
Привет, Хабр! Представляю вашему вниманию перевод статьи «How to Move Beyond a Monolithic Data Lake to a Distributed Data Mesh» автора Zhamak Dehghani (Жамак Дегани)(все изображения взяты из этой же статьи).
Немало компаний инвестируют в следующее поколение Data Lake с надеждой упростить доступ к данным в масштабе всей компании и предоставить бизнесу инсайты и возможность принимать качественные решения автоматически. Но текущие подходы к построению платформ данных имеют схожие проблемы, которые не позволяют достигнуть поставленных целей. Чтобы решить эти проблемы нам необходимо отказаться от парадигмы централизованного Data Lake (или его предшественника – хранилища данных). И перейти к парадигме, основанной на современной распределённой архитектуре: рассматривать бизнес-домены как приоритет первого уровня, применять платформенное мышление для создания инфраструктуры с возможностью самообслуживания и воспринимать данные как продукт.
Содержание
Построение data-driven организации остаётся одной из главных стратегических целей многих компаний, с которыми я работаю. Мои клиенты хорошо знают о преимуществах принятия решений на основе качественных данных: обеспечение высочайшего качества обслуживания клиентов, гипер персонализация, сокращение операционных расходов и сроков за счёт оптимизации, предоставление сотрудникам инструментов анализа и бизнес-аналитики. Они вкладывают значительные средства в создание современных платформ данных. Но несмотря на растущие усилия и инвестиции в создание таких платформ, многие организации считают результаты посредственными.
Организации сталкиваются со многими сложностями в процессе трансформации в data-driven компании: миграция от разрабатываемых годы и десятилетия legacy систем, сопротивление со стороны сложившейся культуры и высокая конкуренция между разными бизнес-приоритетами. Как бы то ни было, я хочу поделиться с вами архитектурным подходом, который учитывает причины провала многих инициатив в области построения платформ данных. Я продемонстрирую как мы можем адаптировать и применить в области данных уроки прошлого десятилетия в построении распределённых архитектур. Этот новый архитектурный подход мною назван Data Mesh.
Прежде чем читать дальше, я прошу вас на время прочтения статьи постараться отказаться от предубеждений, которые заложила текущая парадигма традиционной архитектуры платформы данных. Будьте открыты к возможности перехода от централизованных Data Lakes к намеренно распределённой Data Mesh архитектуре. Примите, что данные по своей природе распределены и вездесущи.
Поговорим про централизованное, монолитное и независимое от бизнес смысла данных Data Lake.
Практически каждый клиент, с которым я работаю, или планирует, или уже строит свою платформу данных третьего поколения. Признавая при этом ошибки предыдущих поколений.
Платформы данных третьего поколения более или менее похожи на предыдущие поколения, но с уклоном в сторону
Платформа данных третьего поколения устраняет некоторые проблемы предыдущих поколений, такие как анализ данных в реальном времени, а также снижает затраты на управление инфраструктурой больших данных. Однако до сих пор сохраняются многие лежащие в основе подхода особенности, которые привели к неудачам предыдущих поколений.

Рисунок 1: Три поколения платформ данных
Чтобы раскрыть основные ограничения, которые несут в себе все поколения платформ данных, давайте посмотрим на их архитектуру и характеристики. В этой статье я буду использовать бизнес потокового интернет-медиа (как Spotify, SoundCloud, Apple iTunes) в качестве примера для пояснения некоторых концепций.
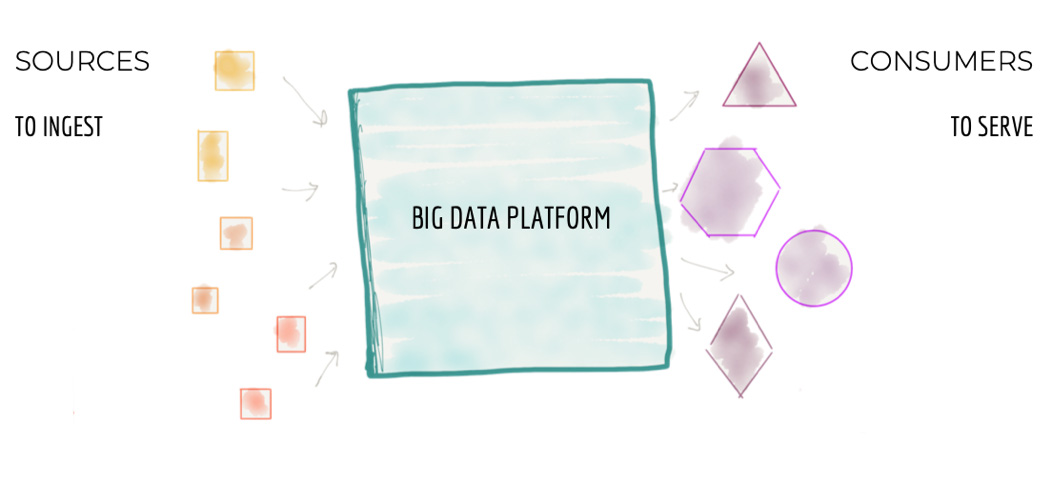
С высоты 10 000 метров архитектура платформы данных выглядит как на рисунке 2 ниже.
Рисунок 2: Вид с высоты 10 000 метров на монолитную платформу данных
Центральная часть архитектуры отвечает за:
По-умолчанию общепринятым соглашением является тот факт, что монолитная Data Platform хранит и владеет данными, которые принадлежат разным бизнес-доменам. К примеру, 'play events', 'sales KPIs', 'artists', 'albums', 'labels', 'audio', 'podcasts', 'music events' и т.д. — данные из большого количества разрозненных доменов.
Несмотря на то, что в последнее десятилетие мы успешно применяли концепцию Domain Driven Design (и ключевой её паттерн Bounded Context) к проектированию наших информационных систем, мы в значительной степени игнорировали эти концепции при проектировании платформ данных. Мы перешли от владения данными на уровне бизнес-домена к владению данными независимо от бизнес-доменов. Мы гордимся тем, что создали самый большой монолит – Big Data Platform.
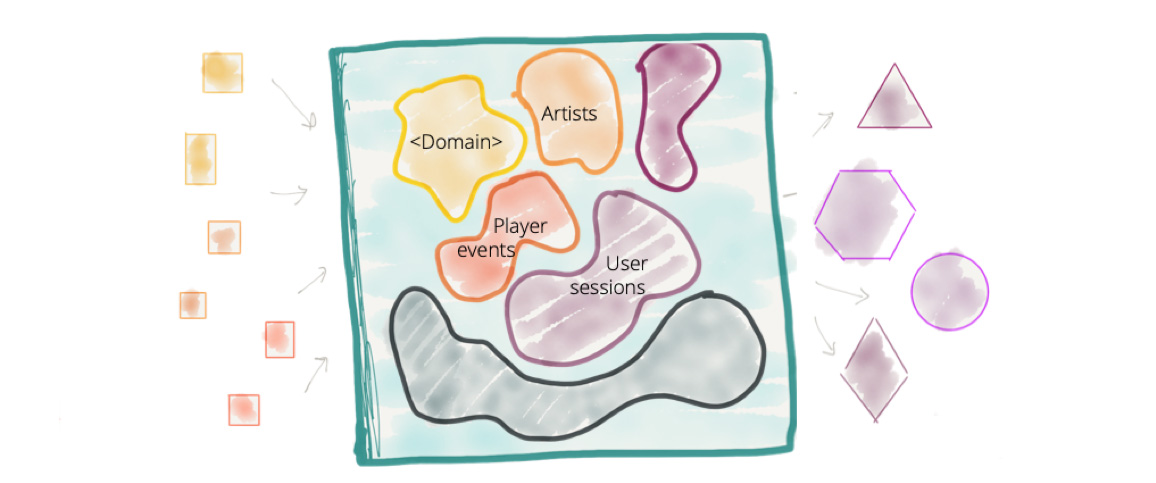
Рисунок 3: Централизованная платформа данных без чётких границ между данными разных бизнес-доменов. И без владения соответствующими данными со стороны бизнес-домена
Такая централизованная модель может работать для небольших организаций, у которых простые бизнес-домены и ограниченные варианты потребления данных. Но она не подходит для больших компаний с крупными и сложными бизнес-доменами, большим количеством источников данных и разнообразными потребностями в работе с данными со стороны потребителей.
Есть два слабых звена в архитектуре и структуре централизованной платформы данных, которые часто приводят к неудаче в процессе её построения:
Здесь мне нужно уточнить, что я не высказываюсь в пользу использования фрагментированных, разрозненных данных, скрытых в недрах легаси систем. Таких данных, которые трудно обнаружить, понять и использовать. Я также не поддерживаю многочисленные разрозненные хранилища данных в рамках одной организации, которые являются результатом многолетнего накопленного технического долга. Но я утверждаю, что ответом на такие недоступные фрагментированные данные не является создание централизованной платформы данных с централизованной же командой, которая хранит и владеет данными из всех бизнес-доменов.
Такой подход не масштабируется в крупных организациях, как уже показано выше.
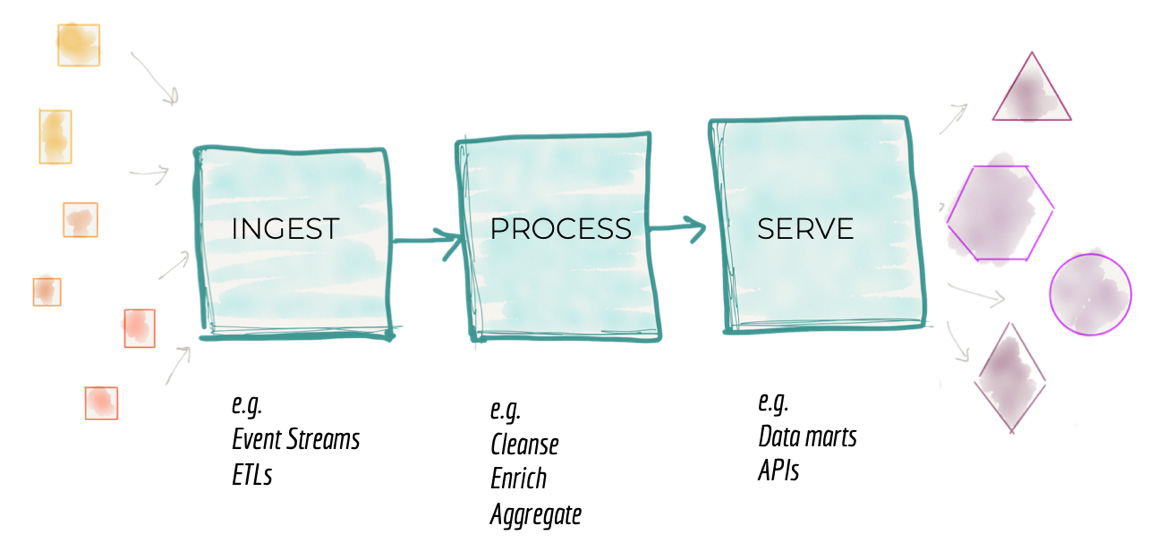
Рисунок 4: Архитектурная декомпозиция платформы данных
Вторая проблема традиционной архитектуры платформы данных связана с тем, как мы декомпозируем архитектуру. Если снизится до 3 000 метров над архитектурой платформы данных, мы обнаружим архитектурную декомпозицию вокруг функций загрузки, очистки, агрегирования, обслуживания данных и т.д. Как описано в предыдущем разделе, потребность в подключении новых источников и новых потребителей требует роста платформы. Архитекторы должны найти способ масштабирования системы, разбив её на архитектурные кванты. Архитектурный квант, как описано в книге “Building Evolutionary Architectures”, представляет собой независимо развёртываемый компонент с высокой функциональной связностью, который включает в себя все структурные элементы, необходимые для правильной работы системы. Мотивация разделения системы на архитектурные кванты в первую очередь состоит в создании независимых команд, каждая из которых создаёт и поддерживает свой архитектурных квант (функциональную подсистему). Это позволяет распараллелить работу и повысить скорость и операционную масштабируемость.
