

Зачем нефтяникам NLP? Как заставить компьютер понимать профессиональный жаргон? Можно ли объяснить машине, что такое «нагнеталка», «приемистость», «затрубное»? Как связаны вновь принятые на работу сотрудники и голосовой ассистент? На эти вопросы мы постараемся ответить в статье о внедрении в ПО для сопровождения нефтедобычи цифрового ассистента, облегчающего рутинную работу геолога-разработчика.
Мы в институте разрабатываем своё ПО (https://rn.digital/) для нефтяной отрасли, а чтобы его пользователи полюбили, нужно не только полезные функции в нём реализовывать, но и всё время думать об удобстве интерфейса. Одним из трендов UI/UX на сегодняшний день является переход к голосовым интерфейсам. Ведь как ни крути, наиболее естественной и удобной формой взаимодействия для человека является речь. Так было принято решение о разработке и внедрении голосового помощника в наши программные продукты.
Помимо улучшения UI/UX составляющей, внедрение ассистента также позволяет снизить «порог вхождения» в работу с ПО для новых сотрудников. Функционал у наших программ обширный, и, чтобы со всем разобраться, может уйти не один день. Возможность «попросить» ассистента выполнить нужную команду позволит сократить время на решение поставленной задачи, а также уменьшить стресс от новой работы.
Поскольку корпоративная служба безопасности очень чувствительно относится к передаче данных во внешние сервисы, мы задумались о разработке ассистента на основе решений с открытым исходным кодом, позволяющих обрабатывать информацию локально.
Структурно наш помощник состоит из следующих модулей:
- Распознавание речи (Automatic Speech Recognition, ASR)
- Выделение смысловых объектов (Natural Language Understanding, NLU)
- Исполнение команд
- Синтез речи (Text-to-Speech, TTS)
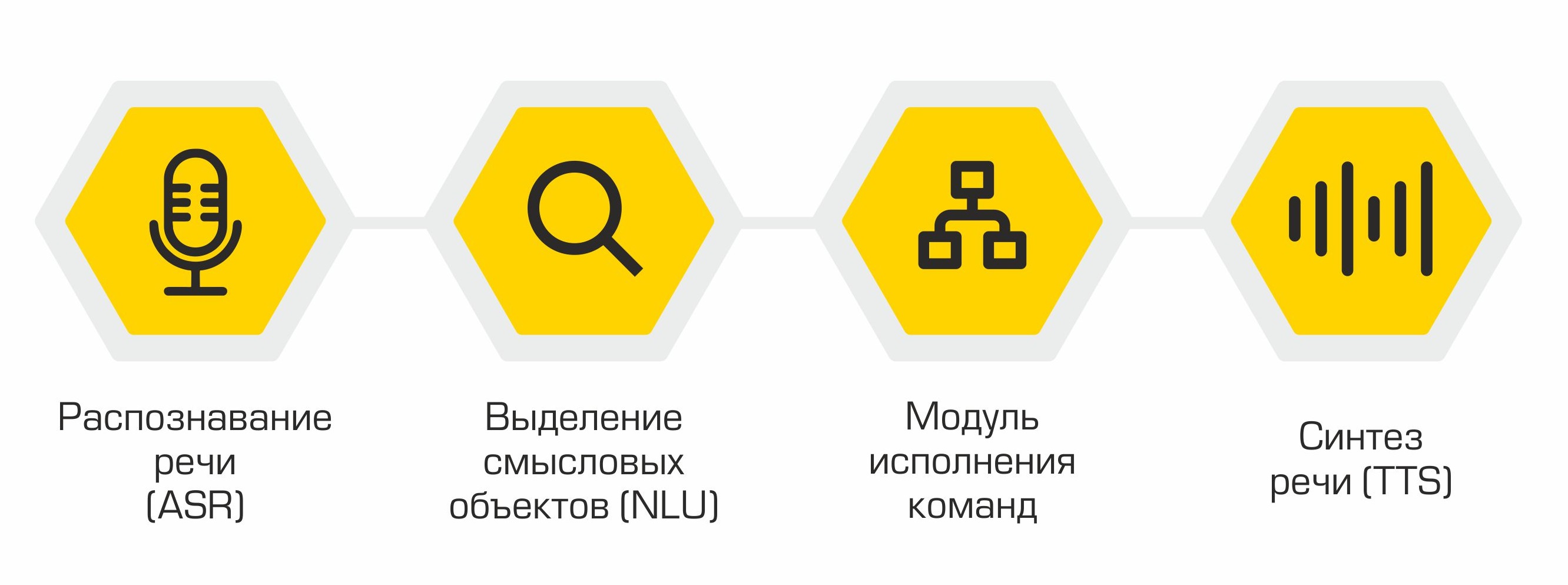
Принцип работы ассистента: от слов (пользователя) к действиям (в ПО)!
