
13 марта на официальном YouTube канале Евровидения была выложена композиция группы Little Big, которая будет представлять Россию на конкурсе. Посмотрев клип, захотелось сравнивать статистику видео нашей группы, с видео других участников; какие ролики самые просматриваемые, у кого самый большой процент лайков, кого чаще всего комментируют. Гугление готовой статистики ни к чему не привело. Поэтому было решено самому собрать нужную статистику.
Структура статьи:
- Код выгрузки
- Анализ
- Обновление на 14.03.2020 20:30
- Дополнительно: Смотрим зависимость просмотров от численности населения страны
Открыв плейлист участников можно увидеть 39 роликов, по факту там 38 песен, композиция Hurricane — Hasta La Vista — Serbia была загружена дважды, поэтому статистика по ней будет просуммирована. Для сбора статистики будем использовать R.
Код выгрузки
Нам понадобятся следующие пакеты:
library(tuber) # пакет взаимодействует с API YouTube, выгрузит нам статистику по роликам
library(dplyr) # пакет для работы с таблицами
library(ggplot2) # рисует графикиДля начала переходим в консоль разработчика google и создаем ключ OAuth на api "YouTube Data API v3". Получив ключ авторизуемся из R.
yt_oauth("Идентификатор клиента", "Секретный код клиента")Теперь можем собирать статистику:
# получаем список роликов из плэйлиста
list_videos <- get_playlist_items(filter = c(playlist_id = "PLmWYEDTNOGUL69D2wj9m2onBKV2s3uT5Y"))
# Собираем статистику по просмотрам, функция get_stats
stats_videos <- lapply(as.character(list_videos$contentDetails.videoId), get_stats) %>%
bind_rows()
stats_videos <- stats_videos %>%
mutate_at(vars(-id), as.integer)
# Получаем названия роликов, функция get_video_details
description_videos <- lapply(as.character(list_videos$contentDetails.videoId), get_video_details)
description_videos <- lapply(description_videos, function(x) {
list(
id = x[["items"]][[1]][["id"]],
name_video = x[["items"]][[1]][["snippet"]][["title"]]
)
}) %>%
bind_rows()Т.к. названия роликов имеют шаблон Исполнитель — Название песни — Страна [Код страны] — Official Music Video — Eurovision 2020, то все что находится после страны, можно удалить. Удаляем и объединяем таблицу статистики с таблицей названий роликов.
# Удаляем лишнюю часть названия ролика
description_videos$name_video <- description_videos$name_video %>%
gsub("[^[:alnum:][:blank:]?&/\\-]", '', .) %>%
gsub("( .*)|( - Offic.*)", '', .)
# Объединяем таблицу названий роликов со статистикой
df <- description_videos %>%
left_join(stats_videos, by = 'id') %>%
rowwise() %>%
