
Пока писал эту сугубо техническую статью, Хабр успел превратиться в местное отделение ВОЗ и теперь мне даже стыдно ее публиковать… но в душе теплится надежда, что айтишники еще не разбежались и она найдет своего читателя. Или нет?
Меня всегда восхищала стандартная библиотека Си, да и сам Си — при всей своей минималистичности от них так и веет духом тех самых первых красноглазиков хакеров. В черновике первого официального стандарта (ANSI C, он же C89, он же ANS X3.159-1989, он же, позднее, C90 и IEC 9899:1990) определяется 145 функций и макросов, из них около 25 — это вариации (ввиду отсутствия в языке перегрузок), а 26 чисто математических. K&R во второй редакции? приводят 114 функций (плюс математические), считая остальные за экзотику. В черновике? C11 функций уже 348, но больше сотни — математика, а еще штук 90 это «перегрузки». А теперь посмотрим на Boost, где одних только библиотек — 160. Чур меня…
И среди этой сотни-полутора функций всегда были: обработка сигналов, вариативные функции (которые до интерпретируемого PHP дошли 25 лет спустя, а в Delphi, бурно развивавшемся одно время, их нет до сих пор) и порядка 50 строковых функций вроде printf() (м-м-м… JavaScript), strftime() (…) и scanf() (дешевая альтернатива регуляркам).
А еще всегда были setjmp()/longjmp(), которые позволяют реализовать привычный по другим языкам механизм исключений, не выходя за рамки переносимого Си. Вот о них и поговорим — Quake World, стеки, регистры, ассемблеры и прочая матчасть, а вишенкой будет занятная статистика (спойлер: Visual Studio непостоянна, как мартовский заяц, а throw saneex.c в два раза быстрее всех).

? По результатам замеров в статье.
? Кстати, книга великолепная. 270 страниц, из которых 80 — это краткий пересказ стандарта. Или в то время еще не умели растекаться мыслью по древу и конвертировать это в гонорар, или авторы были выше этого. K&R — старая школа, чо.
? Из особо достоверных источников известно, что финальные версии стандартов ANSI и ISO продаются за деньги, а черновики бесплатны. Но это не точно.
? Да, я тоже не люблю «сокращалки» вроде TinyURL, но парсер Хабра считает URL частью текста и ругается на длинный текст до ката, яко Твіттер поганий. Дальше этого не будет, честно-честно. Параноикам могу посоветовать urlex.org.
Оглавление:
Итак, герои нашей программы — setjmp()/longjmp(), определенные в setjmp.h, которые любят вместе сокращать как «SJLJ» (хотя мне это слово не нравится, напоминает одну печально известную аббревиатуру). Они появились в C89 и, в общем-то, уходить не собираются, но про них не все знают (знать не значит использовать — знание полезно, а использование — как повезет).
Справедливости ради надо сказать, что на Хабре уже были статьи, посвященные этой теме, в особенности отличная статья от zzeng. В англоязычной Сети, конечно, тоже имеется, плюс можно найти реализации вроде такой или даже вот такой?, но, на мой взгляд, у них есть фатальный недостаток результат или не до конца привычен (к примеру, нельзя выбрасывать исключения повторно), или используются механизмы не по стандарту.
? CException хочется отметить особо — всего 60 строчек, пишут, что работает быстро, тоже ANSI C, но у него нет finally и текстовых сообщений, что для меня принципиально важно.
Вообще, использовать исключения или нет — вечный спор тупоконечников с остроконечниками в любом языке, и я призываю тех, кто по другую сторону баррикад, или пройти мимо, или прочитать материал и отложить его в свою копилку знаний, пусть даже на полку «чего только не тащат в нашу уютненькую сишечку». (Главное, чтобы спорщики не забывали, что ни одна программа на Си по-настоящему от «исключений» не свободна, ибо проверка errno не спасет при делении на ноль. Сигналы — те же яйца, только в профиль.)
Для меня лично исключения это инструмент, который позволяет:
- не думать в каждом конкретном месте, что что-то может пойти не так, если это самое место все равно с этим ничего не может сделать (ресурсы не заблокированы, память не выделена — можно прерываться немедленно, без
if (error) return -1;) - когда что-то и впрямь пошло не так — сохранить как можно больше информации, от кода ошибки и имени файла до значения важных переменных и других исключений, которые породили эту ситуацию
Но обо всем по порядку. Как это у нас принято, начнем с матчасти.
Как работают setjmp()/longjmp()
Регистры, стек и все-все-все
В двух словах, longjmp() — это нелокальный goto, а setjmp() — пророк его способ задания метки этому goto в run-time. Короче, «goto на стероидах». И, как и любые стероиды, то бишь, goto, они могут нанести непоправимый вред вашему коду — превратить его в такую лапшу, которая для goto просто вне досягаемости. Посему лучше всего их использовать не напрямую, а внутри какой-нибудь обертки, задающей четкую иерархию переходов (как то исключения — вверх по стеку в пределах явно обозначенных блоков «try»).