Выход каждого модуля служит входной точкой для следующего компонента системы. Так, речь пользователя преобразуется в текст и отправляется на обработку алгоритмам машинного обучения для определения намерения пользователя. В зависимости от этого намерения активируется нужный класс в модуле исполнения команд, который выполняет требование пользователя. По завершении операции модуль исполнения команд передает информацию о статусе выполнения команды модулю синтеза речи, который, в свою очередь, оповещает пользователя.
Каждый модуль помощника представляет собой микросервис. Так, при желании пользователь может обойтись и вовсе без речевых технологий и обратиться напрямую к «мозгу» ассистента – к модулю выделения смысловых объектов – через форму чат-бота.
Распознавание речи
Первый этап распознавания речи – обработка речевого сигнала и извлечение признаков. Самым простым представлением звукового сигнала может служить осциллограмма. Она отражает количество энергии в каждый момент времени. Однако для определения произносимого звука этой информации недостаточно. Нам важно знать, какое количество энергии содержится в различных частотных диапазонах. Для этого с помощью преобразования Фурье производится переход от осциллограммы к спектру.
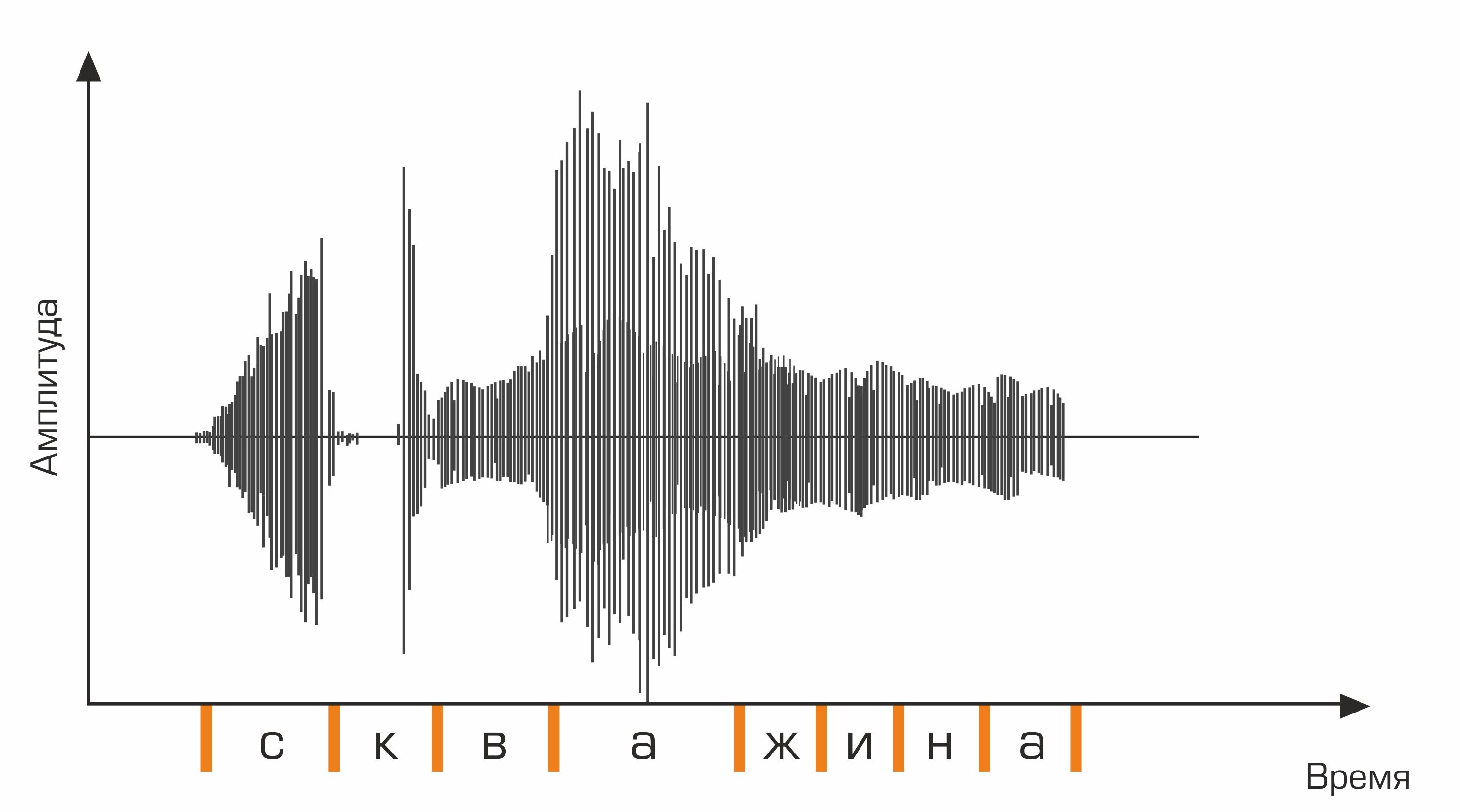
Это осциллограмма.