Под влиянием предыдущих поколений платформ данных, архитекторы разделяют платформу на последовательность этапов обработки данных. Это представляет собой конвейер (pipeline), который реализует обработку данных: загрузка, подготовка, агрегация, предоставление доступа/выгрузка и т.д.
Хотя такое разбиение и обеспечивает некоторый уровень масштабирования, оно имеет и внутреннее ограничение, которое замедляет разработку новой функциональности на платформе: присутствует высокая связность между ступенями конвейера, что не позволяет обеспечить необходимую независимость работы отдельных команд.
Давайте вернёмся к нашему примеру с потоковым мультимедиа. Платформы потокового мультимедиа в Интернете имеют сильную доменную конструкцию вокруг типа мультимедиа, которое они предлагают. Они часто начинают свои сервисы с «песен» и «альбомов», а затем распространяются на «музыкальные события», «подкасты», «радиопостановки», «фильмы» и т. д. Включение одной новой функции, например, видимости для «podcasts play rate», требует изменения во всех компонентах конвейера. Командам необходимо разработать новые сервисы загрузки, очистки и подготовки данных (включая агрегирование), чтобы добавить видимость «podcasts play rate». Это требует синхронизации между релизами различных функциональных команд. Многие платформы данных используют основанные на конфигурации инструменты загрузки, которые могут легко справляться с такими задачами, как простое добавление новых источников или расширение существующих. Но это не устраняет необходимости сквозного управления релизами на всех этапах конвейера обработки данных. Для предоставления пользователям доступа к каким-либо новым данным, минимальная архитектурная единица, которая должна быть изменена – это весь конвейер. И это существенно ограничивает нашу способность повышать скорость и масштабирование развития платформы данных в ответ на появление новых источников данных и пользователей.
Третья проблема современных платформ данных связана с тем, как мы структурируем команды, которые создают и поддерживают платформу. Когда мы снизимся достаточно низко над архитектурой традиционной платформы данных, мы увидим группу узко специализированных data-инженеров, отделённых от тех подразделений организации, в которых данные создаются или используются для принятия решений. Инженеры платформы данных выделены в отдельные команды только на основе их технических компетенций и опыта работы с технологиями больших данных. Бизнес знания соответствующих предметных областей (бизнес-доменов) в таких командах отсутствуют.
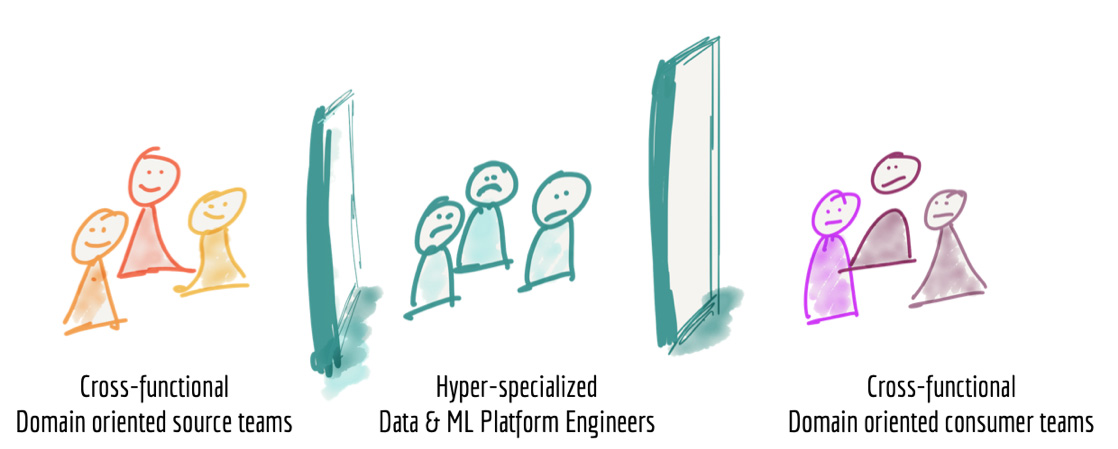
Рисунок 5: Разрозненные узко-специализированные команды платформы данных
Лично я не завидую жизни инженеров платформы данных. Они должны получать данные от команд, у которых нет никаких стимулов предоставлять качественные и корректные данные. У них отсутствует понимание бизнес-смысла тех данных, что приходится загружать. Они должны подготавливать данные для удовлетворения аналитических и операционных потребностей, без чёткого понимания конечного применения этих данных и без доступа к экспертам в области потребления этих данных.
Надо заметить, что мы ранее уже сталкивались с подобной проблемой разобщения команд. И смогли найти успешное решение этой проблемы.
В нашем примере с потоковой передачей мультимедиа у нас есть команда «медиаплеер», которая владеет данными о том, как пользователи взаимодействуют с плеером: прослушиваемые пользователями песни, совершаемые покупки, качество аудио прослушиваемых песен и т.п. С другой стороны есть команды потребителей соответствующих данных: команда разработки рекомендаций по песням; команда, контролирующая показатели продаж; команда оплаты артистам и т.д. А между ними грустная команда разработчиков платформы данных, которая ценой огромных усилий получает данные от одной команды и предоставляет доступ к ним (после предварительной обработки) всем потребителям.
В реальности мы имеем невовлечённые команды источников данных и фрустрированные команды потребителей данных, которым приходится бороться за место на вершине бэклога команды разработки платформы данных.
Мы создали архитектуру и организационную структуру, которая не обеспечивает необходимую масштабируемость и не в состоянии достигнуть поставленных целей построения data-driven организации.
И каково же решение тех проблем, которые мы обсуждали выше? На мой взгляд необходима смена парадигмы. Смена парадигмы на пересечении методов, которые сыграли важную роль в построении современной масштабируемой распределённой архитектуры и которые технологическая индустрия в целом внедрила ускоренными темпами. Методов, которые дали успешные результаты.
Я полагаю, что следующая архитектура платформы корпоративных данных заключается в объединении архитектуры распределённых доменов (Distributed Domain Driven Architecture), проектировании платформ самообслуживания и продуктовом мышлении в отношении данных.

Рисунок 6: Сдвиг парадигмы построения платформы данных следующего поколения.
Понимаю, что это может звучать как много модных слов в одном предложении, но каждый из этих компонентов оказал невероятно положительное влияние на изменение технических основ наших информационных систем. Давайте посмотрим, как мы можем применить каждую из этих дисциплин к миру данных, чтобы отойти от текущей парадигмы, перенесённой из многих лет построения хранилищ данных предыдущих поколений.
Книга Эрика Эванса «Domain-Driven Design» оказала глубокое влияние на современное архитектурное мышление и, тем самым, на организационное моделирование. Новая микросервисная архитектура декомпозировала информационные системы на распределённые сервисы, которые построены в границах конкретных бизнес-доменов. Это фундаментально изменило способ формирования команд: отныне команда может независимо и автономно владеть своими микросервисами.
Интересно, что мы игнорировали понятие бизнес-доменов в области данных. Ближайшее применение Domain Driven Design в архитектуре платформы данных: это появление Business Domain Events в информационных системах и загрузка их в монолитные платформы данных. Однако после того, как данные загружены в централизованное хранилище, концепция владения данных от разных бизнес-доменов разными командами теряется.
Чтобы децентрализовать монолитную платформу данных, необходимо изменить способ мышления о данных, об их местонахождении и о владении ими. Вместо того, чтобы передавать данные в Data Lake или платформу, домены должны хранить и обслуживать свои наборы данных в удобном для использования виде.
В нашем примере, вместо того, чтобы загружать данные из медиаплеера в централизованное хранилище для дальнейшей их обработки командой поддержки хранилища, почему бы не хранить и не обрабатывать эти наборы данных внутри домена и не предоставлять к ним доступ любой другой команде? Само место, где физически будут храниться эти наборы данных, может быть как угодно технически реализовано внутри домена. Безусловно можно использовать централизованную архитектуру, но сами данные из медиаплееров останутся под владением и поддержкой команды соответствующего домена, в котором эти данные и генерятся. Аналогично в нашем примере домен разработки рекомендаций по песням может создавать на основе данных из медиаплеера наборы данных в том формате, который лучше подходит для использования (например, в виде графовых структур). Если есть другие команды, которые считают такой формат удобным и полезным, они тоже могут получить доступ к нему.
Это, безусловно, подразумевает, что мы можем дублировать данные в разных доменах, когда мы меняем их формат на тот, который подходит конкретному потребителю.
Всё это требует сдвига нашего мышления от загрузки данных (через ETL или streaming) к масштабированию этого процесса на все домены. Архитектурный квантум в domain oriented платформе данных – это бизнес-домен, а не этап загрузки и преобразования данных.
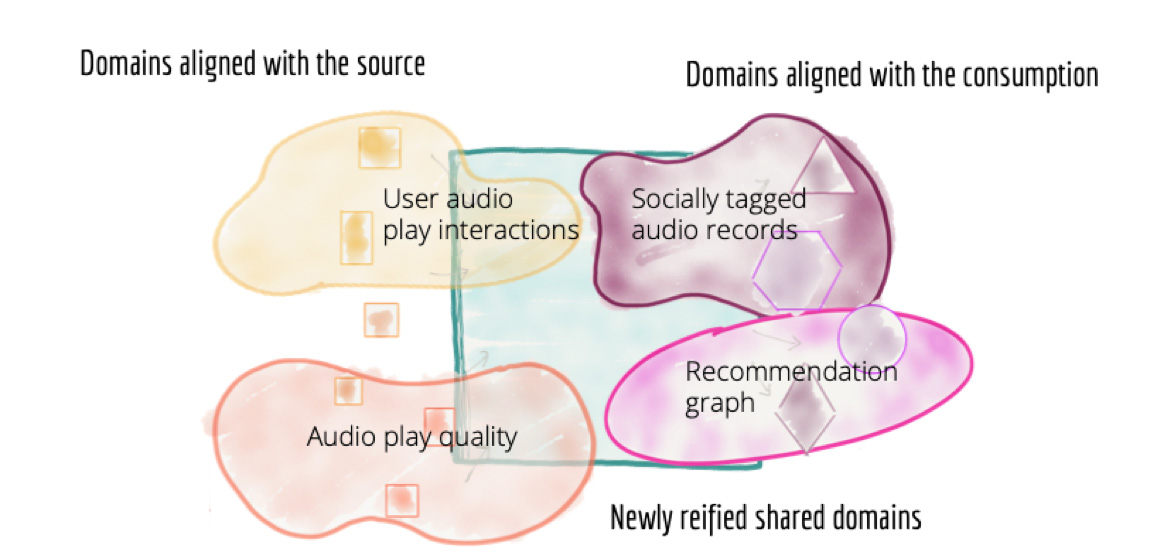
Рисунок 7: Декомпозиция архитектуры на основе бизнес-доменов и команд, владеющих данными.
