
Всем привет! Предлагаем к прочтению перевод статьи, который мы подготовили специально для студентов курса «Архитектор высоких нагрузок».

Отслеживание изменений данных (Change Data Capture, CDC) позволяет в реальном времени получать закоммиченные изменения в базе данных и распространять их среди различных потребителей [1][2]. CDC становится все более популярным, когда требуется синхронизация между разнородными хранилищами данных (например, MySQL и ElasticSearch) и является альтернативой традиционным методам, таким как двойная запись (dual-writes) и распределенные транзакции [3][4].
Источником для CDC, в таких базах данных как MySQL и PostgreSQL, является журнал транзакций (лог транзакций). Но так как журналы транзакций обычно усекаются, то они могут не содержать всю историю изменений. Поэтому для получения полного состояния источника нам нужны дампы. Мы изучили несколько open source CDC-проектов, часто использующих одинаковые библиотеки, API баз данных и протоколы, и обнаружили в них ряд ограничений, которые не удовлетворяют нашим требованиям. Например, остановка обработки событий лога до завершения выполнения дампа (полного снимка данных), отсутствие возможности инициирования выгрузки дампа по требованию или реализации, влияющие на трафик записи из-за использования блокировок таблиц.
Это побудило нас к разработке DBLog с унифицированным подходом к обработке логов и дампов. Для его поддержки в СУБД должны быть реализованы ряд функций, которые уже есть в MySQL, PostgreSQL, MariaDB и ряде других баз.
Некоторые из особенностей DBLog:
Ранее мы обсуждали Delta (перевод), платформу для обогащения и синхронизации данных (data enrichment and synchronization). Цель Delta — синхронизировать несколько хранилищ данных, где одно из них первичное (например, MySQL), а другие производные (например, ElasticSearch). Одним из ключевых требований при разработке была низкая задержка распространения изменений от источника до получателей, а также высокая доступность потока событий. Эти условия применяются независимо от того, используются ли все хранилища данных одной командой или одна команда владеет данными, а потребляет их другая. В статье про Delta (перевод) мы также описали варианты использования, выходящие за рамки синхронизации данных, такие как обработка событий.
Для синхронизации данных и обработки событий, помимо возможности отслеживать изменения в реальном времени, нам необходимо выполнить следующие требования:
Мы изучили несколько существующих open source — решений, в том числе: Maxwell, SpinalTap, Yelp MySQL Streamer и Debezium. В части сбора данных все они работают похожим образом, используя журнал транзакций. Например, с помощью протокола репликации binlog в MySQL или слотов репликации в PostgreSQL.
Но при обработке дампов они имеют, по крайней мере, одно из следующих ограничений:
В конце концов, мы решили применить другой подход к работе с дампами:
DBLog — это java-фреймворк для получения дампов и изменений в реальном времени. Дампы выполняются частями, чтобы они чередовались с реал-тайм событиями и не задерживали их обработку на длительный период. Дампы могут быть сделаны в любое время через API. Это позволяет потребителям получить полное состояние базы данных на этапе инициализации или позднее для восстановления после сбоя.
При проектировании фреймворка мы думали о минимизации влияния на базу данных. Дампы могут быть приостановлены и возобновлены по мере необходимости. Это работает как для восстановления после сбоя, так и для остановки, если база данных стала узким местом. Мы также не блокируем таблицы, чтобы не влиять на операции записи.
DBLog позволяет записывать события в различном виде, в том числе в другую базу данных или через API. Для хранения состояния, связанного с обработкой логов и дампов, а также для выбора ведущего узла, мы используем Zookeeper. При создании DBLog мы реализовали возможность подключения различных плагинов, позволяя менять реализации по своему усмотрению (например, заменить Zookeeper чем-то другим).
Далее рассмотрим подробнее обработку логов и дампов.
Для фреймворка требуется, чтобы база данных фиксировала события для каждой измененной строки в режиме реального времени, сохраняя при этом порядок коммитов. Предполагается, что источником этих событий является журнал транзакций. База данных отправляет их через транспорт, который может использовать DBLog. Для этого транспорта мы используем термин «журнал/лог изменений» («change log»). Событие может быть следующих типов: создание (create), изменение (update) или удаление (delete). Для каждого события необходимо предоставить следующую информацию: порядковый номер в журнале (log sequence number), состояние столбца во время операции и схему, которая применялась в момент выполнения операции.
Каждое изменение сериализуется в формат события DBLog и отправляется в writer, для его дальнейшей передачи на выход (output). Отправка событий в writer является неблокирующей операцией, так как writer работает в отдельном потоке и накапливает события во внутреннем буфере. Буферизованные события отправляются на выход в порядке их получения. Фреймворк позволяет подключить пользовательский форматер для сериализации событий в произвольный формат. Выход (output) представляет собой простой интерфейс, позволяющий подключить любого получателя, например, поток, хранилище данных или даже API.
Дампы необходимы, поскольку журналы транзакций имеют ограниченное время хранения, что не позволяет использовать их для восстановления полного исходного набора данных. Дампы создаются блоками (chunk), так чтобы они могли чередоваться с событиями лога, позволяя обрабатывать их одновременно. Для каждой выбранной строки блока генерируется событие и сериализуется в тот же формат, что и событие лога. Таким образом, потребителю не нужно беспокоиться пришло событие из лога или дампа. Как события лога, так и события дампа отправляются на выход через один и тот же writer.