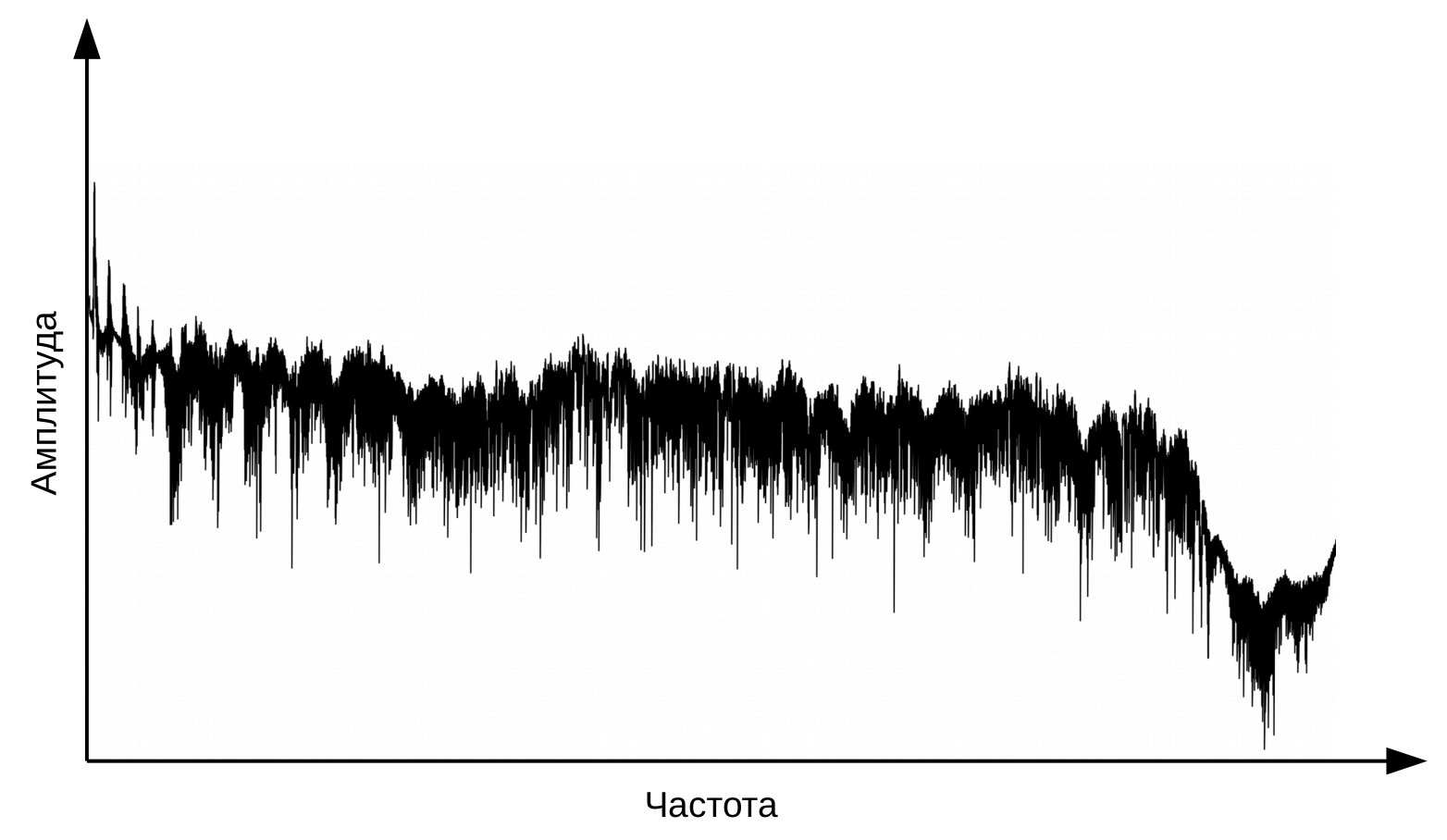
А это спектр для каждого момента времени.
Здесь нужно уточнить, что речь образуется при прохождении вибрирующего воздушного потока через гортань (источник) и голосовой тракт (фильтр). Для классификации фонем нам важна лишь информация о конфигурации фильтра, то есть о положении губ и языка. Выделить такую информацию позволяет переход от спектра к кепстру (cepstrum – анаграмма слова spectrum), выполняемый с помощью обратного преобразования Фурье от логарифма спектра. По оси x вновь откладывается не частота, а время. Для проведения различия между временными областями кепстра и исходного звукового сигнала используют термин «сачтота» (Оппенгейм, Шафер. Цифровая обработка сигналов, 2018).