Некоторые бизнес-домены хорошо выровнены с источниками данных (информационными системами). В идеальном случае информационная система и команда, сопровождающая её, не только отвечают за добавление и поддержку бизнес-функциональности, но и также предоставляют наборы данных (datasets), описывающие факты и реальность соответствующего бизнес-домена. Однако в масштабе крупной организации как правило отсутствует однозначное соответствие между бизнес-доменом и информационной системой. Как правило для каждого домена есть несколько информационных систем, которые автоматизируют разные бизнес процессы данного домена и, соответственно, хранят относящиеся к нему данные. Для таких доменов есть потребность интегрировать и агрегировать разрозненные данные, чтобы получить согласованные и выровненные по всему бизнес-домену наборы данных.
Лучший формат для хранения фактов, описывающих бизнес-домен – это Domain Events. Они могут хранится в виде распределённого лога событий с метками времени. К этому логу можно предоставлять доступ авторизованным потребителям.
В дополнение к таким логам, источники данных должны также предоставлять доступ к периодическим снимкам (snapshots) ключевых наборов данных своего домена. Агрегировать такие снимки стоит за тот интервал времени, который лучше отражает интервал изменений для своего домена (как правило это день/неделя/месяц/квартал и т.п.).
Обратите внимание, что подготовленные для потребителей наборы данных бизнес-домена должны быть отделены от внутренних наборов данных источников (которые информационные системы используют для своей работы). Они должны храниться в физически другом месте, подходящем для работы с большими данными. Далее будет описано как создать такое хранилище данных и обслуживающую инфраструктуру для него.
Доменные наборы данных, подготовленные для потребителей – это самые базовые элементы всей архитектуры. Они не трансформируются и не подгоняются под конкретного потребителя, а представляют собой сырые и необработанные данные.
Другие домены тесно связаны с потребителями данных. Наборы данных такого домена создают таким образом, чтобы они при их использовании подходили под связанный набор пользовательских сценариев. Такие наборы данных отличаются от наборов данных домена источника (source domain datasets). Это уже не сырые данные, а данные, пропущенные через несколько этапов трансформации. Структура этих наборов данных и их представление подогнаны под конкретные кейсы их использования. Т.е. это аналог специализированных витрин данных в централизованном хранилище. Для таких наборов данных домена потребителя (consumer domain datasets) должна быть предусмотрена возможность оперативного восстановления из сырых данных.
Владение данными в нашей новой архитектуре делегировано от центральной платформы к командам внутри бизнес-доменов, но потребности в очистке, подготовке и агрегации данных (использовании data pipeline) никуда не исчезают. Поэтому реализация собственного data pipeline становится внутренней задачей команды бизнес-домена. В результате мы получаем распределённые по всем доменам собственные доменные data pipelines.
К примеру, домены источники должны включать в себя очистку данных, удаление дублей, обогащение данных и т.п., чтобы другие домены могли использовать эти данные без предварительных обработок. Каждый такой набор данных должен соответствовать своему соглашению уровня обслуживания (Service Level Objective) в части качества данных.
Аналогично этапы построения специализированных витрин централизованного конвейера (pipeline) обработки данных переходят в собственные data pipelines доменов потребителей, которые строят consumer domain datasets.
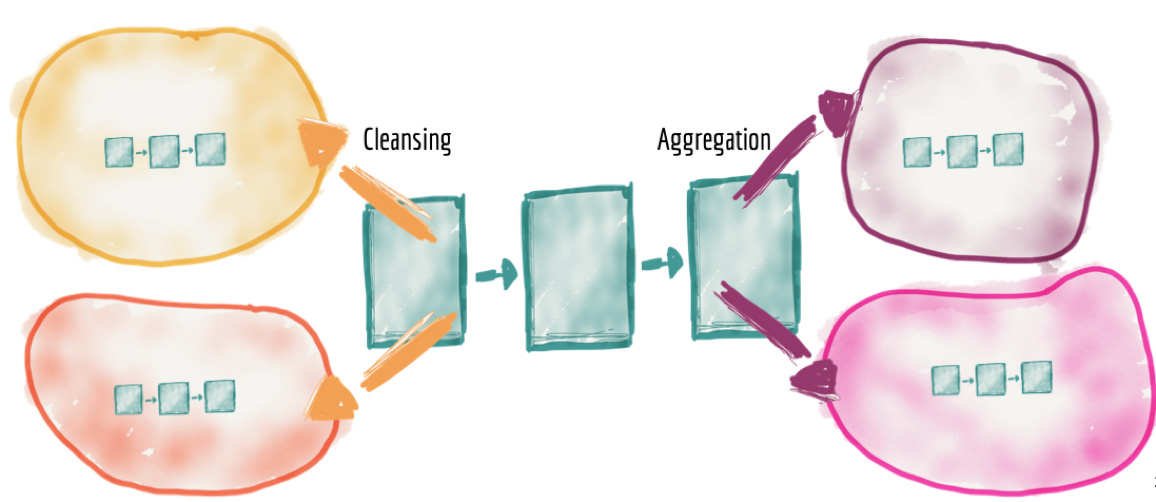
Рисунок 8: Распределённые конвейеры обработки данных, реализованные внутри своих доменов
Может показаться, что подобная модель приведёт к большому дублированию усилий в каждом домене для создания собственной реализации конвейера обработки данных. Мы поговорим об этой проблеме в разделе «централизованная инфраструктура данных как платформа».
Передача владения данными и ответственности за разработку и сопровождение конвейеров обработки данных на сторону бизнес-доменов может вызвать серьёзную озабоченность по поводу дальнейшей доступности и удобства использования таких распределённых наборов данных. Поэтому здесь нам пригодится продуктовое мышление в отношении данных.
За последние десять лет продуктовое мышление глубоко проникло в разработку информационных систем организаций и серьёзным образом трансформировало подход к этой разработке. Доменные команды разработки информационных систем предоставляют новые возможности в виде интерфейсов API, которые используются разработчиками в организациях как строительные блоки для создания функциональности более высокого порядка и более высокой ценности. Команды стремятся создать лучший опыт для пользователей своих API через понятную и детальную документацию, к которой пользователям легко получить доступ; тестовые среды; тщательно отслеживаемые показатели качества.
Чтобы распределённая платформа данных была успешной, data-команды бизнес-доменов должны применять продуктовое мышление по отношению к предоставляем наборам данных (datasets): воспринимать данные, которые они готовят, как продукт, а потребителей (аналитики, data scientists, data инженеры, ML специалисты и т.д.) как своих клиентов.
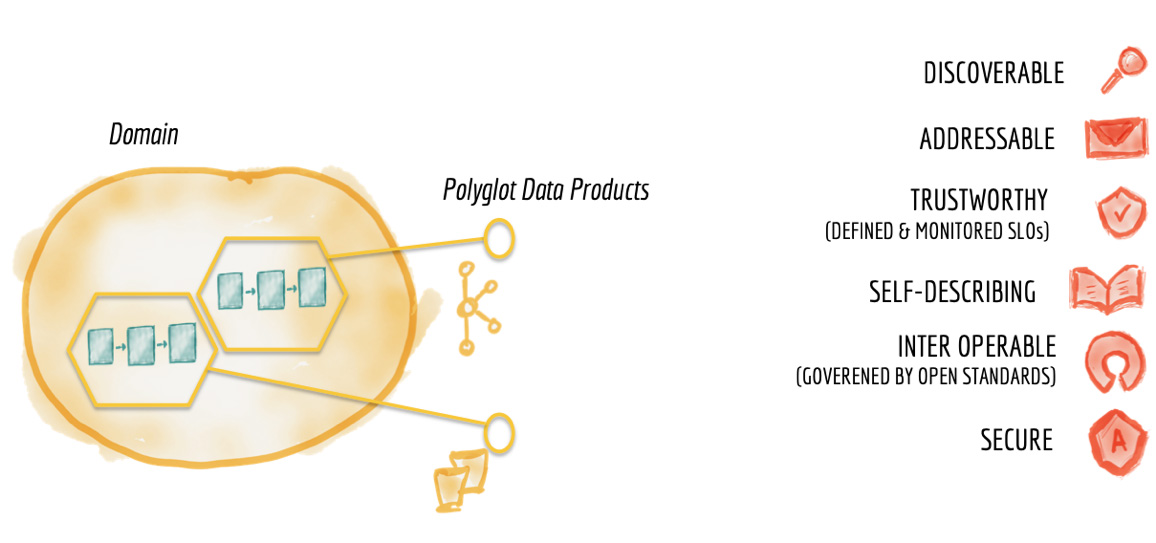
Рисунок 9: Характеристики доменных наборов данных как продуктов
Рассмотрим наш пример – потоковый медиа контент через интернет. Важнейший бизнес-домен – это история воспроизведения: кем, где, когда и какие песни были прослушаны. Это домен имеет разных ключевых потребителей данных внутри организации. Одним требуются данные в режиме, близком к реальному времени, для изучения пользовательского опыта и своевременном обнаружении любых проблем и ошибок воспроизведения. Другие заинтересованы в исторических снимках (snapshots), агрегированные по дням или месяцам. Поэтому наш домен предоставляет данные в двух форматах: события воспроизведения в потоковом виде (streaming, топик в kafka или типа того) и агрегированные события воспроизведения в пакетном формате (файл, таблица в hive и т.п.).
Чтобы обеспечить лучший пользовательский опыт для потребителей, data-продукты бизнес-домена должны обладать следующими ключевыми характеристиками.
Необходимо обеспечить условия, при которых любой data-продукт можно легко найти. Самой распространённой реализацией этого требования является наличие реестра – каталога всех доступных data-продуктов с необходимой метаинформацией (такой, как владельцы, источники происхождения, образцы наборов данных, частота обновления, структура наборов данных и т.п.). Такой централизованный сервис позволяет потребителям данных легко находить интересующий их набор данных. Каждый data-продукт от любого бизнес-домена должен быть зарегистрирован в централизованном каталоге данных.
Обратите внимание, что здесь присутствует сдвиг от единой централизованной платформы, владеющей всеми данными, к распределённым data-продуктам разных бизнес-доменов, которые зарегистрированы в едином каталоге данных.
Каждый data-продукт должен иметь уникальный адрес (в соответствии с глобальным соглашением), который позволит его потребителям получить программный доступ к нему. Организации могут принять различные соглашения о наименовании data-продуктов и их расположении, в зависимости от доступных способов физического хранения данных и форматов самих данных. Для распределённой децентрализованной архитектуры такие общие соглашения являются необходимыми. Стандарты адреса наборов данных устранят трения при поиске и доступе к data-продуктам.
Никто не будет использовать продукт, который не вызывает доверия. В платформах данных текущего поколения повсеместно распространена загрузка и публикация данных, содержащих ошибки и не отражающих всей бизнес-правды, т.е. данных, которым нельзя доверять. Именно в этой части сосредоточено значительное количество ETL джобов, которые очищают данные после загрузки.
Новая архитектура требует от владельцев data-продуктов принятия SLO (Service Level Objective) в отношении точности, достоверности и актуальности данных. Для обеспечения приемлемого качества необходимо использовать такие методы, как очистка данных и автоматическое тестирование целостности данных на этапе создания data-продукта. Информация о происхождении данных (data lineage) в метаданных каждого data-продукта даёт потребителям дополнительную уверенность в самом продукте и его пригодности для конкретных потребностей.
