
Режим самоизоляции многих вынудил работать из дома. Кому-то смена обстановки даётся легче, кому-то сложнее, а кто-то и вовсе не заметил бы разницы, но после объявления недели (а потом и месяца) «карантина» прирост постов о лайфхаках, эффективности и продуктивности в ленте существенно увеличился.
Меня зовут Михаил Трошев, я руковожу службой поисковых интерфейсов Яндекса. Наша команда много лет работает распределённо — ниже расскажу, чем это отличается, а чем схоже с «удалённо», как организовано, почему не ломается и чем может быть полезен наш опыт тем, кого резкая смена режима работы застала врасплох.
Что-то наверняка покажется вам банальным (Agile, Scrum, Kanban, DevOps — ничего себе открытия!), но это ведь как с зарядкой по утрам: все знают, что она полезна, но делать регулярно и в полную силу почему-то лень. Так вот: мы делаем. И это работает.
Не удалённо, а распределённо
Как это выглядит: 90 фронтендеров каждый день собираются в офисах Москвы, Питера, Казани, Иннополиса, Екатеринбурга, Симферополя и Минска — нетрудно заметить, что нас разделяют не только расстояния, но и часовые пояса. Однако и это ещё не всё: фронтендеры распределены между продуктовыми командами (virtual teams) примерно по трое-семеро + бэкендеры, дизайнеры, тестировщики и менеджеры (в 2019 году подробно рассказал про наши рабочие структуры здесь). То есть практически все участники одной такой команды находятся в разных городах. Не совсем удалёнка, но очень близко к этому: хотя несколько коллег рядом всё-таки есть, возможности микросинхронизации с остальными существенно ограничены по сравнению с работой в опенспейсе.
Приходится применять асинхронные средства связи с большой задержкой реакции. Чем сильнее команда распылена между разными офисами, тем больше в повседневном рабочем взаимодействии накладных расходов на ожидание, которые могут похоронить любой проект. Чтобы сэкономить время:
— жизненный цикл каждой задачи от идеи до продакшна устроен максимально консистентно: процедуры, статусы, переход между этапами — формализовано всё, что только можно (примерно 90% задач). При этом мы стараемся сохранить бюрократию простой и понятной, иначе она перестает быть полезной и начинает мешать;
— вся команда в курсе правил, регулирующих рабочий процесс, и старается чётко им следовать; рутину стараемся автоматизировать. Таким образом каждый занят своим делом и не тратит время на принятие однотипных микрорешений: программисты — программируют, менеджеры продукта придумывают продуктовые фичи, дизайнеры — дизайнерят.
Ничего нового, правда? Однако этот нехитрый подход очень выручил нас в условиях самоизоляции: каждый сотрудник может принести максимум пользы самостоятельно, поскольку в курсе достаточных для работы подробностей.
Но обо всём по порядку.
Этап 0. Планирование
У каждой команды есть беклог, верхушка которого оценена и приоритизирована:

Принципиальный момент — каждый участник команды должен понимать: эту задачу нужно делать, потому что она привязана к эпику, эпик привязан к цели, а цель важная. Иначе либо люди могут начать делать не то что нужно, либо менеджер будет вынужден постоянно всех контролировать и тушить пожары. Последнее, кстати, бывает сложно заметить в офисе, но невозможно пропустить на удалёнке: кругом неразбериха, работа стоит, в мессенджере заводится десяток чатиков в попытках синхронизироваться — в итоге вся команда переписывается в чате, вместо того чтобы писать код. Критически важно организовать планирование в команде таким образом, чтобы каждый участник процесса понимал, что и в каком порядке ему нужно делать. Тогда и руководитель команды сможет сосредоточиться на продукте, не отвлекаясь на постоянные мелкие вопросы.
Конечно, детализировать весь беклог до дна невозможно, но качественная проработка его верхушки позволяет быстро набирать новые задачи в спринт — почти все команды живут двухнедельными спринтами — и поддерживать запас для следующего. При таком подходе опытная команда может набрать спринт даже без менеджера, если он вдруг оказался недоступен.
Чтобы не растягивать время работы над задачей, команда занимается «полезной бюрократией»: менеджер формулирует чёткое описание, исполнители проставляют правильные статусы, задачи «перетекают» слева направо на спринтовой борде:

Здесь вся команда видит полную и актуальную картину по спринту. Если кто-то заболел, ушёл на дежурство или в отпуск, другие участники сразу подхватывают задачи в их текущем статусе.