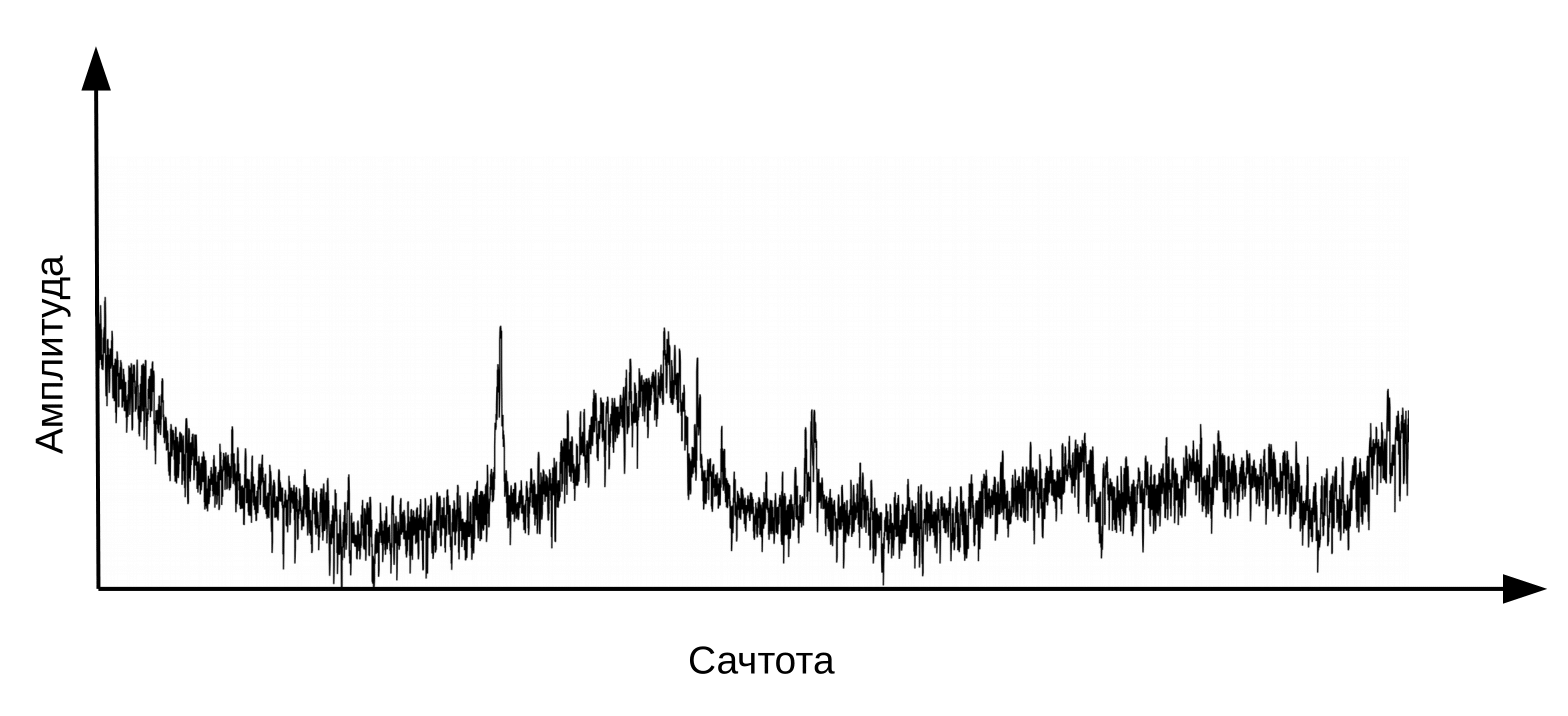
Кепстр, или просто “спектр логарифма спектра”. Да-да, сачтота – это термин, а не опечатка
Информация о положении голосового тракта находится в 12 первых коэффициентах кепстра. Эти 12 кепстральных коэффициентов дополняются динамическими признаками (дельта и дельта-дельта), описывающими изменения звукового сигнала. (Jurafsky, Martin. Speech and Language Processing, 2008). Полученный вектор значений носит название MFCC вектор (Mel-frequency cepstral coefficients) и является наиболее распространенным акустическим признаком, используемым в распознавании речи.
Что же происходит с признаками дальше? Они используются в качестве входных данных для акустической модели. Она показывает, какая лингвистическая единица, скорее всего, «породила» подобный MFCC вектор. В разных системах такими лингвистическими единицами могут служить части фонем, фонемы или даже слова. Таким образом, акустическая модель позволяет преобразовать последовательность MFCC векторов в последовательность наиболее вероятных фонем.
Далее для последовательности фонем необходимо подобрать соответствующую последовательность слов. Здесь в дело вступает словарь языка, содержащий транскрипцию всех распознаваемых системой слов. Составление подобных словарей трудоемкий процесс, требующий экспертных знаний в фонетики и фонологии конкретного языка. Пример строки из словаря транскрипций:
скважина s k v aa zh y n ay
На следующем этапе языковая модель определяет априорную вероятность предложения в языке. Другими словами, модель даёт оценку, насколько правдоподобно появление такого предложения в языке. Хорошая языковая модель определит, что фраза «Построй график дебита нефти» более вероятна, чем предложение «Построй график девять нефти».
