
Чтобы спасти людей, нужна скорость. И открытые источники данных как раз позволяют эту скорость получить. OSINT дает возможность следить за новыми данными в режиме реального времени и узнавать об эпидемиях на 1-2 недели раньше официальных объявлений. А в случае, когда каждый день может уносить тысячи жизней, это время критически важно.
В свою очередь традиционный вариант мониторинга эпидемий является более длительным и дорогостоящим, хотя одновременно и более точным. Заразившемуся нужно понять, что с ним что-то не так, прийти в больницу, сдать анализы. Врачи должны поставить диагноз, а после выявления какого-то опасного заболевания отправить данные в здравоохранительные органы для принятия мер.
В развивающихся странах традиционная система мониторинга заболеваний может и вовсе отсутствовать или быть очень неэффективной. В этом случае OSINT вообще становится единственной возможностью предотвратить или снизить эффект вспышки эпидемии.
Кроме скорости, плюсом OSINT является то, что он доступен большинству. Это дает населению возможность следить за предполагаемыми вспышками в своем регионе и, в случае чего, вовремя обезопасить себя и близких.
Однако открытые данные — это не волшебство, которое всех спасет. OSINT не поможет предсказать появление вируса, но на основе пары выявленных случаев можно спрогнозировать возможную эпидемию и постараться её предотвратить. А если распространение болезни уже в самом разгаре, открытые данные помогут уменьшить количество заболевших.
Подбираем правильные источники
Социальные сети
Twitter — одна из самых распространенных социальных сетей для раннего выявления эпидемий. Часто в коротких сообщениях люди делятся своим самочувствием и используют ключевые слова, которые как раз таки и нужны для мониторинга. К тому же, у этой сети относительно открытая политика с доступом к 1 % случайной выборки твитов.
Поиск намеков на эпидемию в Twitter может выглядеть следующим образом. Твиты, выгруженные за определенный период времени, отфильтровываются в классификаторе SVM по:
— ключевым словам вроде «простуда» (или другое заболевание) на языке региона. Также хорошо добавить фильтр на твиты, в которых человек пишет о себе («я», «мне», «меня») и о том, что он именно заразился («подхватил»), а не просто боится.
— конкретному региону (более точными будут локальные данные — на уровне населенных пунктов). Для этого есть система геолокации в Twitter — Carmen.
А еще нужно исключить ретвиты, новости и ссылки.
Почему в выявлении эпидемий мониторинг Twitter оказывается таким эффективным? В одном исследовании данные по твитам за период с октября 2012 по май 2013 показали корреляцию 0.93 в соотношении с официальными данными из Центров по контролю и профилактике заболеваний в США. В то время как даже данные Министерства здравоохранения и социальных служб США были менее точными — корреляция 0.75. И стоит понимать, что Twitter можно мониторить ежедневно и узнавать информацию из первых рук. А пользователи там могут писать о своем здоровье достаточно откровенно.
Конечно же, Twitter не должен быть единственным источником мониторинга. Ежемесячно там сидят ~4% населения земли. Но на Twitter стоит обратить особое внимание в регионах, где он имеет наибольшее количество активных пользователей.
Кроме Twitter для достижения исходной цели будет полезно мониторить и другие социальные сети.
Например, был интересный случай с WeСhat (как раз по COVID-19). У них есть ресурс WeChat Index, который позволяет определять частоту упоминаний тех или иных ключевых слов. Так вот, в период с 17.11.2019 по 30.12.2019 (за несколько недель до официального объявления и лабораторного подтверждения) WeChat Index наполнился словами «грипп», «нехватка дыхания», «диарея», «новый коронавирус».
Не менее эффективным может оказаться Facebook. Например, определяют места наиболее сильных вспышек по сети контактов. Для этого есть платформа Facebook Data For Good. Там можно получить доступ к сервису Social Connectedness Index (только для НГО и исследователей), который покажет регионы с наиболее тесными связями. Сервис определяет соотношение между дружескими связями в Facebook и местонахождением людей. Это позволяет понять, где люди больше контактируют между собой, и где нужно ввести более строгий карантин.