Ну и как же без ежедневных синков, когда формальной организации процесса недостаточно, чтобы разрулить какие-то частные случаи, и бюрократия начинает скорее мешать процессу. Обычно детализации задач статусами (open > in progress > in review > ready for test > testing > tested > ready for dev > dev > rc > closed) бывает достаточно, но в 10% случаев требуется что-то уточнить, проговорить словами, объяснить «на пальцах». Кстати, я убеждён, что все рабочие встречи (в том числе стендапы) нужно обязательно проводить с использованием видеосвязи, а не только голосом, потому что это заставляет привести себя в порядок и настроиться на работу.
Очень важно, чтобы на синке присутствовала вся команда: быстро сверили контекст, разобрали задачи и начали работать, ориентируясь по борде, не теряя больше времени на вопросы друг другу. Рабочие чаты у нас, конечно, тоже есть, но мы стараемся не флудить в них и использовать для получения быстрого (в идеале бинарного) ответа: можно ли катить релиз, где найти инструкцию, с кем обсудить API источника данных.
Где выиграли время: синхронизация, принятие микрорешений
Этап 1. Разработка: open > in progress
«Open» — задача ждёт исполнителя. Разработчики забирают их так, чтобы каждая была готова максимально быстро. Например, бывает, что на дворе пятница, а разработчик на следующей неделе уходит на дежурство (и это известно заранее, за месяц). В этом случае ему лучше взять мелкую задачу, чтобы успеть сделать её за один день: стараемся не передавать начатое. Если кто-то не успевает довести работу до конца, лучше влить как есть, а потом отдельным пул-реквестом добить остатки.
Развернул локальную рабочую копию проекта — не забудь перевести задачу из «open» в «in progress», чтобы за неё не взялся кто-то другой. «Локальная», кстати, ключевое слово — работать можно откуда угодно, качество интернет-соединения не будет блокирующим фактором. Сейчас, когда инфраструктура и сети перегружены, очень актуально. Наш локальный сервер для разработки позволяет использовать дампы данных — zip-архивы с данными по разным запросам, чтобы можно было полноценно работать совсем без интернета. После того как разработчик закончил работу и отправил пул-реквест, включается автоматизация.
Где выиграли время: самостоятельная оценка сил и возможностей, не всегда требуется превозмогать нестабильное интернет-соединение
Этап 2. Автоматические проверки: in progress > in review
Перед тем как задача уйдёт в ревью, она проходит проверки на качество кода, производительность, отсутствие визуальных и функциональных багов. Тут можно было бы много написать о полноте и разнообразии наших автоматических проверок, но, во-первых, это тянет на несколько отдельных рассказов, а во-вторых, выходит далеко за рамки обсуждаемой темы. Я просто дам ссылки на описание инструментов:
— стандартный набор инструментов статического анализа: ESLint и Stylelint с богатым набором плагинов;
— наши собственные статические проверки: наличие и качество переводов, валидация yaml-файлов;
— стандартные инструменты для модульного тестирования: Mocha, Karma, PhantomJS, Istanbul;
наш собственный инструмент для функционального и визуального тестирования — Hermione;
— Pulse — для тестирования производительности — тоже наш собственный. Упоминали о нём вот тут.
Кстати, сюда же откатится задача в случае возникновения проблем на любом из этапов — к сожалению, даже самое тщательное планирование не спасает от ошибок на 100%, что-то может пойти не так. Обнаруживший призывает в задачу нужного человека, описывает суть проблемы, загружает скриншоты или даже видео, может дополнительно написать в чат команды, чтобы все заметили, что задача застопорилась. Что бы это ни было — баг при тестировании вылез, дизайн поменялся, не хватило данных от бэкенда.
Где выиграли время: фильтрация ошибок — разработчик может обнаружить их без привлечения коллег, меньше паники если что-то пошло не так — очевидный первый шаг
Этап 3. Код-ревью: in review > ready for test
Во-первых, призвать в пул-реквест хочется не просто свободного ревьюера, а человека, который понимает, что происходит в твоём коде; во-вторых, из смежной команды, чтобы вся служба имела представление, кто чем занимается — всё это прописано в нашем регламенте. Даже в маленьком офисе бывает сложно и долго организовывать это вручную, что уж говорить про распределёнку (и самоизоляцию!). На помощь приходит автоматизированная код-ревьюшница: статусы она тоже меняет самостоятельно. Подробно останавливаться на том, как она работает, не буду — лучше послушать рассказ разработчика. Ещё она умеет пинговать исполнителей: чем дольше задача висит в ревью, тем яростнее пингует.
