
Всем привет. OTUS открыл набор в новую группу по курсу «Инфраструктурная платформа на основе Kubernetes», в связи с этим мы подготовили перевод интересного материала по теме.

Возможно, вы один из тех, кто использует terraform для Infrastructure as a Code, и вам интересно, как использовать его продуктивнее и безопаснее. В общем-то, последнее время, это многих беспокоит. Мы все пишем конфигурацию и код, используя разные инструменты, языки и тратим значительное количество времени на то, чтобы сделать его более читабельным, расширяемым и масштабируемым.

Может быть, проблема в нас самих?
Написанный код должен создавать ценность или решать проблему, а также быть пригодным для повторного использования с целью дедупликации. Обычно такого рода дискуссии заканчиваются “Давайте использовать модули”. Мы все используем модули terraform, верно? Я мог бы написать множество историй с проблемами из-за чрезмерной модульности, но это совсем другая история, и я не буду.

Нет, я не буду. Не настаивайте, нет… Ладно, может быть, позже.
Есть хорошо известная практика — тегировать код при использовании модулей для блокировки root-модуля, чтобы гарантировать его работу даже при изменении кода модуля. Этот подход должен стать командным принципом, при котором соответствующие модули тегируются и используются надлежащим образом.
… но что насчет зависимостей? Что, если у меня 120 модулей в 120 разных репозиториях, и изменение одного модуля влияет на 20 других модулей. Означает ли это, что нам нужно делать 20 + 1 пулл реквестов? Если минимальное количество ревьюеров равно 2, то это означает 21 х 2 = 44 ревью. Серьёзно! Мы просто парализуем команду “изменением одного модуля” и все начнут посылать мемы или гифки Властелина колец, и оставшаяся часть дня будет потеряна.

Один PR, чтобы уведомить всех, один PR, чтобы собрать всех вместе, сковать и ввергнуть во тьму
Стоит ли так работать? Должны ли мы уменьшить количество ревьюверов? Или, может, для модулей сделать исключение и не требовать PR, если изменение оказывает большое влияние. Действительно? Вы хотите гулять вслепую в глубоком темном лесу? Или соберете всех вместе, скуете и ввергнете во тьму?
Не надо, не меняйте порядок ревью. Если вы считаете, что правильно работать с PR, то придерживайтесь этого. Если у вас есть умные пайплайны или у вас пушат в master, то оставайтесь с этим подходом.
В данном случае проблема не “как вы работаете”, а “какая структура у ваших git-репозиториев”.