Дампы могут быть запланированы на любое время через API для всех таблиц, одной таблицы или для конкретных первичных ключей таблицы. Дамп таблицы выполняется блоками заданного размера. Также можно настроить задержку обработки новых блоков, разрешая в это время обработку только событий лога. Размер блоков и задержка позволяют сбалансировать обработку событий лога и дампа. Обе настройки могут быть изменены во время выполнения.
Блоки (chunk) выбираются путем сортировки таблицы в порядке возрастания первичного ключа и выбора строк, где первичный ключ больше, чем последний первичный ключ предыдущего блока. Требуется, чтобы база данных выполняла этот запрос эффективно, что обычно применимо к системам, в которых реализовано сканирование диапазона по первичным ключам (range scan).
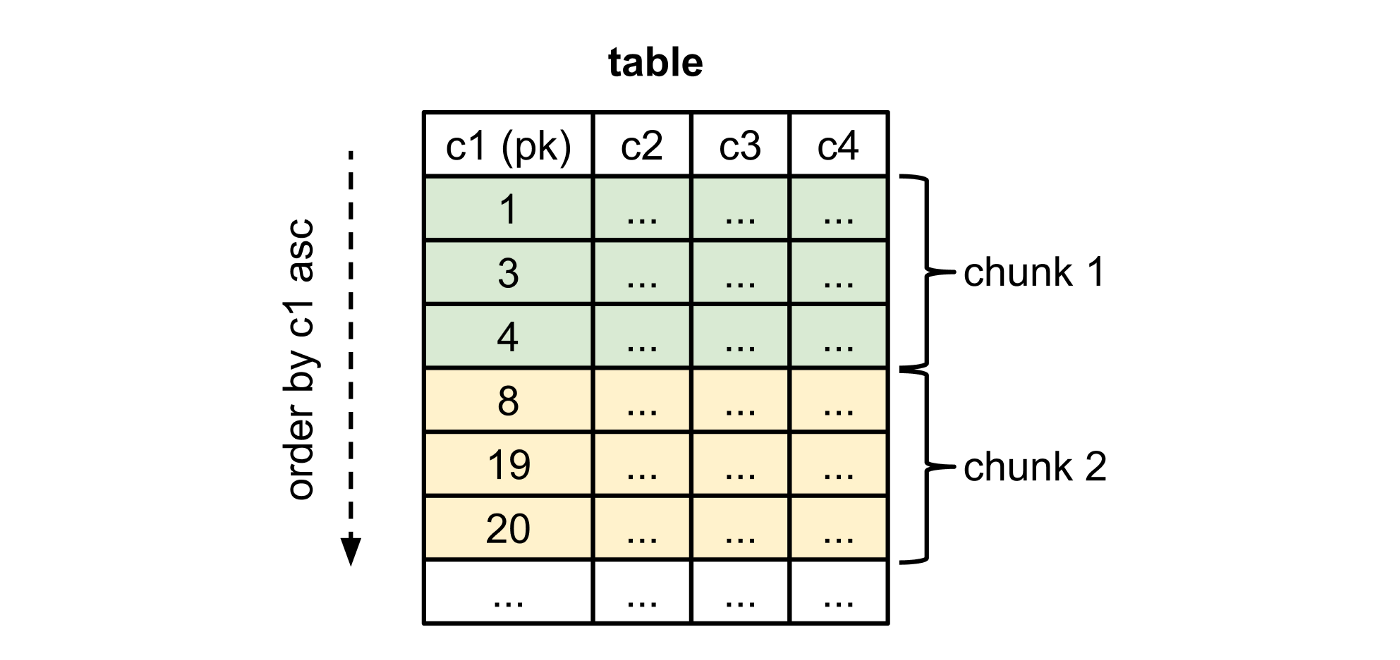
Рисунок 1. Разбивка на блоки таблицы с 4-мя колонками c1-c4 и c1 в качестве первичного ключа (pk). Первичный ключ целого типа, размер блока 3. Блок 2 выбран по условию c1 > 4.
Блоки необходимо брать таким образом, чтобы не задерживать обработку событий лога на длительный период и сохранить историю изменений так, чтобы выбранная строка со старым значением не могла переписать более новое событие.
Для того, чтобы можно было выбирать блоки последовательно, в логе изменений мы создаем распознаваемые “водяные знаки”. Водяные знаки реализуются через таблицу в исходной базе данных. Эта таблица хранится в специальном пространстве имён, чтобы не было коллизий с таблицами приложений. В ней хранится только одна строка с UUID-значением. Водяной знак создается при изменении этого значения на определенный UUID. Обновление строки приводит к возникновению события изменения, которое в конечном счете мы получаем через лог изменений.
Дампы с использованием водяных знаков создаются следующим образом:
Предполагается, что SELECT возвращает состояние, которое представляет закоммиченные изменения до определенного момента в истории. Или, что эквивалентно следующему: SELECT выполняется в определенной позиции лога изменений, учитывая изменения до этого момента. Базы данных обычно не предоставляют информацию о моменте выполнения SELECT (за исключением MariaDB).
Основная идея нашего подхода заключается в том, что в логе изменений мы определяем окно, гарантирующее сохранение позиции SELECT в блоке. Окно открывается записью нижнего водяного знака, после этого выполняется SELECT, и окно закрывается записью верхнего водяного знака. Так как точное положение SELECT неизвестно, удаляются все выбранные строки, которые вступают в конфликт с событиями лога в этом окне. Это гарантирует, что не будет перезаписи истории в логе изменений.
Чтобы это работало, SELECT должен прочитать состояние таблицы с момента нижнего водяного знака или позже (допустимо включить изменения, которые были сделаны после нижнего водяного знака и перед чтением). В общем, требуется, чтобы SELECT видел изменения, сделанные до его выполнения. Мы называем это как “чтение неустаревших данных“ (non-stale reads). Кроме того, поскольку верхний водяной знак записывается после, то гарантируется, что SELECT будет выполнен до него.