Помните, я говорил в начале, что от Си и, конкретно, от setjmp.h прямо веет черт^W юниксовщиной? Так вот, вы вызываете setjmp() один раз, а она возвращается сколько угодно раз (но, как минимум, один). Да, в обычном мире смузихлебы вызывают функцию и она возвращается один раз, а в Советской России функция вызывает вас сама, сколько раз ей хочется и когда ей этого хочется. Такие дела.
Эта концепция, кстати, воплотилась не только в setjmp() — fork() в POSIX делает нечто очень похожее. Я помню, когда я впервые знакомился с *nix’овыми API после десятка лет работы исключительно с WinAPI, мне просто сносило крышу — в моих ментальных шаблонах не укладывалось, что функции могут вот так себя вести. Как метко говорят — «а что, так можно было?»… Но мы отвлеклись.
Думаю, все читающие в курсе, что основной элемент рантайма — это стек, на котором лежат параметры и (некоторые) локальные переменные данной функции. Вызываешь новую функцию — стек растет (причем у Intel’а — вниз), выходишь — тает (у Intel’а — да-да, вверх). Вот примерчик:
void sub(int s) {
char buf[256];
sub(2);
}
int main(int m) {
sub(1);
}Есть такой занятный компилятор — tcc (Tiny C Compiler) от известного программиста-парохода Ф. Беллара. tcc практически не делает оптимизаций и код после него очень приятно смотреть в дизассемблере. Он генерирует такое тело для sub() (в нотации Intel, опуская пролог и эпилог):
sub esp, 100h ; выделяем место под локальную переменную
mov eax, 2 ; передаем параметр
push eax
call sub_401000 ; вызываем sub()
add esp, 4 ; очищаем стек после возврата (= cdecl)Вот схемка происходящего со стеком:
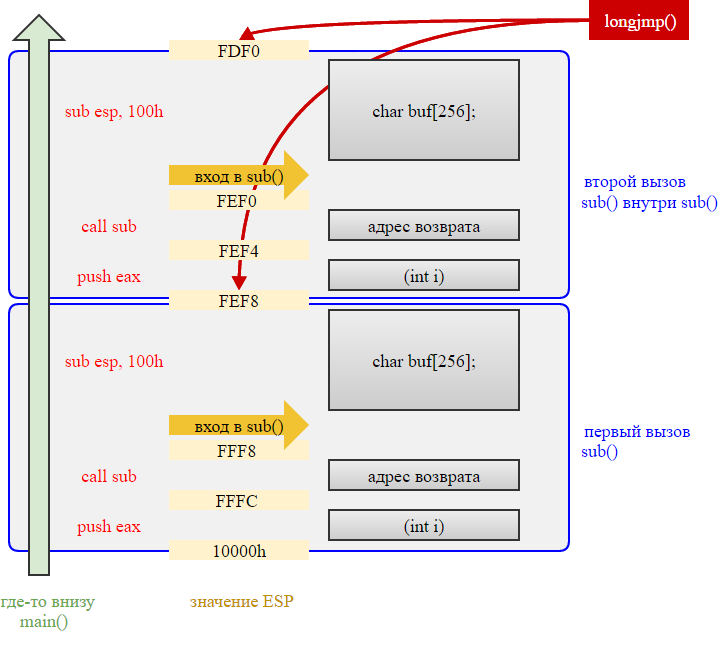
Вот эти оранжевые цифры по центру — это указатель на вершину стека (который у Intel… ну, вы поняли). Указатель хранится в регистре ESP (RSP на x86_64). setjmp() сохраняет текущее значение ESP/RSP, плюс другие служебные регистры, в область памяти jmp_buf, которую вы ему передаете. Если происходит вызов longjmp() далее по курсу (из этой же функции или из подфункции) — указатель восстанавливается и получается, что следом автоматически восстанавливается и окружение функции, где был вызван setjmp(), а все вызванные ранее подфункции моментально завершаются (возвращаются). Эдакий откат во времени, «undo» для рантайма (конечно, с большой натяжкой).
В следующем примере setjmp() поместит в jmp значение указателя FEF8h (FDF0h и т.д. — красные стрелки на схеме выше) и функция продолжит выполнение, как обычно:
void sub(int s) {
char buf[256];
jmp_buf jmp;
setjmp(jmp);
sub(2);
}Но, конечно, есть нюанс™:
- нельзя прыгать между потоками (setjmp() в одном, longjmp() в другом), потому как, очевидно, у каждого потока свой стек
- если функция, которая вызвала setjmp(), уже вернулась, то «реанимировать» ее не выйдет — программа впадет в undefined behavior (и это не лечится)
- компилятор использует регистры для хранения переменных — они, видите ли, быстрее работают! — а регистры, внезапно, хранятся отдельно от стека и, хотя setjmp() могла сохранить их состояние на момент вызова, она и longjmp() не знают, что с ними происходило после вызова setjmp()
Затирание переменных или, по-русски, clobbering
Последний момент особенно интересен. Пример:
#include <stdlib.h>
#include <stdio.h>
#include <setjmp.h>
int main(void) {
int i;
jmp_buf jmp;
i = rand();
if (setjmp(jmp) == 0) {
i = rand();
printf("%d\n", i);
longjmp(jmp, 1);
} else {
printf("%d\n", i);
}
}Вопрос залу: будут ли числа в консоли совпадать?