Это похоже на то, что я чувствовал, когда впервые применил предложенное ниже
Вернемся к основам. Каковы общие требования к репозиторию с terraform-модулями?
Тогда я предлагаю следующее — НЕ используйте микро-репозитории для модулей terraform. Используйте один моно-репозиторий.

У меня есть сила!
Хорошо, но какая будет структура у этого репозитория? Последние четыре года у меня было много неудач, связанных с этим, и я пришел к выводу, что лучшим решением будет отдельная директория на модуль.
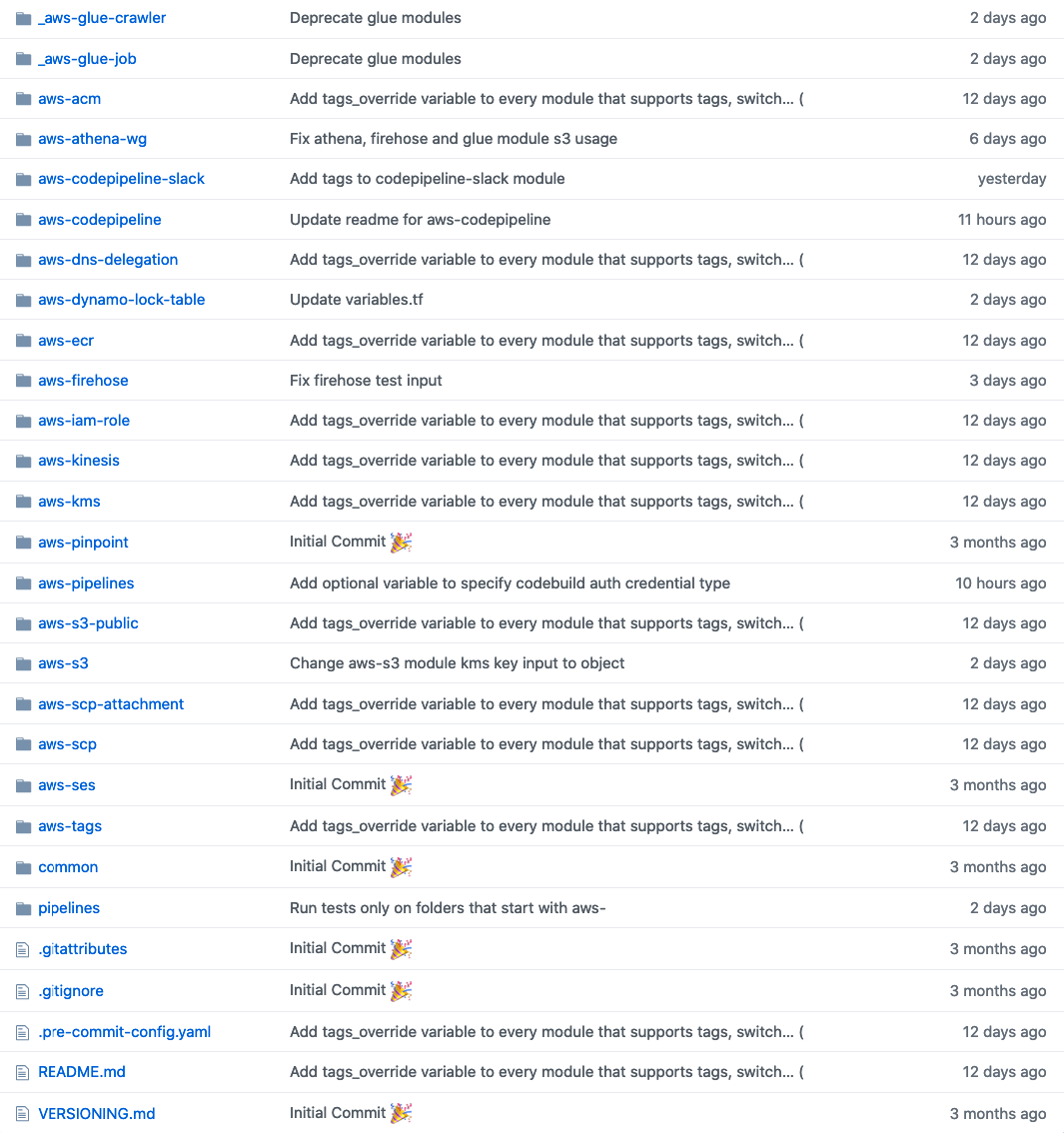
Пример структуры каталогов для моно-репозитория. Видите изменение tags_override?
Таким образом, изменение модуля, которое влияет на 20 других модулей, это всего лишь 1 PR! Даже если вы добавите 5 ревьюеров к этому PR, то ревью будет очень быстрым по сравнению с микро-репозиториями. Если вы используете Github, то это еще лучше! Вы можете использовать CODEOWNERS для модулей, у которых есть мейнтейнеры / владельцы, и любые изменения в этих модулях ДОЛЖНЫ быть одобрены этим владельцем.
Отлично, но как использовать такой модуль, который находится в каталоге моно-репозитория?
Легко:
Какие есть недостатки такого рода структуры? Что ж, если вы попробуете протестировать “каждый модуль” при PR / изменении, то у вас может получиться 1,5 часа CI-пайплайнов. Вам нужно найти измененные модули в PR. Я делаю это так:
Есть еще один недостаток: всякий раз, когда вы запускаете “terraform init”, он загружает весь репозиторий в каталог .terraform. Но у меня никогда не было с этим проблем, так как я запускаю свои пайплайны в масштабируемых контейнерах AWS CodeBuild. Если вы используете Jenkins и persistent Jenkins Slaves, то у вас может возникнуть эта проблема.

Не заставляй нас плакать.
C моно-репозиторием у вас остаются все преимущества микро-репозиториев, но в качестве бонуса вы снижаете стоимость обслуживания ваших модулей.
Честно говоря, после работы в таком режиме, предложение использовать микро-репозитории для модулей terraform должно расцениваться как преступление.
Отлично, а как насчет юнит-тестирования? Вам это действительно нужно? … Вообще, что именно вы понимаете под юнит-тестированием. Вы действительно собираетесь проверять правильно ли создан ресурс AWS? Чья это ответственность: terraform или API, обрабатывающего создание ресурса? Возможно, нам следует больше сосредоточиться на негативном тестировании и идемпотентности кода.