Целевое значение показателя качества данных (либо допустимый диапазон) варьируются в зависимости от data-продукта конкретного бизнес-домена. Например, домен «события воспроизведения» может предоставлять два разных продукта: один в режиме, близком к реальному времени, с более низким уровнем точности (включая пропущенные или повторяющиеся события); и второй с более длинной задержкой и более высоким уровнем качества данных. Каждый data-продукт определяет и поддерживает целевой уровень целостности и достоверности своих данных в виде набора SLO (Service Level Objective).
Качественные продукты должны быть легки в использовании. Создание data-продуктов максимально простых в использовании аналитиками, инженерами и data scientists требует наличия хорошо описанной семантики и синтаксиса данных. В идеале сопровождаемых образцами наборов данных в качестве примеров.
Одной из основных проблем в распределённой domain driven архитектуре данных является необходимость интегрировать данные из разных доменов. Ключом к лёгкой и эффективной интеграции данных между доменами является определение и соблюдение правил и стандартов. Такие стандарты должны определяться на уровне всей организации. Стандартизация требуется в области определения допустимых типов данных и правил их применения, соглашений о наименованиях и адресах data-продуктов, форматов метаданных и т.п.
По тем сущностям, которые могут хранится в разном виде и с разным набором атрибутов в разных доменах, необходимо реализовывать практики Master Data Management. Присваивать им глобальные идентификаторы и выравнивать набор и, главное, значения атрибутов среди всех доменов.
Обеспечение функциональной совместимости данных для их эффективной интеграции, а также определение стандартов хранения и представления data-продуктов на уровне всей организации являются одним из основополагающих принципов построения подобных распределённых систем.
Обеспечение безопасного доступа к данным является обязательным фактором, независимо от того, является ли архитектура централизованной или нет. В мире децентрализованных data-продуктов, ориентированных на бизнес-домен, управление доступом возможно (и должно применяться) с более высокой степенью детализации для каждого набора данных. Политики контроля доступа к данным могут быть определены централизованно, но реализуются отдельно для каждого data-продукта. В качестве удобного способа реализации контроля доступа к наборам данных может быть использование системы Enterprise Identity Management и управление доступом на основе ролей.
Далее будет описана единая инфраструктура, которая позволяет легко и автоматически реализовать вышеуказанные возможности для каждого продукта данных.
В командах, предоставляющих данные в виде data-продуктов, должны быть представлены следующие роли: владелец data-продукта и data-инженер.
Владелец data-продукта отвечает за концепцию и дорожную карту, жизненный цикл своих продуктов. Меряет удовлетворённость своих потребителей и постоянно измеряет и улучшает качество данных своего бизнес-домена. Наполняет и балансирует бэклог своих data-продуктов требованиями, поступающими от потребителей данных.
Также владельцы data-продуктов должны определить ключевые метрики и показатели эффективности (KPI) для своих продуктов. К примеру, время, необходимое для ознакомления и начала использования пользователем data-продукта, может быть одной из таких метрик.
Для того, чтобы создавать и сопровождать свои собственные конвейеры данных (data pipelines) внутри бизнес-домена, команда должна включать в себя data-инженеров. Хорошим побочным эффектом от этого будет распространение соответствующих навыков внутри бизнес-домена. По моим наблюдениям в настоящий момент некоторым data-инженерам, хотя и компетентным в использовании своих инструментов и технологий, не хватает знания стандартных практик разработки программного обеспечения, когда речь идёт о создании data-продуктов. В первую очередь таких DevOps практик, как continuous delivery и автоматическое тестирование. С другой стороны разработчики программного обеспечения, которые развивают информационные системы, часто не имеют достаточного опыта и знаний в области технологий и инструментов для работы с данными как с продуктом. Объединение их в многофункциональные команды в рамках бизнес-домена приведёт к появлению специалистов более широкого профиля. Что-то подобное мы наблюдали при развитии DevOps, когда появились новые типы инженеров, такие как SRE.
Рисунок 10: Кросс функциональная доменная data-команда
Одним из чувствительных моментов распределённой domain driven архитектуры платформы данных является необходимость дублирования в каждом домене усилий и навыков, необходимых для работы инфраструктуры и технологического стека, используемого в конвейерах данных (data pipelines). К счастью, создание общей инфраструктуры как платформы – задача, которую хорошо научились решать в IT (но не в области работы с данными).
Команда инфраструктуры данных должна владеть и предоставлять как сервис инструменты, необходимые бизнес-доменам для сбора, обработки и хранения своих data-продуктов.
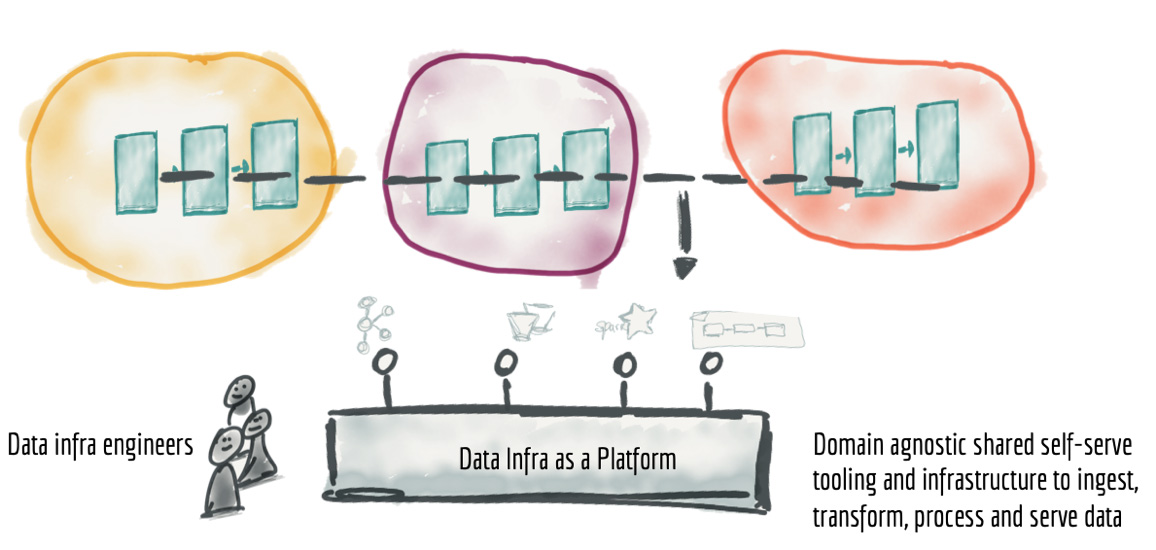
Рисунок 11: Инфраструктура данных как платформа
Инфраструктура данных как платформа должна быть свободна от каких-либо доменно-специфичных концепций или бизнес-логики. Также платформа должна скрывать от пользователей всю сложность своей реализации и предоставлять максимальный объём своего функционала для использования в режиме самообслуживания. Вот список некоторых возможностей, которые должна предоставлять такая централизованная инфраструктура данных как платформа:
При создании централизованной инфраструктуры данных необходимо стремится к тому, чтобы создание data-продукта на такой инфраструктуре занимало как можно меньше времени. Поэтому очень важным является максимальная автоматизация ключевого функционала, как то: возможность загрузки данных с помощью простых конфигураций, автоматическая регистрация data-продукта в каталоге данных и т.д. Использование облачной инфраструктуры может снизить эксплуатационные расходы и повысить скорость предоставления доступа к инфраструктуре данных по требованию.
Это было долгое чтение! Давайте немного резюмируем всё то, что написано выше. Мы рассмотрели некоторые ключевые характеристики современных платформ данных: централизованные, монолитные, сложные data pipelines (c сотнями и тысячами джобов, тесно связанных друг с другом), разрозненные узко-специализированные команды. После поговорили про новый подход data mesh, включающий в себя распределённые data-продукты ориентированные на бизнес-домены, управляемые межфункциональными командами (с владельцами data-продуктов и data-инженерами), использующие общую инфраструктуру данных в качестве платформы для размещения.
Data Mesh представляет собой распределённую архитектуру, с централизованным управлением и разработанными стандартами, обеспечивающими интегрируемость данных, и с централизованной инфраструктурой, предоставляющей возможность использования в режиме самообслуживания. Я надеюсь читателю достаточно очевидно, что такая архитектура очень далека от набора слабосвязанных хранилищ недоступных данных, независимо разрабатываемых в разных подразделениях.
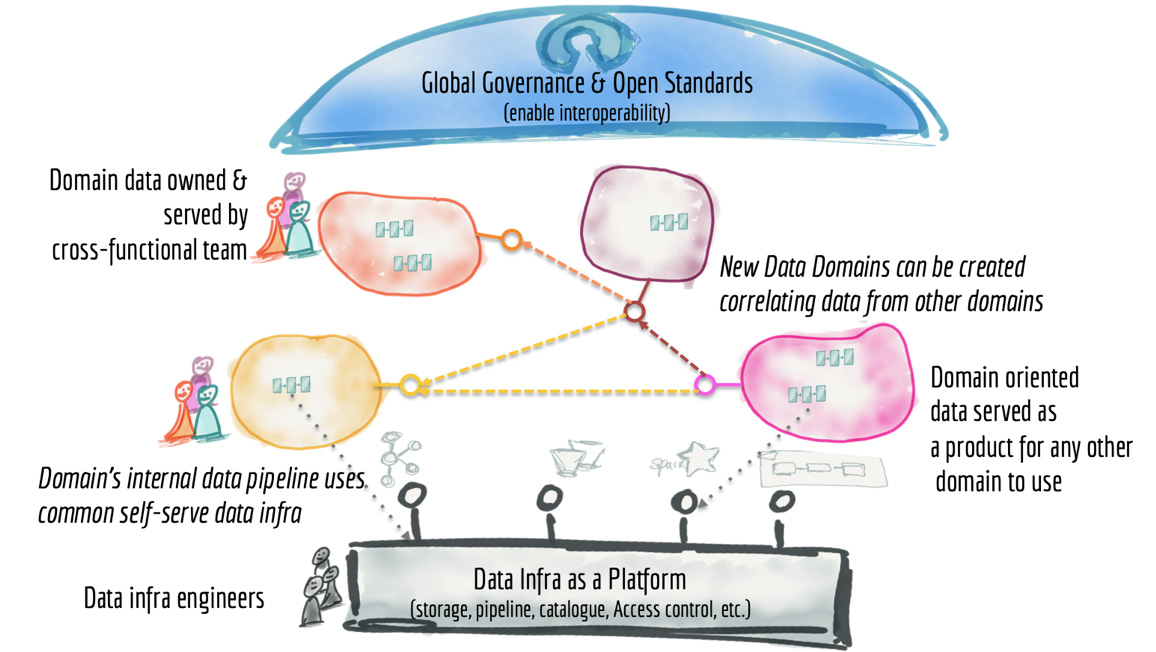
Рисунок 12: Архитектура Data Mesh с высоты 10 000 метров
Вы можете спросить: а как Data Lake или хранилище данных (Data Warehouse) вписываются в эту архитектуру? Они просто являются отдельными узлами (доменами) в этой распределённой архитектуре. Есть высокая вероятность, что в подобной архитектуре нам больше не понадобится Data Lake. Ведь нам будут доступны для исследования оригинальные данные разных бизнес-доменов, оформленные в виде data-продуктов.