Правильный ответ: зависит от воли звезд. Так-то!
Посмотрим, что происходит на примере gcc. Если скомпилировать с -O0, то числа будут совпадать, а в дизассемблере мы увидим вот это:
; int main(void) {
push ebp ; пролог (создается stack frame)
mov ebp, esp ; EBP указывает на стек ниже ESP (если по схеме)
sub esp, E0h
...
call _rand ; результат возвращается в EAX
mov [ebp-D4h], eax ; это i = rand(); где i на стеке (EBP-D4h)
...
; if (... == 0) { ; вызов setjmp() и возврат из нее до прыжка
call _rand
mov [ebp-D4h], eax ; снова i = rand(); на стеке
; printf("%d\n", i);
mov eax, [ebp-D4h] ; передаем i со стека как параметр
mov esi, eax
lea edi, format ; передаем строку "%d\n"
mov eax, 0
call _printf
...
; } else { ; вторичный возврат из setjmp() после прыжка
mov eax, [ebp-D4h] ; снова передаем i, как в ветке выше
mov esi, eax
lea edi, format ; "%d\n"
mov eax, 0
call _printfКак видно, компилятор не заморачивался и поместил переменную i в стек (по адресу EBP - D4h). Если смотреть на всю ту же схемку, то:
- вместо буфера на 256 char мы имеем int и jmp_buf, размер которых на моей системе 4 и 200 байт соответственно, плюс 20 байт для чего-то потребовалось компилятору, так что на стеке под локальные переменные выделилось 224 байта (E0h) вместо 100h, как в том примере
- ESP на момент вызова setjmp() равен
FFF8h - E0h = FF18h(вместоFEF8h), это значение и сохраняется в jmp
- конечно, это значение условно, в реальности оно будет иным
- и первое присваивание i, и второе меняют значение i в стеке (по адресу
FF18h) - longjmp() сбрасывает указатель стека обратно в
FF18h, но, так как переменная i не выходит за эти границы, она по-прежнему доступна, равно как и другая переменная (jmp), и параметры main() (буде они есть)
- в этом примере ESP и так не менялся, но longjmp() легко мог бы быть внутри другой функции, вызванной из main()
А вот если включить хотя бы -O1, то картина изменится:
; пролога и stack frame больше нет, используется значение ESP напрямую
sub esp, E8h
...
call _rand
mov [esp+E8h-DCh], eax ; i = rand(); в стеке, как и с -O0
...
; -O1 почему-то решило, что выполнение else более вероятно, чем
; if (setjmp() == 0) (хотя по-моему наоборот), и переставило
; их местами; здесь я вернул прежний порядок для понятности
; if (... == 0) {
call _rand
mov esi, eax ; ВНИМАНИЕ! запись i в регистр
; printf("%d\n", i);
lea edi, format ; "%d\n"
mov eax, 0
call _printf
...
; } else {
mov esi, [esp+E8h-DCh] ; ВНИМАНИЕ! чтение i со стека
lea edi, format ; "%d\n"
mov eax, 0
call _printfВдобавок, с -O1 gcc при компиляции ругается страшными словами:
test.c:6:11: warning: variable ‘i’ might be clobbered by ‘longjmp’ or ‘vfork’ [-Wclobbered]Что мы здесь видим? Вначале i помещается в регистр, но в первой ветке (внутри if) gcc, видимо сочтя i не используемой после первого printf(), помещает новое значение сразу в ESI, а не в стек (через ESI оно передается дальше в printf(), см. ABI, стр. 22 — RDI (format), RSI (i), …). Из-за этого:
- в стеке по адресу
ESP + E8h - DChостается старое значение rand() - в ESI оказывается новое значение
- printf() (первый вызов) принимает (новое) значение из регистра
- longjmp() сбрасывает указатель стека, но не восстанавливает изменившиеся регистры, которые используются функциями для локальных переменных при включенных оптимизациях
- второй вызов printf() (в else) читает значение, как положено, из стека, то бишь старое
- но даже если бы оно читалось из ESI, то после прыжка в этом регистре был бы мусор (вероятно, из printf() или самого longjmp())
Или, если переписать это обратно на Си:
stack[i] = rand(); // i = rand(); изменение стека (1)
if (setjmp(jmp) == 0) {
ESI = rand(); // i = rand(); изменение регистра (2)
printf("%d\n", ESI); // печать значения (2)
longjmp(jmp, 1); // прыжок
} else {
printf("%d\n", stack[i]); // печать значения (1)
// или могло бы быть так:
printf("%d\n", ESI); // использование регистра, где уже кто-то
// "побывал" (первый printf() или longjmp())
}Честно говоря, мне не понятно, почему gcc результат первого rand() не помещает сразу в ESI или в другой регистр (даже при -O3). На SO пишут, что в режиме x86_64 (под который я компилировал пример) сохраняются все регистры, кроме EAX. Зачем промежуточное сохранение в стек? Я предположил, что gcc отследил printf() в else после longjmp(), но если убрать второй rand() и этот printf() — результат не меняется, i так же вначале пишется в стек.