Поисковые запросы в Google
Тенденция к эпидемии определяется по количеству запросов, относящихся к симптомам, названию заболевания, определенным лекарствам и тд. На сегодняшний день самый доступный инструменты для этого способа — Google Trends.
Двое первых больных коронавирусом в России были зафиксированы 31 января. А Google Trends показывает, что повышенный интерес к вирусу в поисковике по стране начал проявляться за 2 недели до этого.
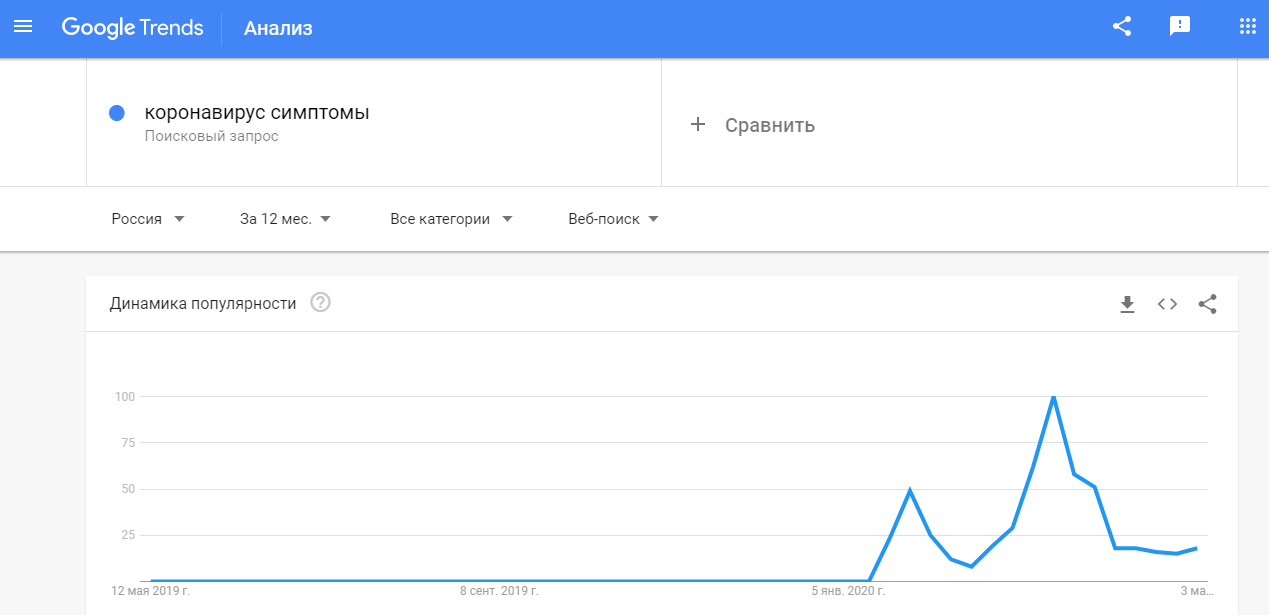
Исследователи из Индии пошли еще дальше и провели корреляцию между двумя источниками открытых данных — между данными о 4-х заболеваниях от Проекта комплексного надзора за болезнями и от Google Trends и Correlate. И по их результатам некоторые вспышки можно было предвидеть аж за 4 недели.
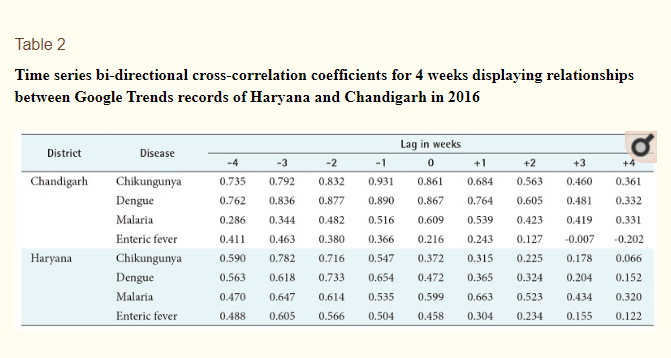
Кроме предсказания вспышек, анализ поисковых запросов поможет примерно определить, когда эпидемия идет на спад.
Аналитика по запросам может быть менее точной и давать результаты с опозданием (данные обновляются еженедельно). Поэтому особенно хороша в сочетании с другими способами.