Соответственно, Data Lake больше не является центральным элементов всей архитектуры. Но технологии и инструменты, используемые при построении Data Lake, мы продолжим применять либо для создания общей инфраструктуры данных, либо для внутренней реализации наших data-продуктов.
Это фактически возвращает нас к тому, с чего всё начиналось. Джеймс Диксон в 2010 году намеревался использовать Data Lake для одного бизнес-домена, а несколько доменов данных образовывали бы Water Garden.
Основной сдвиг парадигмы заключается в том, чтобы рассматривать data-продукт бизнес-домена как задачу первого приоритета, а инструментальные средства и технологии – как задачу второго приоритета (как деталь реализации). Это уводить ментальную модель от централизованного Data Lake в экосистему data-продуктов, которые просто и эффективно интегрируются друг с другом.
Пару слов по поводу отчётности и визуализации (применение BI инструментов и т.п.). В отношении них применяется такой же принцип: в этой архитектуре они являются отдельными узлами. Т.е. это независимые data-продукты внутри какого-либо бизнес-домена, ориентированные прежде всего на потребителя, а не на источник данных.
Я признаю, что хотя и вижу успешное применение принципов Data Mesh моими клиентами, масштабированию этих принципов в крупных организациях предстоит пройти долгий путь. Но очевидно, что технологии не являются здесь ограничением. Все те инструменты, которые мы используем сегодня, могут с тем же успехом применяться для распределения и владения data-продуктами разными командами. В частности, переход к стандартизации пакетных и потоковых джобов обработки данных, а также использование инструментов вроде Apache Beam или Google Cloud DataFlow, позволяет легко обрабатывать разнообразные наборы данных с уникальными адресами.
Платформы каталогов данных, такие как Google Cloud Data Catalog, обеспечивают легкость обнаружения, контроль доступа и централизованное управление наборами данных распределённых бизнес-доменов. Большое количество облачных платформ позволяет бизнес-доменам выбирать подходящие для целевого хранения своих data-продуктов.
Необходимость смены парадигмы очевидна. Все необходимые технологии и инструменты для этого есть. Руководители организаций и профессионалы в области обработки данных должны признать, что существующая парадигма больших данных и подход с одной большой платформой Data Lake только повторит неудачи прошлого, используя при этом новые облачные технологии и инструменты.
Давайте же перейдём от централизованной монолитной платформы данных к экосистеме data-продуктов.

Все крупные компании сейчас пытаются строить огромные централизованные хранилища данных. Или же ещё более огромные кластерные Data Lakes (как правило, на хадупе). Но мне не известно ни одного примера успешного построения такой платформы данных. Везде это боль и страдание как для тех, кто строит платформу данных, так и для пользователей. В статье ниже автор (Жамак Дегани) предлагает совершенно новый подход к построению платформы данных. Это архитектура платформы данных четвертого поколения, которая называется Data Mesh. Оригинальная статья на английском весьма объёмна и откровенно тяжело читается. Перевод так же получился немаленьким и текст не очень прост: длинные предложения, суховатая лексика. Я не стал переформулировать мысли автора, дабы сохранить точность формулировок. Но я крайне рекомендую таки продраться через этот непростой текст и ознакомиться со статьёй. Для тех, кто занимается данными, это будет очень полезно и весьма интересно.
Евгений Черный
Немало компаний инвестируют в следующее поколение Data Lake с надеждой упростить доступ к данным в масштабе всей компании и предоставить бизнесу инсайты и возможность принимать качественные решения автоматически. Но текущие подходы к построению платформ данных имеют схожие проблемы, которые не позволяют достигнуть поставленных целей. Чтобы решить эти проблемы нам необходимо отказаться от парадигмы централизованного Data Lake (или его предшественника – хранилища данных). И перейти к парадигме, основанной на современной распределённой архитектуре: рассматривать бизнес-домены как приоритет первого уровня, применять платформенное мышление для создания инфраструктуры с возможностью самообслуживания и воспринимать данные как продукт.
Содержание
- Текущая архитектура платформы данных в крупной компании
- Проблемные архитектурные подходы
- Централизованное и монолитное
- Декомпозиция конвейера с высокой связностью
- Разрозненные и узко специализированные команды
- Проблемные архитектурные подходы
- Архитектура следующего поколения платформы данных
- Данные и распределённая domain driven архитектура
- Декомпозиция и владение данными на основе ориентации на бизнес-домены
- Ориентация на источник данных
- Ориентация на потребителя данных
- Распределённые конвейеры обработки данных (data pipelines), реализованные внутри своих доменов
- Данные и продуктовое мышление
- Доменные данные как продукт
- Удобство и легкость обнаружения (discoverable)
- Наличие уникального адреса (addressable)
- Качество данных
- Понятное описание семантики и синтаксиса данных
- Интегрируемость данных и стандарты, определяемые на уровне всей организации
- Безопасность данных и контроль доступа к ним
- Доменные данные как продукт
- Кросс функциональная data-команда бизнес-домена
- Централизованная инфраструктура данных как платформа
- Данные и распределённая domain driven архитектура
- Сдвиг парадигмы в сторону Data Mesh
Построение data-driven организации остаётся одной из главных стратегических целей многих компаний, с которыми я работаю. Мои клиенты хорошо знают о преимуществах принятия решений на основе качественных данных: обеспечение высочайшего качества обслуживания клиентов, гипер персонализация, сокращение операционных расходов и сроков за счёт оптимизации, предоставление сотрудникам инструментов анализа и бизнес-аналитики. Они вкладывают значительные средства в создание современных платформ данных. Но несмотря на растущие усилия и инвестиции в создание таких платформ, многие организации считают результаты посредственными.
Организации сталкиваются со многими сложностями в процессе трансформации в data-driven компании: миграция от разрабатываемых годы и десятилетия legacy систем, сопротивление со стороны сложившейся культуры и высокая конкуренция между разными бизнес-приоритетами. Как бы то ни было, я хочу поделиться с вами архитектурным подходом, который учитывает причины провала многих инициатив в области построения платформ данных. Я продемонстрирую как мы можем адаптировать и применить в области данных уроки прошлого десятилетия в построении распределённых архитектур. Этот новый архитектурный подход мною назван Data Mesh.
Прежде чем читать дальше, я прошу вас на время прочтения статьи постараться отказаться от предубеждений, которые заложила текущая парадигма традиционной архитектуры платформы данных. Будьте открыты к возможности перехода от централизованных Data Lakes к намеренно распределённой Data Mesh архитектуре. Примите, что данные по своей природе распределены и вездесущи.
Текущая архитектура платформы данных в крупной компании
Поговорим про централизованное, монолитное и независимое от бизнес смысла данных Data Lake.
Практически каждый клиент, с которым я работаю, или планирует, или уже строит свою платформу данных третьего поколения. Признавая при этом ошибки предыдущих поколений.
- Первое поколение: проприетарные корпоративные хранилища данных и платформы бизнес-аналитики. Это решения за большие суммы денег, которые оставили компаниям столь же большие объёмы технического долга. Технический долг в тысячах неподдерживаемых ETL джобов, таблиц и отчетов, которые понимает только небольшая группа специалистов, что приводит к недооценке положительного влияния этого функционала на бизнес.
- Второе поколение: экосистемы больших данных (Big Data) с Data Lake в качестве серебряной пули. Сложная экосистема больших данных и долго отрабатывающие batch джобы, поддерживаемые центральной командой узко-специализированных data-инженеров. В лучшем случае используется для R&D аналитики.
Платформы данных третьего поколения более или менее похожи на предыдущие поколения, но с уклоном в сторону
- потоковой передачи(streaming) для обеспечения доступности данных в реальном времени с архитектурой вроде Kappa,
- объединения пакетной и потоковой обработки для трансформации данных с использованием таких фреймворков, как Apache Beam,
- использования облачных сервисов для хранения и обработки данных и облачных Machine Learning платформ.
Платформа данных третьего поколения устраняет некоторые проблемы предыдущих поколений, такие как анализ данных в реальном времени, а также снижает затраты на управление инфраструктурой больших данных. Однако до сих пор сохраняются многие лежащие в основе подхода особенности, которые привели к неудачам предыдущих поколений.
Рисунок 1: Три поколения платформ данных
Проблемные архитектурные подходы
Чтобы раскрыть основные ограничения, которые несут в себе все поколения платформ данных, давайте посмотрим на их архитектуру и характеристики. В этой статье я буду использовать бизнес потокового интернет-медиа (как Spotify, SoundCloud, Apple iTunes) в качестве примера для пояснения некоторых концепций.
Централизованное и монолитное
С высоты 10 000 метров архитектура платформы данных выглядит как на рисунке 2 ниже.
Рисунок 2: Вид с высоты 10 000 метров на монолитную платформу данных
Центральная часть архитектуры отвечает за:
- Сбор (to ingest) данных со всей организации от транзакционных систем, отвечающих за операционную поддержку бизнеса, до данных от внешних поставщиков. Например, в сфере потокового мультимедиа платформа данных обеспечивает загрузку таких данных, как: производительность медиа плееров; особенности пользовательского взаимодействия с плеерами; прослушиваемые песни; артисты, на которых пользователи подписаны; финансовые транзакции с поставщиками контента и данные исследования рынка внешними компаниями (демографическая информация о клиентах и т.п.).
- Очистка, обогащение и преобразование данных, загруженных из источников в тот формат достоверных данных, которые могут использовать различные группы потребителей. В нашем примере, одним из таких процессов трансформации данных могло бы быть преобразование отдельных кликов пользовательского взаимодействия в пользовательские сессии, обогащённые данными о пользователях — чтобы представить пользовательский опыт в виде агрегированных представлений.
- Предоставление доступа (to serve) к наборам данным конечным пользователям. Реализация пользовательских потребностей в интервале от аналитики и machine learning до BI отчетов. В нашем примере потокового мультимедиа, это может быть предоставление доступа в режиме реального времени к информации о дефектах и качестве работы медиа плееров по всему миру. Работать такой доступ может через распределённые интерфейсы, такие как Kafka.
По-умолчанию общепринятым соглашением является тот факт, что монолитная Data Platform хранит и владеет данными, которые принадлежат разным бизнес-доменам. К примеру, 'play events', 'sales KPIs', 'artists', 'albums', 'labels', 'audio', 'podcasts', 'music events' и т.д. — данные из большого количества разрозненных доменов.
Несмотря на то, что в последнее десятилетие мы успешно применяли концепцию Domain Driven Design (и ключевой её паттерн Bounded Context) к проектированию наших информационных систем, мы в значительной степени игнорировали эти концепции при проектировании платформ данных. Мы перешли от владения данными на уровне бизнес-домена к владению данными независимо от бизнес-доменов. Мы гордимся тем, что создали самый большой монолит – Big Data Platform.
Рисунок 3: Централизованная платформа данных без чётких границ между данными разных бизнес-доменов. И без владения соответствующими данными со стороны бизнес-домена
Такая централизованная модель может работать для небольших организаций, у которых простые бизнес-домены и ограниченные варианты потребления данных. Но она не подходит для больших компаний с крупными и сложными бизнес-доменами, большим количеством источников данных и разнообразными потребностями в работе с данными со стороны потребителей.