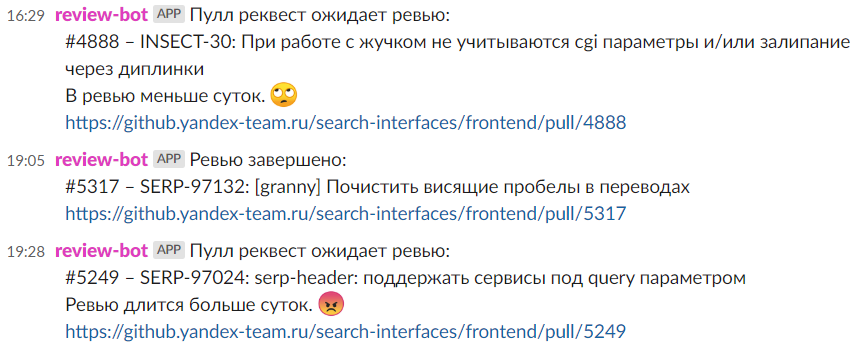
Где выиграли время: поиск релевантного ревьюера, напоминания обработать пул-реквест
Этап 4. Тестирование: testing > tested
Когда изменение прошло код-ревью, запускаем автотесты. Только после того как все они станут зелёными, задача передаётся на ручное тестирование. Важно, что за задачу, пока её явно не передали кому-то ещё, всегда отвечает исполнитель — именно он должен побыстрее протащить свой код через код-ревью и тестирование до продакшена. То есть мы всегда знаем, кто крайний, каждый постоянно мониторит не только свои задачи, но и всё происходящее в команде. Тестировщик в команде обычно один, и ему это тоже удобно: он видит, что прилетит следующим, может эффективнее использовать своё время.
Тестировщик может:
— отдать задачу на тестирование асессорам — пост со всеми подробностями. По итогам тестирования асессорами что-то может потребовать исследовательского тестирования или перепроверки;
— сам протестировать задачу на живом девайсе или используя ферму устройств с удалённым доступом — Колхоз.
Живые девайсы находятся в Гиперкубах в каждом офисе Яндекса. Любой сотрудник может взять необходимое ему устройство с нужными характеристиками, предварительно выбрав ближайшую точку со свободным устройством. В норме через некоторое время система автоматически напомнит, что девайс пора вернуть, но на время самоизоляции эту функцию отключили. Дежурная команда отследила, чтобы живые устройства достались тем, кому это критически необходимо, а всем остальным, чтобы не тормозить рабочие процессы, помогли с подключением к Колхозу.
Колхоз — ферма устройств для удалённого тестирования, воспользоваться которой может любой сотрудник. Android, iOS — мы проверяем изменения даже на самых старых, сложных в поддержке версиях систем, чтобы наши сервисы были доступны любому. Но и флагманы тоже стараемся заполучить как можно скорее и в Колхоз, и в Гиперкубы. Помните «шторку» (она же «монобровь»), которая появилась у девятого iPhone, и все связанные с ней проблемы?
Где выиграли время: планирование, автотесты, распределение устройств: доступны даже при самоизоляции
Этап 5. Вливание: ready for fev > dev
Задача протестирована — пора влить её в общую ветку.
N.B. исторически так сложилось, что конкретно в нашем проекте общая ветка называется неmasterилиtrunk, аdev. Отсюда и название статусов задач в Трекере. Но далее для простоты я буду называть общую веткуtrunk.
Когда вливаний много (у нас, например, больше 30 влитых пул-реквестов в день), возникают две проблемы:
— минорная: история в git, если вливаться как попало и не делать rebase, становится очень запутанной, а если нашёлся какой-то баг, откатиться назад очень сложно;
— критичная: интеграционное тестирование. Не всегда физически возможно дождаться окончания тестирования своих изменений вместе с последней версией trunk, поэтому может случиться следующее: два пул-реквеста, каждый из которых по отдельности ничего не ломает, после вливания сломают trunk. Чтобы предотвратить подобное, мы придерживаемся Trunk based development, то есть релиз можно выкатить от любого коммита. И хотя мы ещё не пришли окончательно к Continuous Deployment, trunk у нас «зелёный». И ломать его даже раз в неделю для нас категорически неприемлемо.