mutate( # считаем долю лайков
proc_like = round(likeCount / (likeCount + dislikeCount), 2)
) %>%
ungroup()
# Hurricane - Hasta La Vista - Serbia две композиции в одном плейлисте, суммируем их
df <- df %>%
group_by(name_video) %>%
summarise(
id = first(id),
viewCount = sum(viewCount),
likeCount = sum(likeCount),
dislikeCount = sum(dislikeCount),
commentCount = sum(commentCount),
proc_like = round(likeCount / (likeCount + dislikeCount), 2)
)
df$color <- ifelse(df$name_video == 'Little Big - Uno - Russia','red','gray')Анализ
Теперь у нас есть итоговая таблица для анализа и можно начать смотреть кто самый популярный. Формируем графики.
# Кол-во просмотров
ggplot(df, aes(x = reorder(name_video, viewCount), y = viewCount, fill = color)) +
geom_col() +
coord_flip() +
theme_light() +
labs(x = NULL, y = "Кол-во просмотров") +
guides(fill = F) +
scale_fill_manual(values = c('gray', 'red')) +
scale_y_continuous(labels = scales::number_format(big.mark = " "))
# Доля лайков к дизлайкам
ggplot(df, aes(x = reorder(name_video, proc_like), y = proc_like, fill = color)) +
geom_col() +
coord_flip() +
theme_light() +
labs(x = NULL, y = "Доля лайков к дизлайкам") +
guides(fill = F) +
scale_fill_manual(values = c('gray', 'red')) +
scale_y_continuous(labels = scales::percent_format(accuracy = 1))
# Кол-во комментариев
ggplot(df, aes(x = reorder(name_video, commentCount), y = commentCount, fill = color)) +
geom_col() +
coord_flip() +
theme_light() +
labs(x = NULL, y = "Кол-во комментариев") +
guides(fill = F) +
scale_fill_manual(values = c('gray', 'red')) +
scale_y_continuous(labels = scales::number_format(big.mark = " "))
# Доля комментариев к просмотрам
ggplot(df, aes(x = reorder(name_video, commentCount/viewCount), y = commentCount/viewCount, fill = color)) +
geom_col() +
coord_flip() +
theme_light() +
labs(x = NULL, y = "Доля комментариев к просмотрам") +
guides(fill = F) +
scale_fill_manual(values = c('gray', 'red')) +
scale_y_continuous(labels = scales::percent_format(accuracy = 0.25))Небольшая ремарка, когда я задался темой статьи у Little Big было меньше 1 млн просмотров, и часть показателей не так сильно отличалась от других участников.
Количество просмотров. У композиции Little Big виден огромный отрыв, но это больше связано с тем что ролик попал в тренды. А вот самое маленькое кол-во просмотров у эстонской группы.
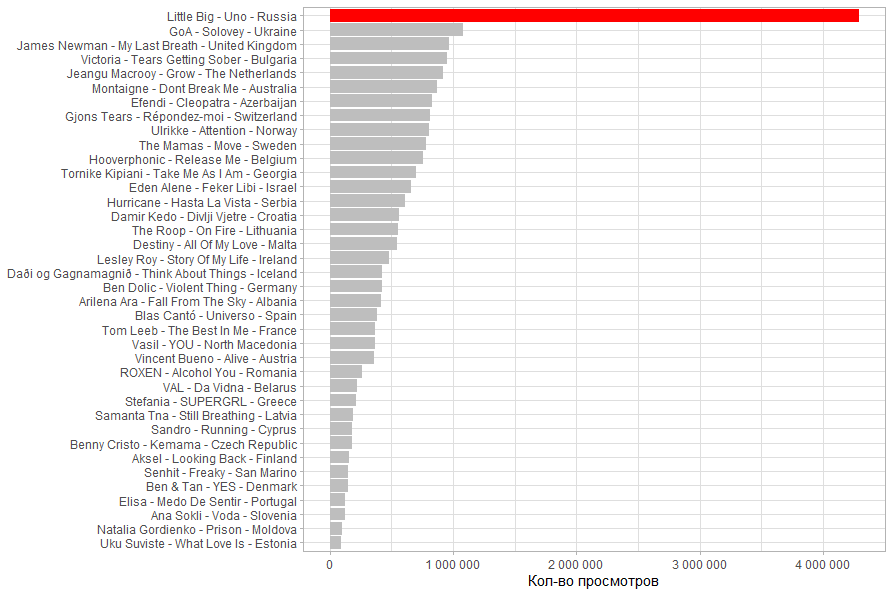
Доля лайков среди суммы лайков, дизлайков. Больше всего смотревшим понравились композиции Грузии и Литвы. А вот самая плохая композиция у Чехии.