Популярность статей в Википедии
Результатом поиска информации в Google зачастую становится страница в Википедии. В то время как Google показывает нам, какие темы сейчас ищут больше всего, Википедия — в каких темах люди реально заинтересованы (что даже зашли на ресурс о них почитать).
Википедия предоставляет возможность отслеживать количество просмотров статьи за определенные промежутки времени. Это значит, что можно проследить, когда статья становится более популярной. Информация предоставляется быстро, так как обновляется каждый час. Посмотреть её можно здесь или (более простой вариант, но данные только за месяц) зайти на конкретную статью > слева в «инструментах» нажать «сведения о странице» > на открывшейся странице в первой табличке внизу будет «количество просмотров страницы за последние 30 дней» > справа от него цифра, на которую нажимаете и видите статистику за месяц.
Вот, например, статистика по статье COVID-19 на русском.
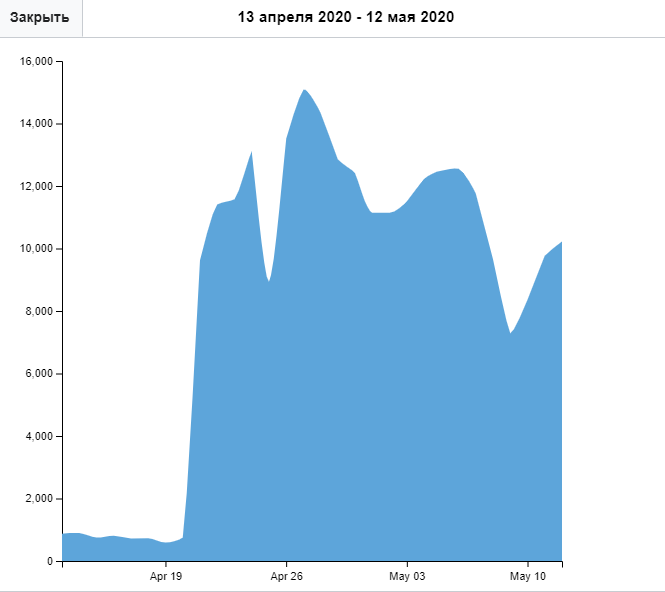
В теории, ничего не мешает нам ежедневно собирать такую открытую статистику по всем страницам с болезнями каким-нибудь скриптом для определения свои трендов в дополнение к Google Trends. Мы, конечно, не сможем проследить за статьей о какой-то редкой и необычной болезни, но статьи о наиболее часто возникающих заразных болезнях можно достаточно просто мониторить.
Подробную статистику по разным параметрам можно смотреть здесь. Например, популярные статьи отфильтровываются по месяцам и дням, а также с указанием конкретного языка. Для этого нужно зайти в «Total Page Views», слева нажать «Top viewed articles» и выбрать язык и период времени. Вот, например, топовые статьи на русском за январь 2020.
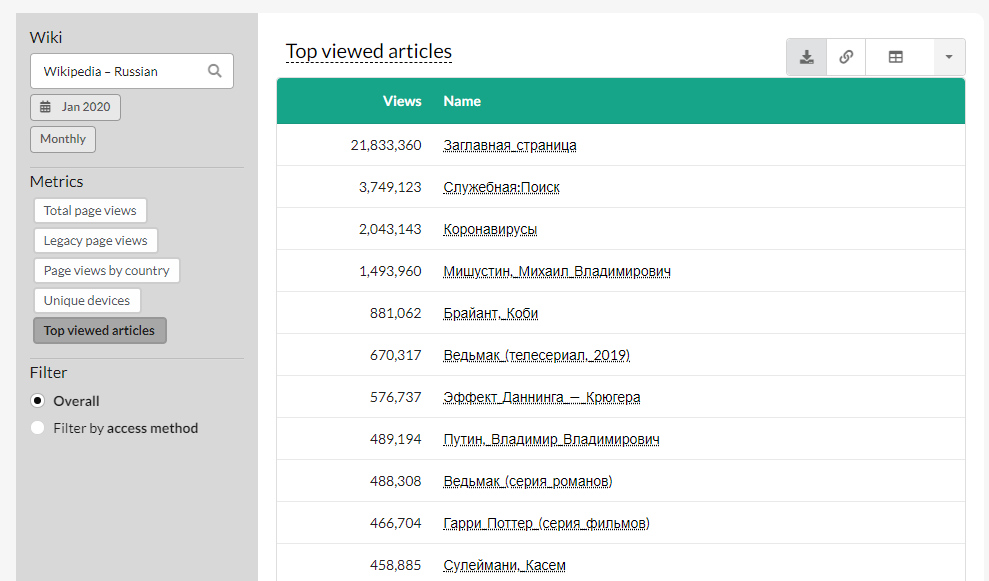
Если вдруг какие-то статьи о заболеваниях (особенно заразных) начинают выбиваться вперед — возможно это тревожный звонок.
