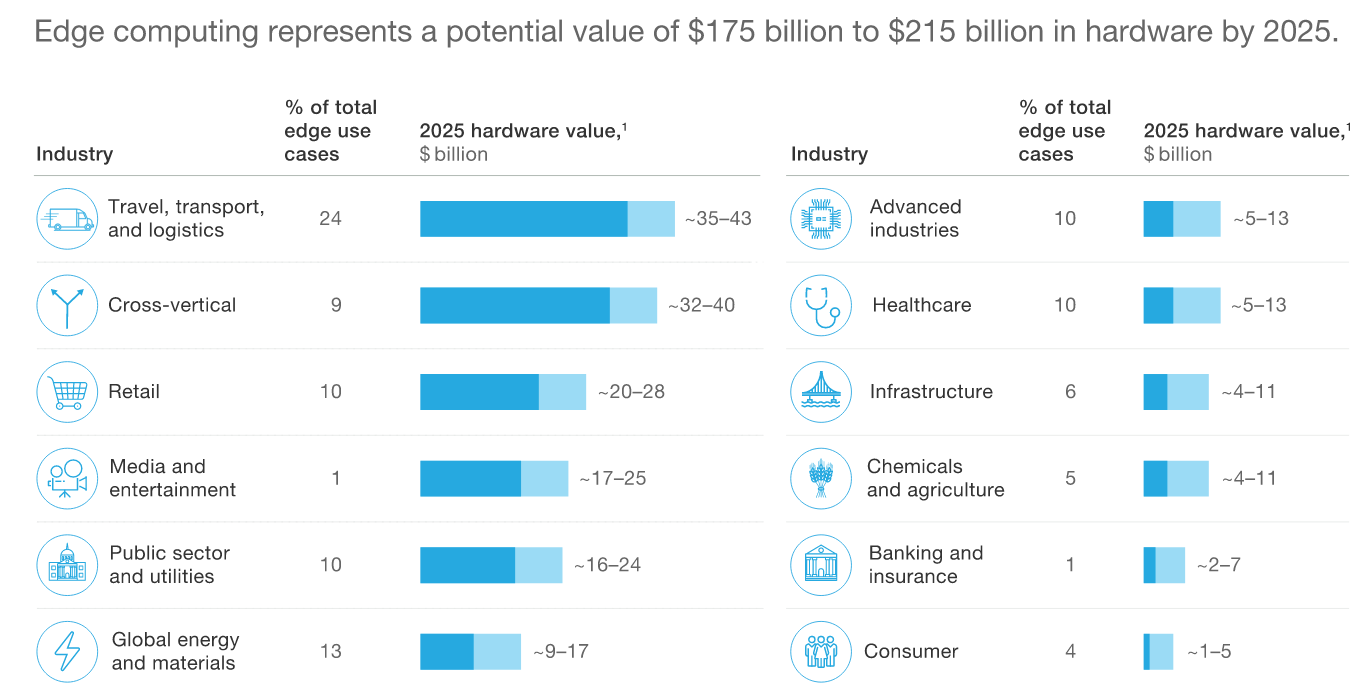
По прогнозам McKinsey, объём мирового рынка оборудования для периферийных вычислений к 2025 году составит 175 — 215 млрд долларов.
Что это значит для крупных предприятий, городов, малого бизнеса и отдельных потребителей, какие даёт преимущества? Как данные на периферии помогут нам лучше работать, отдыхать, жить, путешествовать? Какие возможности для аналитики данных возникают на границе сети? Именно на эти вопросы отвечает отчёт Seagate.
В «Data at the Edge» приводится несколько примеров, как периферийные вычисления уже сегодня трансформируют глобальный бизнес и приносят пользу людям. Например, в Чили ирригационная система с искусственным интеллектом, оснащённая датчиками, сокращает потребление воды на 70%.
А вот что происходит на собственных заводах Seagate. Компания производит миллионы единиц продукции ежеквартально и миллиарды датчиков ежегодно. Это требует внедрения высокоавтоматизированных процессов, причём система должна принимать от 20 до 30 решений в секунду. При такой скорости некогда ждать, пока данные, собранные на производственной линии, будут отправлены в центр для обработки, а потом оттуда же придёт решение.