Есть два слабых звена в архитектуре и структуре централизованной платформы данных, которые часто приводят к неудаче в процессе её построения:
- Большое количество источников и большие объёмы данных. Чем больше данных становятся доступными повсеместно, тем меньше наши способности собирать, согласовывать и контролировать их в рамках одной платформы. К примеру, касательно клиентской информации появляется всё больше источников внутри и за пределами организаций. Они предоставляют разнообразную информацию о существующих и потенциальных клиентах. Подход, при котором нам нужно собирать и хранить данные в одном месте, чтобы получить ценность из интеграции различных источников, ограничит нашу способность реагировать на появление новых источников данных. Поймите меня правильно, я осознаю потребность аналитиков и data scientists обрабатывать разнообразные наборы данных с минимальными издержками и с возможностью интеграции их. Также понятно, что данные наших информационных систем (обслуживающие операционные потребности бизнеса) следует отделять от данных, используемых в аналитических целях. Но я предполагаю, что существующие решения централизованных хранилищ данных – не самый оптимальных вариант для крупных предприятий с большим количеством бизнес-доменов и постоянно появляющимися новыми источниками данных.
- Потребности организаций в инновациях. Необходимость в быстрой проверке гипотез и частых экспериментах ведёт к большому количеству вариантов использования данных. Это подразумевает постоянно растущее количество трансформаций в данных, которые необходимо реализовывать на наших централизованных платформах данных. Долгое время реализации потребностей пользователей исторически являлось точкой организационных трений и остаётся таковым при текущей архитектуре платформы данных.
Здесь мне нужно уточнить, что я не высказываюсь в пользу использования фрагментированных, разрозненных данных, скрытых в недрах легаси систем. Таких данных, которые трудно обнаружить, понять и использовать. Я также не поддерживаю многочисленные разрозненные хранилища данных в рамках одной организации, которые являются результатом многолетнего накопленного технического долга. Но я утверждаю, что ответом на такие недоступные фрагментированные данные не является создание централизованной платформы данных с централизованной же командой, которая хранит и владеет данными из всех бизнес-доменов.
Такой подход не масштабируется в крупных организациях, как уже показано выше.
Декомпозиция конвейера с высокой связностью
Рисунок 4: Архитектурная декомпозиция платформы данных
Вторая проблема традиционной архитектуры платформы данных связана с тем, как мы декомпозируем архитектуру. Если снизится до 3 000 метров над архитектурой платформы данных, мы обнаружим архитектурную декомпозицию вокруг функций загрузки, очистки, агрегирования, обслуживания данных и т.д. Как описано в предыдущем разделе, потребность в подключении новых источников и новых потребителей требует роста платформы. Архитекторы должны найти способ масштабирования системы, разбив её на архитектурные кванты. Архитектурный квант, как описано в книге “Building Evolutionary Architectures”, представляет собой независимо развёртываемый компонент с высокой функциональной связностью, который включает в себя все структурные элементы, необходимые для правильной работы системы. Мотивация разделения системы на архитектурные кванты в первую очередь состоит в создании независимых команд, каждая из которых создаёт и поддерживает свой архитектурных квант (функциональную подсистему). Это позволяет распараллелить работу и повысить скорость и операционную масштабируемость.
Под влиянием предыдущих поколений платформ данных, архитекторы разделяют платформу на последовательность этапов обработки данных. Это представляет собой конвейер (pipeline), который реализует обработку данных: загрузка, подготовка, агрегация, предоставление доступа/выгрузка и т.д.
Хотя такое разбиение и обеспечивает некоторый уровень масштабирования, оно имеет и внутреннее ограничение, которое замедляет разработку новой функциональности на платформе: присутствует высокая связность между ступенями конвейера, что не позволяет обеспечить необходимую независимость работы отдельных команд.
Давайте вернёмся к нашему примеру с потоковым мультимедиа. Платформы потокового мультимедиа в Интернете имеют сильную доменную конструкцию вокруг типа мультимедиа, которое они предлагают. Они часто начинают свои сервисы с «песен» и «альбомов», а затем распространяются на «музыкальные события», «подкасты», «радиопостановки», «фильмы» и т. д. Включение одной новой функции, например, видимости для «podcasts play rate», требует изменения во всех компонентах конвейера. Командам необходимо разработать новые сервисы загрузки, очистки и подготовки данных (включая агрегирование), чтобы добавить видимость «podcasts play rate». Это требует синхронизации между релизами различных функциональных команд. Многие платформы данных используют основанные на конфигурации инструменты загрузки, которые могут легко справляться с такими задачами, как простое добавление новых источников или расширение существующих. Но это не устраняет необходимости сквозного управления релизами на всех этапах конвейера обработки данных. Для предоставления пользователям доступа к каким-либо новым данным, минимальная архитектурная единица, которая должна быть изменена – это весь конвейер. И это существенно ограничивает нашу способность повышать скорость и масштабирование развития платформы данных в ответ на появление новых источников данных и пользователей.
Разрозненные и узко специализированные команды
Третья проблема современных платформ данных связана с тем, как мы структурируем команды, которые создают и поддерживают платформу. Когда мы снизимся достаточно низко над архитектурой традиционной платформы данных, мы увидим группу узко специализированных data-инженеров, отделённых от тех подразделений организации, в которых данные создаются или используются для принятия решений. Инженеры платформы данных выделены в отдельные команды только на основе их технических компетенций и опыта работы с технологиями больших данных. Бизнес знания соответствующих предметных областей (бизнес-доменов) в таких командах отсутствуют.
Рисунок 5: Разрозненные узко-специализированные команды платформы данных
Лично я не завидую жизни инженеров платформы данных. Они должны получать данные от команд, у которых нет никаких стимулов предоставлять качественные и корректные данные. У них отсутствует понимание бизнес-смысла тех данных, что приходится загружать. Они должны подготавливать данные для удовлетворения аналитических и операционных потребностей, без чёткого понимания конечного применения этих данных и без доступа к экспертам в области потребления этих данных.
Надо заметить, что мы ранее уже сталкивались с подобной проблемой разобщения команд. И смогли найти успешное решение этой проблемы.
В нашем примере с потоковой передачей мультимедиа у нас есть команда «медиаплеер», которая владеет данными о том, как пользователи взаимодействуют с плеером: прослушиваемые пользователями песни, совершаемые покупки, качество аудио прослушиваемых песен и т.п. С другой стороны есть команды потребителей соответствующих данных: команда разработки рекомендаций по песням; команда, контролирующая показатели продаж; команда оплаты артистам и т.д. А между ними грустная команда разработчиков платформы данных, которая ценой огромных усилий получает данные от одной команды и предоставляет доступ к ним (после предварительной обработки) всем потребителям.
В реальности мы имеем невовлечённые команды источников данных и фрустрированные команды потребителей данных, которым приходится бороться за место на вершине бэклога команды разработки платформы данных.
Мы создали архитектуру и организационную структуру, которая не обеспечивает необходимую масштабируемость и не в состоянии достигнуть поставленных целей построения data-driven организации.
Архитектура следующего поколения платформы данных
И каково же решение тех проблем, которые мы обсуждали выше? На мой взгляд необходима смена парадигмы. Смена парадигмы на пересечении методов, которые сыграли важную роль в построении современной масштабируемой распределённой архитектуры и которые технологическая индустрия в целом внедрила ускоренными темпами. Методов, которые дали успешные результаты.
Я полагаю, что следующая архитектура платформы корпоративных данных заключается в объединении архитектуры распределённых доменов (Distributed Domain Driven Architecture), проектировании платформ самообслуживания и продуктовом мышлении в отношении данных.
Рисунок 6: Сдвиг парадигмы построения платформы данных следующего поколения.
Понимаю, что это может звучать как много модных слов в одном предложении, но каждый из этих компонентов оказал невероятно положительное влияние на изменение технических основ наших информационных систем. Давайте посмотрим, как мы можем применить каждую из этих дисциплин к миру данных, чтобы отойти от текущей парадигмы, перенесённой из многих лет построения хранилищ данных предыдущих поколений.
Данные и распределённая domain driven архитектура
Декомпозиция и владение данными на основе ориентации на бизнес-домены
Книга Эрика Эванса «Domain-Driven Design» оказала глубокое влияние на современное архитектурное мышление и, тем самым, на организационное моделирование. Новая микросервисная архитектура декомпозировала информационные системы на распределённые сервисы, которые построены в границах конкретных бизнес-доменов. Это фундаментально изменило способ формирования команд: отныне команда может независимо и автономно владеть своими микросервисами.
Интересно, что мы игнорировали понятие бизнес-доменов в области данных. Ближайшее применение Domain Driven Design в архитектуре платформы данных: это появление Business Domain Events в информационных системах и загрузка их в монолитные платформы данных. Однако после того, как данные загружены в централизованное хранилище, концепция владения данных от разных бизнес-доменов разными командами теряется.
Чтобы децентрализовать монолитную платформу данных, необходимо изменить способ мышления о данных, об их местонахождении и о владении ими. Вместо того, чтобы передавать данные в Data Lake или платформу, домены должны хранить и обслуживать свои наборы данных в удобном для использования виде.
В нашем примере, вместо того, чтобы загружать данные из медиаплеера в централизованное хранилище для дальнейшей их обработки командой поддержки хранилища, почему бы не хранить и не обрабатывать эти наборы данных внутри домена и не предоставлять к ним доступ любой другой команде? Само место, где физически будут храниться эти наборы данных, может быть как угодно технически реализовано внутри домена. Безусловно можно использовать централизованную архитектуру, но сами данные из медиаплееров останутся под владением и поддержкой команды соответствующего домена, в котором эти данные и генерятся. Аналогично в нашем примере домен разработки рекомендаций по песням может создавать на основе данных из медиаплеера наборы данных в том формате, который лучше подходит для использования (например, в виде графовых структур). Если есть другие команды, которые считают такой формат удобным и полезным, они тоже могут получить доступ к нему.
Это, безусловно, подразумевает, что мы можем дублировать данные в разных доменах, когда мы меняем их формат на тот, который подходит конкретному потребителю.
Всё это требует сдвига нашего мышления от загрузки данных (через ETL или streaming) к масштабированию этого процесса на все домены. Архитектурный квантум в domain oriented платформе данных – это бизнес-домен, а не этап загрузки и преобразования данных.
Рисунок 7: Декомпозиция архитектуры на основе бизнес-доменов и команд, владеющих данными.
Наборы данных домена источника (source domain datasets)
Некоторые бизнес-домены хорошо выровнены с источниками данных (информационными системами). В идеальном случае информационная система и команда, сопровождающая её, не только отвечают за добавление и поддержку бизнес-функциональности, но и также предоставляют наборы данных (datasets), описывающие факты и реальность соответствующего бизнес-домена. Однако в масштабе крупной организации как правило отсутствует однозначное соответствие между бизнес-доменом и информационной системой. Как правило для каждого домена есть несколько информационных систем, которые автоматизируют разные бизнес процессы данного домена и, соответственно, хранят относящиеся к нему данные. Для таких доменов есть потребность интегрировать и агрегировать разрозненные данные, чтобы получить согласованные и выровненные по всему бизнес-домену наборы данных.
Лучший формат для хранения фактов, описывающих бизнес-домен – это Domain Events. Они могут хранится в виде распределённого лога событий с метками времени. К этому логу можно предоставлять доступ авторизованным потребителям.