Википедия позволяет следить за данными в реальном времени, то есть тоже дает информацию быстрее, чем официальные объявления, в среднем на 2 недели.
Получение данных через краудсорсинг
В среде OSINT никто не запрещает создавать новые источники информации путем привлечения заинтересованных в этой информации людей. В этом случае пользователь сам приходит на наш ресурс и оставляет данные о своем здоровье. Все это анонимно, но помогает определить местоположение новых вспышек. То есть в онлайн-режиме можно посмотреть, где появились случаи заболеваний и где их больше всего.
Такой формат хорош тем, что человек может не иметь возможности или не хотеть идти к врачу. А с помощью готовых краудсорсинговых платформ он может помочь в быстром выявлении новых вспышек и получить некоторые полезные рекомендации. К тому же, это почти 100% точность данных без участия лаборатории, чего, например, анализ запросов в поисковиках уж точно дать не может. А плох этот способ тем, что люди могут не узнать об этом ресурсе своевременно.
Платформа для США: Flu Near You. На сайте анонимно можно рассказать о своем самочувствии. Данные сразу же визуализируются на карту так, что другие могут зайти и посмотреть, в каких регионах есть заболевшие люди.
Для 10 европейских стран: Influenzanet. Тут можно заполнить анкету с вопросами о симптомах, географических данных. После этого, каждую неделю участникам напоминают сообщать о новых симптомах и как меняется их состояние. Все тоже анонимно. Полученные данные отображаются на графиках и каждую неделю обновляются.
Мониторинг местных новостей
Регулярный мониторинг локальных новостей может реально ускорить реакцию государства на эпидемию. Рассмотрим несколько платформ, которые этим занимаются.
Например, канадский государственный ресурс GPHIN. По ключевым словам информационная сеть анализирует данные из различных новостных интернет-источников. Он доступен только по платной подписке и обычно его используют международные и некоммерческие организации, государства, некоторые частные компании.
Впервые GPHIN успешно помог в выявлении необычного вируса в Китае в конце 2002 на 3 месяца(!) раньше традиционной системы мониторинга через какую-то местную газетку в провинции Гуандонг.
Нельзя обойти стороной ресурс Worldometer. Он отображает мировую статистику по разным темам (в том числе и здравоохранение) в режиме реального времени. Аналитики, разработчики, исследователи и волонтеры по всему миру собирают данные из достоверных новостных сообщений. Несмотря на то, что основной источник информации у платформы все-таки государственные данные и лабораторно подтвержденные случаи, они могут реагировать быстрее официальных сообщений. Например, отслеживать информацию из социальных сетей кого-то из властей или с пресс-конференций и сразу же её публиковать.
Сейчас у них есть отдельная страница по COVID-19. Там можно найти форму, которая позволяет сообщать о новых случаях. Что значительно ускоряет поступление новых данных. В профилях у некоторых стран даже есть прогнозы и данные по отдельным регионам.