Для проверки идемпотентности кода terraform предоставляет отличный параметр, называемый
После этого запускаете
Что насчет негативного тестирования? Что, вообще, такое негативное тестирование? На самом деле это не сильно отличается от юнит-тестирования, но вы обращаете внимание на негативные ситуации.
Например, никому не разрешено создавать незашифрованный и публичный бакет S3.
Таким образом, вместо того, чтобы проверять, действительно ли создается S3 бакет, вы, фактически, на основе набора политик, проверяете создает ли ваш код ресурс. Как это сделать? Terraform Enterprise предоставляет отличный инструмент для этого, Sentinel.
… но есть также альтернативы с открытым исходным кодом. В настоящее время существует множество инструментов для статического анализа HCL-кода. Эти инструменты, основываясь на общих лучших практиках, не позволят вам сделать что-либо нежелательное, но что, если в нем нет нужного вам теста… или, что еще хуже, если ваша ситуация немного отличается. Например, вы хотите разрешить сделать некоторые S3 бакеты публичными на основе некоторых условий, что, на самом деле, будет ошибкой безопасности для этих инструментов.
Здесь появляется terraform-compliance. Этот инструмент не только позволит вам написать свои тесты, в которых вы сможете определить ЧТО вы хотите в качестве политики вашей компании, но также поможет вам разделить безопасность и разработку, сдвинув безопасность влево. Звучит довольно противоречиво, не так ли? Нет. Тогда как?

Лого terraform-compliance
Прежде всего, terraform-compliance использует Behavior Driven Development (BDD).
Проверяем включено ли шифрование
Если вам этого не достаточно то, вы можете написать подробнее:
Углубляемся и проверяем, что для шифрования используется KMS
Код terraform для этого теста:
Таким образом, тесты понятны буквально ВСЕМ в вашей организации. Здесь вы можете делегировать написание этих тестов службе безопасности или разработчикам с достаточным знанием безопасности. Этот инструмент также позволяет хранить BDD-файлы в другом репозитории. Это поможет разграничить ответственность, когда изменения в коде и изменения в политиках безопасности, связанных с вашим кодом, будут представлять собой две разные сущности. Это могут быть разные команды с разными жизненными циклами. Удивительно верно? Ну, по крайней мере, для меня это было так.
Для получения дополнительной информации о terraform-compliance посмотрите эту презентацию.
Мы решили массу проблем с помощью terraform-compliance, особенно там, где службы безопасности достаточно отдалены от команд разработчиков, и могут не понимать, что делают разработчики. Вы уже догадываетесь, что происходит в такого рода организациях. Обычно служба безопасности начинает блокировать все для них подозрительное и строит систему безопасности, основываясь на безопасности периметра. О, Боже…