Рисунки 2a и 2b иллюстрируют алгоритм выбора блоков. В качестве примера приведем таблицу с первичными ключами от k1 до k6. Каждая запись в логе изменений представляет событие создания, обновления или удаления для первичного ключа. На рисунке 2а показана генерация водяных знаков и выбор блока (шаги с 1 по 4). Обновление таблицы водяных знаков на шагах 2 и 4 создает два события изменения (пурпурный цвет), которые в итоге принимаются через лог. На рисунке 2b мы фокусируемся на строках текущего блока, которые удаляются из результирующего набора с первичными ключами, которые появляются между водяными знаками (шаги с 5 по 7).
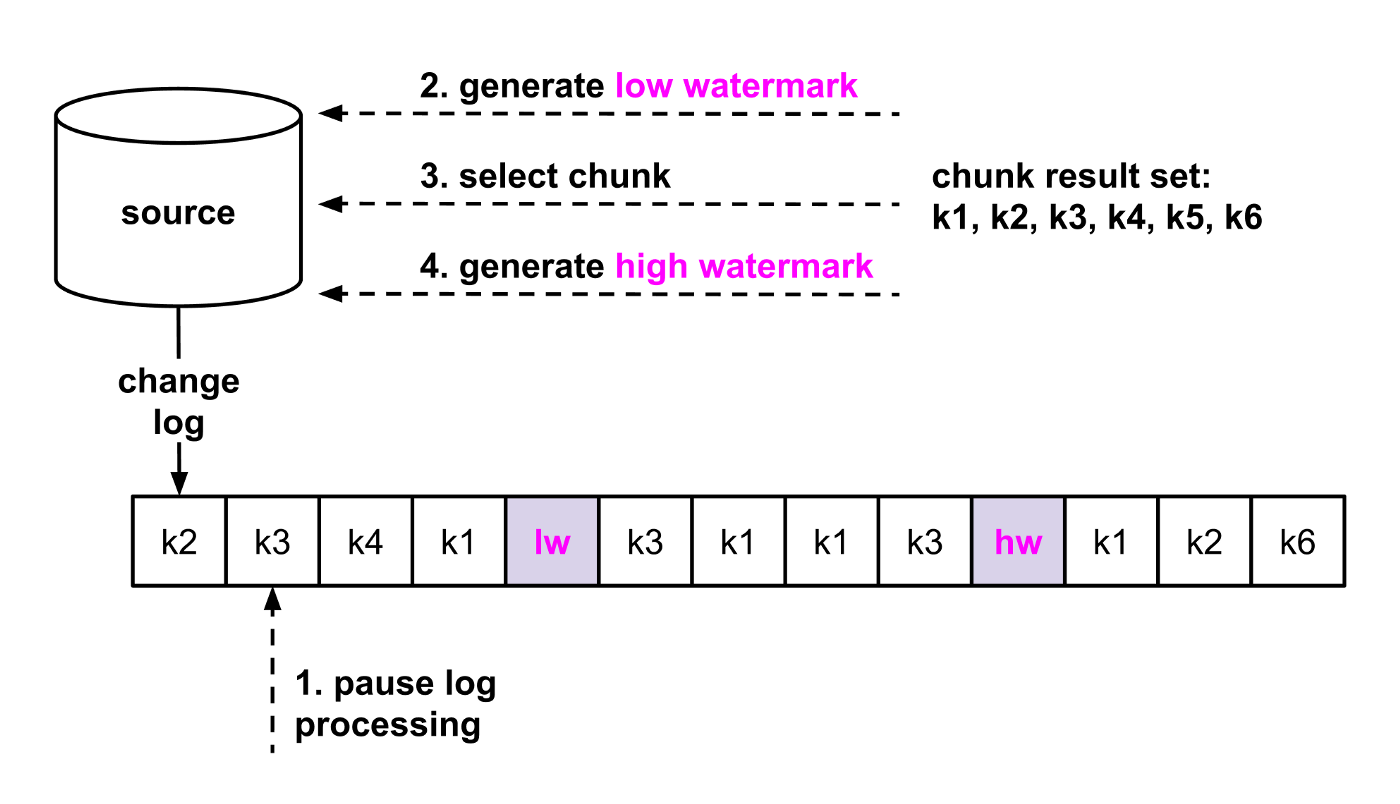
Рисунок 2a — Алгоритм водяных знаков для выбора блока (шаги 1–4).

Рисунок 2b — Алгоритм водяных знаков для выбора блоков (шаги 5–7).
Обратите внимание, что между нижним и верхним водяными знаками может появиться большое количество событий в логе, если одна или несколько транзакций сделали много изменений строк. Именно по этой причине мы делаем кратковременную приостановку обработки лога на этапах 2–4, чтобы не пропустить водяные знаки. Таким образом, обработка событий лога может возобновляться событие за событием, что в итоге позволит обнаружить водяные знаки без необходимости кэшировать записи событий лога. Обработка лога приостанавливается лишь на короткое время, так как ожидается, что шаги 2–4 будут быстрыми: обновление водяных знаков представляет собой одиночную операцию записи, а SELECT выполняется с ограничением.
Как только на шаге 7 получен верхний водяной знак, не конфликтующие строки блока передаются на выход в порядке их получения. Это неблокирующая операция, так как writer работает в отдельном потоке, что позволяет быстро возобновить обработку лога после шага 7. После этого обработка лога продолжается для событий, которые происходят после верхнего водяного знака.