Мы не можем остановить производственную линию: нужно сохранять темпы выпуска продукции, одновременно обеспечивая её высокое качество. А значит, решения надо принимать там же, где генерируются данные. Для этого в Seagate создали собственную технологию для обнаружения аномалий и анализа изображений на заводской площадке. Это сокращает время ожидания с сотен до менее 10 миллисекунд.
«Насколько широко сейчас используются периферийные вычисления в России? Во-первых, внедрение любых новых технологий требует времени. Во-вторых, и сам термин «периферийные вычисления» ещё не вошел в обиход. То есть даже если компания и применяет данный подход, то называет его иначе, — объясняет Александр Малинин. — Между тем периферийные вычисления часто используются, например, в геодезии, в нефтегазовой отрасли. Данные геодезических исследований собираются и обрабатываются в небольшом локальном дата-центре, а затем отправляются в централизованное хранилище. Периферийные вычисления применяются и в нефтегазовой отрасли, где собирается большой объём данных и хранить их все не требуется».
«С развитием телекоммуникаций, с увеличением скорости передачи данных количество периферийных дата-центров будет только расти, — продолжает Александр Малинин. — Да и сам термин «периферийные вычисления» получит большее распространение. Отрасли хранения данных есть что для этого предложить. Существуют различные технологии хранения, отвечающие разным задачам, есть математические алгоритмы для анализа данных. Основная проблема сейчас — в телекоммуникационных технологиях, в получении данных. Например, интернет вещей предлагает широкое использование беспроводных подключений. Это потребует развёртывания беспроводных сетей, например 5G. Похожие процессы происходили при внедрении технологии больших данных. Её уже начали использовать, но называли иначе: это вопрос терминологии».
Что стимулирует спрос на новую вычислительную архитектуру? По результатам исследований и опросов руководителей ИТ в Seagate выделили четыре ключевых фактора, определяющих спрос на периферийные вычисления. Это задержка в сети (латентность); недостаточная пропускная способность коммуникационных каналов для доставки больших объёмов данных в ЦОД; эффективность и стоимость решения; суверенитет данных и соблюдение нормативов.
Фактор номер один — латентность. Из-за физических ограничений ИТ- и телекоммуникационной инфраструктуры требуется слишком много времени, чтобы переместить данные из места их создания в центральный узел. Таким образом, задержка становится ключевым фактором: отправка данных в центральный узел и обратно может занять и 100, и 200 миллисекунд.
Фактор номер два — проблема пропускной способности. Общие объёмы данных достигают уже не эксабайтных, а зеттабайтных масштабов. И они продолжают расти хотя бы из-за появления новых датчиков — не только датчиков температуры, погоды, вибрации или других, которые собирают сравнительно немного данных, но и камер, радаров, лидаров и других устройств, генерирующих очень много информации. В будущем таких датчиков станет ещё больше. Инфраструктура 5G может поддерживать миллионы устройств на квадратный километр, но где найти пропускную способность, чтобы отправить все данные в централизованные облачные ЦОД?
В-третьих, эффективность. Даже если вы сможете отправить все данные в централизованный ЦОД, затраты и сложность архитектуры для обработки такого большого объёма информации будут так велики, что система станет плохо управляемой. С системой, которая ведёт интенсивную обработку данных на периферии, ближе к источнику, дела обстоят намного лучше.
Наконец, четвёртый фактор — это требование, чтобы данные обрабатывались в соответствии с нормативами и стандартами, которые приняты у клиентов. Когда вы имеете дело с информационной безопасностью, вы часто не можете отправить данные из определённого региона или страны за рубеж для централизованной обработки. Это касается, например, персональной информации.
«Периферийные вычисления потребуют особых подходов к регулированию хранения данных, к обеспечению безопасности, в том числе и безопасности физического доступа к данным, — подчёркивает Александр Малинин. — Но мы однозначно увидим рост периферийных вычислений в ближайшие два-три года, потому что растёт количество запросов организаций на небольшие дата-центры, которые обслуживали бы и отдельные отрасли, и большие национальные компании. То есть, растёт количество запросов на организацию локального хранения данных».