Во многих ситуациях только использование terraform и terraform-compliance для команд, которые проектируют (или/и сопровождают) инфраструктуру, помогло посадить эти две разные команды за один стол. Когда ваша служба безопасности начинает что-то разрабатывать с немедленной обратной связью от всех пайплайнов разработки, то у них обычно появляется мотивация делать все больше и больше. Ну, как правило…
Поэтому, при использовании terraform мы структурируем git-репозитории следующим образом:
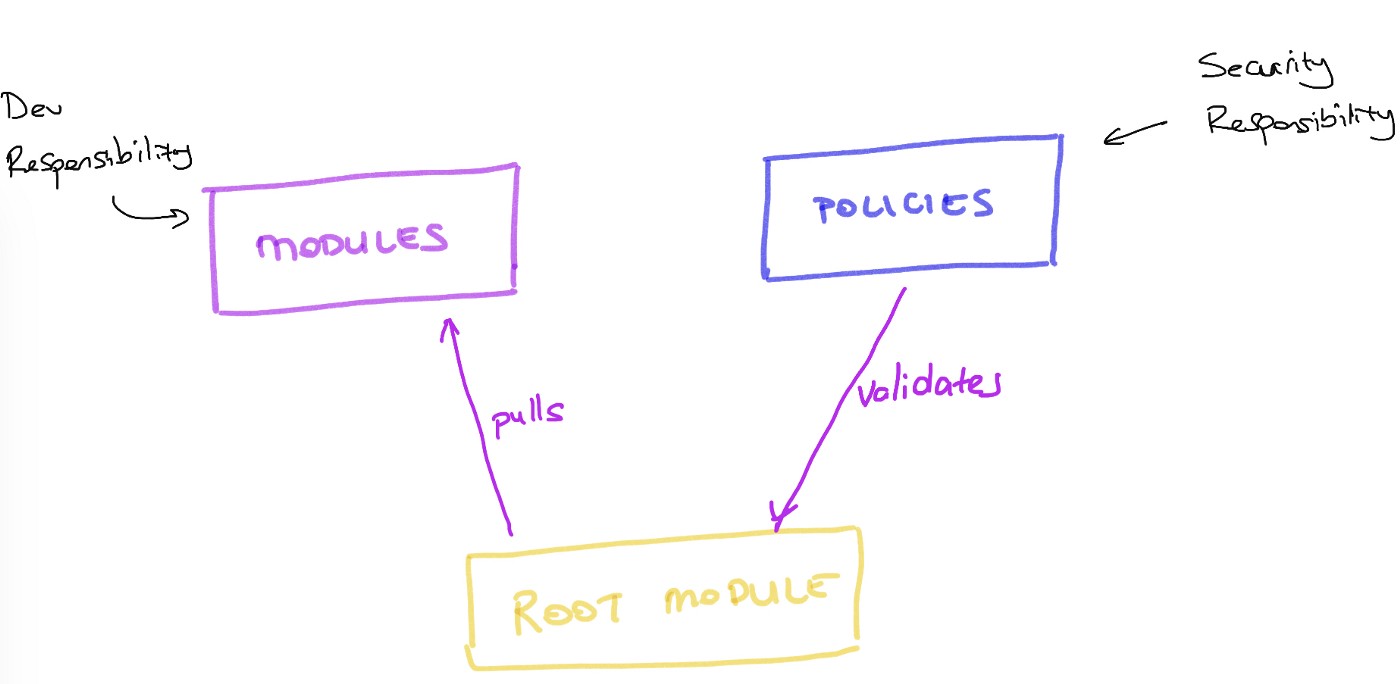
Конечно, это довольно самоуверенно. Но мне повезло (или не повезло?) поработать с более детализированной структурой в нескольких организациях. К сожалению, все это заканчивалось не очень хорошо. Счастливый конец должен быть скрыт в числе 3.
Дайте мне знать, если у вас есть какие-нибудь истории успеха с микро-репозиториями, мне действительно интересно!
Приглашаем вас на бесплатный урок, в рамках которого мы рассмотрим компоненты будущей инфраструктурной платформы и разберемся, как доставлять наше приложение правильно.
Возможно, вы один из тех, кто использует terraform для Infrastructure as a Code, и вам интересно, как использовать его продуктивнее и безопаснее. В общем-то, последнее время, это многих беспокоит. Мы все пишем конфигурацию и код, используя разные инструменты, языки и тратим значительное количество времени на то, чтобы сделать его более читабельным, расширяемым и масштабируемым.
Может быть, проблема в нас самих?
Написанный код должен создавать ценность или решать проблему, а также быть пригодным для повторного использования с целью дедупликации. Обычно такого рода дискуссии заканчиваются “Давайте использовать модули”. Мы все используем модули terraform, верно? Я мог бы написать множество историй с проблемами из-за чрезмерной модульности, но это совсем другая история, и я не буду.
Нет, я не буду. Не настаивайте, нет… Ладно, может быть, позже.
Есть хорошо известная практика — тегировать код при использовании модулей для блокировки root-модуля, чтобы гарантировать его работу даже при изменении кода модуля. Этот подход должен стать командным принципом, при котором соответствующие модули тегируются и используются надлежащим образом.
… но что насчет зависимостей? Что, если у меня 120 модулей в 120 разных репозиториях, и изменение одного модуля влияет на 20 других модулей. Означает ли это, что нам нужно делать 20 + 1 пулл реквестов? Если минимальное количество ревьюеров равно 2, то это означает 21 х 2 = 44 ревью. Серьёзно! Мы просто парализуем команду “изменением одного модуля” и все начнут посылать мемы или гифки Властелина колец, и оставшаяся часть дня будет потеряна.
Один PR, чтобы уведомить всех, один PR, чтобы собрать всех вместе, сковать и ввергнуть во тьму
Стоит ли так работать? Должны ли мы уменьшить количество ревьюверов? Или, может, для модулей сделать исключение и не требовать PR, если изменение оказывает большое влияние. Действительно? Вы хотите гулять вслепую в глубоком темном лесу? Или соберете всех вместе, скуете и ввергнете во тьму?