Уже несколько лет мы используем инструмент Merge Queue для автоматизации очереди и постоянно совершенствуем его. Изменения вливает не разработчик, а робот. В каждом пул-реквесте делает rebase по свежей версии trunk и запускает полный набор тестов. Это довольно длительный процесс, поэтому на живых людях построить его невозможно — человек просто не дождётся окончательных результатов. А робот трудится без сна, отдыха и выходных. Более того, задачу может поставить в очередь не сам разработчик, а тестировщик сразу после окончания тестирования, это лишний раз позволяет сэкономить время.

Подробнее о Merge Queue.
Где выиграли время: предотвращаем блокирующие поломки, не надо вручную контролировать вливание пул-реквеста
Этап 6. Релиз: rc > closed
Каждый рабочий день в 5 утра от последнего коммита в trunk у нас автоматически отводится новый релиз: сборка статического и динамического пакетов, выкладка на prestable, тестирование асессорами. Дальше дежурный тестировщик просматривает отчёт и, если есть баги, сообщает о них дежурному разработчику. А если всё хорошо, передаёт дежурному менеджеру. Если тот даёт добро, дежурный разработчик выкатывает релиз.
Тут важно уточнить, что в релиз попадают задачи разных команд, поэтому всем выгодно, когда на релизы явно выделен один дежурный разработчик, который целую неделю только и занимается тем, что катает релизы и следит за мониторингами ошибок. Это позволяет остальным разработчикам проекта как можно раньше (фактически сразу после отправки в Merge Queue) переключаться на новые задачи.
Обычно вся релизная деятельность происходит в рабочее время (даже из дома мы просим всех соблюдать режим — в итоге все нарушают его в разную сторону, но мы не прекращаем пытаться), но если что-то не так в продакшне, дежурная смена разбудит дежурного разработчика, чтобы тот оперативно отреагировал.
Напоминаю, основная задача — сократить время синхронизации участников команды друг с другом и количество рутины: все в курсе, кто на дежурстве. Все знают, что и как надо делать, у всех есть инструкции. Когда менеджер разрешит выкатывать релиз, он не будет объяснять разработчику порядок действий, разработчик сам всё знает и умеет.
Где выиграли время: синхронизация, принятие микрорешений
Цикл замкнулся.
Распределённая работа — прививка от плохих, неэффективных процессов, тормозящих проекты даже в привычных условиях, что уж говорить о нестандартных. Опыт нашей команды подтверждает: если с должным занудством подойти к настройке процедур и взаимодействий и по-честному соблюдать все правила, какими бы банальными они ни казались, рабочий процесс будет довольно сложно парализовать.
Чем-то напоминает организацию дорожного движения: когда автомобилей было мало и они были медленными, о ПДД мало кто задумывался. Сейчас автомобилей очень много и они быстрые — движение без правил стало невозможным. Чем лучше (и одновременно проще) сформулированы эти правила, чем тщательнее их выполняют участники движения, тем выше пропускная способность дорог.
Спасибо, что дочитали до конца. До встречи в комментариях!

achekalin
101 пост на тему «как мы успешно работаем по домам». Правда, зачем?
Что не у каждого дома есть нужное число метров, комнат и вообще условий работать — это уже можно не обсуждать.
Andre_487
Тут есть несколько моментов. Возможно, каждому дома удобно, но вот всей команде вместе может быть не так удобно от того, что все дома, и работа замедляется. Есть люди, которые действительно страдают без офиса. Да, среди работников IT есть экстраверты.
И есть класс людей, у которых дома условий нет. Например, там постоянно бегают дети или там родители, например, просят вынести мусор, а не играться в компьютер.
Так что есть аудитория, которой важен опыт успешной организации как личной работы, так и работы со стороны команды. Особенно большой команды.
mishanga Автор
Этот пост не столько про удаленку, сколько про эффективную работу команды. Удаленка — как лакмусовая бумажка. Если в команде выстроены процессы, то и удаленка не так страшно проходит, и работа в офисе становится эффективнее. Карантин закончится, а процессы останутся.
Можно пережить карантин и постараться забыть его как страшный сон, а можно попытаться проанализировать и сделать выводы о том, как организовать работу в команде эффективнее.