На рисунке 2c показан порядок записи для всего блока, используя тот же пример, что и на рисунках 2a и 2b. События в логе, которые появляются до верхнего водяного знака, записываются первыми. Затем оставшиеся строки из результата блока (пурпурный цвет). И, наконец, записываются события, которые происходят после верхнего водяного знака.

Рисунок 2c — Порядок записи выходных данных. Чередование лога с дампом.
Для использования DBLog база данных должна предоставлять лог изменений как линейную историю закоммиченных изменений с чтением неустаревших данных (non-stale reads). Эти условия выполняются такими системами, как MySQL, PostgreSQL, MariaDB и т.д., поэтому фреймворк может использоваться единообразно с этими базами данных.
Пока что мы добавили поддержку MySQL и PostgreSQL. Для получения событий лога в каждой из баз данных используются свои библиотеки, поскольку каждая из них использует проприетарный протокол. Для MySQL мы используем shyiko/mysql-binlog-connector, реализующий протокол репликации binlog. Для PostgreSQL — слоты репликации с плагином wal2json. Изменения принимаются через протокол потоковой репликации, который реализуется jdbc-драйвером PostgreSQL. Определение схемы для каждого захваченного изменения отличается в MySQL и PostgreSQL. В PostgreSQL wal2json содержит имена, типы столбцов и значения. Для MySQL изменения в схеме должны отслеживаться как события binlog.
Обработка дампа была сделана с использованием SQL и JDBC, требуя только реализации выбора блока и обновления водяного знака. Для MySQL и PostgreSQL используется один и тот же код, который может быть использован и для других аналогичных баз данных. Сама обработка дампа не зависит от SQL или JDBC и позволяет использовать базы данных, которые отвечают требованиям DBLog, даже если они используют разные стандарты.
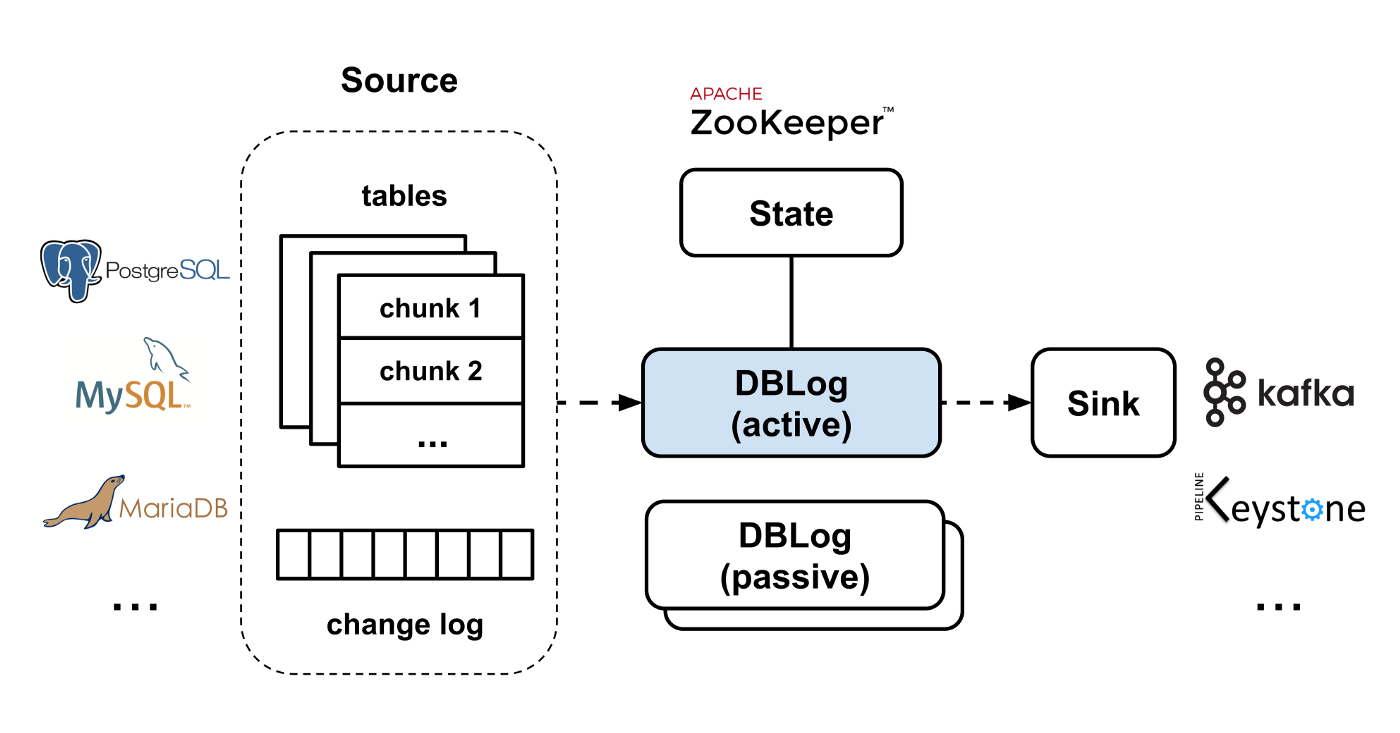
Рисунок 3 — Высокоуровневая архитектура DBLog.