Количество комментариев коррелирует с количеством просмотров.
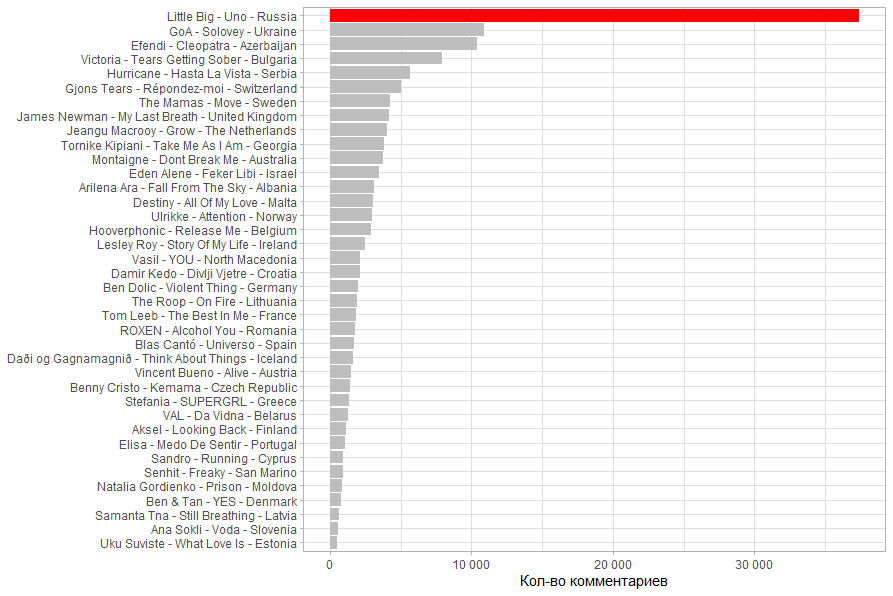
Доля комментариев к просмотрам(комментарии / просмотры). Чем больше комментариев по отношению к просмотрам тем более вероятна заинтересованность просмотревших. Наибольший интерес вызывает клип Азербайджана и Украины.
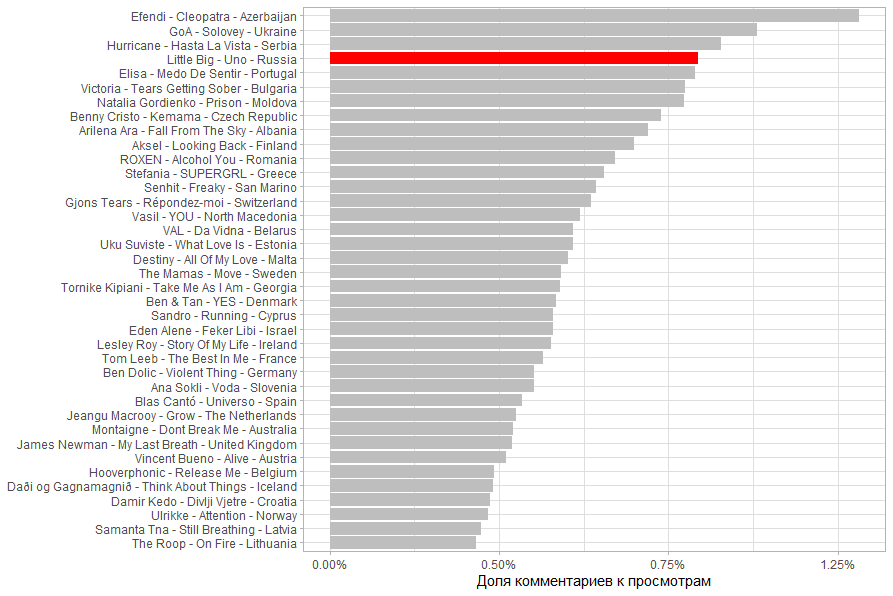
Итого по состоянию на 13.03.2020 18:00 в той или иной мере у пользователей вызывают интерес клипы России, Грузии, Литвы, Азербайджана и Украины.
UPD: по состоянию на 14.03.2020 20:30
Количество просмотров. Без изменения. У композиции Little Big так же огромный отрыв, Украина на втором месте по количеству просмотров.