Комбинация акустической модели, языковой модели и словаря произношений создает «решетку» гипотез – все возможные последовательности слов, из которых с помощью алгоритма динамического программирования можно найти наиболее вероятную. Её система и предложит в качестве распознанного текста.
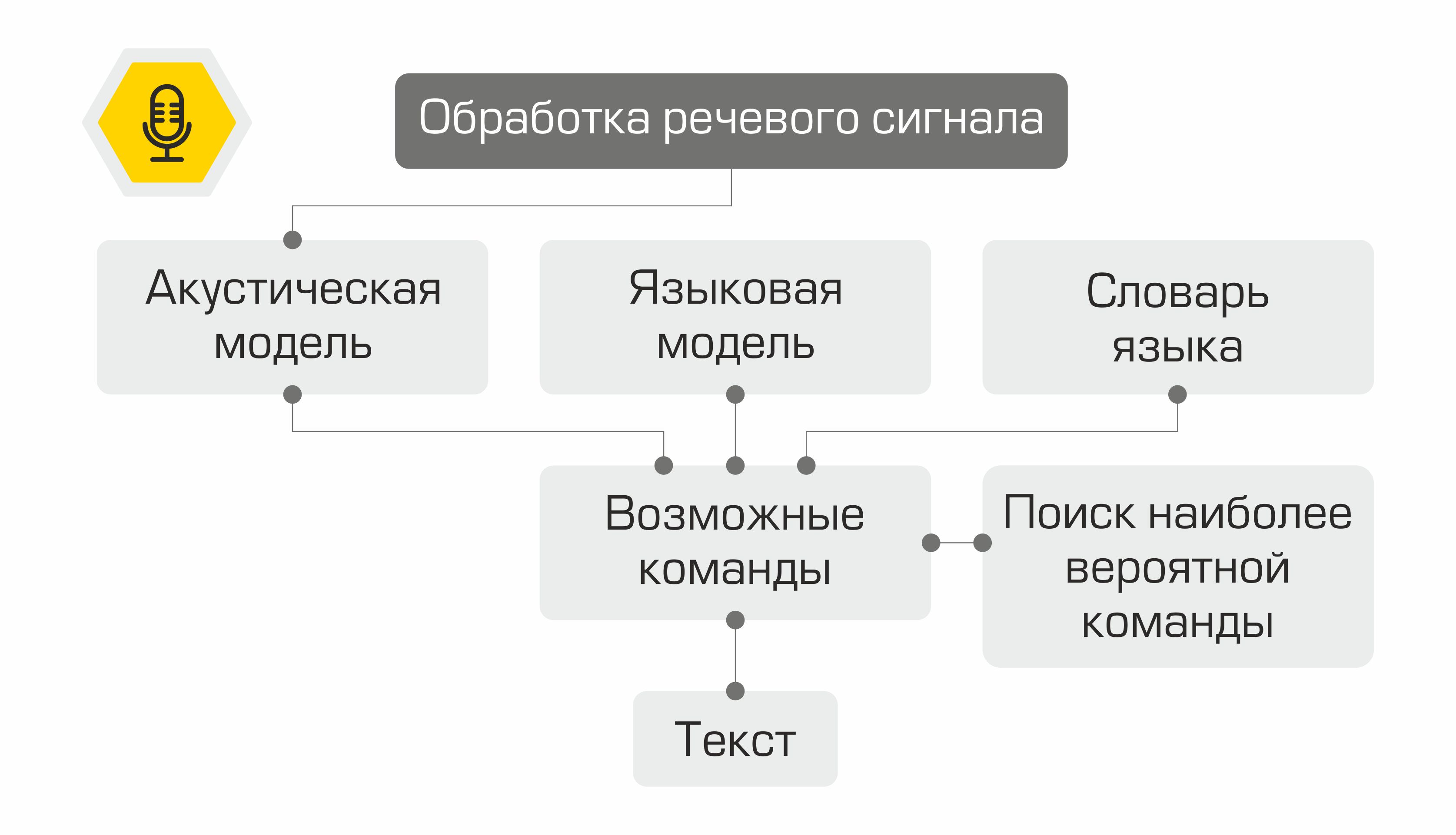
Схематичное изображение работы системы распознавания речи
Изобретать велосипед и писать с нуля библиотеку для распознавания речи было бы нецелесообразно, поэтому наш выбор пал на фреймворк kaldi. Несомненным плюсом библиотеки является её гибкость, позволяющая при необходимости создавать и модифицировать все компоненты системы. Кроме того, лицензия Apache License 2.0 позволяет свободно использовать библиотеку в коммерческой разработке.