DBLog использует архитектуру с одним ведущим узлом (active-passive). Один экземпляр является активным (ведущим), а другие — пассивные (резервные). Для выбора ведущего узла мы используем Zookeeper. Для ведущего узла используется договор аренды (lease), который он должен периодически обновлять, чтобы продолжать оставаться ведущим. В случае прекращения возобновления аренды функции ведущего передаются другому узлу. В настоящее время мы разворачиваем по одному экземпляру на каждую AZ (зону доступности, обычно у нас 3 AZ), поэтому если одна AZ падает, то экземпляр в другой AZ может продолжать обработку с минимальным общим временем простоя. Резервные экземпляры можно расположить в разных регионах, хотя рекомендуется работать в том же регионе, что и хост базы данных, чтобы обеспечить низкие задержки захвата изменений.
DBLog является основой для MySQL- и PostgreSQL-коннекторов, используемых в Delta. Delta используется в продакшн с 2018 года для синхронизации хранилищ данных и обработки событий в приложениях студии Netflix. Коннекторы Delta используют свой сериализатор событий. В качестве выходных данных используются специфические потоки Netflix, такие как Keystone.
Рисунок 4 — Delta Connector.
Помимо Delta, DBLog также используется в Netflix для создания коннекторов для других платформ перемещения данных, которые имеют собственные форматы данных.
В DBLog есть дополнительные возможности, которые не рассмотрены в этой статье, такие как:
Мы планируем открыть исходный код DBLog в 2020 году и включить в него дополнительную документацию.
Мы хотели бы поблагодарить следующих людей за участие в разработке DBLog: Josh Snyder, Raghuram Onti Srinivasan, Tharanga Gamaethige и Yun Wang.
[1] Das, Shirshanka, et al. “All aboard the Databus!: Linkedin’s scalable consistent change data capture platform.” Third ACM Symposium on Cloud Computing. ACM, 2012
[2] “About Change Data Capture (SQL Server)”, Microsoft SQL docs, 2019
[3] Kleppmann, Martin, “Using logs to build a solid data infrastructure (or: why dual writes are a bad idea)“, Confluent, 2015
[4] Kleppmann, Martin, Alastair R. Beresford, Boerge Svingen. “Online event processing.” Communications of the ACM 62.5 (2019): 43–49
[5] https://debezium.io/documentation/reference/0.10/connectors/mysql.html#snapshots
Узнать подробнее о курсе.
Введение
Отслеживание изменений данных (Change Data Capture, CDC) позволяет в реальном времени получать закоммиченные изменения в базе данных и распространять их среди различных потребителей [1][2]. CDC становится все более популярным, когда требуется синхронизация между разнородными хранилищами данных (например, MySQL и ElasticSearch) и является альтернативой традиционным методам, таким как двойная запись (dual-writes) и распределенные транзакции [3][4].
Источником для CDC, в таких базах данных как MySQL и PostgreSQL, является журнал транзакций (лог транзакций). Но так как журналы транзакций обычно усекаются, то они могут не содержать всю историю изменений. Поэтому для получения полного состояния источника нам нужны дампы. Мы изучили несколько open source CDC-проектов, часто использующих одинаковые библиотеки, API баз данных и протоколы, и обнаружили в них ряд ограничений, которые не удовлетворяют нашим требованиям. Например, остановка обработки событий лога до завершения выполнения дампа (полного снимка данных), отсутствие возможности инициирования выгрузки дампа по требованию или реализации, влияющие на трафик записи из-за использования блокировок таблиц.
Это побудило нас к разработке DBLog с унифицированным подходом к обработке логов и дампов. Для его поддержки в СУБД должны быть реализованы ряд функций, которые уже есть в MySQL, PostgreSQL, MariaDB и ряде других баз.
Некоторые из особенностей DBLog:
- События лога обрабатываются в порядке их возникновения.
- Дампы можно сделать в любое время для всех таблиц, для одной таблицы или для конкретных первичных ключей таблицы.
- Обработка лога чередуется с обработкой дампа, разделяя дамп на блоки. Таким образом, обработка лога может проходить параллельно с обработкой дампа. Если процесс завершается то, он может быть возобновлен после последнего завершенного блока без необходимости начинать все с нуля. Это также позволяет регулировать пропускную способность при создании дампа и, если необходимо, приостанавливать его создание.
- Не используются блокировки таблиц, что предотвращает влияние на трафик записи в исходную базу данных.
- Поддерживается множество вариантов вывода: поток, хранилище данных или даже API.
- Изначально разработан с учетом высокой доступности. Потребители могут быть уверены, что получат события об изменениях сразу после их возникновения в источнике.
Требования
Ранее мы обсуждали Delta (перевод), платформу для обогащения и синхронизации данных (data enrichment and synchronization). Цель Delta — синхронизировать несколько хранилищ данных, где одно из них первичное (например, MySQL), а другие производные (например, ElasticSearch). Одним из ключевых требований при разработке была низкая задержка распространения изменений от источника до получателей, а также высокая доступность потока событий. Эти условия применяются независимо от того, используются ли все хранилища данных одной командой или одна команда владеет данными, а потребляет их другая. В статье про Delta (перевод) мы также описали варианты использования, выходящие за рамки синхронизации данных, такие как обработка событий.
Для синхронизации данных и обработки событий, помимо возможности отслеживать изменения в реальном времени, нам необходимо выполнить следующие требования:
- Получение полного состояния. Производные хранилища (например, ElasticSearch) должны в конечном счете хранить полное состояние источника. Мы реализуем это через дампы исходной базы данных.
- Запуск восстановления состояния в любое время. Вместо того чтобы рассматривать дамп как разовую операцию только для первичной инициализации, мы можем сделать его в любое время: для всех таблиц, для одной таблицы или для конкретных первичных ключей. Это очень важно для восстановления потребителей, в случаях потери или повреждения данных.