Что это значит для ИТ-архитекторов, что они должны делать по-другому? Начнём с того, что проектирование традиционной инфраструктуры дата-центра или облачного центра обработки данных сильно отличается от разработки периферийной архитектуры. Традиционные центры обработки данных включают в себя системы охлаждения и кондиционирования, источники бесперебойного питания с двойным резервированием, системы физической безопасности. Их обслуживает целая команда специалистов.
Периферийный же центр (или, скорее, узел) обработки данных может находиться на телекоммуникационной вышке либо в небольшом помещении. Он часто подвергается воздействию внешней среды, поэтому его климат-контроль — сложная задача.
Что касается физической безопасности, то в архитектуру придётся встроить специальную защиту данных на случай стихийного бедствия или злонамеренных действий. Кроме того, из-за отсутствия персонала, который может быстро прийти и всё исправить, периферийные системы обязаны быть особенно надёжными. Если что-то случится, периферийный ЦОД должен сам восстановиться и продолжить работу.
Иными словами, если мы намереваемся обрабатывать данные на периферии, нужно довести до совершенства функциональность ЦОД: охлаждение, безопасность и т.д. Системные архитекторы уже работают над поиском решений. Цель — сделать так, чтобы периферийные центры обработки данных были простыми и обеспечивали достаточную телеметрию.
Кроме того, часть данных, которые будут обработаны на периферии, там не останутся. Они отправятся в центр для дальнейшего анализа или более длительного хранения. ИТ-архитектор обязан продумать этот процесс, определив стратегию управления данными.
Организации должны будут опираться на свою архитектуру облачных вычислений, учиться обрабатывать и, что особенно важно, безопасно хранить больше данных на периферии.
В отчёте о данных на периферии от компании Seagate и Vapor IO сказано, что у каждой организации есть ценность, о которой та даже не подозревает. Это её собственные данные. То, как мы создаём данные на периферии сети и работаем с ними, придаёт им особую значимость. Чтобы продолжать расти, компаниям необходимо пользоваться этим преимуществом.
«Проблемы внедрения периферийных вычислений сейчас в основном сводятся к телекоммуникациям, к скорости доступа к данным. Чем быстрее начнётся внедрение в России телекоммуникационных технологий следующего поколения, тем быстрее будут развиваться периферийные вычисления, — уверен Александр Малинин. — При этом развиваться периферийные вычисления будут параллельно с существующими дата-центрами и дополняя их. Коренной перестройки не потребуется».
По прогнозу Gartner, к 2021 году 40% предприятий в мире разработают полномасштабные стратегии периферийных вычислений. Поэтому вендоры сейчас торопятся занять перспективную нишу. В ближайшие пять лет рынок будет активно формироваться, появятся новые платформы и готовые решения, ориентированные на различные задачи и отрасли. Компании, которые займутся развитием периферийных вычислений, смогут стать лидерами в новых направлениях бизнеса.
По мнению экспертов Gartner, к 2020 году более 50% всех данных, генерируемых предприятиями, будут обрабатываться за пределами традиционных ЦОД или облачной среды (сегодня этот показатель составляет лишь 10%). В такой архитектуре будут работать 5,6 млрд устройств интернета вещей (IoT). При этом объёмы продуцируемых устройствами данных исчисляются терабайтами, а интерпретировать и анализировать их зачастую нужно в реальном времени.
Чтобы помочь партнёрам и клиентам изучить этот тренд, Seagate объединилась с консорциумом компаний, которые специализируются на периферийных вычислениях, и выпустила отчёт «Data at the Edge». В нём также использовались результаты исследования, проведённого IDC. Целью отчёта было проиллюстрировать некоторые проблемы с данными, которые сегодня актуальны для компаний, и показать, как компаниям лучше управлять своими ИТ-ресурсами.