В качестве данных для обучения акустической модели использовался свободно распространяемый аудио датасет VoxForge. Для преобразования последовательности фонем в слова мы использовали словарь русского языка, предоставляемый библиотекой CMU Sphinx. Поскольку в словаре отсутствовало произношение терминов специфичных для нефтяной отрасли, на его основе с помощью утилиты g2p-seq2seq была обучена модель графемно-фонемного преобразования (grapheme-to-phoneme), позволяющая быстро создавать транскрипции для новых слов. Языковая модель обучалась как на транскриптах аудио с VoxForge, так и на созданном нами датасете, содержащим термины нефтегазовой отрасли, названия месторождений и добывающих обществ.
Выделение смысловых объектов
Итак, речь пользователя мы распознали, но ведь это всего лишь строчка текста. Как объяснить компьютеру, что необходимо выполнить? Самые первые системы голосового управления использовали жестко ограниченный набор команд. Распознав одну из таких фраз можно было вызвать соответствующую ей операцию. С тех пор технологии в сфере обработки и понимания естественного языка (NLP и NLU соответственно) шагнули далеко вперед. Уже сегодня модели, обученные на больших объемах данных, способны неплохо понимать смысл, заключенный в том или ином высказывании.
Чтобы выделить смысл из текста распознанной фразы, необходимо решить две задачи машинного обучения:
- Классификация команды пользователя (Intent Classification).
- Выделение именованных сущностей (Named Entity Recognition).
При разработке моделей мы использовали библиотеку с открытым исходным кодом Rasa, распространяемую под лицензией Apache License 2.0.
Чтобы решить первую задачу, необходимо представить текст в виде числового вектора, который может быть обработан машиной. Для подобного преобразования использована нейронная модель StarSpace, позволяющая «вложить» текст запроса и класс запроса в общее пространство.

Нейронная модель StarSpace
Во время обучения нейронная сеть учится сравнивать сущности, так чтобы минимизировать расстояние между вектором запроса и вектором верного класса и максимизировать расстояние до векторов отличных классов. Во время тестирования для запроса х выбирается класс у, так чтобы:
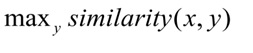
В качестве меры схожести векторов используется косинусное расстояние:
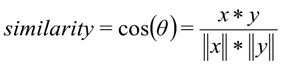
, где
х – запрос пользователя, у – категория запроса.
Для обучения классификатора намерений пользователя было размечено 3000 запросов. Всего у нас вышло 8 классов. Выборку мы разделили на обучающую и тестовую выборки в соотношении 70/30 с помощью метода стратификации по целевой переменной. Стратификация позволила сохранить исходное распределение классов в трейне и тесте. Качество обученной модели оценивалось сразу по нескольким критериям:
- Полнота (Recall) – доля верно классифицированных запросов относительно всех запросов данного класса.
- Доля верно классифицированных запросов (Accuracy).
- Точность (Precision) – доля верно классифицированных запросов относительно всех запросов, которые система отнесла к данному классу.
- Мера F1 – гармоническое среднее между точностью и полнотой.
Также для оценки качества модели классификации используется матрица ошибок системы. По оси y проставлен истинный класс высказывания, по оси x – класс, предсказанный алгоритмом.
На контрольной выборке модель показала следующие результаты:
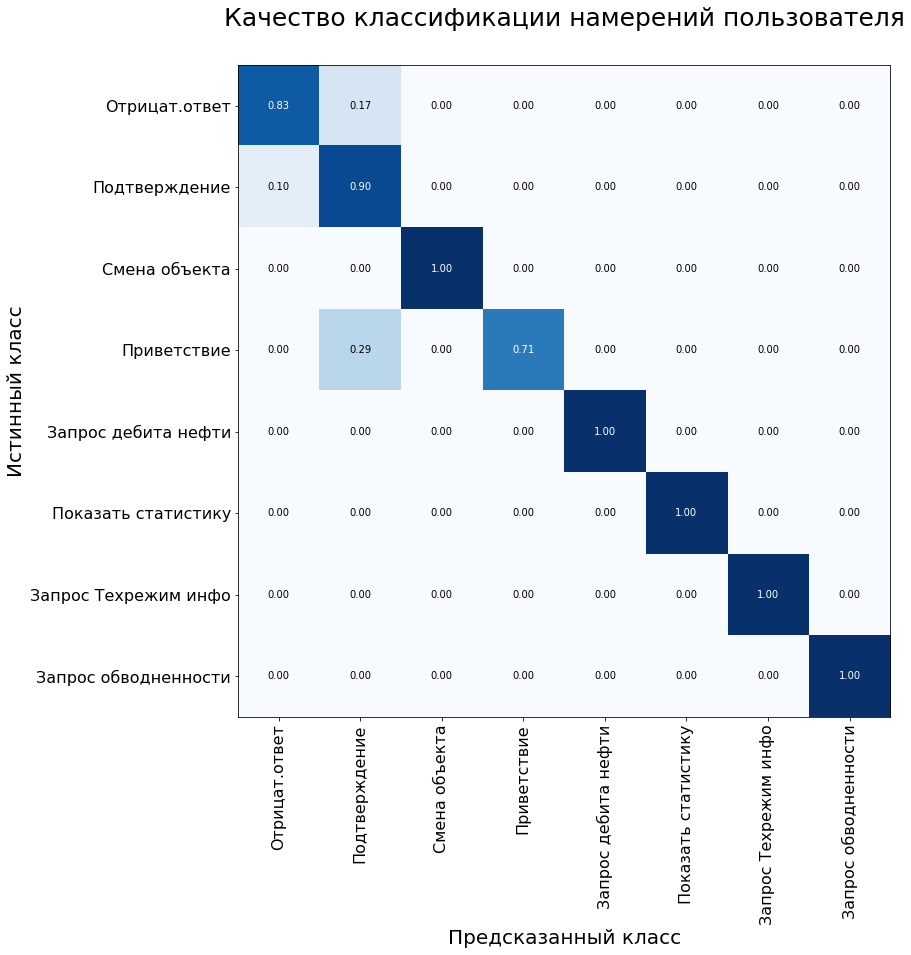
Метрики модели на тестовом датасете: Accuracy – 92%, F1 – 90%.