- Обеспечение высокой доступности для реал-тайм событий. Распространение изменений в реальном времени предъявляет требования по высокой доступности. Нежелательно, если поток событий останавливается на длительный период (например, на минуты или больше). Это требование должно быть выполнено даже во время восстановления и без блокировки обработки реал-тайм событий. Мы хотим, чтобы реал-тайм события и события дампа чередовались и выполнялись вместе.
- Минимизация влияния на базу данных. При подключении к базе данных важно обеспечить как можно меньшее воздействие на нее с точки зрения пропускной способности и обслуживания операций чтения и записи для приложений. Поэтому следует избегать использования API, которое может блокировать трафик записи, например, блокировки таблиц. В дополнение к этому должны быть реализованы механизмы, которые позволяют регулировать пропускную способность обработки логов и дампов и, при необходимости, приостанавливать обработку.
- Разные способы отправки событий. Для потоковой обработки в Netflix используются различные решения, такие как Kafka, SQS, Kinesis, а также специальные решения Netflix, такие как Keystone. Несмотря на то, что наличие потока в качестве выхода может быть хорошим выбором (например, при наличии нескольких потребителей), но не всегда будет идеальным (например, если потребитель только один). Мы хотим предоставить возможность прямой записи для потребителя без использования потоков. Потребителем может быть хранилище данных или внешний API.
- Поддержка реляционных баз данных. В Netflix есть сервисы, которые используют РСУБД (MySQL, PostgreSQL) в AWS RDS. Мы хотим поддерживать эти базы как источник данных.
Существующие решения
Мы изучили несколько существующих open source — решений, в том числе: Maxwell, SpinalTap, Yelp MySQL Streamer и Debezium. В части сбора данных все они работают похожим образом, используя журнал транзакций. Например, с помощью протокола репликации binlog в MySQL или слотов репликации в PostgreSQL.
Но при обработке дампов они имеют, по крайней мере, одно из следующих ограничений:
- Остановка обработки событий лога во время создания дампа. Как следствие, если дамп имеет большой размер, то обработка событий лога останавливается на длительный период. Это будет проблемой, если потребители полагаются на небольшие задержки в распространении изменений.
- Отсутствие возможности создания дампов по требованию. Большинство решений выполняют дамп на этапе начальной загрузки или при обнаружении потери данных в журналах транзакций. Однако возможность инициировать создание дампов по требованию имеет важное значение для начальной загрузки новых потребителей (например, нового индекса ElasticSearch) или для восстановления данных в случае их потери.
- Влияние на трафик записи через блокировку таблиц. Некоторые решения для согласованного создания дампа используют блокировки таблиц. В зависимости от реализации и базы данных блокировка может быть кратковременной или продолжаться в течение всего процесса создания дампа [5]. В последнем случае трафик записи блокируется до завершения создания дампа. В некоторых случаях можно настроить выделенную реплику для чтения, чтобы избежать влияния на операции записи на главном сервере. Однако эта стратегия работает не для всех баз данных. Например, в PostgreSQL RDS изменения могут быть получены только с главного сервера.
- Использование специфических функций базы данных. Мы обнаружили, что некоторые решения используют дополнительные возможности баз данных, которые присутствуют не во всех системах. Например, использование blackhole engine в MySQL или получение согласованного снимка дампов через слоты репликации в PostgreSQL. Это ограничивает повторное использования кода между разными базами данных.
В конце концов, мы решили применить другой подход к работе с дампами:
- чередовать события лога и дампа так, чтобы они могли выполняться вместе;
- запускать дамп в любое время;
- не использовать блокировки таблиц;
- не использовать специфические возможности баз данных.
DBLog Framework
DBLog — это java-фреймворк для получения дампов и изменений в реальном времени. Дампы выполняются частями, чтобы они чередовались с реал-тайм событиями и не задерживали их обработку на длительный период. Дампы могут быть сделаны в любое время через API. Это позволяет потребителям получить полное состояние базы данных на этапе инициализации или позднее для восстановления после сбоя.
При проектировании фреймворка мы думали о минимизации влияния на базу данных. Дампы могут быть приостановлены и возобновлены по мере необходимости. Это работает как для восстановления после сбоя, так и для остановки, если база данных стала узким местом. Мы также не блокируем таблицы, чтобы не влиять на операции записи.
DBLog позволяет записывать события в различном виде, в том числе в другую базу данных или через API. Для хранения состояния, связанного с обработкой логов и дампов, а также для выбора ведущего узла, мы используем Zookeeper. При создании DBLog мы реализовали возможность подключения различных плагинов, позволяя менять реализации по своему усмотрению (например, заменить Zookeeper чем-то другим).
Далее рассмотрим подробнее обработку логов и дампов.
Логи
Для фреймворка требуется, чтобы база данных фиксировала события для каждой измененной строки в режиме реального времени, сохраняя при этом порядок коммитов. Предполагается, что источником этих событий является журнал транзакций. База данных отправляет их через транспорт, который может использовать DBLog. Для этого транспорта мы используем термин «журнал/лог изменений» («change log»). Событие может быть следующих типов: создание (create), изменение (update) или удаление (delete). Для каждого события необходимо предоставить следующую информацию: порядковый номер в журнале (log sequence number), состояние столбца во время операции и схему, которая применялась в момент выполнения операции.