Доля лайков среди суммы лайков, дизлайков. Здесь у Little Big немного увеличилась доля лайков, тем самым поравнялась с роликом из Мальты

Количество комментариев Без изменений.

Доля комментариев к просмотрам(комментарии / просмотры). С момента написания последнего поста ещё 2 участника выложили видео, один из них, Армения, вызвала наибольший интерес пользователей. И теперь этот ролик самый обсуждаемый в комментариях.

Итого по состоянию на 14.03.2020 20:30 список роликов интересных пользователям не сильно изменился это так же Россия, Грузия, Литва, Азербайджан, Украина. К ним просто добавилась Армения.
Дополнительно: Смотрим зависимость просмотров от численности населения страны
helg1978 высказал интересную мысль что количество просмотров может коррелировать с количеством населения страны. Захотелось проверить эту мысль.
К композициям подгрузил численность населения стран из википедии
library(rvest)
library(tidyr)
# Выгружаем численность населения
hdoc <- read_html('https://en.wikipedia.org/wiki/List_of_countries_and_dependencies_by_population')
tnode <- html_node(hdoc, xpath = '/html/body/div[3]/div[3]/div[4]/div/table')
df_population <- html_table(tnode)
df_population <- df_population %>% filter(`Country (or dependent territory)` != 'World')
df_population$Population <- as.integer(gsub(',','',df_population$Population,fixed = T))
df_population$`Country (or dependent territory)` <- gsub('\\[.*\\]','', df_population$`Country (or dependent territory)`)
df_population <- df_population %>%
select(
`Country (or dependent territory)`,
Population
) %>%
rename(Country = `Country (or dependent territory)`)
# добавляем численность населения в копию основной таблицы
df2 <- df %>%
separate(name_video, c('compozitor', 'name_track', 'Country'), ' - ', remove = F) %>%
mutate(Country = ifelse(Country == 'The Netherlands', 'Netherlands', Country)) %>%
left_join(df_population, by = 'Country')
# Зависимость просмотров от численности населения
cor(df2$viewCount,df2$Population)
ggplot(df2, aes(x = Population, y = viewCount)) +
geom_point() +
theme_light() +
geom_smooth(method = 'lm') +
labs(x = "Население, чел", y = "Кол-во просмотров") +
scale_y_continuous(labels = scales::number_format(big.mark = " ")) +
scale_x_continuous(labels = scales::number_format(big.mark = " "))
# Зависимость просмотров от численности населения, без России
cor(df2[df2$Country != 'Russia',]$viewCount,df2[df2$Country != 'Russia',]$Population)
ggplot(df2 %>% filter(Country != 'Russia') , aes(x = Population, y = viewCount)) +
geom_point() +
theme_light() +
geom_smooth(method = 'lm') +
labs(x = "Население, чел", y = "Кол-во просмотров") +
scale_y_continuous(labels = scales::number_format(big.mark = " ")) +
scale_x_continuous(labels = scales::number_format(big.mark = " "))
# Зависимость просмотров от численности населения, ранги
cor(df2$viewCount,df2$Population, method = "spearman")
ggplot(df2 , aes(x = rank(Population), y = rank(viewCount))) +
geom_point() +
theme_light() +
geom_smooth(method = 'lm') +
labs(x = "Население, чел (Ранги от 1 до 40)", y = "Кол-во просмотров (Ранги от 1 до 40)") +
guides(fill = F)
# Доля от общей численности населения
ggplot(df2, aes(x = reorder(name_video, viewCount/Population), y = viewCount/Population, fill = color)) +
geom_col() +
coord_flip() +
theme_light() +
labs(x = NULL, y = "Доля от общей численности населения") +
guides(fill = F) +
scale_fill_manual(values = c('gray', 'red')) +
scale_y_continuous(labels = scales::percent_format(accuracy = 0.25))Если смотреть в целом на все, то видно что Россия сильно выбивается из общей картины, у других стран с населением больше 50 млн нет такой тенденции. Формально коэффициент корреляции 71%.