Вторая задача – выделение именованных сущностей – заключается в идентификации слов и словосочетаний, обозначающих конкретный предмет или явление. Такими сущностями могут быть, например, название месторождения или добывающего общества.
Для решения задачи использовался алгоритм условных вероятностных полей (Conditional Random Fields), представляющих собой разновидность Марковских полей. CRF является дискриминативной моделью, то есть моделирует условную вероятность P(Y|X) скрытого состояния Y (класс слова) от наблюдения X (слово).
Чтобы выполнять просьбы пользователей, нашему ассистенту необходимо выделять три типа именованных сущностей: название месторождения, имя скважины и наименование объекта разработки. Для обучения модели мы подготовили датасет и произвели аннотацию: каждому слову в выборке был присвоен соответствующий класс.

Пример из обучающей выборки для задачи Named Entity Recognition.
Однако всё оказалось не так просто. У разработчиков месторождений и геологов довольно распространены профессиональные жаргонизмы. Людям не составляет труда понять, что «нагнеталка» – это нагнетательная скважина, а «Самотлор», скорее всего, обозначает Самотлорское месторождение. Для модели же, обученной на ограниченном объеме данных, провести такую параллель пока трудно. Справиться с этим ограничением помогает такая замечательная фича библиотеки Rasa, как создание словаря синонимов.
## synonym: Самотлор
— Самотлор
— Самотлорское
— самое большое месторождении нефти в России
Добавление синонимов также позволило немного расширить выборку. Объем всего датасета составил 2000 запросов, которые мы разделили на трейн и тест в соотношении 70/30. Качество модели оценивалось с помощью метрики F1 и составило 98% при тестировании на контрольной выборке.
Исполнение команд
В зависимости от класса запроса пользователя, определенного на предыдущем шаге, система активирует соответствующий класс в ядре программного обеспечения. Каждый класс обладает как минимум двумя методами: методом, непосредственно выполняющим запрос, и методом генерации ответа для пользователя.
Например, при отнесении команды к классу “запрос_график_добычи” создается объект класса RequestOilChart, выгружающий информацию по добыче нефти из базы данных. Выделенные именованные сущности (например, название скважины и месторождения) используются для заполнения слотов в запросах для обращения к базе данных или ядру программного обеспечения. Отвечает ассистент с помощью заготовленных шаблонов, пробелы в которых заполняются значениями выгруженных данных.

Пример работы прототипа ассистента.
Синтез речи

Схема работы конкатенативного синтеза речи
Сгенерированный на предыдущем этапе текст оповещения пользователя выводится на экран, а также используется в качестве входа для модуля синтеза устной речи. Генерация речи осуществляется с использованием библиотеки RHVoice. Лицензия GNU LGPL v2.1 позволяет использовать фреймворк в качестве компонента коммерческого ПО. Основными компонентами системы синтеза речи являются лингвистический процессор, который обрабатывает подаваемый на вход текст. Производится нормализация текста: цифры приводятся к письменному представлению, аббревиатуры расшифровываются и т. п. Далее с помощью словаря произношений происходит создание транскрипции для текста, которая далее передается на вход акустического процессора. Данный компонент отвечает за выбор звуковых элементов из речевой базы данных, конкатенацию выбранных элементов и обработку звукового сигнала.