Каждое изменение сериализуется в формат события DBLog и отправляется в writer, для его дальнейшей передачи на выход (output). Отправка событий в writer является неблокирующей операцией, так как writer работает в отдельном потоке и накапливает события во внутреннем буфере. Буферизованные события отправляются на выход в порядке их получения. Фреймворк позволяет подключить пользовательский форматер для сериализации событий в произвольный формат. Выход (output) представляет собой простой интерфейс, позволяющий подключить любого получателя, например, поток, хранилище данных или даже API.
Дампы
Дампы необходимы, поскольку журналы транзакций имеют ограниченное время хранения, что не позволяет использовать их для восстановления полного исходного набора данных. Дампы создаются блоками (chunk), так чтобы они могли чередоваться с событиями лога, позволяя обрабатывать их одновременно. Для каждой выбранной строки блока генерируется событие и сериализуется в тот же формат, что и событие лога. Таким образом, потребителю не нужно беспокоиться пришло событие из лога или дампа. Как события лога, так и события дампа отправляются на выход через один и тот же writer.
Дампы могут быть запланированы на любое время через API для всех таблиц, одной таблицы или для конкретных первичных ключей таблицы. Дамп таблицы выполняется блоками заданного размера. Также можно настроить задержку обработки новых блоков, разрешая в это время обработку только событий лога. Размер блоков и задержка позволяют сбалансировать обработку событий лога и дампа. Обе настройки могут быть изменены во время выполнения.
Блоки (chunk) выбираются путем сортировки таблицы в порядке возрастания первичного ключа и выбора строк, где первичный ключ больше, чем последний первичный ключ предыдущего блока. Требуется, чтобы база данных выполняла этот запрос эффективно, что обычно применимо к системам, в которых реализовано сканирование диапазона по первичным ключам (range scan).
Рисунок 1. Разбивка на блоки таблицы с 4-мя колонками c1-c4 и c1 в качестве первичного ключа (pk). Первичный ключ целого типа, размер блока 3. Блок 2 выбран по условию c1 > 4.
Блоки необходимо брать таким образом, чтобы не задерживать обработку событий лога на длительный период и сохранить историю изменений так, чтобы выбранная строка со старым значением не могла переписать более новое событие.
Для того, чтобы можно было выбирать блоки последовательно, в логе изменений мы создаем распознаваемые “водяные знаки”. Водяные знаки реализуются через таблицу в исходной базе данных. Эта таблица хранится в специальном пространстве имён, чтобы не было коллизий с таблицами приложений. В ней хранится только одна строка с UUID-значением. Водяной знак создается при изменении этого значения на определенный UUID. Обновление строки приводит к возникновению события изменения, которое в конечном счете мы получаем через лог изменений.
Дампы с использованием водяных знаков создаются следующим образом:
- Ненадолго приостанавливаем обработку событий лога.
- Генерируем “нижний” (low) водяной знак, обновив таблицу водяных знаков.
- Запускаем SELECT для следующего блока и сохраняем в памяти результат, проиндексированный по первичному ключу.
- Генерируем “верхний” (high) водяной знак, обновив таблицу водяных знаков.
- Возобновляем отправку полученных событий лога. Следим за нижним и верхним водяными знаками в логе.
- После получения нижнего водяного знака начинаем удалять записи из набора результатов для всех первичных ключей, полученных после нижнего водяного знака.
- Как только получен верхний водяной знак, перед обработкой новых событий лога, отправляем все оставшиеся записи из набора результатов на выход.
- Если есть еще блоки, то переходим к шагу 1.
Предполагается, что SELECT возвращает состояние, которое представляет закоммиченные изменения до определенного момента в истории. Или, что эквивалентно следующему: SELECT выполняется в определенной позиции лога изменений, учитывая изменения до этого момента. Базы данных обычно не предоставляют информацию о моменте выполнения SELECT (за исключением MariaDB).
Основная идея нашего подхода заключается в том, что в логе изменений мы определяем окно, гарантирующее сохранение позиции SELECT в блоке. Окно открывается записью нижнего водяного знака, после этого выполняется SELECT, и окно закрывается записью верхнего водяного знака. Так как точное положение SELECT неизвестно, удаляются все выбранные строки, которые вступают в конфликт с событиями лога в этом окне. Это гарантирует, что не будет перезаписи истории в логе изменений.
Чтобы это работало, SELECT должен прочитать состояние таблицы с момента нижнего водяного знака или позже (допустимо включить изменения, которые были сделаны после нижнего водяного знака и перед чтением). В общем, требуется, чтобы SELECT видел изменения, сделанные до его выполнения. Мы называем это как “чтение неустаревших данных“ (non-stale reads). Кроме того, поскольку верхний водяной знак записывается после, то гарантируется, что SELECT будет выполнен до него.
Рисунки 2a и 2b иллюстрируют алгоритм выбора блоков. В качестве примера приведем таблицу с первичными ключами от k1 до k6. Каждая запись в логе изменений представляет событие создания, обновления или удаления для первичного ключа. На рисунке 2а показана генерация водяных знаков и выбор блока (шаги с 1 по 4). Обновление таблицы водяных знаков на шагах 2 и 4 создает два события изменения (пурпурный цвет), которые в итоге принимаются через лог. На рисунке 2b мы фокусируемся на строках текущего блока, которые удаляются из результирующего набора с первичными ключами, которые появляются между водяными знаками (шаги с 5 по 7).
Рисунок 2a — Алгоритм водяных знаков для выбора блока (шаги 1–4).
Рисунок 2b — Алгоритм водяных знаков для выбора блоков (шаги 5–7).