Периферийные вычисления
«Игроки рынка систем хранения данных прошли в развитии своего бизнеса несколько этапов. Пару десятилетий назад перспективными считались средства хранения для серверных систем, потом в центре внимания оказались локальные ЦОД. Это отразилось на линейках продуктов вендоров: они стали производить накопители для данного сегмента. Затем началось развитие облачного хранения, облачных вычислений. Следующий этап — периферийные вычисления, — рассказывает Александр Малинин, директор представительства компании Seagate в России и СНГ. — Поскольку данных становится очень много, и генерируются они не только людьми, но и машинами, отправлять всё это в ЦОД не всегда оптимально. Есть смысл произвести часть вычислений за пределами дата-центров и передать в ЦОД уже обработанные результаты. По сути, это создание ещё одного контура вычислений, где данные аккумулируются, хранятся какое-то время, обрабатываются и передаются в основной дата-центр для дальнейшего хранения и доступа к ним».
Поскольку миллиарды устройств продолжают подключаться к сети, собирая и генерируя зеттабайты данных, современным централизованным облачным средам требуется поддержка новой периферийной ИТ-архитектуры. А размещая вычислительные, сетевые ресурсы и ресурсы хранения в непосредственной близости от этих устройств, можно анализировать данные прямо на месте.
Благодаря тому, что данные проходят первичную обработку там же, где создаются, часть управленческих решений (например, для корректировки режима работы промышленного оборудования) можно принимать локально, с минимальной задержкой.
Периферия может располагаться где угодно: от заводских цехов до ферм, на крышах домов и на сотовых вышках, в любых транспортных средствах на суше, на море и в воздухе. Будучи внешней границей сети, она часто находится в сотнях километров от ближайшего корпоративного или облачного центра обработки данных и очень близко к источнику данных.
Согласно исследованию IDC, к 2020 году 45% всех данных, генерируемых устройствами интернета вещей, будут храниться и обрабатываться в пограничных сегментах сети или около них. Есть много случаев, когда вычислительный процесс лучше переместить на периферию. Так, в «умных городах» обработка и анализ данных ближе к их источнику сокращает время задержки и позволяет различным службам быстрее реагировать на ситуацию.
В интеллектуальных транспортных системах периферийные вычисления позволяют обрабатывать информацию локально, отправляя в облако только самые важные данные. Эта технология уже используется в интеллектуальных транспортных системах. Также этот подход повышает безопасность и эффективность перевозок. Самоуправляемые автомобили должны моментально реагировать на полученные данные, поскольку даже малейшая задержка может быть опасной.
Распространение периферийных вычислений потребует новой инфраструктуры для хранения и управления данными. Например, «умная фабрика» будет создавать около 5 петабайт видео в день, «умный город» с населением 1 миллион человек — 200 петабайт данных ежедневно, а автономный автомобиль — 4 терабайта.
Что будут означать эти данные на границе? Как такая эволюция повлияет на структуру и функционирование существующих центров обработки данных и облачных ЦОД? Не вытеснят ли периферийные вычисления облачные, которые преобладают сегодня, потому что они более гибкие и масштабируемые в плане приложений?
Облака и периферия
Авторы отчёта «Data at the Edge» подчёркивают, что хотя периферийные вычисления позволяют более эффективно использовать данные, традиционная инфраструктура не утратит своё значение. Поскольку огромные объёмы данных будут создаваться вне традиционных центров их обработки, облако расширится до периферии. То есть речь не о сценарии «облако против периферии», а, скорее, об «облаке с периферией».
Как подсчитали аналитики, скомбинировать облачные и периферийные вычисления обойдётся всего в 36% стоимости чисто облачного варианта, а объём передаваемых данных при этом сократится на 95%.
Таким образом, будущее — за совместной работой периферии и облака. Это поможет предприятиям мгновенно принимать более взвешенные решения, повысить их производительность, эффективность работы и лучше удовлетворять потребности клиентов.
Бизнес на основе данных
Сегодня почти любой бизнес или организация связаны с обработкой и хранением данных. Инновации в управлении информацией проложили путь к более эффективным способам её использования. Это относится и к данным на периферии.
По прогнозам McKinsey, объём мирового рынка оборудования для периферийных вычислений к 2025 году составит 175 — 215 млрд долларов.