Без России этот же график будет выглядеть следующим образом. Корреляция при этом упадет с 71% до 15%. Что в целом будет говорит об отсутствии зависимости.

Если смотреть на зависимость не параметрически(по рангам значений), то будет более сильная связь, но все равно не определяющая(Коэф. коррел. 40%).

И справочно посчитал долю просмотров от населения страны. Для особо маленьких стран получается что их смотрели больше из других стран. В частности это Мальта, Сан Марино и Исландия











towin
Закон простой, чем более эпатажно выглядят и действуют участники, чем больше бабла вкачано в раскрутку, чтобы из каждого утюга это все лилось в уши и глаза, тем более вероятна народная любовь.
Потому что народ в целом не отягощен интеллектом. В пирамиде Маслоу он находится где-то на уровне инстинктов размножения и поглощения еды. С настоящим творчеством — это не к нему.
AWSVladimir
Да просто задрало все, коронавирус, кризис и прочий негатив.
А Литлбиг поет: Uno-Dos-Quatro на эти все проблемы, что в переводе 1-2-4.
И как в комментариях пишут в ютубе, всем этим проблемам загибаем пальцы под песню начиная с мизинца. Один, два, четыре. )))
erimeev
В интернете пишут, что пропуск тройки это пасхалка — в смысле если загибать пальцы от мизинца, то будет стандартный такой жест
Eldhenn
А что там эпатажного? Чёрные губы Лиссова? Немного смешной толстячок? И всего-то?
towin
Крайне незатейливый мотивчик во всех песнях, черные губы, тату медведя, толстяк, цветастые костюмы, суровая морда певца.
Всё это направлено на то чтобы:
1. Выделится визуально там где контент потребляется глазами — ленты соцсетей, телевизор, youtube.
2. Выделиться аудиально — на радио. Из массы обычной нормальной мелодичной музыки, своими резкими мелодиями из пары нот. По нормальному такую ерунду на радио не поставят. Но если за песню заплачено, её будут крутить пока у слушателя она в подкорку головного мозга своим мотивом не застрянет. Причем, визуальная составляющая в ПЕСНЕ у них оказывается важнее.
Просто сравните это хайповое дерьмо, изготовленное с единственной целью заработать как можно больше денег с такими песнями и клипами как:
Михей — Сука-любовь отличная мелодия, замечательный голос, ничем не примечательный клип, люди слушают до сих пор.
Stardust — Music Sounds Better With You отличная мелодия, ничем не примечательный клип, топ чартов и продаж сингла.
Sandra — Secret Land нереальный вокал Сандры, очень нетривиальная ритмичная мелодия от Крету, никаких вырвиглазных костюмов, сисек и татуировок.
Продолжать можно бесконечно, потому что Little Big это просто днище музыки.
cjmaxik
Вкусовщина, тащ.
AllexIn
Очевидно что вам не нравится рейв и нравится попса. Ваше право.
Я вот тоже от рейва не в восторге. Но клипы у Little Big нравятся, и они крутые не потому что эпатажные, а потому что интересные и многослойные.
Eldhenn
> Крайне незатейливый мотивчик во всех песнях, черные губы, тату медведя, толстяк, цветастые костюмы, суровая морда певца
И что именно из перечисленного является эпатажем? Вот если бы Прусикин в плавках вышел, как в Faradenza, ещё туда-сюда.
mrtux
Тебя самого не тошнит от снобизма в своём комменте?
CBR
Ваши утверждения не бьются с реальностью.
1. У Little Big самый дешевый по производству клип, созданный за 5 дней. А просмотров уже 17 миллионов за 2 дня.
2. Вы ожидаете, что просмотр музыкальных клипов должен быть тяжелой высокоинтеллектуальной работой, иначе это признак деградации? Любое развитие человека построено на циклической нагрузке «работа(истощение ресурсов) — отдых (восстановление с суперкомпенсацией)».
Чтобы видеоклип улучшал фазу отдыха, он и не должен состоять из формул ядерной физики.