Собираем всё воедино
Итак, все компоненты голосового помощника готовы. Осталось лишь «собрать» их в правильной последовательности и протестировать. Как мы упоминали ранее, каждый модуль представляет собой микросервис. В качестве шины для связки всех модулей используется фреймворк RabbitMQ. Иллюстрация наглядно демонстрирует внутреннюю работу ассистента на примере типичного запроса пользователя:
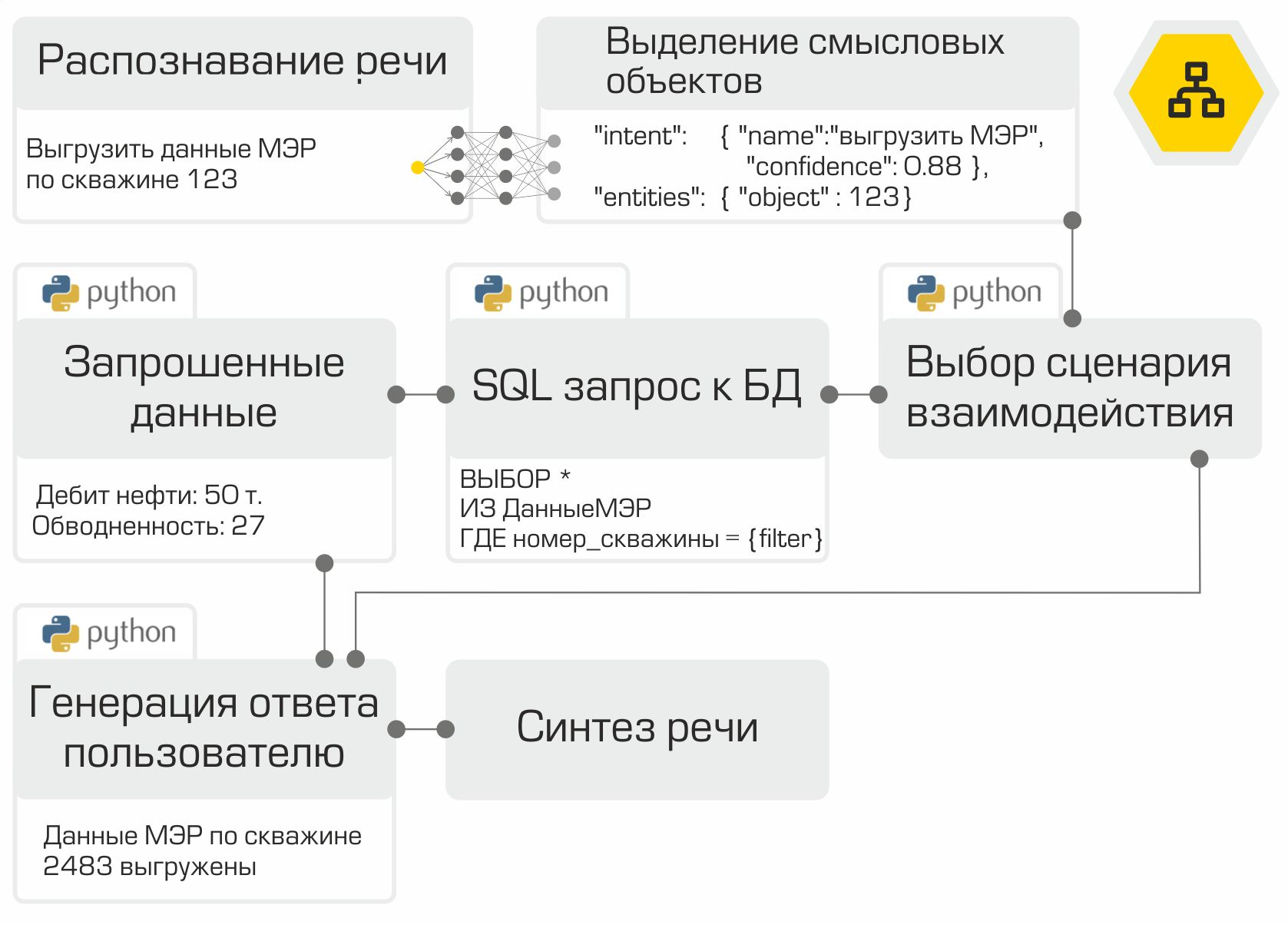
Созданное решение позволяет разместить всю инфраструктуру в сети Компании. Локальная обработка информации является главным достоинством системы. Однако платить за автономность приходится тем, что собирать данные, обучать и тестировать модели приходится самостоятельно, а не использовать мощь топовых вендоров на рынке цифровых ассистентов.
В данный момент мы занимаемся интеграцией помощника в один из разрабатываемых продуктов.
Как удобно будет искать свою скважину или любимый куст с помощью всего одной фразы!
На следующем этапе планируется сбор и анализ обратной связи от пользователей. Также в планах расширение команд, распознаваемых и выполняемых ассистентом.
Описанный в статье проект – далеко не единственный пример использования методов машинного обучения в нашей Компании. Так, например, анализ данных применяется для автоматического подбора скважин-кандидатов на геолого-технические мероприятия, целью которых является интенсификации добычи нефти. В одной из ближайших статей мы расскажем, как решали эту крутую задачу. Подписывайтесь на наш блог, чтобы не пропустить!






LeToan
Самотлор — это волейбольная команда. Кое-где это название никаких иных ассоциаций не вызовет.
Maslukhin
Кое-где и "мать" — биологический родитель. Но это же не повод :)