Периферия и жизнь
Что это значит для крупных предприятий, городов, малого бизнеса и отдельных потребителей, какие даёт преимущества? Как данные на периферии помогут нам лучше работать, отдыхать, жить, путешествовать? Какие возможности для аналитики данных возникают на границе сети? Именно на эти вопросы отвечает отчёт Seagate.
В «Data at the Edge» приводится несколько примеров, как периферийные вычисления уже сегодня трансформируют глобальный бизнес и приносят пользу людям. Например, в Чили ирригационная система с искусственным интеллектом, оснащённая датчиками, сокращает потребление воды на 70%.
А вот что происходит на собственных заводах Seagate. Компания производит миллионы единиц продукции ежеквартально и миллиарды датчиков ежегодно. Это требует внедрения высокоавтоматизированных процессов, причём система должна принимать от 20 до 30 решений в секунду. При такой скорости некогда ждать, пока данные, собранные на производственной линии, будут отправлены в центр для обработки, а потом оттуда же придёт решение.
Мы не можем остановить производственную линию: нужно сохранять темпы выпуска продукции, одновременно обеспечивая её высокое качество. А значит, решения надо принимать там же, где генерируются данные. Для этого в Seagate создали собственную технологию для обнаружения аномалий и анализа изображений на заводской площадке. Это сокращает время ожидания с сотен до менее 10 миллисекунд.
Периферийные вычисления в России
«Насколько широко сейчас используются периферийные вычисления в России? Во-первых, внедрение любых новых технологий требует времени. Во-вторых, и сам термин «периферийные вычисления» ещё не вошел в обиход. То есть даже если компания и применяет данный подход, то называет его иначе, — объясняет Александр Малинин. — Между тем периферийные вычисления часто используются, например, в геодезии, в нефтегазовой отрасли. Данные геодезических исследований собираются и обрабатываются в небольшом локальном дата-центре, а затем отправляются в централизованное хранилище. Периферийные вычисления применяются и в нефтегазовой отрасли, где собирается большой объём данных и хранить их все не требуется».
«С развитием телекоммуникаций, с увеличением скорости передачи данных количество периферийных дата-центров будет только расти, — продолжает Александр Малинин. — Да и сам термин «периферийные вычисления» получит большее распространение. Отрасли хранения данных есть что для этого предложить. Существуют различные технологии хранения, отвечающие разным задачам, есть математические алгоритмы для анализа данных. Основная проблема сейчас — в телекоммуникационных технологиях, в получении данных. Например, интернет вещей предлагает широкое использование беспроводных подключений. Это потребует развёртывания беспроводных сетей, например 5G. Похожие процессы происходили при внедрении технологии больших данных. Её уже начали использовать, но называли иначе: это вопрос терминологии».
Факторы роста
Что стимулирует спрос на новую вычислительную архитектуру? По результатам исследований и опросов руководителей ИТ в Seagate выделили четыре ключевых фактора, определяющих спрос на периферийные вычисления. Это задержка в сети (латентность); недостаточная пропускная способность коммуникационных каналов для доставки больших объёмов данных в ЦОД; эффективность и стоимость решения; суверенитет данных и соблюдение нормативов.
1. Латентность
Фактор номер один — латентность. Из-за физических ограничений ИТ- и телекоммуникационной инфраструктуры требуется слишком много времени, чтобы переместить данные из места их создания в центральный узел. Таким образом, задержка становится ключевым фактором: отправка данных в центральный узел и обратно может занять и 100, и 200 миллисекунд.
2. Пропускная способность
Фактор номер два — проблема пропускной способности. Общие объёмы данных достигают уже не эксабайтных, а зеттабайтных масштабов. И они продолжают расти хотя бы из-за появления новых датчиков — не только датчиков температуры, погоды, вибрации или других, которые собирают сравнительно немного данных, но и камер, радаров, лидаров и других устройств, генерирующих очень много информации. В будущем таких датчиков станет ещё больше. Инфраструктура 5G может поддерживать миллионы устройств на квадратный километр, но где найти пропускную способность, чтобы отправить все данные в централизованные облачные ЦОД?