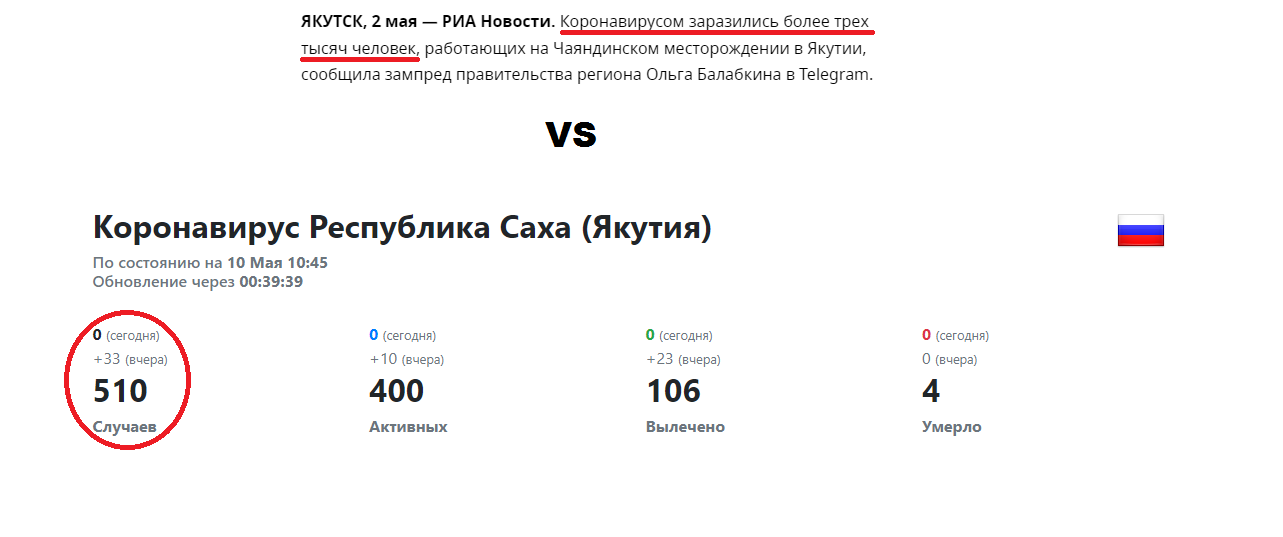
Анализ местных новостей с точки зрения OSINT помогает не только выявить эпидемию, но и избежать распространения дезинформации. Так как он предполагает обработку больших объемов данных из разных источников и проверку найденной информации. Вот недавний пример: в сети появилась информация, что в Республике Якутия 3500 человек заразилось COVID-19 на каком-то промышленном объекте. По официальным же данным на 10 мая во всей республике чуть больше 500 зараженных. Казалось бы, и то и другое — открытые источники, но наложение их друг на друга в ходе небольшой разведки позволило немного скорректировать картину по эпидемии в регионе (а может, и во всей стране?)
Гибридный способ
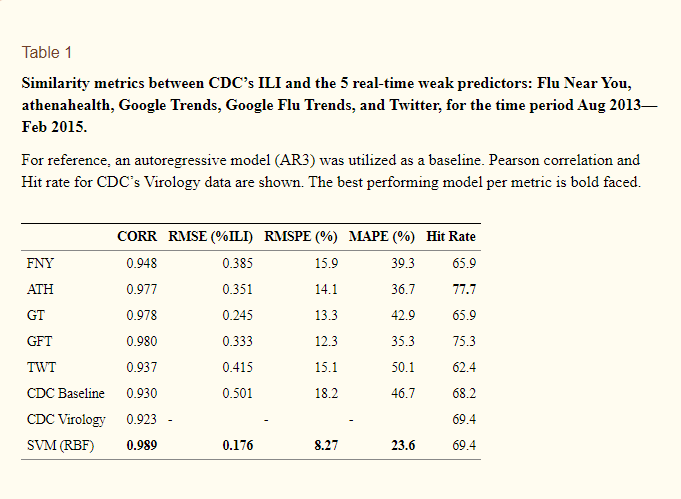
Некоторые исследователи предлагают совместить распознавание эпидемий через OSINT и традиционный мониторинг. Например, соединить в одну систему результаты по запросам в Гугл, анализ постов в социальных сетях, краудсорсинговые платформы и данные о том, что люди обращались с какой-то болезнью, из электронных медицинских карточек (их можно получить, например, с помощью athenahealth). И это отличный вариант, потому что даже, если какой-то из способов даст неверные или искаженные данные, это не испортит общую картину.
В этом примере исследователи скомбинировали все способы и сравнили с официальными данными, которые поступали из американских Центров по контролю и профилактике заболеваний (у них лабораторно подтвержденные случаи). Получилось, что корреляция данных из всех источников с официальными данными значительно выше, чем если использовать их по отдельности.