В дополнение к таким логам, источники данных должны также предоставлять доступ к периодическим снимкам (snapshots) ключевых наборов данных своего домена. Агрегировать такие снимки стоит за тот интервал времени, который лучше отражает интервал изменений для своего домена (как правило это день/неделя/месяц/квартал и т.п.).
Обратите внимание, что подготовленные для потребителей наборы данных бизнес-домена должны быть отделены от внутренних наборов данных источников (которые информационные системы используют для своей работы). Они должны храниться в физически другом месте, подходящем для работы с большими данными. Далее будет описано как создать такое хранилище данных и обслуживающую инфраструктуру для него.
Доменные наборы данных, подготовленные для потребителей – это самые базовые элементы всей архитектуры. Они не трансформируются и не подгоняются под конкретного потребителя, а представляют собой сырые и необработанные данные.
Наборы данных домена потребителя (consumer domain datasets)
Другие домены тесно связаны с потребителями данных. Наборы данных такого домена создают таким образом, чтобы они при их использовании подходили под связанный набор пользовательских сценариев. Такие наборы данных отличаются от наборов данных домена источника (source domain datasets). Это уже не сырые данные, а данные, пропущенные через несколько этапов трансформации. Структура этих наборов данных и их представление подогнаны под конкретные кейсы их использования. Т.е. это аналог специализированных витрин данных в централизованном хранилище. Для таких наборов данных домена потребителя (consumer domain datasets) должна быть предусмотрена возможность оперативного восстановления из сырых данных.
Распределённые конвейеры обработки данных (data pipelines), реализованные внутри своих доменов
Владение данными в нашей новой архитектуре делегировано от центральной платформы к командам внутри бизнес-доменов, но потребности в очистке, подготовке и агрегации данных (использовании data pipeline) никуда не исчезают. Поэтому реализация собственного data pipeline становится внутренней задачей команды бизнес-домена. В результате мы получаем распределённые по всем доменам собственные доменные data pipelines.
К примеру, домены источники должны включать в себя очистку данных, удаление дублей, обогащение данных и т.п., чтобы другие домены могли использовать эти данные без предварительных обработок. Каждый такой набор данных должен соответствовать своему соглашению уровня обслуживания (Service Level Objective) в части качества данных.
Аналогично этапы построения специализированных витрин централизованного конвейера (pipeline) обработки данных переходят в собственные data pipelines доменов потребителей, которые строят consumer domain datasets.
Рисунок 8: Распределённые конвейеры обработки данных, реализованные внутри своих доменов
Может показаться, что подобная модель приведёт к большому дублированию усилий в каждом домене для создания собственной реализации конвейера обработки данных. Мы поговорим об этой проблеме в разделе «централизованная инфраструктура данных как платформа».
Данные и продуктовое мышление
Передача владения данными и ответственности за разработку и сопровождение конвейеров обработки данных на сторону бизнес-доменов может вызвать серьёзную озабоченность по поводу дальнейшей доступности и удобства использования таких распределённых наборов данных. Поэтому здесь нам пригодится продуктовое мышление в отношении данных.
Доменные данные как продукт
За последние десять лет продуктовое мышление глубоко проникло в разработку информационных систем организаций и серьёзным образом трансформировало подход к этой разработке. Доменные команды разработки информационных систем предоставляют новые возможности в виде интерфейсов API, которые используются разработчиками в организациях как строительные блоки для создания функциональности более высокого порядка и более высокой ценности. Команды стремятся создать лучший опыт для пользователей своих API через понятную и детальную документацию, к которой пользователям легко получить доступ; тестовые среды; тщательно отслеживаемые показатели качества.
Чтобы распределённая платформа данных была успешной, data-команды бизнес-доменов должны применять продуктовое мышление по отношению к предоставляем наборам данных (datasets): воспринимать данные, которые они готовят, как продукт, а потребителей (аналитики, data scientists, data инженеры, ML специалисты и т.д.) как своих клиентов.
Рисунок 9: Характеристики доменных наборов данных как продуктов
Рассмотрим наш пример – потоковый медиа контент через интернет. Важнейший бизнес-домен – это история воспроизведения: кем, где, когда и какие песни были прослушаны. Это домен имеет разных ключевых потребителей данных внутри организации. Одним требуются данные в режиме, близком к реальному времени, для изучения пользовательского опыта и своевременном обнаружении любых проблем и ошибок воспроизведения. Другие заинтересованы в исторических снимках (snapshots), агрегированные по дням или месяцам. Поэтому наш домен предоставляет данные в двух форматах: события воспроизведения в потоковом виде (streaming, топик в kafka или типа того) и агрегированные события воспроизведения в пакетном формате (файл, таблица в hive и т.п.).
Чтобы обеспечить лучший пользовательский опыт для потребителей, data-продукты бизнес-домена должны обладать следующими ключевыми характеристиками.
Удобство и легкость обнаружения (discoverable)
Необходимо обеспечить условия, при которых любой data-продукт можно легко найти. Самой распространённой реализацией этого требования является наличие реестра – каталога всех доступных data-продуктов с необходимой метаинформацией (такой, как владельцы, источники происхождения, образцы наборов данных, частота обновления, структура наборов данных и т.п.). Такой централизованный сервис позволяет потребителям данных легко находить интересующий их набор данных. Каждый data-продукт от любого бизнес-домена должен быть зарегистрирован в централизованном каталоге данных.
Обратите внимание, что здесь присутствует сдвиг от единой централизованной платформы, владеющей всеми данными, к распределённым data-продуктам разных бизнес-доменов, которые зарегистрированы в едином каталоге данных.
Наличие уникального адреса (addressable)
Каждый data-продукт должен иметь уникальный адрес (в соответствии с глобальным соглашением), который позволит его потребителям получить программный доступ к нему. Организации могут принять различные соглашения о наименовании data-продуктов и их расположении, в зависимости от доступных способов физического хранения данных и форматов самих данных. Для распределённой децентрализованной архитектуры такие общие соглашения являются необходимыми. Стандарты адреса наборов данных устранят трения при поиске и доступе к data-продуктам.
Качество данных
Никто не будет использовать продукт, который не вызывает доверия. В платформах данных текущего поколения повсеместно распространена загрузка и публикация данных, содержащих ошибки и не отражающих всей бизнес-правды, т.е. данных, которым нельзя доверять. Именно в этой части сосредоточено значительное количество ETL джобов, которые очищают данные после загрузки.
Новая архитектура требует от владельцев data-продуктов принятия SLO (Service Level Objective) в отношении точности, достоверности и актуальности данных. Для обеспечения приемлемого качества необходимо использовать такие методы, как очистка данных и автоматическое тестирование целостности данных на этапе создания data-продукта. Информация о происхождении данных (data lineage) в метаданных каждого data-продукта даёт потребителям дополнительную уверенность в самом продукте и его пригодности для конкретных потребностей.
Целевое значение показателя качества данных (либо допустимый диапазон) варьируются в зависимости от data-продукта конкретного бизнес-домена. Например, домен «события воспроизведения» может предоставлять два разных продукта: один в режиме, близком к реальному времени, с более низким уровнем точности (включая пропущенные или повторяющиеся события); и второй с более длинной задержкой и более высоким уровнем качества данных. Каждый data-продукт определяет и поддерживает целевой уровень целостности и достоверности своих данных в виде набора SLO (Service Level Objective).
Понятное описание семантики и синтаксиса данных
Качественные продукты должны быть легки в использовании. Создание data-продуктов максимально простых в использовании аналитиками, инженерами и data scientists требует наличия хорошо описанной семантики и синтаксиса данных. В идеале сопровождаемых образцами наборов данных в качестве примеров.
Интегрируемость данных и стандарты, определяемые на уровне всей организации
Одной из основных проблем в распределённой domain driven архитектуре данных является необходимость интегрировать данные из разных доменов. Ключом к лёгкой и эффективной интеграции данных между доменами является определение и соблюдение правил и стандартов. Такие стандарты должны определяться на уровне всей организации. Стандартизация требуется в области определения допустимых типов данных и правил их применения, соглашений о наименованиях и адресах data-продуктов, форматов метаданных и т.п.
По тем сущностям, которые могут хранится в разном виде и с разным набором атрибутов в разных доменах, необходимо реализовывать практики Master Data Management. Присваивать им глобальные идентификаторы и выравнивать набор и, главное, значения атрибутов среди всех доменов.
Обеспечение функциональной совместимости данных для их эффективной интеграции, а также определение стандартов хранения и представления data-продуктов на уровне всей организации являются одним из основополагающих принципов построения подобных распределённых систем.
Безопасность данных и контроль доступа к ним
Обеспечение безопасного доступа к данным является обязательным фактором, независимо от того, является ли архитектура централизованной или нет. В мире децентрализованных data-продуктов, ориентированных на бизнес-домен, управление доступом возможно (и должно применяться) с более высокой степенью детализации для каждого набора данных. Политики контроля доступа к данным могут быть определены централизованно, но реализуются отдельно для каждого data-продукта. В качестве удобного способа реализации контроля доступа к наборам данных может быть использование системы Enterprise Identity Management и управление доступом на основе ролей.
Далее будет описана единая инфраструктура, которая позволяет легко и автоматически реализовать вышеуказанные возможности для каждого продукта данных.
Кросс функциональная data-команда бизнес-домена
В командах, предоставляющих данные в виде data-продуктов, должны быть представлены следующие роли: владелец data-продукта и data-инженер.
Владелец data-продукта отвечает за концепцию и дорожную карту, жизненный цикл своих продуктов. Меряет удовлетворённость своих потребителей и постоянно измеряет и улучшает качество данных своего бизнес-домена. Наполняет и балансирует бэклог своих data-продуктов требованиями, поступающими от потребителей данных.
Также владельцы data-продуктов должны определить ключевые метрики и показатели эффективности (KPI) для своих продуктов. К примеру, время, необходимое для ознакомления и начала использования пользователем data-продукта, может быть одной из таких метрик.
Для того, чтобы создавать и сопровождать свои собственные конвейеры данных (data pipelines) внутри бизнес-домена, команда должна включать в себя data-инженеров. Хорошим побочным эффектом от этого будет распространение соответствующих навыков внутри бизнес-домена. По моим наблюдениям в настоящий момент некоторым data-инженерам, хотя и компетентным в использовании своих инструментов и технологий, не хватает знания стандартных практик разработки программного обеспечения, когда речь идёт о создании data-продуктов. В первую очередь таких DevOps практик, как continuous delivery и автоматическое тестирование. С другой стороны разработчики программного обеспечения, которые развивают информационные системы, часто не имеют достаточного опыта и знаний в области технологий и инструментов для работы с данными как с продуктом. Объединение их в многофункциональные команды в рамках бизнес-домена приведёт к появлению специалистов более широкого профиля. Что-то подобное мы наблюдали при развитии DevOps, когда появились новые типы инженеров, такие как SRE.
Рисунок 10: Кросс функциональная доменная data-команда
Централизованная инфраструктура данных как платформа
Одним из чувствительных моментов распределённой domain driven архитектуры платформы данных является необходимость дублирования в каждом домене усилий и навыков, необходимых для работы инфраструктуры и технологического стека, используемого в конвейерах данных (data pipelines). К счастью, создание общей инфраструктуры как платформы – задача, которую хорошо научились решать в IT (но не в области работы с данными).