Если кто может пролить свет на сию тайну — прошу в комментарии.
Квалификатор volatile
Решение проблемы «летучих переменных» — квалификатор volatile (дословно — «летучий»). Он заставляет компилятор всегда помещать переменную в стек, поэтому наш код будет работать, как ожидается, при любом уровне оптимизаций:
volatile int i;Единственное изменение при -O1 будет в теле if:
; было:
call _rand
mov esi, eax
; стало:
call _rand
mov [rsp+E8h-DCh], eax
mov esi, [rsp+E8h-DCh]
; или можно переписать так:
call _rand
mov esi, eax
mov [rsp+E8h-DCh], eaxКак видим, компилятор продублировал присвоение в стек (сравните):
if (setjmp(jmp) == 0) {
ESI = stack[i] = rand();Случаи использования IRL
Итак, если соблюдать меры предосторожности — не прыгать между потоками и между завершившимися функциями и не использовать изменившиеся не-volatile переменные после прыжка, то SJLJ позволяет нам беспроблемно перемещаться по стеку вызовов в произвольную точку. И не обязательно быть адептом секты свидетелей исключений — сопротивление бесполезно, ибо SJLJ уже давно заполонили всю планету среди нас:
- Википедия предлагает использовать их для реализации корутин в Си (я бы не стал — как бы чего не вышло, хотя ldir такую технику тоже упоминал)
- на Хабре alexkalmuk писал про юнит-тесты в Эльбрусе на основе SJLJ (+ вторая статья), а dzeban — про профилирование в Linux
- также местные писали про быстрый интерпретатор (осторожно: очень сильное колдунство от Atakua), про обработку ошибок в x86emu (NWOcs) и в libpng (в libjpeg-turbo аналогично)
- в 2017 Skapix писал про pthreads, а kutelev — про прыжки из обработчиков сигналов
- тут пишут, что эта парочка использовалась в Symbian
- а в Quake World она использовалась совершенно точно — см. перевод археологических раскопок от PatientZero и, собственно, исходники (там есть и пара других мест)
Последний пример, на мой взгляд, наиболее хрестоматийный — это обработка ошибок и других состояний, когда нужно выйти «вот прямо сейчас», с любого уровня, при этом вставлять везде проверки на выход утомительно, а где-то и не возможно (библиотеки). Кстати, еще один пример был описан в проекте DrMefistO.
Конкретно в Quake World запускается бесконечный цикл в WinMain(), где каждая новая итерация устанавливает jmp_buf, а несколько функций могут в него прыгать, таким образом реализуя «глубокий continue»:
// WinQuake/host.c
jmp_buf host_abortserver;
void Host_EndGame (char *message, ...)
{
...
if (cls.demonum != -1)
CL_NextDemo ();
else
CL_Disconnect ();
longjmp (host_abortserver, 1);
}
void Host_Error (char *error, ...)
{
...
if (cls.state == ca_dedicated)
Sys_Error ("Host_Error: %s\n",string); // dedicated servers exit
CL_Disconnect ();
cls.demonum = -1;
inerror = false;
longjmp (host_abortserver, 1);
}
void _Host_Frame (float time)
{
static double time1 = 0;
static double time2 = 0;
static double time3 = 0;
int pass1, pass2, pass3;
if (setjmp (host_abortserver) )
return; // something bad happened, or the server disconnected
...
}
// QW/client/sys_win.c
int WINAPI WinMain (...)
{
...
while (1)
{
...
newtime = Sys_DoubleTime ();
time = newtime - oldtime;
Host_Frame (time);
oldtime = newtime;
}
/* return success of application */
return TRUE;
}Производительность
Один из доводов, который приводят против использования исключений — их отрицательное влияние на производительность. И действительно, в исходниках setjmp() в glibc видно, что сохраняются почти все регистры общего назначения ЦП. Тем не менее:
- само собой разумеется, что ни исключения в общем, ни SJLJ/
saneex.cв частности и не предполагаются к применению во внутренностях числодробилок - современные те-кхе…кхе-нологии (
извиняюсь, электрон в горло попал) таковы, что сохранение лишнего десятка-другого регистров — это самая малая из проблем, которые они в себе несут - если скорость критична, а исключений хочется — есть механизмы zero-cost exceptions (или, точнее, zero-cost try), которые радикально снижают нагрузку при входе в блок try, оставляя всю грязную работу на момент обработки (выброса) — а так как исключения это не goto и должны использоваться, гм, в исключительных ситуациях, то на производительности такой «перекос» сказывается, э-э, исключительно положительно
«Честные» zero-cost exceptions особенно полезны в том плане, что избавляют от более медленных volatile-переменных, которые иначе размещаются в стеке, а не в регистрах (именно поэтому они и не затираются longjmp()). Тем не менее, их поддержка это уже задача для компилятора и платформы:
- В Windows есть SEH и VEH, последний подвезли в XP.