Не надо, не меняйте порядок ревью. Если вы считаете, что правильно работать с PR, то придерживайтесь этого. Если у вас есть умные пайплайны или у вас пушат в master, то оставайтесь с этим подходом.
В данном случае проблема не “как вы работаете”, а “какая структура у ваших git-репозиториев”.
Это похоже на то, что я чувствовал, когда впервые применил предложенное ниже
Вернемся к основам. Каковы общие требования к репозиторию с terraform-модулями?
- Он должен быть тегирован для того, чтобы не было breaking changes.
- Любое изменение должно иметь возможность тестирования.
- Изменения должны проходить взаимное ревью.
Тогда я предлагаю следующее — НЕ используйте микро-репозитории для модулей terraform. Используйте один моно-репозиторий.
- Вы можете тегировать весь репозиторий, когда есть изменение / требование
- Любое изменение, PR или push можно протестировать
- Любое изменение может пройти через ревью
У меня есть сила!
Хорошо, но какая будет структура у этого репозитория? Последние четыре года у меня было много неудач, связанных с этим, и я пришел к выводу, что лучшим решением будет отдельная директория на модуль.
Пример структуры каталогов для моно-репозитория. Видите изменение tags_override?
Таким образом, изменение модуля, которое влияет на 20 других модулей, это всего лишь 1 PR! Даже если вы добавите 5 ревьюеров к этому PR, то ревью будет очень быстрым по сравнению с микро-репозиториями. Если вы используете Github, то это еще лучше! Вы можете использовать CODEOWNERS для модулей, у которых есть мейнтейнеры / владельцы, и любые изменения в этих модулях ДОЛЖНЫ быть одобрены этим владельцем.
Отлично, но как использовать такой модуль, который находится в каталоге моно-репозитория?
Легко:
module "from_mono_repo" {
source = "git::ssh://.../<org>/<repo>.git//<my_module_dir>"
...
}
module "from_mono_repo_with_tags" {
source = "git::ssh://..../<org>/<repo>.git//<mod_dir>?ref=1.2.4"
...
}
module "from_micro_repo" {
source = "git::ssh://.../<org>/<mod_repo>.git"
...
}
module "from_micro_repo_with_tags" {
source = "git::ssh://.../<org>/<mod_repo>.git?ref=1.2.4"
...
}Какие есть недостатки такого рода структуры? Что ж, если вы попробуете протестировать “каждый модуль” при PR / изменении, то у вас может получиться 1,5 часа CI-пайплайнов. Вам нужно найти измененные модули в PR. Я делаю это так:
changed_modules=$(git diff --name-only $(git rev-parse origin/master) HEAD | cut -d "/" -f1 | grep ^aws- | uniq)Есть еще один недостаток: всякий раз, когда вы запускаете “terraform init”, он загружает весь репозиторий в каталог .terraform. Но у меня никогда не было с этим проблем, так как я запускаю свои пайплайны в масштабируемых контейнерах AWS CodeBuild. Если вы используете Jenkins и persistent Jenkins Slaves, то у вас может возникнуть эта проблема.
Не заставляй нас плакать.
C моно-репозиторием у вас остаются все преимущества микро-репозиториев, но в качестве бонуса вы снижаете стоимость обслуживания ваших модулей.
Честно говоря, после работы в таком режиме, предложение использовать микро-репозитории для модулей terraform должно расцениваться как преступление.
Отлично, а как насчет юнит-тестирования? Вам это действительно нужно? … Вообще, что именно вы понимаете под юнит-тестированием. Вы действительно собираетесь проверять правильно ли создан ресурс AWS? Чья это ответственность: terraform или API, обрабатывающего создание ресурса? Возможно, нам следует больше сосредоточиться на негативном тестировании и идемпотентности кода.
Для проверки идемпотентности кода terraform предоставляет отличный параметр, называемый
-detailed-exitcode. Просто запустите:> terraform plan -detailed-exitcodeПосле этого запускаете
terraform apply и все. По крайней мере, вы будете уверены в том, что ваш код идемпотентен и не создает новых ресурсов из-за случайной строки или чего-то еще.Что насчет негативного тестирования? Что, вообще, такое негативное тестирование? На самом деле это не сильно отличается от юнит-тестирования, но вы обращаете внимание на негативные ситуации.