Какие еще инструменты доступны для исследования эпидемий методами OSINT?
ProMED
Это ресурс, который собирает информацию по сети и не только, проверяет ее, сразу же публикует у себя на сайте и рассылает на почту тем, кто на них подписан.
ProMED открыт к любым источникам: сообщения СМИ, официальные сообщения, данные от местных обозревателей и др. Перед публикацией команда модераторов-экспертов проверяет поступающую информацию. Кстати, ProMED доступен и на русском. Эта версия освещает только русскоговорящий регион постсоветских стран.
Не самый быстрый способ выявления эпидемий, но, предположительно, быстрее, чем традиционную систему мониторинга. За неделю до официального объявления ВОЗ, 30 декабря 2020 ProMED узнал о странной пневмонии из китайского ресурса микроблогов Weibo.
HealthMap
Это система, которая с помощью алгоритмов анализирует десятки тысяч источников данных: новостные порталы, сообщения госорганов, социальные сети, блоги. И всё для того, чтобы выявить и отследить новые вспышки. Ресурс сразу же визуализирует полученные данные в виде карты. А в борьбе с неточностями они используют искусственный интеллект, который помогает избавиться от повторов и нерелевантной информации.
Яркий пример успешности HealthMap — распознавание вируса эболы 14 марта 2014, за 9 дней до официального объявления от органов здравоохранения Гвинеи.
Как бороться с искажениями в данных из открытых источников
1. Открытые данные находятся во власти соответствующих компаний (Google, Facebook, разные платформы и сайты). И эти корпорации могут менять алгоритмы при сборе информации без какого-либо уведомления. Или что-то удалять, изменять в собранных данных.
Решение: накапливать нужные данные у себя. В том числе — с помощью готовых инструментов, таких как web archive. Так их можно будет или мониторить в режиме реального времени или анализировать в ретроспективе.
2. Недостаточная репрезентативность в Интернете. Данные могут показывать, что заболевших больше, например, в США. В Африке их может быть ещё больше. Но так как у них охват территорий интернетом сильно меньше, им сложнее как-то обозначиться. А платформы HealthMap и GPHIN дают лучшие результаты в странах, где больше новостных порталов и других СМИ. Что тоже совсем не помогает быстрому распознаванию эпидемий в развивающихся странах.
Решение: здесь поможет статистика — смотреть откуда приходят данные и соотносить с количеством людей, которые там живут, количеством населения, которое имеет доступ к сети и проводить экстраполяцию.
3. Совпадение с похожими словами с другим значением и в других контекстах. Если используются простые ключевые слова для поиска без сложной фильтрации, то есть шанс получить неверную информацию. В 2007 в США Google trends ошибочно выявил эпидемию холеры. А это просто Опра Уинфри выбрала роман «Любовь во время холеры» для своего книжного клуба и поэтому был резкий всплеск запросов на слово «холера».
Решение: нужна автоматизированная семантическая фильтрация — отделение данных с ключевыми словами, которые точнее отражают смысл того, что мы ищем.
4. Нет подтверждения, что люди, которые что-то ищут или что-то пишут, действительно заражены и болеют. Это можно решить использованием гибридного способа, о котором мы говорили выше, либо положиться на большие данные+закон больших чисел, которые в совокупности нивелируют негативный эффект.
Что дальше: повышение эффективности выявления эпидемий методами OSINT
Как минимум, те данные, которые пользователи оставляют в открытом доступе, должны быть доступны для анализа органов здравоохранения и других желающих, которые хотят знать больше и быстрее об эпидемиологической обстановке в стране и в мире. Ведь далеко не все платформы предоставляют возможность выгружать данные или вообще хоть как-то анализировать происходящее через OSINT.