- В gcc было несколько разных вариантов — вначале на основе SJLJ, потом DWARF, коего на сегодняшний день было пять версий (DWARF применяется и в clang). На эту тему см. отменные статьи zzeng: тыц и тыц, и сайт dwarfstd.org.
- В комментарии к другой статье камрад nuit дал наводку на интересный проект libunwind, но использовать его только ради исключений — это как стрелять из воробьев по пушкам (больно большой).
И, хотя saneex.c не претендует на пальму zero-cost (ее пальма — это переносимость), так ли уж страшен setjmp(), как его малюют? Может, это суеверие? Чтобы не быть голословными — померяем.
Тестовая среда
Я набросал два бенчмарка «на коленке», которые в main() в цикле 100 тысяч раз входят в блок try/catch и делают или не делают throw().
Исходник бенчмарка на C:
#include <stdio.h>
#include <time.h>
#include "saneex.h"
int main(void) {
for (int i = 0; i < 100000; i++) {
try {
// либо ("выброс" = да):
throw(msgex("A quick fox jumped over a red dog and a nyancat was spawned"));
// либо ("выброс" = нет):
time(NULL);
} catchall {
fprintf(stderr, "%s\n", curex().message);
} endtry
}
}Исходник на С++ (я адаптировал пример с Википедии, вынеся объявление вектора за цикл и заменив cerr << на fprintf()):
#include <iostream>
#include <vector>
#include <stdexcept>
#include <time.h>
int main() {
std::vector<int> vec{ 3, 4, 3, 1 };
for (int i = 0; i < 100000; i++) {
try {
// либо ("выброс" = да):
int i{ vec.at(4) };
// либо ("выброс" = нет):
time(NULL);
}
catch (std::out_of_range & e) {
// << вместо fprintf() вызывает замедление цикла на 25-50%
//std::cerr << "Accessing a non-existent element: " << e.what() << '\n';
fprintf(stderr, "%s\n", e.what());
}
catch (std::exception & e) {
//std::cerr << "Exception thrown: " << e.what() << '\n';
fprintf(stderr, "%s\n", e.what());
}
catch (...) {
//std::cerr << "Some fatal error\n";
fprintf(stderr, "Some fatal error");
}
}
return 0;
}Тестировалось все на одной машине в двух ОС (обе 64-битные):
- Windows 10 2019 LTSC под PowerShell с помощью
Measure-Command { test.exe 2>$null } - последний Live CD Ubuntu с помощью встроенной time
Также я попробовал замерить исключения в Windows через расширения __try/__except, взяв другой пример с Википедии:
#include <windows.h>
#include <stdio.h>
#include <vector>
int filterExpression(EXCEPTION_POINTERS* ep) {
ep->ContextRecord->Eip += 8;
return EXCEPTION_EXECUTE_HANDLER;
}
int main() {
static int zero;
for (int i = 0; i < 100000; i++) {
__try {
zero = 1 / zero;
__asm {
nop
nop
nop
nop
nop
nop
nop
}
printf("Past the exception.\n");
}
__except (filterExpression(GetExceptionInformation())) {
printf("Handler called.\n");
}
}
}Однако вектор включить в цикл не вышло — компилятор сообщил, что:
error C2712: Cannot use __try in functions that require object unwindingТак как накладываемые ограничения на код идут вразрез с принципом привычности, о котором я говорил в начале, я не внес эти результаты в таблицу ниже. Ориентировочно это 1100-1300 мс (Debug или Release, x86) — быстрее, чем стандартные исключения в VS, но все равно медленнее, чем они же в g++.
Результаты
№ Компилятор Конфиг Платф Механизм Выброс Время (мс)? saneex медленнее
1. VS 2019 v16.0.0 Debug x64 saneex.c да 9713 / 8728 = 1.1 в 1.8 / 1.8
2. VS 2019 v16.0.0 Debug x64 saneex.c нет 95 / 46 = 2 в 4.5 / 2.3
3. VS 2019 v16.0.0 Debug x64 C++ да 5449 / 4750? = 1.6
4. VS 2019 v16.0.0 Debug x64 C++ нет 21 / 20 = 1
5. VS 2019 v16.0.0 Release x64 saneex.c да 8542? / 182 = 47 в 1.8 / 0.4
6. VS 2019 v16.0.0 Release x64 saneex.c нет 80? / 23 = 3.5 в 8 / 1.8
7. VS 2019 v16.0.0 Release x64 C++ да 4669? / 420 = 11
8. VS 2019 v16.0.0 Release x64 C++ нет 10? / 13 = 0.8
9. gcc 9.2.1 -O0 x64 saneex.c да 71 / 351 = 0.2 в 0.2 / 0.6
10. gcc 9.2.1 -O0 x64 saneex.c нет 6 / 39 = 0.2 в 1.5 / 1.1
11. g++ 9.2.1 -O0 x64 C++ да 378 / 630 = 0.6
12. g++ 9.2.1 -O0 x64 C++ нет 4 / 37 = 0.1
13. gcc 9.2.1 -O3 x64 saneex.c да 66 / 360 = 0.2 в 0.2 / 0.6
14. gcc 9.2.1 -O3 x64 saneex.c нет 5 / 23 = 0.2 в 1 / 0.6
15. g++ 9.2.1 -O3 x64 C++ да 356 / 605 = 0.6
16. g++ 9.2.1 -O3 x64 C++ нет 5 / 38 = 0.1? В столбце Время добавлены замеры одного из читателей на Windows 7 SP1 x64 с VS 2017 v15.9.17 и gcc под cygwin.