Команда инфраструктуры данных должна владеть и предоставлять как сервис инструменты, необходимые бизнес-доменам для сбора, обработки и хранения своих data-продуктов.
Рисунок 11: Инфраструктура данных как платформа
Инфраструктура данных как платформа должна быть свободна от каких-либо доменно-специфичных концепций или бизнес-логики. Также платформа должна скрывать от пользователей всю сложность своей реализации и предоставлять максимальный объём своего функционала для использования в режиме самообслуживания. Вот список некоторых возможностей, которые должна предоставлять такая централизованная инфраструктура данных как платформа:
- Масштабируемое хранения данных в разных форматах
- Шифрование данных (тут же хэширование, обезличивание и т.д.)
- Версионирование data-продуктов
- Хранение схемы данных data-продукта
- Контроль доступа к данным
- Журналирование
- Оркестровка потоков/процессов по обработке данных
- Кэширование данных в памяти
- Хранение метаданных и data lineage
- Мониторинг, оповещения, логгирование
- Расчёт метрик качества data-продуктов
- Ведение каталога данных
- Стандартизация и политики, возможность контроля соответствия
- Адресация data-продуктов
- CI/CD pipelines для data-продуктов
При создании централизованной инфраструктуры данных необходимо стремится к тому, чтобы создание data-продукта на такой инфраструктуре занимало как можно меньше времени. Поэтому очень важным является максимальная автоматизация ключевого функционала, как то: возможность загрузки данных с помощью простых конфигураций, автоматическая регистрация data-продукта в каталоге данных и т.д. Использование облачной инфраструктуры может снизить эксплуатационные расходы и повысить скорость предоставления доступа к инфраструктуре данных по требованию.
Сдвиг парадигмы в сторону Data Mesh
Это было долгое чтение! Давайте немного резюмируем всё то, что написано выше. Мы рассмотрели некоторые ключевые характеристики современных платформ данных: централизованные, монолитные, сложные data pipelines (c сотнями и тысячами джобов, тесно связанных друг с другом), разрозненные узко-специализированные команды. После поговорили про новый подход data mesh, включающий в себя распределённые data-продукты ориентированные на бизнес-домены, управляемые межфункциональными командами (с владельцами data-продуктов и data-инженерами), использующие общую инфраструктуру данных в качестве платформы для размещения.
Data Mesh представляет собой распределённую архитектуру, с централизованным управлением и разработанными стандартами, обеспечивающими интегрируемость данных, и с централизованной инфраструктурой, предоставляющей возможность использования в режиме самообслуживания. Я надеюсь читателю достаточно очевидно, что такая архитектура очень далека от набора слабосвязанных хранилищ недоступных данных, независимо разрабатываемых в разных подразделениях.
Рисунок 12: Архитектура Data Mesh с высоты 10 000 метров
Вы можете спросить: а как Data Lake или хранилище данных (Data Warehouse) вписываются в эту архитектуру? Они просто являются отдельными узлами (доменами) в этой распределённой архитектуре. Есть высокая вероятность, что в подобной архитектуре нам больше не понадобится Data Lake. Ведь нам будут доступны для исследования оригинальные данные разных бизнес-доменов, оформленные в виде data-продуктов.
Соответственно, Data Lake больше не является центральным элементов всей архитектуры. Но технологии и инструменты, используемые при построении Data Lake, мы продолжим применять либо для создания общей инфраструктуры данных, либо для внутренней реализации наших data-продуктов.
Это фактически возвращает нас к тому, с чего всё начиналось. Джеймс Диксон в 2010 году намеревался использовать Data Lake для одного бизнес-домена, а несколько доменов данных образовывали бы Water Garden.
Основной сдвиг парадигмы заключается в том, чтобы рассматривать data-продукт бизнес-домена как задачу первого приоритета, а инструментальные средства и технологии – как задачу второго приоритета (как деталь реализации). Это уводить ментальную модель от централизованного Data Lake в экосистему data-продуктов, которые просто и эффективно интегрируются друг с другом.
Пару слов по поводу отчётности и визуализации (применение BI инструментов и т.п.). В отношении них применяется такой же принцип: в этой архитектуре они являются отдельными узлами. Т.е. это независимые data-продукты внутри какого-либо бизнес-домена, ориентированные прежде всего на потребителя, а не на источник данных.
Я признаю, что хотя и вижу успешное применение принципов Data Mesh моими клиентами, масштабированию этих принципов в крупных организациях предстоит пройти долгий путь. Но очевидно, что технологии не являются здесь ограничением. Все те инструменты, которые мы используем сегодня, могут с тем же успехом применяться для распределения и владения data-продуктами разными командами. В частности, переход к стандартизации пакетных и потоковых джобов обработки данных, а также использование инструментов вроде Apache Beam или Google Cloud DataFlow, позволяет легко обрабатывать разнообразные наборы данных с уникальными адресами.
Платформы каталогов данных, такие как Google Cloud Data Catalog, обеспечивают легкость обнаружения, контроль доступа и централизованное управление наборами данных распределённых бизнес-доменов. Большое количество облачных платформ позволяет бизнес-доменам выбирать подходящие для целевого хранения своих data-продуктов.
Необходимость смены парадигмы очевидна. Все необходимые технологии и инструменты для этого есть. Руководители организаций и профессионалы в области обработки данных должны признать, что существующая парадигма больших данных и подход с одной большой платформой Data Lake только повторит неудачи прошлого, используя при этом новые облачные технологии и инструменты.
Давайте же перейдём от централизованной монолитной платформы данных к экосистеме data-продуктов.
Ссылки на первоисточники и дополнительные материалы по теме
- martinfowler.com/articles/data-monolith-to-mesh.html
- www.youtube.com/watch?v=On4WBHOaP4c
- softwareengineeringdaily.com/2019/07/29/data-mesh-with-zhamak-deghani
- www.dataengineeringpodcast.com/zhamak-dehghani-data-mesh-episode-90
- www.infoq.com/presentations/data-mesh-paradigm
- www.infoq.com/podcasts/domain-oriented-data
- fast.wistia.net/embed/iframe/vys2juvzc3?videoFoam (видео, доступно через vpn)




sshikov
Возможно я что-то упустил, но совершенно непонятным остался один аспект. Мы не будем строить монолитное хранилище, а сделаем отдельные домены доступными извне, адресуемыми, снабдим их метаданными, и т.д. и т.п. Прелестно, прелестно. А дальше-то?
Представим, что нам нужен, условно, JOIN с использованием данных из разных доменов. Распределенных, как автор предложил. Кто и где его будет строить? Ресурсы каких процессоров, место на каких носителях, что за код при этом будет выполняться?
Evgeny_Chernyy Автор
Прежде всего сделаю оговорку, что не считаю себя экспертом по этой новой архитектуре Data Mesh. Но статью перевёл + изучил все доступные материалы по теме в Интернете (коих пока немного). Поэтому далее моё личное понимание материала.
Значит по поводу того, что делать с join-ами данных из разных доменов.
Ключевое отличие этой архитектуры Data Mesh от предыдущих в том, что у нас теперь действительно не монолитное хранилище (или монолитный Data Lake), а экосистема data-продуктов.
Data-продукты могут быть двух видов (об этом написано в статье):
1. Data-продукты, ориентированные на источник данных — по сути сырые данные, но уже прошедшие через какие-то этапы очистки и, возможно, трансформации формата. В качестве источников данных для таких продуктов выступают информационные системы банка.
2. Data-продукты, ориентированные на потребителя — читай витрины (хотя могут быть и в разных форматах: таблицы, выгрузки в файл, потоковые данные — топики кафка и т.п.). В качестве источников данных для таких продуктов будут уже чаще выступать другие data-продукты. Создаются эти продукты тем доменом, у которого есть потребность в них.
По поводу того где размещать эти продукты. Тут могут быть разные варианты. Автор статьи предлагает использовать централизованную инфраструктурную платформу для всех data-продуктов. Это может быть как единая СУБД, где каждый домен будет иметь свою схему, так и единый для всех кластер hadoop со своими областями для каждого домена. Возможна и федеративная архитектура с собственной вычислительной инфраструктурой у каждого домена. При создании data-продуктов предполагается максимальное использование всех инструментов и фреймворков, предоставленных централизованной инфраструктурной командой.
sshikov
>единый для всех кластер hadoop со своими областями для каждого домена
Ну мне вот почему-то кажется, что для реально больших данных — это чуть ле не единственно практичный вариант.
Вообще, почему мне идея еще сомнительна — потому что «монолитный» Data Lake — это прежде всего монолитная архитектура. Т.е. это хадуп, например, и все данные в хадупе, доступны для например спарка (или упомятуного тут Beam, хотя я совершенно не понял, что автор такого увидела в Beam, чего нет в спарке, продукт как продукт, совершенно не новый, и никакого прорыва, на мой взгляд, не дает вообще).
А распределенные бизнес домены — это как правило разные архитектуры, т.е. где-то в основе оракл, где-то Терадата, где-то еще что-то — и на их интеграцию нужны разработчики, имеющие квалификацию в каждой технологии. И наш опыт четко показывает, что чем больше зоопарка в технологиях — тем больше проблем. Берем тривиально и к ораклу добавляем еще MS SQL — и уже огребаем время от времени.
Evgeny_Chernyy Автор
Ну в общем автор так и пишет:
Зоопарка разных технологий, своих для каждого бизнес-домена, не предполагается.
Evgeny_Chernyy Автор
Вообще, в этой архитектуре централизованными остаются немного вещей:
1. Формирование стандартов и практик в отношении создания/сопровождения/предоставления доступов к data-продуктам. Ну и контроль за соблюдением и выполнением этих стандартов и практик
2. Создание и поддержка централизованной инфраструктуры для создания и хранения всех data-продуктов. Здесь же все инструменты для создания data pipelines (ETL процессов), версионирования, шифрования, мониторинга и т.д.
3. Создание и сопровождение инструментов для регистрации продуктов (Data Catalog) и ведения бизнес-глосария. И, соответственно, контроль регистрации data-продуктов и ведения бизнес-глосария
4. Всё!
Лично я не исключаю варианта создания и поддержки некоторых базовых витрин и общих справочников централизованной командой. В случае, если у таких витрин и справочников не очевидна принадлежность к конкретному домену и много потенциальных потребителей из разных доменов.
sshikov
>2. Создание и поддержка централизованной инфраструктуры для создания и хранения всех data-продуктов. Здесь же все инструменты для создания data pipelines (ETL процессов), версионирования, шифрования, мониторинга и т.д.
Ну мы и так уже к этому пришли. Причем на обычном хадупе. Грубо говоря, вы можете иметь два или больше кластеров — но IPA при этом лучше иметь общую (хотя тут есть проблемы с масштабированием, начиная с некоторых размеров). И еще некоторые инструменты неплохо иметь централизованные. А дальше вполне можно (и даже где-то нужно) жить не на одном большом хадупе, который тоже упирается в масштабирование некоторых компонент, а на нескольких поменьше размером.
Evgeny_Chernyy Автор
Тут весь вопрос в том, кто у вас загружает сырые данные из источников и строит специализированные витрины. Если всё это делают централизованные команды, не имеющие понимания ни бизнес-смысла загружаемых данных, ни реальных кейсов их дальнейшего использования, то это не Data Mesh :) Суть новой архитектуры в том, что владение данными (data-продуктами) распределено по бизнес-доменам.