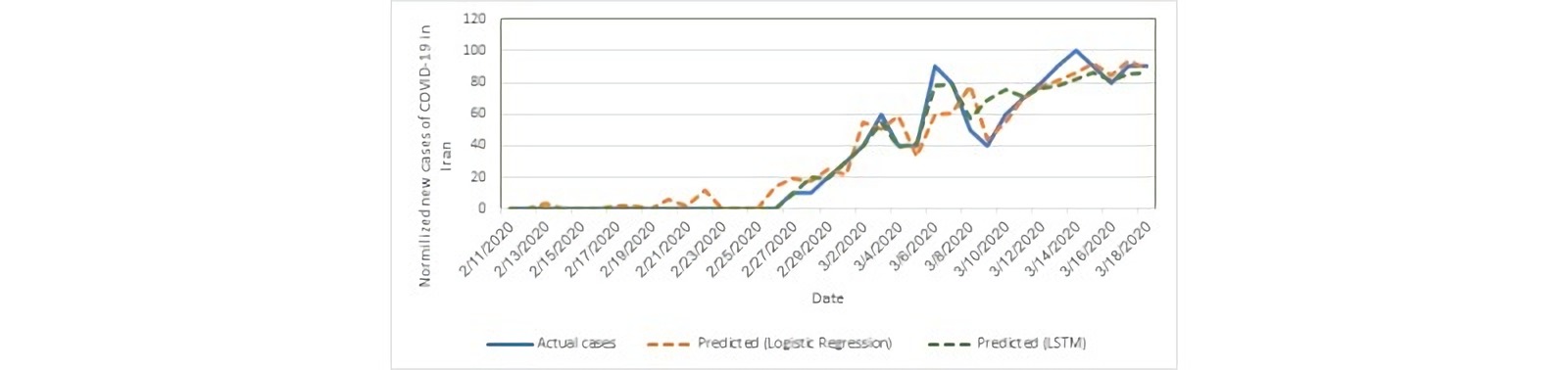
Некоторые исследователи пытаются «прикрутить» к такой аналитике средства машинного обучения. Например, в Иране провели эксперимент с долгой краткосрочной памятью (LSTM) и пандемией COVID-19. Они использовали данные из Google Trends и смогли очень неплохо предсказать количество новых случаев. На графике ниже показано, как реальное количество заболевших соотносится с предсказанием LSTM. Исследователи отмечают, что если бы данных для обучения было больше, то и результаты были бы точнее.
Глубокое обучение пробуют использовать для прогнозирования количества зараженных ВИЧ. Например, в Китае для эксперимента взяли официальные данные за 2005-2016 по автономной области Гуанси и, используя разные модели (в том числе LSTM), попробовали предсказать количество зараженных за 2015-2016. Исследователи сравнили результаты с реальными данными, и долгая краткосрочная память дала наиболее точные предсказания.
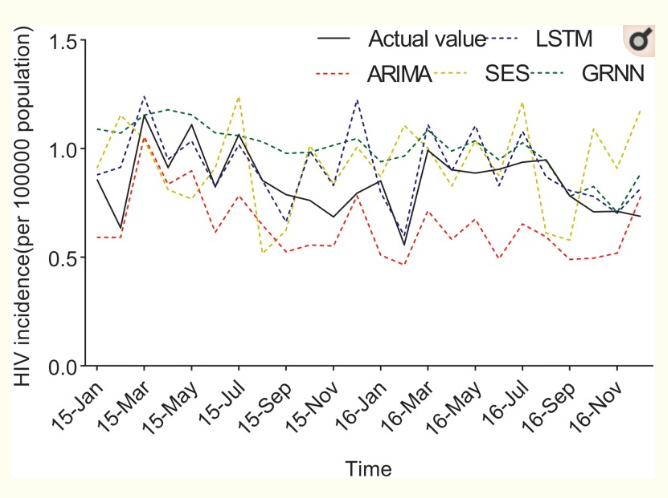
Чтобы развивать инструменты на основе глубокого обучения, нужно очень много данных. А сейчас существует тенденция, наоборот, оставлять как можно меньше своей информации в интернете, защищать свою приватность. Тем не менее, как показала практика, для того, чтобы успешно применять методы OSINT при исследовании любой проблемы, достаточно уметь оперативно находить релевантные источники в открытом доступе и иметь в своем арсенале несколько приемов для их эффективного анализа.
teecat
Интерес не есть эпидемия. Это скорее ближе к панике. Мне кажется все описанное возможно, если публикации отвечают критериям достоверности (без паники, теорий заговоров и прочего) и отсутствия фильтрации. А этого как раз и нет