? Крайне странный факт: если fprintf() заменить на cerr <<, то время выполнения сократится в 3 раза: 1386/1527 мс.
? VS в релизных сборках на моей системе выдает очень непостоянные результаты, поэтому в дальнейших рассуждениях я использую цифры читателя.
Результаты получились… интересные:
- Показатели сильно плавают на разных машинах и/или окружениях и особенно «чудит» VS. Чем это вызвано — непонятно.
- Использование
cerr <<вместо fprintf() в паре с выбросом исключения в VS в отладочной сборке ускоряет цикл в 3-4 раза (строка 3). ЧЯДНТ? - Во всех случаях расходы на блок try в отсутствие throw — мизерные (4-28 мс на 100 тысяч итераций).
- Не считая «разогнанного» Debug в VS, выброс исключений в
saneex.cбыстрее, чем во встроенных языковых конструкциях (в 2.3 раза быстрее VS, в 5 раз быстрее gcc/g++), а try без throw — помедленнее, но речь идет о единицах миллисекунд. Вот это поворот!
Что тут можно сказать… Есть о чем похоливарить. Добро пожаловать в комментарии!
Для меня самый важный use-case — это много блоков try с крайне редкими throw («лови много, бросай мало»), а он зависит практически только от скорости setjmp(), причем производительность последнего, судя по таблице, далеко не так плоха, как часто думают. Косвенно это подтверждается и вот этой статьей, где автор после замеров делает вывод, что один вызов setjmp() равен двум вызовам пустых функций в OpenBSD и полутора (1.45) — в Solaris. Причем эта статья от 2005 года. Единственное «но» — сохранять нужно без сигнальной маски, но она обычно и не интересна.
Ну, а напоследок…
Виновник торжества — saneex.c
Библиотека, чей пример был на КДПВ:
- может компилироваться даже в Visual Studio
- поддерживает любую вложенность блоков, throw() из любого места, finally и несколько catch на блок (по коду исключения)
- не выделяет память и не использует указатели (все в static)
- опционально-многопоточная (__thread/_Thread_local)
- в public domain (CC0)
Интересующиеся могут найти ее исходники на GitHub. Ниже я кратко на одном примере покажу, как ей пользоваться и какие есть подводные камни. Код примера из saneex-demo.c в репозитории:
01. #include <stdio.h>
02. #include "saneex.h"
03.
04. int main(void) {
05. sxTag = "SaneC's Exceptions Demo";
06.
07. try {
08. printf("Enter a message to fail with: [] [1] [2] [!] ");
09.
10. char msg[50];
11. thrif(!fgets(msg, sizeof(msg), stdin), "fgets() error");
12.
13. int i = strlen(msg) - 1;
14. while (i >= 0 && msg[i] <= ' ') { msg[i--] = 0; }
15.
16. if (msg[0]) {
17. errno = atoi(msg);
18. struct SxTraceEntry e = newex();
19. e = sxprintf(e, "Your message: %s", msg);
20. e.uncatchable = msg[0] == '!';
21. throw(e);
22. }
23.
24. puts("End of try body");
25.
26. } catch (1) {
27. puts("Caught in catch (1)");
28. sxPrintTrace();
29.
30. } catch (2) {
31. puts("Caught in catch (2)");
32. errno = 123;
33. rethrow(msgex("calling rethrow() with code 123"));
34.
35. } catchall {
36. printf("Caught in catchall, message is: %s\n", curex().message);
37.
38. } finally {
39. puts("Now in finally");
40.
41. } endtry
42.
43. puts("End of main()");
44. }Программа выше читает сообщение, бросает исключение и обрабатывает его в зависимости от пользовательского ввода:
- если ничего не ввести — исключение выброшено не будет, и мы увидим:
End of try body
Now in finally
End of main()- если ввести текст, начинающийся с единицы, то будет создано исключение с этим кодом (1), оно будет поймано в первом блоке
catch (1)(26.), а на экране появится:
Caught in catch (1)
Your message: 1 hello, habr!