Например, никому не разрешено создавать незашифрованный и публичный бакет S3.
Таким образом, вместо того, чтобы проверять, действительно ли создается S3 бакет, вы, фактически, на основе набора политик, проверяете создает ли ваш код ресурс. Как это сделать? Terraform Enterprise предоставляет отличный инструмент для этого, Sentinel.
… но есть также альтернативы с открытым исходным кодом. В настоящее время существует множество инструментов для статического анализа HCL-кода. Эти инструменты, основываясь на общих лучших практиках, не позволят вам сделать что-либо нежелательное, но что, если в нем нет нужного вам теста… или, что еще хуже, если ваша ситуация немного отличается. Например, вы хотите разрешить сделать некоторые S3 бакеты публичными на основе некоторых условий, что, на самом деле, будет ошибкой безопасности для этих инструментов.
Здесь появляется terraform-compliance. Этот инструмент не только позволит вам написать свои тесты, в которых вы сможете определить ЧТО вы хотите в качестве политики вашей компании, но также поможет вам разделить безопасность и разработку, сдвинув безопасность влево. Звучит довольно противоречиво, не так ли? Нет. Тогда как?
Лого terraform-compliance
Прежде всего, terraform-compliance использует Behavior Driven Development (BDD).
Feature: Ensure that we have encryption everywhere.
Scenario: Reject if an S3 bucket is not encrypted
Given I have aws_s3_bucket defined
Then it must contain server_side_encryption_configurationПроверяем включено ли шифрование
Если вам этого не достаточно то, вы можете написать подробнее:
Feature: Ensure that we have encryption everywhere.
Scenario: Reject if an S3 bucket is not encrypted with KMS
Given I have aws_s3_bucket defined
Then it must contain server_side_encryption_configuration
And it must contain rule
And it must contain apply_server_side_encryption_by_default
And it must contain sse_algorithm
And its value must match the "aws:kms" regexУглубляемся и проверяем, что для шифрования используется KMS
Код terraform для этого теста:
resource "aws_kms_key" "mykey" {
description = "This key is used to encrypt bucket objects"
deletion_window_in_days = 10
}
resource "aws_s3_bucket" "mybucket" {
bucket = "mybucket"
server_side_encryption_configuration {
rule {
apply_server_side_encryption_by_default {
kms_master_key_id = "${aws_kms_key.mykey.arn}"
sse_algorithm = "aws:kms"
}
}
}
}Таким образом, тесты понятны буквально ВСЕМ в вашей организации. Здесь вы можете делегировать написание этих тестов службе безопасности или разработчикам с достаточным знанием безопасности. Этот инструмент также позволяет хранить BDD-файлы в другом репозитории. Это поможет разграничить ответственность, когда изменения в коде и изменения в политиках безопасности, связанных с вашим кодом, будут представлять собой две разные сущности. Это могут быть разные команды с разными жизненными циклами. Удивительно верно? Ну, по крайней мере, для меня это было так.
Для получения дополнительной информации о terraform-compliance посмотрите эту презентацию.
Мы решили массу проблем с помощью terraform-compliance, особенно там, где службы безопасности достаточно отдалены от команд разработчиков, и могут не понимать, что делают разработчики. Вы уже догадываетесь, что происходит в такого рода организациях. Обычно служба безопасности начинает блокировать все для них подозрительное и строит систему безопасности, основываясь на безопасности периметра. О, Боже…
Во многих ситуациях только использование terraform и terraform-compliance для команд, которые проектируют (или/и сопровождают) инфраструктуру, помогло посадить эти две разные команды за один стол. Когда ваша служба безопасности начинает что-то разрабатывать с немедленной обратной связью от всех пайплайнов разработки, то у них обычно появляется мотивация делать все больше и больше. Ну, как правило…
Поэтому, при использовании terraform мы структурируем git-репозитории следующим образом:
Конечно, это довольно самоуверенно. Но мне повезло (или не повезло?) поработать с более детализированной структурой в нескольких организациях. К сожалению, все это заканчивалось не очень хорошо. Счастливый конец должен быть скрыт в числе 3.
Дайте мне знать, если у вас есть какие-нибудь истории успеха с микро-репозиториями, мне действительно интересно!
Приглашаем вас на бесплатный урок, в рамках которого мы рассмотрим компоненты будущей инфраструктурной платформы и разберемся, как доставлять наше приложение правильно.