Обратите внимание, что между нижним и верхним водяными знаками может появиться большое количество событий в логе, если одна или несколько транзакций сделали много изменений строк. Именно по этой причине мы делаем кратковременную приостановку обработки лога на этапах 2–4, чтобы не пропустить водяные знаки. Таким образом, обработка событий лога может возобновляться событие за событием, что в итоге позволит обнаружить водяные знаки без необходимости кэшировать записи событий лога. Обработка лога приостанавливается лишь на короткое время, так как ожидается, что шаги 2–4 будут быстрыми: обновление водяных знаков представляет собой одиночную операцию записи, а SELECT выполняется с ограничением.
Как только на шаге 7 получен верхний водяной знак, не конфликтующие строки блока передаются на выход в порядке их получения. Это неблокирующая операция, так как writer работает в отдельном потоке, что позволяет быстро возобновить обработку лога после шага 7. После этого обработка лога продолжается для событий, которые происходят после верхнего водяного знака.
На рисунке 2c показан порядок записи для всего блока, используя тот же пример, что и на рисунках 2a и 2b. События в логе, которые появляются до верхнего водяного знака, записываются первыми. Затем оставшиеся строки из результата блока (пурпурный цвет). И, наконец, записываются события, которые происходят после верхнего водяного знака.
Рисунок 2c — Порядок записи выходных данных. Чередование лога с дампом.
Поддерживаемые базы данных
Для использования DBLog база данных должна предоставлять лог изменений как линейную историю закоммиченных изменений с чтением неустаревших данных (non-stale reads). Эти условия выполняются такими системами, как MySQL, PostgreSQL, MariaDB и т.д., поэтому фреймворк может использоваться единообразно с этими базами данных.
Пока что мы добавили поддержку MySQL и PostgreSQL. Для получения событий лога в каждой из баз данных используются свои библиотеки, поскольку каждая из них использует проприетарный протокол. Для MySQL мы используем shyiko/mysql-binlog-connector, реализующий протокол репликации binlog. Для PostgreSQL — слоты репликации с плагином wal2json. Изменения принимаются через протокол потоковой репликации, который реализуется jdbc-драйвером PostgreSQL. Определение схемы для каждого захваченного изменения отличается в MySQL и PostgreSQL. В PostgreSQL wal2json содержит имена, типы столбцов и значения. Для MySQL изменения в схеме должны отслеживаться как события binlog.
Обработка дампа была сделана с использованием SQL и JDBC, требуя только реализации выбора блока и обновления водяного знака. Для MySQL и PostgreSQL используется один и тот же код, который может быть использован и для других аналогичных баз данных. Сама обработка дампа не зависит от SQL или JDBC и позволяет использовать базы данных, которые отвечают требованиям DBLog, даже если они используют разные стандарты.
Рисунок 3 — Высокоуровневая архитектура DBLog.
Высокая доступность
DBLog использует архитектуру с одним ведущим узлом (active-passive). Один экземпляр является активным (ведущим), а другие — пассивные (резервные). Для выбора ведущего узла мы используем Zookeeper. Для ведущего узла используется договор аренды (lease), который он должен периодически обновлять, чтобы продолжать оставаться ведущим. В случае прекращения возобновления аренды функции ведущего передаются другому узлу. В настоящее время мы разворачиваем по одному экземпляру на каждую AZ (зону доступности, обычно у нас 3 AZ), поэтому если одна AZ падает, то экземпляр в другой AZ может продолжать обработку с минимальным общим временем простоя. Резервные экземпляры можно расположить в разных регионах, хотя рекомендуется работать в том же регионе, что и хост базы данных, чтобы обеспечить низкие задержки захвата изменений.
Использование на продакшене
DBLog является основой для MySQL- и PostgreSQL-коннекторов, используемых в Delta. Delta используется в продакшн с 2018 года для синхронизации хранилищ данных и обработки событий в приложениях студии Netflix. Коннекторы Delta используют свой сериализатор событий. В качестве выходных данных используются специфические потоки Netflix, такие как Keystone.
Рисунок 4 — Delta Connector.
Помимо Delta, DBLog также используется в Netflix для создания коннекторов для других платформ перемещения данных, которые имеют собственные форматы данных.
Оставайтесь с нами
В DBLog есть дополнительные возможности, которые не рассмотрены в этой статье, такие как:
- Возможность получения схем таблиц без использования блокировок.
- Интеграция с хранилищем схем. Для каждого события в хранилище сохраняется схема, ссылка на которую указывается в полезной нагрузке события.
- Монотонная запись (monotonic writes mode). Гарантия того, что после сохранения состояния конкретной строки, ее прошлое состояние не может быть перезаписано. Таким образом, потребители получают изменения состояния только в прямом направлении, не передвигаясь назад и вперед во времени.
Мы планируем открыть исходный код DBLog в 2020 году и включить в него дополнительную документацию.
Благодарности
Мы хотели бы поблагодарить следующих людей за участие в разработке DBLog: Josh Snyder, Raghuram Onti Srinivasan, Tharanga Gamaethige и Yun Wang.
Ссылки
[1] Das, Shirshanka, et al. “All aboard the Databus!: Linkedin’s scalable consistent change data capture platform.” Third ACM Symposium on Cloud Computing. ACM, 2012
[2] “About Change Data Capture (SQL Server)”, Microsoft SQL docs, 2019
[3] Kleppmann, Martin, “Using logs to build a solid data infrastructure (or: why dual writes are a bad idea)“, Confluent, 2015
[4] Kleppmann, Martin, Alastair R. Beresford, Boerge Svingen. “Online event processing.” Communications of the ACM 62.5 (2019): 43–49
[5] https://debezium.io/documentation/reference/0.10/connectors/mysql.html#snapshots
Узнать подробнее о курсе.