...at saneex-demo.c:18, code 1
Now in finally
End of main()- если ввести двойку, то исключение будет поймано (30.), выброшено новое (со своим кодом, текстом и прочим) с сохранением предыдущей информации в цепочке (33.), дойдет до внешнего обработчика и программа завершится:
Caught in catch (2)
Now in finally
Uncaught exception (code 123) - terminating. Tag: SaneC's Exceptions Demo
Your message: 2 TM! kak tam blok4ain?
...at saneex-demo.c:18, code 2
calling rethrow() with code 123
...at saneex-demo.c:33, code 123
rethrown by ENDTRY
...at saneex-demo.c:41, code 123- если ввести
!, то исключение получится «неуловимым» (uncatchable; 20.) — оно пройдет сквозь все блоки try выше по стеку, вызывая их обработчики (как catch, так и finally), пока не дойдет до внешнего и не завершит процесс — гуманный аналог abort():
Caught in catch (1)
Your message: ! it is a good day to die
...UNCATCHABLE at saneex-demo.c:18, code 0
Now in finally
Uncaught exception (code 0) - terminating. Tag: SaneC's Exceptions Demo
Your message: ! it is a good day to die
...UNCATCHABLE at saneex-demo.c:18, code 0
UNCATCHABLE rethrown by ENDTRY
...at saneex-demo.c:41, code 0- наконец, если ввести тройку, то исключение попадет в catchall (35.), где просто будет выведено его сообщение:
Caught in catchall, message is: Your message: 3 we need more gold
Now in finally
End of main()Остальные «фичи»
Потокобезопасность. По умолчанию ее нет, но если у вас нормальный компилятор (не MSVC?), то C11 спасет отца народов за счет помещения важных переменных в локальную область потока (TLS):
#define SX_THREAD_LOCAL _Thread_local? Последние годы у Microsoft имеются какие-то подвижки на почве open source, но всем по дело идет медленно, хотя и лучше, чем 8 лет назад, так что мы пока держимся.
sxTag (05.) — строка, которая выводится вместе с непойманным исключением в stderr. По умолчанию — дата и время компиляции (__DATE__ __TIME__).
Создание SxTraceEntry (записи в stack trace). Есть несколько полезных макросов — оберток над (struct SxTraceEntry) {...}:
newex()— этот был в примере; присваивает __FILE__, __LINE__ и код ошибки = errno (что удобно после проверки результата вызова системной функции, как в примере после fgets(); 11.)
- код меньше 1 становится 1 (ибо setjmp() возвращает 0 только при первом вызове), поэтому
catch (0)никогда не сработает
- код меньше 1 становится 1 (ибо setjmp() возвращает 0 только при первом вызове), поэтому
msgex(m)— как newex(), но также устанавливает текст ошибки (константное выражение)exex(m, e)— как msgex(), но также прицепляет к исключению произвольный указатель; его память будет освобождена через free() автоматически:
try {
TimeoutException *e = malloc(sizeof(*e));
e->elapsed = timeElapsed;
e->limit = MAX_TIMEOUT;
errno = 146;
throw(exex("Connection timed out", e));
} catch (146) {
printf("%s after %d\n", curex().message,
// читаем через void *SxTraceEntry.extra:
((TimeoutException *) curex().extra)->elapsed);
} endtryИ, конечно, есть мои любимые designated initializers из все того же C99 (работают в Visual Studio 2013+):
throw( (struct SxTraceEntry) {.message = "kaboom!"} );Выброс исключения:
throw(e)— бросает готовый SxTraceEntryrethrow(e)— аналогично throw(), но не очищает текущий stack trace; может использоваться только внутри catch/catchallthrif(x, m)— макрос; приif (x)создает SxTraceEntry с текстом x + m и «выбрасывает» егоthri(x)— как thrif(), только с пустым m
Макросы нужны для удобного «преобразования» результата типичного библиотечного вызова в исключение — как в примере с fgets() (11.), если функция не смогла прочитать ничего. Конкретно с fgets() это не обязательно обозначает ошибку (это может быть просто EOF: ./a.out </dev/null), но других подходящих функций в том примере не используется. Вот более жизненный:
thri(read(0xBaaD, buf, nbyte));
// errno = 9, "Bad file descriptor"
// Assertion error: read(0xBaaD, buf, nbyte);…И «особенности реализации»
Их всего две с половиной (но зато какие!):
- блок обязан заканчиваться на endtry — здесь происходит завершение процесса при отсутствии обработчика (блока try) выше по стеку
- эту ошибку компилятор, скорее всего, поймает, ибо try открывает три
{, а endtry их закрывает
- эту ошибку компилятор, скорее всего, поймает, ибо try открывает три
- нельзя делать return между try и endtry — это самый жирный минус, но моя фантазия не нашла способов отловить эту ситуацию; принимаются идеи и PR
- естественно, goto внутрь и наружу тоже под запретом, но разве его кто-то использует?
</sarcasm>
- естественно, goto внутрь и наружу тоже под запретом, но разве его кто-то использует?