3. Эффективность
В-третьих, эффективность. Даже если вы сможете отправить все данные в централизованный ЦОД, затраты и сложность архитектуры для обработки такого большого объёма информации будут так велики, что система станет плохо управляемой. С системой, которая ведёт интенсивную обработку данных на периферии, ближе к источнику, дела обстоят намного лучше.
4. Нормативные требования и корпоративные стандарты
Наконец, четвёртый фактор — это требование, чтобы данные обрабатывались в соответствии с нормативами и стандартами, которые приняты у клиентов. Когда вы имеете дело с информационной безопасностью, вы часто не можете отправить данные из определённого региона или страны за рубеж для централизованной обработки. Это касается, например, персональной информации.
«Периферийные вычисления потребуют особых подходов к регулированию хранения данных, к обеспечению безопасности, в том числе и безопасности физического доступа к данным, — подчёркивает Александр Малинин. — Но мы однозначно увидим рост периферийных вычислений в ближайшие два-три года, потому что растёт количество запросов организаций на небольшие дата-центры, которые обслуживали бы и отдельные отрасли, и большие национальные компании. То есть, растёт количество запросов на организацию локального хранения данных».
Новая архитектура
Что это значит для ИТ-архитекторов, что они должны делать по-другому? Начнём с того, что проектирование традиционной инфраструктуры дата-центра или облачного центра обработки данных сильно отличается от разработки периферийной архитектуры. Традиционные центры обработки данных включают в себя системы охлаждения и кондиционирования, источники бесперебойного питания с двойным резервированием, системы физической безопасности. Их обслуживает целая команда специалистов.
Периферийный же центр (или, скорее, узел) обработки данных может находиться на телекоммуникационной вышке либо в небольшом помещении. Он часто подвергается воздействию внешней среды, поэтому его климат-контроль — сложная задача.
Что касается физической безопасности, то в архитектуру придётся встроить специальную защиту данных на случай стихийного бедствия или злонамеренных действий. Кроме того, из-за отсутствия персонала, который может быстро прийти и всё исправить, периферийные системы обязаны быть особенно надёжными. Если что-то случится, периферийный ЦОД должен сам восстановиться и продолжить работу.
Иными словами, если мы намереваемся обрабатывать данные на периферии, нужно довести до совершенства функциональность ЦОД: охлаждение, безопасность и т.д. Системные архитекторы уже работают над поиском решений. Цель — сделать так, чтобы периферийные центры обработки данных были простыми и обеспечивали достаточную телеметрию.
Кроме того, часть данных, которые будут обработаны на периферии, там не останутся. Они отправятся в центр для дальнейшего анализа или более длительного хранения. ИТ-архитектор обязан продумать этот процесс, определив стратегию управления данными.
Организации должны будут опираться на свою архитектуру облачных вычислений, учиться обрабатывать и, что особенно важно, безопасно хранить больше данных на периферии.
В отчёте о данных на периферии от компании Seagate и Vapor IO сказано, что у каждой организации есть ценность, о которой та даже не подозревает. Это её собственные данные. То, как мы создаём данные на периферии сети и работаем с ними, придаёт им особую значимость. Чтобы продолжать расти, компаниям необходимо пользоваться этим преимуществом.
«Проблемы внедрения периферийных вычислений сейчас в основном сводятся к телекоммуникациям, к скорости доступа к данным. Чем быстрее начнётся внедрение в России телекоммуникационных технологий следующего поколения, тем быстрее будут развиваться периферийные вычисления, — уверен Александр Малинин. — При этом развиваться периферийные вычисления будут параллельно с существующими дата-центрами и дополняя их. Коренной перестройки не потребуется».
По прогнозу Gartner, к 2021 году 40% предприятий в мире разработают полномасштабные стратегии периферийных вычислений. Поэтому вендоры сейчас торопятся занять перспективную нишу. В ближайшие пять лет рынок будет активно формироваться, появятся новые платформы и готовые решения, ориентированные на различные задачи и отрасли. Компании, которые займутся развитием периферийных вычислений, смогут стать лидерами в новых направлениях бизнеса.