Что касается «половины», то это уже разобранный ранее volatile. «Прием» исключения — это повторный вход в середину функции (см. longjmp()), поэтому, если значение переменной было изменено внутри тела try, то такая переменная не должна использоваться в catch/catchall/finally и после endtry, если она не объявлена как volatile. Компилятор заботливо предупредит о такой проблеме. Вот наглядный пример:
int foo = 1;
try {
foo = 2;
// здесь можно использовать foo
} catchall {
// а здесь уже нет!
} finally {
// и здесь тоже!
} endtry
// и здесь нельзя!С volatile переменную можно использовать где угодно:
volatile int foo = 1;
try {
...Итог: как это работает
У каждого потока есть два статически-выделенных (глобальных) массива:
struct SxTryContext— информация о блоках try, внутри которых мы сейчас находимся — в частности, jmp_buf на каждый из них; например, здесь их два:
try {
try {
// мы здесь
} endtry
} endtrystruct SxTraceEntry— текущий stack trace, то есть объекты, переданные кодом снаружи для идентификации исключений; их может быть больше или меньше, чем блоков try:
try { // один SxTryContext
try { // два SxTryContext
// ноль SxTraceEntry
throw(msgex("Первый пошел!"));
// один SxTraceEntry
} catchall {
// один SxTraceEntry
rethrow(msgex("Второй к бою готов!"));
// два SxTraceEntry (*)
} endtry
} endtryЕсли в коде выше вместо rethrow() использовать throw(), то объектов SxTraceEntry (*) будет не два, а один — предыдущей будет удален (stack trace будет очищен). Кроме того, можно вручную добавить элемент в цепочку через sxAddTraceEntry(e).
try и другие элементы конструкции суть макросы (— ваш К. О.). Скобки { } после них не обязательны. В итоге, все это сводится к следующему псевдокоду:
try { int _sxLastJumpCode = setjmp(add_context()?);
bool handled = false;
if (_sxLastJumpCode == 0) {
throw(msgex("Mama mia!")); clearTrace();
sxAddTraceEntry(msgex(...));
if (count_contexts() == 0) {
fprintf(stderr, "Shurik, vsё propalo!");
sxPrintTrace();
exit(curex().code);
} else {
longjmp(top_context());
}
} catch (9000) { } else if (_sxLastJumpCode == 9000) {
handled = true;
} catchall { } else {
handled = true;
} finally { }
// здесь действия в finally { }
} endtry remove_context();
if (!handled) {
// как выше с throw()
}? Имена с _ в библиотеке не используются, это абстракции.
Думаю, после подробных объяснений, как работает SJLJ, что-то еще здесь комментировать излишне, а потому позвольте откланяться и предоставить слово уже вам.





sshikov
Чего только не придумают, чтобы не ходить на овощную базу (с) (анекдот советских времен)
Я правильно понял, что само исключение у вас это структура, в которой есть сообщение, строка где его кинули, и указатель еще на что-то?
Не уловил, можно ли будет посмотреть стектрейс, как скажем в Java, все строки, по которым проходил вызов до точки, где кинули исключение. На мой взгляд, для Java исключений это чуть ли не самое удобное, что дают исключения. Причем без усилий вообще.
ProgerXP Автор
Да: https://github.com/ProgerXP/SaneC/blob/master/saneex.h#L187
Конечно, в этом и смысл. На КДПВ справа внизу — именно такой stack trace.
Структура доступна в рантайме, ее можно проитерировать через
sxWalkTrace():https://github.com/ProgerXP/SaneC/blob/master/saneex.c#L42
Да, "без усилий вообще" — это как раз "привычный по другим языкам механизм исключений" для меня.
saneexэто дает из коробки.sshikov
Да, понял. Спасибо
Кстати, построение вот этого самого стека, насколько я помню — это как раз то, что в Java сильно снижает производительность при использовании исключений. На хабре даже пару раз упоминали небольшой хак, как все ускорить, кидая исключения без stacktrace.
ProgerXP Автор
Я с низким уровнем в JVM мало знаком, но, как пишут на SO, там используется подход zero-cost exceptions (см. в статье), то есть вся обработка делается в момент поимки исключения (если оно возникает). А Java — высокоуровневый язык с синхронизациями, объектами и прочим, поэтому такая обработка затратна.
В saneex и "голом" С все наоборот — throw это почти что один longjmp(), который, фактически, только сбрасывает указатель стека (ESP). Затраты на этот сброс околонулевые, что показывают мои замеры, по которым throw/longjmp() в C быстрее, чем throw в C++ (где, как и в JVM, дело не ограничивается только изменением ESP).
"Построение стека" происходит по мере вызовов try — там копируются параметры исключения (file, message и пр.) в статический массив, плюс вызывается setjmp(). Как раз последний является лимитирующим фактором, но от него избавиться нельзя никак, не уходя от C99. Но даже там счет идет на единицы-десятки мс при 100к повторений.